Omówienie i najlepsze rozwiązania dotyczące grup trybu failover — Azure SQL Managed Instance
Dotyczy: ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Funkcja grup trybu failover umożliwia zarządzanie replikacją i trybem failover wszystkich baz danych użytkowników w wystąpieniu zarządzanym do innego regionu świadczenia usługi Azure. Ten artykuł zawiera omówienie funkcji grupy trybu failover z najlepszymi rozwiązaniami i zaleceniami dotyczącymi korzystania z niej w usłudze Azure SQL Managed Instance.
Aby rozpocząć korzystanie z tej funkcji, zapoznaj się z artykułem Konfigurowanie grupy trybu failover dla usługi Azure SQL Managed Instance.
Omówienie
Funkcja grup trybu failover umożliwia zarządzanie replikacją i trybem failover baz danych użytkowników w wystąpieniu zarządzanym do wystąpienia zarządzanego w innym regionie świadczenia usługi Azure. Grupy trybu failover zostały zaprojektowane w celu uproszczenia wdrażania baz danych replikowanych geograficznie i zarządzania nimi na dużą skalę.
Aby uzyskać więcej informacji, zobacz Wysoka dostępność dla usługi Azure SQL Managed Instance. Aby uzyskać informacje na temat celu punktu odzyskiwania i celu punktu odzyskiwania w trybie failover geograficznego, zobacz omówienie ciągłości działania.
Przekierowywanie punktu końcowego
Grupy trybu failover zapewniają punkty końcowe odbiornika tylko do odczytu i odczytu, które pozostają niezmienione podczas przechodzenia w tryb failover geograficznego. Nie musisz zmieniać parametry połączenia dla aplikacji po przejściu w tryb failover geograficznie, ponieważ połączenia są automatycznie kierowane do bieżącego podstawowego elementu. Tryb failover geograficznego przełącza wszystkie pomocnicze bazy danych w grupie na rolę podstawową. Po zakończeniu przechodzenia w tryb failover geograficznie rekord DNS zostanie automatycznie zaktualizowany w celu przekierowania punktów końcowych do nowego regionu.
Odciążanie obciążeń tylko do odczytu
Aby zmniejszyć ruch do podstawowych baz danych, możesz również użyć pomocniczych baz danych w grupie trybu failover, aby odciążyć obciążenia tylko do odczytu. Użyj odbiornika tylko do odczytu, aby skierować ruch tylko do odczytu do pomocniczej bazy danych z możliwością odczytu.
Odzyskiwanie aplikacji
Aby zapewnić pełną ciągłość działania, dodanie regionalnej nadmiarowości bazy danych jest tylko częścią rozwiązania. Odzyskiwanie kompleksowej aplikacji (usługi) po katastrofalnym niepowodzeniu wymaga odzyskania wszystkich składników, które stanowią usługę i wszelkie usługi zależne. Przykłady tych składników obejmują oprogramowanie klienckie (na przykład przeglądarkę z niestandardowym kodem JavaScript), frontony internetowe, magazyn i system DNS. Ważne jest, aby wszystkie składniki były odporne na te same awarie i stały się dostępne w ramach celu czasu odzyskiwania (RTO) aplikacji. W związku z tym należy zidentyfikować wszystkie usługi zależne i zrozumieć oferowane przez nich gwarancje i możliwości. Następnie należy podjąć odpowiednie kroki, aby upewnić się, że funkcje usługi podczas pracy w trybie failover usług, od których zależy.
Zasady trybu failover
Grupy trybu failover obsługują dwie zasady trybu failover:
- Zarządzane przez klienta (zalecane) — klienci mogą wykonać tryb failover grupy, gdy zauważą nieoczekiwaną awarię, która ma wpływ na co najmniej jedną bazę danych w grupie trybu failover. W przypadku korzystania z narzędzi wiersza polecenia, takich jak program PowerShell, interfejs wiersza polecenia platformy Azure lub interfejs API REST, wartość zasad trybu failover dla zarządzanego przez klienta to
manual. - Zarządzane przez firmę Microsoft — w przypadku awarii na szeroką skalę, która ma wpływ na region podstawowy, firma Microsoft inicjuje przejście w tryb failover wszystkich grup, na które mają wpływ zasady trybu failover skonfigurowane pod kątem zarządzania przez firmę Microsoft. Tryb failover zarządzany przez firmę Microsoft nie zostanie zainicjowany dla poszczególnych grup trybu failover ani podzbioru grup trybu failover w regionie. W przypadku korzystania z narzędzi wiersza polecenia, takich jak program PowerShell, interfejs wiersza polecenia platformy Azure lub interfejs API REST, wartość zasad trybu failover dla zarządzanego przez firmę Microsoft to
automatic.
Każda zasada trybu failover ma unikatowy zestaw przypadków użycia i odpowiednie oczekiwania dotyczące zakresu trybu failover i utraty danych, jak podsumowuje poniższa tabela:
| Zasady trybu failover | Zakres trybu failover | Przypadek użycia | Potencjalna utrata danych |
|---|---|---|---|
| Zarządzane przez klienta (Zalecane) |
Grupy trybu failover | Co najmniej jedna baza danych w grupach trybu failover ma wpływ na awarię i stanie się niedostępna. Możesz wybrać tryb failover. | Tak |
| Zarządzany przez firmę Microsoft | Wszystkie grupy trybu failover w regionie | Powszechna awaria w centrum danych, strefie dostępności lub regionie powoduje niedostępność baz danych, a zespół usługi Microsoft Azure SQL decyduje się na wyzwolenie wymuszonego przejścia w tryb failover. Użyj tej opcji tylko wtedy, gdy chcesz delegować odpowiedzialność za odzyskiwanie po awarii firmie Microsoft, a aplikacja jest odporna na cel czasu odzyskiwania (przestój) co najmniej jedną godzinę. |
Tak |
Zarządzane przez klienta
W rzadkich przypadkach wbudowana dostępność lub wysoka dostępność nie wystarczy, aby zapobiec awarii, a bazy danych w grupie trybu failover mogą być niedostępne przez czas, który nie jest akceptowalny dla umowy dotyczącej poziomu usług (SLA) aplikacji korzystających z baz danych. Bazy danych mogą być niedostępne z powodu zlokalizowanego problemu mającego wpływ tylko na kilka baz danych lub na poziomie centrum danych, strefy dostępności lub regionu. W każdym z tych przypadków, aby przywrócić ciągłość działalności biznesowej, możesz zainicjować wymuszone przejście w tryb failover.
