Rozwiązywanie problemów z kolekcją metryk rozwiązania Prometheus w usłudze Azure Monitor
Wykonaj kroki opisane w tym artykule, aby określić przyczynę, że metryki Rozwiązania Prometheus nie są zbierane zgodnie z oczekiwaniami w usłudze Azure Monitor.
Replika zasobników metryki kube-state-metricsz , niestandardowe elementy docelowe zeskrobania w ama-metrics-prometheus-config mapie konfiguracji i niestandardowe elementy docelowe zeskrobu zdefiniowane w zasobach niestandardowych. Zasobniki daemonSet zeskrobać metryki z następujących obiektów docelowych w odpowiednim węźle: kubelet, cAdvisor, node-exporteri niestandardowe elementy docelowe zeskrobu w mapie ama-metrics-prometheus-config-node konfiguracji. Zasobnik, dla którego chcesz wyświetlić dzienniki i interfejs użytkownika rozwiązania Prometheus, zależy od tego, który element docelowy jest badany.
Rozwiązywanie problemów przy użyciu skryptu programu PowerShell
Jeśli podczas próby włączenia monitorowania klastra usługi AKS wystąpi błąd, postępuj zgodnie z tymi instrukcjami , aby uruchomić skrypt rozwiązywania problemów. Ten skrypt jest przeznaczony do wykonywania podstawowej diagnostyki wszelkich problemów z konfiguracją w klastrze i można dołączyć wygenerowane pliki podczas tworzenia wniosku o pomoc techniczną w celu szybszego rozwiązania zgłoszenia do pomocy technicznej.
Ograniczanie metryk
Usługa zarządzana usługi Azure Monitor dla rozwiązania Prometheus ma domyślne limity i limity przydziału pozyskiwania. Po osiągnięciu limitów pozyskiwania może wystąpić ograniczanie przepustowości. Możesz zażądać zwiększenia tych limitów. Aby uzyskać informacje na temat limitów metryk rozwiązania Prometheus, zobacz Limity usługi Azure Monitor.
W witrynie Azure Portal przejdź do obszaru roboczego usługi Azure Monitor. Przejdź do Metricspozycji , a następnie wybierz metryki Active Time Series % Utilization i Events Per Minute Received % Utilization. Sprawdź, czy oba są poniżej 100%.
Aby uzyskać więcej informacji na temat monitorowania i zgłaszania alertów dotyczących metryk pozyskiwania danych, zobacz Monitorowanie pozyskiwania metryk obszaru roboczego usługi Azure Monitor.
Sporadyczne luki w zbieraniu danych metryk
Podczas aktualizacji węzła może zostać wyświetlona 1–2-minutowa luka w danych metryk dla metryk zebranych z naszego modułu zbierającego na poziomie klastra. Ta luka wynika z faktu, że węzeł, w którym ona występuje, jest aktualizowany w ramach normalnego procesu aktualizacji. Ma to wpływ na cele obejmujące cały klaster, takie jak kube-state-metrics i określone elementy docelowe aplikacji niestandardowych. Występuje ona, gdy klaster jest aktualizowany ręcznie lub za pośrednictwem aktualizacji automatycznej. To zachowanie jest oczekiwane i występuje z powodu aktualizacji węzła, w którym pojawia się ta luka. To zachowanie nie ma wpływu na żadne z naszych zalecanych reguł alertów.
Stan zasobnika
Sprawdź stan zasobnika za pomocą następującego polecenia:
kubectl get pods -n kube-system | grep ama-metrics
Gdy usługa działa poprawnie, zwracana jest następująca lista zasobników w formacie ama-metrics-xxxxxxxxxx-xxxxx :
ama-metrics-operator-targets-*ama-metrics-ksm-*ama-metrics-node-*zasobnik dla każdego węzła w klastrze.
Każdy stan zasobnika powinien mieć Running równą liczbę ponownych uruchomień do liczby zastosowanych zmian mapy konfiguracji. Zasobnik ama-metrics-operator-targets-* może mieć dodatkowe ponowne uruchomienie na początku i jest to oczekiwane:

Jeśli każdy stan zasobnika to Running ale co najmniej jeden zasobnik ma ponowne uruchomienie, uruchom następujące polecenie:
kubectl describe pod <ama-metrics pod name> -n kube-system
- To polecenie udostępnia przyczynę ponownych uruchomień. Ponowne uruchomienie zasobnika jest oczekiwane, jeśli wprowadzono zmiany w mapie konfiguracji. Jeśli przyczyną ponownego uruchomienia jest
OOMKilled, zasobnik nie może nadążyć za ilością metryk. Zobacz zalecenia dotyczące skalowania dotyczące ilości metryk.
Jeśli zasobniki działają zgodnie z oczekiwaniami, następnym miejscem do sprawdzenia jest dzienniki kontenera.
Sprawdzanie konfiguracji ponownego etykietowania
Jeśli brakuje metryk, możesz również sprawdzić, czy masz ponownie etykiety konfiguracji. W przypadku ponownego etykietowania konfiguracji upewnij się, że ponowne etykietowanie nie odfiltruje elementów docelowych, a etykiety skonfigurowane poprawnie pasują do elementów docelowych. Aby uzyskać więcej informacji, zobacz dokumentację konfiguracji relabel usługi Prometheus.
Dzienniki kontenerów
Wyświetl dzienniki kontenera za pomocą następującego polecenia:
kubectl logs <ama-metrics pod name> -n kube-system -c prometheus-collector
Podczas uruchamiania wszelkie początkowe błędy są drukowane na czerwono, podczas gdy ostrzeżenia są drukowane w kolorze żółtym. (Wyświetlanie kolorowych dzienników wymaga co najmniej programu PowerShell w wersji 7 lub dystrybucji systemu Linux).
- Sprawdź, czy występuje problem z uzyskaniem tokenu uwierzytelniania:
- Komunikat Brak konfiguracji dla zasobu usługi AKS jest rejestrowany co 5 minut.
- Zasobnik jest uruchamiany co 15 minut, aby ponowić próbę z powodu błędu: Brak konfiguracji dla zasobu usługi AKS.
- Jeśli tak, sprawdź, czy w grupie zasobów istnieje reguła zbierania danych i punkt końcowy zbierania danych.
- Sprawdź również, czy obszar roboczy usługi Azure Monitor istnieje.
- Sprawdź, czy nie masz prywatnego klastra usługi AKS i czy nie jest połączony z zakresem usługi Azure Monitor Private Link dla żadnej innej usługi. Ten scenariusz nie jest obecnie obsługiwany.
Przetwarzanie konfiguracji
Wyświetl dzienniki kontenera za pomocą następującego polecenia:
kubectl logs <ama-metrics-operator-targets pod name> -n kube-system -c config-reader
- Sprawdź, czy nie ma żadnych błędów podczas analizowania konfiguracji rozwiązania Prometheus, scalania z włączonymi domyślnymi obiektami docelowymi zeskrobowania i weryfikowania pełnej konfiguracji.
- Jeśli dołączysz niestandardową konfigurację rozwiązania Prometheus, sprawdź, czy została rozpoznana w dziennikach. Jeśli nie:
- Sprawdź, czy mapa konfiguracji ma poprawną nazwę:
ama-metrics-prometheus-configwkube-systemprzestrzeni nazw. - Sprawdź, czy na mapie konfiguracji konfiguracja rozwiązania Prometheus znajduje się w sekcji o nazwie
prometheus-configponiżej, jakdatapokazano poniżej:kind: ConfigMap apiVersion: v1 metadata: name: ama-metrics-prometheus-config namespace: kube-system data: prometheus-config: |- scrape_configs: - job_name: <your scrape job here>
- Sprawdź, czy mapa konfiguracji ma poprawną nazwę:
- Jeśli utworzono zasoby niestandardowe, podczas tworzenia monitorów zasobników/usługi powinny zostać wyświetlone błędy walidacji. Jeśli nadal nie widzisz metryk z obiektów docelowych, upewnij się, że w dziennikach nie są wyświetlane żadne błędy.
kubectl logs <ama-metrics-operator-targets pod name> -n kube-system -c targetallocator
- Sprawdź, czy nie ma żadnych błędów dotyczących
MetricsExtensionuwierzytelniania w obszarze roboczym usługi Azure Monitor. - Sprawdź, czy nie ma żadnych błędów dotyczących
OpenTelemetry collectorzłomowania celów.
