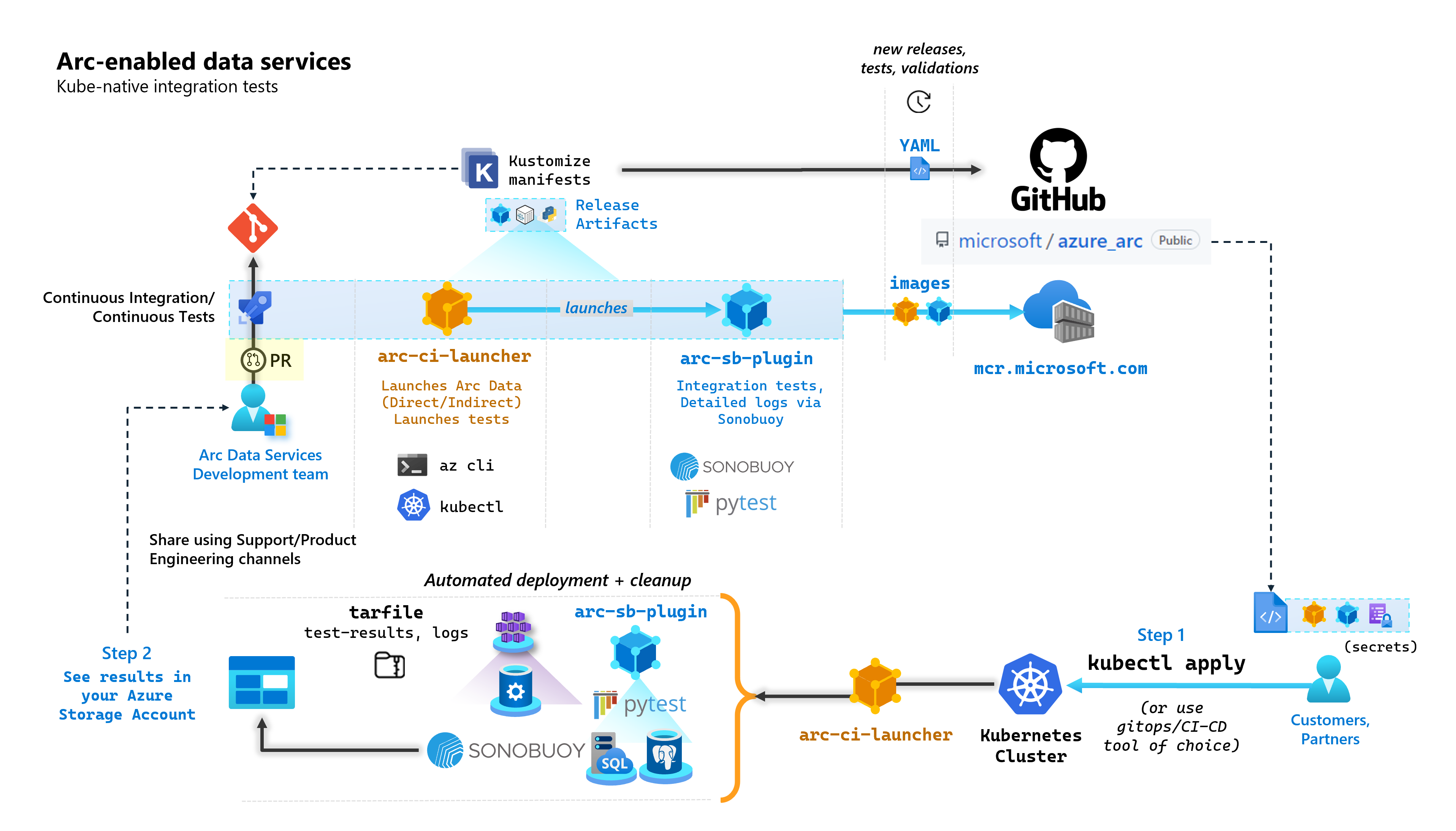
Samouczek: zautomatyzowane testowanie poprawności
W ramach każdego zatwierdzenia, które tworzy usługi danych z obsługą usługi Arc, firma Microsoft uruchamia zautomatyzowane potoki ciągłej integracji/ciągłego wdrażania, które wykonują kompleksowe testy. Te testy są orkiestrowane za pośrednictwem dwóch kontenerów, które są obsługiwane obok podstawowego produktu (kontroler danych, wystąpienie zarządzane SQL włączone przez serwer Usługi Azure Arc i PostgreSQL). Te kontenery to:
arc-ci-launcher: zawiera zależności wdrażania (na przykład rozszerzenia interfejsu wiersza polecenia), a także kod wdrożenia produktu (przy użyciu interfejsu wiersza polecenia platformy Azure) dla trybów łączności bezpośredniej i pośredniej. Po dołączeniu platformy Kubernetes do kontrolera danych kontener używa rozwiązania Sonobuoy do wyzwalania równoległych testów integracji.arc-sb-plugin: Wtyczka Sonobuoy zawierająca kompleksowe testy integracji oparte na narzędziu Pytest, począwszy od prostych testów weryfikacyjnych kompilacji (wdrożeń, usuwania), do złożonych scenariuszy wysokiej dostępności, testów chaosu (usuwania zasobów) itp.
Te kontenery testowania są udostępniane publicznie klientom i partnerom w celu przeprowadzenia testów poprawności usług danych z obsługą usługi Arc we własnych klastrach Kubernetes działających w dowolnym miejscu w celu zweryfikowania:
- Dystrybucja/wersje rozwiązania Kubernetes
- Usuwanie/wersje hosta
- Storage (/CSI), networking (
StorageClassnp.LoadBalancers, DNS) - Inne konfiguracje dotyczące platformy Kubernetes lub infrastruktury
W przypadku klientów, którzy zamierzają uruchamiać usługi danych z obsługą usługi Arc w nieudokumentowanej dystrybucji, muszą pomyślnie uruchomić te testy weryfikacyjne, aby zostały uznane za obsługiwane. Ponadto partnerzy mogą użyć tego podejścia do certyfikowania rozwiązania zgodnego z usługami danych z obsługą usługi Arc — zobacz Walidacja platformy Kubernetes usług danych z obsługą usługi Azure Arc.
Na poniższym diagramie przedstawiono ten proces wysokiego poziomu:
Z tego samouczka dowiesz się, jak wykonywać następujące czynności:
- Wdrażanie
arc-ci-launcherprzy użyciu poleceniakubectl - Sprawdzanie wyników testu poprawności na koncie usługi Azure Blob Storage
Wymagania wstępne
Poświadczenia:
- Plik
test.env.tmplzawiera wymagane poświadczenia i jest kombinacją istniejących wymagań wstępnych wymaganych do dołączenia klastra połączonego usługi Azure Arc i bezpośrednio połączonego kontrolera danych. Konfiguracja tego pliku jest wyjaśniona poniżej przy użyciu przykładów. - Plik kubeconfig do przetestowanego klastra Kubernetes z dostępem
cluster-admin(wymagany do dołączania połączonego klastra w tej chwili)
- Plik
Narzędzia klienckie:
kubectlzainstalowano — minimalna wersja (główna:"1", pomocnicza:"21")gitInterfejs wiersza polecenia (lub alternatywy oparte na interfejsie użytkownika)
Przygotowywanie manifestu platformy Kubernetes
Uruchamianie jest udostępniane w ramach microsoft/azure_arc repozytorium, ponieważ manifest Kustomize — Kustomize jest wbudowany kubectl — więc nie jest wymagane żadne dodatkowe narzędzia.
- Sklonuj repozytorium lokalnie:
git clone https://github.com/microsoft/azure_arc.git
- Przejdź do
azure_arc/arc_data_services/test/launcherfolderu , aby wyświetlić następującą strukturę folderów:
├── base <- Comon base for all Kubernetes Clusters
│ ├── configs
│ │ └── .test.env.tmpl <- To be converted into .test.env with credentials for a Kubernetes Secret
│ ├── kustomization.yaml <- Defines the generated resources as part of the launcher
│ └── launcher.yaml <- Defines the Kubernetes resources that make up the launcher
└── overlays <- Overlays for specific Kubernetes Clusters
├── aks
│ ├── configs
│ │ └── patch.json.tmpl <- To be converted into patch.json, patch for Data Controller control.json
│ └── kustomization.yaml
├── kubeadm
│ ├── configs
│ │ └── patch.json.tmpl
│ └── kustomization.yaml
└── openshift
├── configs
│ └── patch.json.tmpl
├── kustomization.yaml
└── scc.yaml
W tym samouczku skupimy się na krokach dotyczących usługi AKS, ale powyższa struktura nakładek może zostać rozszerzona w celu uwzględnienia dodatkowych dystrybucji platformy Kubernetes.
Gotowy do wdrożenia manifest będzie reprezentować następujące elementy:
├── base
│ ├── configs
│ │ ├── .test.env <- Config 1: For Kubernetes secret, see sample below
│ │ └── .test.env.tmpl
│ ├── kustomization.yaml
│ └── launcher.yaml
└── overlays
└── aks
├── configs
│ ├── patch.json.tmpl
│ └── patch.json <- Config 2: For control.json patching, see sample below
└── kustomization.yam
Istnieją dwa pliki, które należy wygenerować w celu zlokalizowania modułu uruchamiającego w określonym środowisku. Każdy z tych plików można wygenerować przez wklejanie kopii i wypełnianie każdego z powyższych plików szablonu (*.tmpl):
.test.env: wypełnij z.test.env.tmplpatch.json: wypełnij zpatch.json.tmpl
Napiwek
Jest .test.env to pojedynczy zestaw zmiennych środowiskowych, które napędzają zachowanie modułu uruchamiającego. Wygenerowanie go z opieką dla danego środowiska zapewni powtarzalność zachowania modułu uruchamiającego.
Konfiguracja 1: .test.env
Wypełniona próbka .test.env pliku wygenerowana na .test.env.tmpl podstawie jest udostępniana poniżej z wbudowanym komentarzem.
Ważne
Poniższa składnia export VAR="value" nie ma być uruchamiana lokalnie w celu uzyskania zmiennych środowiskowych ze swojej maszyny — ale jest dostępna dla modułu uruchamiającego. Moduł uruchamiający instaluje ten .test.env plik jako kubernetes secret przy użyciu usługi Kustomize secretGenerator (Kustomize pobiera plik, base64 koduje zawartość całego pliku i zamienia go w wpis tajny Kubernetes). Podczas inicjowania uruchamianie uruchamia polecenie powłoki bash source , które importuje zmienne środowiskowe z pliku jako zainstalowanego .test.env do środowiska uruchamiania.
Innymi słowy, po skopiowaniu wklejania .test.env.tmpl i edytowaniu w celu utworzenia .test.envwygenerowanego pliku powinien wyglądać podobnie do poniższego przykładu. Proces wypełniania .test.env pliku jest identyczny w systemach operacyjnych i terminalach.
Napiwek
Istnieje kilka zmiennych środowiskowych, które wymagają dodatkowego wyjaśnienia dla jasności w powtarzalności. Zostaną one oznaczone jako komentarz.see detailed explanation below [X]
Napiwek
Zwróć uwagę, że poniższy .test.env przykład dotyczy trybu bezpośredniego . Niektóre z tych zmiennych, takie jak ARC_DATASERVICES_EXTENSION_VERSION_TAG nie mają zastosowania do trybu pośredniego . Dla uproszczenia najlepszym rozwiązaniem jest skonfigurowanie .test.env pliku ze zmiennymi trybu bezpośredniego, przełączenie spowoduje, że uruchamianie zignoruje CONNECTIVITY_MODE=indirect ustawienia specyficzne dla trybu bezpośredniego i użyje podzestawu z listy.
Innymi słowy, planowanie trybu bezpośredniego pozwala nam spełnić zmienne trybu pośredniego .
Zakończono próbkę elementu .test.env:
# ======================================
# Arc Data Services deployment version =
# ======================================
# Controller deployment mode: direct, indirect
# For 'direct', the launcher will also onboard the Kubernetes Cluster to Azure Arc
# For 'indirect', the launcher will skip Azure Arc and extension onboarding, and proceed directly to Data Controller deployment - see `patch.json` file
export CONNECTIVITY_MODE="direct"
# The launcher supports deployment of both GA/pre-GA trains - see detailed explanation below [1]
export ARC_DATASERVICES_EXTENSION_RELEASE_TRAIN="stable"
export ARC_DATASERVICES_EXTENSION_VERSION_TAG="1.11.0"
# Image version
export DOCKER_IMAGE_POLICY="Always"
export DOCKER_REGISTRY="mcr.microsoft.com"
export DOCKER_REPOSITORY="arcdata"
export DOCKER_TAG="v1.11.0_2022-09-13"
# "arcdata" Azure CLI extension version override - see detailed explanation below [2]
export ARC_DATASERVICES_WHL_OVERRIDE=""
# ================
# ARM parameters =
# ================
# Custom Location Resource Provider Azure AD Object ID - this is a single, unique value per Azure AD tenant - see detailed explanation below [3]
export CUSTOM_LOCATION_OID="..."
# A pre-rexisting Resource Group is used if found with the same name. Otherwise, launcher will attempt to create a Resource Group
# with the name specified, using the Service Principal specified below (which will require `Owner/Contributor` at the Subscription level to work)
export LOCATION="eastus"
export RESOURCE_GROUP_NAME="..."
# A Service Principal with "sufficient" privileges - see detailed explanation below [4]
export SPN_CLIENT_ID="..."
export SPN_CLIENT_SECRET="..."
export SPN_TENANT_ID="..."
export SUBSCRIPTION_ID="..."
# Optional: certain integration tests test upload to Log Analytics workspace:
# https://learn.microsoft.com/azure/azure-arc/data/upload-logs
export WORKSPACE_ID="..."
export WORKSPACE_SHARED_KEY="..."
# ====================================
# Data Controller deployment profile =
# ====================================
# Samples for AKS
# To see full list of CONTROLLER_PROFILE, run: az arcdata dc config list
export CONTROLLER_PROFILE="azure-arc-aks-default-storage"
# azure, aws, gcp, onpremises, alibaba, other
export DEPLOYMENT_INFRASTRUCTURE="azure"
# The StorageClass used for PVCs created during the tests
export KUBERNETES_STORAGECLASS="default"
# ==============================
# Launcher specific parameters =
# ==============================
# Log/test result upload from launcher container, via SAS URL - see detailed explanation below [5]
export LOGS_STORAGE_ACCOUNT="<your-storage-account>"
export LOGS_STORAGE_ACCOUNT_SAS="?sv=2021-06-08&ss=bfqt&srt=sco&sp=rwdlacupiytfx&se=...&spr=https&sig=..."
export LOGS_STORAGE_CONTAINER="arc-ci-launcher-1662513182"
# Test behavior parameters
# The test suites to execute - space seperated array,
# Use these default values that run short smoke tests, further elaborate test suites will be added in upcoming releases
export SQL_HA_TEST_REPLICA_COUNT="3"
export TESTS_DIRECT="direct-crud direct-hydration controldb"
export TESTS_INDIRECT="billing controldb kube-rbac"
export TEST_REPEAT_COUNT="1"
export TEST_TYPE="ci"
# Control launcher behavior by setting to '1':
#
# - SKIP_PRECLEAN: Skips initial cleanup
# - SKIP_SETUP: Skips Arc Data deployment
# - SKIP_TEST: Skips sonobuoy tests
# - SKIP_POSTCLEAN: Skips final cleanup
# - SKIP_UPLOAD: Skips log upload
#
# See detailed explanation below [6]
export SKIP_PRECLEAN="0"
export SKIP_SETUP="0"
export SKIP_TEST="0"
export SKIP_POSTCLEAN="0"
export SKIP_UPLOAD="0"
Ważne
W przypadku generowania pliku konfiguracji na maszynie z systemem Windows należy przekonwertować sekwencję końcową z CRLF systemu (Windows) na LF (Linux), uruchamianą arc-ci-launcher jako kontener systemu Linux. Pozostawienie wiersza kończącego się CRLF może spowodować błąd po arc-ci-launcher uruchomieniu kontenera — na /launcher/config/.test.env: $'\r': command not found przykład: przeprowadź zmianę przy użyciu programu VSCode (w prawym dolnym rogu okna):

Szczegółowe wyjaśnienie niektórych zmiennych
1. ARC_DATASERVICES_EXTENSION_* — Wersja rozszerzenia i szkolenie
Obowiązkowe: jest to wymagane w przypadku
directwdrożeń w trybie.
Moduł uruchamiający może wdrażać zarówno wersje ogólnodostępne, jak i wersje wstępne.
Wersja rozszerzenia do mapowania release-train (ARC_DATASERVICES_EXTENSION_RELEASE_TRAIN) jest uzyskiwana z tego miejsca:
- Ogólna dostępność:
stable- Dziennik wersji - Wstępna dostępność:
preview- Testowanie wersji wstępnej
2. ARC_DATASERVICES_WHL_OVERRIDE — Adres URL pobierania poprzedniej wersji interfejsu wiersza polecenia platformy Azure
Opcjonalnie: pozostaw to pole puste,
.test.envaby użyć wstępnie spakowanej wartości domyślnej.
Obraz uruchamiania jest wstępnie spakowany z najnowszą wersją interfejsu wiersza polecenia arcdata w momencie wydania każdego obrazu kontenera. Jednak aby pracować ze starszymi wersjami i testowaniem uaktualniania, może być konieczne podanie linku pobierania adresu URL obiektu blob interfejsu wiersza polecenia platformy Azure w celu zastąpienia wersji wstępnie spakowanej; Na przykład w celu poinstruowania modułu uruchamiającego, aby zainstalować wersję 1.4.3, wypełnij następujące informacje:
export ARC_DATASERVICES_WHL_OVERRIDE="https://azurearcdatacli.blob.core.windows.net/cli-extensions/arcdata-1.4.3-py2.py3-none-any.whl"
Mapowanie adresu URL obiektu blob w wersji interfejsu wiersza polecenia można znaleźć tutaj.
3. CUSTOM_LOCATION_OID — Identyfikator obiektu lokalizacji niestandardowych z określonej dzierżawy firmy Microsoft Entra
Obowiązkowe: jest to wymagane w przypadku tworzenia lokalizacji niestandardowej połączonego klastra.
Poniższe kroki pochodzą z obszaru Włącz lokalizacje niestandardowe w klastrze , aby pobrać unikatowy identyfikator obiektu lokalizacji niestandardowej dla dzierżawy firmy Microsoft Entra.
Istnieją dwa podejścia do uzyskania CUSTOM_LOCATION_OID dzierżawy firmy Microsoft Entra.
Za pośrednictwem interfejsu wiersza polecenia platformy Azure:
az ad sp show --id bc313c14-388c-4e7d-a58e-70017303ee3b --query objectId -o tsv # 51dfe1e8-70c6-4de... <--- This is for Microsoft's own tenant - do not use, the value for your tenant will be different, use that instead to align with the Service Principal for launcher.
Za pośrednictwem witryny Azure Portal przejdź do bloku Microsoft Entra i wyszukaj ciąg
Custom Locations RP: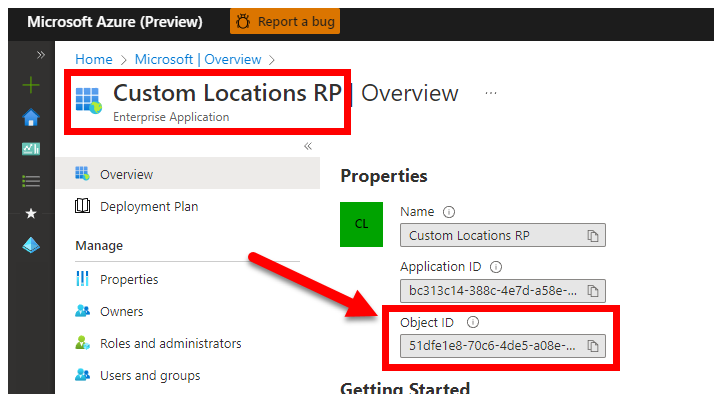
4. SPN_CLIENT_* — Poświadczenia jednostki usługi
Obowiązkowe: jest to wymagane w przypadku wdrożeń w trybie bezpośrednim.
Uruchamianie loguje się na platformie Azure przy użyciu tych poświadczeń.
Testowanie poprawności ma być przeprowadzane w klastrze Kubernetes nieprodukcyjnym i testowym subskrypcji platformy Azure — koncentrując się na funkcjonalnej weryfikacji konfiguracji platformy Kubernetes/infrastruktury. W związku z tym, aby uniknąć liczby ręcznych kroków wymaganych do wykonania uruchomień, zaleca się podanie elementu SPN_CLIENT_ID/SECRET , który ma Owner poziom grupy zasobów (lub subskrypcji), ponieważ utworzy kilka zasobów w tej grupie zasobów, a także przypisanie uprawnień do tych zasobów względem kilku tożsamości zarządzanych utworzonych w ramach wdrożenia (te przypisania ról z kolei wymagają, aby jednostka usługi miała Ownerwartość ).
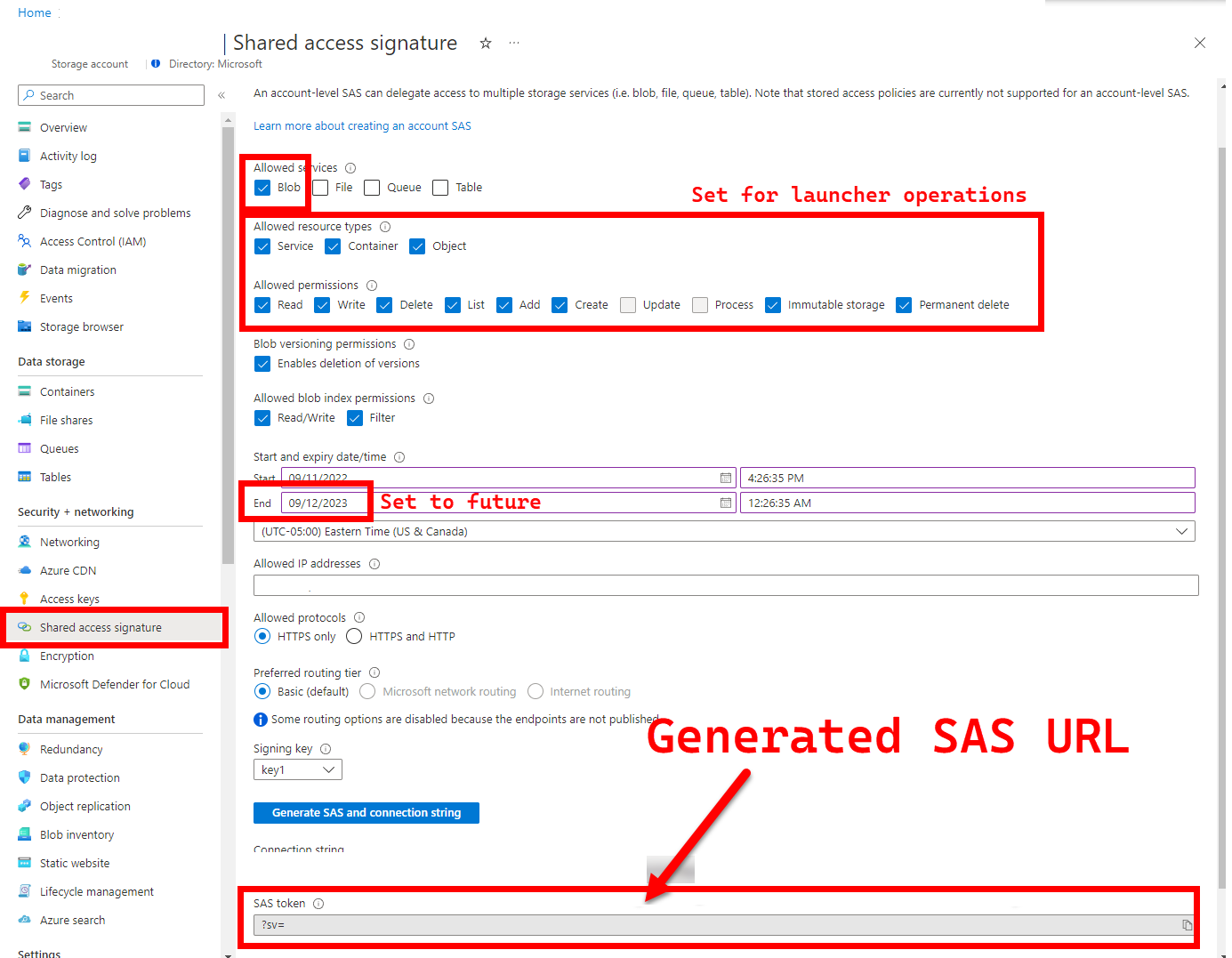
5. LOGS_STORAGE_ACCOUNT_SAS — Adres URL sygnatury dostępu współdzielonego konta usługi Blob Storage
Zalecane: pozostawienie tego pustego oznacza, że nie uzyskasz wyników testów i dzienników.
Uruchamianie wymaga trwałej lokalizacji (Azure Blob Storage) w celu przekazania wyników, ponieważ platforma Kubernetes nie zezwala na kopiowanie plików z zatrzymanych/ukończonych zasobników — zobacz tutaj. Moduł uruchamiający osiąga łączność z usługą Azure Blob Storage przy użyciu adresu URL sygnatury dostępu współdzielonego o zakresie konta (w przeciwieństwie do kontenera lub obiektu blob ) — podpisany adres URL z definicją dostępu powiązanego czasowo — zobacz Udzielanie ograniczonego dostępu do zasobów usługi Azure Storage przy użyciu sygnatur dostępu współdzielonego (SAS), aby:
- Utwórz nowy kontener magazynu na istniejącym koncie magazynu (
LOGS_STORAGE_ACCOUNT), jeśli nie istnieje (nazwa oparta na )LOGS_STORAGE_CONTAINER - Utwórz nowe, unikatowo nazwane obiekty blob (pliki tar dziennika testowego)
Poniższe kroki pochodzą z sekcji Udzielanie ograniczonego dostępu do zasobów usługi Azure Storage przy użyciu sygnatur dostępu współdzielonego (SAS).
Napiwek
Adresy URL sygnatur dostępu współdzielonego różnią się od klucza konta magazynu. Adres URL sygnatury dostępu współdzielonego jest sformatowany w następujący sposób.
?sv=2021-06-08&ss=bfqt&srt=sco&sp=rwdlacupiytfx&se=...&spr=https&sig=...
Istnieje kilka metod generowania adresu URL sygnatury dostępu współdzielonego. W tym przykładzie pokazano portal:
Aby zamiast tego użyć interfejsu wiersza polecenia platformy Azure, zobacz az storage account generate-sas
6. SKIP_* - kontrolowanie zachowania uruchamiania przez pomijanie niektórych etapów
Opcjonalnie: pozostaw to pole puste,
.test.envaby uruchomić wszystkie etapy (równoważne0lub puste)
SKIP_* Uruchamianie i pomijanie określonych etapów, na przykład w celu wykonania uruchomienia "tylko oczyszczania".
Mimo że moduł uruchamiający jest przeznaczony do czyszczenia zarówno na początku, jak i na końcu każdego przebiegu, możliwe jest uruchomienie i/lub niepowodzenia testowe pozostawienia zasobów pozostałości. Aby uruchomić moduł uruchamiania w trybie "tylko oczyszczanie", ustaw następujące zmienne w pliku .test.env:
export SKIP_PRECLEAN="0" # Run cleanup
export SKIP_SETUP="1" # Do not setup Arc-enabled Data Services
export SKIP_TEST="1" # Do not run integration tests
export SKIP_POSTCLEAN="1" # POSTCLEAN is identical to PRECLEAN, although idempotent, not needed here
export SKIP_UPLOAD="1" # Do not upload logs from this run
Powyższe ustawienia instruują moduł uruchamiający, aby wyczyścił wszystkie zasoby usług Arc i Arc Data Services, a nie wdrażał/testował/przekazywać dzienniki.
Konfiguracja 2: patch.json
Wypełniona próbka patch.json pliku wygenerowana na patch.json.tmpl podstawie jest udostępniana poniżej:
Należy pamiętać, że wartości
spec.docker.registry, repository, imageTagpowinny być identyczne z powyższymi wartościami.test.env
Zakończono próbkę elementu patch.json:
{
"patch": [
{
"op": "add",
"path": "spec.docker",
"value": {
"registry": "mcr.microsoft.com",
"repository": "arcdata",
"imageTag": "v1.11.0_2022-09-13",
"imagePullPolicy": "Always"
}
},
{
"op": "add",
"path": "spec.storage.data.className",
"value": "default"
},
{
"op": "add",
"path": "spec.storage.logs.className",
"value": "default"
}
]
}
Wdrażanie modułu uruchamiania
Zaleca się wdrożenie modułu uruchamiania w klastrze nieprodukcyjnym/testowym — ponieważ wykonuje destrukcyjne akcje w usłudze Arc i innych używanych zasobach platformy Kubernetes.
imageTag specyfikacja
Uruchamianie jest definiowane w manifeście Kubernetes jako Jobelement , który wymaga poinstruowania platformy Kubernetes, gdzie można znaleźć obraz modułu uruchamiania. Ta opcja jest ustawiona w pliku base/kustomization.yaml:
images:
- name: arc-ci-launcher
newName: mcr.microsoft.com/arcdata/arc-ci-launcher
newTag: v1.11.0_2022-09-13
Napiwek
Aby podsumować, w tym momencie - istnieją 3 określone miejsca imageTag, dla jasności, oto wyjaśnienie różnych zastosowań każdego z nich. Zazwyczaj — podczas testowania danej wersji wszystkie 3 wartości będą takie same (wyrównanie do danej wersji):
| # | Nazwa pliku | Nazwa zmiennej | Dlaczego? | Używane przez? |
|---|---|---|---|---|
| 1 | .test.env |
DOCKER_TAG |
Określanie źródła obrazu programu inicjjącego w ramach instalacji rozszerzenia | az k8s-extension create w wyrzutni |
| 2 | patch.json |
value.imageTag |
Określanie źródła obrazu kontrolera danych | az arcdata dc create w wyrzutni |
| 3 | kustomization.yaml |
images.newTag |
Określanie źródła obrazu modułu uruchamiania | kubectl applying wyrzutni |
kubectl apply
Aby sprawdzić, czy manifest został prawidłowo skonfigurowany, spróbuj przeprowadzić walidację po stronie klienta za pomocą polecenia --dry-run=client, która wyświetla zasoby Kubernetes do utworzenia dla modułu uruchamiania:
kubectl apply -k arc_data_services/test/launcher/overlays/aks --dry-run=client
# namespace/arc-ci-launcher created (dry run)
# serviceaccount/arc-ci-launcher created (dry run)
# clusterrolebinding.rbac.authorization.k8s.io/arc-ci-launcher created (dry run)
# secret/test-env-fdgfm8gtb5 created (dry run) <- Created from Config 1: `patch.json`
# configmap/control-patch-2hhhgk847m created (dry run) <- Created from Config 2: `.test.env`
# job.batch/arc-ci-launcher created (dry run)
Aby wdrożyć dzienniki uruchamiania i końcowego, uruchom następujące polecenie:
kubectl apply -k arc_data_services/test/launcher/overlays/aks
kubectl wait --for=condition=Ready --timeout=360s pod -l job-name=arc-ci-launcher -n arc-ci-launcher
kubectl logs job/arc-ci-launcher -n arc-ci-launcher --follow
W tym momencie powinien zostać uruchomiony moduł uruchamiania — i powinny zostać wyświetlone następujące elementy:
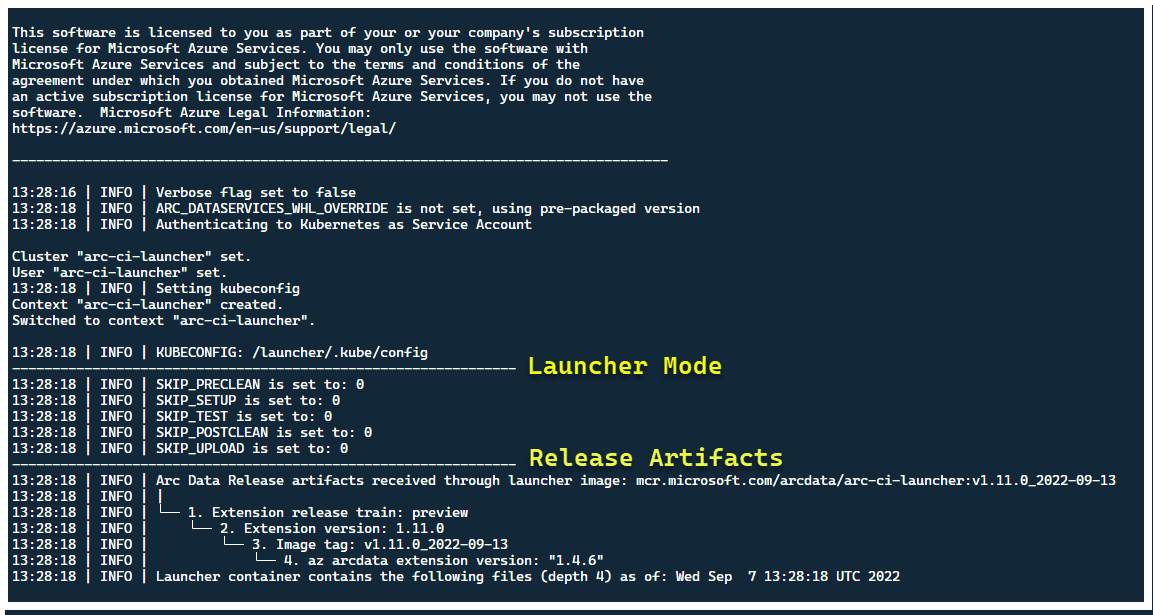
Mimo że najlepszym rozwiązaniem jest wdrożenie modułu uruchamiania w klastrze bez istniejących wcześniej zasobów usługi Arc, uruchamianie zawiera walidację przed lotem w celu odnalezienia istniejących wstępnie istniejących zasobów usługi Arc i Arc Data Services CRD i ARM oraz prób wyczyszczenia ich w oparciu o najlepsze nakłady pracy (przy użyciu podanych poświadczeń jednostki usługi), przed wdrożeniem nowej wersji:
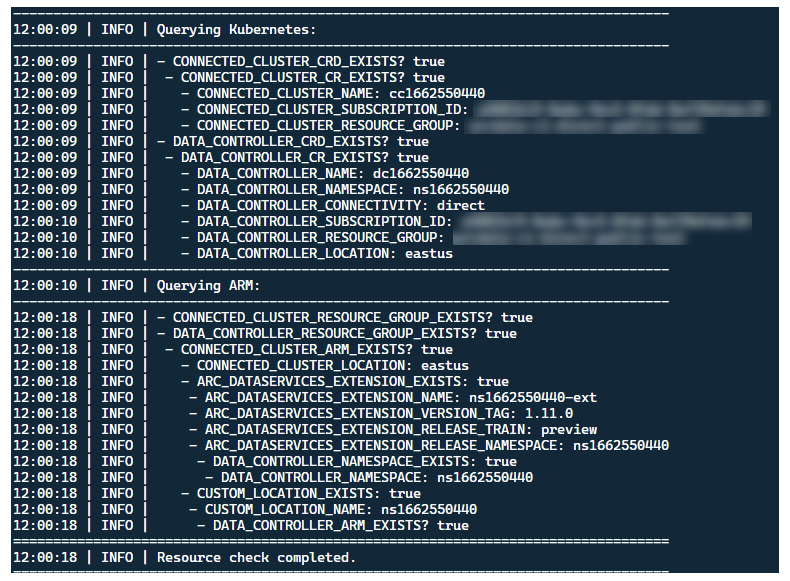
Ten sam proces odnajdywania metadanych i oczyszczania jest również uruchamiany po zakończeniu uruchamiania, aby pozostawić klaster tak blisko, jak to możliwe, aby był wstępnie istniejący stan przed uruchomieniem.
Kroki wykonywane przez moduł uruchamiania
Na wysokim poziomie uruchamianie wykonuje następującą sekwencję kroków:
Uwierzytelnianie w interfejsie API kubernetes przy użyciu zainstalowanego konta usługi
Uwierzytelnianie w interfejsie API usługi ARM przy użyciu zainstalowanej wpisów tajnych jednostki usługi
Przeprowadź skanowanie metadanych CRD, aby odnaleźć istniejące zasoby niestandardowe usług Arc i Arc Data Services
Wyczyść wszystkie istniejące zasoby niestandardowe na platformie Kubernetes i kolejne zasoby na platformie Azure. Jeśli jakiekolwiek niezgodności między poświadczeniami w
.test.envporównaniu z zasobami istniejącymi w klastrze, zamknij.Wygeneruj unikatowy zestaw zmiennych środowiskowych na podstawie sygnatury czasowej dla nazwy klastra usługi Arc, kontrolera danych i niestandardowej lokalizacji/przestrzeni nazw. Wyświetla zmienne środowiskowe, zaciemniając poufne wartości (np. hasło jednostki usługi itp.)
a. W przypadku trybu bezpośredniego — dołącza klaster do usługi Azure Arc, a następnie wdraża kontroler.
b. W przypadku trybu pośredniego: wdrażanie kontrolera danych
Gdy kontroler danych to
Ready, wygeneruj zestaw dzienników interfejsu wiersza polecenia platformy Azure (az arcdata dc debug) i zapisz lokalnie, oznaczony jakosetup-complete— jako punkt odniesienia.Użyj zmiennej środowiskowej
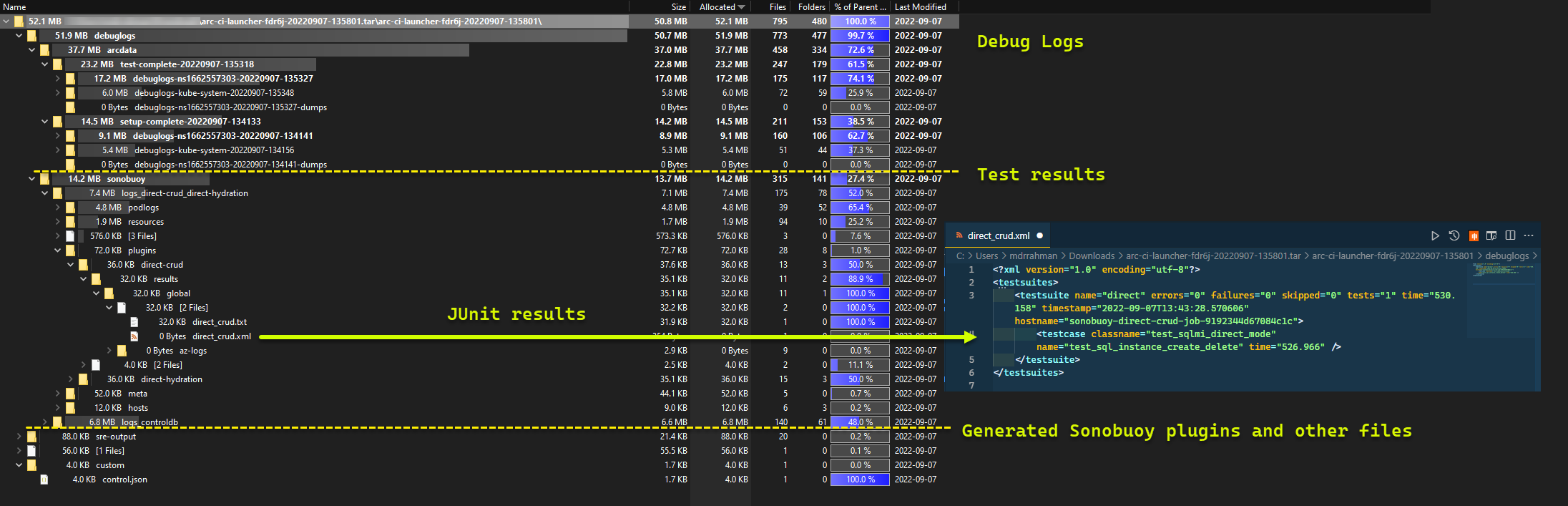
TESTS_DIRECT/INDIRECTz.test.env, aby uruchomić zestaw równoległych przebiegów testów Sonobuoy na podstawie tablicy rozdzielanej spacjami (TESTS_(IN)DIRECT). Te przebiegi są wykonywane w nowejsonobuoyprzestrzeni nazw przy użyciuarc-sb-pluginzasobnika zawierającego testy poprawności Pytest.Agregator Sonobuoy gromadzi
junitwyniki testów i dzienniki naarc-sb-pluginprzebieg testu, które są eksportowane do zasobnika uruchamiania.Zwraca kod zakończenia testów i generuje inny zestaw dzienników debugowania — interfejs wiersza polecenia platformy Azure i
sonobuoy— przechowywany lokalnie z etykietą .test-completeWykonaj skanowanie metadanych CRD podobne do kroku 3, aby odnaleźć istniejące zasoby niestandardowe usług Arc i Arc Data Services. Następnie przejdź do zniszczenia wszystkich zasobów danych Arc i Arc w odwrotnej kolejności od wdrożenia, a także crDs, Role/ClusterRoles, PV/PVCs itp.
Spróbuj użyć udostępnionego tokenu
LOGS_STORAGE_ACCOUNT_SASSAS, aby utworzyć nowy kontener konta magazynu o nazwie naLOGS_STORAGE_CONTAINERpodstawie , w istniejącym wcześniej koncieLOGS_STORAGE_ACCOUNTmagazynu . Jeśli kontener konta magazynu już istnieje, użyj go. Przekaż wszystkie wyniki testu lokalnego i dzienniki do tego kontenera magazynu jako tarball (zobacz poniżej).Wyjście.
Testy wykonywane dla zestawu testów
Dostępnych jest około 375 unikatowych testów integracji w 27 zestawach testów — każda z nich testuje oddzielne funkcje.
| Suita # | Nazwa zestawu testów | Opis testu |
|---|---|---|
| 1 | ad-connector |
Testuje wdrażanie i aktualizowanie łącznika usługi Active Directory (AD Connector). |
| 2 | billing |
Testowanie różnych typów licencji Krytyczne dla działania firmy jest odzwierciedlane w tabeli zasobów na kontrolerze, używane do przekazywania rozliczeń. |
| 3 | ci-billing |
Podobnie jak billing, ale z większą ilością permutacji procesora CPU/pamięci. |
| 100 | ci-sqlinstance |
Długotrwałe testy na potrzeby tworzenia, aktualizacji, aktualizacji gp —> BC Update, walidacji kopii zapasowej i agenta programu SQL Server. |
| 5 | controldb |
Testy kontroli bazy danych — sprawdzanie wpisów tajnych programu SA, weryfikacja logowania systemu, tworzenie inspekcji i sprawdzanie kondycji wersji kompilacji SQL. |
| 6 | dc-export |
Przekazywanie rozliczeń i użycia w trybie pośrednim. |
| 7 | direct-crud |
Tworzy wystąpienie SQL przy użyciu wywołań usługi ARM, sprawdza poprawność zarówno na platformie Kubernetes, jak i w usłudze ARM. |
| 8 | direct-fog |
Tworzy wiele wystąpień SQL i tworzy grupę trybu failover między nimi przy użyciu wywołań usługi ARM. |
| 9 | direct-hydration |
Tworzy wystąpienie SQL za pomocą interfejsu API Kubernetes, weryfikuje obecność w usłudze ARM. |
| 10 | direct-upload |
Weryfikuje przekazywanie rozliczeń w trybie bezpośrednim |
| 11 | kube-rbac |
Zapewnia, że uprawnienia konta usługi Kubernetes Service dla usług Arc Data Services są zgodne z oczekiwaniami dotyczącymi najniższych uprawnień. |
| 12 | nonroot |
Zapewnia uruchamianie kontenerów jako użytkownik niebędący użytkownikiem głównym |
| 13 | postgres |
Wykonuje różne operacje tworzenia bazy danych Postgres, skalowania, wykonywania kopii zapasowych/przywracania testów. |
| 14 | release-sanitychecks |
Sprawdzanie kondycji wersji miesięcznych, takich jak wersje kompilacji programu SQL Server. |
| 15 | sqlinstance |
Krótsza wersja programu ci-sqlinstanceumożliwia szybkie walidacje. |
| 16 | sqlinstance-ad |
Testuje tworzenie wystąpień SQL za pomocą łącznika usługi Active Directory. |
| 17 | sqlinstance-credentialrotation |
Testuje automatyczną rotację poświadczeń zarówno dla ogólnego przeznaczenia, jak i Krytyczne dla działania firmy. |
| 18 | sqlinstance-ha |
Różne testy przeciążenia wysokiej dostępności, w tym ponowne uruchomienie zasobnika, wymuszone przejścia w tryb failover i zawieszenia. |
| 19 | sqlinstance-tde |
Różne testy Transparent Data Encryption. |
| 20 | telemetry-elasticsearch |
Weryfikuje pozyskiwanie dzienników w usłudze Elasticsearch. |
| 21 | telemetry-grafana |
Sprawdza, czy aplikacja Grafana jest osiągalna. |
| 22 | telemetry-influxdb |
Weryfikuje pozyskiwanie metryk do bazy danych InfluxDB. |
| 23 | telemetry-kafka |
Różne testy platformy Kafka przy użyciu protokołu SSL, konfiguracji pojedynczej/wielo brokera. |
| 24 | telemetry-monitorstack |
Testy składników monitorowania, takich jak Fluentbit i Collectd są funkcjonalne. |
| 25 | telemetry-telemetryrouter |
Testuje otwieranie telemetrii. |
| 26 | telemetry-webhook |
Testuje elementy webhook usług Data Services z prawidłowymi i nieprawidłowymi wywołaniami. |
| 27 | upgrade-arcdata |
Uaktualnia pełny pakiet wystąpień SQL (GP, BC 2 replica, BC 3 replica, with Active Directory) i uaktualnia z zeszłego miesiąca do najnowszej kompilacji. |
Na przykład w przypadku programu sqlinstance-hasą wykonywane następujące testy:
test_critical_configmaps_present: Zapewnia, że ConfigMaps i odpowiednie pola są obecne dla wystąpienia SQL.test_suspended_system_dbs_auto_heal_by_orchestrator: zapewnia, czymasterimsdbsą zawieszone w dowolny sposób (w tym przypadku użytkownik). Konserwacja programu Orchestrator uzgadnia ją automatycznie.test_suspended_user_db_does_not_auto_heal_by_orchestrator: zapewnia, że baza danych użytkownika została celowo zawieszona przez użytkownika, uzgadnianie konserwacji programu Orchestrator nie powoduje jego automatycznego naprawy.test_delete_active_orchestrator_twice_and_delete_primary_pod: Usuwa zasobnik orkiestratora wiele razy, a następnie replikę podstawową i sprawdza, czy wszystkie repliki są synchronizowane. Oczekiwania dotyczące czasu pracy w trybie failover dla 2 replik są złagodzone.test_delete_primary_pod: usuwa replikę podstawową i sprawdza, czy wszystkie repliki są synchronizowane. Oczekiwania dotyczące czasu pracy w trybie failover dla 2 replik są złagodzone.test_delete_primary_and_orchestrator_pod: Usuwa replikę podstawową i zasobnik orkiestratora oraz sprawdza, czy wszystkie repliki są synchronizowane.test_delete_primary_and_controller: Usuwa zasobnik repliki podstawowej i kontrolera danych oraz sprawdza, czy podstawowy punkt końcowy jest dostępny, a nowa replika podstawowa jest synchronizowana. Oczekiwania dotyczące czasu pracy w trybie failover dla 2 replik są złagodzone.test_delete_one_secondary_pod: Usuwa zasobnik repliki pomocniczej i kontrolera danych oraz sprawdza, czy wszystkie repliki są synchronizowane.test_delete_two_secondaries_pods: usuwa repliki pomocnicze i zasobnik kontrolera danych i sprawdza, czy wszystkie repliki są synchronizowane.test_delete_controller_orchestrator_secondary_replica_pods:test_failaway: Wymusza przejście grupy dostępności w tryb failover z bieżącego podstawowego elementu podstawowego, gwarantuje, że nowy element podstawowy nie jest taki sam jak stary podstawowy. Sprawdza, czy wszystkie repliki są synchronizowane.test_update_while_rebooting_all_non_primary_replicas: Testy oparte na kontrolerach aktualizacje są odporne na ponawianie prób pomimo różnych burzliwych okoliczności.
Uwaga
Niektóre testy mogą wymagać określonego sprzętu, takiego jak uprzywilejowany dostęp do kontrolerów domeny na potrzeby ad testów tworzenia wpisu konta i systemu DNS — które mogą nie być dostępne we wszystkich środowiskach, które chcą używać .arc-ci-launcher
Badanie wyników testu
Przykładowy kontener magazynu i plik przekazany przez moduł uruchamiania:
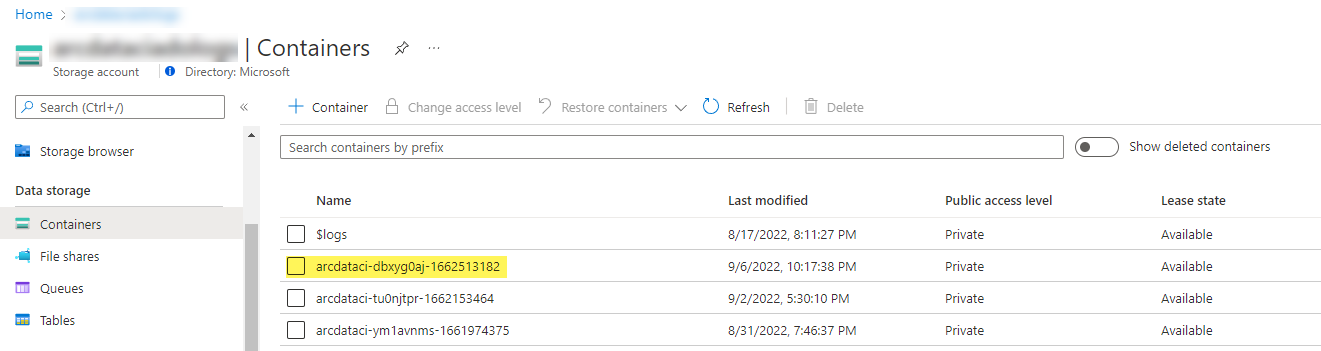
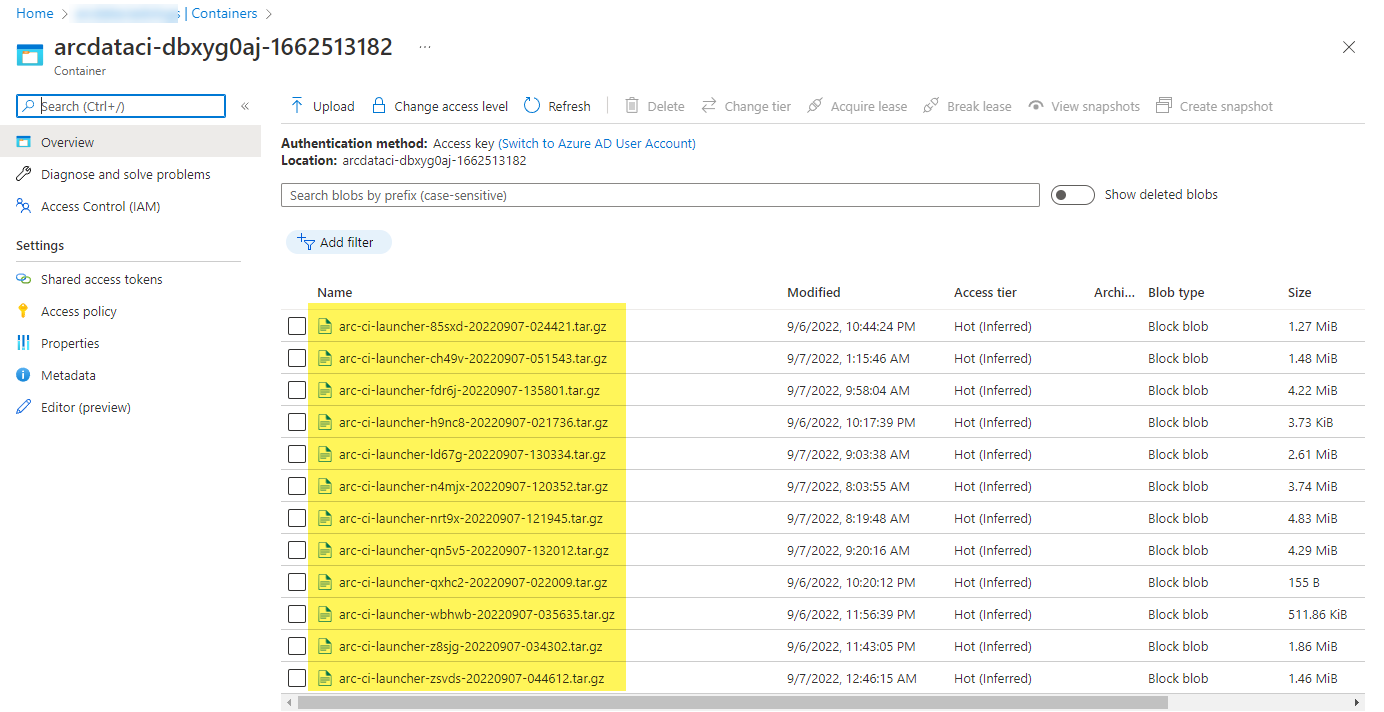
A wyniki testu wygenerowane na podstawie przebiegu:
Czyszczenie zasobów
Aby usunąć moduł uruchamiania, uruchom polecenie:
kubectl delete -k arc_data_services/test/launcher/overlays/aks
Spowoduje to wyczyszczenie manifestów zasobów wdrożonych w ramach uruchamiania.