Ustawienie zasad trybu failover na zarządzane przez klienta jest zdecydowanie zalecane, ponieważ zapewnia kontrolę nad tym, kiedy należy zainicjować tryb failover i przywrócić ciągłość działania. Możesz zainicjować tryb failover, gdy zauważysz nieoczekiwaną awarię, która ma wpływ na co najmniej jedną bazę danych w grupie trybu failover.
Zarządzany przez firmę Microsoft
W przypadku zasad trybu failover zarządzanego przez firmę Microsoft odpowiedzialność za odzyskiwanie po awarii jest delegowana do usługi Azure SQL. Aby usługa Azure SQL mogła zainicjować wymuszone przejście w tryb failover, muszą zostać spełnione następujące warunki:
- Awaria na poziomie centrum danych, strefy dostępności lub regionu spowodowana przez zdarzenie klęski żywiołowej, zmiany konfiguracji, błędy oprogramowania lub awarie składników sprzętowych i wiele baz danych w regionie ma wpływ.
- Okres prolongaty wygasł. Ze względu na to, że weryfikowanie skali i łagodzenie awarii zależy od działań człowieka, okres prolongaty nie może być ustawiony poniżej jednej godziny.
Po spełnieniu tych warunków usługa Azure SQL inicjuje wymuszone przełączenia w tryb failover dla wszystkich grup trybu failover w regionie, w którym ustawiono zasady trybu failover na zarządzane przez firmę Microsoft.
Ważne
Użyj zasad trybu failover zarządzanych przez klienta, aby przetestować i wdrożyć plan odzyskiwania po awarii. Nie należy polegać na zarządzanym przez firmę Microsoft trybie failover, który może być wykonywany tylko przez firmę Microsoft w ekstremalnych okolicznościach. Zarządzany przez firmę Microsoft tryb failover zostanie zainicjowany dla wszystkich grup trybu failover w regionie z zasadami trybu failover ustawionymi na zarządzane przez firmę Microsoft. Nie można zainicjować jej dla pojedynczej grupy trybu failover. Jeśli potrzebujesz możliwości selektywnego przejścia w tryb failover do grupy trybu failover, użyj zasad trybu failover zarządzanych przez klienta.
Ustaw zasady trybu failover na zarządzane przez firmę Microsoft tylko wtedy, gdy:
- Chcesz delegować odpowiedzialność za odzyskiwanie po awarii do usługi Azure SQL.
- Aplikacja jest odporna na niedostępność bazy danych przez co najmniej jedną godzinę.
- Dopuszczalne jest wyzwalanie wymuszonych przełączeń w tryb failover przez pewien czas po wygaśnięciu okresu prolongaty, ponieważ rzeczywisty czas wymuszonego przejścia w tryb failover może się znacznie różnić.
- Dopuszczalne jest, aby wszystkie bazy danych w grupie trybu failover przejdą w tryb failover, niezależnie od ich konfiguracji nadmiarowości strefy lub stanu dostępności. Mimo że bazy danych skonfigurowane na potrzeby nadmiarowości strefy są odporne na awarie strefowe i mogą nie mieć wpływu na awarię, nadal będą one przenoszone w tryb failover, jeśli są częścią grupy trybu failover z zasadami trybu failover zarządzanymi przez firmę Microsoft.
- Dopuszczalne jest wymuszanie pracy w trybie failover baz danych w grupie trybu failover bez uwzględnienia zależności aplikacji od innych usług lub składników platformy Azure używanych przez aplikację, co może spowodować obniżenie wydajności lub niedostępność aplikacji.
- Akceptowalne jest poniesienie nieznanej ilości danych, ponieważ dokładny czas wymuszonego przejścia w tryb failover nie może być kontrolowany i ignoruje stan synchronizacji pomocniczych baz danych.
- Wszystkie podstawowe i pomocnicze bazy danych w grupie trybu failover oraz wszystkie relacje replikacji geograficznej mają tę samą warstwę usługi, warstwę obliczeniową (aprowizowaną lub bezserwerową) i rozmiar obliczeniowy (jednostki DTU lub rdzenie wirtualne). Jeśli cel poziomu usług (SLO) wszystkich baz danych nie jest zgodny, zasady trybu failover zostaną ostatecznie zaktualizowane z zarządzanej przez firmę Microsoft do klienta zarządzanego przez usługę Azure SQL.
Po wyzwoleniu trybu failover przez firmę Microsoft wpis nazwy operacji trybu failover usługi Azure SQL w trybie failover zostanie dodany do dziennika aktywności usługi Azure Monitor. Wpis zawiera nazwę grupy trybu failover w obszarze Zasób, a zdarzenie zainicjowane przez program wyświetla jeden łącznik (-), aby wskazać, że tryb failover został zainicjowany przez firmę Microsoft. Te informacje można również znaleźć na stronie Dziennik aktywności nowego serwera podstawowego lub wystąpienia w witrynie Azure Portal.
