Omówienie języków woluminów w usłudze Azure NetApp Files
Język woluminu (podobnie jak ustawienia regionalne systemu w systemach operacyjnych klienta) w woluminie usługi Azure NetApp Files steruje obsługiwanymi językami i zestawami znaków podczas korzystania z protokołów NFS i SMB. Usługa Azure NetApp Files używa domyślnego języka woluminu C.UTF-8, który zapewnia kodowanie UTF-8 zgodne ze standardem POSIX dla zestawów znaków. Język C.UTF-8 natywnie obsługuje znaki o rozmiarze od 0 do 3 bajtów, który zawiera większość języków świata na płaszczyźnie wielojęzycznej (BMP) (w tym japoński, niemiecki i większość języków hebrajskich i cyrylica). Aby uzyskać więcej informacji na temat protokołu BMP, zobacz Unicode.
Znaki spoza protokołu BMP czasami przekraczają rozmiar 3 bajtów obsługiwany przez usługę Azure NetApp Files. W związku z tym muszą używać logiki par zastępczych, w której wiele zestawów bajtów znaków jest połączonych w celu utworzenia nowych znaków. Symbole emoji, na przykład, należą do tej kategorii i są obsługiwane w usłudze Azure NetApp Files w scenariuszach, w których kod UTF-8 nie jest wymuszany: takich jak klienci systemu Windows korzystający z kodowania UTF-16 lub NFSv3, który nie wymusza utF-8. System plików NFSv4.x wymusza utF-8, co oznacza, że znaki par zastępczych nie są prawidłowo wyświetlane podczas korzystania z systemu plików NFSv4.x.
Kodowanie niestandardowe, takie jak Shift-JIS i rzadziej spotykane znaki CJK, również nie są wyświetlane prawidłowo, gdy kod UTF-8 jest wymuszany w usłudze Azure NetApp Files.
Napiwek
Należy wysyłać i odbierać tekst przy użyciu protokołu UTF-8, aby uniknąć sytuacji, w których nie można poprawnie przetłumaczyć znaków, co może powodować błędy tworzenia/zmieniania nazwy pliku lub kopiowania.
Obecnie nie można modyfikować ustawień języka woluminów w usłudze Azure NetApp Files. Aby uzyskać więcej informacji, zobacz Zachowania protokołu ze specjalnymi zestawami znaków.
Aby uzyskać najlepsze rozwiązania, zobacz Najlepsze rozwiązania dotyczące zestawu znaków.
Kodowanie znaków w woluminach NFS i SMB usługi Azure NetApp Files
W środowisku udostępniania plików usługi Azure NetApp Files nazwy plików i folderów są reprezentowane przez serię znaków odczytywanych i interpretowanych przez użytkowników końcowych. Sposób wyświetlania tych znaków zależy od sposobu wysyłania i odbierania przez klienta kodowania tych znaków. Jeśli na przykład klient wysyła starsze kodowanie American Standard Code for Information Interchange (ASCII) do woluminu usługi Azure NetApp Files podczas uzyskiwania do niego dostępu, jest on ograniczony do wyświetlania tylko znaków obsługiwanych w formacie ASCII.
Na przykład japoński znak danych to 資. Ponieważ ten znak nie może być reprezentowany w ASCII, klient używający kodowania ASCII pokazuje znak "?" zamiast 資.
ASCII obsługuje tylko 95 znaków drukowalnych, głównie tych znajdujących się w języku angielskim. Każdy z tych znaków używa 1 bajtu, który jest uwzględniany w łącznej długości ścieżki pliku na woluminie usługi Azure NetApp Files. Ogranicza to internacjonalizację zestawów danych, ponieważ nazwy plików mogą mieć różne znaki, które nie są rozpoznawane przez ASCII, od japońskiego do cyrylica po emoji. Międzynarodowy standard (ISO/IEC 8859) próbował wspierać więcej znaków międzynarodowych, ale także miał swoje ograniczenia. Większość nowoczesnych klientów wysyła i odbiera znaki przy użyciu jakiejś formy Unicode.
Unicode
W wyniku ograniczeń kodowania ASCII i ISO/IEC 8859 standard Unicode został ustanowiony, aby każdy mógł wyświetlać język swojego regionu macierzystego z urządzeń.
- Kod Unicode obsługuje ponad milion zestawów znaków, zwiększając zarówno liczbę bajtów na znak dozwolony (do 4 bajtów), jak i łączną liczbę bajtów dozwolonych w ścieżce pliku, w przeciwieństwie do starszych kodowań, takich jak ASCII.
- Kod Unicode obsługuje zgodność z poprzednimi wersjami, rezerwując pierwsze 128 znaków dla ASCII, zapewniając jednocześnie, że pierwsze 256 punktów kodu jest identycznych ze standardami ISO/IEC 8859.
- W standardzie Unicode zestawy znaków są podzielone na płaszczyzny. Płaszczyzna to ciągła grupa 65 536 punktów kodu. W sumie istnieje 17 płaszczyzn (0-16) w standardzie Unicode. Limit wynosi 17 ze względu na ograniczenia utF-16.
- Płaszczyzna 0 to podstawowa wielojęzyczna płaszczyzna (BMP). Ta płaszczyzna zawiera najczęściej używane znaki w wielu językach.
- Spośród 17 płaszczyzn tylko pięć aktualnie przypisanych zestawów znaków jako Unicode w wersji 15.1.
- Samoloty 1-17 są znane jako dodatkowe samoloty wielojęzyczne (SMP) i zawierają mniej używane zestawy znaków, na przykład starożytne systemy pisania, takie jak cuneiform i hieroglyphs, a także specjalne znaki chińskie/japońskie/koreańskie (CJK).
- Aby zapoznać się z metodami, aby wyświetlić długości znaków i rozmiary ścieżek oraz kontrolować kodowanie wysyłane do systemu, zobacz Konwertowanie plików na różne kodowanie.
Unicode używa formatu Unicode Transformation Format jako standardu, a utF-8 i UTF-16 są dwoma głównymi formatami.
Płaszczyzny Unicode
Unicode wykorzystuje 17 płaszczyzn z 65 536 znakami (256 punktów kodu pomnożonych przez 256 pól w płaszczyźnie), z samolotem 0 jako podstawową wielojęzyczną płaszczyzną (BMP). Ta płaszczyzna zawiera najczęściej używane znaki w wielu językach. Ponieważ języki i zestawy znaków na świecie przekraczają 65536 znaków, do obsługi rzadziej używanych zestawów znaków potrzebna jest większa liczba płaszczyzn.
Na przykład Samolot 1 (dodatkowe samoloty wielojęzyczne (SMP) obejmuje historyczne skrypty, takie jak cuneiform i egipskie hieroglyphs, a także niektóre Osage, Warang Citi, Adlam, Wancho i Toto. Płaszczyzna 1 zawiera również niektóre symbole i znaki emotikonu .
Samolot 2 – dodatkowy samolot ideograficzne (SIP) — zawiera chińskie/japońskie/koreańskie (CJK) ujednolicone ideografy. Znaki w płaszczyznach 1 i 2 zazwyczaj mają rozmiar 4 bajty.
Na przykład:
- "uśmiechająca się twarz z wielkimi oczami" emotikon "😃" w samolocie 1 jest 4 bajty wielkości.
- Egipski hieroglyph "𓀀" w samolocie 1 ma rozmiar 4 bajty.
- Znak Osage "𐒸" w płaszczyźnie 1 ma rozmiar 4 bajty.
- Znak CJK "𫝁" w płaszczyźnie 2 ma rozmiar 4 bajty.
Ponieważ wszystkie te znaki mają rozmiar >3 bajty, wymagają one prawidłowego działania par zastępczych. Usługa Azure NetApp Files natywnie obsługuje pary zastępcze, ale wyświetlanie znaków różni się w zależności od używanego protokołu, ustawień regionalnych klienta i ustawień ustawień regionalnych aplikacji dostępu klienta zdalnego.
UTF-8
UtF-8 używa kodowania 8-bitowego i może mieć maksymalnie 112 064 punkty kodu (lub znaki). UTF-8 to standardowe kodowanie we wszystkich językach w systemach operacyjnych opartych na systemie Linux. Ponieważ kodowanie UTF-8 używa kodowania 8-bitowego, maksymalna liczba całkowita bez znaku to 255 (2^8– 1), która jest również maksymalną długością nazwy pliku dla tego kodowania. UtF-8 jest używany na ponad 98% stron w Internecie, dzięki czemu jest to zdecydowanie najbardziej przyjęty standard kodowania. Grupa robocza technologii aplikacji hipertekstowych sieci Web (WHATWG) uwzględnia kodowanie UTF-8 "obowiązkowe kodowanie dla wszystkich [tekstu]" i że ze względów bezpieczeństwa aplikacje przeglądarki nie powinny używać protokołu UTF-16.
Znaki w formacie UTF-8 używają od 1 do 4 bajtów, ale prawie wszystkie znaki we wszystkich językach używają od 1 do 3 bajtów. Przykład:
- Alfabet łaciński "A" używa 1 bajtu. (Jeden z 128 zastrzeżonych znaków ASCII)
- Symbol prawa autorskiego "©" używa 2 bajtów.
- Znak "ä" używa 2 bajtów. (1 bajt dla "a" + 1 bajt dla umlaut)
- Japoński symbol Kanji dla danych (資) używa 3 bajtów.
- Uśmiechnięty emoji twarzy (😃) używa 4 bajtów.
Ustawienia regionalne języka mogą używać standardowego formatu UTF-8 (C.UTF-8) lub większego formatu specyficznego dla regionu, takiego jak en_US. UTF-8, ja. UTF-8 itp. Podczas uzyskiwania dostępu do usługi Azure NetApp Files należy używać kodowania UTF-8 dla klientów z systemem Linux, gdy jest to możliwe. Od systemu OS X klienci systemu macOS używają również standardu UTF-8 do jego domyślnego kodowania i nie należy ich dostosowywać.
Klienci systemu Windows używają protokołu UTF-16. W większości przypadków to ustawienie powinno być pozostawione jako domyślne dla ustawień regionalnych systemu operacyjnego, ale nowi klienci oferują obsługę wersji beta dla znaków UTF-8 za pośrednictwem pola wyboru. Klienci terminali w systemie Windows można również dostosować do używania utF-8 w programie PowerShell lub CMD zgodnie z potrzebami. Aby uzyskać więcej informacji, zobacz Zachowania dwóch protokołów ze specjalnymi zestawami znaków.
UTF-16
UtF-16 używa kodowania 16-bitowego i może kodować wszystkie 112 064 punkty kodu Unicode. Kodowanie utF-16 może używać co najmniej jednej 16-bitowej jednostki kodu, z których każdy ma rozmiar 2 bajty. Wszystkie znaki w formacie UTF-16 używają 2 lub 4-bajtowych rozmiarów. Znaki w formacie UTF-16 używające 4 bajtów wykorzystują pary zastępcze, które łączą dwa oddzielne 2 bajty w celu utworzenia nowego znaku. Te dodatkowe znaki wykraczają poza standardowy samolot BMP i do jednego z innych wielojęzycznych samolotów.
UtF-16 jest używany w systemach operacyjnych Windows i interfejsach API, Java i JavaScript. Ponieważ nie obsługuje zgodności wstecznej z formatami ASCII, nigdy nie zyskał popularności w internecie. UTF-16 stanowi tylko około 0,002% wszystkich stron w Internecie. Grupa robocza technologii aplikacji hipertekstowych sieci Web (WHATWG) uwzględnia kodowanie UTF-8 "obowiązkowe kodowanie dla całego tekstu" i zaleca aplikacjom używanie protokołu UTF-16 do zabezpieczeń przeglądarki.
Usługa Azure NetApp Files obsługuje większość znaków UTF-16, w tym pary zastępcze. W przypadkach, gdy znak nie jest obsługiwany, klienci systemu Windows zgłaszają błąd "określona nazwa pliku jest nieprawidłowa lub za długa".
Obsługa zestawu znaków przez klientów zdalnych
Połączenia zdalne z klientami, którzy zainstalują woluminy usługi Azure NetApp Files (takie jak połączenia SSH z klientami systemu Linux w celu uzyskania dostępu do instalacji systemu plików NFS), można skonfigurować do wysyłania i odbierania określonych kodowań języka woluminu. Kodowanie języka wysyłane do klienta za pośrednictwem narzędzia połączenia zdalnego kontroluje sposób tworzenia i wyświetlania zestawów znaków. W związku z tym połączenie zdalne korzystające z innego kodowania języka niż inne połączenie zdalne (takie jak dwa różne okna PuTTY) może wyświetlać różne wyniki dla znaków podczas wyświetlania nazw plików i folderów w woluminie usługi Azure NetApp Files. W większości przypadków nie spowoduje to powstania rozbieżności (takich jak w przypadku znaków łacińskich/angielskich), ale w przypadku znaków specjalnych, takich jak emoji, wyniki mogą się różnić.
Na przykład użycie kodowania UTF-8 dla połączenia zdalnego pokazuje przewidywalne wyniki dla znaków w woluminach usługi Azure NetApp Files, ponieważ C.UTF-8 jest językiem woluminu. Japoński znak "data" (資) jest wyświetlany inaczej w zależności od kodowania wysyłanego przez terminal.
Kodowanie znaków w programie PuTTY
Gdy okno PuTTY używa formatu UTF-8 (znajdującego się w ustawieniach tłumaczenia systemu Windows), znak jest poprawnie reprezentowany dla zainstalowanego woluminu NFSv3 w usłudze Azure NetApp Files:

Jeśli w oknie PuTTY jest używane inne kodowanie, takie jak ISO-8859-1:1998 (Latin-1, Europa Zachodnia), ten sam znak jest wyświetlany inaczej, mimo że nazwa pliku jest taka sama.

PuTTY domyślnie nie zawiera kodowań CJK. Dostępne są poprawki umożliwiające dodanie tych zestawów języków do programu PuTTY.
Kodowanie znaków w usłudze Bastion
Platforma Microsoft Azure zaleca używanie usługi Bastion na potrzeby łączności zdalnej z maszynami wirtualnymi na platformie Azure. W przypadku korzystania z usługi Bastion kodowanie języka wysyłane i odbierane nie jest widoczne w konfiguracji, ale korzysta ze standardowego kodowania UTF-8. W związku z tym większość zestawów znaków widocznych w programie PuTTY korzystających z protokołu UTF-8 powinna być również widoczna w usłudze Bastion, pod warunkiem że zestawy znaków są obsługiwane w używanym protokole.

Napiwek
Inne terminale SSH mogą być używane, takie jak TeraTerm. TeraTerm udostępnia domyślnie szerszy zakres obsługiwanych zestawów znaków, w tym kodowanie CJK i niestandardowe kodowania, takie jak Shift-JIS.
Zachowania protokołu ze specjalnymi zestawami znaków
Woluminy usługi Azure NetApp Files używają kodowania UTF-8 i natywnie obsługują znaki, które nie przekraczają 3 bajtów. Wszystkie znaki w zestawach ASCII i UTF-8 są prawidłowo wyświetlane, ponieważ mieszczą się w zakresie od 1 do 3 bajtów. Na przykład:
- Znak alfabetu łacińskiego "A" używa 1 bajtu (jeden z 128 zastrzeżonych znaków ASCII).
- Symbol © prawa autorskiego używa 2 bajtów.
- Znak "ä" używa 2 bajtów (1 bajt dla "a" i 1 bajt dla umlaut).
- Japoński symbol Kanji dla danych (資) używa 3 bajtów.
Usługa Azure NetApp Files obsługuje również niektóre znaki, które przekraczają 3 bajty za pośrednictwem logiki par zastępczych (takich jak emoji), pod warunkiem, że kodowanie klienta i wersja protokołu obsługują je. Aby uzyskać więcej informacji na temat zachowań protokołu, zobacz:
Zachowania protokołu SMB
W woluminach SMB usługa Azure NetApp Files tworzy i przechowuje dwie nazwy plików lub katalogów w dowolnym katalogu, który ma dostęp z klienta SMB: oryginalna długa nazwa i nazwa w formacie 8.3.
Nazwy plików w usłudze SMB z usługą Azure NetApp Files
Gdy nazwy plików lub katalogów przekraczają dozwolone bajty znaków lub używają nieobsługiwanych znaków, usługa Azure NetApp Files generuje nazwę formatu 8.3 w następujący sposób:
- Obcina oryginalną nazwę pliku lub katalogu.
- Dołącza tyldę (~) i cyfrę (1–5) do nazw plików lub katalogów, które nie są już unikatowe po obcięciu. Jeśli istnieje więcej niż pięć plików o nazwach innych niż unikatowe, usługa Azure NetApp Files tworzy unikatową nazwę bez relacji z oryginalną nazwą. W przypadku plików usługa Azure NetApp Files obcina rozszerzenie nazwy pliku do trzech znaków.
Jeśli na przykład klient systemu plików NFS tworzy plik o nazwie specifications.html, usługa Azure NetApp Files tworzy nazwę specif~1.htm pliku w formacie 8.3. Jeśli ta nazwa już istnieje, usługa Azure NetApp Files używa innej liczby na końcu nazwy pliku. Jeśli na przykład klient NFS tworzy inny plik o nazwie specifications\_new.html, format 8.3 to specifications\_new.html specif~2.htm.
Znak specjalny w usłudze SMB za pomocą usługi Azure NetApp Files
W przypadku korzystania z protokołu SMB z woluminami usługi Azure NetApp Files znaki przekraczające 3 bajty używane w nazwach plików i folderów (w tym emotikony) mogą być dozwolone z powodu obsługi par zastępczych. Poniżej przedstawiono informacje wyświetlane w Eksploratorze Windows dla znaków spoza protokołu BMP w folderze utworzonym na podstawie klienta systemu Windows w przypadku używania języka angielskiego z domyślnym kodowaniem UTF-16.
Uwaga
Domyślną czcionką w Eksploratorze Windows jest interfejs użytkownika Segoe. Zmiany czcionek mogą mieć wpływ na sposób wyświetlania niektórych znaków na klientach.

Sposób wyświetlania znaków na kliencie zależy od czcionki systemowej oraz ustawień regionalnych i językowych. Ogólnie rzecz biorąc, znaki wchodzące w protokół BMP są obsługiwane we wszystkich protokołach, niezależnie od tego, czy kodowanie jest UTF-8 lub UTF-16.
W przypadku korzystania z narzędzia CMD lub programu PowerShell wyświetlanie zestawu znaków zależy od ustawień czcionki. Te narzędzia domyślnie mają ograniczone opcje czcionek. CmD używa consolas jako czcionki domyślnej.
Nazwy plików mogą nie być wyświetlane zgodnie z oczekiwaniami w zależności od czcionki używanej, ponieważ niektóre konsole nie obsługują natywnie interfejsu użytkownika Segoe ani innych czcionek, które poprawnie renderują znaki specjalne.
Ten problem można rozwiązać na klientach systemu Windows przy użyciu programu PowerShell ISE, który zapewnia bardziej niezawodną obsługę czcionek. Na przykład ustawienie programu PowerShell ISE na Segoe UI wyświetla nazwy plików z obsługiwanymi znakami prawidłowo.

Jednak program PowerShell ISE jest przeznaczony do tworzenia skryptów zamiast zarządzania udziałami. Nowsze wersje systemu Windows oferują Terminal Windows, co pozwala na kontrolę nad czcionkami i wartościami kodowania.
Uwaga
Użyj polecenia , chcp aby wyświetlić kodowanie dla terminalu. Aby uzyskać pełną listę stron kodu, zobacz Identyfikatory stron kodowych.

Jeśli wolumin jest włączony dla dwóch protokołów (zarówno NFS, jak i SMB), możesz obserwować różne zachowania. Aby uzyskać więcej informacji, zobacz Zachowania dwóch protokołów ze specjalnymi zestawami znaków.
Zachowania systemu plików NFS
Sposób wyświetlania znaków specjalnych systemu plików NFS zależy od używanej wersji systemu plików NFS, ustawień regionalnych klienta, zainstalowanych czcionek i ustawień używanego klienta połączenia zdalnego. Na przykład użycie usługi Bastion w celu uzyskania dostępu do znaku obsługi klienta systemu Ubuntu różni się od klienta Programu PuTTY ustawionego na inne ustawienia regionalne na tej samej maszynie wirtualnej. W poniższych przykładach systemu plików NFS są oparte na tych ustawieniach regionalnych dla maszyny wirtualnej z systemem Ubuntu:
~$ locale
LANG=C.UTF-8
LANGUAGE=
LC\_CTYPE="C.UTF-8"
LC\_NUMERIC="C.UTF-8"
LC\_TIME="C.UTF-8"
LC\_COLLATE="C.UTF-8"
LC\_MONETARY="C.UTF-8"
LC\_MESSAGES="C.UTF-8"
LC\_PAPER="C.UTF-8"
LC\_NAME="C.UTF-8"
LC\_ADDRESS="C.UTF-8"
LC\_TELEPHONE="C.UTF-8"
LC\_MEASUREMENT="C.UTF-8"
LC\_IDENTIFICATION="C.UTF-8"
LC\_ALL=
Zachowanie systemu plików NFSv3
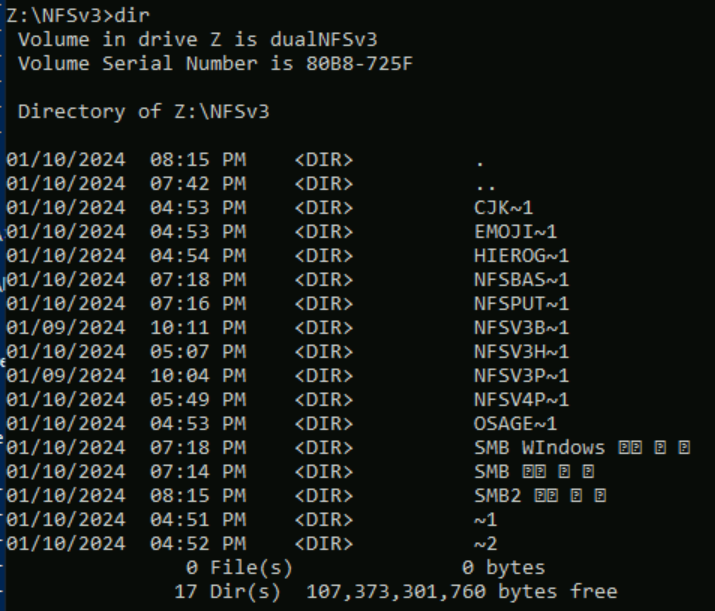
System plików NFSv3 nie wymusza kodowania UTF na plikach i folderach. W większości przypadków zestawy znaków specjalnych nie powinny mieć problemów. Jednak używany klient połączenia może mieć wpływ na sposób wysyłania i odbierania znaków. Na przykład użycie znaków Unicode spoza protokołu BMP dla nazwy folderu w usłudze Azure Connection Client Bastion może spowodować nieoczekiwane zachowanie ze względu na działanie kodowania klienta.
Na poniższym zrzucie ekranu usługa Bastion nie może skopiować i wkleić wartości do wiersza polecenia spoza przeglądarki podczas nazywania katalogu za pośrednictwem systemu plików NFSv3. Podczas próby skopiowania i wklejenia wartości NFSv3Bastion𓀀𫝁😃𐒸znaków specjalnych są wyświetlane jako znaki cudzysłowu w danych wejściowych.

Polecenie copy-paste jest dozwolone w systemie plików NFSv3, ale znaki są tworzone jako ich wartości liczbowe, wpływające na ich wyświetlanie:
NFSv3Bastion'$'\262\270\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355
Ten ekran jest spowodowany kodowaniem używanym przez usługę Bastion do wysyłania wartości tekstowych podczas kopiowania i wklejania.
W przypadku używania programu PuTTY do utworzenia folderu o tych samych znakach za pośrednictwem systemu plików NFSv3 nazwa folderu niż w usłudze Bastion niż w przypadku użycia usługi Bastion do jego utworzenia. Emotikon jest wyświetlany zgodnie z oczekiwaniami (ze względu na zainstalowane czcionki i ustawienia regionalne), ale inne znaki (takie jak Osage "𐒸") nie.

W oknie PuTTY znaki są wyświetlane poprawnie:

Zachowanie NFSv4.x
System plików NFSv4.x wymusza kodowanie UTF-8 w nazwach plików i folderów zgodnie ze specyfikacjami międzynarodowych RFC-8881.
W związku z tym, jeśli znak specjalny jest wysyłany z kodowaniem innych niż UTF-8, NFSv4.x może nie zezwalać na wartość.
W niektórych przypadkach polecenie może być dozwolone przy użyciu znaku poza podstawową wielojęzyczną płaszczyzną (BMP), ale może nie wyświetlać wartości po jej utworzeniu.
Na przykład wydawanie mkdir z nazwą folderu zawierającego znaki "𓀀𫝁😃𐒸" (znaki w dodatkowych płaszczyznach wielojęzycznych (SMP) i dodatkowej płaszczyzny ideograficznej (SIP)) wydaje się zakończyć się powodzeniem w systemie NFSv4.x. Folder nie będzie widoczny podczas uruchamiania ls polecenia.
root@ubuntu:/NFSv4/NFS$ mkdir "NFSv4 Putty 𓀀𫝁😃𐒸"
root@ubuntu:/NFSv4/NFS$ ls -la
total 8
drwxrwxr-x 3 nobody 4294967294 4096 Jan 10 17:15 .
drwxrwxrwx 4 root root 4096 Jan 10 17:15 ..
root@ubuntu:/NFSv4/NFS$
Folder istnieje w woluminie. Zmiana na tę ukrytą nazwę katalogu działa z klienta PuTTY, a plik można utworzyć wewnątrz tego katalogu.
root@ubuntu:/NFSv4/NFS$ cd "NFSv4 Putty 𓀀𫝁😃𐒸"
root@ubuntu:/NFSv4/NFS/NFSv4 Putty 𓀀𫝁😃𐒸$ sudo touch Unicode.txt
root@ubuntu:/NFSv4/NFS/NFSv4 Putty 𓀀𫝁😃𐒸$ ls -la
-rw-r--r-- 1 root root 0 Jan 10 17:31 Unicode.txt
Polecenie stat z programu PuTTY potwierdza również, że folder istnieje:
root@ubuntu:/NFSv4/NFS$ stat "NFSv4 Putty 𓀀𫝁😃𐒸"
**File: NFSv4 Putty** **𓀀**** 𫝁 ****😃**** 𐒸**
Size: 4096 Blocks: 8 IO Block: 262144 **directory**
Device: 3ch/60d Inode: 101 Links: 2
Access: (0775/drwxrwxr-x) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2024-01-10 17:15:44.860775000 +0000
Modify: 2024-01-10 17:31:35.049770000 +0000
Change: 2024-01-10 17:31:35.049770000 +0000
Birth: -
Mimo że folder jest potwierdzony, że istnieje, polecenia z symbolami wieloznacznymi nie działają, ponieważ klient nie może oficjalnie "zobaczyć" folderu na ekranie.
root@ubuntu:/NFSv4/NFS$ cp \* /NFSv3/
cp: can't stat '\*': No such file or directory
NFSv4.1 wysyła błąd do klienta, gdy napotka znak, który nie opiera się na kodowaniu UTF-8.
Na przykład w przypadku próby uzyskania dostępu do tego samego katalogu, który został utworzony przy użyciu programu PuTTY za pośrednictwem systemu plików NFSv4.1, jest to wynik:
root@ubuntu:/NFSv4/NFS$ cd "NFSv4 Putty 𓀀𫝁😃�"
-bash: cd: $'NFSv4 Putty \262\270\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355': Invalid argument
The "invalid argument" error message doesn't help diagnose the root cause, but a packet capture shines a light on the problem:
78 1.704856 y.y.y.y x.x.x.x NFS 346 V4 Call (Reply In 79) LOOKUP DH: 0x44caa451/NFSv4 Putty ��������
79 1.705058 x.x.x.x y.y.y.y NFS 166 V4 Reply (Call In 25) OPEN Status: NFS4ERR\_INVAL
NFS4ERR_INVAL jest omówiony w RFC-8881.
Ponieważ dostęp do folderu można uzyskać z programu PuTTY (ze względu na wysyłanie i odbieranie kodowania), można go skopiować, jeśli zostanie określona nazwa. Po skopiowaniu tego folderu z woluminu NFSv4.1 Usługi Azure NetApp Files do woluminu NFSv3 usługi Azure NetApp Files zostanie wyświetlona nazwa folderu:
root@ubuntu:/NFSv4/NFS$ cp -r /NFSv4/NFS/"NFSv4 Putty 𓀀𫝁😃𐒸" /NFSv3/NFSv3/
root@ubuntu:/NFSv4/NFS$ ls -la /NFSv3/NFSv3 | grep v4
drwxrwxr-x 2 root root 4096 Jan 10 17:49 NFSv4 Putty 𓀀𫝁😃𐒸
Ten sam NFS4ERR\_INVAL błąd można zobaczyć, jeśli podjęto próbę konwersji pliku (przy użyciu polecenia "iconv") do formatu innego niż UTF-8, takiego jak Shift-JIS.
# echo "Test file with SJIS encoded filename" \> "$(echo 'テストファイル.txt' | iconv -t SJIS)"
-bash: $(echo 'テストファイル.txt' | iconv -t SJIS): Invalid argument
Aby uzyskać więcej informacji, zobacz Konwertowanie plików na różne kodowanie.
Zachowania dwóch protokołów
Usługa Azure NetApp Files umożliwia dostęp do woluminów zarówno przez system plików NFS, jak i SMB za pośrednictwem dostępu za pomocą dwóch protokołów. Ze względu na ogromne różnice w kodowaniu języka używanym przez system plików NFS (UTF-8) i SMB (UTF-16), zestawy znaków, nazwy plików i folderów oraz długości ścieżek mogą mieć bardzo różne zachowania między protokołami.
Wyświetlanie plików i folderów utworzonych w systemie plików NFS z poziomu protokołu SMB
Gdy usługa Azure NetApp Files jest używana do dostępu za pomocą dwóch protokołów (SMB i NFS), zestaw znaków nieobsługiwany przez protokół UTF-16 może być używany w nazwie pliku utworzonej przy użyciu protokołu UTF-8 za pośrednictwem systemu plików NFS. W tych scenariuszach, gdy protokół SMB uzyskuje dostęp do pliku z nieobsługiwanymi znakami, nazwa jest obcięta w usłudze SMB przy użyciu konwencji krótkiej nazwy pliku w wersji 8.3.
Pliki utworzone przez NFSv3 i zachowania protokołu SMB z zestawami znaków
System plików NFSv3 nie wymusza kodowania UTF-8. Znaki używające niestandardowych kodowań języków (takich jak Shift-JIS) współpracują z usługą Azure NetApp Files podczas korzystania z systemu plików NFSv3.
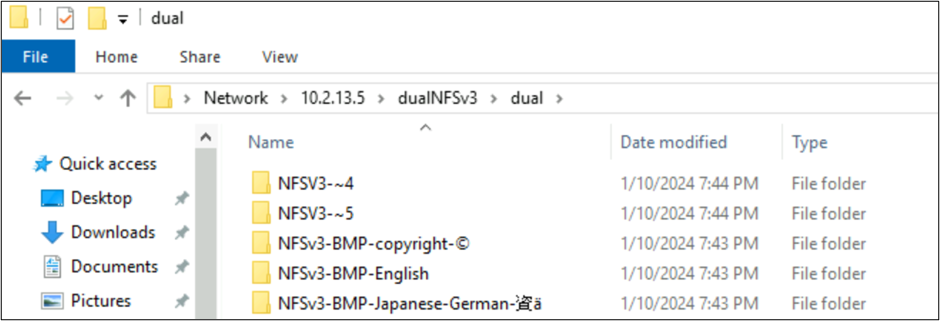
W poniższym przykładzie w woluminie usługi Azure NetApp Files utworzono serię nazw folderów używających różnych zestawów znaków z różnych płaszczyzn w formacie Unicode przy użyciu systemu plików NFSv3. Po wyświetleniu z systemu plików NFSv3 te są wyświetlane poprawnie.
root@ubuntu:/NFSv3/dual$ ls -la
drwxrwxr-x 2 root root 4096 Jan 10 19:43 NFSv3-BMP-English
drwxrwxr-x 2 root root 4096 Jan 10 19:43 NFSv3-BMP-Japanese-German-資ä
drwxrwxr-x 2 root root 4096 Jan 10 19:43 NFSv3-BMP-copyright-©
drwxrwxr-x 2 root root 4096 Jan 10 19:44 NFSv3-CJK-plane2-𫝁
drwxrwxr-x 2 root root 4096 Jan 10 19:44 NFSv3-emoji-plane1-😃
Z poziomu protokołu SMB systemu Windows foldery z znakami znajdującymi się w wyświetlaczu BMP są prawidłowo wyświetlane, ale znaki spoza tej płaszczyzny są wyświetlane w formacie nazwy 8.3 ze względu na niezgodność konwersji UTF-8/UTF-16.
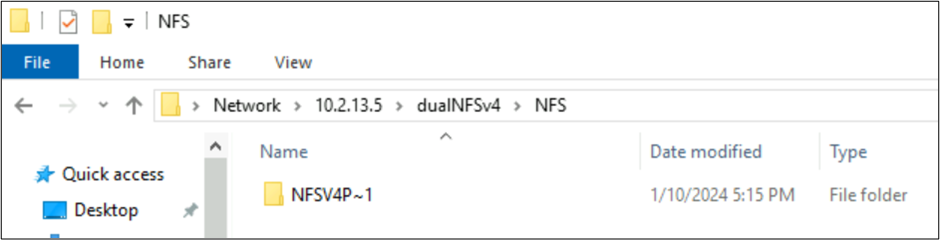
Pliki utworzone w systemie plików NFSv4.1 i zachowania protokołu SMB z zestawami znaków
W poprzednich przykładach folder o nazwie NFSv4 Putty 𓀀𫝁😃𐒸 został utworzony na woluminie usługi Azure NetApp Files za pośrednictwem systemu plików NFSv4.1, ale nie można go wyświetlić przy użyciu systemu plików NFSv4.1. Można go jednak zobaczyć przy użyciu protokołu SMB. Nazwa jest obcięta w SMB do obsługiwanego formatu 8.3 ze względu na nieobsługiwane zestawy znaków utworzone na podstawie klienta NFS i niezgodną konwersję UTF-8/UTF-16 dla znaków w różnych płaszczyznach Unicode.
Gdy nazwa folderu używa standardowych znaków UTF-8 znalezionych w BMP (angielski lub w inny sposób), protokół SMB tłumaczy nazwy prawidłowo.
root@ubuntu:/NFSv4/NFS$ mkdir NFS-created-English
root@ubuntu:/NFSv4/NFS$ mkdir NFS-created-資ä
root@ubuntu:/NFSv4/NFS$ ls -la
total 16
drwxrwxr-x 5 nobody 4294967294 4096 Jan 10 18:26 .
drwxrwxrwx 4 root root 4096 Jan 10 17:15 ..
**drwxrwxr-x 2 root root 4096 Jan 10 18:21 NFS-created-English**
**drwxrwxr-x 2 root root 4096 Jan 10 18:26 NFS-created-**** 資 ****ä**
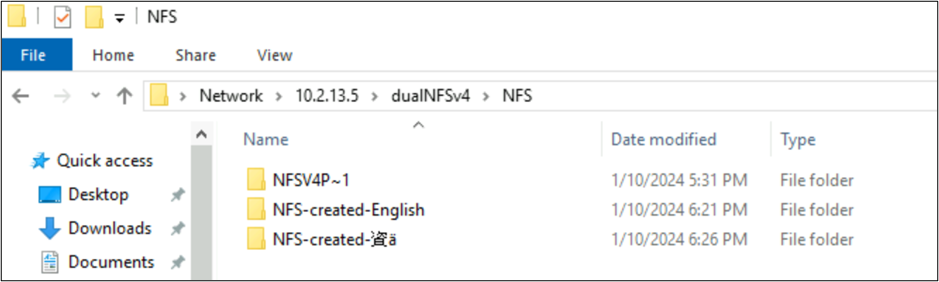
Pliki i foldery utworzone przez protokół SMB za pośrednictwem systemu plików NFS
Klienci systemu Windows to podstawowy typ klientów używanych do uzyskiwania dostępu do udziałów SMB. Ci klienci domyślnie mają kodowanie UTF-16. Istnieje możliwość obsługi niektórych znaków zakodowanych w formacie UTF-8 w systemie Windows, włączając je w ustawieniach regionu:
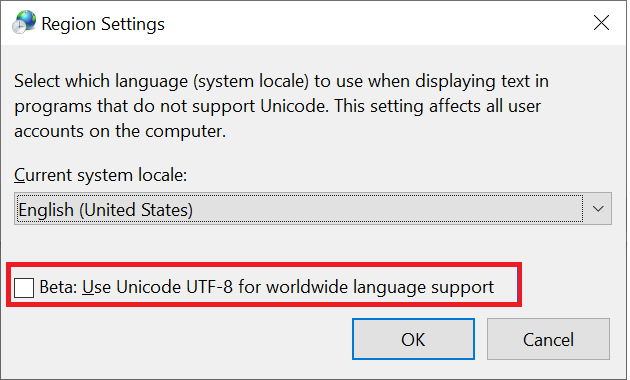
Po utworzeniu pliku lub folderu za pośrednictwem udziału SMB w usłudze Azure NetApp Files zestaw znaków koduje jako UTF-16. W związku z tym klienci korzystający z kodowania UTF-8 (np. klientów systemu plików NFS z systemem Linux) mogą nie być w stanie poprawnie przetłumaczyć niektórych zestawów znaków — szczególnie znaków, które wykraczają poza podstawową płaszczyznę wielojęzyczną (BMP).
Nieobsługiwane zachowanie znaków
W tych scenariuszach, gdy klient systemu plików NFS uzyskuje dostęp do pliku utworzonego przy użyciu protokołu SMB z nieobsługiwanymi znakami, nazwa jest wyświetlana jako seria wartości liczbowych reprezentujących wartości Unicode dla znaku.
Na przykład ten folder został utworzony w Eksploratorze Windows przy użyciu znaków spoza protokołu BMP.
PS Z:\SMB\> dir
Directory: Z:\SMB
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 1/9/2024 9:53 PM SMB𓀀𫝁😃𐒸
W systemie plików NFSv3 zostanie wyświetlony folder utworzony przez protokół SMB:
$ ls -la
drwxrwxrwx 2 root daemon 4096 Jan 9 21:53 'SMB'$'\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355\262\270'
W systemie plików NFSv4.1 folder utworzony przez protokół SMB jest wyświetlany w następujący sposób:
$ ls -la
drwxrwxrwx 2 root daemon 4096 Jan 4 17:09 'SMB'$'\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355\262\270'
Obsługiwane zachowanie znaków
Gdy znaki znajdują się w protokole BMP, nie ma problemów między protokołami SMB i NFS i ich wersjami.
Na przykład nazwa folderu utworzona przy użyciu protokołu SMB w woluminie usługi Azure NetApp Files z znakami znajdującymi się w usłudze BMP w wielu językach (angielski, niemiecki, cyrylica, Runic) jest wyświetlana poprawnie we wszystkich protokołach i wersjach.
- Podstawowa łacińska "SMB"
- Grecki "ͶΘΩ"
- Cyrylica "ЄЊ"
- Runic "ᚠᚱᛯ"
- CJK Compatibility Ideographs "豈滑虜"
W ten sposób nazwa jest wyświetlana w usłudze SMB:
PS Z:\SMB\> mkdir SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 1/11/2024 8:00 PM SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
W ten sposób nazwa jest wyświetlana z systemu plików NFSv3:
$ ls | grep SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
W ten sposób nazwa jest wyświetlana z systemu plików NFSv4.1:
$ ls /NFSv4/SMB | grep SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
Konwertowanie plików na różne kodowanie
Nazwy plików i folderów nie są jedyną częścią obiektów systemu plików korzystających z kodowania języka. Zawartość pliku (na przykład znaki specjalne wewnątrz pliku tekstowego) może również odgrywać rolę. Jeśli na przykład plik zostanie zapisany ze znakami specjalnymi w niezgodnym formacie, może zostać wyświetlony komunikat o błędzie. W takim przypadku nie można zapisać pliku z znakami Katagana w usłudze ANSI, ponieważ te znaki nie istnieją w tym kodowaniu.
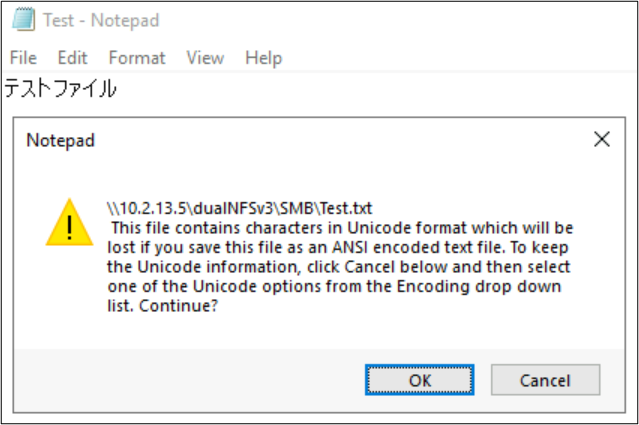
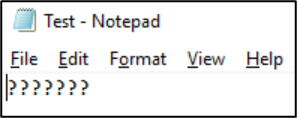
Po zapisaniu tego pliku w tym formacie znaki są konwertowane na znaki zapytania:
Kodowanie plików można wyświetlać z poziomu klientów NAS. Na klientach z systemem Windows można użyć aplikacji, takiej jak Notatnik lub Notatnik++, aby wyświetlić kodowanie pliku. Jeśli Podsystem Windows dla systemu Linux (WSL) lub Git są zainstalowane na kliencie, file można użyć polecenia .
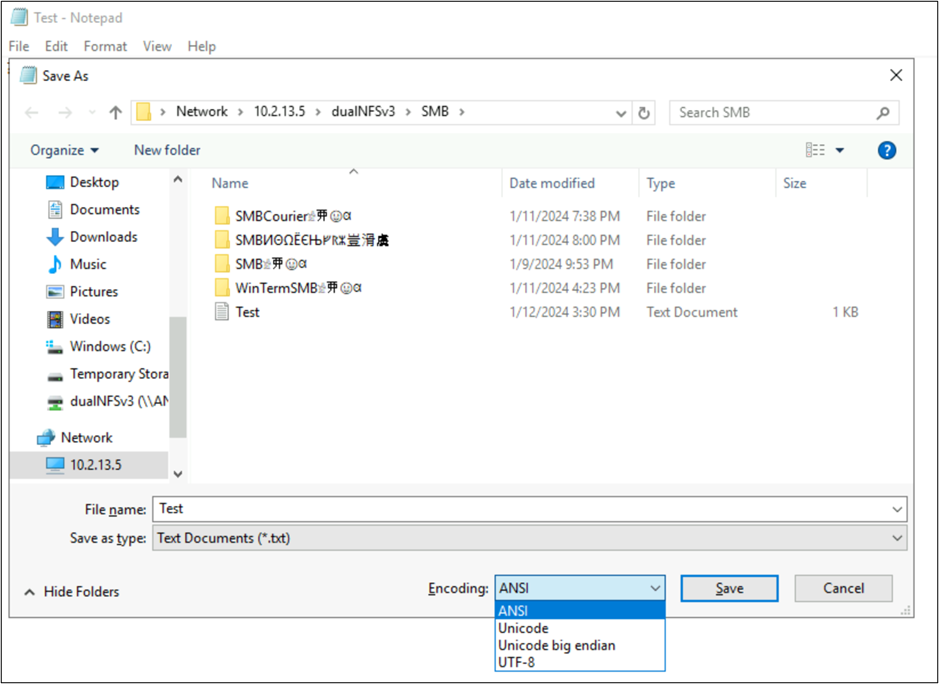
Te aplikacje umożliwiają również zmianę kodowania pliku przez zapisanie ich jako różnych typów kodowania. Ponadto program PowerShell może służyć do konwertowania kodowania na pliki za Get-Content pomocą poleceń cmdlet i Set-Content .
Na przykład plik utf8-text.txt jest zakodowany jako UTF-8 i zawiera znaki poza BMP. Ponieważ używany jest kod UTF-8, znaki są wyświetlane prawidłowo.
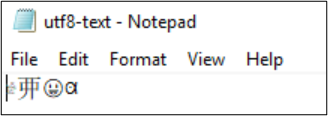
Jeśli kodowanie jest konwertowane na utF-32, znaki nie są wyświetlane poprawnie.
PS Z:\SMB\> Get-Content .\utf8-text.txt |Set-Content -Encoding UTF32 -Path utf32-text.txt
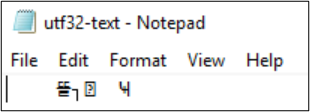
Get-Content można również użyć do wyświetlania zawartości pliku. Domyślnie program PowerShell używa kodowania UTF-16 (strona kodowa 437), a opcje czcionek dla konsoli są ograniczone, więc plik sformatowany za pomocą znaków specjalnych UTF-8 nie może być poprawnie wyświetlany:
Klienci systemu Linux mogą używać file polecenia , aby wyświetlić kodowanie pliku. W środowiskach z podwójnym protokołem, jeśli plik jest tworzony przy użyciu protokołu SMB, klient systemu Linux korzystający z systemu plików NFS może sprawdzić kodowanie plików.
$ file -i utf8-text.txt
utf8-text.txt: text/plain; charset=utf-8
$ file -i utf32-text.txt
utf32-text.txt: text/plain; charset=utf-32le
Konwersję kodowania plików można wykonać na klientach z systemem Linux za pomocą iconv polecenia . Aby wyświetlić listę obsługiwanych formatów kodowania, użyj polecenia iconv -l.
Na przykład kodowany plik UTF-8 można przekonwertować na utF-16.
$ iconv -t UTF16 utf8-text.txt \> utf16-text.txt
$ file -i utf8-text.txt
utf8-text.txt: text/plain; **charset=utf-8**
$ file -i utf16-text.txt
utf16-text.txt: text/plain; **charset=utf-16le**
Jeśli znak ustawiony na nazwie pliku lub w zawartości pliku nie jest obsługiwany przez kodowanie docelowe, konwersja nie jest dozwolona. Na przykład shift-JIS nie może obsługiwać znaków w zawartości pliku.
$ iconv -t SJIS utf8-text.txt SJIS-text.txt
iconv: illegal input sequence at position 0
Jeśli plik zawiera znaki obsługiwane przez kodowanie, konwersja powiedzie się. Jeśli na przykład plik zawiera znaki Katagana テストファイ potrzeby, konwersja Shift-JIS powiedzie się w systemie plików NFS. Ponieważ używany tutaj klient NFS nie rozumie shift-JIS ze względu na ustawienia regionalne, kodowanie pokazuje wartość "unknown-8bit".
$ cat SJIS.txt
テストファイル
$ file -i SJIS.txt
SJIS.txt: text/plain; charset=utf-8
$ iconv -t SJIS SJIS.txt \> SJIS2.txt
$ file -i SJIS.txt
SJIS.txt: text/plain; **charset=utf-8**
$ file -i SJIS2.txt
SJIS2.txt: text/plain; **charset=unknown-8bit**
Ponieważ woluminy usługi Azure NetApp Files obsługują tylko formatowanie zgodne z protokołem UTF-8, znaki Katagana są konwertowane na nieczytelny format.
$ cat SJIS2.txt
▒e▒X▒g▒t▒@▒C▒▒
W przypadku korzystania z systemu plików NFSv4.x konwersja jest dozwolona, gdy niezgodne znaki znajdują się wewnątrz zawartości pliku, mimo że NFSv4.x wymusza kodowanie UTF-8. W tym przykładzie zakodowany w formacie UTF-8 plik z znakami Katagana znajdującymi się na woluminie usługi Azure NetApp Files pokazuje prawidłową zawartość pliku.
$ file -i SJIS.txt
SJIS.txt: text/plain; charset=utf-8
S$ cat SJIS.txt
テストファイル
Jednak po przekonwertowaniu znaki w pliku są wyświetlane nieprawidłowo z powodu niezgodnego kodowania.
$ cat SJIS2.txt
▒e▒X▒g▒t▒@▒C▒▒
Jeśli nazwa pliku zawiera nieobsługiwane znaki utF-8, konwersja powiedzie się w systemie plików NFSv3, ale w trybie failover NFSv4.x z powodu wymuszania protokołu UTF-8.
# echo "Test file with SJIS encoded filename" \> "$(echo 'テストファイル.txt' | iconv -t SJIS)"
-bash: $(echo 'テストファイル.txt' | iconv -t SJIS): Invalid argument
Najlepsze rozwiązania dotyczące zestawu znaków
W przypadku używania znaków specjalnych lub znaków spoza standardowej podstawowej płaszczyzny wielojęzycznej (BMP) na woluminach usługi Azure NetApp Files należy wziąć pod uwagę niektóre najlepsze rozwiązania.
- Ponieważ woluminy usługi Azure NetApp Files używają języka woluminów UTF-8, kodowanie plików dla klientów NFS powinno również używać kodowania UTF-8 w celu uzyskania spójnych wyników.
- Zestawy znaków w nazwach plików lub zawarte w zawartości pliku powinny być zgodne z utF-8 dla prawidłowego wyświetlania i funkcjonalności.
- Ponieważ protokół SMB używa kodowania znaków UTF-16, znaki spoza protokołu BMP mogą nie być prawidłowo wyświetlane w systemie plików NFS w woluminach z dwoma protokołami. Jak to możliwe, zminimalizuj użycie znaków specjalnych w zawartości pliku.
- Unikaj używania znaków specjalnych spoza protokołu BMP w nazwach plików, zwłaszcza w przypadku korzystania z woluminów NFSv4.1 lub podwójnych protokołów.
- W przypadku zestawów znaków innych niż w protokole BMP kodowanie UTF-8 powinno zezwalać na wyświetlanie znaków w usłudze Azure NetApp Files przy użyciu pojedynczego protokołu plików (tylko protokół SMB lub tylko NFS). Jednak woluminy z dwoma protokołami nie są w stanie pomieścić tych zestawów znaków w większości przypadków.
- Kodowanie niezgodne (takie jak Shift-JIS) nie jest obsługiwane na woluminach usługi Azure NetApp Files.
- Znaki par zastępczych (takie jak emoji) są obsługiwane na woluminach usługi Azure NetApp Files.