Projektowanie usług dostępnych globalnie przy użyciu usługi Azure SQL Database
Dotyczy: ![]() Azure SQL Database
Azure SQL Database
Podczas kompilowania i wdrażania usług w chmurze za pomocą usługi Azure SQL Database należy użyć aktywnej replikacji geograficznej lub grup trybu failover, aby zapewnić odporność na awarie regionalne i katastrofalne awarie. Ta sama funkcja umożliwia tworzenie globalnie rozproszonych aplikacji zoptymalizowanych pod kątem lokalnego dostępu do danych. W tym artykule omówiono typowe wzorce aplikacji, w tym korzyści i kompromisy poszczególnych opcji.
Uwaga
Jeśli używasz baz danych w warstwie Premium lub Krytyczne dla działania firmy i elastycznych pul, możesz uczynić je odpornymi na awarie regionalne, konwertując je na konfigurację wdrożenia strefowo nadmiarowego. Zobacz Bazy danych strefowo nadmiarowe.
Scenariusz 1: Używanie dwóch regionów świadczenia usługi Azure na potrzeby ciągłości działania z minimalnym przestojem
W tym scenariuszu aplikacje mają następujące cechy:
- Aplikacja jest aktywna w jednym regionie świadczenia usługi Azure
- Wszystkie sesje bazy danych wymagają dostępu do odczytu i zapisu (RW) do danych
- Warstwy sieci Web i warstwy danych należy połączyć, aby zmniejszyć opóźnienia i koszt ruchu
- Zasadniczo przestój jest większym ryzykiem biznesowym dla tych aplikacji niż utrata danych
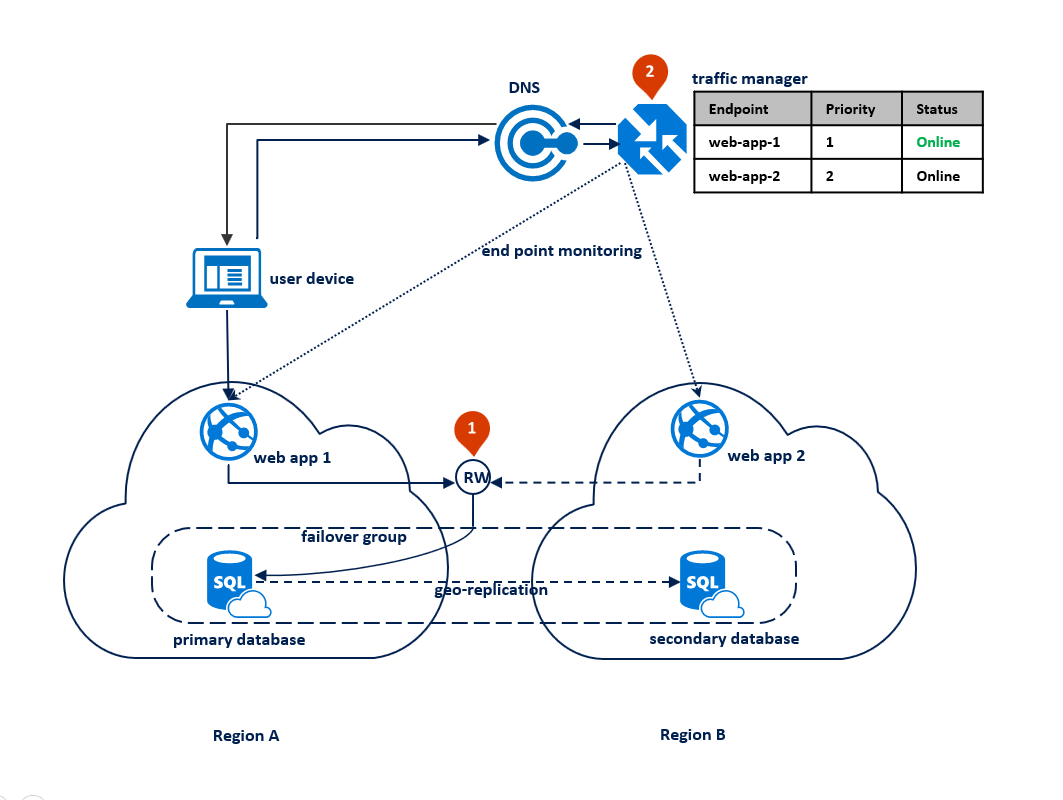
W takim przypadku topologia wdrażania aplikacji jest zoptymalizowana pod kątem obsługi regionalnych awarii, gdy wszystkie składniki aplikacji muszą przejść w tryb failover razem. Na poniższym diagramie przedstawiono tę topologię. W przypadku nadmiarowości geograficznej zasoby aplikacji są wdrażane w regionach A i B. Jednak zasoby w regionie B nie są używane do czasu awarii regionu A. Grupa trybu failover jest skonfigurowana między dwoma regionami w celu zarządzania łącznością z bazą danych, replikacją i trybem failover. Usługa sieci Web w obu regionach jest skonfigurowana do uzyskiwania dostępu do bazy danych za pośrednictwem odbiornika <odczytu i zapisu failover-group-name.database.windows.net> (1). Usługa Azure Traffic Manager jest skonfigurowana do używania metody routingu priorytetowego (2).
Uwaga
Usługa Azure Traffic Manager jest używana tylko w tym artykule do celów ilustracyjnych. Możesz użyć dowolnego rozwiązania do równoważenia obciążenia, które obsługuje metodę routingu priorytetowego.
Na poniższym diagramie przedstawiono tę konfigurację przed awarią:
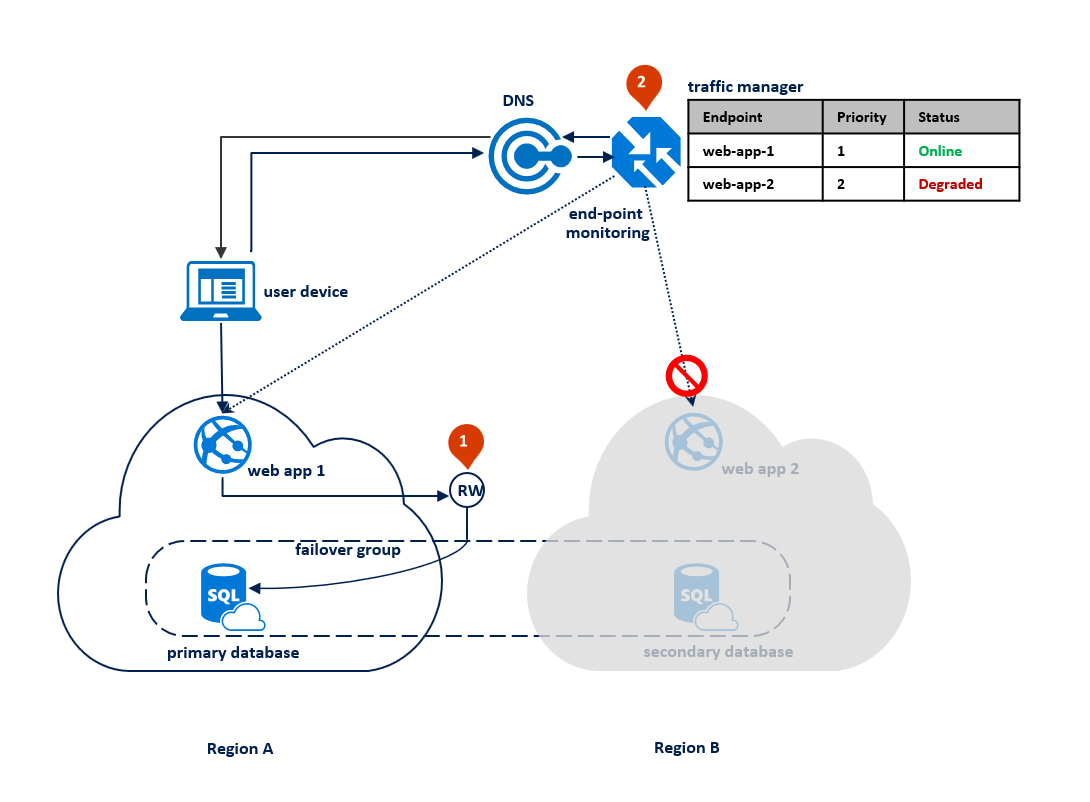
Po awarii w regionie podstawowym usługa SQL Database wykrywa, że podstawowa baza danych nie jest dostępna i wyzwala przejście w tryb failover do regionu pomocniczego na podstawie parametrów zasad automatycznego trybu failover (1). W zależności od umowy SLA aplikacji można skonfigurować okres prolongaty, który kontroluje czas między wykryciem awarii a samym przejściem w tryb failover. Istnieje możliwość, że usługa Azure Traffic Manager inicjuje tryb failover punktu końcowego przed wyzwoleniem trybu failover grupy trybu failover bazy danych. W takim przypadku aplikacja internetowa nie może natychmiast ponownie nawiązać połączenia z bazą danych. Jednak ponowne nawiązywanie połączeń zakończy się automatycznie po zakończeniu pracy w trybie failover bazy danych. Gdy region, w którym wystąpił błąd, zostanie przywrócony i przywrócony w trybie online, stary podstawowy automatycznie ponownie nawiąze połączenie jako nowe pomocnicze. Na poniższym diagramie przedstawiono konfigurację po przejściu w tryb failover.
Uwaga
Wszystkie transakcje zatwierdzone po przejściu w tryb failover zostaną utracone podczas ponownego nawiązywania połączenia. Po zakończeniu pracy w trybie failover aplikacja w regionie B może ponownie nawiązać połączenie i ponownie uruchomić przetwarzanie żądań użytkownika. Zarówno aplikacja internetowa, jak i podstawowa baza danych znajdują się teraz w regionie B i pozostają współlokowane.
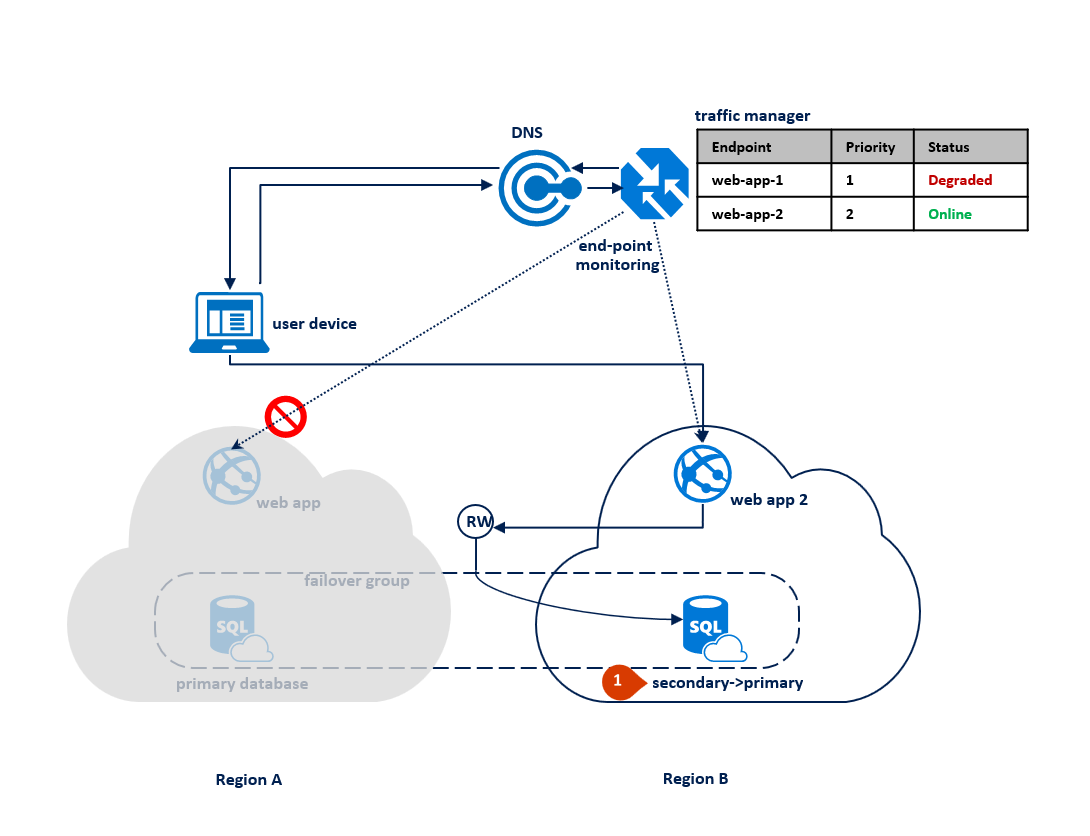
Jeśli wystąpi awaria w regionie B, proces replikacji między podstawową i pomocniczą bazą danych zostanie zawieszony, ale połączenie między nimi pozostanie nienaruszone (1). Usługa Traffic Manager wykrywa, że łączność z regionem B jest uszkodzona i oznacza aplikację internetową punktu końcowego 2 jako obniżoną wydajność (2). Wydajność aplikacji nie ma wpływu na tę sprawę, ale baza danych zostanie uwidoczniona i w związku z tym na większe ryzyko utraty danych w przypadku awarii regionu A z rzędu.
Uwaga
W przypadku odzyskiwania po awarii zalecamy konfigurację z wdrożeniem aplikacji ograniczonym do dwóch regionów. Wynika to z faktu, że większość lokalizacji geograficznych platformy Azure ma tylko dwa regiony. Ta konfiguracja nie chroni aplikacji przed równoczesną katastrofalną awarią obu regionów. W mało prawdopodobnym przypadku takiego błędu można odzyskać bazy danych w trzecim regionie przy użyciu operacji przywracania geograficznego. Aby uzyskać więcej informacji, zobacz Wskazówki dotyczące odzyskiwania po awarii usługi Azure SQL Database.
Po ograniczeniu awarii pomocnicza baza danych automatycznie ponownie synchronizuje się z bazą podstawową. Podczas synchronizacji może mieć to wpływ na wydajność podstawowej. Konkretny wpływ zależy od ilości danych pozyskanych przez nowy podstawowy od czasu przejścia w tryb failover.
Uwaga
Po ograniczeniu awarii usługa Traffic Manager rozpocznie routing połączeń z aplikacją w regionie A jako punkt końcowy o wyższym priorytecie. Jeśli zamierzasz zachować wartość podstawową w regionie B przez jakiś czas, należy odpowiednio zmienić tabelę priorytetu w profilu usługi Traffic Manager.
Na poniższym diagramie przedstawiono awarię w regionie pomocniczym:
Najważniejsze zalety tego wzorca projektowego to:
- Ta sama aplikacja internetowa jest wdrażana w obu regionach bez żadnej konfiguracji specyficznej dla regionu i nie wymaga dodatkowej logiki do zarządzania trybem failover.
- Wydajność aplikacji nie ma wpływu na tryb failover, ponieważ aplikacja internetowa i baza danych są zawsze współlokowane.
Głównym kompromisem jest to, że zasoby aplikacji w regionie B są niedostatecznie wykorzystywane przez większość czasu.
Scenariusz 2. Regiony świadczenia usługi Azure zapewniające ciągłość działalności biznesowej z maksymalnym zachowaniem danych
Ta opcja jest najbardziej odpowiednia dla aplikacji o następujących cechach:
- Każda utrata danych jest dużym ryzykiem biznesowym. Tryb failover bazy danych może być używany tylko w ostateczności, jeśli awaria jest spowodowana katastrofalnym niepowodzeniem.
- Aplikacja obsługuje tryby tylko do odczytu i zapisu operacji i może działać w trybie tylko do odczytu przez pewien czas.
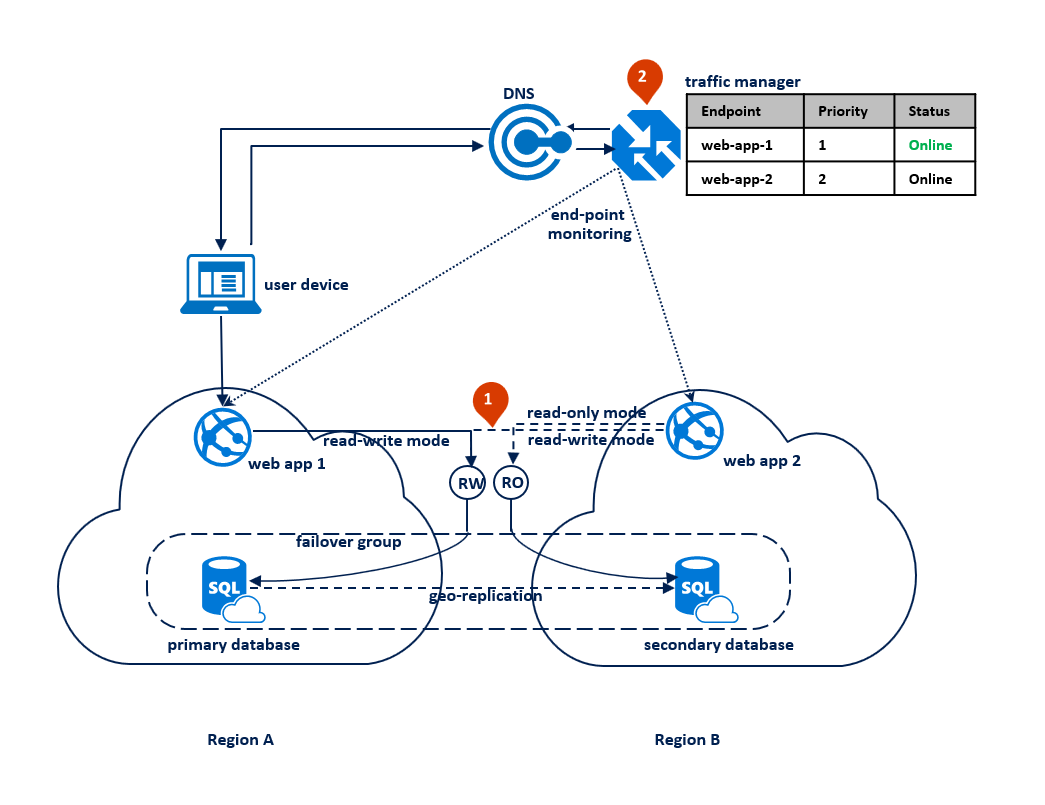
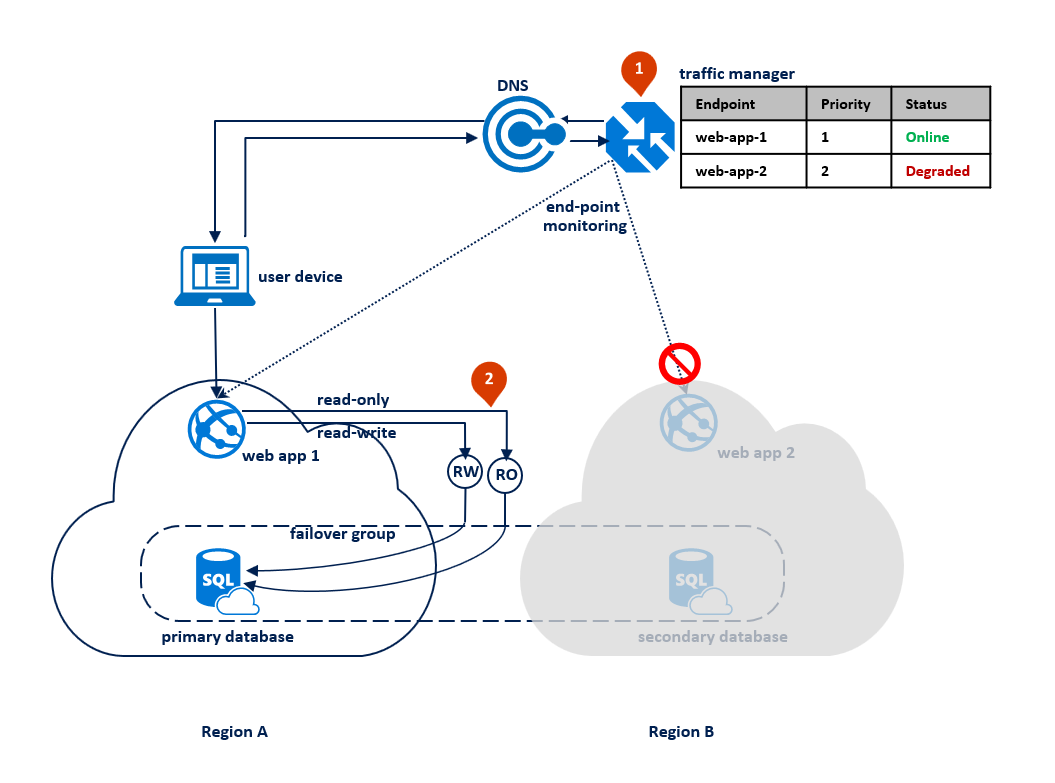
W tym wzorcu aplikacja przełącza się do trybu tylko do odczytu, gdy połączenia odczytu i zapisu zaczynają uzyskiwać błędy przekroczenia limitu czasu. Aplikacja internetowa jest wdrażana w obu regionach i zawiera połączenie z punktem końcowym odbiornika odczytu i zapisu oraz innym połączeniem z punktem końcowym odbiornika tylko do odczytu (1). Profil usługi Traffic Manager powinien używać routingu priorytetowego. Monitorowanie punktu końcowego powinno być włączone dla punktu końcowego aplikacji w każdym regionie (2).
Na poniższym diagramie przedstawiono tę konfigurację przed awarią:
Gdy usługa Traffic Manager wykryje błąd łączności z regionem A, automatycznie przełącza ruch użytkowników do wystąpienia aplikacji w regionie B. W przypadku tego wzorca ważne jest, aby ustawić okres prolongaty z utratą danych na wystarczająco wysoką wartość, na przykład 24 godziny. Gwarantuje to, że utrata danych jest zapobiegana, jeśli awaria zostanie zmniejszona w tym czasie. Gdy aplikacja internetowa w regionie B zostanie aktywowana, operacje odczytu i zapisu kończą się niepowodzeniem. W tym momencie należy przełączyć się na tryb tylko do odczytu (1). W tym trybie żądania są automatycznie kierowane do pomocniczej bazy danych. Jeśli awaria jest spowodowana katastrofalnym niepowodzeniem, najprawdopodobniej nie można go złagodzić w okresie prolongaty. Po wygaśnięciu grupy trybu failover wyzwala tryb failover. Gdy odbiornik odczytu i zapisu stanie się dostępny, a połączenia z nim przestaną się uruchomić (2). Na poniższym diagramie przedstawiono dwa etapy procesu odzyskiwania.
Uwaga
Jeśli awaria w regionie podstawowym zostanie złagodzony w okresie prolongaty, usługa Traffic Manager wykryje przywrócenie łączności w regionie podstawowym i przełącza ruch użytkowników z powrotem do wystąpienia aplikacji w regionie A. To wystąpienie aplikacji wznawia działanie w trybie odczytu i zapisu przy użyciu podstawowej bazy danych w regionie A, jak pokazano na poprzednim diagramie.
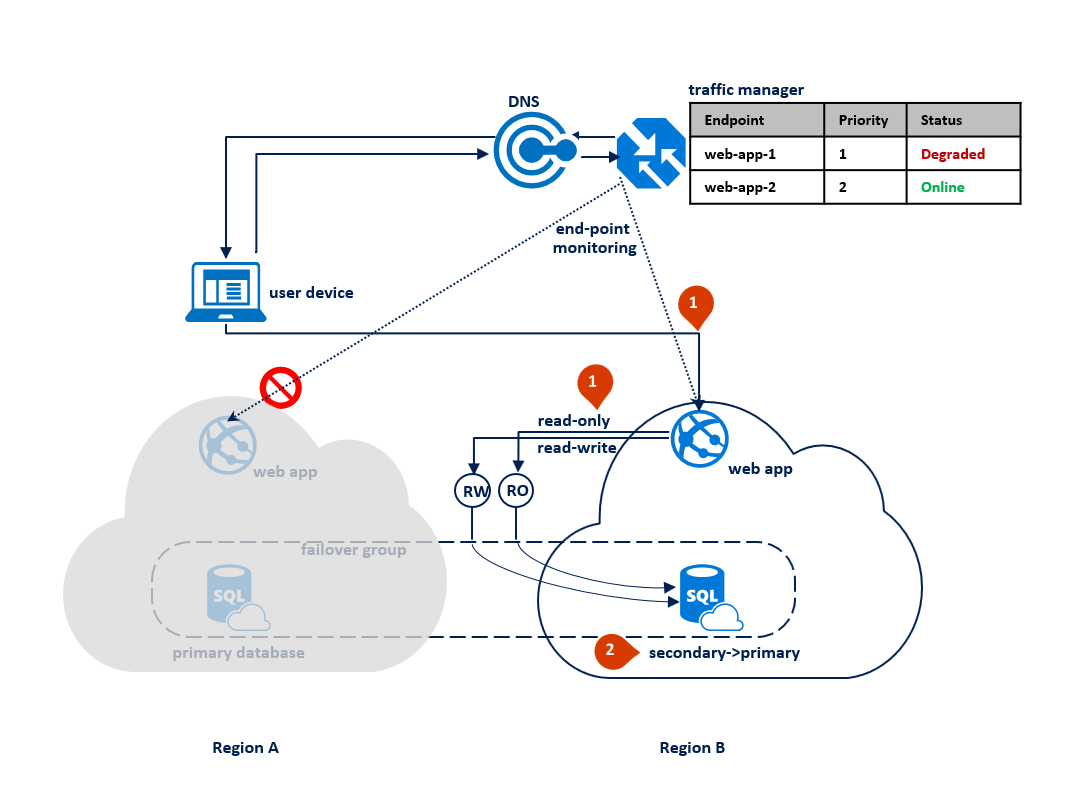
Jeśli awaria wystąpi w regionie B, usługa Traffic Manager wykryje awarię punktu końcowego web-app-2 w regionie B i oznacza jego obniżoną wydajność (1). W międzyczasie grupa trybu failover przełącza odbiornik tylko do odczytu do regionu A (2). Ta awaria nie ma wpływu na środowisko użytkownika końcowego, ale podstawowa baza danych jest uwidoczniona podczas awarii. Na poniższym diagramie przedstawiono błąd w regionie pomocniczym:
Po ograniczeniu awarii pomocnicza baza danych jest natychmiast synchronizowana z bazą podstawową, a odbiornik tylko do odczytu jest przełączany z powrotem do pomocniczej bazy danych w regionie B. Podczas synchronizacji wydajność podstawowej może mieć nieznaczny wpływ w zależności od ilości danych, które należy zsynchronizować.
Ten wzorzec projektowy ma kilka zalet:
- Zapobiega to utracie danych podczas tymczasowych przestojów.
- Przestój zależy tylko od tego, jak szybko usługa Traffic Manager wykrywa awarię łączności, którą można skonfigurować.
Kompromis polega na tym, że aplikacja musi mieć możliwość działania w trybie tylko do odczytu.
Planowanie ciągłości działania: wybierz projekt aplikacji na potrzeby odzyskiwania po awarii w chmurze
Konkretna strategia odzyskiwania po awarii w chmurze może łączyć lub rozszerzać te wzorce projektowe, aby najlepiej zaspokoić potrzeby aplikacji. Jak wspomniano wcześniej, wybrana strategia jest oparta na umowie SLA, którą chcesz zaoferować klientom i topologii wdrażania aplikacji. Aby ułatwić podjęcie decyzji, w poniższej tabeli porównano opcje na podstawie celu punktu odzyskiwania (RPO) i szacowany czas odzyskiwania (ERT).
| Wzorzec | RPO | ERT |
|---|---|---|
| Aktywne-pasywne wdrażanie na potrzeby odzyskiwania po awarii z dostępem do wspólnej bazy danych | Dostęp do < odczytu i zapisu 5 s | Czas wykrywania błędów i czas wygaśnięcia DNS |
| Wdrażanie aktywne-aktywne na potrzeby równoważenia obciążenia aplikacji | Dostęp do < odczytu i zapisu 5 s | Czas wykrywania błędów i czas wygaśnięcia DNS |
| Wdrażanie aktywne-pasywne na potrzeby zachowywania danych | Dostęp tylko do < odczytu 5 s | Dostęp tylko do odczytu = 0 |
| Dostęp do odczytu i zapisu = zero | Dostęp do odczytu i zapisu = czas wykrywania awarii i okres prolongaty z utratą danych |
Następne kroki
- Aby zapoznać się z omówieniem i scenariuszami ciągłości działalności biznesowej, zobacz Omówienie ciągłości działania
- Aby dowiedzieć się więcej o aktywnej replikacji geograficznej, zobacz Aktywna replikacja geograficzna.
- Aby dowiedzieć się więcej o grupach trybu failover, zobacz Grupy trybu failover.
- Aby uzyskać informacje na temat aktywnej replikacji geograficznej z elastycznymi pulami, zobacz Strategie odzyskiwania po awarii elastycznej puli.