Dostępność dzięki nadmiarowości — Azure SQL Database
Dotyczy:![]() Baza danych SQL Usługi Azure SQL Database
Baza danych SQL Usługi Azure SQL Database![]() w sieci szkieletowej
w sieci szkieletowej
W tym artykule opisano architekturę usługi Azure SQL Database i bazy danych SQL w sieci szkieletowej, która zapewnia dostępność dzięki nadmiarowości lokalnej i wysokiej dostępności dzięki nadmiarowości strefy.
Omówienie
Usługi Azure SQL Database i SQL Database w sieci szkieletowej działają w najnowszej stabilnej wersji aparatu bazy danych programu SQL Server w systemie operacyjnym Windows ze wszystkimi odpowiednimi poprawkami. Usługa SQL Database automatycznie obsługuje krytyczne zadania obsługi, takie jak stosowanie poprawek, kopie zapasowe, uaktualnienia systemu Windows i aparatu SQL oraz nieplanowane zdarzenia, takie jak awarie sprzętu, oprogramowania lub sieci. Jeśli baza danych lub elastyczna pula w usłudze SQL Database zostanie poprawiona lub przejdą w tryb failover, przestój nie będzie mieć wpływu na zastosowanie logiki ponawiania prób w aplikacji. Usługa SQL Database może szybko odzyskiwać dane nawet w najbardziej krytycznych okolicznościach, zapewniając, że dane są zawsze dostępne. Większość użytkowników nie zauważa, że uaktualnienia są wykonywane w sposób ciągły.
Domyślnie usługa Azure SQL Database osiąga dostępność dzięki nadmiarowości lokalnej, dzięki czemu baza danych jest dostępna podczas wykonywania następujących kroków:
- Zainicjowane przez klienta operacje zarządzania, które powodują krótki przestój
- Operacje konserwacji usługi
- Problemy z:
- stojak, na którym działają maszyny zasilające usługę
- maszyna fizyczna, która hostuje aparat bazy danych SQL
- Inne problemy z aparatem bazy danych SQL
- Inne potencjalne nieplanowane awarie lokalne
Domyślne rozwiązanie dostępności zostało zaprojektowane w celu zapewnienia, że zatwierdzone dane nigdy nie zostaną utracone z powodu awarii, operacje konserwacji nie wpływają na obciążenie i że baza danych nie jest pojedynczym punktem awarii w architekturze oprogramowania.
Jednak aby zminimalizować wpływ na dane w przypadku awarii w całej strefie, można osiągnąć wysoką dostępność , włączając nadmiarowość strefy. Bez nadmiarowości strefy tryb failover odbywa się lokalnie w tym samym centrum danych, co może spowodować niedostępność bazy danych do momentu rozwiązania awarii — jedynym sposobem odzyskania jest rozwiązanie odzyskiwania po awarii, takie jak geograficzne przejście w tryb failover przez aktywną replikację geograficzną, grupy trybu failover lub przywracanie geograficzne geograficznie nadmiarowej kopii zapasowej. Aby dowiedzieć się więcej, zapoznaj się z omówieniem ciągłości działania.
Istnieją trzy modele architektury dostępności:
- Zdalny model magazynu oparty na rozdzieleniu zasobów obliczeniowych i magazynu. Opiera się na dostępności i niezawodności zdalnej warstwy magazynowania. Ta architektura jest przeznaczona dla aplikacji biznesowych ukierunkowanych na budżet, które mogą tolerować pewne pogorszenie wydajności podczas działań konserwacyjnych.
- Lokalny model magazynu oparty na klastrze procesów aparatu bazy danych. Opiera się na tym, że zawsze istnieje kworum dostępnych węzłów aparatu bazy danych. Ta architektura jest przeznaczona dla aplikacji o kluczowym znaczeniu z wysoką wydajnością operacji we/wy, wysoką szybkością transakcji i gwarantuje minimalny wpływ na wydajność obciążenia podczas działań konserwacyjnych.
