Samouczek: synchronizowanie danych z usługi SQL Edge do usługi Azure Blob Storage przy użyciu usługi Azure Data Factory
Ważne
Usługa Azure SQL Edge zostanie wycofana 30 września 2025 r. Aby uzyskać więcej informacji i opcji migracji, zobacz powiadomienie o wycofaniu.
Uwaga
Usługa Azure SQL Edge nie obsługuje już platformy ARM64.
W tym samouczku pokazano, jak za pomocą usługi Azure Data Factory przyrostowo synchronizować dane z usługi Azure Blob Storage z tabeli w wystąpieniu usługi Azure SQL Edge.
Zanim rozpoczniesz
Jeśli baza danych lub tabela nie została jeszcze utworzona we wdrożeniu usługi Azure SQL Edge, utwórz jedną z następujących metod:
Użyj programu SQL Server Management Studio lub Azure Data Studio, aby nawiązać połączenie z usługą SQL Edge. Uruchom skrypt SQL, aby utworzyć bazę danych i tabelę.
Utwórz bazę danych i tabelę przy użyciu narzędzia sqlcmd , łącząc się bezpośrednio z modułem SQL Edge. Aby uzyskać więcej informacji, zobacz Nawiązywanie połączenia z aparatem bazy danych przy użyciu narzędzia sqlcmd.
Użyj SQLPackage.exe, aby wdrożyć plik pakietu DAC w kontenerze usługi SQL Edge. Ten proces można zautomatyzować, określając identyfikator URI pliku SqlPackage w ramach żądanej konfiguracji właściwości modułu. Możesz również bezpośrednio użyć narzędzia klienta SqlPackage.exe w celu wdrożenia pakietu DAC w usłudze SQL Edge.
Aby uzyskać informacje na temat pobierania SqlPackage.exe, zobacz Pobieranie i instalowanie pakietu sqlpackage. Poniżej przedstawiono kilka przykładowych poleceń dla SqlPackage.exe. Aby uzyskać więcej informacji, zobacz dokumentację SqlPackage.exe.
Tworzenie pakietu DAC
sqlpackage /Action:Extract /SourceConnectionString:"Data Source=<Server_Name>,<port>;Initial Catalog=<DB_name>;User ID=<user>;Password=<password>" /TargetFile:<dacpac_file_name>Stosowanie pakietu DAC
sqlpackage /Action:Publish /Sourcefile:<dacpac_file_name> /TargetServerName:<Server_Name>,<port> /TargetDatabaseName:<DB_Name> /TargetUser:<user> /TargetPassword:<password>
Tworzenie tabeli SQL i procedury do przechowywania i aktualizowania poziomów limitu
Tabela limitu służy do przechowywania znacznika czasu ostatniego, do którego dane zostały już zsynchronizowane z usługą Azure Storage. Procedura składowana języka Transact-SQL (T-SQL) służy do aktualizowania tabeli limitu po każdej synchronizacji.
Uruchom następujące polecenia w wystąpieniu usługi SQL Edge:
CREATE TABLE [dbo].[watermarktable] (
TableName VARCHAR(255),
WatermarkValue DATETIME,
);
GO
CREATE PROCEDURE usp_write_watermark @timestamp DATETIME,
@TableName VARCHAR(50)
AS
BEGIN
UPDATE [dbo].[watermarktable]
SET [WatermarkValue] = @timestamp
WHERE [TableName] = @TableName;
END
GO
Tworzenie potoku usługi Data Factory
W tej sekcji utworzysz potok usługi Azure Data Factory w celu zsynchronizowania danych z usługą Azure Blob Storage z tabeli w usłudze Azure SQL Edge.
Tworzenie fabryki danych przy użyciu interfejsu użytkownika usługi Data Factory
Utwórz fabrykę danych, postępując zgodnie z instrukcjami w tym samouczku.
Tworzenie potoku usługi Data Factory
Na stronie Wprowadzenie w interfejsie użytkownika usługi Data Factory wybierz pozycję Utwórz potok.

