Inteligentne aplikacje
Dotyczy: ![]() Baza danych SQL Usługi Azure SQL Database
Baza danych SQL Usługi Azure SQL Database ![]() w sieci szkieletowej
w sieci szkieletowej
Ten artykuł zawiera omówienie korzystania z opcji sztucznej inteligencji, takich jak OpenAI i wektory, w celu tworzenia inteligentnych aplikacji za pomocą usługi Azure SQL Database i usługi Fabric SQL Database, która udostępnia wiele z tych funkcji usługi Azure SQL Database.
Przykłady i przykłady można znaleźć w repozytorium Przykładów sztucznej inteligencji SQL.
Obejrzyj ten film wideo z serii Podstawy usługi Azure SQL Database, aby uzyskać krótkie omówienie tworzenia aplikacji gotowej do użycia sztucznej inteligencji :
Omówienie
Duże modele językowe (LLM) umożliwiają deweloperom tworzenie aplikacji opartych na sztucznej inteligencji ze znanym środowiskiem użytkownika.
Korzystanie z funkcji LLMs w aplikacjach zapewnia większą wartość i ulepszone środowisko użytkownika, gdy modele mogą uzyskiwać dostęp do odpowiednich danych w odpowiednim czasie z bazy danych aplikacji. Ten proces jest znany jako Pobieranie rozszerzonej generacji (RAG) i usługi Azure SQL Database i Fabric SQL Database mają wiele funkcji, które obsługują ten nowy wzorzec, dzięki czemu jest to świetna baza danych do tworzenia inteligentnych aplikacji.
Poniższe linki zawierają przykładowy kod różnych opcji tworzenia inteligentnych aplikacji:
| Opcja sztucznej inteligencji | opis |
|---|---|
| Azure OpenAI | Generuj osadzanie dla rozwiązania RAG i integruj się z dowolnym modelem obsługiwanym przez usługę Azure OpenAI. |
| Wektory | Dowiedz się, jak przechowywać wektory zapytań i wykonywać zapytania w bazie danych. |
| Azure AI Search | Użyj bazy danych razem z usługą Azure AI Search, aby wytrenować rozwiązanie LLM na danych. |
| Inteligentne aplikacje | Dowiedz się, jak utworzyć kompleksowe rozwiązanie przy użyciu wspólnego wzorca, który można replikować w dowolnym scenariuszu. |
| Umiejętności copilot w usłudze Azure SQL Database | Dowiedz się więcej o zestawie środowisk wspomaganych przez sztuczną inteligencję zaprojektowanych w celu usprawnienia projektowania, działania, optymalizacji i kondycji aplikacji opartych na usłudze Azure SQL Database. |
| Umiejętności copilot w usłudze Fabric SQL Database | Dowiedz się więcej o zestawie środowisk wspomaganych przez sztuczną inteligencję zaprojektowanych w celu usprawnienia projektowania, operacji, optymalizacji i kondycji aplikacji opartych na bazie danych SQL Fabric. |
Kluczowe pojęcia dotyczące implementowania rozwiązania RAG za pomocą usługi Azure OpenAI
Ta sekcja zawiera kluczowe pojęcia, które mają kluczowe znaczenie dla implementacji programu RAG za pomocą usługi Azure OpenAI w usłudze Azure SQL Database lub bazie danych SQL Fabric.
Pobieranie rozszerzonej generacji (RAG)
RAG to technika, która zwiększa zdolność LLM do tworzenia odpowiednich i informacyjnych odpowiedzi przez pobieranie dodatkowych danych ze źródeł zewnętrznych. Na przykład usługa RAG może wysyłać zapytania do artykułów lub dokumentów zawierających wiedzę specyficzną dla domeny związane z pytaniem lub monitem użytkownika. Usługa LLM może następnie użyć tych pobranych danych jako odwołania podczas generowania odpowiedzi. Na przykład prosty wzorzec RAG korzystający z usługi Azure SQL Database może być:
- Wstaw dane do tabeli.
- Łączenie usługi Azure SQL Database z usługą Azure AI Search.
- Utwórz model GPT4 usługi Azure OpenAI i połącz go z usługą Azure AI Search.
- Porozmawiaj i zadaj pytania dotyczące danych przy użyciu wytrenowanego modelu usługi Azure OpenAI z poziomu aplikacji i z usługi Azure SQL Database.
Wzorzec RAG, z monitem inżynieryjnym, służy do zwiększania jakości odpowiedzi, oferując bardziej kontekstowe informacje do modelu. Program RAG umożliwia modelowi zastosowanie szerszej bazy wiedzy poprzez włączenie odpowiednich źródeł zewnętrznych do procesu generowania, co skutkuje bardziej kompleksowymi i świadomymi odpowiedziami. Aby uzyskać więcej informacji na temat uziemienia LLMs, zobacz Grounding LLMs — Microsoft Community Hub.
Monity i monity inżynieryjne
Monit odnosi się do określonego tekstu lub informacji, które służą jako instrukcje dla usługi LLM lub jako danych kontekstowych, na których może opierać się usługa LLM. Monit może przyjmować różne formy, takie jak pytanie, instrukcja, a nawet fragment kodu.
Przykładowe monity, których można użyć do wygenerowania odpowiedzi z poziomu usługi LLM:
- Instrukcje: dostarczanie dyrektyw do usługi LLM
- Zawartość podstawowa: zawiera informacje dotyczące usługi LLM na potrzeby przetwarzania
- Przykłady: pomoc w warunku modelu dla określonego zadania lub procesu
- Wskazówki: kierowanie danych wyjściowych llM we właściwym kierunku
- Zawartość pomocnicza: reprezentuje informacje uzupełniające, których usługa LLM może używać do generowania danych wyjściowych
Proces tworzenia dobrych monitów dotyczących scenariusza jest nazywany inżynierią monitu. Aby uzyskać więcej informacji na temat monitów i najlepszych rozwiązań dotyczących inżynierii monitów, zobacz Azure OpenAI Service.
Tokeny
Tokeny są małymi fragmentami tekstu generowanymi przez podzielenie tekstu wejściowego na mniejsze segmenty. Te segmenty mogą być wyrazami lub grupami znaków, różniąc się długością od pojedynczego znaku do całego wyrazu. Na przykład słowo hamburger zostanie podzielone na tokeny, takie jak ham, bur, i ger choć krótkie i typowe słowo będzie pear traktowane jako pojedynczy token.
W usłudze Azure OpenAI tekst wejściowy udostępniany interfejsowi API jest przekształcany w tokeny (tokenizowane). Liczba tokenów przetwarzanych w każdym żądaniu interfejsu API zależy od czynników, takich jak długość parametrów wejściowych, wyjściowych i żądań. Ilość przetwarzanych tokenów wpływa również na czas odpowiedzi i przepływność modeli. Istnieją limity liczby tokenów, które każdy model może przyjąć w jednym żądaniu/odpowiedzi z usługi Azure OpenAI. Aby dowiedzieć się więcej, zobacz Limity przydziału i limity usługi Azure OpenAI.
Wektory
Wektory są uporządkowanymi tablicami liczb (zazwyczaj zmiennoprzecinkowymi), które mogą reprezentować informacje o niektórych danych. Na przykład obraz może być reprezentowany jako wektor wartości pikseli lub ciąg tekstu może być reprezentowany jako wektor lub wartości ASCII. Proces przekształcania danych w wektor jest nazywany wektoryzacją. Aby uzyskać więcej informacji, zobacz Vectors (Wektory).
Osadzanie
Osadzanie to wektory reprezentujące ważne funkcje danych. Osadzanie jest często używane przy użyciu modelu uczenia głębokiego, a modele uczenia maszynowego i sztucznej inteligencji wykorzystują je jako funkcje. Osadzanie może również przechwytywać semantyczną podobieństwo między podobnymi pojęciami. Na przykład podczas generowania osadzania dla wyrazów person i human, spodziewalibyśmy się, że ich osadzanie (reprezentacja wektorowa) będzie podobne w wartości, ponieważ wyrazy są również semantycznie podobne.
Modele funkcji usługi Azure OpenAI do tworzenia osadzania na podstawie danych tekstowych. Usługa dzieli tekst na tokeny i generuje osadzanie przy użyciu modeli wstępnie wytrenowanych przez interfejs OpenAI. Aby dowiedzieć się więcej, zobacz Tworzenie osadzania za pomocą usługi Azure OpenAI.
Wyszukiwanie wektorowe
Wyszukiwanie wektorowe odnosi się do procesu znajdowania wszystkich wektorów w zestawie danych, które są semantycznie podobne do określonego wektora zapytania. W związku z tym wektor zapytania dla wyrazu human wyszukuje cały słownik pod kątem semantycznie podobnych słów i powinien znaleźć słowo person jako bliskie dopasowanie. Ta bliskość lub odległość jest mierzona przy użyciu metryki podobieństwa, takiej jak podobieństwo cosinusu. Bliżej wektory znajdują się w podobieństwie, tym mniejsza jest odległość między nimi.
Rozważmy scenariusz, w którym uruchamiasz zapytanie dotyczące milionów dokumentów, aby znaleźć najbardziej podobne dokumenty w danych. Możesz tworzyć osadzanie dla danych i wykonywać zapytania dotyczące dokumentów przy użyciu usługi Azure OpenAI. Następnie możesz wykonać wyszukiwanie wektorów, aby znaleźć najbardziej podobne dokumenty z zestawu danych. Jednak wykonywanie wyszukiwania wektorowego w kilku przykładach jest proste. Wykonanie tego samego wyszukiwania w tysiącach lub milionach punktów danych staje się trudne. Istnieją również kompromisy między wyczerpującym wyszukiwaniem a przybliżonymi metodami wyszukiwania najbliższego sąsiada (ANN), w tym opóźnieniami, przepływnością, dokładnością i kosztami, z których wszystkie zależą od wymagań aplikacji.
Wektory w usłudze Azure SQL Database można efektywnie przechowywać i wykonywać zapytania zgodnie z opisem w następnych sekcjach, umożliwiając dokładne wyszukiwanie najbliższych sąsiadów z wielką wydajnością. Nie musisz decydować o dokładności i szybkości: możesz mieć obie te wartości. Przechowywanie osadzania wektorów wraz z danymi w zintegrowanym rozwiązaniu minimalizuje potrzebę zarządzania synchronizacją danych i przyspiesza czas opracowywania aplikacji sztucznej inteligencji.
Azure OpenAI
Osadzanie to proces reprezentowania świata rzeczywistego jako danych. Tekst, obrazy lub dźwięki można konwertować na osadzanie. Modele usługi Azure OpenAI umożliwiają przekształcanie rzeczywistych informacji w osadzanie. Modele są dostępne jako punkty końcowe REST i dlatego można je łatwo używać z usługi Azure SQL Database przy użyciu sp_invoke_external_rest_endpoint procedury składowanej systemu:
DECLARE @retval INT, @response NVARCHAR(MAX);
DECLARE @payload NVARCHAR(MAX);
SET @payload = JSON_OBJECT('input': @text);
EXEC @retval = sp_invoke_external_rest_endpoint @url = 'https://<openai-url>/openai/deployments/<model-name>/embeddings?api-version=2023-03-15-preview',
@method = 'POST',
@credential = [https://<openai-url>/openai/deployments/<model-name>],
@payload = @payload,
@response = @response OUTPUT;
SELECT CAST([key] AS INT) AS [vector_value_id],
CAST([value] AS FLOAT) AS [vector_value]
FROM OPENJSON(JSON_QUERY(@response, '$.result.data[0].embedding'));
Użycie wywołania usługi REST w celu pobrania osadzania jest tylko jedną z opcji integracji, które masz podczas pracy z usługami SQL Database i OpenAI. Dowolny z dostępnych modeli może uzyskiwać dostęp do danych przechowywanych w usłudze Azure SQL Database w celu utworzenia rozwiązań, w których użytkownicy mogą wchodzić w interakcje z danymi, na przykład w poniższym przykładzie.
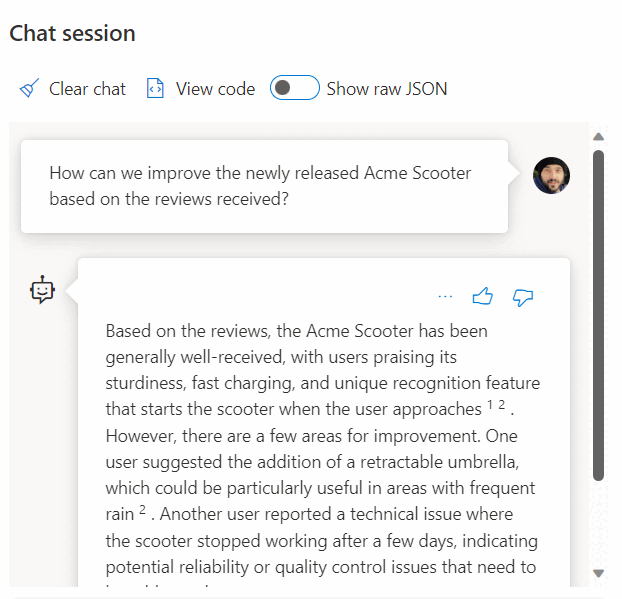
Aby uzyskać dodatkowe przykłady dotyczące korzystania z usług SQL Database i OpenAI, zobacz następujące artykuły:
- Generowanie obrazów za pomocą usługi Azure OpenAI Service (DALL-E) i usługi Azure SQL Database
- Używanie punktów końcowych REST interfejsu OpenAI z usługą Azure SQL Database
Wektory
Typ danych wektora
W listopadzie 2024 r. w usłudze Azure SQL Database wprowadzono nowy typ danych wektorów .
Dedykowany typ wektora umożliwia wydajne i zoptymalizowane przechowywanie danych wektorowych oraz zestaw funkcji ułatwia deweloperom usprawnianie implementacji wyszukiwania wektorów i podobieństw. Obliczanie odległości między dwoma wektorami można wykonać w jednym wierszu kodu przy użyciu nowej VECTOR_DISTANCE funkcji. Aby uzyskać więcej informacji na temat typu danych wektorów i powiązanych funkcji, zobacz Omówienie wektorów w a aparatu bazy danych SQL.
Na przykład:
CREATE TABLE [dbo].[wikipedia_articles_embeddings_titles_vector]
(
[article_id] [int] NOT NULL,
[embedding] [vector](1536) NOT NULL,
)
GO
SELECT TOP(10)
*
FROM
[dbo].[wikipedia_articles_embeddings_titles_vector]
ORDER BY
VECTOR_DISTANCE('cosine', @my_reference_vector, embedding)
Wektory w starszych wersjach programu SQL Server
Chociaż starsze wersje aparatu programu SQL Server, do i w tym programu SQL Server 2022, nie mają natywnego typu wektora , wektor nie jest czymś więcej niż uporządkowaną krotką, a relacyjne bazy danych doskonale nadają się do zarządzania krotkami. Krotkę można traktować jako formalny termin dla wiersza w tabeli.
Usługa Azure SQL Database obsługuje również indeksy magazynu kolumn i wykonywanie trybu wsadowego. Podejście oparte na wektorach jest używane do przetwarzania w trybie wsadowym, co oznacza, że każda kolumna w partii ma własną lokalizację pamięci, w której jest przechowywana jako wektor. Dzięki temu można szybciej i wydajniej przetwarzać dane w partiach.
W poniższym przykładzie pokazano, jak można przechowywać wektor w usłudze SQL Database:
CREATE TABLE [dbo].[wikipedia_articles_embeddings_titles_vector]
(
[article_id] [int] NOT NULL,
[vector_value_id] [int] NOT NULL,
[vector_value] [float] NOT NULL
)
GO
CREATE CLUSTERED COLUMNSTORE INDEX ixc
ON dbo.wikipedia_articles_embeddings_titles_vector
ORDER (article_id);
GO
Aby zapoznać się z przykładem, który używa wspólnego podzbioru artykułów Wikipedii z osadzanymi już wygenerowanymi przy użyciu interfejsu OpenAI, zobacz Wyszukiwanie podobieństwa wektorów w usługach Azure SQL Database i OpenAI.
Inną opcją korzystania z wyszukiwania wektorowego w bazie danych Azure SQL Database jest integracja z usługą Azure AI przy użyciu zintegrowanych możliwości wektoryzacji: wyszukiwanie wektorowe z usługą Azure SQL Database i usługą Azure AI Search
Wyszukiwanie AI platformy Azure
Zaimplementuj wzorce RAG za pomocą usług Azure SQL Database i Azure AI Search. Obsługiwane modele czatów można uruchamiać na danych przechowywanych w usłudze Azure SQL Database bez konieczności trenowania lub dostosowywania modeli dzięki integracji usługi Azure AI Search z usługami Azure OpenAI i Azure SQL Database. Uruchamianie modeli na danych umożliwia czatowanie na bieżąco i analizowanie danych z większą dokładnością i szybkością.
- Usługa Azure OpenAI na danych
- Pobieranie rozszerzonej generacji (RAG) w usłudze Azure AI Search
- Wyszukiwanie wektorowe przy użyciu usług Azure SQL Database i Azure AI Search
Inteligentne aplikacje
Usługa Azure SQL Database może służyć do tworzenia inteligentnych aplikacji, które obejmują funkcje sztucznej inteligencji, takie jak rekomendacje, i pobieranie rozszerzonej generacji (RAG), jak pokazano na poniższym diagramie:

Aby uzyskać kompleksowe przykładowe tworzenie aplikacji obsługującej sztuczną inteligencję przy użyciu sesji abstrakcyjnych jako przykładowego zestawu danych, zobacz:
- Jak skompilowałem moduł polecający sesję w ciągu 1 godziny przy użyciu interfejsu OpenAI.
- Korzystanie z rozszerzonej generacji pobierania w celu utworzenia asystenta sesji konferencyjnej
Integracja aplikacji LangChain
LangChain to dobrze znana platforma do tworzenia aplikacji opartych na modelach językowych. Przykłady pokazujące, jak można użyć biblioteki LangChain do utworzenia czatbota na własnych danych, zobacz:
- Tworzenie czatbota na własnych danych w ciągu 1 godziny przy użyciu usług Azure SQL, Langchain i Chainlit: tworzenie czatbota przy użyciu wzorca RAG na własnych danych przy użyciu biblioteki Langchain do organizowania wywołań LLM i chainlit dla interfejsu użytkownika.
- Tworzenie własnego rozwiązania DB Copilot dla usługi Azure SQL przy użyciu usługi Azure OpenAI GPT-4: Tworzenie środowiska przypominającego copilot w celu wykonywania zapytań dotyczących baz danych przy użyciu języka naturalnego.
Integracja jądra semantycznego
Semantyczne jądro to zestaw SDK typu open source, który umożliwia łatwe tworzenie agentów, którzy mogą wywoływać istniejący kod. Jako wysoce rozszerzalny zestaw SDK można używać semantycznego jądra z modelami z poziomu usług OpenAI, Azure OpenAI, Hugging Face i nie tylko! Łącząc istniejący kod C#, Python i Java z tymi modelami, możesz tworzyć agentów, którzy odpowiadają na pytania i automatyzują procesy.
- Ostateczny czatbot?: Tworzenie czatbota na własnych danych przy użyciu wzorców NL2SQL i RAG w celu uzyskania ostatecznego środowiska użytkownika.
- Przykład osadzania interfejsu OpenAI: przykład pokazujący, jak używać semantycznego jądra i pamięci jądra do pracy z osadzaniem w aplikacji platformy .NET przy użyciu programu SQL Server jako bazy danych wektora.
- Semantyczna pamięć jądra i jądra — łącznik SQL — zapewnia połączenie z bazą danych SQL dla jądra semantycznego dla pamięci.
Umiejętności platformy Microsoft Copilot w usłudze Azure SQL Database
Umiejętności firmy Microsoft Copilot w usłudze Azure SQL Database (wersja zapoznawcza) to zestaw środowisk wspomaganych przez sztuczną inteligencję zaprojektowanych w celu usprawnienia projektowania, operacji, optymalizacji i kondycji aplikacji opartych na usłudze Azure SQL Database. Copilot może zwiększyć produktywność, oferując język naturalny konwersji SQL i samodzielnej pomocy w zakresie administrowania bazą danych.
Copilot zapewnia odpowiednie odpowiedzi na pytania użytkowników, upraszczając zarządzanie bazami danych, korzystając z kontekstu bazy danych, dokumentacji, dynamicznych widoków zarządzania, magazynu zapytań i innych źródeł wiedzy. Na przykład:
- Administratorzy baz danych mogą niezależnie zarządzać bazami danych i rozwiązywać problemy lub dowiedzieć się więcej o wydajności i możliwościach bazy danych.
- Deweloperzy mogą zadawać pytania dotyczące swoich danych tak, jak w tekście lub konwersacji w celu wygenerowania zapytania T-SQL. Deweloperzy mogą również nauczyć się szybciej pisać zapytania dzięki szczegółowym objaśnieniom wygenerowanego zapytania.
Uwaga
Umiejętności firmy Microsoft Copilot w usłudze Azure SQL Database są obecnie dostępne w wersji zapoznawczej dla ograniczonej liczby wczesnych użytkowników. Aby zarejestrować się w tym programie, odwiedź stronę Request Access to Copilot in Azure SQL Database: Preview (Żądanie dostępu do aplikacji Copilot w usłudze Azure SQL Database: wersja zapoznawcza).
Wersja zapoznawcza narzędzia Copilot dla usługi Azure SQL Database obejmuje dwa środowiska witryny Azure Portal:
| Lokalizacja portalu | Środowiska |
|---|---|
| Edytor Power Query witryny Azure Portal | Język naturalny do języka SQL: to środowisko w edytorze zapytań witryny Azure Portal dla usługi Azure SQL Database tłumaczy zapytania języka naturalnego na język SQL, dzięki czemu interakcje z bazą danych są bardziej intuicyjne. Aby zapoznać się z samouczkiem i przykładami funkcji języka naturalnego do języka SQL, zobacz Język naturalny do języka SQL w edytorze zapytań w witrynie Azure Portal (wersja zapoznawcza). |
| Microsoft Copilot dla platformy Azure | Integracja z rozwiązaniem Azure Copilot: to środowisko dodaje umiejętności usługi Azure SQL do rozwiązania Microsoft Copilot dla platformy Azure, zapewniając klientom samodzielną pomoc, umożliwiając im zarządzanie bazami danych i samodzielne rozwiązywanie problemów. |
Aby uzyskać więcej informacji, zobacz Często zadawane pytania dotyczące umiejętności platformy Microsoft Copilot w usłudze Azure SQL Database (wersja zapoznawcza).
Umiejętności firmy Microsoft Copilot w usłudze Fabric SQL Database (wersja zapoznawcza)
Rozwiązanie Copilot dla bazy danych SQL w usłudze Microsoft Fabric (wersja zapoznawcza) obejmuje zintegrowaną pomoc dotyczącą sztucznej inteligencji z następującymi funkcjami:
Uzupełnianie kodu: Rozpoczęcie pisania języka T-SQL w edytorze zapytań SQL i Copilot automatycznie wygeneruje sugestię dotyczącą kodu, aby ułatwić ukończenie zapytania. Tab akceptuje sugestię kodu lub ciągle pisze, aby zignorować sugestię.
Szybkie akcje: na wstążce edytora zapytań SQL opcje Napraw i Wyjaśnij są szybkimi akcjami. Wyróżnij wybrane zapytanie SQL i wybierz jeden z przycisków szybkiej akcji, aby wykonać wybraną akcję w zapytaniu.
Poprawka: Copilot może naprawić błędy w kodzie w miarę pojawiania się komunikatów o błędach. Scenariusze błędów mogą zawierać niepoprawny/nieobsługiwany kod T-SQL, nieprawidłowe pisownie i nie tylko. Copilot udostępni również komentarze, które wyjaśniają zmiany i sugerują najlepsze rozwiązania dotyczące języka SQL.
Wyjaśnienie: Copilot może udostępniać wyjaśnienia języka naturalnego dotyczące zapytania SQL i schematu bazy danych w formacie komentarzy.
Okienko czatu: użyj okienka czatu, aby zadawać pytania do aplikacji Copilot za pomocą języka naturalnego. Copilot odpowiada za pomocą wygenerowanego zapytania SQL lub języka naturalnego na podstawie zadanego pytania.
Język naturalny do języka SQL: generowanie kodu T-SQL na podstawie żądań zwykłego tekstu i uzyskiwanie sugestii dotyczących pytań, które należy zadać, aby przyspieszyć przepływ pracy.
Pytania i odpowiedzi na podstawie dokumentów: zadaj pytanie Copilot dotyczące ogólnych możliwości bazy danych SQL i odpowiada w języku naturalnym. Copilot pomaga również znaleźć dokumentację związaną z twoim żądaniem.
Copilot dla bazy danych SQL korzysta z nazw tabel i widoków, nazw kolumn, klucza podstawowego i metadanych klucza obcego do generowania kodu T-SQL. Funkcja Copilot dla bazy danych SQL nie używa danych w tabelach do generowania sugestii języka T-SQL.
Powiązana zawartość
- Tworzenie i wdrażanie zasobu usługi Azure OpenAI Service
- Osadzanie modeli
- Przykłady i przykłady sztucznej inteligencji SQL
- Często zadawane pytania dotyczące umiejętności platformy Microsoft Copilot w usłudze Azure SQL Database (wersja zapoznawcza)
- Często zadawane pytania dotyczące odpowiedzialnej sztucznej inteligencji dla platformy Microsoft Copilot dla platformy Azure (wersja zapoznawcza)