Monitorowanie wydajności przy użyciu dynamicznych widoków zarządzania
Dotyczy: ![]() Baza danych SQL Usługi Azure SQL Database
Baza danych SQL Usługi Azure SQL Database ![]() w sieci szkieletowej
w sieci szkieletowej
Dynamiczne widoki zarządzania (DMV) umożliwiają monitorowanie wydajności obciążeń i diagnozowanie problemów z wydajnością, które mogą być spowodowane przez zablokowane lub długotrwałe zapytania, wąskie gardła zasobów, nieoptymalne plany zapytań i nie tylko.
Ten artykuł zawiera informacje na temat wykrywania typowych problemów z wydajnością przez wykonywanie zapytań dotyczących dynamicznych widoków zarządzania za pośrednictwem języka T-SQL. Możesz użyć dowolnego narzędzia do wykonywania zapytań, takiego jak:
Uprawnienia
W usłudze Azure SQL Database w zależności od rozmiaru obliczeniowego, opcji wdrożenia i danych w widoku DMV wykonywanie zapytań dotyczących widoku DMV może wymagać VIEW DATABASE STATEuprawnień lub VIEW SERVER PERFORMANCE STATEVIEW SERVER SECURITY STATE . Ostatnie dwa uprawnienia są uwzględnione w uprawnieniach VIEW SERVER STATE . Uprawnienia do wyświetlania stanu serwera są przyznawane za pośrednictwem członkostwa w odpowiednich rolach serwera. Aby określić, które uprawnienia są wymagane do wykonywania zapytań dotyczących określonego dynamicznego widoku zarządzania, zobacz Dynamiczne widoki zarządzania i znajdź artykuł opisujący dynamiczny widok zarządzania.
Aby udzielić uprawnienia użytkownikowi VIEW DATABASE STATE bazy danych, uruchom następujące zapytanie, zastępując database_user ciąg nazwą podmiotu zabezpieczeń użytkownika w bazie danych:
GRANT VIEW DATABASE STATE TO [database_user];
Aby udzielić członkostwa w ##MS_ServerStateReader## roli serwera do nazwy logowania o nazwie login_name na serwerze logicznym, połącz się z master bazą danych, a następnie uruchom następujące zapytanie jako przykład:
ALTER SERVER ROLE [##MS_ServerStateReader##] ADD MEMBER [login_name];
Zastosowanie udzielenia uprawnień może potrwać kilka minut. Aby uzyskać więcej informacji, zobacz Ograniczenia ról na poziomie serwera.
Monitorowanie użycia zasobów
Użycie zasobów można monitorować na poziomie bazy danych przy użyciu następujących widoków. Te widoki mają zastosowanie do autonomicznych baz danych i baz danych w elastycznej puli.
Użycie zasobów można monitorować na poziomie elastycznej puli przy użyciu następujących widoków:
Użycie zasobów można monitorować na poziomie zapytania przy użyciu szczegółowych informacji o wydajności zapytań usługi SQL Database w witrynie Azure Portal lub za pośrednictwem magazynu zapytań.
sys.dm_db_resource_stats
Widok sys.dm_db_resource_stats można używać w każdej bazie danych. Widok sys.dm_db_resource_stats pokazuje ostatnie dane użycia zasobów w stosunku do limitów rozmiaru obliczeniowego. Procent użycia procesora CPU, operacji we/wy danych, zapisów dzienników, wątków procesów roboczych i użycia pamięci w kierunku limitu są rejestrowane dla każdego 15-sekundowego interwału i są utrzymywane przez około jedną godzinę.
Ponieważ ten widok zawiera szczegółowe dane użycia zasobów, należy najpierw użyć sys.dm_db_resource_stats funkcji analizy bieżącego stanu lub rozwiązywania problemów. Na przykład to zapytanie pokazuje średnie i maksymalne użycie zasobów dla bieżącej bazy danych w ciągu ostatniej godziny:
SELECT
database_name = DB_NAME(),
AVG(avg_cpu_percent) AS 'Average CPU use in percent',
MAX(avg_cpu_percent) AS 'Maximum CPU use in percent',
AVG(avg_data_io_percent) AS 'Average data IO in percent',
MAX(avg_data_io_percent) AS 'Maximum data IO in percent',
AVG(avg_log_write_percent) AS 'Average log write use in percent',
MAX(avg_log_write_percent) AS 'Maximum log write use in percent',
AVG(avg_memory_usage_percent) AS 'Average memory use in percent',
MAX(avg_memory_usage_percent) AS 'Maximum memory use in percent',
MAX(max_worker_percent) AS 'Maximum worker use in percent'
FROM sys.dm_db_resource_stats
Inne zapytania można znaleźć w przykładach w sys.dm_db_resource_stats.
sys.resource_stats
Widok sys.resource_stats w master bazie danych zawiera dodatkowe informacje, które mogą ułatwić monitorowanie wydajności bazy danych w określonej warstwie usługi i rozmiarze obliczeniowym. Dane są zbierane co 5 minut i są przechowywane przez około 14 dni. Ten widok jest przydatny w przypadku długoterminowej analizy historycznej sposobu, w jaki baza danych korzysta z zasobów.
Na poniższym wykresie przedstawiono użycie zasobów procesora CPU dla bazy danych Premium z rozmiarem obliczeniowym P2 dla każdej godziny w tygodniu. Ten wykres rozpoczyna się w poniedziałek, pokazuje pięć dni roboczych, a następnie pokazuje weekend, gdy w aplikacji dzieje się znacznie mniej.
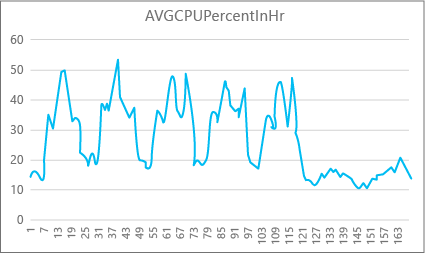
Z danych ta baza danych ma obecnie szczytowe obciążenie procesora CPU nieco ponad 50 procent użycia względem rozmiaru obliczeniowego P2 (w południe we wtorek). Jeśli procesor CPU jest dominującym czynnikiem w profilu zasobu aplikacji, możesz zdecydować, że P2 jest odpowiednim rozmiarem obliczeniowym, aby zagwarantować, że obciążenie zawsze pasuje. Jeśli spodziewasz się, że aplikacja wzrośnie wraz z upływem czasu, dobrym pomysłem jest posiadanie dodatkowego buforu zasobów, aby aplikacja nigdy nie osiągnęła limitu poziomu wydajności. Jeśli zwiększysz rozmiar obliczeniowy, możesz uniknąć widocznych przez klienta błędów, które mogą wystąpić, gdy baza danych nie ma wystarczającej mocy do efektywnego przetwarzania żądań, szczególnie w środowiskach wrażliwych na opóźnienia.
W przypadku innych typów aplikacji można interpretować ten sam graf inaczej. Jeśli na przykład aplikacja próbuje przetwarzać dane listy płac każdego dnia i ma ten sam wykres, ten rodzaj modelu "zadania wsadowego" może być odpowiedni w przypadku rozmiaru obliczeniowego P1. Rozmiar obliczeniowy P1 ma 100 jednostek DTU w porównaniu z 200 jednostkami DTU w rozmiarze obliczeniowym P2. Rozmiar obliczeniowy P1 zapewnia połowę wydajności rozmiaru obliczeniowego P2. Dlatego 50 procent użycia procesora CPU w P2 jest równe 100 procent użycia procesora w P1. Jeśli aplikacja nie ma limitów czasu, może nie mieć znaczenia, czy zadanie trwa 2 godziny lub 2,5 godziny, jeśli zostanie wykonane dzisiaj. Aplikacja w tej kategorii prawdopodobnie może używać rozmiaru obliczeniowego P1. Możesz skorzystać z faktu, że istnieją okresy czasu w ciągu dnia, gdy użycie zasobów jest niższe, dzięki czemu każdy "duży szczyt" może rozlać się do jednego z korytów w późniejszym terminie. Rozmiar obliczeniowy P1 może być odpowiedni dla tego rodzaju aplikacji (i zaoszczędzić pieniądze), o ile zadania mogą być wykonywane codziennie.
Aparat bazy danych uwidacznia informacje o zużytych zasobach dla każdej aktywnej master bazy danych w sys.resource_stats widoku bazy danych na każdym serwerze logicznym. Dane w widoku są agregowane przez 5-minutowe interwały. Wyświetlenie tych danych w tabeli może potrwać kilka minut, więc sys.resource_stats jest bardziej przydatne w przypadku analizy historycznej, a nie analizy niemal w czasie rzeczywistym. sys.resource_stats Wykonaj zapytanie względem widoku, aby wyświetlić najnowszą historię bazy danych i sprawdzić, czy wybrany rozmiar obliczeniowy dostarczył odpowiednią wydajność w razie potrzeby.
Uwaga
Aby wykonać zapytanie sys.resource_stats w poniższych przykładach, musisz mieć połączenie z bazą master danych.
W tym przykładzie przedstawiono dane w pliku sys.resource_stats:
SELECT TOP 10 *
FROM sys.resource_stats
WHERE database_name = 'userdb1'
ORDER BY start_time DESC;
W następnym przykładzie przedstawiono różne sposoby używania sys.resource_stats widoku wykazu w celu uzyskania informacji o sposobie korzystania z zasobów bazy danych:
Aby zapoznać się z użyciem zasobu z ostatniego tygodnia dla bazy danych
userdb1użytkownika , możesz uruchomić to zapytanie, zastępując własną nazwę bazy danych:SELECT * FROM sys.resource_stats WHERE database_name = 'userdb1' AND start_time > DATEADD(day, -7, GETDATE()) ORDER BY start_time DESC;Aby ocenić, jak dobrze obciążenie pasuje do rozmiaru obliczeniowego, należy przejść do szczegółów poszczególnych aspektów metryk zasobów: procesora CPU, operacji we/wy danych, zapisu dziennika, liczby procesów roboczych i liczby sesji. Poniżej przedstawiono poprawione zapytanie używane do
sys.resource_statsraportowania średnich i maksymalnych wartości tych metryk zasobów dla każdego rozmiaru obliczeniowego, dla których aprowizowano bazę danych:SELECT rs.database_name , rs.sku , storage_mb = MAX(rs.storage_in_megabytes) , 'Average CPU Utilization In %' = AVG(rs.avg_cpu_percent) , 'Maximum CPU Utilization In %' = MAX(rs.avg_cpu_percent) , 'Average Data IO In %' = AVG(rs.avg_data_io_percent) , 'Maximum Data IO In %' = MAX(rs.avg_data_io_percent) , 'Average Log Write Utilization In %' = AVG(rs.avg_log_write_percent) , 'Maximum Log Write Utilization In %' = MAX(rs.avg_log_write_percent) , 'Maximum Requests In %' = MAX(rs.max_worker_percent) , 'Maximum Sessions In %' = MAX(rs.max_session_percent) FROM sys.resource_stats AS rs WHERE rs.database_name = 'userdb1' AND rs.start_time > DATEADD(day, -7, GETDATE()) GROUP BY rs.database_name, rs.sku;Dzięki tym informacjom o średnich i maksymalnych wartościach każdej metryki zasobów możesz ocenić, jak dobrze obciążenie pasuje do wybranego rozmiaru obliczeniowego. Zazwyczaj średnie wartości z
sys.resource_statsdają dobrą linię bazową do użycia względem rozmiaru docelowego.W przypadku baz danych modelu zakupów jednostek DTU:
Na przykład możesz użyć warstwy usługi Standardowa z rozmiarem obliczeniowym S2. Średnie wartości procentowe użycia dla operacji odczytu i operacji we/wy procesora CPU i operacji we/wy są poniżej 40 procent, średnia liczba procesów roboczych jest niższa niż 50, a średnia liczba sesji jest niższa niż 200. Obciążenie może mieścić się w rozmiarze obliczeniowym S1. Łatwo sprawdzić, czy baza danych pasuje do limitów procesów roboczych i sesji. Aby sprawdzić, czy baza danych mieści się w niższym rozmiarze obliczeniowym, podziel liczbę jednostek DTU mniejszego rozmiaru obliczeniowego na liczbę jednostek DTU bieżącego rozmiaru obliczeniowego, a następnie pomnoż wynik o 100:
S1 DTU / S2 DTU * 100 = 20 / 50 * 100 = 40Wynikiem jest względna różnica wydajności między dwoma rozmiarami obliczeniowymi w procentach. Jeśli użycie zasobu nie przekracza tej wartości procentowej, obciążenie może mieścić się w niższym rozmiarze obliczeniowym. Należy jednak przyjrzeć się wszystkim zakresom wartości użycia zasobów i określić, według wartości procentowych, jak często obciążenie bazy danych mieści się w niższym rozmiarze obliczeniowym. Następujące zapytanie zwraca wartość procentową dopasowania na wymiar zasobu na podstawie progu wynoszącego 40 procent obliczonego w tym przykładzie:
SELECT database_name, 100*((COUNT(database_name) - SUM(CASE WHEN avg_cpu_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'CPU Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_log_write_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Log Write Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_data_io_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Physical Data IO Fit Percent' FROM sys.resource_stats WHERE start_time > DATEADD(day, -7, GETDATE()) AND database_name = 'sample' --remove to see all databases GROUP BY database_name;Na podstawie warstwy usługi bazy danych możesz zdecydować, czy obciążenie mieści się w niższym rozmiarze obliczeniowym. Jeśli cel obciążenia bazy danych wynosi 99,9 procent, a poprzednie zapytanie zwraca wartości większe niż 99,9 procent dla wszystkich trzech wymiarów zasobów, obciążenie prawdopodobnie mieści się w niższym rozmiarze obliczeniowym.