Uruchom następujące polecenie:
kubectl logs <ama-metrics pod name> -n kube-system -c addon-token-adapter
- To polecenie wyświetla błąd, jeśli występuje problem z uwierzytelnianiem w obszarze roboczym usługi Azure Monitor. W poniższym przykładzie przedstawiono dzienniki bez problemów:
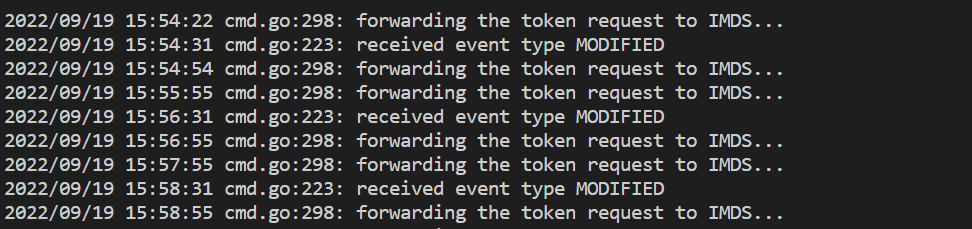

Jeśli w dziennikach nie ma żadnych błędów, interfejs Prometheus może służyć do debugowania w celu zweryfikowania oczekiwanej konfiguracji i obiektów docelowych, które są zeskropane.
Prometheus, interfejs
Każdy ama-metrics-* zasobnik ma interfejs użytkownika trybu agenta Prometheus dostępny na porcie 9090.
Niestandardowa konfiguracja i elementy docelowe zasobów niestandardowych są złomowane przez ama-metrics-* zasobnik i obiekty docelowe węzła ama-metrics-node-* przez zasobnik.
Przekaż port do zasobnika repliki lub jednego z zasobników zestawu demonów, aby sprawdzić konfigurację, odnajdywanie usług i docelowe punkty końcowe, zgodnie z opisem w tym miejscu, aby sprawdzić, czy niestandardowe konfiguracje są poprawne, zamierzone obiekty docelowe zostały odnalezione dla każdego zadania i nie ma żadnych błędów ze złomowaniem określonych obiektów docelowych.
Uruchom polecenie kubectl port-forward <ama-metrics pod> -n kube-system 9090.
Otwórz przeglądarkę pod adresem
127.0.0.1:9090/config. Ten interfejs użytkownika ma pełną konfigurację złomowania. Sprawdź, czy wszystkie zadania są uwzględnione w konfiguracji.
Przejdź do strony , aby
127.0.0.1:9090/service-discoverywyświetlić obiekty docelowe odnalezione przez określony obiekt odnajdywania usługi i to, co relabel_configs przefiltrowały obiekty docelowe. Jeśli na przykład brakuje metryk z określonego zasobnika, możesz sprawdzić, czy ten zasobnik został odnaleziony i jaki jest jego identyfikator URI. Następnie możesz użyć tego identyfikatora URI podczas przeglądania obiektów docelowych, aby sprawdzić, czy występują jakiekolwiek błędy zeskrobu.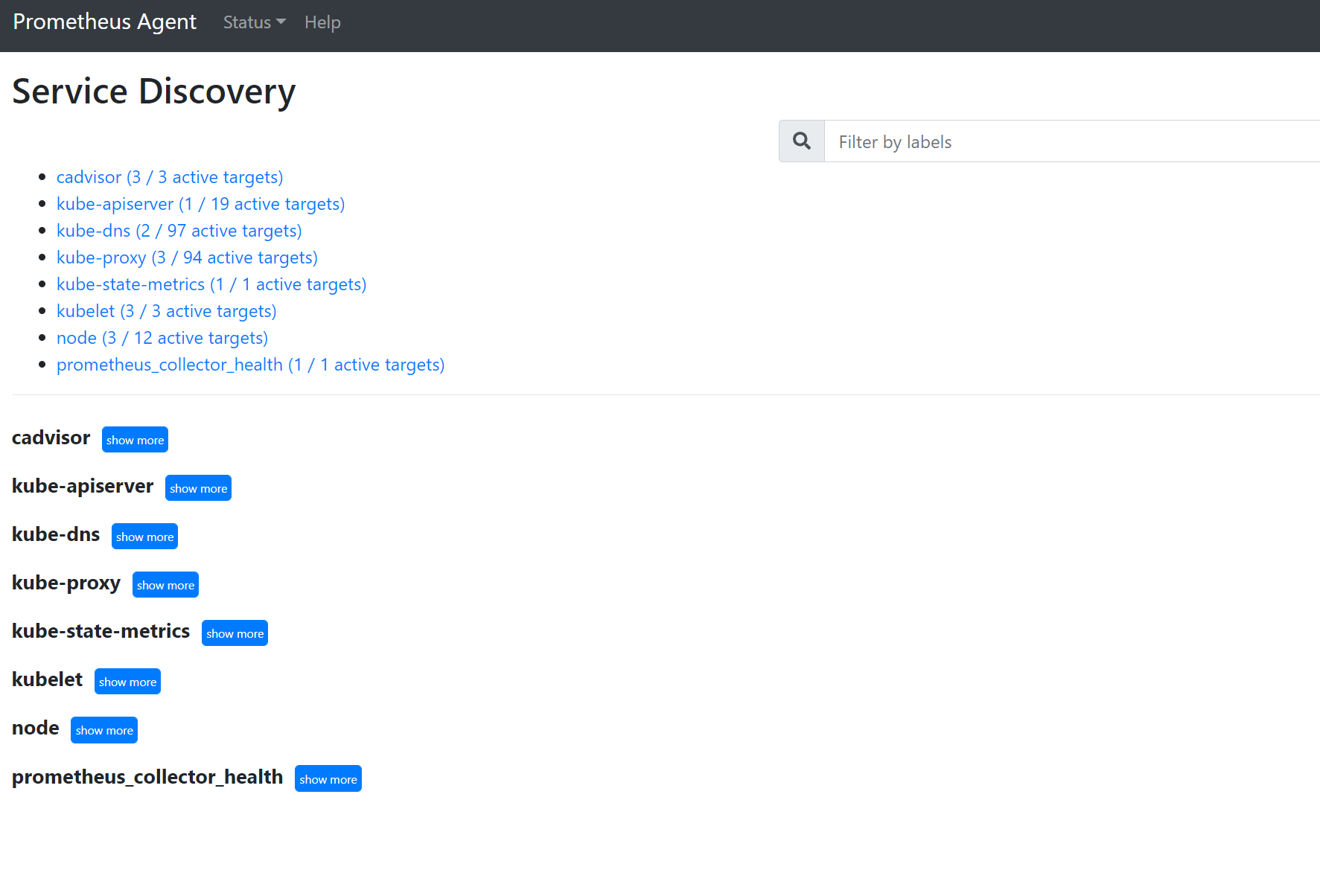
Przejdź do strony
127.0.0.1:9090/targets, aby wyświetlić wszystkie zadania, ostatni raz punkt końcowy dla tego zadania został zeskropany i wszelkie błędy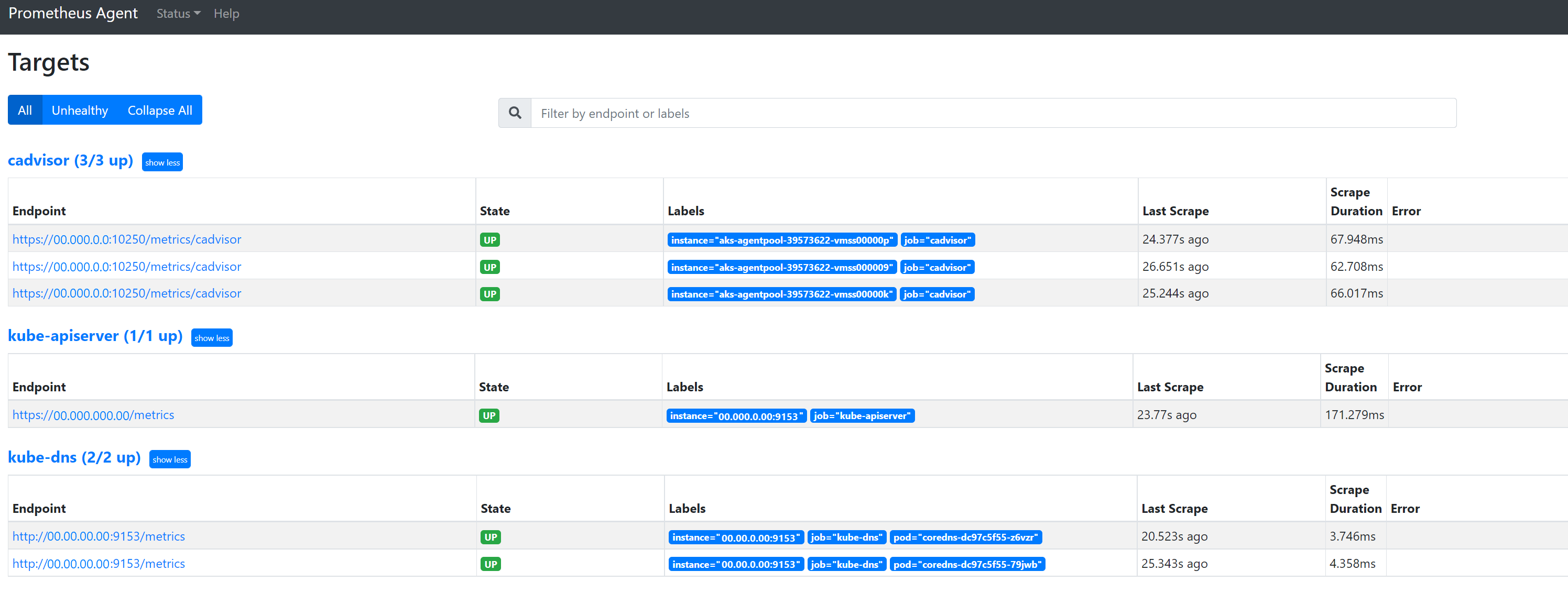