Terminologia i możliwości
Grupa trybu failover (FOG)
Grupa trybu failover umożliwia wszystkim bazom danych użytkowników w wystąpieniu zarządzanym przełączanie w tryb failover jako jednostki do innego regionu świadczenia usługi Azure w przypadku niedostępności podstawowego wystąpienia zarządzanego z powodu awarii regionu podstawowego. Ponieważ grupy trybu failover dla usługi SQL Managed Instance zawierają wszystkie bazy danych użytkowników w wystąpieniu, na wystąpieniu można skonfigurować tylko jedną grupę trybu failover.
Ważne
Nazwa grupy trybu failover musi być unikatowa w skali globalnej w domenie
.database.windows.net.Podstawowe
Wystąpienie zarządzane hostujące podstawowe bazy danych w grupie trybu failover.
Podrzędny
Wystąpienie zarządzane, które hostuje pomocnicze bazy danych w grupie trybu failover. Pomocnicza nie może znajdować się w tym samym regionie świadczenia usługi Azure co podstawowy.
Ważne
Jeśli baza danych zawiera obiekty OLTP w pamięci, wystąpienie podstawowej i pomocniczej repliki geograficznej musi mieć pasujące warstwy usługi, ponieważ obiekty OLTP w pamięci znajdują się w pamięci. Niższa warstwa usługi w wystąpieniu repliki geograficznej może powodować problemy z brakiem pamięci. W takim przypadku replika pomocnicza może nie odzyskać bazy danych, powodując niedostępność pomocniczej bazy danych wraz z obiektami OLTP w pamięci na pomocniczym obszarze geograficznym. Z kolei może to spowodować niepowodzenie przejścia w tryb failover. Aby tego uniknąć, upewnij się, że warstwa usługi wystąpienia pomocniczego geograficznego jest zgodna z podstawową bazą danych. Uaktualnienia warstwy usług mogą być operacjami o rozmiarze danych i mogą zająć trochę czasu.
Tryb failover (brak utraty danych)
Tryb failover wykonuje pełną synchronizację danych między podstawowymi i pomocniczymi bazami danych, zanim pomocnicza przełączy się do roli podstawowej. Gwarantuje to brak utraty danych. Tryb failover jest możliwy tylko wtedy, gdy podstawowy jest dostępny. Tryb failover jest używany w następujących scenariuszach:
- Wykonywanie próbnego odzyskiwania po awarii w środowisku produkcyjnym, gdy utrata danych nie jest akceptowalna
- Przenoszenie obciążenia do innego regionu
- Zwróć obciążenie do regionu podstawowego po ograniczeniu awarii (powrót po awarii)
Wymuszone przejście w tryb failover (potencjalna utrata danych)
Wymuszone przejście w tryb failover natychmiast przełącza pomocniczą do roli podstawowej bez oczekiwania na propagację ostatnich zmian z podstawowej. Ta operacja może spowodować potencjalną utratę danych. Wymuszone przejście w tryb failover jest używane jako metoda odzyskiwania podczas awarii, gdy podstawowy nie jest dostępny. Gdy awaria zostanie złagodzone, stary serwer podstawowy zostanie automatycznie ponownie połączony i stanie się nowym pomocniczym. Można wykonać tryb failover w celu powrotu po awarii, zwracając repliki do ich oryginalnych ról podstawowych i pomocniczych.
Okres prolongaty z utratą danych
Ponieważ dane są replikowane do pomocniczej przy użyciu replikacji asynchronicznej, wymuszone przejście w tryb failover grup za pomocą zasad trybu failover zarządzanego przez firmę Microsoft może spowodować utratę danych. Zasady trybu failover można dostosować, aby odzwierciedlały tolerancję aplikacji na utratę danych. Konfigurując
GracePeriodWithDataLossHoursprogram , można kontrolować, jak długo usługa Azure SQL czeka przed zainicjowaniem wymuszonego przejścia w tryb failover, co może spowodować utratę danych.
Strefa DNS
Unikatowy identyfikator generowany automatycznie podczas tworzenia nowego wystąpienia zarządzanego SQL. Certyfikat z wieloma domenami (SAN) dla tego wystąpienia jest aprowizowany w celu uwierzytelniania połączeń klienta z dowolnym wystąpieniem w tej samej strefie DNS. Dwa wystąpienia zarządzane w tej samej grupie trybu failover muszą współużytkować strefę DNS.
Odbiornik odczytu/zapisu grupy trybu failover
Rekord CNAME dns wskazujący bieżący podstawowy. Jest on tworzony automatycznie po utworzeniu grupy trybu failover i umożliwia obciążenie odczytu i zapisu w sposób niewidoczny ponownie nawiąż połączenie z serwerem podstawowym, gdy podstawowe zmiany po przejściu w tryb failover. Po utworzeniu grupy trybu failover w wystąpieniu zarządzanym SQL rekord CNAME systemu DNS dla adresu URL odbiornika jest tworzony jako
<fog-name>.<zone_id>.database.windows.net.Odbiornik tylko do odczytu grupy trybu failover
Rekord CNAME dns wskazujący bieżący pomocniczy. Jest on tworzony automatycznie po utworzeniu grupy trybu failover i umożliwia obciążeniu SQL tylko do odczytu przezroczyste łączenie się z pomocniczym, gdy zmiany pomocnicze po przejściu w tryb failover. Po utworzeniu grupy trybu failover w wystąpieniu zarządzanym SQL rekord CNAME systemu DNS dla adresu URL odbiornika jest tworzony jako
<fog-name>.secondary.<zone_id>.database.windows.net. Domyślnie tryb failover odbiornika tylko do odczytu jest wyłączony, ponieważ gwarantuje, że wydajność podstawowego elementu podstawowego nie ma wpływu, gdy pomocnicza jest w trybie offline. Jednak oznacza to również, że sesje tylko do odczytu nie będą mogły nawiązać połączenia, dopóki pomocnicza nie zostanie odzyskana. Jeśli nie możesz tolerować przestojów dla sesji tylko do odczytu i może używać podstawowej zarówno dla ruchu tylko do odczytu, jak i odczytu i zapisu kosztem potencjalnego obniżenia wydajności podstawowego, możesz włączyć tryb failover dla odbiornika tylko do odczytu, konfigurującAllowReadOnlyFailoverToPrimarywłaściwość. W takim przypadku ruch tylko do odczytu jest automatycznie przekierowywany do lokalizacji podstawowej, jeśli pomocnicza nie jest dostępna.Uwaga
Właściwość
AllowReadOnlyFailoverToPrimaryma wpływ tylko wtedy, gdy zasady trybu failover zarządzanego przez firmę Microsoft są włączone i wymuszone przejście w tryb failover zostało wyzwolone. W takim przypadku, jeśli właściwość ma wartość True, nowy podstawowy będzie obsługiwać zarówno sesje odczytu i zapisu, jak i tylko do odczytu.