Zapoznanie się z wartością procentową dopasowania daje również wgląd w to, czy należy przejść do następnego wyższego rozmiaru obliczeniowego w celu osiągnięcia celu. Na przykład użycie procesora CPU dla przykładowej bazy danych w ciągu ostatniego tygodnia:
Średni procent procesora CPU Maksymalny procent procesora CPU 24.5 100.00 Średni procesor CPU wynosi około jednej czwartej limitu rozmiaru obliczeniowego, co dobrze pasuje do rozmiaru obliczeniowego bazy danych.
W przypadku modelu zakupów jednostek DTU i baz danych modelu zakupów rdzeni wirtualnych:
Maksymalna wartość pokazuje, że baza danych osiąga limit rozmiaru obliczeniowego. Czy musisz przejść do następnego wyższego rozmiaru obliczeniowego? Sprawdź, ile razy obciążenie osiągnie 100 procent, a następnie porównaj je z celem obciążenia bazy danych.
SELECT database_name, 100*((COUNT(database_name) - SUM(CASE WHEN avg_cpu_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'CPU Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_log_write_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Log Write Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_data_io_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Physical Data IO Fit Percent' FROM sys.resource_stats WHERE start_time > DATEADD(day, -7, GETDATE()) AND database_name = 'sample' --remove to see all databases GROUP BY database_name;Te wartości procentowe to liczba próbek, które można dopasować do obciążenia w bieżącym rozmiarze obliczeniowym. Jeśli to zapytanie zwróci wartość mniejszą niż 99,9 procent dla dowolnego z trzech wymiarów zasobów, średnie obciążenie próbki przekroczyło limity. Rozważ przejście do następnego wyższego rozmiaru obliczeniowego lub użycie technik dostrajania aplikacji w celu zmniejszenia obciążenia bazy danych.
sys.dm_elastic_pool_resource_stats
Dotyczy:![]() tylko usługa Azure SQL Database
tylko usługa Azure SQL Database
Podobnie jak sys.dm_db_resource_statsw przypadku programu sys.dm_elastic_pool_resource_stats udostępnia najnowsze i szczegółowe dane użycia zasobów dla elastycznej puli usługi Azure SQL Database. Widok można odpytować w dowolnej bazie danych w elastycznej puli, aby zapewnić dane użycia zasobów dla całej puli, a nie każdą konkretną bazę danych. Wartości procentowe zgłaszane przez ten dynamiczny widok zarządzania są w kierunku limitów puli elastycznej, które mogą być wyższe niż limity dla bazy danych w puli.
W tym przykładzie przedstawiono podsumowane dane użycia zasobów dla bieżącej elastycznej puli w ciągu ostatnich 15 minut:
SELECT dso.elastic_pool_name,
AVG(eprs.avg_cpu_percent) AS avg_cpu_percent,
MAX(eprs.avg_cpu_percent) AS max_cpu_percent,
AVG(eprs.avg_data_io_percent) AS avg_data_io_percent,
MAX(eprs.avg_data_io_percent) AS max_data_io_percent,
AVG(eprs.avg_log_write_percent) AS avg_log_write_percent,
MAX(eprs.avg_log_write_percent) AS max_log_write_percent,
MAX(eprs.max_worker_percent) AS max_worker_percent,
MAX(eprs.used_storage_percent) AS max_used_storage_percent,
MAX(eprs.allocated_storage_percent) AS max_allocated_storage_percent
FROM sys.dm_elastic_pool_resource_stats AS eprs
CROSS JOIN sys.database_service_objectives AS dso
WHERE eprs.end_time >= DATEADD(minute, -15, GETUTCDATE())
GROUP BY dso.elastic_pool_name;
Jeśli okaże się, że każde użycie zasobów zbliża się do 100% przez dłuższy czas, może być konieczne przejrzenie użycia zasobów dla poszczególnych baz danych w tej samej elastycznej puli, aby określić, ile każda baza danych przyczynia się do użycia zasobów na poziomie puli.
sys.elastic_pool_resource_stats
Dotyczy:![]() tylko usługa Azure SQL Database
tylko usługa Azure SQL Database
Podobnie jak sys.resource_statsprogram , sys.elastic_pool_resource_stats w master bazie danych udostępnia historyczne dane użycia zasobów dla wszystkich pul elastycznych na serwerze logicznym. Do monitorowania historycznego w ciągu ostatnich 14 dni, w tym analizy trendu użycia, można użyć sys.elastic_pool_resource_stats funkcji monitorowania historycznego.
W tym przykładzie przedstawiono podsumowane dane użycia zasobów w ciągu ostatnich siedmiu dni dla wszystkich pul elastycznych na bieżącym serwerze logicznym. Wykonaj zapytanie w master bazie danych.
SELECT elastic_pool_name,
AVG(avg_cpu_percent) AS avg_cpu_percent,
MAX(avg_cpu_percent) AS max_cpu_percent,
AVG(avg_data_io_percent) AS avg_data_io_percent,
MAX(avg_data_io_percent) AS max_data_io_percent,
AVG(avg_log_write_percent) AS avg_log_write_percent,
MAX(avg_log_write_percent) AS max_log_write_percent,
MAX(max_worker_percent) AS max_worker_percent,
AVG(avg_storage_percent) AS avg_used_storage_percent,
MAX(avg_storage_percent) AS max_used_storage_percent,
AVG(avg_allocated_storage_percent) AS avg_allocated_storage_percent,
MAX(avg_allocated_storage_percent) AS max_allocated_storage_percent
FROM sys.elastic_pool_resource_stats
WHERE start_time >= DATEADD(day, -7, GETUTCDATE())
GROUP BY elastic_pool_name
ORDER BY elastic_pool_name ASC;
Żądania współbieżne
Aby wyświetlić bieżącą liczbę współbieżnych żądań, uruchom to zapytanie w bazie danych użytkownika:
SELECT COUNT(*) AS [Concurrent_Requests]
FROM sys.dm_exec_requests;
Jest to tylko migawka w jednym punkcie w czasie. Aby lepiej zrozumieć wymagania dotyczące obciążenia i żądań współbieżnych, należy zebrać wiele przykładów w czasie.
Średnia szybkość żądań
W tym przykładzie pokazano, jak znaleźć średni współczynnik żądań dla bazy danych lub baz danych w elastycznej puli w danym okresie. W tym przykładzie okres jest ustawiony na 30 sekund. Można ją dostosować, modyfikując instrukcję WAITFOR DELAY . Wykonaj to zapytanie w bazie danych użytkownika. Jeśli baza danych znajduje się w elastycznej puli i jeśli masz wystarczające uprawnienia, wyniki obejmują inne bazy danych w elastycznej puli.