Zasoby niestandardowe
- Jeśli dołączysz zasoby niestandardowe, upewnij się, że są one wyświetlane w obszarze konfiguracji, odnajdywania usług i obiektów docelowych.
Konfigurowanie

Odnajdywanie usług

Elementy docelowe

Jeśli nie ma żadnych problemów i docelowe cele są złomowane, możesz wyświetlić dokładne metryki, które są zeskropane, włączając tryb debugowania.
Tryb debugowania
Ostrzeżenie
Ten tryb może mieć wpływ na wydajność i powinien być włączony tylko przez krótki czas na potrzeby debugowania.
Dodatek metryk można skonfigurować tak, aby był uruchamiany w trybie debugowania, zmieniając ustawienie enabled mapy konfiguracji na debug-mode , true postępując zgodnie z instrukcjami podanymi tutaj.
Po włączeniu wszystkie metryki Prometheus, które są złomowane, są hostowane na porcie 9091. Uruchom następujące polecenie:
kubectl port-forward <ama-metrics pod name> -n kube-system 9091
Przejdź do 127.0.0.1:9091/metrics witryny w przeglądarce, aby sprawdzić, czy metryki zostały zeskropane przez moduł zbierający OpenTelemetry. Dostęp do tego interfejsu użytkownika można uzyskać dla każdego ama-metrics-* zasobnika. Jeśli nie ma metryk, może wystąpić problem z długością nazwy metryki lub etykiety albo liczbą etykiet. Sprawdź również, czy przekroczono limit przydziału pozyskiwania dla metryk Prometheus, jak określono w tym artykule.
Nazwy metryk, nazwy etykiet i wartości etykiet
Obecnie metryki są ograniczane w poniższej tabeli:
| Właściwości | Limit |
|---|---|
| Długość nazwy etykiety | Mniejsze niż lub równe 511 znaków. Gdy ten limit zostanie przekroczony dla dowolnego szeregu czasowego w zadaniu, całe zadanie złomu nie powiedzie się, a metryki zostaną porzucone z tego zadania przed pozyskaniem. Możesz zobaczyć wartość up=0 dla tego zadania, a także docelowy element Ux pokazuje przyczynę up=0. |
| Długość wartości etykiety | Mniejsze niż lub równe 1023 znaki. Gdy ten limit zostanie przekroczony dla dowolnego szeregu czasowego w zadaniu, całe złomowanie zakończy się niepowodzeniem, a metryki zostaną porzucone z tego zadania przed pozyskaniem. Możesz zobaczyć wartość up=0 dla tego zadania, a także docelowy element Ux pokazuje przyczynę up=0. |
| Liczba etykiet na szeregi czasowe | Mniejsze niż lub równe 63. Gdy ten limit zostanie przekroczony dla dowolnego szeregu czasowego w zadaniu, całe zadanie złomu nie powiedzie się, a metryki zostaną porzucone z tego zadania przed pozyskaniem. Możesz zobaczyć wartość up=0 dla tego zadania, a także docelowy element Ux pokazuje przyczynę up=0. |
| Długość nazwy metryki | Mniejsze niż lub równe 511 znaków. Gdy ten limit zostanie przekroczony dla dowolnego szeregu czasowego w zadaniu, tylko ta określona seria zostanie porzucona. Element MetricextensionConsoleDebugLog zawiera ślady usuniętej metryki. |
| Nazwy etykiet z inną wielkością liter | Dwie etykiety w tym samym przykładzie metryki z inną wielkością są traktowane jako zduplikowane etykiety i są porzucane podczas pozyskiwania. Na przykład szereg my_metric{ExampleLabel="label_value_0", examplelabel="label_value_1} czasowy jest porzucony z powodu zduplikowanych etykiet, ponieważ ExampleLabel i examplelabel jest postrzegany jako ta sama nazwa etykiety. |
Sprawdzanie limitu przydziału pozyskiwania w obszarze roboczym usługi Azure Monitor
Jeśli metryki zostały pominięte, możesz najpierw sprawdzić, czy limity pozyskiwania są przekraczane dla obszaru roboczego usługi Azure Monitor. W witrynie Azure Portal możesz sprawdzić bieżące użycie dla dowolnego obszaru roboczego usługi Azure Monitor. Bieżące metryki użycia są widoczne w Metrics menu dla obszaru roboczego usługi Azure Monitor. Poniższe metryki użycia są dostępne jako metryki standardowe dla każdego obszaru roboczego usługi Azure Monitor.
- Active Time Series — liczba unikatowych szeregów czasowych ostatnio pozyskanych do obszaru roboczego w ciągu ostatnich 12 godzin
- Limit aktywnych szeregów czasowych — limit liczby unikatowych szeregów czasowych, które mogą być aktywnie pozyskiwane do obszaru roboczego
- Wykorzystanie aktywnej serii czasowej — procent aktualnie używanych aktywnych szeregów czasowych
- Zdarzenia na minutę pozyskane — liczba zdarzeń (próbek) na minutę ostatnio odebranych
- Limit pozyskiwania zdarzeń na minutę — maksymalna liczba zdarzeń na minutę, którą można pozyskać przed ograniczeniem
- Zdarzenia na minutę pozyskane % wykorzystania — procent wykorzystania bieżącej metryki limitu pozyskiwania danych
Aby uniknąć ograniczania pozyskiwania metryk, możesz monitorować i konfigurować alert dotyczący limitów pozyskiwania. Zobacz Monitorowanie limitów pozyskiwania.
Zapoznaj się z tematem Limity przydziału i limity usług dla domyślnych przydziałów , a także dowiedz się, co można zwiększyć na podstawie użycia. Możesz zażądać zwiększenia limitu przydziału dla obszarów roboczych usługi Azure Monitor przy użyciu Support Request menu obszaru roboczego usługi Azure Monitor. Upewnij się, że w żądaniu pomocy technicznej dołączysz identyfikator, identyfikator wewnętrzny i lokalizację/region obszaru roboczego usługi Azure Monitor, który można znaleźć w menu "Właściwości" obszaru roboczego usługi Azure Monitor w witrynie Azure Portal.
Tworzenie obszaru roboczego usługi Azure Monitor nie powiodło się z powodu oceny usługi Azure Policy
Jeśli tworzenie obszaru roboczego usługi Azure Monitor zakończy się niepowodzeniem z komunikatem "Zasób "resource-name-xyz" został niedozwolony przez zasady", mogą istnieć zasady platformy Azure uniemożliwiające utworzenie zasobu. Jeśli istnieją zasady wymuszające konwencję nazewnictwa dla zasobów lub grup zasobów platformy Azure, należy utworzyć wykluczenie dla konwencji nazewnictwa na potrzeby tworzenia obszaru roboczego usługi Azure Monitor.
Podczas tworzenia obszaru roboczego usługi Azure Monitor domyślnie reguła zbierania danych i punkt końcowy zbierania danych w formularzu "azure-monitor-workspace-name" zostanie automatycznie utworzona w grupie zasobów w postaci "MA_azure-monitor-workspace-name_location_managed". Obecnie nie ma możliwości zmiany nazw tych zasobów i należy ustawić wykluczenie w usłudze Azure Policy, aby wykluczyć powyższe zasoby z oceny zasad. Zobacz Struktura wykluczania usługi Azure Policy.