- Model hiperskala korzystający z rozproszonego systemu składników o wysokiej dostępności, takich jak węzły obliczeniowe, serwery stron, usługa dziennika i magazyn trwały. Każdy składnik obsługujący bazę danych w warstwie Hiperskala zapewnia własną nadmiarowość i odporność na awarie. Węzły obliczeniowe, serwery stronicowania i usługa rejestrowania są uruchamiane w usłudze Azure Service Fabric, która kontroluje kondycję każdego składnika i wykonuje przejścia w tryb failover do dostępnych węzłów w dobrej kondycji zgodnie z potrzebami. Magazyn trwały korzysta z usługi Azure Storage z natywną wysoką dostępnością i nadmiarowością. Aby dowiedzieć się więcej, zobacz Architektura hiperskala.
W ramach każdego z trzech modeli dostępności usługa SQL Database obsługuje lokalną nadmiarowość i opcje nadmiarowości strefowej. Nadmiarowość lokalna zapewnia odporność w centrum danych, podczas gdy nadmiarowość strefowa zwiększa odporność, chroniąc przed awariami strefy dostępności w regionie.
W poniższej tabeli przedstawiono opcje dostępności oparte na warstwach usług:
| Warstwa usług | Model wysokiej dostępności | dostępność lokalnie nadmiarowa | Dostępność strefowo nadmiarowa |
|---|---|---|---|
| Ogólnego przeznaczenia (rdzenie wirtualne) | Magazyn zdalny | Tak | Tak |
| Krytyczne dla działania firmy (rdzeń wirtualny) | Magazyn lokalny | Tak | Tak |
| Hiperskala (rdzeń wirtualny) | Hiperskala | Tak | Tak |
| Podstawowa (DTU) | Magazyn zdalny | Tak | Nie. |
| Standardowa (DTU) | Magazyn zdalny | Tak | Nie. |
| Premium (DTU) | Magazyn lokalny | Tak | Tak |
Aby uzyskać więcej informacji na temat określonych umów SLA dla różnych warstw usług, zapoznaj się z umową SLA dotyczącą usługi Azure SQL Database.
Dostępność za pośrednictwem nadmiarowości lokalnej
Dostępność lokalnie nadmiarowa jest oparta na przechowywaniu bazy danych w magazynie lokalnie nadmiarowym (LRS), który kopiuje dane trzy razy w jednym centrum danych w regionie podstawowym i chroni dane w przypadku awarii lokalnej, takiej jak awaria sieci na małą skalę lub awaria zasilania. Magazyn LRS to opcja najniższego kosztu nadmiarowości i oferuje najmniejszą trwałość w porównaniu z innymi opcjami. Jeśli w regionie wystąpi awaria na dużą skalę, taka jak pożar lub powodzia, wszystkie repliki konta magazynu korzystającego z magazynu LRS mogą zostać utracone lub nieodwracalne. W związku z tym, aby dodatkowo chronić dane podczas korzystania z opcji dostępności lokalnie nadmiarowej, rozważ użycie bardziej odpornej opcji magazynu dla kopii zapasowych bazy danych. Nie dotyczy to baz danych w warstwie Hiperskala, w których ten sam magazyn jest używany zarówno dla plików danych, jak i kopii zapasowych.
Dostępność lokalnie nadmiarowa jest dostępna dla wszystkich baz danych we wszystkich warstwach usług i celu punktu odzyskiwania (RPO), co wskazuje, że ilość utraty danych wynosi zero.
Warstwy usług Podstawowa, Standardowa i Ogólnego przeznaczenia
Warstwy usług Podstawowa i Standardowa modelu zakupów opartego na jednostkach DTU oraz warstwa usługi Ogólnego przeznaczenia modelu zakupów opartego na rdzeniach wirtualnych korzystają z modelu dostępności magazynu zdalnego zarówno dla zasobów obliczeniowych bezserwerowych, jak i aprowizowanych. Na poniższym rysunku przedstawiono cztery różne węzły z oddzielnymi warstwami obliczeniowymi i warstwami magazynu.
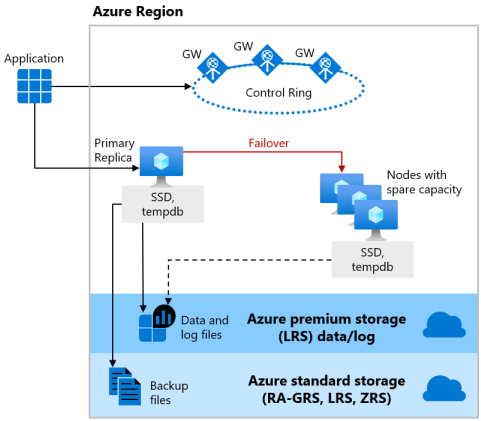
Model dostępności magazynu zdalnego obejmuje dwie warstwy:
- Bezstanowa warstwa obliczeniowa, która uruchamia proces aparatu bazy danych i zawiera tylko przejściowe i buforowane dane, takie jak
tempdbbazy danych imodelna dołączonym dysku SSD, pamięć podręczna planu, pula i pula magazynu kolumn w pamięci. Ten bezstanowy węzeł jest obsługiwany przez usługę Azure Service Fabric, która inicjuje aparat bazy danych, kontroluje kondycję węzła i w razie potrzeby wykonuje przejście w tryb failover do innego węzła. - Stanowa warstwa danych z plikami bazy danych (
.mdfi.ldf) przechowywana w usłudze Azure Blob Storage. Usługa Azure Blob Storage ma wbudowane funkcje dostępności i nadmiarowości danych. Gwarantuje to, że każdy rekord w pliku dziennika lub stronie w pliku danych zostanie zachowany, nawet jeśli proces aparatu bazy danych ulegnie awarii.
Za każdym razem, gdy aparat bazy danych lub system operacyjny zostanie uaktualniony lub zostanie wykryty błąd, usługa Azure Service Fabric przeniesie bezstanowy proces aparatu bazy danych do innego bezstanowego węzła obliczeniowego z wystarczającą ilością wolnej pojemności. Przeniesienie danych w usłudze Azure Blob Storage nie ma wpływu na dane, a pliki danych/dziennika są dołączane do nowo zainicjowanego procesu aparatu bazy danych. Ten proces gwarantuje wysoką dostępność, ale duże obciążenie może spowodować obniżenie wydajności podczas przejścia, ponieważ nowy proces aparatu bazy danych rozpoczyna się od zimnej pamięci podręcznej.
Warstwa usługi Premium i Krytyczne dla działania firmy
Warstwa usługi Premium modelu zakupów opartego na jednostkach DTU i warstwa usługi Krytyczne dla działania firmy modelu zakupów opartego na rdzeniach wirtualnych korzysta z lokalnego modelu dostępności magazynu, który integruje zasoby obliczeniowe (proces aparatu bazy danych) i magazyn (lokalnie dołączony dysk SSD) w jednym węźle. Wysoka dostępność jest osiągana przez replikowanie zasobów obliczeniowych i magazynu do dodatkowych węzłów.
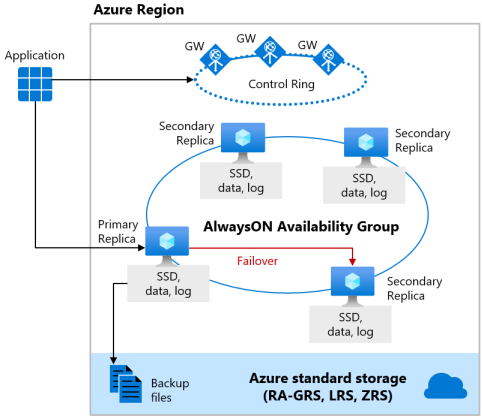
Podstawowe pliki bazy danych (.mdf/.ldf) są umieszczane w dołączonym magazynie SSD w celu zapewnienia bardzo małych opóźnień we/wy do obciążenia. Wysoka dostępność jest implementowana przy użyciu technologii podobnej do zawsze włączonych grup dostępności programu SQL Server. Klaster zawiera jedną replikę podstawową dostępną dla obciążeń klientów odczytu i zapisu oraz maksymalnie trzy repliki pomocnicze (obliczeniowe i magazynowe) zawierające kopie danych. Replika podstawowa stale wypycha zmiany do replik pomocniczych w kolejności i zapewnia, że dane są utrwalane na wystarczającej liczbie replik pomocniczych przed zatwierdzeniem każdej transakcji. Ten proces gwarantuje, że jeśli replika podstawowa lub replika pomocnicza z jakiegoś powodu ulegnie awarii z możliwością odczytu, zawsze istnieje w pełni zsynchronizowana replika w trybie failover. Tryb failover jest inicjowany przez usługę Azure Service Fabric. Gdy replika pomocnicza stanie się nową repliką podstawową, zostanie utworzona inna replika pomocnicza, aby upewnić się, że klaster ma wystarczającą liczbę replik do obsługi kworum. Po zakończeniu pracy w trybie failover połączenia usługi Azure SQL są automatycznie przekierowywane do nowej repliki podstawowej lub repliki pomocniczej z możliwością odczytu.
Dodatkową korzyścią jest możliwość przekierowywania połączeń usługi Azure SQL tylko do odczytu z jedną z replik pomocniczych. Ta funkcja jest nazywana skalowaniem odczytu w poziomie. Zapewnia ona 100% dodatkowej pojemności obliczeniowej bez dodatkowych opłat za operacje tylko do odczytu, takie jak obciążenia analityczne, z repliki podstawowej.
Warstwa usługi Hiperskala
Architektura warstwy usługi Hiperskala jest opisana w temacie Architektura funkcji rozproszonych.

Model dostępności w warstwie Hiperskala obejmuje cztery warstwy:
- Bezstanowa warstwa obliczeniowa, która uruchamia aparat bazy danych procesy i zawiera tylko przejściowe i buforowane dane, takie jak nieprzechodząca pamięć podręczna
tempdbRBPEX imodelbazy danych itp. na dołączonym dysku SSD, pamięci podręcznej planu, puli i puli magazynu kolumn w pamięci. Ta warstwa bezstanowa zawiera podstawową replikę obliczeniową i opcjonalnie wiele pomocniczych replik obliczeniowych, które mogą służyć jako obiekty docelowe trybu failover. - Bezstanowa warstwa magazynu utworzona przez serwery stron. Ta warstwa jest rozproszonym aparatem magazynu dla procesów aparatu bazy danych uruchomionych w replikach obliczeniowych. Każdy serwer stron zawiera tylko dane przejściowe i buforowane, takie jak pokrycie pamięci podręcznej RBPEX na dołączonym dysku SSD i strony danych buforowane w pamięci. Każdy serwer stron ma sparowany serwer stron w konfiguracji aktywne-aktywne w celu zapewnienia równoważenia obciążenia, nadmiarowości i wysokiej dostępności.
- Warstwa magazynu dziennika transakcji stanowych utworzona przez węzeł obliczeniowy z uruchomionym procesem usługi dzienników dzienników, strefą docelową dziennika transakcji i długoterminowym magazynem dziennika transakcji. Strefa docelowa i długoterminowy magazyn korzystają z usługi Azure Storage, która zapewnia dostępność i nadmiarowość dziennika transakcji, zapewniając trwałość danych dla zatwierdzonych transakcji.
- Stanowa warstwa magazynu danych z plikami bazy danych (.mdf/.ndf), które są przechowywane w usłudze Azure Storage i są aktualizowane przez serwery stron. Ta warstwa używa funkcji dostępności i nadmiarowości danych usługi Azure Storage. Gwarantuje to, że każda strona w pliku danych zostanie zachowana nawet w przypadku awarii procesów w innych warstwach architektury hiperskala lub awarii węzłów obliczeniowych.
Węzły obliczeniowe we wszystkich warstwach hiperskala są uruchamiane w usłudze Azure Service Fabric, która kontroluje kondycję każdego węzła i wykonuje przejścia w tryb failover do dostępnych węzłów w dobrej kondycji w razie potrzeby.
Aby uzyskać więcej informacji na temat wysokiej dostępności w warstwie Hiperskala, zobacz Wysoka dostępność bazy danych w warstwie Hiperskala.
Wysoka dostępność dzięki nadmiarowości strefowej
Dostępność strefowo nadmiarowa zapewnia rozmieszczenie danych w trzech strefach dostępności platformy Azure w regionie podstawowym. Każda strefa dostępności jest oddzielną lokalizacją fizyczną z niezależnym zasilaniem, chłodzeniem i siecią.
Dostępność strefowo nadmiarowa jest dostępna dla baz danych w warstwach usług Krytyczne dla działania firmy, Ogólnego przeznaczenia i Hiperskala modelu zakupów opartych na rdzeniach wirtualnych, a tylko warstwa usługi Premium modelu zakupów opartego na jednostkach DTU — warstwy usług Podstawowa i Standardowa nie obsługują nadmiarowości strefy.
Podczas gdy każda warstwa usługi implementuje nadmiarowość strefy inaczej, wszystkie implementacje zapewniają cel punktu odzyskiwania (RPO) z zerową utratą zatwierdzonych danych po przejściu w tryb failover.
Warstwa usługi Ogólnego przeznaczenia
Konfiguracja strefowo nadmiarowa dla warstwy usługi Ogólnego przeznaczenia jest oferowana zarówno dla bezserwerowych, jak i aprowizowanych zasobów obliczeniowych dla baz danych w modelu zakupów rdzeni wirtualnych. Ta konfiguracja korzysta z usługi Azure Strefy dostępności do replikowania baz danych w wielu lokalizacjach fizycznych w regionie świadczenia usługi Azure. Wybierając nadmiarowość strefową, możesz wprowadzić nowe i istniejące bezserwerowe pojedyncze bazy danych i elastyczne pule ogólnego przeznaczenia odporne na znacznie większy zestaw awarii, w tym katastrofalne awarie centrum danych bez żadnych zmian logiki aplikacji.
Konfiguracja strefowo nadmiarowa dla warstwy Ogólnego przeznaczenia ma dwie warstwy:
- Stanowa warstwa danych z plikami bazy danych (.mdf/.ldf), które są przechowywane w magazynie strefowo nadmiarowym ZRS. Używanie magazynu ZRS pliki danych i dziennika są synchronicznie kopiowane w trzech fizycznie izolowanych strefach dostępności platformy Azure.
- Bezstanowa warstwa obliczeniowa, która uruchamia proces sqlservr.exe i zawiera tylko dane przejściowe i buforowane, takie jak
tempdbbazy danych imodelna dołączonym dysku SSD, pamięć podręczna planu, pula i pula magazynu kolumn w pamięci. Ten bezstanowy węzeł jest obsługiwany przez usługę Azure Service Fabric, która inicjuje sqlservr.exe, kontroluje kondycję węzła i wykonuje przejście w tryb failover do innego węzła w razie potrzeby. W przypadku baz danych bezserwerowych strefowo nadmiarowych i aprowizowanych baz danych ogólnego przeznaczenia węzły z wolnej pojemnością są łatwo dostępne w innych Strefy dostępności na potrzeby trybu failover.
Wersja strefowo nadmiarowa architektury wysokiej dostępności dla warstwy usługi Ogólnego przeznaczenia przedstawiono na poniższym diagramie:
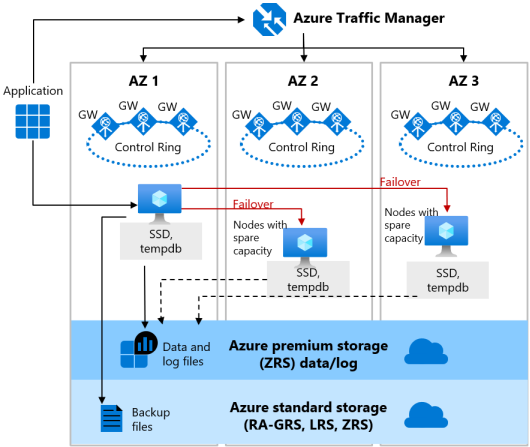
Podczas konfigurowania baz danych ogólnego przeznaczenia z nadmiarowością stref należy wziąć pod uwagę następujące kwestie:
- W przypadku warstwy Ogólnego przeznaczenia konfiguracja strefowo nadmiarowa jest ogólnie dostępna w następujących regionach:
- (Afryka) Republika Południowej Afryki Północnej
- (Azja i Pacyfik) Australia Wschodnia
- (Azja i Pacyfik) Azja Wschodnia
- (Azja i Pacyfik) Japonia Wschodnia
- (Azja i Pacyfik) Korea Środkowa
- (Azja i Pacyfik) Azja Południowo-Wschodnia
- (Azja i Pacyfik) Indie Środkowe
- (Azja i Pacyfik) Chiny Północne 3
- (Azja i Pacyfik) Zjednoczone Emiraty Arabskie Na Północ
- (Europa) Francja Środkowa
- (Europa) Niemcy Zachodnio-środkowe
- (Europa) Włochy Północne
- (Europa) Europa Północna
- (Europa) Norwegia Wschodnia
- (Europa) Polska Środkowa
- (Europa) Europa Zachodnia
- (Europa) Południowe Zjednoczone Królestwo
- (Europa) Szwajcaria Północna
- (Europa) Szwecja Środkowa
- (Bliski Wschód) Izrael Środkowy
- (Bliski Wschód) Katar Środkowy
- (Ameryka Północna) Kanada Środkowa
- (Ameryka Północna) Środkowe stany USA
- (Ameryka Północna) Wschodnie stany USA
- (Ameryka Północna) Wschodnie stany USA 2
- (Ameryka Północna) Południowo-środkowe stany USA
- (Ameryka Północna) Zachodnie stany USA 2
- (Ameryka Północna) Zachodnie stany USA 3
- (Ameryka Południowa) Brazylia Południowa
- W przypadku dostępności strefowo nadmiarowej wybierz okno obsługi inne niż domyślne jest obecnie dostępne w wybranych regionach.
- Konfiguracja strefowo nadmiarowa jest dostępna tylko w usłudze SQL Database, gdy wybrano sprzęt z serii Standardowa (Gen5).
- Nadmiarowość strefowa nie jest dostępna dla warstw usług w warstwach Podstawowa i Standardowa w modelu zakupów jednostek DTU.
Warstwy usług Premium i Krytyczne dla działania firmy
Gdy nadmiarowość strefy jest włączona dla warstwy usługi Premium lub Krytyczne dla działania firmy, repliki są umieszczane w różnych strefach dostępności w tym samym regionie. Aby wyeliminować pojedynczy punkt awarii, pierścień kontrolny jest również duplikowany w wielu strefach jako trzy pierścienie bramy (GW). Routing do określonego pierścienia bramy jest kontrolowany przez usługę Azure Traffic Manager. Ponieważ konfiguracja strefowo nadmiarowa w warstwach usług Premium lub Krytyczne dla działania firmy używa istniejących replik do umieszczania w różnych strefach dostępności, można ją włączyć bez dodatkowych kosztów. Wybierając konfigurację strefowo nadmiarową, możesz sprawić, że bazy danych w warstwie Premium lub Krytyczne dla działania firmy i elastyczne pule będą odporne na znacznie większy zestaw awarii, w tym katastrofalne awarie centrum danych bez żadnych zmian logiki aplikacji. Możesz również przekonwertować istniejące bazy danych w warstwie Premium lub Krytyczne dla działania firmy lub elastyczne pule na konfigurację strefowo nadmiarową.
Wersja strefowo nadmiarowa architektury wysokiej dostępności przedstawiono na poniższym diagramie:
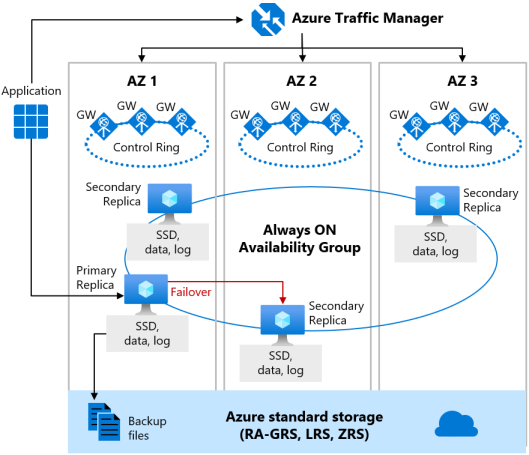
Podczas konfigurowania baz danych Premium lub Krytyczne dla działania firmy z nadmiarowością stref należy wziąć pod uwagę następujące kwestie:
- Aby uzyskać aktualne informacje o regionach, w których są obsługiwane strefowo nadmiarowe bazy danych, zobacz Obsługa usług według regionów.
- W przypadku dostępności strefowo nadmiarowej wybierz okno obsługi inne niż domyślne jest obecnie dostępne w wybranych regionach.
Warstwa usługi Hiperskala
Istnieje możliwość skonfigurowania nadmiarowości strefowej dla baz danych w warstwie usługi Hiperskala. Aby dowiedzieć się więcej, zobacz Tworzenie strefowo nadmiarowej bazy danych w warstwie Hiperskala.
Włączenie tej konfiguracji zapewnia odporność na poziomie strefy przez replikację między Strefy dostępności dla wszystkich warstw hiperskala. Wybierając nadmiarowość strefową, możesz sprawić, że bazy danych w warstwie Hiperskala będą odporne na znacznie większy zestaw awarii, w tym katastrofalne awarie centrum danych bez żadnych zmian logiki aplikacji. Wszystkie regiony platformy Azure, w których Strefy dostępności obsługują strefowo nadmiarową bazę danych w warstwie Hiperskala. Obsługa nadmiarowości stref dla sprzętu PRMS w warstwie Hiperskala i MOPRMS jest dostępna w regionach wymienionych tutaj.
Dostępność strefowo nadmiarowa jest obsługiwana zarówno w autonomicznych bazach danych w warstwie Hiperskala, jak i w elastycznych pulach Hiperskala. Aby uzyskać więcej informacji, zobacz Elastyczne pule hiperskala.
Na poniższym diagramie przedstawiono podstawową architekturę dla strefowo nadmiarowych baz danych w warstwie Hiperskala:

Rozważ następujące ograniczenia:
Konfigurację strefowo nadmiarową można określić tylko podczas tworzenia bazy danych. Tego ustawienia nie można zmodyfikować po aprowizacji zasobu. Użyj funkcji kopiowania bazy danych, przywracania do punktu w czasie lub utwórz replikę geograficzną, aby zaktualizować konfigurację strefowo nadmiarową dla istniejącej bazy danych w warstwie Hiperskala. W przypadku korzystania z jednej z tych opcji aktualizacji, jeśli docelowa baza danych znajduje się w innym regionie niż źródło lub jeśli nadmiarowość magazynu kopii zapasowej bazy danych różni się od źródłowej bazy danych, operacja kopiowania będzie rozmiarem operacji danych.
W przypadku dostępności strefowo nadmiarowej wybierz okno obsługi inne niż domyślne jest obecnie dostępne w wybranych regionach.
Obecnie nie ma możliwości określenia nadmiarowości strefy podczas migrowania bazy danych do warstwy Hiperskala przy użyciu witryny Azure Portal. Jednak nadmiarowość strefy można określić przy użyciu programu Azure PowerShell, interfejsu wiersza polecenia platformy Azure lub interfejsu API REST podczas migracji istniejącej bazy danych z innej warstwy usługi Azure SQL Database do warstwy Hiperskala. Oto przykład interfejsu wiersza polecenia platformy Azure:
az sql db update --resource-group "myRG" --server "myServer" --name "myDB" --edition Hyperscale --zone-redundant true`Co najmniej 1 replika obliczeniowa o wysokiej dostępności i użycie magazynu kopii zapasowych strefowo nadmiarowego lub geograficznie nadmiarowego jest wymagane do włączenia konfiguracji strefowo nadmiarowej dla warstwy Hiperskala.
Dostępność strefowo nadmiarowa bazy danych
W usłudze Azure SQL Database serwer jest konstrukcją logiczną, która działa jako centralny punkt administracyjny dla kolekcji baz danych. Na poziomie serwera można administrować identyfikatorami logowania, metodą uwierzytelniania, regułami zapory, regułami inspekcji, zasadami wykrywania zagrożeń i grupami trybu failover. Dane związane z niektórymi z tych funkcji, takie jak identyfikatory logowania i reguły zapory, są przechowywane w master bazie danych. Podobnie dane niektórych widoków DMV, na przykład sys.resource_stats, są również przechowywane w master bazie danych.
Gdy baza danych z konfiguracją strefowo nadmiarową jest tworzona na serwerze logicznym, master baza danych skojarzona z serwerem jest również automatycznie strefowo nadmiarowa. Gwarantuje to, że w przypadku awarii strefowej aplikacje korzystające z bazy danych pozostaną bez wpływu, ponieważ funkcje zależne od master bazy danych, takie jak logowania i reguły zapory, są nadal dostępne.
master Tworzenie strefowo nadmiarowej bazy danych jest procesem asynchronicznym i ukończenie procesu w tle zajmie trochę czasu.