Architektura grupy trybu failover
Należy skonfigurować grupę trybu failover w wystąpieniu podstawowym i połączyć ją z wystąpieniem pomocniczym w innym regionie świadczenia usługi Azure. Wszystkie bazy danych użytkowników w wystąpieniu zostaną zreplikowane do wystąpienia pomocniczego. Systemowe bazy danych, takie jak master i msdb nie zostaną zreplikowane.
Na poniższym diagramie przedstawiono typową konfigurację aplikacji w chmurze geograficznie nadmiarowej przy użyciu wystąpienia zarządzanego i grupy trybu failover:
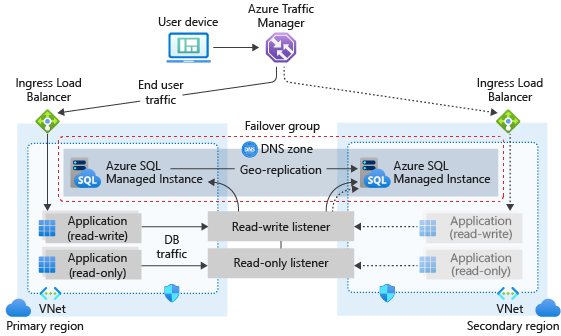
Jeśli aplikacja używa usługi SQL Managed Instance jako warstwy danych, postępuj zgodnie z ogólnymi wytycznymi i najlepszymi rozwiązaniami opisanymi w tym artykule podczas projektowania pod kątem ciągłości działania.
Tworzenie wystąpienia pomocniczego obszaru geograficznego
Aby zapewnić nie przerywaną łączność z podstawowym wystąpieniem zarządzanym SQL po przejściu w tryb failover, zarówno wystąpienia podstawowe, jak i pomocnicze muszą znajdować się w tej samej strefie DNS. Gwarantuje to, że ten sam certyfikat z wieloma domenami (SAN) może służyć do uwierzytelniania połączeń klientów z jednym z dwóch wystąpień w grupie trybu failover. Gdy aplikacja jest gotowa do wdrożenia produkcyjnego, utwórz pomocnicze wystąpienie zarządzane SQL w innym regionie i upewnij się, że współudzieli strefę DNS z podstawowym wystąpieniem zarządzanym SQL. Można to zrobić, określając opcjonalny parametr podczas tworzenia. Jeśli używasz programu PowerShell lub interfejsu API REST, nazwa opcjonalnego parametru to DNSZonePartner. Nazwa odpowiedniego opcjonalnego pola w witrynie Azure Portal to Podstawowe wystąpienie zarządzane.
Ważne
Pierwsze wystąpienie zarządzane utworzone w podsieci określa strefę DNS dla wszystkich kolejnych wystąpień w tej samej podsieci. Oznacza to, że dwa wystąpienia z tej samej podsieci nie mogą należeć do różnych stref DNS.
Aby uzyskać więcej informacji na temat tworzenia pomocniczego wystąpienia zarządzanego SQL w tej samej strefie DNS co wystąpienie podstawowe, zobacz Konfigurowanie grupy trybu failover dla usługi Azure SQL Managed Instance.
Korzystanie ze sparowanych regionów
Aby poprawić wydajność, wdróż oba wystąpienia zarządzane w sparowanych regionach. Grupy trybu failover usługi SQL Managed Instance w sparowanych regionach mają lepszą wydajność niż w niesparowanych regionach.
Usługa Azure SQL Managed Instance jest zgodna z praktyką bezpiecznego wdrażania, w której sparowane regiony platformy Azure zwykle nie są wdrażane w tym samym czasie. Nie można jednak przewidzieć, który region zostanie uaktualniony jako pierwszy, więc kolejność wdrożenia nie jest gwarantowana. Czasami wystąpienie podstawowe jest najpierw uaktualniane, a czasami wystąpienie pomocnicze jest najpierw uaktualniane.
W sytuacjach, gdy usługa Azure SQL Managed Instance jest częścią grupy trybu failover, a wystąpienia w grupie nie należą do sparowanych regionów platformy Azure, wybierz różne harmonogramy okien obsługi dla podstawowej i pomocniczej bazy danych. Na przykład wybierz okno obsługi dzień powszedni dla pomocniczej bazy danych geograficznej i okno obsługi weekendowej dla podstawowej bazy danych geograficznej.
Włączanie i optymalizowanie przepływu ruchu replikacji geograficznej między wystąpieniami
Łączność między podsieciami sieci wirtualnej hostująca wystąpienie podstawowe i pomocnicze należy ustanowić i utrzymywać w celu nieprzerwanego przepływu ruchu replikacji geograficznej. Istnieje wiele sposobów zapewnienia łączności między wystąpieniami, które można wybrać na podstawie topologii sieci i zasad:
Globalna komunikacja równorzędna sieci wirtualnych (komunikacja równorzędna sieci wirtualnych) to zalecany sposób nawiązywania łączności między dwoma wystąpieniami w grupie trybu failover. Zapewnia ona prywatne połączenie o niskim opóźnieniu i wysokiej przepustowości między równorzędnymi sieciami wirtualnymi, wykorzystujące infrastrukturę szkieletową firmy Microsoft. W komunikacji między równorzędnymi sieciami wirtualnymi nie jest wymagany żaden publiczny Internet, bramy ani dodatkowe szyfrowanie.
Wstępne rozmieszczanie
Podczas ustanawiania grupy trybu failover między wystąpieniami zarządzanymi istnieje początkowa faza rozmieszczania przed rozpoczęciem replikacji danych. Początkowa faza inicjowania jest najdłuższą i najdroższą częścią operacji. Po zakończeniu początkowego rozmieszczania dane są synchronizowane, a tylko kolejne zmiany danych są replikowane. Czas potrzebny na ukończenie początkowego rozmieszczania zależy od rozmiaru danych, liczby replikowanych baz danych, intensywności obciążenia w podstawowych bazach danych oraz szybkości połączenia między sieciami wirtualnymi hostujących wystąpienie podstawowe i pomocnicze, które w większości zależą od sposobu nawiązywania łączności. W normalnych okolicznościach i gdy łączność jest ustanawiana przy użyciu zalecanej globalnej komunikacji równorzędnej sieci wirtualnych, szybkość rozmieszczania wynosi do 360 GB za godzinę dla usługi SQL Managed Instance. Rozmieszczanie jest wykonywane równolegle dla partii baz danych użytkowników — niekoniecznie dla wszystkich baz danych w tym samym czasie. W przypadku wielu baz danych hostowanych w wystąpieniu może być potrzebnych wiele partii.
Jeśli szybkość połączenia między dwoma wystąpieniami jest wolniejsza niż to, co jest konieczne, czas inicjowania może być zauważalnie dotknięty. Możesz użyć podanej szybkości rozmieszczania, liczby baz danych, całkowitego rozmiaru danych i szybkości łącza, aby oszacować, jak długo początkowa faza rozmieszczania będzie trwać przed rozpoczęciem replikacji danych. Na przykład w przypadku pojedynczej bazy danych o pojemności 100 GB początkowa faza inicjowania zajęłaby około 1,2 godziny, jeśli link może wypchnąć 84 GB na godzinę, a jeśli nie ma żadnych innych baz danych, które są rozmieszczane. Jeśli link może przenieść tylko 10 GB na godzinę, rozmieszczanie bazy danych o pojemności 100 GB może potrwać około 10 godzin. Jeśli istnieje wiele baz danych do replikacji, rozmieszczanie zostanie wykonane równolegle, a w połączeniu z powolną szybkością połączenia początkowa faza rozmieszczania może trwać znacznie dłużej, zwłaszcza jeśli równoległe rozmieszczanie danych ze wszystkich baz danych przekracza dostępną przepustowość łącza.
Ważne
W przypadku bardzo małej szybkości lub połączenia zajętego, co powoduje, że początkowa faza rozmieszczania może zająć kilka dni, tworzenie grupy trybu failover może upłynął limit czasu. Proces tworzenia zostanie automatycznie anulowany po upływie 6 dni.
Zarządzanie trybem failover geograficznym w wystąpieniu pomocniczym geograficznym
Grupa trybu failover zarządza trybem geograficznym trybu failover wszystkich baz danych w podstawowym wystąpieniu zarządzanym. Po utworzeniu grupy każda baza danych w wystąpieniu zostanie automatycznie zreplikowana geograficznie do wystąpienia pomocniczego obszaru geograficznego. Nie można użyć grup trybu failover do zainicjowania częściowego trybu failover podzestawu baz danych.
Ważne
Jeśli baza danych zostanie porzucona w podstawowym wystąpieniu zarządzanym, zostanie również automatycznie porzucona w pomocniczym wystąpieniu zarządzanym geograficznie.
Korzystanie z odbiornika odczytu i zapisu (podstawowego wystąpienia zarządzanego)
W przypadku obciążeń odczytu i zapisu użyj <fog-name>.zone_id.database.windows.net jako nazwy serwera. Połączenia są automatycznie kierowane do serwera podstawowego. Ta nazwa nie zmienia się po przejściu w tryb failover. Przejście w tryb failover geograficznego obejmuje aktualizowanie rekordu DNS, więc nowe połączenia klienckie są kierowane do nowego podstawowego tylko po odświeżeniu pamięci podręcznej DNS klienta. Ponieważ wystąpienie pomocnicze współudzieli strefę DNS z serwerem podstawowym, aplikacja kliencka będzie mogła ponownie nawiązać z nią połączenie przy użyciu tego samego certyfikatu SIECI SAN po stronie serwera. Istniejące połączenia klienta muszą zostać przerwane, a następnie ponownie skierować je do nowego podstawowego. Odbiornik odczytu i zapisu i odbiornik tylko do odczytu nie można uzyskać dostępu za pośrednictwem publicznego punktu końcowego dla wystąpienia zarządzanego.
Używanie odbiornika tylko do odczytu (pomocnicze wystąpienie zarządzane)
Jeśli masz logicznie izolowane obciążenia tylko do odczytu, które są odporne na opóźnienia danych, możesz uruchomić je w pomocniczej lokalizacji geograficznej. Aby połączyć się bezpośrednio z pomocniczym obszarem geograficznym, użyj <fog-name>.secondary.<zone_id>.database.windows.net jako nazwy serwera.
W warstwie Krytyczne dla działania firmy usługa SQL Managed Instance obsługuje używanie replik tylko do odczytu do odciążania obciążeń zapytań tylko do odczytu przy użyciu parametru ApplicationIntent=ReadOnly w parametry połączenia. Po skonfigurowaniu pomocniczej replikacji geograficznej można użyć tej funkcji, aby nawiązać połączenie z repliką tylko do odczytu w lokalizacji podstawowej lub w lokalizacji replikowanej geograficznie:
- Aby nawiązać połączenie z repliką tylko do odczytu w lokalizacji podstawowej, użyj polecenia
ApplicationIntent=ReadOnlyi<fog-name>.<zone_id>.database.windows.net. - Aby nawiązać połączenie z repliką tylko do odczytu w lokalizacji pomocniczej, użyj polecenia
ApplicationIntent=ReadOnlyi<fog-name>.secondary.<zone_id>.database.windows.net.
Odbiornik odczytu i zapisu i odbiornik tylko do odczytu nie można uzyskać dostępu za pośrednictwem publicznego punktu końcowego dla wystąpienia zarządzanego.
Potencjalne obniżenie wydajności po przejściu w tryb failover
Typowa aplikacja systemu Azure korzysta z wielu usług platformy Azure i obejmuje wiele składników. Geograficzne przejście w tryb failover grupy jest wyzwalane na podstawie stanu samych składników usługi Azure SQL. Niedostępność aplikacji może nie mieć wpływu na inne usługi platformy Azure w regionie podstawowym, a ich składniki mogą nadal być dostępne w tym regionie. Po przełączeniu podstawowych baz danych do regionu pomocniczego opóźnienie między składnikami zależnych może wzrosnąć. Upewnij się, że nadmiarowość wszystkich składników aplikacji w regionie pomocniczym i składników aplikacji w trybie failover wraz z bazą danych, dzięki czemu wydajność aplikacji nie ma wpływu na większe opóźnienie między regionami.
Potencjalna utrata danych po wymuszonym przejściu w tryb failover
W przypadku wymuszonego przejścia w tryb failover aplikacji w regionie podstawowym ostatnie transakcje mogą nie zostać zreplikowane do pomocniczej lokalizacji geograficznej i może dojść do utraty danych.
Aktualizacja DNS
Aktualizacja DNS odbiornika odczytu i zapisu zostanie wykonana natychmiast po zainicjowaniu trybu failover. Ta operacja nie spowoduje utraty danych. Jednak proces przełączania ról bazy danych może potrwać do 5 minut w normalnych warunkach. Do momentu ukończenia niektóre bazy danych w nowym wystąpieniu podstawowym będą nadal tylko do odczytu. Jeśli tryb failover jest inicjowany przy użyciu programu PowerShell, operacja przełączania roli repliki podstawowej jest synchroniczna. Jeśli zainicjowano ją przy użyciu witryny Azure Portal, interfejs użytkownika wskazuje stan ukończenia. Jeśli jest inicjowany przy użyciu interfejsu API REST, użyj standardowego mechanizmu sondowania usługi Azure Resource Manager, aby monitorować ukończenie.
Ważne
Użyj ręcznego planowanego przejścia w tryb failover, aby przenieść element podstawowy z powrotem do oryginalnej lokalizacji po awarii, która spowodowała ograniczenie geograficznego trybu failover.
Oszczędzanie kosztów dzięki bezpłatnej licencji repliki odzyskiwania po awarii
Możesz zaoszczędzić na kosztach licencji programu SQL Server, konfigurując pomocnicze wystąpienie zarządzane do użycia tylko na potrzeby odzyskiwania po awarii. Aby to skonfigurować, zobacz Konfigurowanie repliki rezerwowej bez licencji dla usługi Azure SQL Managed Instance.
Jeśli wystąpienie pomocnicze nie jest używane w przypadku obciążeń do odczytu, firma Microsoft udostępnia bezpłatną liczbę rdzeni wirtualnych, aby dopasować je do wystąpienia podstawowego. Nadal są naliczane opłaty za zasoby obliczeniowe i magazyn używane przez wystąpienie pomocnicze. Grupy trybu failover obsługują tylko jedną replikę — replika musi być repliką do odczytu lub wyznaczoną jako replika tylko do odzyskiwania po awarii.
Włączanie scenariuszy zależnych od obiektów z systemowych baz danych
Systemowe bazy danych nie są replikowane do wystąpienia pomocniczego w grupie trybu failover. Aby włączyć scenariusze zależne od obiektów z systemowych baz danych, pamiętaj, aby utworzyć takie same obiekty w wystąpieniu pomocniczym i zachować ich synchronizację z wystąpieniem podstawowym.
Jeśli na przykład planujesz używać tych samych identyfikatorów logowania w wystąpieniu pomocniczym, pamiętaj, aby utworzyć je przy użyciu identycznego identyfikatora SID.
-- Code to create login on the secondary instance
CREATE LOGIN foo WITH PASSWORD = '<enterStrongPasswordHere>', SID = <login_sid>;
Aby dowiedzieć się więcej, zobacz temat Replication of logins and agent jobs (Replikacja identyfikatorów logowania i zadań agenta).
Synchronizowanie właściwości wystąpienia i wystąpień zasad przechowywania
Wystąpienia w grupie trybu failover pozostają oddzielnymi zasobami platformy Azure, a żadne zmiany konfiguracji wystąpienia podstawowego nie zostaną automatycznie zreplikowane do wystąpienia pomocniczego. Upewnij się, że wszystkie istotne zmiany są wykonywane zarówno w wystąpieniu podstawowym , jak i pomocniczym. Jeśli na przykład zmienisz nadmiarowość magazynu kopii zapasowych lub zasady długoterminowego przechowywania kopii zapasowych w wystąpieniu podstawowym, pamiętaj o zmianie go również w wystąpieniu pomocniczym.
Skalowanie wystąpień
Możesz skalować w górę lub skalować w dół wystąpienie podstawowe i pomocnicze do innego rozmiaru obliczeniowego w ramach tej samej warstwy usługi lub do innej warstwy usługi. Podczas skalowania w górę w tej samej warstwie usługi zalecamy najpierw skalowanie w górę pomocniczego obszaru geograficznego, a następnie skalowanie w górę podstawowego. Podczas skalowania w dół w ramach tej samej warstwy usługi należy odwrócić kolejność: najpierw przeskaluj w dół podstawową, a następnie przeprowadź skalowanie w dół pomocniczej. W przypadku wystąpienia skalowania do innej warstwy usługi to zalecenie jest wymuszane. Sekwencja operacji jest wymuszana podczas skalowania warstwy usługi i rdzeni wirtualnych, a także magazynu.
Ta sekwencja jest zalecana specjalnie po to, aby uniknąć problemu polegającego na tym, że geograficzne wystąpienie pomocnicze z niższym poziomem jednostki SKU zostaje przeciążone i musi zostać ponownie rozmieszczone podczas procesu podwyższania lub obniżania poziomu.
Ważne
- W przypadku wystąpień wewnątrz grupy trybu failover zmiana warstwy usługi na lub z niej nie jest obsługiwana w warstwie Ogólnego przeznaczenia następnej generacji. Najpierw należy usunąć grupę trybu failover przed zmodyfikowaną repliką, a następnie ponownie utworzyć grupę trybu failover po wprowadzeniu zmiany.
- Istnieje znany problem, który może mieć wpływ na dostępność wystąpienia skalowanego przy użyciu skojarzonego odbiornika grupy trybu failover.
Zapobieganie utracie krytycznych danych
Ze względu na duże opóźnienie sieci rozległe replikacja geograficzna używa mechanizmu replikacji asynchronicznej. Replikacja asynchroniczna sprawia, że utrata danych jest nieunikniona w przypadku awarii podstawowej. Aby chronić krytyczne transakcje przed utratą danych, deweloper aplikacji może wywołać procedurę składowaną sp_wait_for_database_copy_sync natychmiast po zatwierdzeniu transakcji. Wywołanie sp_wait_for_database_copy_sync blokuje wątek wywołujący do czasu przesyłania ostatniej zatwierdzonej transakcji i wzmacniania zabezpieczeń w dzienniku transakcji pomocniczej bazy danych. Jednak nie czeka na ponowne odtworzenie przesyłanych transakcji (redone) na pomocniczym. sp_wait_for_database_copy_sync jest ograniczona do określonego łącza replikacji geograficznej. Każdy użytkownik z prawami połączenia do podstawowej bazy danych może wywołać tę procedurę.
Aby zapobiec utracie danych podczas inicjowanego przez użytkownika, planowanego trybu failover geograficznego, replikacja automatycznie i tymczasowo zmienia się na replikację synchroniczną, a następnie wykonuje tryb failover. Następnie replikacja powraca do trybu asynchronicznego po zakończeniu trybu geograficznego trybu failover.
Uwaga
sp_wait_for_database_copy_sync zapobiega utracie danych po przejściu w tryb failover geograficznym dla określonych transakcji, ale nie gwarantuje pełnej synchronizacji w celu uzyskania dostępu do odczytu. Opóźnienie spowodowane sp_wait_for_database_copy_sync wywołaniem procedury może być znaczące i zależy od rozmiaru dziennika transakcji, który nie został jeszcze przesłany na serwerze podstawowym w momencie wywołania.
Stan grupy trybu failover
Grupa trybu failover zgłasza swój stan opisujący bieżący stan replikacji danych:
- Rozmieszczanie — początkowe rozmieszczanie odbywa się po utworzeniu grupy trybu failover, dopóki wszystkie bazy danych użytkowników nie zostaną zainicjowane w wystąpieniu pomocniczym. Nie można zainicjować procesu trybu failover, gdy grupa trybu failover znajduje się w stanie Rozmieszczanie, ponieważ bazy danych użytkowników nie są jeszcze kopiowane do wystąpienia pomocniczego.
- Synchronizowanie — zwykły stan grupy trybu failover. Oznacza to, że zmiany danych w wystąpieniu podstawowym są replikowane asynchronicznie do wystąpienia pomocniczego. Ten stan nie gwarantuje, że dane są w pełni synchronizowane w każdej chwili. Mogą istnieć zmiany danych z podstawowej nadal replikowane do pomocniczej ze względu na asynchroniczny charakter procesu replikacji między wystąpieniami w grupie trybu failover. Zarówno automatyczne, jak i ręczne przechodzenie w tryb failover można zainicjować, gdy grupa trybu failover znajduje się w stanie Synchronizowanie.
- Tryb failover w toku — ten stan wskazuje, że trwa proces automatycznego lub ręcznego inicjowania trybu failover. Nie można zainicjować żadnych zmian w grupie trybu failover lub dodatkowych trybów failover, gdy grupa trybu failover jest w tym stanie.
Powrót po awarii
Gdy grupy trybu failover są konfigurowane przy użyciu zasad trybu failover zarządzanego przez firmę Microsoft, wymuszone przejście w tryb failover na serwer pomocniczy geograficznie jest inicjowane w scenariuszu awarii zgodnie ze zdefiniowanym okresem prolongaty. Powrót po awarii do starego podstawowego elementu musi zostać zainicjowany ręcznie.
Współdziałanie funkcji
Kopie zapasowe
Pełna kopia zapasowa jest wykonywana w następujących scenariuszach:
- Przed rozpoczęciem początkowego rozmieszczania podczas tworzenia grupy trybu failover.
- Po przejściu w tryb failover.
Pełna kopia zapasowa to rozmiar operacji danych, których nie można pominąć ani odroczyć, i może zająć trochę czasu. Czas potrzebny do ukończenia zależy od rozmiaru danych, liczby baz danych i intensywności obciążenia podstawowych baz danych. Pełna kopia zapasowa może znacznie opóźnić wstępne rozmieszczanie i może opóźnić lub zapobiec operacji przejścia w tryb failover na nowym wystąpieniu wkrótce po przejściu w tryb failover.
Usługa Log Replay Service
Bazy danych migrowane do usługi Azure SQL Managed Instance przy użyciu usługi ponownego odtwarzania dziennika (LRS) nie można dodać do grupy trybu failover do momentu wykonania kroku migracji jednorazowej. Baza danych zmigrowana z magazynem LRS jest w stanie przywracania do momentu przejścia jednorazowego, a bazy danych w stanie przywracania nie mogą być dodawane do grupy trybu failover. Próba utworzenia grupy trybu failover z bazą danych w stanie przywracania opóźnia tworzenie grupy trybu failover do momentu zakończenia przywracania bazy danych.
Replikacja transakcyjna
Korzystanie z replikacji transakcyjnej z wystąpieniami w grupie trybu failover jest obsługiwane. Jeśli jednak skonfigurujesz replikację przed dodaniem wystąpienia zarządzanego SQL do grupy trybu failover, replikacja zostanie wstrzymana po rozpoczęciu tworzenia grupy trybu failover, a monitor replikacji wyświetli stan Replicated transactions are waiting for the next log backup or for mirroring partner to catch up. Replikacja zostanie wznowiona po pomyślnym utworzeniu grupy trybu failover.
Jeśli wydawca lub dystrybutor wystąpienie zarządzane SQL znajduje się w grupie trybu failover, administrator wystąpienia zarządzanego SQL musi wyczyścić wszystkie publikacje w starym podstawowym i ponownie skonfigurować je w nowym podstawowym po przejściu w tryb failover. Zapoznaj się z przewodnikiem replikacji transakcyjnej, aby zapoznać się z krokami działań, które są wymagane w tym scenariuszu.
Uprawnienia i ograniczenia
Przed skonfigurowaniem grupy trybu failover przejrzyj listę uprawnień i ograniczeń .
Programowe zarządzanie grupami trybu failover
Grupami trybu failover można również zarządzać programowo przy użyciu środowiska Azure PowerShell, interfejsu wiersza polecenia (CLI) platformy Azure i interfejsu API REST. Przejrzyj sekcję Konfigurowanie grupy trybu failover, aby dowiedzieć się więcej.
Próbne odzyskiwanie po awarii
Zalecanym sposobem wykonania próbnego odzyskiwania po awarii jest użycie ręcznego planowanego trybu failover zgodnie z następującym samouczkiem: Testowanie trybu failover.
Wykonanie ćwiczenia przy użyciu wymuszonego przejścia w tryb failover nie jest zalecane, ponieważ ta operacja nie zapewnia barier zabezpieczających przed utratą danych. Niemniej jednak możliwe jest osiągnięcie bezstratnej, wymuszonej pracy w trybie failover bez utraty danych, zapewniając spełnienie następujących warunków przed zainicjowanie wymuszonego przejścia w tryb failover:
- Obciążenie jest zatrzymywane w podstawowym wystąpieniu zarządzanym.
- Wszystkie długotrwałe transakcje zostały ukończone.
- Wszystkie połączenia klienta z podstawowym wystąpieniem zarządzanym zostały rozłączone.
- Stan grupy trybu failover to "Synchronizowanie".
Upewnij się, że dwa wystąpienia zarządzane mają przełączone role i że stan grupy trybu failover został przełączony z "Tryb failover w toku" na "Synchronizacja" przed opcjonalnym ustanawianiem połączeń z nowym podstawowym wystąpieniem zarządzanym i uruchamianiem obciążenia odczytu i zapisu.
Aby wykonać bezstratny powrót po awarii danych do oryginalnych ról wystąpienia zarządzanego, zdecydowanie zaleca się użycie ręcznego planowanego trybu failover zamiast wymuszonego przejścia w tryb failover. Aby kontynuować powrót po awarii wymuszonej:
- Wykonaj te same kroki co w przypadku bezstratnej pracy w trybie failover danych.
- Dłuższy czas wykonywania powrotu po awarii jest oczekiwany, jeśli wymuszony powrót po awarii zostanie wykonany wkrótce po zakończeniu wymuszonego przejścia w tryb failover, ponieważ musi czekać na ukończenie zaległych operacji automatycznego tworzenia kopii zapasowej w byłym podstawowym wystąpieniu zarządzanym.
Powiązana zawartość
- Konfigurowanie grupy trybu failover
- Dodawanie wystąpienia zarządzanego do grupy trybu failover przy użyciu programu PowerShell
- Konfigurowanie bezpłatnej licencji repliki rezerwowej dla usługi Azure SQL Managed Instance
- Omówienie zagadnień dotyczących ciągłości działalności biznesowej zapewnianej przez usługę Azure SQL Managed Instance
- Automatyczne kopie zapasowe w usłudze Azure SQL Managed Instance
- Przywracanie bazy danych z kopii zapasowej w usłudze Azure SQL Managed Instance