Flapping in Autoscale
W tym artykule opisano flapping w autoskalowaniu i jak go uniknąć.
Flapping odnosi się do warunku pętli, który powoduje serię przeciwnych zdarzeń skalowania. Flapping występuje, gdy zdarzenie skalowania wyzwala odwrotne zdarzenie skalowania.
Autoskalowanie ocenia oczekujące działanie skalowania w poziomie, aby sprawdzić, czy może to spowodować flapping. W przypadkach, gdy może wystąpić flapping, autoskalowanie może pominąć akcję skalowania i ponownie przeprowadzić ponowną akcję przy następnym uruchomieniu lub skalowanie automatyczne może być skalowane o mniejszą niż określona liczba wystąpień zasobów. Proces oceny automatycznego skalowania odbywa się za każdym razem, gdy aparat autoskalowania jest uruchamiany co 30 do 60 sekund, w zależności od typu zasobu.
Aby zapewnić odpowiednie zasoby, sprawdzanie potencjalnego flappingu nie występuje w przypadku zdarzeń skalowanych w poziomie. Autoskalowanie spowoduje tylko odroczenie zdarzenia skalowania w poziomie, aby uniknąć flappingu.
Załóżmy na przykład następujące reguły:
- Zwiększanie skali w poziomie o 1 wystąpienie, gdy średnie użycie procesora CPU przekracza 50%.
- Skalowanie w zmniejszaniu liczby wystąpień o 1 wystąpienie, gdy średnie użycie procesora CPU jest niższe niż 30%.
W poniższej tabeli na T0, gdy użycie wynosi 56%, akcja skalowania w poziomie jest wyzwalana i skutkuje użyciem procesora CPU w 56% w 2 wystąpieniach. Daje to średnio 28% dla zestawu skalowania. Ponieważ 28% jest mniejsze niż próg skalowania w poziomie, skalowanie automatyczne powinno być skalowane z powrotem. Skalowanie w obiekcie spowoduje zwrócenie zestawu skalowania do 56% użycia procesora CPU, co spowoduje wyzwolenie akcji skalowania w poziomie.
| Czas | Liczba wystąpień | % procesora CPU | Procent użycia procesora CPU na wystąpienie | Skalowanie zdarzenia | Wynikowa liczba wystąpień |
|---|---|---|---|---|---|
| T0 | 1 | 56% | 56% | Skalowanie w poziomie | 2 |
| T1 | 2 | 56% | 28% | Skalowanie w pionie | 1 |
| T2 | 1 | 56% | 56% | Skalowanie w poziomie | 2 |
| T3 | 2 | 56% | 28% | Skalowanie w pionie | 1 |
Jeśli nie zostanie to kontrolowane, będzie tocząca się seria zdarzeń skalowania. Jednak w tej sytuacji aparat autoskalowania odroczyć skalowanie w przypadku T1 i dokona ponownej oceny podczas następnego uruchomienia autoskalowania. Skalowanie w poziomie nastąpi tylko wtedy, gdy średnie użycie procesora CPU będzie niższe niż 30%.
Flapping jest często spowodowany przez:
- Małe lub bez marginesów między progami
- Skalowanie według więcej niż jednego wystąpienia
- Skalowanie w i wyprzedanie przy użyciu różnych metryk
Małe lub bez marginesów między progami
Aby uniknąć flappingu, zachowaj odpowiednie marginesy między progami skalowania.
Na przykład następujące reguły, w których nie ma marginesu między progami, powodują flapping.
- Skalowanie w poziomie, gdy liczba wątków >= 600
- Skalowanie w poziomie, gdy liczba < wątków: 600
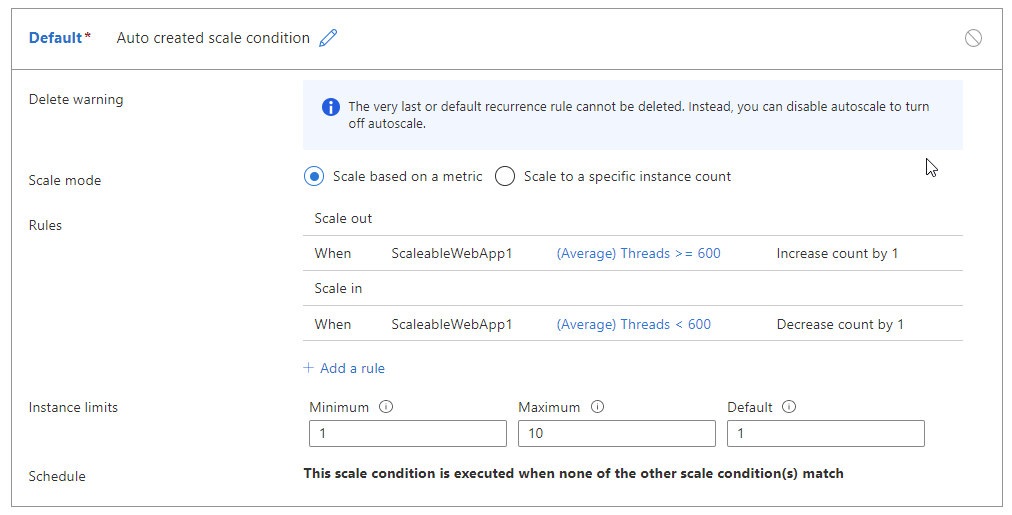
W poniższej tabeli przedstawiono potencjalny wynik tych reguł skalowania automatycznego:
| Czas | Liczba wystąpień | Liczba wątków | Liczba wątków na wystąpienie | Skalowanie zdarzenia | Wynikowa liczba wystąpień |
|---|---|---|---|---|---|
| T0 | 2 | 1250 | 625 | Skalowanie w poziomie | 3 |
| T1 | 3 | 1250 | 417 | Skalowanie w pionie | 2 |
- W czasie T0 istnieją dwa wystąpienia obsługujące 1250 wątków lub 625 bieżników na wystąpienie. Skalowanie automatyczne jest skalowane w poziomie do trzech wystąpień.
- Po skalowaniu w poziomie w T1 mamy te same 1250 wątków, ale z trzema wystąpieniami tylko 417 wątków na wystąpienie. Zdarzenie skalowania w poziomie jest wyzwalane.
- Przed skalowaniem autoskalowanie ocenia, co się stanie w przypadku wystąpienia zdarzenia skalowania w poziomie. W tym przykładzie 1250 / 2 = 625, czyli 625 wątków na wystąpienie. Autoskalowania musiałby natychmiast skalować w poziomie ponownie po skalowaniu w poziomie. Jeśli proces zostanie ponownie przeskalowany w poziomie, będzie powtarzany, co prowadzi do pętli flapping.
- Aby uniknąć tej sytuacji, skalowanie automatyczne nie jest skalowane w poziomie. Autoskalowanie pomija bieżące zdarzenie skalowania i ponownie zszacuje regułę w następnym cyklu wykonywania.
W takim przypadku wygląda na to, że autoskalowanie nie działa, ponieważ nie ma miejsca żadne zdarzenie skalowania. Sprawdź kartę Historia uruchamiania na stronie ustawienia autoskalowania, aby sprawdzić, czy nie ma żadnych flappingów.

Ustawienie odpowiedniego marginesu między progami pozwala uniknąć powyższego scenariusza. Na przykład:
- Skalowanie w poziomie, gdy liczba wątków >= 600
- Skalowanie w poziomie, gdy liczba < wątków: 400

Jeśli liczba wątków skalowanych w poziomie wynosi 400, łączna liczba wątków musiałaby spaść do poniżej 1200, zanim nastąpi zdarzenie skalowania. Zapoznaj się z poniższą tabelą.
| Czas | Liczba wystąpień | Liczba wątków | Liczba wątków na wystąpienie | Skalowanie zdarzenia | Wynikowa liczba wystąpień |
|---|---|---|---|---|---|
| T0 | 2 | 1250 | 625 | Skalowanie w poziomie | 3 |
| T1 | 3 | 1250 | 417 | brak zdarzenia skalowania | 3 |
| T2 | 3 | 1180 | 394 | skalowanie w | 2 |
| T3 | 3 | 1180 | 590 | brak zdarzenia skalowania | 2 |
Skalowanie według więcej niż jednego wystąpienia
Aby uniknąć flappingu podczas skalowania w poziomie lub w poziomie przez więcej niż jedno wystąpienie, autoskalowanie może być skalowane o mniej niż liczba wystąpień określonych w regule.
Na przykład następujące reguły mogą powodować flapping:
- Skalowanie w poziomie o 20, gdy liczba >żądań = 200 na wystąpienie.
- LUB, gdy procesor CPU > 70% na wystąpienie.
- Skaluj w poziomie o 10, gdy liczba <żądań = 50 na wystąpienie.
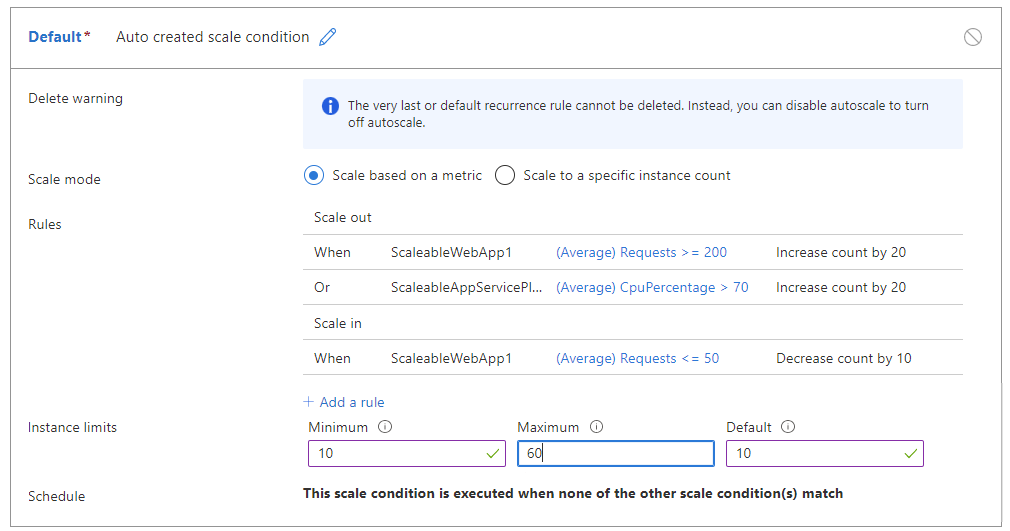
W poniższej tabeli przedstawiono potencjalny wynik tych reguł skalowania automatycznego:
| Czas | Liczba wystąpień | Procesor CPU | Liczba żądań | Skalowanie zdarzenia | Wynikowe wystąpienia | Komentarze |
|---|---|---|---|---|---|---|
| T0 | 30 | 65% | 3000 lub 100 na wystąpienie. | Brak zdarzenia skalowania | 30 | |
| T1 | 30 | 65 | 1500 | Skalowanie wg 3 wystąpień | 27 | Skalowanie w poziomie o 10 spowodowałoby szacowany wzrost procesora CPU powyżej 70%, co prowadzi do zdarzenia skalowalnego w poziomie. |
W czasie T0 aplikacja działa z 30 wystąpieniami, łączną liczbą żądań wynoszącą 3000 i użyciem procesora CPU wynoszącym 65% na wystąpienie.
W T1, gdy liczba żądań spadnie do 1500 żądań lub 50 żądań na wystąpienie, skalowanie automatyczne spróbuje skalować w ciągu 10 wystąpień do 20. Jednak skalowanie automatyczne szacuje, że obciążenie procesora CPU dla 20 wystąpień będzie wyższe niż 70%, co powoduje zdarzenie skalowania w poziomie.
Aby uniknąć flappingu, aparat autoskalowania szacuje użycie procesora CPU dla wystąpień liczone powyżej 20 do momentu znalezienia liczby wystąpień, w której wszystkie metryki znajdują się w zdefiniowanych progach:
- Zachowaj procesor poniżej 70%.
- Zachowaj liczbę żądań na wystąpienie powyżej 50.
- Zmniejsz liczbę wystąpień poniżej 30.
