Odzyskiwanie po awarii i dystrybucja geograficzna w usłudze Azure Durable Functions
Firma Microsoft dąży do zapewnienia, że usługi platformy Azure są zawsze dostępne. Mogą jednak wystąpić nieplanowane awarie usług. Jeśli aplikacja wymaga odporności, firma Microsoft zaleca skonfigurowanie aplikacji pod kątem nadmiarowości geograficznej. Ponadto klienci powinni mieć plan odzyskiwania po awarii na potrzeby obsługi regionalnej awarii usługi. Ważną częścią planu odzyskiwania po awarii jest przygotowanie do przejścia w tryb failover do repliki pomocniczej aplikacji i magazynu w przypadku niedostępności repliki podstawowej.
W Durable Functions stan jest domyślnie utrwalany w usłudze Azure Storage. Centrum zadań to logiczny kontener dla zasobów usługi Azure Storage, które są używane do aranżacji i jednostek. Funkcje orkiestratora, działania i jednostki mogą współdziałać ze sobą tylko wtedy, gdy należą do tego samego centrum zadań. Ten dokument będzie dotyczyć centrów zadań podczas opisywania scenariuszy utrzymania wysokiej dostępności tych zasobów usługi Azure Storage.
Uwaga
Wskazówki zawarte w tym artykule zakładają, że używasz domyślnego dostawcy usługi Azure Storage do przechowywania Durable Functions stanu środowiska uruchomieniowego. Można jednak skonfigurować alternatywnych dostawców magazynu, którzy przechowują stan w innym miejscu, na przykład bazę danych SQL Server. Dla alternatywnych dostawców magazynu mogą być wymagane różne strategie odzyskiwania po awarii i dystrybucji geograficznej. Aby uzyskać więcej informacji na temat alternatywnych dostawców magazynu, zobacz dokumentację dostawców magazynu Durable Functions.
Orkiestracje i jednostki mogą być wyzwalane przy użyciu funkcji klienta, które są wyzwalane za pośrednictwem protokołu HTTP lub jednego z innych obsługiwanych typów wyzwalaczy Azure Functions. Można je również wyzwalać przy użyciu wbudowanych interfejsów API PROTOKOŁU HTTP. Dla uproszczenia ten artykuł koncentruje się na scenariuszach obejmujących wyzwalacze funkcji oparte na protokole HTTP i azure Storage oraz opcje zwiększania dostępności i minimalizowania przestojów podczas działań odzyskiwania po awarii. Inne typy wyzwalaczy, takie jak service bus lub wyzwalacze usługi Azure Cosmos DB, nie zostaną jawnie omówione.
Poniższe scenariusze są oparte na Active-Passive konfiguracjach, ponieważ są one sterowane użyciem usługi Azure Storage. Ten wzorzec składa się z wdrażania aplikacji funkcji kopii zapasowej (pasywnej) w innym regionie. Usługa Traffic Manager będzie monitorować podstawową (aktywną) aplikację funkcji pod kątem dostępności protokołu HTTP. W przypadku awarii podstawowej nastąpi przełączenie jej w tryb failover do aplikacji funkcji kopii zapasowej. Aby uzyskać więcej informacji, zobacz Metoda priorytetu usługiAzure Traffic Manager Traffic-Routing.
Uwaga
- Proponowana konfiguracja Active-Passive gwarantuje, że klient zawsze może wyzwalać nowe aranżacje za pośrednictwem protokołu HTTP. Jednak w wyniku dwóch aplikacji funkcji współużytkujących to samo centrum zadań w magazynie niektóre transakcje magazynu w tle będą dystrybuowane między obydwoma z nich. W związku z tym ta konfiguracja wiąże się z pewnymi dodatkowymi kosztami ruchu wychodzącego dla pomocniczej aplikacji funkcji.
- Podstawowe konto magazynu i centrum zadań są tworzone w regionie podstawowym i są współużytkowane przez obie aplikacje funkcji.
- Wszystkie aplikacje funkcji, które są wdrażane nadmiarowo, muszą współużytkować te same klucze dostępu funkcji w przypadku aktywowania za pośrednictwem protokołu HTTP. Środowisko uruchomieniowe usługi Functions udostępnia interfejs API zarządzania , który umożliwia konsumentom programowe dodawanie, usuwanie i aktualizowanie kluczy funkcji. Zarządzanie kluczami jest również możliwe przy użyciu interfejsów API usługi Azure Resource Manager.
Scenariusz 1 — równoważenie obciążenia obliczeniowego z magazynem udostępnionym
Jeśli infrastruktura obliczeniowa na platformie Azure ulegnie awarii, aplikacja funkcji może stać się niedostępna. Aby zminimalizować możliwość takiego przestoju, w tym scenariuszu są używane dwie aplikacje funkcji wdrożone w różnych regionach. Usługa Traffic Manager jest skonfigurowana do wykrywania problemów w podstawowej aplikacji funkcji i automatycznego przekierowywania ruchu do aplikacji funkcji w regionie pomocniczym. Ta aplikacja funkcji współudzieli to samo konto usługi Azure Storage i centrum zadań. W związku z tym stan aplikacji funkcji nie zostanie utracony i praca może być wznowiona normalnie. Po przywróceniu kondycji do regionu podstawowego usługa Azure Traffic Manager automatycznie rozpocznie kierowanie żądań do tej aplikacji funkcji.
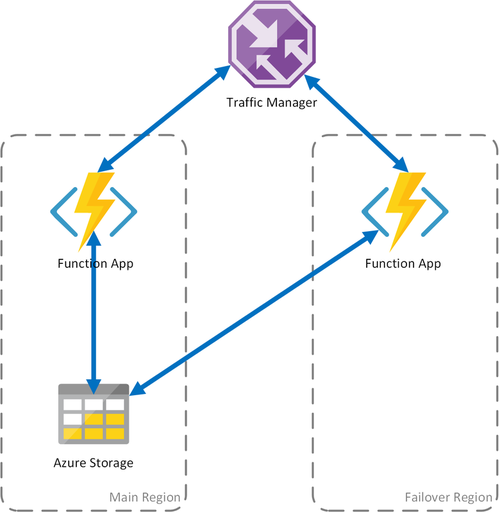
W przypadku korzystania z tego scenariusza wdrażania istnieje kilka korzyści:
- Jeśli infrastruktura obliczeniowa ulegnie awarii, praca może wznowić pracę w regionie trybu failover bez utraty danych.
- Usługa Traffic Manager automatycznie zajmuje się automatycznym przejściem w tryb failover do aplikacji funkcji w dobrej kondycji.
- Usługa Traffic Manager automatycznie ponownie ustanawia ruch do podstawowej aplikacji funkcji po skorygowaniu awarii.
Jednak w tym scenariuszu należy wziąć pod uwagę następujące kwestie:
- Jeśli aplikacja funkcji jest wdrażana przy użyciu dedykowanego planu App Service, replikowanie infrastruktury obliczeniowej w centrum danych trybu failover zwiększa koszty.
- Ten scenariusz obejmuje awarie w infrastrukturze obliczeniowej, ale konto magazynu nadal jest pojedynczym punktem awarii aplikacji funkcji. Jeśli wystąpi awaria magazynu, aplikacja przestój wystąpi.
- Jeśli aplikacja funkcji zostanie przełączona w tryb failover, zostanie zwiększone opóźnienie, ponieważ będzie ona uzyskiwać dostęp do konta magazynu w różnych regionach.
- Uzyskiwanie dostępu do usługi magazynu z innego regionu, w którym znajduje się, wiąże się z wyższymi kosztami z powodu ruchu wychodzącego sieci.
- Ten scenariusz zależy od usługi Traffic Manager. Biorąc pod uwagę sposób działania usługi Traffic Manager, aplikacja kliencka korzystająca z funkcji Durable Musi wykonać zapytanie o adres aplikacji funkcji z usługi Traffic Manager.
Uwaga
Począwszy od wersji 2.3.0 rozszerzenia Durable Functions, dwie aplikacje funkcji mogą być uruchamiane bezpiecznie w tym samym czasie przy użyciu tego samego konta magazynu i konfiguracji centrum zadań. Pierwsza aplikacja do uruchomienia uzyska dzierżawę obiektu blob na poziomie aplikacji, która uniemożliwia innym aplikacjom kradzież komunikatów z kolejek centrum zadań. Jeśli pierwsza aplikacja przestanie działać, jej dzierżawa wygaśnie i będzie mogła zostać uzyskana przez drugą aplikację, która następnie przejdzie do przetwarzania komunikatów centrum zadań.
Przed wersją 2.3.0 aplikacje funkcji skonfigurowane do korzystania z tego samego konta magazynu będą przetwarzać komunikaty i aktualizować artefakty magazynu jednocześnie, co powoduje znacznie większe ogólne opóźnienia i koszty ruchu wychodzącego. Jeśli aplikacje podstawowe i repliki kiedykolwiek mają wdrożony inny kod, nawet tymczasowo, orkiestracje mogą również nie działać poprawnie z powodu niespójności funkcji orkiestratora w dwóch aplikacjach. Dlatego zaleca się, aby wszystkie aplikacje wymagające dystrybucji geograficznej na potrzeby odzyskiwania po awarii używały rozszerzenia Durable w wersji 2.3.0 lub nowszej.
Scenariusz 2 — równoważenie obciążenia obliczeniowego przy użyciu magazynu regionalnego
Powyższy scenariusz obejmuje tylko przypadek awarii w infrastrukturze obliczeniowej. Jeśli usługa magazynu nie powiedzie się, spowoduje to awarię aplikacji funkcji. Aby zapewnić ciągłą obsługę funkcji trwałych, w tym scenariuszu jest używane lokalne konto magazynu w każdym regionie, w którym są wdrażane aplikacje funkcji.
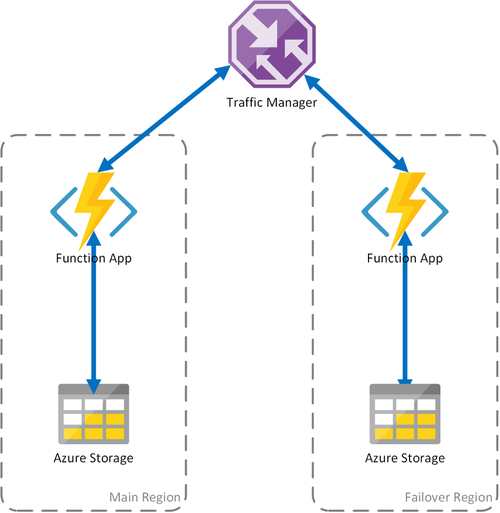
To podejście dodaje ulepszenia w poprzednim scenariuszu:
- Jeśli aplikacja funkcji ulegnie awarii, usługa Traffic Manager zajmie się trybem failover w regionie pomocniczym. Jednak ze względu na to, że aplikacja funkcji opiera się na własnym koncie magazynu, trwałe funkcje nadal działają.
- Podczas pracy w trybie failover nie ma dodatkowego opóźnienia w regionie trybu failover, ponieważ aplikacja funkcji i konto magazynu są kolokowane.
- Awaria warstwy magazynu spowoduje błędy w funkcjach trwałych, co z kolei spowoduje przekierowanie do regionu trybu failover. Ponownie, ponieważ aplikacja funkcji i magazyn są izolowane dla poszczególnych regionów, funkcje trwałe będą nadal działać.
Ważne zagadnienia dotyczące tego scenariusza:
- Jeśli aplikacja funkcji jest wdrażana przy użyciu dedykowanego planu App Service, replikowanie infrastruktury obliczeniowej w centrum danych trybu failover zwiększa koszty.
- Bieżący stan nie jest przełączany w tryb failover, co oznacza, że istniejące aranżacje i jednostki zostaną skutecznie wstrzymane i niedostępne do momentu odzyskania regionu podstawowego.
Podsumowując, kompromis między pierwszym i drugim scenariuszem polega na tym, że opóźnienie jest zachowywane, a koszty ruchu wychodzącego są zminimalizowane, ale istniejące aranżacje i jednostki będą niedostępne podczas przestoju. To, czy te kompromisy są dopuszczalne, zależy od wymagań aplikacji.
Scenariusz 3 — równoważenie obciążenia obliczeniowego z magazynem udostępnionym GRS
Ten scenariusz jest modyfikacją pierwszego scenariusza implementowania udostępnionego konta magazynu. Główną różnicą jest to, że konto magazynu jest tworzone z włączoną replikacją geograficzną. Funkcjonalnie ten scenariusz zapewnia takie same korzyści jak scenariusz 1, ale zapewnia dodatkowe korzyści z odzyskiwania danych:
- Magazyn geograficznie nadmiarowy (GRS) i dostęp do odczytu GRS (RA-GRS) maksymalizuje dostępność konta magazynu.
- Jeśli wystąpiła regionalna awaria usługi Storage, możesz ręcznie zainicjować przejście w tryb failover do repliki pomocniczej. W ekstremalnych okolicznościach, w których region zostanie utracony z powodu poważnej awarii, firma Microsoft może zainicjować regionalny tryb failover. W takim przypadku nie jest wymagana żadna akcja ze swojej strony.
- W przypadku przejścia w tryb failover stan funkcji trwałych zostanie zachowany do ostatniej replikacji konta magazynu, co zwykle występuje co kilka minut.
Podobnie jak w przypadku innych scenariuszy, należy wziąć pod uwagę następujące kwestie:
- Przejście w tryb failover do repliki może zająć trochę czasu. Do czasu ukończenia trybu failover i zaktualizowania rekordów DNS usługi Azure Storage aplikacja funkcji ulegnie awarii.
- Istnieje zwiększony koszt korzystania z kont magazynu replikowanych geograficznie.
- Replikacja GRS kopiuje dane asynchronicznie. Niektóre z najnowszych transakcji mogą zostać utracone z powodu opóźnienia procesu replikacji.
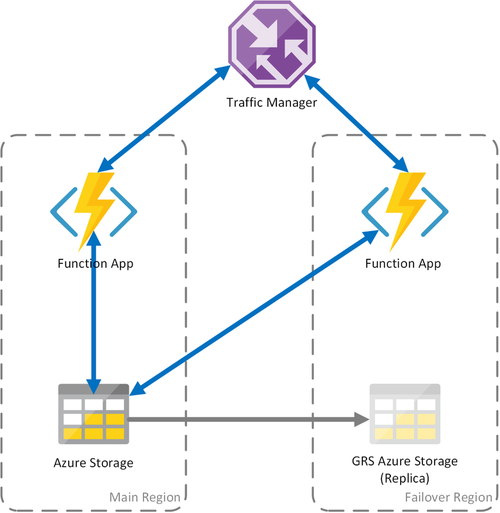
Uwaga
Zgodnie z opisem w scenariuszu 1 zdecydowanie zaleca się, aby aplikacje funkcji wdrożone przy użyciu tej strategii używały wersji 2.3.0 lub nowszej rozszerzenia Durable Functions.
Aby uzyskać więcej informacji, zobacz dokumentację odzyskiwania po awarii usługi Azure Storage i trybu failover konta magazynu .