Jeśli żadna z baz danych na serwerze nie jest strefowo nadmiarowa lub gdy tworzysz pusty serwer, master baza danych skojarzona z serwerem nie jest strefowo nadmiarowa.
Aby sprawdzić właściwość bazy danych, możesz użyć programu Azure PowerShell lub interfejsu wiersza polecenia platformy Azure lub master REST:
Użyj następującego przykładowego polecenia, aby sprawdzić wartość właściwości "ZoneRedundant" dla master bazy danych.
Get-AzSqlDatabase -ResourceGroupName "myResourceGroup" -ServerName "myServerName" -DatabaseName "master"
Testowanie odporności błędów aplikacji
Wysoka dostępność to podstawowa część platformy usługi SQL Database, która działa w sposób niewidoczny dla aplikacji bazy danych. Wiemy jednak, że warto przetestować, jak automatyczne operacje trybu failover inicjowane podczas planowanych lub nieplanowanych zdarzeń będą miały wpływ na aplikację przed wdrożeniem jej w środowisku produkcyjnym. Możesz ręcznie wyzwolić tryb failover, wywołując specjalny interfejs API w celu ponownego uruchomienia bazy danych lub elastycznej puli. W przypadku bezserwerowej bazy danych strefowo nadmiarowej lub aprowizowanej bazy danych ogólnego przeznaczenia lub elastycznej puli wywołanie interfejsu API spowoduje przekierowanie połączeń klienta do nowego podstawowego w strefie dostępności innej niż strefa dostępności starego podstawowego. Oprócz testowania wpływu pracy w tryb failover na istniejące sesje bazy danych można również sprawdzić, czy zmienia on kompleksową wydajność ze względu na zmiany opóźnienia sieci. Ponieważ operacja ponownego uruchamiania jest natrętna i duża ich liczba może przeciążyć platformę, tylko jedno wywołanie trybu failover jest dozwolone co 15 minut dla każdej bazy danych lub elastycznej puli.
Aby uzyskać więcej informacji na temat wysokiej dostępności i odzyskiwania po awarii usługi Azure SQL Database, zapoznaj się z listą kontrolną wysokiej dostępności/odzyskiwania po awarii.
Tryb failover można zainicjować przy użyciu programu PowerShell, interfejsu API REST lub interfejsu wiersza polecenia platformy Azure:
| Typ wdrożenia | PowerShell | Interfejs API REST | Interfejs wiersza polecenia platformy Azure |
|---|---|---|---|
| baza danych | Invoke-AzSqlDatabaseFailover | Tryb failover bazy danych | polecenie az rest może służyć do wywoływania wywołania interfejsu API REST z poziomu interfejsu wiersza polecenia platformy Azure |
| Pula elastyczna | Invoke-AzSqlElasticPoolFailover | Tryb failover elastycznej puli | polecenie az rest może służyć do wywoływania wywołania interfejsu API REST z poziomu interfejsu wiersza polecenia platformy Azure |
Ważne
Polecenie trybu failover nie jest dostępne dla replik pomocniczych z możliwością odczytu baz danych w warstwie Hiperskala.
Podsumowanie
Usługa Azure SQL Database oferuje wbudowane rozwiązanie wysokiej dostępności, które jest głęboko zintegrowane z platformą Azure. Jest on zależny od usługi Service Fabric do wykrywania i odzyskiwania błędów w usłudze Azure Blob Storage na potrzeby ochrony danych oraz od Strefy dostępności w celu zapewnienia większej odporności na uszkodzenia. Ponadto usługa SQL Database używa technologii zawsze włączonej grupy dostępności z programu SQL Server na potrzeby synchronizacji danych i trybu failover. Połączenie tych technologii pozwala aplikacjom w pełni wykorzystać zalety modelu magazynu mieszanego i obsługiwać najbardziej wymagające umowy SLA.
Powiązana zawartość
Aby dowiedzieć się więcej, zapoznaj się z tematem: