Samouczek: wykrywanie i analizowanie anomalii przy użyciu funkcji uczenia maszynowego KQL w usłudze Azure Monitor
Język zapytań Kusto (KQL) obejmuje operatory uczenia maszynowego, funkcje i wtyczki do analizy szeregów czasowych, wykrywania anomalii, prognozowania i analizy głównej przyczyny. Skorzystaj z tych funkcji języka KQL, aby przeprowadzić zaawansowaną analizę danych w usłudze Azure Monitor bez konieczności eksportowania danych do zewnętrznych narzędzi uczenia maszynowego.
Z tego samouczka dowiesz się, jak wykonywać następujące czynności:
- Tworzenie szeregów czasowych
- Identyfikowanie anomalii w szeregach czasowych
- Dostosowywanie ustawień wykrywania anomalii w celu uściślinia wyników
- Analizowanie głównej przyczyny anomalii
Uwaga
Ten samouczek zawiera linki do środowiska demonstracyjnego usługi Log Analytics, w którym można uruchamiać przykłady zapytań języka KQL. Dane w środowisku demonstracyjnym są dynamiczne, więc wyniki zapytania nie są takie same jak wyniki zapytania pokazane w tym artykule. Można jednak zaimplementować te same zapytania I podmioty zabezpieczeń języka KQL we własnym środowisku oraz wszystkie narzędzia usługi Azure Monitor korzystające z języka KQL.
Wymagania wstępne
- Konto platformy Azure z aktywną subskrypcją. Utwórz konto bezpłatnie.
- Obszar roboczy z danymi dziennika.
Wymagane uprawnienia
Musisz mieć Microsoft.OperationalInsights/workspaces/query/*/read uprawnienia do obszarów roboczych usługi Log Analytics, które wykonujesz, zgodnie z wbudowaną rolą czytelnika usługi Log Analytics.
Tworzenie szeregów czasowych
Użyj operatora KQL make-series , aby utworzyć szeregi czasowe.
Utwórzmy szereg czasowy na podstawie dzienników w tabeli Użycie, która zawiera informacje o ilości danych w każdej tabeli w obszarze roboczym pozyskiwanych co godzinę, w tym rozliczanych i niepodliczalnych danych.
To zapytanie używa make-series do tworzenia wykresu całkowitej ilości rozliczanych danych pozyskanych przez każdą tabelę w obszarze roboczym każdego dnia w ciągu ostatnich 21 dni:
Kliknij, aby uruchomić zapytanie
let starttime = 21d; // The start date of the time series, counting back from the current date
let endtime = 0d; // The end date of the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we’re analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Include only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| render timechart // Renders results in a timechart
Na wykresie wynikowym można wyraźnie zobaczyć pewne anomalie — na przykład w AzureDiagnostics typach danych i SecurityEvent :
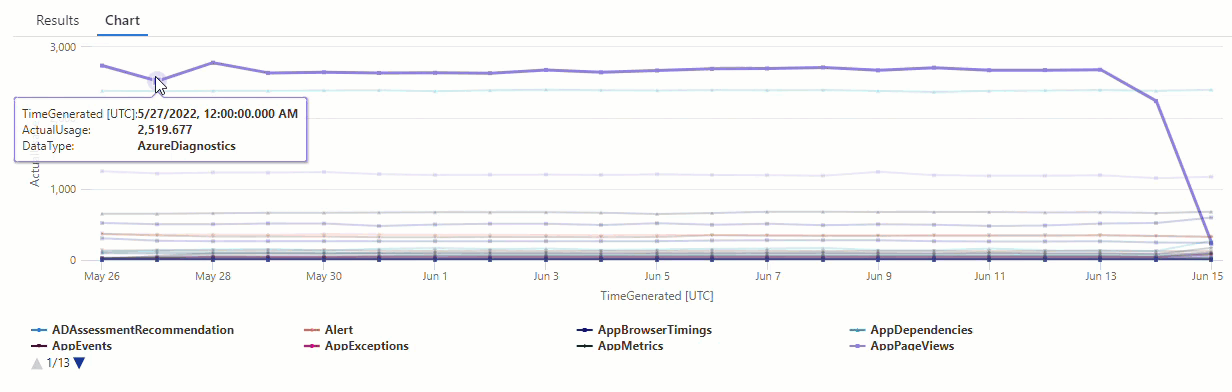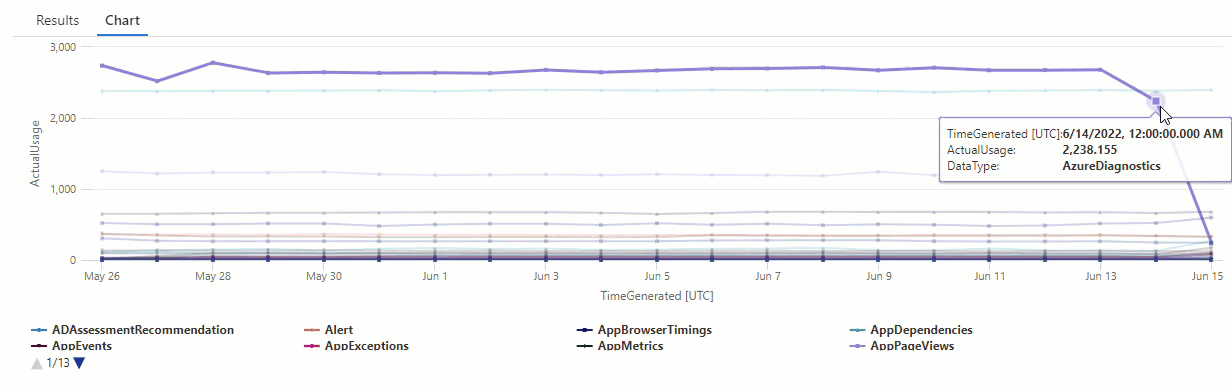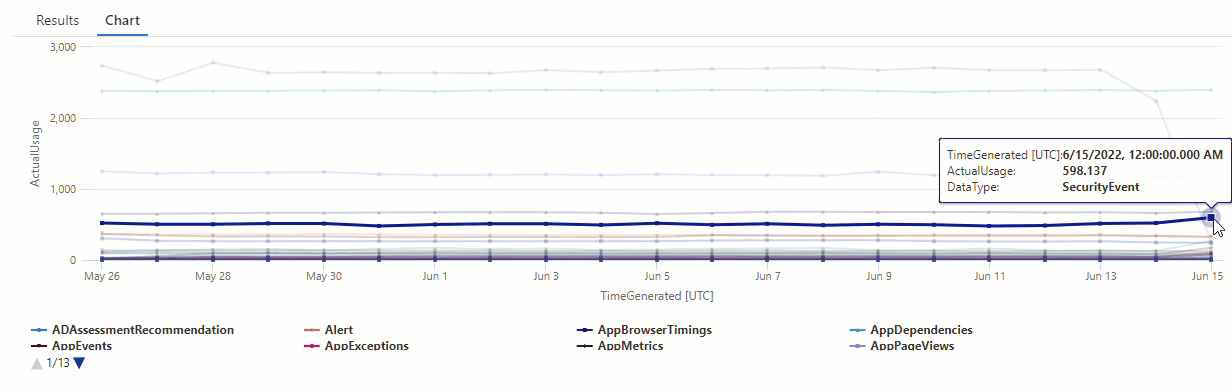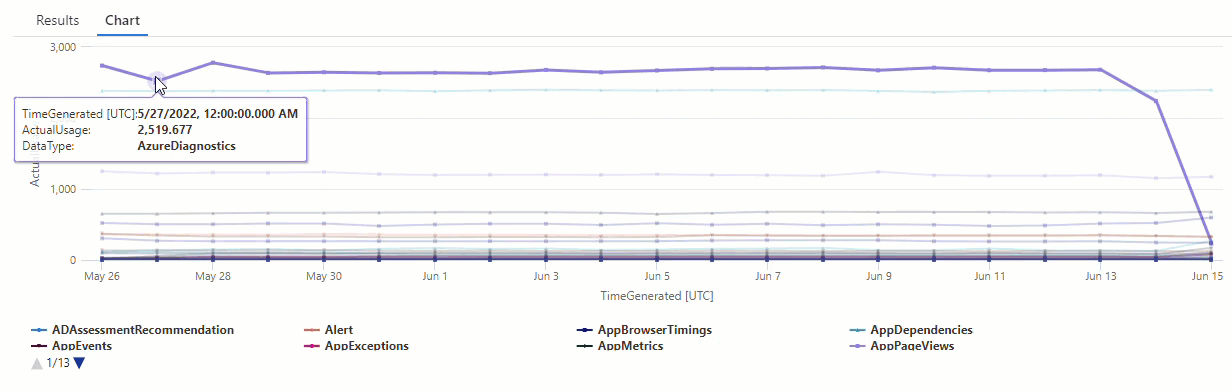
Następnie użyjemy funkcji KQL, aby wyświetlić listę wszystkich anomalii w szeregach czasowych.
Uwaga
Aby uzyskać więcej informacji na temat make-series składni i użycia, zobacz operator make-series.
Znajdowanie anomalii w szeregach czasowych
Funkcja series_decompose_anomalies() przyjmuje szereg wartości jako dane wejściowe i wyodrębnia anomalie.
Nadajmy zestawowi wyników zapytania szeregów czasowych jako dane wejściowe series_decompose_anomalies() funkcji:
Kliknij, aby uruchomić zapytanie
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we’re analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Includes only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| extend(Anomalies, AnomalyScore, ExpectedUsage) = series_decompose_anomalies(ActualUsage) // Scores and extracts anomalies based on the output of make-series
| mv-expand ActualUsage to typeof(double), TimeGenerated to typeof(datetime), Anomalies to typeof(double),AnomalyScore to typeof(double), ExpectedUsage to typeof(long) // Expands the array created by series_decompose_anomalies()
| where Anomalies != 0 // Returns all positive and negative deviations from expected usage
| project TimeGenerated,ActualUsage,ExpectedUsage,AnomalyScore,Anomalies,DataType // Defines which columns to return
| sort by abs(AnomalyScore) desc // Sorts results by anomaly score in descending ordering
To zapytanie zwraca wszystkie anomalie użycia dla wszystkich tabel w ciągu ostatnich trzech tygodni:

Patrząc na wyniki zapytania, możesz zobaczyć, że funkcja:
- Oblicza oczekiwane dzienne użycie dla każdej tabeli.
- Porównuje rzeczywiste dzienne użycie z oczekiwanym użyciem.
- Przypisuje wynik anomalii do każdego punktu danych wskazujący zakres odchylenia rzeczywistego użycia od oczekiwanego użycia.
- Identyfikuje dodatnie () i ujemne (
1-1) anomalie w każdej tabeli.
Uwaga
Aby uzyskać więcej informacji na temat series_decompose_anomalies() składni i użycia, zobacz series_decompose_anomalies().
Dostosowywanie ustawień wykrywania anomalii w celu uściślinia wyników
Dobrym rozwiązaniem jest przejrzenie początkowych wyników zapytania i wprowadzenie poprawek do zapytania, jeśli jest to konieczne. Wartości odstające w danych wejściowych mogą mieć wpływ na uczenie funkcji i może być konieczne dostosowanie ustawień wykrywania anomalii funkcji, aby uzyskać dokładniejsze wyniki.
Przefiltruj wyniki zapytania pod kątem series_decompose_anomalies() anomalii w typie AzureDiagnostics danych:

Wyniki pokazują dwie anomalie 14 czerwca i 15 czerwca. Porównaj te wyniki z wykresem z naszego pierwszego make-series zapytania, gdzie można zobaczyć inne anomalie 27 maja i 28 maja:

Różnica w wynikach występuje, ponieważ series_decompose_anomalies() funkcja ocenia anomalie względem oczekiwanej wartości użycia, którą funkcja oblicza na podstawie pełnego zakresu wartości w serii wejściowej.
Aby uzyskać bardziej wyrafinowane wyniki z funkcji, wyklucz użycie w dniu 15 czerwca — co jest wartością odstawą w porównaniu z innymi wartościami z serii — z procesu uczenia funkcji.
Składnia series_decompose_anomalies() funkcji to:
series_decompose_anomalies (Series[Threshold,Seasonality,Trend,Test_points,AD_method,Seasonality_threshold])
Test_points określa liczbę punktów na końcu serii do wykluczenia z procesu uczenia (regresji).
Aby wykluczyć ostatni punkt danych, ustaw wartość Test_points 1:
Kliknij, aby uruchomić zapytanie
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we’re analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Includes only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| extend(Anomalies, AnomalyScore, ExpectedUsage) = series_decompose_anomalies(ActualUsage,1.5,-1,'avg',1) // Scores and extracts anomalies based on the output of make-series, excluding the last value in the series - the Threshold, Seasonality, and Trend input values are the default values for the function
| mv-expand ActualUsage to typeof(double), TimeGenerated to typeof(datetime), Anomalies to typeof(double),AnomalyScore to typeof(double), ExpectedUsage to typeof(long) // Expands the array created by series_decompose_anomalies()
| where Anomalies != 0 // Returns all positive and negative deviations from expected usage
| project TimeGenerated,ActualUsage,ExpectedUsage,AnomalyScore,Anomalies,DataType // Defines which columns to return
| sort by abs(AnomalyScore) desc // Sorts results by anomaly score in descending ordering
Przefiltruj wyniki dla AzureDiagnostics typu danych:

Wszystkie anomalie na wykresie z naszego pierwszego make-series zapytania są teraz wyświetlane w zestawie wyników.
Analizowanie głównej przyczyny anomalii
Porównanie oczekiwanych wartości z nietypowymi wartościami pomaga zrozumieć przyczynę różnic między dwoma zestawami.
Wtyczka KQL diffpatterns() porównuje dwa zestawy danych tej samej struktury i znajduje wzorce charakteryzujące różnice między dwoma zestawami danych.
To zapytanie porównuje AzureDiagnostics użycie w dniu 15 czerwca, skrajnego odstania w naszym przykładzie z użyciem tabeli w innych dniach:
Kliknij, aby uruchomić zapytanie
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let anomalyDate = datetime_add('day',-1, make_datetime(startofday(ago(endtime)))); // Start of day of the anomaly date, which is the last full day in the time range in our example (you can replace this with a specific hard-coded anomaly date)
AzureDiagnostics
| extend AnomalyDate = iff(startofday(TimeGenerated) == anomalyDate, "AnomalyDate", "OtherDates") // Adds calculated column called AnomalyDate, which splits the result set into two data sets – AnomalyDate and OtherDates
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Defines the time range for the query
| project AnomalyDate, Resource // Defines which columns to return
| evaluate diffpatterns(AnomalyDate, "OtherDates", "AnomalyDate") // Compares usage on the anomaly date with the regular usage pattern
Zapytanie identyfikuje każdy wpis w tabeli w postaci anomaliiDate (15 czerwca) lub OtherDates. Następnie wtyczka diffpatterns() dzieli te zestawy danych — o nazwie A (OtherDates w naszym przykładzie) i B (AnomalyDate w naszym przykładzie) — i zwraca kilka wzorców, które przyczyniają się do różnic w dwóch zestawach:

Patrząc na wyniki zapytania, można zobaczyć następujące różnice:
- Istnieje 24 892 147 wystąpień pozyskiwania z zasobu CH1-GEARAMAAKS we wszystkich pozostałych dniach w zakresie czasu zapytania i bez pozyskiwania danych z tego zasobu 15 czerwca. Dane z zasobu CH1-GEARAMAAKS stanowią 73,36% całkowitego pozyskiwania w innych dniach w zakresie czasu zapytania i 0% całkowitego pozyskiwania w dniu 15 czerwca.
- Istnieje 2168 448 wystąpień pozyskiwania z zasobu sieciowej grupy zabezpieczeń-TESTSQLMI519 we wszystkich pozostałych dniach w zakresie czasu zapytania i 110 544 wystąpień pozyskiwania z tego zasobu w dniu 15 czerwca. Dane z zasobów sieciowych grup zabezpieczeń TESTSQLMI519 stanowią 6,39% całkowitego pozyskiwania w innych dniach w zakresie czasu zapytania i 25,61% pozyskiwania w dniu 15 czerwca.
Zauważ, że średnio w ciągu 20 dni istnieje 108 422 wystąpień pozyskiwania z zasobu sieciowej grupy zabezpieczeń TESTSQLMI519 w ciągu 20 dni, które składają się na drugi okres dni (podziel 2168 448 do 20). W związku z tym pozyskiwanie z zasobu sieciowej grupy zabezpieczeń TESTSQLMI519 w dniu 15 czerwca nie różni się znacząco od pozyskiwania z tego zasobu w innych dniach. Jednak ponieważ nie ma pozyskiwania z CH1-GEARAMAAKS 15 czerwca, pozyskiwanie z sieciowej grupy zabezpieczeń-TESTSQLMI519 stanowi znacznie większy procent całkowitego pozyskiwania w dniu anomalii w porównaniu z innymi dniami.
Kolumna PercentDiffAB pokazuje bezwzględną różnicę punktów procentowych między A i B (|PercentA — PercentB|), która jest główną miarą różnicy między dwoma zestawami. Domyślnie wtyczka diffpatterns() zwraca różnicę ponad 5% między dwoma zestawami danych, ale można dostosować ten próg. Na przykład aby zwrócić tylko różnice 20% lub więcej między dwoma zestawami danych, można ustawić | evaluate diffpatterns(AnomalyDate, "OtherDates", "AnomalyDate", "~", 0.20) w powyższym zapytaniu. Zapytanie zwraca teraz tylko jeden wynik:

Uwaga
Aby uzyskać więcej informacji na temat diffpatterns() składni i użycia, zobacz wtyczkę diff patterns.
Następne kroki
Dowiedz się więcej na następujące tematy: