Skalowanie w górę z Azure SQL Database
Dotyczy:![]() Azure SQL Database
Azure SQL Database
Bazy danych można łatwo skalować w usłudze Azure SQL Database przy użyciu narzędzi Elastic Database. Te narzędzia i funkcje umożliwiają korzystanie z zasobów bazy danych usługi Azure SQL Database do tworzenia rozwiązań dla obciążeń transakcyjnych, a zwłaszcza aplikacji SaaS (Software as a Service). Funkcje elastycznej bazy danych składają się z następujących elementów:
- Biblioteka klienta elastycznej bazy danych: biblioteka klienta to funkcja umożliwiająca tworzenie i konserwowanie baz danych podzielonych na fragmenty. Zobacz Wprowadzenie do narzędzi elastycznej bazy danych.
- Przenoszenie danych między skalowalnymi w poziomie bazami danych w chmurze: przenosi dane między podzielonymi na fragmenty bazami danych. To narzędzie jest przydatne do przenoszenia danych z bazy danych z wieloma najemcami do bazy danych z jednym najemcą (lub odwrotnie). Zobacz Wdróż usługę podziału i łączenia do przenoszenia danych między podzielonymi bazami danych.
- Zadania elastyczne w usłudze Azure SQL Database: zarządzanie dużą liczbą baz danych w usłudze Azure SQL Database przy użyciu zadań. Łatwo wykonywać operacje administracyjne, takie jak zmiany schematu, zarządzanie poświadczeniami, aktualizacje danych referencyjnych, zbieranie danych o wydajności czy zbieranie danych telemetrycznych najemcy przy użyciu zadań.
- Omówienie zapytań elastycznych usługi Azure SQL Database (wersja zapoznawcza) (wersja zapoznawcza): umożliwia uruchamianie zapytania Transact-SQL obejmującego wiele baz danych. Umożliwia to połączenie z narzędziami raportowania, takimi jak Excel, Power BI, Tableau itp.
- Transakcje rozproszone w bazach danych w chmurze: ta funkcja umożliwia uruchamianie transakcji obejmujących kilka baz danych. Transakcje elastycznej bazy danych są dostępne dla aplikacji .NET korzystających z platformy .NET ADO i integrują się ze znanym środowiskiem programowania przy użyciu klas System.Transaction.
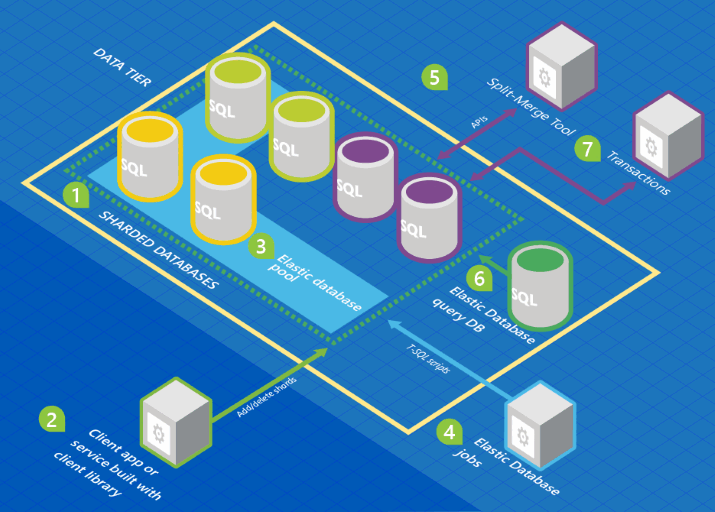
Na poniższej ilustracji przedstawiono architekturę obejmującą funkcje elastycznej bazy danych w odniesieniu do kolekcji baz danych.
Na tej ilustracji kolory bazy danych reprezentują schematy. Bazy danych o tym samym kolorze współużytkują ten sam schemat.
- Zestaw baz danych SQL jest hostowany na platformie Azure przy użyciu architektury fragmentowania.
- Biblioteka klienta Elastic Database służy do zarządzania zestawem fragmentów.
- Podzbiór baz danych jest umieszczany w elastycznej puli.
- Zadanie elastycznej bazy danych uruchamia skrypty języka T-SQL dla wszystkich baz danych.
- Narzędzie „split-merge” służy do przenoszenia danych z jednego shardu do innego.
- Zapytanie Elastic Database umożliwia napisanie zapytania obejmującego wszystkie bazy danych w całym zestawie shards.
- Elastyczne transakcje umożliwiają uruchamianie transakcji obejmujących kilka baz danych.
Dlaczego warto używać narzędzi?
Osiągnięcie elastyczności i skalowalności aplikacji w chmurze jest proste w przypadku maszyn wirtualnych i magazynowania blobów — wystarczy dodać lub odjąć jednostki albo zwiększyć moc. Pozostaje jednak wyzwaniem dla stanowego przetwarzania danych w relacyjnych bazach danych. W tych scenariuszach pojawiły się wyzwania:
- Rosnąca i zmniejszająca się pojemność dla części relacyjnej bazy danych obciążenia.
- Zarządzanie hotspotami, które mogą mieć wpływ na określony podzestaw danych, na przykład zajęty klient końcowy (najemca).
Tradycyjnie scenariusze takie jak te zostały rozwiązane przez inwestowanie w serwery o większej skali w celu obsługi aplikacji. Ta opcja jest jednak ograniczona w chmurze, w której wszystkie operacje przetwarzania odbywają się na wstępnie zdefiniowanym sprzęcie towarów. Zamiast tego dystrybucja danych i przetwarzania w wielu identycznych strukturalnych bazach danych (wzorzec skalowania w poziomie nazywany "fragmentowaniem") stanowi alternatywę dla tradycyjnych metod skalowania w górę zarówno pod względem kosztów, jak i elastyczności.
Skalowanie w poziomie i w pionie
Na poniższej ilustracji przedstawiono poziomy i pionowy wymiar skalowania, które są podstawowymi sposobami skalowania elastycznych baz danych.

Skalowanie w poziomie odnosi się do dodawania lub usuwania baz danych w celu dostosowania pojemności lub ogólnej wydajności, nazywane również "skalowaniem poziomym". Fragmentacja danych, w której dane są partycjonowane w kolekcji jednakowo ustrukturyzowanych baz danych, jest typowym sposobem implementowania skalowania w poziomie.
Skalowanie w pionie odnosi się do zwiększania lub zmniejszania rozmiaru obliczeniowego pojedynczej bazy danych, nazywanej również "skalowaniem w górę".
Większość aplikacji baz danych w skali chmury używa kombinacji tych dwóch strategii. Na przykład aplikacja Oprogramowanie jako usługa może używać skalowania w poziomie do aprowizowania nowych klientów końcowych i skalowania w pionie, aby umożliwić każdej bazie danych klienta końcowego zwiększanie lub zmniejszanie zasobów zgodnie z potrzebami obciążenia.
- Skalowanie w poziomie jest zarządzane przy użyciu biblioteki klienta elastic Database.
- Skalowanie w pionie odbywa się przy użyciu poleceń cmdlet programu Azure PowerShell w celu zmiany warstwy usługi lub umieszczania baz danych w elastycznej puli.
Szardowanie
Fragmentowanie to technika dystrybucji dużych ilości identycznych danych ustrukturyzowanych w wielu niezależnych bazach danych. Jest to szczególnie popularne wśród deweloperów rozwiązań w chmurze tworzących oferty saas (Software as a Service) dla klientów końcowych lub firm. Ci klienci końcowi są często nazywani „najemcami”. Fragmentowanie może być wymagane z różnych powodów:
- Łączna ilość danych jest zbyt duża, aby zmieścić się w ograniczeniach pojedynczej bazy danych
- Przepustowość transakcji całego obciążenia przekracza możliwości pojedynczej bazy danych
- Najemcy mogą wymagać fizycznej izolacji od siebie, więc oddzielne bazy danych są potrzebne dla każdego najemcy
- Różne sekcje bazy danych mogą wymagać przechowywania w różnych lokalizacjach geograficznych ze względów zgodności, wydajności lub geopolitycznych.
W innych scenariuszach, takich jak pozyskiwanie danych z urządzeń rozproszonych, fragmentowanie może służyć do wypełniania zestawu baz danych, które są zorganizowane czasowo. Na przykład oddzielna baza danych może być dedykowana dla każdego dnia lub tygodnia. W takim przypadku klucz fragmentowania może być liczbą całkowitą reprezentującą datę (obecną we wszystkich wierszach tabel podzielonych na fragmenty), a zapytania dotyczące pobierania informacji dla zakresu dat muszą być kierowane przez aplikację do podzbioru baz danych obejmujących kwestionowany zakres.
Fragmentowanie działa najlepiej, gdy każda transakcja w aplikacji może być ograniczona do pojedynczej wartości klucza fragmentowania. Dzięki temu wszystkie transakcje są lokalne dla określonej bazy danych.
Wielodostępność i jednodostępność
Niektóre aplikacje używają najprostszego podejścia do tworzenia oddzielnej bazy danych dla każdego klienta. Takie podejście jest wzorcem fragmentowania pojedynczej dzierżawy, który zapewnia izolację, możliwość tworzenia kopii zapasowych/przywracania i skalowanie zasobów na poziomie szczegółowości dzierżawy. W przypadku fragmentowania pojedynczej dzierżawy każda baza danych jest skojarzona z określoną wartością identyfikatora dzierżawy (lub wartością klucza klienta), ale ten klucz nie musi być obecny w samych danych. Obowiązkiem aplikacji jest kierowanie każdego żądania do odpowiedniej bazy danych — a biblioteka kliencka może uprościć to zadanie.

Inne scenariusze łączą wielu najemców do baz danych, zamiast izolować ich w oddzielne bazy danych. Ten wzorzec jest typowym wzorcem shardingu wielodostępnego — może to wynikać z faktu, że aplikacja zarządza dużą liczbą małych dzierżawców. We fragmentacji wielodostępnej wiersze w tabelach bazy danych są zaprojektowane do przechowywania klucza identyfikującego ID najemcy lub klucz fragmentacji. Ponownie warstwa aplikacji jest odpowiedzialna za kierowanie żądania dzierżawy do odpowiedniej bazy danych i może być obsługiwana przez elastyczną bibliotekę klienta bazy danych. Ponadto zabezpieczenia na poziomie wiersza mogą służyć do filtrowania wierszy, do których może uzyskać dostęp każdy klient — aby uzyskać szczegółowe informacje, zobacz Wielodostępne aplikacje z elastycznymi narzędziami bazy danych i zabezpieczeniami na poziomie wiersza. Ponowne rozmieszczenie danych między bazami danych może być potrzebne w przypadku wielodostępnego wzorca fragmentacji i jest wspomagane przez narzędzie do elastycznego podziału i scalania baz danych. Aby dowiedzieć się więcej na temat wzorców projektowania aplikacji SaaS korzystających z elastycznych pul, zobacz Multitenant SaaS database tenancy patterns (Wzorce dzierżawy wielodostępnych baz danych SaaS).
Przenoszenie danych z wielu baz danych do baz danych z pojedynczym najemcą
Podczas tworzenia aplikacji SaaS typowe jest oferowanie potencjalnym klientom wersji próbnej oprogramowania. W takim przypadku opłacalne jest użycie bazy danych wielodzierżawczej do przechowywania danych. Jednak gdy potencjalny klient staje się klientem, baza danych jednonajemcy jest lepsza, ponieważ zapewnia lepszą wydajność. Jeśli klient tworzy dane w okresie próbnym, użyj narzędzia do podziału i scalania, aby przenieść dane z bazy danych wielodzierżawowej do nowej bazy danych jednodzierżawowej.
Uwaga
Przywracanie z wielodostępnych baz danych do pojedynczego tenantu nie jest możliwe.
Przykłady i samouczki
Aby zapoznać się z przykładową aplikacją, która demonstruje bibliotekę klienta, zobacz Wprowadzenie do narzędzi elastycznej bazy danych.
Aby przekonwertować istniejące bazy danych na użycie narzędzi, zobacz Migrowanie istniejących baz danych w celu skalowania w poziomie.
Aby wyświetlić szczegóły puli elastycznej, zobacz Zagadnienia dotyczące cen i wydajności dla elastycznej puli, lub utwórz nową pulę za pomocą elastycznych pul.
Powiązana zawartość
Jeszcze nie korzystasz z narzędzi elastycznych baz danych? Zapoznaj się z naszym przewodnikiem Wprowadzenie. W przypadku pytań skontaktuj się z nami na stronie pytań i odpowiedzi dotyczących usługi SQL Database oraz w przypadku żądań funkcji, dodaj nowe pomysły lub zagłosuj na istniejące pomysły na forum opinii usługi SQL Database.