Samouczek: implementowanie rozproszonej geograficznie bazy danych (Azure SQL Database)
Dotyczy:![]() Azure SQL Database
Azure SQL Database
Skonfiguruj bazę danych w usłudze SQL Database i aplikację kliencką do przełączania awaryjnego w regionie zdalnym oraz przetestuj plan przełączenia awaryjnego. Nauczysz się, jak:
- Utwórz grupę failover
- Uruchamianie aplikacji Java w celu wykonywania zapytań dotyczących bazy danych w usłudze SQL Database
- Testowanie trybu failover
Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto.
Wymagania wstępne
Uwaga
W tym artykule użyto modułu Azure Az programu PowerShell, który jest zalecanym modułem programu PowerShell do interakcji z platformą Azure. Aby rozpocząć pracę z modułem Azure PowerShell, zobacz Instalowanie programu Azure PowerShell. Aby dowiedzieć się, jak przeprowadzić migrację do modułu Az PowerShell, zobacz Migracja programu Azure PowerShell z modułu AzureRM do modułu Az.
Ważne
Moduł Azure Resource Manager (AzureRM) programu PowerShell został wycofany 29 lutego 2024 r. Wszystkie przyszłe programowanie powinno używać modułu Az.Sql. Zaleca się migrowanie użytkowników z modułu AzureRM do modułu Az programu PowerShell w celu zapewnienia ciągłej obsługi i aktualizacji. Moduł AzureRM nie jest już utrzymywany ani obsługiwany. Argumenty poleceń w module Az programu PowerShell i modułach AzureRM są zasadniczo identyczne. Aby uzyskać więcej informacji na temat ich zgodności, zobacz Wprowadzenie nowego modułu Az PowerShell.
Aby ukończyć samouczek, upewnij się, że zainstalowano następujące elementy:
Pojedyncza baza danych w usłudze Azure SQL Database. Aby utworzyć jedno zastosowanie,
Uwaga
W tym samouczku jest używana przykładowa baza danych AdventureWorksLT .
Ważne
Pamiętaj, aby skonfigurować reguły zapory do korzystania z publicznego adresu IP komputera, na którym wykonujesz kroki opisane w tym samouczku. Reguły zapory na poziomie bazy danych będą automatycznie replikowane do serwera pomocniczego.
Aby uzyskać informacje, zobacz Tworzenie reguły zapory na poziomie bazy danych, albo aby określić adres IP używany dla reguły zapory na poziomie serwera dla Twojego komputera, zobacz Tworzenie zapory na poziomie serwera.
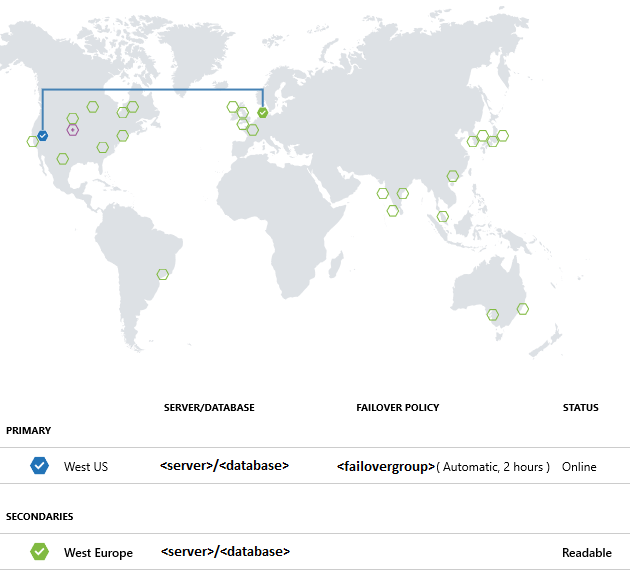
Utwórz grupę przełączania awaryjnego
Za pomocą programu Azure PowerShell utwórz grupy przełączania awaryjnego między istniejącym serwerem a nowym serwerem w innym regionie. Następnie dodaj przykładową bazę danych do grupy trybu failover.
Ważne
Ten przykład wymaga modułu Azure PowerShell Az w wersji 1.0 lub nowszej. Uruchom polecenie Get-Module -ListAvailable Az , aby zobaczyć, które wersje są zainstalowane.
Jeśli musisz zainstalować, zobacz Instalowanie modułu programu Azure PowerShell.
Uruchom polecenie Connect-AzAccount , aby zalogować się do platformy Azure.
Aby utworzyć grupę trybu failover, uruchom następujący skrypt:
$admin = "<adminName>"
$password = "<password>"
$resourceGroup = "<resourceGroupName>"
$location = "<resourceGroupLocation>"
$server = "<serverName>"
$database = "<databaseName>"
$drLocation = "<disasterRecoveryLocation>"
$drServer = "<disasterRecoveryServerName>"
$failoverGroup = "<globallyUniqueFailoverGroupName>"
# create a backup server in the failover region
New-AzSqlServer -ResourceGroupName $resourceGroup -ServerName $drServer `
-Location $drLocation -SqlAdministratorCredentials $(New-Object -TypeName System.Management.Automation.PSCredential `
-ArgumentList $admin, $(ConvertTo-SecureString -String $password -AsPlainText -Force))
# create a failover group between the servers
New-AzSqlDatabaseFailoverGroup –ResourceGroupName $resourceGroup -ServerName $server `
-PartnerServerName $drServer –FailoverGroupName $failoverGroup –FailoverPolicy Automatic -GracePeriodWithDataLossHours 2
# add the database to the failover group
Get-AzSqlDatabase -ResourceGroupName $resourceGroup -ServerName $server -DatabaseName $database | `
Add-AzSqlDatabaseToFailoverGroup -ResourceGroupName $resourceGroup -ServerName $server -FailoverGroupName $failoverGroup
Ustawienia replikacji geograficznej można również zmienić w portalu Azure, wybierając bazę danych, a następnie Ustawienia>Replikacja geograficzna.
Uruchamianie przykładowego projektu
W konsoli programu utwórz projekt Maven za pomocą następującego polecenia:
mvn archetype:generate "-DgroupId=com.sqldbsamples" "-DartifactId=SqlDbSample" "-DarchetypeArtifactId=maven-archetype-quickstart" "-Dversion=1.0.0"Wpisz Y i naciśnij Enter.
Zmień katalogi na nowy projekt.
cd SqlDbSampleZa pomocą ulubionego edytora otwórz plik pom.xml w folderze projektu.
Dodaj zależność sterownika JDBC firmy Microsoft dla programu SQL Server, dodając następującą
dependencysekcję. Zależność musi być wklejona w większejdependenciessekcji.<dependency> <groupId>com.microsoft.sqlserver</groupId> <artifactId>mssql-jdbc</artifactId> <version>6.1.0.jre8</version> </dependency>Określ wersję języka Java, dodając sekcję
propertiespodependenciessekcji:<properties> <maven.compiler.source>1.8</maven.compiler.source> <maven.compiler.target>1.8</maven.compiler.target> </properties>Obsługuj pliki manifestu, dodając sekcję
buildpo sekcjiproperties:<build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-jar-plugin</artifactId> <version>3.0.0</version> <configuration> <archive> <manifest> <mainClass>com.sqldbsamples.App</mainClass> </manifest> </archive> </configuration> </plugin> </plugins> </build>Zapisz i zamknij plik pom.xml.
Otwórz plik App.java znajdujący się w lokalizacji .. \SqlDbSample\src\main\java\com\sqldbsamples i zastąp zawartość następującym kodem:
package com.sqldbsamples; import java.sql.Connection; import java.sql.Statement; import java.sql.PreparedStatement; import java.sql.ResultSet; import java.sql.Timestamp; import java.sql.DriverManager; import java.util.Date; import java.util.concurrent.TimeUnit; public class App { private static final String FAILOVER_GROUP_NAME = "<your failover group name>"; // add failover group name private static final String DB_NAME = "<your database>"; // add database name private static final String USER = "<your admin>"; // add database user private static final String PASSWORD = "<password>"; // add database password private static final String READ_WRITE_URL = String.format("jdbc:" + "sqlserver://%s.database.windows.net:1433;database=%s;user=%s;password=%s;encrypt=true;" + "hostNameInCertificate=*.database.windows.net;loginTimeout=30;", FAILOVER_GROUP_NAME, DB_NAME, USER, PASSWORD); private static final String READ_ONLY_URL = String.format("jdbc:" + "sqlserver://%s.secondary.database.windows.net:1433;database=%s;user=%s;password=%s;encrypt=true;" + "hostNameInCertificate=*.database.windows.net;loginTimeout=30;", FAILOVER_GROUP_NAME, DB_NAME, USER, PASSWORD); public static void main(String[] args) { System.out.println("#######################################"); System.out.println("## GEO DISTRIBUTED DATABASE TUTORIAL ##"); System.out.println("#######################################"); System.out.println(""); int highWaterMark = getHighWaterMarkId(); try { for(int i = 1; i < 1000; i++) { // loop will run for about 1 hour System.out.print(i + ": insert on primary " + (insertData((highWaterMark + i)) ? "successful" : "failed")); TimeUnit.SECONDS.sleep(1); System.out.print(", read from secondary " + (selectData((highWaterMark + i)) ? "successful" : "failed") + "\n"); TimeUnit.SECONDS.sleep(3); } } catch(Exception e) { e.printStackTrace(); } } private static boolean insertData(int id) { // Insert data into the product table with a unique product name so we can find the product again String sql = "INSERT INTO SalesLT.Product " + "(Name, ProductNumber, Color, StandardCost, ListPrice, SellStartDate) VALUES (?,?,?,?,?,?);"; try (Connection connection = DriverManager.getConnection(READ_WRITE_URL); PreparedStatement pstmt = connection.prepareStatement(sql)) { pstmt.setString(1, "BrandNewProduct" + id); pstmt.setInt(2, 200989 + id + 10000); pstmt.setString(3, "Blue"); pstmt.setDouble(4, 75.00); pstmt.setDouble(5, 89.99); pstmt.setTimestamp(6, new Timestamp(new Date().getTime())); return (1 == pstmt.executeUpdate()); } catch (Exception e) { return false; } } private static boolean selectData(int id) { // Query the data previously inserted into the primary database from the geo replicated database String sql = "SELECT Name, Color, ListPrice FROM SalesLT.Product WHERE Name = ?"; try (Connection connection = DriverManager.getConnection(READ_ONLY_URL); PreparedStatement pstmt = connection.prepareStatement(sql)) { pstmt.setString(1, "BrandNewProduct" + id); try (ResultSet resultSet = pstmt.executeQuery()) { return resultSet.next(); } } catch (Exception e) { return false; } } private static int getHighWaterMarkId() { // Query the high water mark id stored in the table to be able to make unique inserts String sql = "SELECT MAX(ProductId) FROM SalesLT.Product"; int result = 1; try (Connection connection = DriverManager.getConnection(READ_WRITE_URL); Statement stmt = connection.createStatement(); ResultSet resultSet = stmt.executeQuery(sql)) { if (resultSet.next()) { result = resultSet.getInt(1); } } catch (Exception e) { e.printStackTrace(); } return result; } }Zapisz i zamknij plik App.java .
W konsoli poleceń uruchom następujące polecenie:
mvn packageUruchom aplikację, która będzie uruchamiana przez około 1 godzinę do czasu ręcznego zatrzymania, co pozwala na uruchomienie testu trybu failover.
mvn -q -e exec:java "-Dexec.mainClass=com.sqldbsamples.App"####################################### ## GEO DISTRIBUTED DATABASE TUTORIAL ## ####################################### 1. insert on primary successful, read from secondary successful 2. insert on primary successful, read from secondary successful 3. insert on primary successful, read from secondary successful ...
Testowanie pracy w trybie failover
Uruchom następujące skrypty, aby symulować tryb failover i obserwować wyniki aplikacji. Zwróć uwagę, że podczas migracji bazy danych niektóre operacje wstawiania i wybierania danych zakończą się niepowodzeniem.
Rolę serwera odzyskiwania po awarii można sprawdzić podczas testu za pomocą następującego polecenia:
(Get-AzSqlDatabaseFailoverGroup -FailoverGroupName $failoverGroup `
-ResourceGroupName $resourceGroup -ServerName $drServer).ReplicationRole
Aby przetestować przełączenie awaryjne:
Rozpocznij ręczne przełączenie grupy awaryjnej.
Switch-AzSqlDatabaseFailoverGroup -ResourceGroupName $resourceGroup ` -ServerName $drServer -FailoverGroupName $failoverGroupPrzywróć grupę failover do serwera podstawowego.
Switch-AzSqlDatabaseFailoverGroup -ResourceGroupName $resourceGroup ` -ServerName $server -FailoverGroupName $failoverGroup
Następne kroki
Przejrzyj listę kontrolną wysokiej dostępności i odzyskiwania po awarii.
Powiązana zawartość usługi Azure SQL Database:
- Ciągłość biznesowa
- Wysoka dostępność
- Grupy przełączania awaryjnego
- Aktywna replikacja geograficzna