Na stronie Ogólne okna Właściwości potoku wprowadź nazwę PeriodicSync.
Dodaj działanie Lookup, aby uzyskać starą wartość limitu. W okienku Działania rozwiń węzeł Ogólne i przeciągnij działanie Lookup na powierzchnię projektanta potoku. Zmień nazwę działania na OldWatermark.
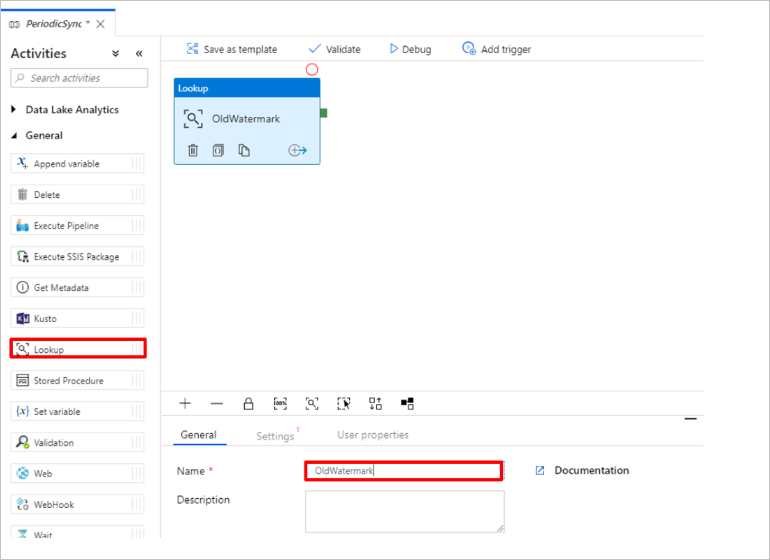
Przejdź do karty Ustawienia i wybierz pozycję Nowy dla zestawu danych źródłowych. Teraz utworzysz zestaw danych reprezentujący dane w tabeli limitu. Ta tabela zawiera stary limit, który był używany w poprzedniej operacji kopiowania.
W oknie Nowy zestaw danych wybierz pozycję Azure SQL Server, a następnie wybierz pozycję Kontynuuj.
W oknie Ustawianie właściwości zestawu danych w obszarze Nazwa wprowadź wartość WatermarkDataset.
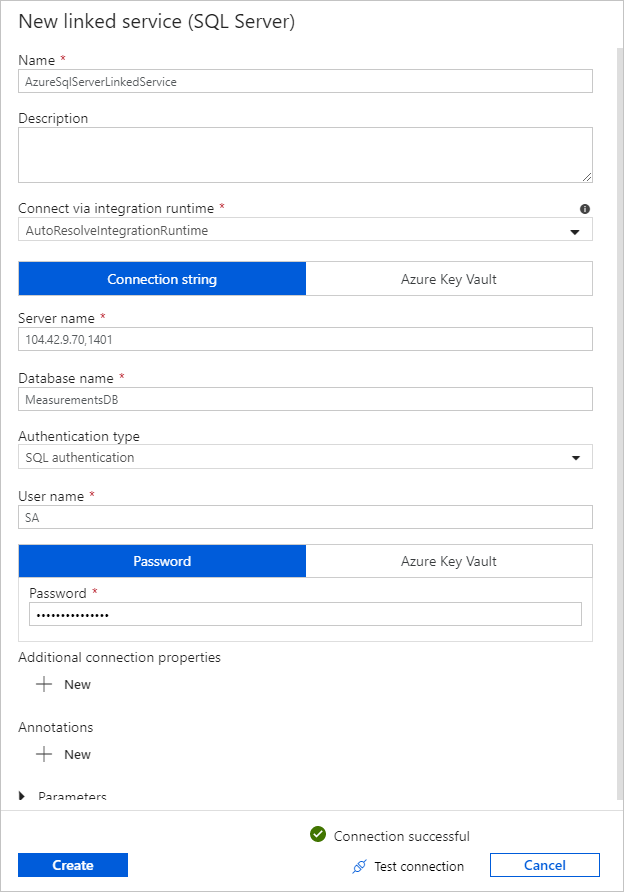
W obszarze Połączona usługa wybierz pozycję Nowa, a następnie wykonaj następujące kroki:
W obszarze Nazwa wprowadź wartość SQLDBEdgeLinkedService.
W obszarze Nazwa serwera wprowadź szczegóły serwera SQL Edge.
Wybierz swoją nazwę bazy danych z listy.
Wprowadź nazwę użytkownika i hasło.
Aby przetestować połączenie z wystąpieniem usługi SQL Edge, wybierz pozycję Testuj połączenie.
Wybierz pozycję Utwórz.
Wybierz przycisk OK.
Na karcie Ustawienia wybierz pozycję Edytuj.
Na karcie Połączenie wybierz pozycję
[dbo].[watermarktable]Tabela. Jeśli chcesz wyświetlić podgląd danych w tabeli, wybierz pozycję Podgląd danych.Przejdź do edytora potoku, wybierając kartę potoku u góry lub wybierając nazwę potoku w widoku drzewa po lewej stronie. W oknie właściwości działania Lookup upewnij się, że na liście źródłowych zestawów danych wybrano pozycję WatermarkDataset.
W okienku Działania rozwiń węzeł Ogólne i przeciągnij kolejne działanie Lookup na powierzchnię projektanta potoku. Ustaw nazwę na NewWatermark na karcie Ogólne okna właściwości. To działanie Odnośnik pobiera nową wartość limitu z tabeli zawierającej dane źródłowe, aby można je było skopiować do miejsca docelowego.
W oknie właściwości drugiego działania Lookup przejdź do karty Ustawienia i wybierz pozycję Nowy , aby utworzyć zestaw danych, aby wskazać tabelę źródłową zawierającą nową wartość limitu.
W oknie Nowy zestaw danych wybierz pozycję Wystąpienie usługi SQL Edge, a następnie wybierz pozycję Kontynuuj.
W oknie Ustawianie właściwości w obszarze Nazwa wprowadź wartość SourceDataset. W obszarze Połączona usługa wybierz pozycję SQLDBEdgeLinkedService.
W obszarze Tabela wybierz tabelę, którą chcesz zsynchronizować. Możesz również określić zapytanie dotyczące tego zestawu danych zgodnie z opisem w dalszej części tego samouczka. Zapytanie ma pierwszeństwo przed tabelą, którą określisz w tym kroku.
Wybierz przycisk OK.
Przejdź do edytora potoku, wybierając kartę potoku u góry lub wybierając nazwę potoku w widoku drzewa po lewej stronie. W oknie właściwości działania Lookup upewnij się, że na liście Zestaw danych źródłowych wybrano pozycję SourceDataset.
Wybierz pozycję Zapytanie w obszarze Użyj zapytania. Zaktualizuj nazwę tabeli w poniższym zapytaniu, a następnie wprowadź zapytanie. Wybierasz tylko maksymalną wartość
timestampz tabeli. Pamiętaj, aby wybrać tylko pierwszy wiersz.SELECT MAX(timestamp) AS NewWatermarkValue FROM [TableName];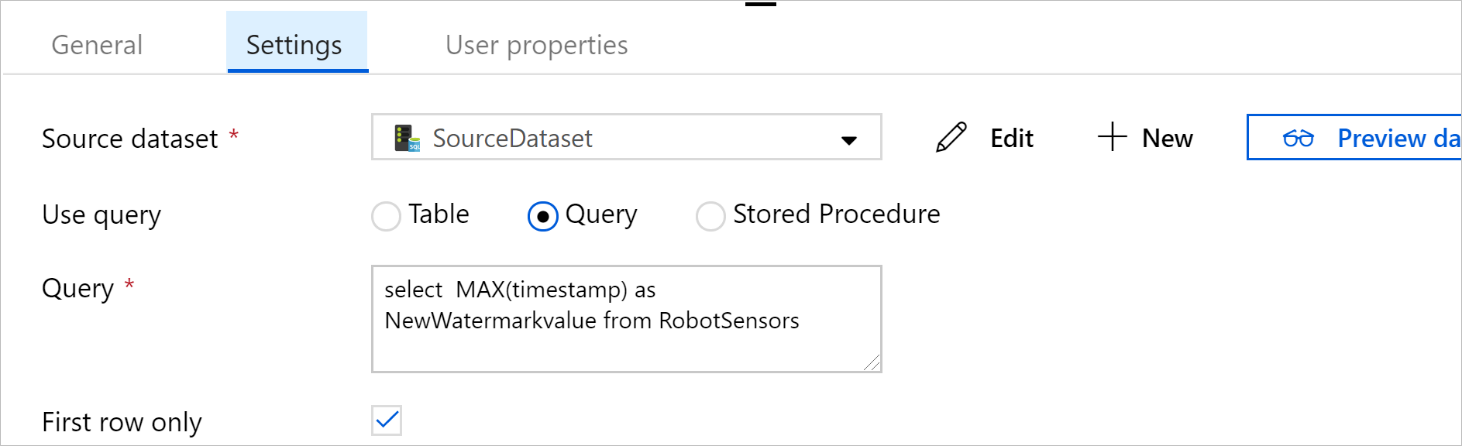
W okienku Działania rozwiń pozycję Przenieś i przekształć i przeciągnij działanie Kopiuj z okienka Działania do powierzchni projektanta. Ustaw nazwę działania na IncrementalCopy.
Połącz oba działania wyszukiwania z działaniem kopiowania, przeciągając do działania kopiowania zielony przycisk dołączony do działania wyszukiwania. Zwolnij przycisk myszy, gdy zobaczysz kolor obramowania działanie Kopiuj zmienić na niebieski.
Wybierz działanie Kopiuj i upewnij się, że właściwości działania są widoczne w oknie Właściwości.
Przejdź do karty Źródło w oknie Właściwości i wykonaj następujące kroki:
W polu Źródłowy zestaw danych wybierz pozycję SourceDataset.
W obszarze Użyj zapytania wybierz pozycję Zapytanie.
Wprowadź zapytanie SQL w polu Zapytanie . Oto przykładowe zapytanie:
SELECT * FROM TemperatureSensor WHERE timestamp > '@{activity(' OldWaterMark ').output.firstRow.WatermarkValue}' AND timestamp <= '@{activity(' NewWaterMark ').output.firstRow.NewWatermarkvalue}';Na karcie Ujście wybierz pozycję Nowy w obszarze Zestaw danych ujścia.
W tym samouczku magazyn danych ujścia jest magazynem danych usługi Azure Blob Storage. Wybierz pozycję Azure Blob Storage, a następnie wybierz pozycję Kontynuuj w oknie Nowy zestaw danych .
W oknie Wybieranie formatu wybierz format danych, a następnie wybierz pozycję Kontynuuj.
W oknie Ustawianie właściwości w obszarze Nazwa wprowadź wartość SinkDataset. W obszarze Połączona usługa wybierz pozycję Nowa. Teraz utworzysz połączenie (połączoną usługę) z usługą Azure Blob Storage.
W oknie Nowa połączona usługa (Azure Blob Storage) wykonaj następujące kroki:
W polu Nazwa wprowadź wartość AzureStorageLinkedService.
W obszarze Nazwa konta magazynu wybierz konto usługi Azure Storage dla subskrypcji platformy Azure.
Przetestuj połączenie, a następnie wybierz pozycję Zakończ.
W oknie Ustawianie właściwości upewnij się, że w obszarze Połączona usługa wybrano pozycję AzureStorageLinkedService. Wybierz pozycję Utwórz i OK.
Na karcie Ujście wybierz pozycję Edytuj.
Przejdź do karty Połączenie zestawu SinkDataset i wykonaj następujące kroki:
W obszarze Ścieżka pliku wprowadź wartość
asdedatasync/incrementalcopy, gdzieasdedatasyncjest nazwą kontenera obiektów blob iincrementalcopynazwą folderu. Utwórz kontener, jeśli nie istnieje lub użyj nazwy istniejącego kontenera. Usługa Azure Data Factory automatycznie tworzy folderincrementalcopywyjściowy, jeśli nie istnieje. Można również za pomocą przycisku Przeglądaj pola Ścieżka pliku przejść do folderu w kontenerze obiektów blob.W obszarze Plik ścieżki pliku wybierz pozycję Dodaj zawartość dynamiczną [Alt+P], a następnie wprowadź
@CONCAT('Incremental-', pipeline().RunId, '.txt')w wyświetlonym oknie. Wybierz Zakończ. Nazwa pliku jest generowana dynamicznie przez wyrażenie. Każde uruchomienie potoku ma unikatowy identyfikator. Działanie kopiowania używa identyfikatora uruchomienia do wygenerowania nazwy pliku.
Przejdź do edytora potoku, wybierając kartę potoku u góry lub wybierając nazwę potoku w widoku drzewa po lewej stronie.
W okienku Działania rozwiń węzeł Ogólne i przeciągnij działanie Procedura składowana z okienka Działania do powierzchni projektanta potoku. Połącz zielone (powodzenie) dane wyjściowe działanie Kopiuj z działaniem Procedura składowana.
Wybierz pozycję Działanie procedury składowanej w projektancie potoku i zmień jego nazwę na
SPtoUpdateWatermarkActivity.Przejdź do karty Konto SQL i wybierz pozycję *QLDBEdgeLinkedService w obszarze Połączona usługa.
Przejdź do karty Procedura składowana i wykonaj następujące kroki:
W obszarze Nazwa procedury składowanej wybierz pozycję
[dbo].[usp_write_watermark].Aby określić wartości parametrów procedury składowanej, wybierz pozycję Importuj parametr i wprowadź następujące wartości dla parametrów:
Nazwisko Typ Wartość LastModifiedTime DateTime @{activity('NewWaterMark').output.firstRow.NewWatermarkvalue}TableName String @{activity('OldWaterMark').output.firstRow.TableName}Aby zweryfikować ustawienia potoku, wybierz pozycję Weryfikuj na pasku narzędzi. Potwierdź, że weryfikacja nie zwróciła błędów. Aby zamknąć okno Raport weryfikacji potoku, wybierz pozycję >>.
Opublikuj jednostki (połączone usługi, zestawy danych i potoki) w usłudze Azure Data Factory, wybierając przycisk Opublikuj wszystko . Poczekaj, aż zostanie wyświetlony komunikat z potwierdzeniem, że operacja publikowania zakończyła się pomyślnie.
Wyzwalanie potoku na podstawie harmonogramu
Na pasku narzędzi potoku wybierz pozycję Dodaj wyzwalacz, wybierz pozycję Nowy/Edytuj, a następnie wybierz pozycję Nowy.
Nadaj wyzwalaczowi nazwę HourlySync. W obszarze Typ wybierz pozycję Harmonogram. Ustaw wartość Cykl co 1 godzinę.
Wybierz przycisk OK.
Wybierz pozycję Opublikuj wszystkie.
Wybierz pozycję Wyzwól teraz.
Przejdź do karty Monitorowanie po lewej stronie. Widoczny będzie stan uruchomienia potoku, który został wyzwolony za pomocą wyzwalacza ręcznego. Wybierz pozycję Odśwież, aby odświeżyć listę.
## Powiązana zawartość
- Potok usługi Azure Data Factory w tym samouczku kopiuje dane z tabeli w wystąpieniu usługi SQL Edge do lokalizacji w usłudze Azure Blob Storage co godzinę. Aby dowiedzieć się więcej o korzystaniu z usługi Data Factory w innych scenariuszach, zobacz te samouczki.