DECLARE @DbRequestSnapshot TABLE (
database_name sysname PRIMARY KEY,
total_request_count bigint NOT NULL,
snapshot_time datetime2 NOT NULL DEFAULT (SYSDATETIME())
);
INSERT INTO @DbRequestSnapshot
(
database_name,
total_request_count
)
SELECT rg.database_name,
wg.total_request_count
FROM sys.dm_resource_governor_workload_groups AS wg
INNER JOIN sys.dm_user_db_resource_governance AS rg
ON wg.name = CONCAT('UserPrimaryGroup.DBId', rg.database_id);
WAITFOR DELAY '00:00:30';
SELECT rg.database_name,
(wg.total_request_count - drs.total_request_count) / DATEDIFF(second, drs.snapshot_time, SYSDATETIME()) AS requests_per_second
FROM sys.dm_resource_governor_workload_groups AS wg
INNER JOIN sys.dm_user_db_resource_governance AS rg
ON wg.name = CONCAT('UserPrimaryGroup.DBId', rg.database_id)
INNER JOIN @DbRequestSnapshot AS drs
ON rg.database_name = drs.database_name;
Bieżące sesje
Aby wyświetlić liczbę bieżących aktywnych sesji, uruchom to zapytanie w bazie danych:
SELECT COUNT(*) AS [Sessions]
FROM sys.dm_exec_sessions
WHERE is_user_process = 1;
To zapytanie zwraca liczbę punktów w czasie. Jeśli z czasem zbierzesz wiele przykładów, będziesz mieć najlepszą wiedzę na temat użycia sesji.
Najnowsza historia żądań, sesji i procesów roboczych
Ten przykład zwraca ostatnie historyczne użycie żądań, sesji i wątków procesów roboczych dla bazy danych lub baz danych w elastycznej puli. Każdy wiersz reprezentuje migawkę użycia zasobów w danym momencie dla bazy danych. Kolumna requests_per_second jest średnią szybkością żądań w przedziale czasu kończącym się na .snapshot_time Jeśli baza danych znajduje się w elastycznej puli i jeśli masz wystarczające uprawnienia, wyniki obejmują inne bazy danych w elastycznej puli.
SELECT rg.database_name,
wg.snapshot_time,
wg.active_request_count,
wg.active_worker_count,
wg.active_session_count,
CAST(wg.delta_request_count AS decimal) / duration_ms * 1000 AS requests_per_second
FROM sys.dm_resource_governor_workload_groups_history_ex AS wg
INNER JOIN sys.dm_user_db_resource_governance AS rg
ON wg.name = CONCAT('UserPrimaryGroup.DBId', rg.database_id)
ORDER BY snapshot_time DESC;
Obliczanie rozmiarów baz danych i obiektów
Następujące zapytanie zwraca rozmiar danych w bazie danych (w megabajtach):
-- Calculates the size of the database.
SELECT SUM(CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8192.) / 1024 / 1024 AS size_mb
FROM sys.database_files
WHERE type_desc = 'ROWS';
Następujące zapytanie zwraca rozmiar pojedynczych obiektów (w megabajtach) w bazie danych:
-- Calculates the size of individual database objects.
SELECT o.name, SUM(ps.reserved_page_count) * 8.0 / 1024 AS size_mb
FROM sys.dm_db_partition_stats AS ps
INNER JOIN sys.objects AS o
ON ps.object_id = o.object_id
GROUP BY o.name
ORDER BY size_mb DESC;
Identyfikowanie problemów z wydajnością procesora CPU
Ta sekcja ułatwia identyfikowanie poszczególnych zapytań, które są głównymi użytkownikami procesora CPU.
Jeśli użycie procesora CPU przekracza 80% przez dłuższy czas, rozważ następujące kroki rozwiązywania problemów, czy problem z procesorem CPU występuje teraz , czy wystąpił w przeszłości. Możesz również wykonać kroki opisane w tej sekcji, aby aktywnie identyfikować zapytania zużywające najwięcej procesora CPU i dostroić je. W niektórych przypadkach zmniejszenie użycia procesora CPU może pozwolić na skalowanie baz danych i elastycznych pul oraz obniżenie kosztów.
Kroki rozwiązywania problemów są takie same w przypadku autonomicznych baz danych i baz danych w elastycznej puli. Wykonaj wszystkie zapytania w bazie danych użytkownika.
Problem z procesorem CPU występuje teraz
Jeśli problem występuje teraz, istnieją dwa możliwe scenariusze:
Wiele pojedynczych zapytań, które zbiorczo zużywają wysokie użycie procesora CPU
Użyj następującego zapytania, aby zidentyfikować najważniejsze zapytania według skrótu zapytania:
PRINT '-- top 10 Active CPU Consuming Queries (aggregated)--';
SELECT TOP 10 GETDATE() runtime, *
FROM (SELECT query_stats.query_hash, SUM(query_stats.cpu_time) 'Total_Request_Cpu_Time_Ms', SUM(logical_reads) 'Total_Request_Logical_Reads', MIN(start_time) 'Earliest_Request_start_Time', COUNT(*) 'Number_Of_Requests', SUBSTRING(REPLACE(REPLACE(MIN(query_stats.statement_text), CHAR(10), ' '), CHAR(13), ' '), 1, 256) AS "Statement_Text"
FROM (SELECT req.*, SUBSTRING(ST.text, (req.statement_start_offset / 2)+1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text)ELSE req.statement_end_offset END-req.statement_start_offset)/ 2)+1) AS statement_text
FROM sys.dm_exec_requests AS req
CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST ) AS query_stats
GROUP BY query_hash) AS t
ORDER BY Total_Request_Cpu_Time_Ms DESC;
Długotrwałe zapytania, które zużywają procesor CPU, są nadal uruchomione
Użyj następującego zapytania, aby zidentyfikować te zapytania:
PRINT '--top 10 Active CPU Consuming Queries by sessions--';
SELECT TOP 10 req.session_id, req.start_time, cpu_time 'cpu_time_ms', OBJECT_NAME(ST.objectid, ST.dbid) 'ObjectName', SUBSTRING(REPLACE(REPLACE(SUBSTRING(ST.text, (req.statement_start_offset / 2)+1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text)ELSE req.statement_end_offset END-req.statement_start_offset)/ 2)+1), CHAR(10), ' '), CHAR(13), ' '), 1, 512) AS statement_text
FROM sys.dm_exec_requests AS req
CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST
ORDER BY cpu_time DESC;
GO
Problem z procesorem CPU wystąpił w przeszłości
Jeśli problem wystąpił w przeszłości i chcesz przeprowadzić analizę głównej przyczyny, użyj magazynu zapytań. Użytkownicy z dostępem do bazy danych mogą używać języka T-SQL do wykonywania zapytań dotyczących danych magazynu zapytań. Domyślnie magazyn zapytań przechwytuje zagregowane statystyki zapytań dla interwałów jednogodzinnych.
Użyj następującego zapytania, aby przyjrzeć się aktywności w przypadku zapytań zużywających wysokie użycie procesora CPU. To zapytanie zwraca 15 najważniejszych zapytań zużywających procesor CPU. Pamiętaj, aby zmienić okres
rsi.start_time >= DATEADD(hour, -2, GETUTCDATE()na inny niż ostatnie dwie godziny:-- Top 15 CPU consuming queries by query hash -- Note that a query hash can have many query ids if not parameterized or not parameterized properly WITH AggregatedCPU AS ( SELECT q.query_hash ,SUM(count_executions * avg_cpu_time / 1000.0) AS total_cpu_ms ,SUM(count_executions * avg_cpu_time / 1000.0) / SUM(count_executions) AS avg_cpu_ms ,MAX(rs.max_cpu_time / 1000.00) AS max_cpu_ms ,MAX(max_logical_io_reads) max_logical_reads ,COUNT(DISTINCT p.plan_id) AS number_of_distinct_plans ,COUNT(DISTINCT p.query_id) AS number_of_distinct_query_ids ,SUM(CASE WHEN rs.execution_type_desc = 'Aborted' THEN count_executions ELSE 0 END) AS Aborted_Execution_Count ,SUM(CASE WHEN rs.execution_type_desc = 'Regular' THEN count_executions ELSE 0 END) AS Regular_Execution_Count ,SUM(CASE WHEN rs.execution_type_desc = 'Exception' THEN count_executions ELSE 0 END) AS Exception_Execution_Count ,SUM(count_executions) AS total_executions ,MIN(qt.query_sql_text) AS sampled_query_text FROM sys.query_store_query_text AS qt INNER JOIN sys.query_store_query AS q ON qt.query_text_id = q.query_text_id INNER JOIN sys.query_store_plan AS p ON q.query_id = p.query_id INNER JOIN sys.query_store_runtime_stats AS rs ON rs.plan_id = p.plan_id INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id = rs.runtime_stats_interval_id WHERE rs.execution_type_desc IN ('Regular','Aborted','Exception') AND rsi.start_time >= DATEADD(HOUR, - 2, GETUTCDATE()) GROUP BY q.query_hash ) ,OrderedCPU AS ( SELECT query_hash ,total_cpu_ms ,avg_cpu_ms ,max_cpu_ms ,max_logical_reads ,number_of_distinct_plans ,number_of_distinct_query_ids ,total_executions ,Aborted_Execution_Count ,Regular_Execution_Count ,Exception_Execution_Count ,sampled_query_text ,ROW_NUMBER() OVER ( ORDER BY total_cpu_ms DESC ,query_hash ASC ) AS query_hash_row_number FROM AggregatedCPU ) SELECT OD.query_hash ,OD.total_cpu_ms ,OD.avg_cpu_ms ,OD.max_cpu_ms ,OD.max_logical_reads ,OD.number_of_distinct_plans ,OD.number_of_distinct_query_ids ,OD.total_executions ,OD.Aborted_Execution_Count ,OD.Regular_Execution_Count ,OD.Exception_Execution_Count ,OD.sampled_query_text ,OD.query_hash_row_number FROM OrderedCPU AS OD WHERE OD.query_hash_row_number <= 15 --get top 15 rows by total_cpu_ms ORDER BY total_cpu_ms DESC;Po zidentyfikowaniu problematycznych zapytań nadszedł czas, aby dostosować te zapytania w celu zmniejszenia wykorzystania procesora CPU. Alternatywnie możesz zwiększyć rozmiar obliczeniowy bazy danych lub elastycznej puli, aby obejść ten problem.
Aby uzyskać więcej informacji na temat obsługi problemów z wydajnością procesora CPU w usłudze Azure SQL Database, zobacz Diagnozowanie i rozwiązywanie problemów z wysokim użyciem procesora CPU w usłudze Azure SQL Database.
Zidentyfikuj problemy z wydajnością operacji We/Wy
Podczas identyfikowania problemów z wydajnością wejścia/wyjścia magazynu (we/wy) najważniejsze typy oczekiwania to:
PAGEIOLATCH_*W przypadku problemów z we/wy pliku danych (w tym
PAGEIOLATCH_SH,PAGEIOLATCH_EX,PAGEIOLATCH_UP). Jeśli nazwa typu oczekiwania zawiera we/wy, wskazuje na problem z we/wy. Jeśli nazwa oczekiwania na zatrzask strony nie istnieje, wskazuje inny typ problemu, który nie jest związany z wydajnością magazynu (na przykładtempdbrywalizacją).WRITE_LOGW przypadku problemów z we/wy dziennika transakcji.
Jeśli problem we/wy występuje teraz
Użyj sys.dm_exec_requests lub sys.dm_os_waiting_tasks, aby wyświetlić element wait_type i wait_time.
Identyfikowanie użycia operacji we/wy danych i dzienników
Użyj następującego zapytania, aby zidentyfikować dane i użycie operacji we/wy dziennika.
SELECT
database_name = DB_NAME()
, UTC_time = end_time
, 'Data IO In % of Limit' = rs.avg_data_io_percent
, 'Log Write Utilization In % of Limit' = rs.avg_log_write_percent
FROM sys.dm_db_resource_stats AS rs --past hour only
ORDER BY rs.end_time DESC;
Aby uzyskać więcej przykładów użycia sys.dm_db_resource_stats, zobacz sekcję Monitorowanie użycia zasobów w dalszej części tego artykułu.
Jeśli osiągnięto limit operacji we/wy, masz dwie opcje:
- Uaktualnij rozmiar obliczeniowy lub warstwę usługi
- Identyfikowanie i dostrajanie zapytań zużywających najwięcej operacji we/wy.
Wyświetlanie operacji we/wy związanych z buforem przy użyciu magazynu zapytań
Aby zidentyfikować najważniejsze zapytania według oczekiwań związanych z we/wy, możesz użyć następującego zapytania magazynu zapytań, aby wyświetlić ostatnie dwie godziny śledzonych działań:
-- Top queries that waited on buffer
-- Note these are finished queries
WITH Aggregated AS (SELECT q.query_hash, SUM(total_query_wait_time_ms) total_wait_time_ms, SUM(total_query_wait_time_ms / avg_query_wait_time_ms) AS total_executions, MIN(qt.query_sql_text) AS sampled_query_text, MIN(wait_category_desc) AS wait_category_desc
FROM sys.query_store_query_text AS qt
INNER JOIN sys.query_store_query AS q ON qt.query_text_id=q.query_text_id
INNER JOIN sys.query_store_plan AS p ON q.query_id=p.query_id
INNER JOIN sys.query_store_wait_stats AS waits ON waits.plan_id=p.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id=waits.runtime_stats_interval_id
WHERE wait_category_desc='Buffer IO' AND rsi.start_time>=DATEADD(HOUR, -2, GETUTCDATE())
GROUP BY q.query_hash), Ordered AS (SELECT query_hash, total_executions, total_wait_time_ms, sampled_query_text, wait_category_desc, ROW_NUMBER() OVER (ORDER BY total_wait_time_ms DESC, query_hash ASC) AS query_hash_row_number
FROM Aggregated)
SELECT OD.query_hash, OD.total_executions, OD.total_wait_time_ms, OD.sampled_query_text, OD.wait_category_desc, OD.query_hash_row_number
FROM Ordered AS OD
WHERE OD.query_hash_row_number <= 15 -- get top 15 rows by total_wait_time_ms
ORDER BY total_wait_time_ms DESC;
GO
Możesz również użyć widoku sys.query_store_runtime_stats , koncentrując się na zapytaniach z dużymi wartościami w kolumnach avg_physical_io_reads i avg_num_physical_io_reads .
Wyświetlanie całkowitej operacji we/wy dziennika na potrzeby oczekiwania funkcji WRITELOG
Jeśli typ oczekiwania to WRITELOG, użyj następującego zapytania, aby wyświetlić łączną liczbę operacji we/wy dziennika według instrukcji:
-- Top transaction log consumers
-- Adjust the time window by changing
-- rsi.start_time >= DATEADD(hour, -2, GETUTCDATE())
WITH AggregatedLogUsed
AS (SELECT q.query_hash,
SUM(count_executions * avg_cpu_time / 1000.0) AS total_cpu_ms,
SUM(count_executions * avg_cpu_time / 1000.0) / SUM(count_executions) AS avg_cpu_ms,
SUM(count_executions * avg_log_bytes_used) AS total_log_bytes_used,
MAX(rs.max_cpu_time / 1000.00) AS max_cpu_ms,
MAX(max_logical_io_reads) max_logical_reads,
COUNT(DISTINCT p.plan_id) AS number_of_distinct_plans,
COUNT(DISTINCT p.query_id) AS number_of_distinct_query_ids,
SUM( CASE
WHEN rs.execution_type_desc = 'Aborted' THEN
count_executions
ELSE 0
END
) AS Aborted_Execution_Count,
SUM( CASE
WHEN rs.execution_type_desc = 'Regular' THEN
count_executions
ELSE 0
END
) AS Regular_Execution_Count,
SUM( CASE
WHEN rs.execution_type_desc = 'Exception' THEN
count_executions
ELSE 0
END
) AS Exception_Execution_Count,
SUM(count_executions) AS total_executions,
MIN(qt.query_sql_text) AS sampled_query_text
FROM sys.query_store_query_text AS qt
INNER JOIN sys.query_store_query AS q ON qt.query_text_id = q.query_text_id
INNER JOIN sys.query_store_plan AS p ON q.query_id = p.query_id
INNER JOIN sys.query_store_runtime_stats AS rs ON rs.plan_id = p.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id = rs.runtime_stats_interval_id
WHERE rs.execution_type_desc IN ( 'Regular', 'Aborted', 'Exception' )
AND rsi.start_time >= DATEADD(HOUR, -2, GETUTCDATE())
GROUP BY q.query_hash),
OrderedLogUsed
AS (SELECT query_hash,
total_log_bytes_used,
number_of_distinct_plans,
number_of_distinct_query_ids,
total_executions,
Aborted_Execution_Count,
Regular_Execution_Count,
Exception_Execution_Count,
sampled_query_text,
ROW_NUMBER() OVER (ORDER BY total_log_bytes_used DESC, query_hash ASC) AS query_hash_row_number
FROM AggregatedLogUsed)
SELECT OD.total_log_bytes_used,
OD.number_of_distinct_plans,
OD.number_of_distinct_query_ids,
OD.total_executions,
OD.Aborted_Execution_Count,
OD.Regular_Execution_Count,
OD.Exception_Execution_Count,
OD.sampled_query_text,
OD.query_hash_row_number
FROM OrderedLogUsed AS OD
WHERE OD.query_hash_row_number <= 15 -- get top 15 rows by total_log_bytes_used
ORDER BY total_log_bytes_used DESC;
GO
Identyfikowanie problemów z wydajnością bazy danych tempdb
Typowe typy oczekiwania skojarzone z problemami tempdb to PAGELATCH_* (nie PAGEIOLATCH_*). Jednak oczekiwania nie zawsze oznaczają, PAGELATCH_* że masz tempdb rywalizację. To oczekiwanie może również oznaczać występowanie rywalizacji o stronę danych obiektu użytkownika z powodu współbieżnych żądań przeznaczonych dla tej samej strony danych. Aby jeszcze bardziej potwierdzić tempdb rywalizację, użyj sys.dm_exec_requests , aby potwierdzić, że wait_resource wartość zaczyna się od 2:x:y miejsca, gdzie 2 jest tempdb identyfikatorem bazy danych, x jest identyfikatorem pliku i y jest identyfikatorem strony.
W przypadku tempdb rywalizacji typową metodą jest zmniejszenie lub przepisanie kodu aplikacji, który opiera się na metodzie tempdb. Typowe tempdb obszary użycia obejmują:
- Tabele tymczasowe
- Zmienne tabeli
- Parametry z wartościami przechowywanymi w tabeli
- Zapytania z planami, które używają sortowania, sprzężeń skrótów i buforów
Aby uzyskać więcej informacji, zobacz tempdb in Azure SQL (Baza danych tempdb w usłudze Azure SQL).
Wszystkie bazy danych w elastycznej puli współdzielą tę samą tempdb bazę danych. Wysokie tempdb wykorzystanie miejsca przez jedną bazę danych może mieć wpływ na inne bazy danych w tej samej elastycznej puli.
Najważniejsze zapytania korzystające ze zmiennych tabeli i tabel tymczasowych
Użyj następującego zapytania, aby zidentyfikować najważniejsze zapytania korzystające ze zmiennych tabeli i tabel tymczasowych:
SELECT plan_handle, execution_count, query_plan
INTO #tmpPlan
FROM sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_query_plan(plan_handle);
GO
WITH XMLNAMESPACES('http://schemas.microsoft.com/sqlserver/2004/07/showplan' AS sp)
SELECT plan_handle, stmt.stmt_details.value('@Database', 'varchar(max)') AS 'Database'
, stmt.stmt_details.value('@Schema', 'varchar(max)') AS 'Schema'
, stmt.stmt_details.value('@Table', 'varchar(max)') AS 'table'
INTO #tmp2
FROM
(SELECT CAST(query_plan AS XML) sqlplan, plan_handle FROM #tmpPlan) AS p
CROSS APPLY sqlplan.nodes('//sp:Object') AS stmt(stmt_details);
GO
SELECT t.plan_handle, [Database], [Schema], [table], execution_count
FROM
(SELECT DISTINCT plan_handle, [Database], [Schema], [table]
FROM #tmp2
WHERE [table] LIKE '%@%' OR [table] LIKE '%#%') AS t
INNER JOIN #tmpPlan AS t2 ON t.plan_handle=t2.plan_handle;
GO
DROP TABLE #tmpPlan
DROP TABLE #tmp2
Identyfikowanie długotrwałych transakcji
Użyj następującego zapytania, aby zidentyfikować długotrwałe transakcje. Długotrwałe transakcje uniemożliwiają czyszczenie trwałego magazynu wersji (PVS). Aby uzyskać więcej informacji, zobacz Rozwiązywanie problemów z przyspieszonym odzyskiwaniem bazy danych.
SELECT DB_NAME(dtr.database_id) 'database_name',
sess.session_id,
atr.name AS 'tran_name',
atr.transaction_id,
transaction_type,
transaction_begin_time,
database_transaction_begin_time,
transaction_state,
is_user_transaction,
sess.open_transaction_count,
TRIM(REPLACE(
REPLACE(
SUBSTRING(
SUBSTRING(
txt.text,
(req.statement_start_offset / 2) + 1,
((CASE req.statement_end_offset
WHEN -1 THEN
DATALENGTH(txt.text)
ELSE
req.statement_end_offset
END - req.statement_start_offset
) / 2
) + 1
),
1,
1000
),
CHAR(10),
' '
),
CHAR(13),
' '
)
) Running_stmt_text,
recenttxt.text 'MostRecentSQLText'
FROM sys.dm_tran_active_transactions AS atr
INNER JOIN sys.dm_tran_database_transactions AS dtr
ON dtr.transaction_id = atr.transaction_id
LEFT JOIN sys.dm_tran_session_transactions AS sess
ON sess.transaction_id = atr.transaction_id
LEFT JOIN sys.dm_exec_requests AS req
ON req.session_id = sess.session_id
AND req.transaction_id = sess.transaction_id
LEFT JOIN sys.dm_exec_connections AS conn
ON sess.session_id = conn.session_id
OUTER APPLY sys.dm_exec_sql_text(req.sql_handle) AS txt
OUTER APPLY sys.dm_exec_sql_text(conn.most_recent_sql_handle) AS recenttxt
WHERE atr.transaction_type != 2
AND sess.session_id != @@spid
ORDER BY start_time ASC;
Identyfikowanie problemów z wydajnością oczekiwania na udzielanie pamięci
Jeśli najlepszym typem oczekiwania jest RESOURCE_SEMAPHORE, może wystąpić problem z oczekiwaniem na udzielenie pamięci, w którym zapytania nie mogą rozpocząć wykonywania, dopóki nie otrzymają wystarczająco dużej ilości pamięci.
Ustal, czy oczekiwanie RESOURCE_SEMAPHORE jest oczekiwaniem na górę
Użyj następującego zapytania, aby określić, czy RESOURCE_SEMAPHORE oczekiwanie jest najważniejsze. Wskazuje również, że rosnąca ranga czasu oczekiwania w najnowszej RESOURCE_SEMAPHORE historii. Aby uzyskać więcej informacji na temat rozwiązywania problemów z oczekiwaniem na udzielanie pamięci, zobacz Rozwiązywanie problemów z niską wydajnością lub małą ilością pamięci spowodowanych przez przydziały pamięci w programie SQL Server.
SELECT wait_type,
SUM(wait_time) AS total_wait_time_ms
FROM sys.dm_exec_requests AS req
INNER JOIN sys.dm_exec_sessions AS sess
ON req.session_id = sess.session_id
WHERE is_user_process = 1
GROUP BY wait_type
ORDER BY SUM(wait_time) DESC;
Identyfikowanie instrukcji zużywających dużą ilość pamięci
Jeśli wystąpią błędy braku pamięci w usłudze Azure SQL Database, zapoznaj się z sys.dm_os_out_of_memory_events. Aby uzyskać więcej informacji, zobacz Rozwiązywanie problemów z błędami braku pamięci w usłudze Azure SQL Database.
Najpierw zmodyfikuj następujący skrypt, aby zaktualizować odpowiednie wartości i start_time end_time. Następnie uruchom następujące zapytanie, aby zidentyfikować instrukcje zużywające dużą ilość pamięci:
SELECT IDENTITY(INT, 1, 1) rowId,
CAST(query_plan AS XML) query_plan,
p.query_id
INTO #tmp
FROM sys.query_store_plan AS p
INNER JOIN sys.query_store_runtime_stats AS r
ON p.plan_id = r.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS i
ON r.runtime_stats_interval_id = i.runtime_stats_interval_id
WHERE start_time > '2018-10-11 14:00:00.0000000'
AND end_time < '2018-10-17 20:00:00.0000000';
WITH cte
AS (SELECT query_id,
query_plan,
m.c.value('@SerialDesiredMemory', 'INT') AS SerialDesiredMemory
FROM #tmp AS t
CROSS APPLY t.query_plan.nodes('//*:MemoryGrantInfo[@SerialDesiredMemory[. > 0]]') AS m(c) )
SELECT TOP 50
cte.query_id,
t.query_sql_text,
cte.query_plan,
CAST(SerialDesiredMemory / 1024. AS DECIMAL(10, 2)) SerialDesiredMemory_MB
FROM cte
INNER JOIN sys.query_store_query AS q
ON cte.query_id = q.query_id
INNER JOIN sys.query_store_query_text AS t
ON q.query_text_id = t.query_text_id
ORDER BY SerialDesiredMemory DESC;
Identyfikowanie 10 aktywnych przydziałów pamięci
Użyj następującego zapytania, aby zidentyfikować 10 aktywnych przydziałów pamięci:
SELECT TOP 10
CONVERT(VARCHAR(30), GETDATE(), 121) AS runtime,
r.session_id,
r.blocking_session_id,
r.cpu_time,
r.total_elapsed_time,
r.reads,
r.writes,
r.logical_reads,
r.row_count,
wait_time,
wait_type,
r.command,
OBJECT_NAME(txt.objectid, txt.dbid) 'Object_Name',
TRIM(REPLACE(REPLACE(SUBSTRING(SUBSTRING(TEXT, (r.statement_start_offset / 2) + 1,
( (
CASE r.statement_end_offset
WHEN - 1
THEN DATALENGTH(TEXT)
ELSE r.statement_end_offset
END - r.statement_start_offset
) / 2
) + 1), 1, 1000), CHAR(10), ' '), CHAR(13), ' ')) AS stmt_text,
mg.dop, --Degree of parallelism
mg.request_time, --Date and time when this query requested the memory grant.
mg.grant_time, --NULL means memory has not been granted
mg.requested_memory_kb / 1024.0 requested_memory_mb, --Total requested amount of memory in megabytes
mg.granted_memory_kb / 1024.0 AS granted_memory_mb, --Total amount of memory actually granted in megabytes. NULL if not granted
mg.required_memory_kb / 1024.0 AS required_memory_mb, --Minimum memory required to run this query in megabytes.
max_used_memory_kb / 1024.0 AS max_used_memory_mb,
mg.query_cost, --Estimated query cost.
mg.timeout_sec, --Time-out in seconds before this query gives up the memory grant request.
mg.resource_semaphore_id, --Non-unique ID of the resource semaphore on which this query is waiting.
mg.wait_time_ms, --Wait time in milliseconds. NULL if the memory is already granted.
CASE mg.is_next_candidate --Is this process the next candidate for a memory grant
WHEN 1 THEN
'Yes'
WHEN 0 THEN
'No'
ELSE
'Memory has been granted'
END AS 'Next Candidate for Memory Grant',
qp.query_plan
FROM sys.dm_exec_requests AS r
INNER JOIN sys.dm_exec_query_memory_grants AS mg
ON r.session_id = mg.session_id
AND r.request_id = mg.request_id
CROSS APPLY sys.dm_exec_sql_text(mg.sql_handle) AS txt
CROSS APPLY sys.dm_exec_query_plan(r.plan_handle) AS qp
ORDER BY mg.granted_memory_kb DESC;
Monitorowanie połączeń
Możesz użyć widoku sys.dm_exec_connections , aby pobrać informacje o połączeniach ustanowionych z określoną bazą danych i szczegóły każdego połączenia. Jeśli baza danych znajduje się w elastycznej puli i masz wystarczające uprawnienia, widok zwraca zestaw połączeń dla wszystkich baz danych w puli elastycznej. Ponadto widok sys.dm_exec_sessions jest przydatny podczas pobierania informacji o wszystkich aktywnych połączeniach użytkowników i zadaniach wewnętrznych.
Wyświetlanie bieżących sesji
Poniższe zapytanie pobiera informacje dotyczące bieżącego połączenia i sesji. Aby wyświetlić wszystkie połączenia i sesje, usuń klauzulę WHERE .
Wszystkie sesje wykonywania w bazie danych są widoczne tylko wtedy, gdy masz VIEW DATABASE STATE uprawnienia do bazy danych podczas wykonywania sys.dm_exec_requests widoków i sys.dm_exec_sessions . W przeciwnym razie zobaczysz tylko bieżącą sesję.
SELECT
c.session_id, c.net_transport, c.encrypt_option,
c.auth_scheme, s.host_name, s.program_name,
s.client_interface_name, s.login_name, s.nt_domain,
s.nt_user_name, s.original_login_name, c.connect_time,
s.login_time
FROM sys.dm_exec_connections AS c
INNER JOIN sys.dm_exec_sessions AS s
ON c.session_id = s.session_id
WHERE c.session_id = @@SPID; --Remove to view all sessions, if permissions allow
Monitorowanie wydajności zapytań
Wolne lub długotrwałe zapytania mogą zużywać znaczne zasoby systemowe. W tej sekcji pokazano, jak używać dynamicznych widoków zarządzania do wykrywania kilku typowych problemów z wydajnością zapytań przy użyciu dynamicznego widoku zarządzania sys.dm_exec_query_stats . Widok zawiera jeden wiersz na instrukcję zapytania w ramach buforowanego planu, a okres istnienia wierszy jest powiązany z samym planem. Gdy plan zostanie usunięty z pamięci podręcznej, odpowiednie wiersze zostaną wyeliminowane z tego widoku. Jeśli zapytanie nie ma buforowanego planu, na przykład ze względu OPTION (RECOMPILE) na to, że jest używane, nie jest obecne w wynikach z tego widoku.
Znajdowanie najważniejszych zapytań według czasu procesora CPU
Poniższy przykład zwraca informacje o 15 pierwszych zapytaniach sklasyfikowanych według średniego czasu procesora CPU na wykonanie. W tym przykładzie zapytania są agregowane zgodnie z ich skrótem zapytania, dzięki czemu zapytania równoważne logicznie są grupowane według skumulowanego użycia zasobów.
SELECT TOP 15 query_stats.query_hash AS Query_Hash,
SUM(query_stats.total_worker_time) / SUM(query_stats.execution_count) AS Avg_CPU_Time,
MIN(query_stats.statement_text) AS Statement_Text
FROM
(SELECT QS.*,
SUBSTRING(ST.text, (QS.statement_start_offset/2) + 1,
((CASE statement_end_offset
WHEN -1 THEN DATALENGTH(ST.text)
ELSE QS.statement_end_offset END
- QS.statement_start_offset)/2) + 1) AS statement_text
FROM sys.dm_exec_query_stats AS QS
CROSS APPLY sys.dm_exec_sql_text(QS.sql_handle) AS ST
) AS query_stats
GROUP BY query_stats.query_hash
ORDER BY Avg_CPU_Time DESC;
Monitorowanie planów zapytań dla skumulowanego czasu procesora CPU
Nieefektywny plan zapytania może również zwiększyć użycie procesora CPU. Poniższy przykład określa, które zapytanie używa najbardziej skumulowanego procesora CPU w najnowszej historii.
SELECT
highest_cpu_queries.plan_handle,
highest_cpu_queries.total_worker_time,
q.dbid,
q.objectid,
q.number,
q.encrypted,
q.[text]
FROM
(SELECT TOP 15
qs.plan_handle,
qs.total_worker_time
FROM
sys.dm_exec_query_stats AS qs
ORDER BY qs.total_worker_time desc
) AS highest_cpu_queries
CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS q
ORDER BY highest_cpu_queries.total_worker_time DESC;
Monitorowanie zablokowanych zapytań
Powolne lub długotrwałe zapytania mogą przyczynić się do nadmiernego użycia zasobów i być konsekwencją zablokowanych zapytań. Przyczyną blokowania może być słaba konstrukcja aplikacji, złe plany zapytań, brak przydatnych indeksów itd.
Możesz użyć sys.dm_tran_locks widoku, aby uzyskać informacje o bieżącym działaniu blokowania w bazie danych. Aby zapoznać się z przykładami kodu, zobacz sys.dm_tran_locks. Aby uzyskać więcej informacji na temat rozwiązywania problemów z blokowaniem, zobacz Omówienie i rozwiązywanie problemów z blokowaniem usługi Azure SQL.
Monitorowanie zakleszczeń
W niektórych przypadkach co najmniej dwa zapytania mogą blokować się nawzajem, co powoduje zakleszczenie.
Możesz utworzyć ślad zdarzeń rozszerzonych w celu przechwycenia zdarzeń zakleszczenia, a następnie znaleźć powiązane zapytania i ich plany wykonywania w magazynie zapytań. Dowiedz się więcej w artykule Analizowanie i zapobieganie zakleszczeniom w usłudze Azure SQL Database, w tym laboratorium powodujące zakleszczenie w aplikacji AdventureWorksLT. Dowiedz się więcej o typach zasobów, które mogą zakleszczeć.
Powiązana zawartość
- Wprowadzenie do usług Azure SQL Database i Azure SQL Managed Instance
- Diagnozowanie i rozwiązywanie problemów z wysokim wykorzystaniem procesora CPU w usłudze Azure SQL Database
- Dostrajanie aplikacji i baz danych pod kątem wydajności w usłudze Azure SQL Database
- Omówienie i rozwiązywanie problemów z blokowaniem usługi Azure SQL Database
- Analizowanie i zapobieganie zakleszczeniom w usłudze Azure SQL Database
- Monitorowanie obciążeń usługi Azure SQL za pomocą obserwatora bazy danych (wersja zapoznawcza)