W takiej sytuacji skalowanie automatyczne może być skalowane o 3, z 30 do 27 wystąpień w celu spełnienia reguł, mimo że reguła określa spadek o 10. Komunikat dziennika jest zapisywany w dzienniku aktywności z opisem zawierającym skalowanie w dół z zaktualizowaną liczbą wystąpień, aby uniknąć flappingu
Jeśli autoskalowanie nie może znaleźć odpowiedniej liczby wystąpień, spowoduje to pominięcie skali w przypadku i ponownej oceny podczas następnego cyklu.
Uwaga
Jeśli aparat skalowania automatycznego wykryje, że flapping może wystąpić w wyniku skalowania do docelowej liczby wystąpień, spróbuje również przeprowadzić skalowanie do mniejszej liczby wystąpień między bieżącą liczbą a liczbą docelową. Jeśli flapping nie występuje w tym zakresie, autoskalowanie będzie kontynuować operację skalowania z nowym obiektem docelowym.
Plik dzienników
Znajdź flapping w dzienniku aktywności za pomocą następującego zapytania:
// Activity log, CategoryValue: Autoscale
// Lists latest Autoscale operations from the activity log, with OperationNameValue =="Microsoft.Insights/AutoscaleSettings/Flapping/Action
AzureActivity
|where CategoryValue =="Autoscale" and OperationNameValue =="Microsoft.Insights/AutoscaleSettings/Flapping/Action"
|sort by TimeGenerated desc
Poniżej znajduje się przykład rekordu dziennika aktywności na potrzeby flappingu:

{
"eventCategory": "Autoscale",
"eventName": "FlappingOccurred",
"operationId": "1111bbbb-22cc-dddd-ee33-ffffff444444",
"eventProperties":
"{"Description":"Scale down will occur with updated instance count to avoid flapping.
Resource: '/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourcegroups/ed-rg-001/providers/Microsoft.Web/serverFarms/ScaleableAppServicePlan'.
Current instance count: '6',
Intended new instance count: '1'.
Actual new instance count: '4'",
"ResourceName":"/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourcegroups/rg-001/providers/Microsoft.Web/serverFarms/ScaleableAppServicePlan",
"OldInstancesCount":6,
"NewInstancesCount":4,
"ActiveAutoscaleProfile":{"Name":"Auto created scale condition",
"Capacity":{"Minimum":"1","Maximum":"30","Default":"1"},
"Rules":[{"MetricTrigger":{"Name":"Requests","Namespace":"microsoft.web/sites","Resource":"/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/rg-001/providers/Microsoft.Web/sites/ScaleableWebApp1","ResourceLocation":"West Central US","TimeGrain":"PT1M","Statistic":"Average","TimeWindow":"PT1M","TimeAggregation":"Maximum","Operator":"GreaterThanOrEqual","Threshold":3.0,"Source":"/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/ed-rg-001/providers/Microsoft.Web/sites/ScaleableWebApp1","MetricType":"MDM","Dimensions":[],"DividePerInstance":true},"ScaleAction":{"Direction":"Increase","Type":"ChangeCount","Value":"10","Cooldown":"PT1M"}},{"MetricTrigger":{"Name":"Requests","Namespace":"microsoft.web/sites","Resource":"/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/rg-001/providers/Microsoft.Web/sites/ScaleableWebApp1","ResourceLocation":"West Central US","TimeGrain":"PT1M","Statistic":"Max","TimeWindow":"PT1M","TimeAggregation":"Maximum","Operator":"LessThan","Threshold":3.0,"Source":"/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/ed-rg-001/providers/Microsoft.Web/sites/ScaleableWebApp1","MetricType":"MDM","Dimensions":[],"DividePerInstance":true},"ScaleAction":{"Direction":"Decrease","Type":"ChangeCount","Value":"5","Cooldown":"PT1M"}}]}}",
"eventDataId": "dddd3333-ee44-5555-66ff-777777aaaaaa",
"eventSubmissionTimestamp": "2022-09-13T07:20:41.1589076Z",
"resource": "scaleableappserviceplan",
"resourceGroup": "RG-001",
"resourceProviderValue": "MICROSOFT.WEB",
"subscriptionId": "aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e",
"activityStatusValue": "Succeeded"
}
Następne kroki
Aby dowiedzieć się więcej na temat autoskalowania, zobacz następujące zasoby: