Przenoszenie danych do klastra vFXT — pozyskiwanie danych równoległych
Po utworzeniu nowego klastra vFXT pierwszym zadaniem może być przeniesienie danych na nowy wolumin magazynu na platformie Azure. Jeśli jednak zwykła metoda przenoszenia danych wykonuje proste polecenie kopiowania z jednego klienta, prawdopodobnie zobaczysz niską wydajność kopiowania. Kopiowanie jednowątkowe nie jest dobrym rozwiązaniem do kopiowania danych do magazynu zaplecza klastra Avere vFXT.
Ponieważ klaster Avere vFXT for Azure to skalowalna pamięć podręczna z wieloma klientami, najszybszym i najbardziej wydajnym sposobem kopiowania danych do niego jest użycie wielu klientów. Ta technika zrównalizuje pozyskiwanie plików i obiektów.
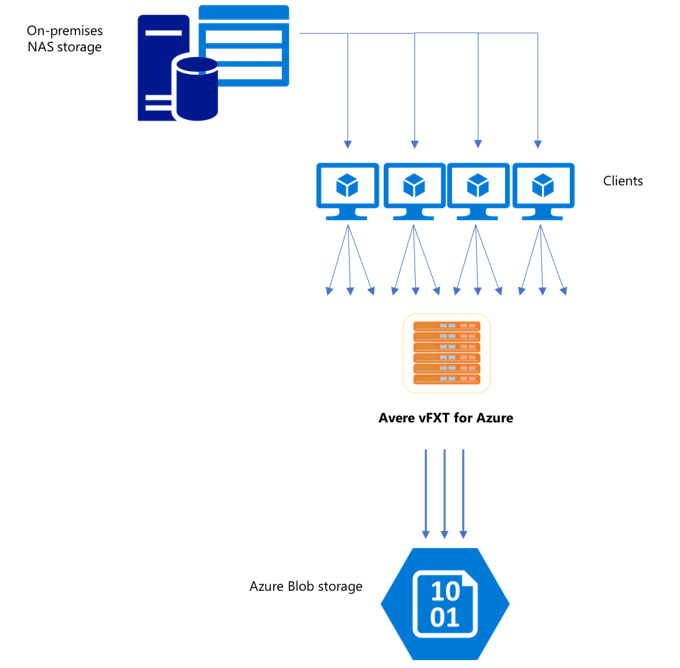
Polecenia cp lub copy , które są często używane do przesyłania danych z jednego systemu magazynu do innego, to procesy jednowątkowe, które kopiują tylko jeden plik naraz. Oznacza to, że serwer plików pozyskiwa tylko jeden plik jednocześnie — co jest stratą zasobów klastra.
W tym artykule opisano strategie tworzenia systemu kopiowania plików wielowątkowego obejmującego wiele klientów w celu przeniesienia danych do klastra Avere vFXT. Wyjaśniono w nim pojęcia dotyczące transferu plików i punkty decyzyjne, które mogą służyć do wydajnego kopiowania danych przy użyciu wielu klientów i prostych poleceń kopiowania.
Wyjaśnia również niektóre narzędzia, które mogą pomóc. Narzędzie msrsync może służyć do częściowego automatyzowania procesu dzielenia zestawu danych na zasobniki i używania rsync poleceń. Skrypt parallelcp jest innym narzędziem, które odczytuje katalog źródłowy i automatycznie wystawia polecenia kopiowania. Ponadto narzędzie może być używane w dwóch fazach, rsync aby zapewnić szybszą kopię, która nadal zapewnia spójność danych.
Kliknij link, aby przejść do sekcji:
- Przykład ręcznego kopiowania — dokładne wyjaśnienie przy użyciu poleceń kopiowania
- Dwufazowy przykład rsync
- Przykład częściowo zautomatyzowanego (msrsync)
- Przykład kopiowania równoległego
Szablon maszyny wirtualnej ingestor danych
Szablon usługi Resource Manager jest dostępny w usłudze GitHub, aby automatycznie utworzyć maszynę wirtualną przy użyciu równoległych narzędzi do pozyskiwania danych wymienionych w tym artykule.
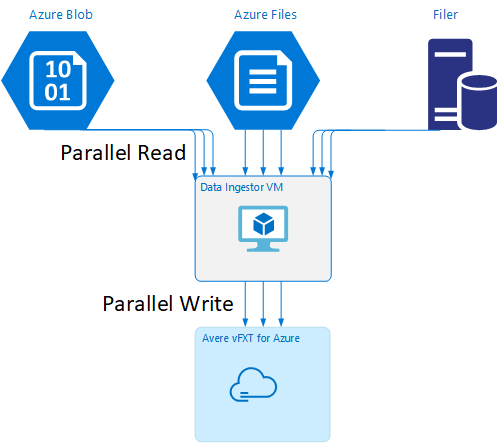
Maszyna wirtualna ingestor danych jest częścią samouczka, w którym nowo utworzona maszyna wirtualna instaluje klaster Avere vFXT i pobiera skrypt uruchamiania z klastra. Aby uzyskać szczegółowe informacje, przeczytaj bootstrap maszynę wirtualną ingestor danych.
Planowanie strategiczne
Podczas projektowania strategii kopiowania danych równolegle należy zrozumieć kompromisy dotyczące rozmiaru pliku, liczby plików i głębokości katalogu.
- Gdy pliki są małe, metryka zainteresowania to pliki na sekundę.
- Gdy pliki są duże (10MiBi lub większe), metryka zainteresowania jest bajtami na sekundę.
Każdy proces kopiowania ma szybkość przepływności i szybkość transferu plików, która może być mierzona według czasu długości polecenia kopiowania i uwzględniania rozmiaru pliku i liczby plików. Wyjaśnienie sposobu mierzenia stawek wykracza poza zakres tego dokumentu, ale ważne jest, aby zrozumieć, czy będziesz radzić sobie z małymi lub dużymi plikami.
Przykład ręcznego kopiowania
Możesz ręcznie utworzyć kopię wielowątkową na kliencie, uruchamiając jednocześnie więcej niż jedno polecenie kopiowania w tle względem wstępnie zdefiniowanych zestawów plików lub ścieżek.
Polecenie Linux/system UNIX cp zawiera argument -p umożliwiający zachowanie własności i metadanych mtime. Dodanie tego argumentu do poniższych poleceń jest opcjonalne. (Dodanie argumentu zwiększa liczbę wywołań systemu plików wysyłanych z klienta do docelowego systemu plików w celu modyfikacji metadanych).
Ten prosty przykład kopiuje dwa pliki równolegle:
cp /mnt/source/file1 /mnt/destination1/ & cp /mnt/source/file2 /mnt/destination1/ &
Po wydaniu jobs tego polecenia polecenie pokaże, że dwa wątki są uruchomione.
Przewidywalna struktura nazwy pliku
Jeśli nazwy plików są przewidywalne, możesz użyć wyrażeń do tworzenia równoległych wątków kopiowania.
Jeśli na przykład katalog zawiera 1000 plików, które są numerowane sekwencyjnie z 0001 do 1000, możesz użyć następujących wyrażeń, aby utworzyć dziesięć równoległych wątków, które każdy kopiuje 100 plików:
cp /mnt/source/file0* /mnt/destination1/ & \
cp /mnt/source/file1* /mnt/destination1/ & \
cp /mnt/source/file2* /mnt/destination1/ & \
cp /mnt/source/file3* /mnt/destination1/ & \
cp /mnt/source/file4* /mnt/destination1/ & \
cp /mnt/source/file5* /mnt/destination1/ & \
cp /mnt/source/file6* /mnt/destination1/ & \
cp /mnt/source/file7* /mnt/destination1/ & \
cp /mnt/source/file8* /mnt/destination1/ & \
cp /mnt/source/file9* /mnt/destination1/
Nieznana struktura nazwy pliku
Jeśli struktura nazewnictwa plików nie jest przewidywalna, możesz grupować pliki według nazw katalogów.
W tym przykładzie zbierane są całe katalogi do wysyłania do cp poleceń uruchamianych jako zadania w tle:
/root
|-/dir1
| |-/dir1a
| |-/dir1b
| |-/dir1c
|-/dir1c1
|-/dir1d
Po zebraniu plików można uruchamiać równoległe polecenia kopiowania, aby rekursywnie kopiować podkatalogi i całą ich zawartość:
cp /mnt/source/* /mnt/destination/
mkdir -p /mnt/destination/dir1 && cp /mnt/source/dir1/* mnt/destination/dir1/ &
cp -R /mnt/source/dir1/dir1a /mnt/destination/dir1/ &
cp -R /mnt/source/dir1/dir1b /mnt/destination/dir1/ &
cp -R /mnt/source/dir1/dir1c /mnt/destination/dir1/ & # this command copies dir1c1 via recursion
cp -R /mnt/source/dir1/dir1d /mnt/destination/dir1/ &
Kiedy dodać punkty instalacji
Po dokonaniu wystarczającej liczby równoległych wątków przechodzących do pojedynczego docelowego punktu instalacji systemu plików będzie istnieć punkt, w którym dodanie większej liczby wątków nie zapewnia większej przepływności. (Przepływność będzie mierzona w plikach/sekundach lub bajtach/sekundach w zależności od typu danych). Co gorsza, nadmierne wątkowanie może czasami spowodować obniżenie przepływności.
W takim przypadku można dodać punkty instalacji po stronie klienta do innych adresów IP klastra vFXT przy użyciu tej samej ścieżki instalacji zdalnego systemu plików:
10.1.0.100:/nfs on /mnt/sourcetype nfs (rw,vers=3,proto=tcp,addr=10.1.0.100)
10.1.1.101:/nfs on /mnt/destination1type nfs (rw,vers=3,proto=tcp,addr=10.1.1.101)
10.1.1.102:/nfs on /mnt/destination2type nfs (rw,vers=3,proto=tcp,addr=10.1.1.102)
10.1.1.103:/nfs on /mnt/destination3type nfs (rw,vers=3,proto=tcp,addr=10.1.1.103)
Dodanie punktów instalacji po stronie klienta umożliwia rozwidlenie dodatkowych poleceń kopiowania do dodatkowych /mnt/destination[1-3] punktów instalacji, co zapewnia dalszy równoległość.
Jeśli na przykład pliki są bardzo duże, możesz zdefiniować polecenia kopiowania, aby używać odrębnych ścieżek docelowych, wysyłając równolegle więcej poleceń od klienta wykonującego kopię.
cp /mnt/source/file0* /mnt/destination1/ & \
cp /mnt/source/file1* /mnt/destination2/ & \
cp /mnt/source/file2* /mnt/destination3/ & \
cp /mnt/source/file3* /mnt/destination1/ & \
cp /mnt/source/file4* /mnt/destination2/ & \
cp /mnt/source/file5* /mnt/destination3/ & \
cp /mnt/source/file6* /mnt/destination1/ & \
cp /mnt/source/file7* /mnt/destination2/ & \
cp /mnt/source/file8* /mnt/destination3/ & \
W powyższym przykładzie wszystkie trzy punkty instalacji docelowej są objęte procesami kopiowania plików klienta.
Kiedy dodać klientów
Na koniec po osiągnięciu możliwości klienta dodanie kolejnych wątków kopiowania lub dodatkowych punktów instalacji nie spowoduje zwiększenia liczby dodatkowych plików/s lub bajtów na sekundę. W takiej sytuacji można wdrożyć innego klienta z tym samym zestawem punktów instalacji, które będą uruchamiać własne zestawy procesów kopiowania plików.
Przykład:
Client1: cp -R /mnt/source/dir1/dir1a /mnt/destination/dir1/ &
Client1: cp -R /mnt/source/dir2/dir2a /mnt/destination/dir2/ &
Client1: cp -R /mnt/source/dir3/dir3a /mnt/destination/dir3/ &
Client2: cp -R /mnt/source/dir1/dir1b /mnt/destination/dir1/ &
Client2: cp -R /mnt/source/dir2/dir2b /mnt/destination/dir2/ &
Client2: cp -R /mnt/source/dir3/dir3b /mnt/destination/dir3/ &
Client3: cp -R /mnt/source/dir1/dir1c /mnt/destination/dir1/ &
Client3: cp -R /mnt/source/dir2/dir2c /mnt/destination/dir2/ &
Client3: cp -R /mnt/source/dir3/dir3c /mnt/destination/dir3/ &
Client4: cp -R /mnt/source/dir1/dir1d /mnt/destination/dir1/ &
Client4: cp -R /mnt/source/dir2/dir2d /mnt/destination/dir2/ &
Client4: cp -R /mnt/source/dir3/dir3d /mnt/destination/dir3/ &
Tworzenie manifestów plików
Po zrozumieniu powyższych podejść (wiele wątków kopiowania na miejsce docelowe, wiele miejsc docelowych na klienta, wielu klientów na system plików źródłowych dostępnych dla sieci), rozważ następujące zalecenie: Kompiluj manifesty plików, a następnie użyj ich z poleceniami kopiowania w wielu klientach.
W tym scenariuszu użyto polecenia system UNIX find w celu utworzenia manifestów plików lub katalogów:
user@build:/mnt/source > find . -mindepth 4 -maxdepth 4 -type d
./atj5b55c53be6-01/support/gsi/2018-07-22T21:12:06EDT
./atj5b55c53be6-01/support/pcap/2018-07-23T01:34:57UTC
./atj5b55c53be6-01/support/trace/rolling
./atj5b55c53be6-03/support/gsi/2018-07-22T21:12:06EDT
./atj5b55c53be6-03/support/pcap/2018-07-23T01:34:57UTC
./atj5b55c53be6-03/support/trace/rolling
./atj5b55c53be6-02/support/gsi/2018-07-22T21:12:06EDT
./atj5b55c53be6-02/support/pcap/2018-07-23T01:34:57UTC
./atj5b55c53be6-02/support/trace/rolling
Przekieruj ten wynik do pliku: find . -mindepth 4 -maxdepth 4 -type d > /tmp/foo
Następnie można iterować za pośrednictwem manifestu, używając poleceń BASH do zliczenia plików i określenia rozmiarów podkatalogów:
ben@xlcycl1:/sps/internal/atj5b5ab44b7f > for i in $(cat /tmp/foo); do echo " `find ${i} |wc -l` `du -sh ${i}`"; done
244 3.5M ./atj5b5ab44b7f-02/support/gsi/2018-07-18T00:07:03EDT
9 172K ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-18T05:01:00UTC
124 5.8M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-19T01:01:01UTC
152 15M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-20T01:01:00UTC
131 13M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-20T21:59:41UTC_partial
789 6.2M ./atj5b5ab44b7f-02/support/gsi/2018-07-20T21:59:41UTC
134 12M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-20T22:22:55UTC_vfxt_catchup
7 16K ./atj5b5ab44b7f-02/support/pcap/2018-07-18T17:12:19UTC
8 83K ./atj5b5ab44b7f-02/support/pcap/2018-07-18T17:17:17UTC
575 7.7M ./atj5b5ab44b7f-02/support/cores/armada_main.2000.1531980253.gsi
33 4.4G ./atj5b5ab44b7f-02/support/trace/rolling
281 6.6M ./atj5b5ab44b7f-01/support/gsi/2018-07-18T00:07:03EDT
15 182K ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-18T05:01:00UTC
244 17M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-19T01:01:01UTC
299 31M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-20T01:01:00UTC
256 29M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-20T21:59:41UTC_partial
889 7.7M ./atj5b5ab44b7f-01/support/gsi/2018-07-20T21:59:41UTC
262 29M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-20T22:22:55UTC_vfxt_catchup
11 248K ./atj5b5ab44b7f-01/support/pcap/2018-07-18T17:12:19UTC
11 88K ./atj5b5ab44b7f-01/support/pcap/2018-07-18T17:17:17UTC
645 11M ./atj5b5ab44b7f-01/support/cores/armada_main.2019.1531980253.gsi
33 4.0G ./atj5b5ab44b7f-01/support/trace/rolling
244 2.1M ./atj5b5ab44b7f-03/support/gsi/2018-07-18T00:07:03EDT
9 158K ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-18T05:01:00UTC
124 5.3M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-19T01:01:01UTC
152 15M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-20T01:01:00UTC
131 12M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-20T21:59:41UTC_partial
789 8.4M ./atj5b5ab44b7f-03/support/gsi/2018-07-20T21:59:41UTC
134 14M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-20T22:25:58UTC_vfxt_catchup
7 159K ./atj5b5ab44b7f-03/support/pcap/2018-07-18T17:12:19UTC
7 157K ./atj5b5ab44b7f-03/support/pcap/2018-07-18T17:17:17UTC
576 12M ./atj5b5ab44b7f-03/support/cores/armada_main.2013.1531980253.gsi
33 2.8G ./atj5b5ab44b7f-03/support/trace/rolling
Na koniec należy utworzyć rzeczywiste polecenia kopiowania plików do klientów.
Jeśli masz czterech klientów, użyj następującego polecenia:
for i in 1 2 3 4 ; do sed -n ${i}~4p /tmp/foo > /tmp/client${i}; done
Jeśli masz pięciu klientów, użyj czegoś podobnego do następującego:
for i in 1 2 3 4 5; do sed -n ${i}~5p /tmp/foo > /tmp/client${i}; done
I na sześć.... Ekstrapoluj zgodnie z potrzebami.
for i in 1 2 3 4 5 6; do sed -n ${i}~6p /tmp/foo > /tmp/client${i}; done
Otrzymasz N plików wynikowych, po jednym dla każdego klienta N, który ma nazwy ścieżek do poziomów czterech katalogów uzyskanych w ramach danych wyjściowych polecenia find .
Użyj każdego pliku, aby skompilować polecenie kopiowania:
for i in 1 2 3 4 5 6; do for j in $(cat /tmp/client${i}); do echo "cp -p -R /mnt/source/${j} /mnt/destination/${j}" >> /tmp/client${i}_copy_commands ; done; done
Powyższe polecenie da N plików, z których każdy ma polecenie kopiowania w każdym wierszu, które można uruchomić jako skrypt powłoki BASH na kliencie.
Celem jest jednoczesne uruchamianie wielu wątków tych skryptów na klienta równolegle na wielu klientach.
Korzystanie z dwufazowego procesu rsync
Standardowe rsync narzędzie nie działa dobrze w przypadku wypełniania magazynu w chmurze za pośrednictwem systemu Avere vFXT for Azure, ponieważ generuje dużą liczbę operacji tworzenia i zmieniania nazw plików w celu zagwarantowania integralności danych. Można jednak bezpiecznie użyć --inplace opcji z rsync , aby pominąć bardziej staranną procedurę kopiowania, jeśli wykonasz to z drugim uruchomieniem sprawdzającym integralność pliku.
Standardowa rsync operacja kopiowania tworzy plik tymczasowy i wypełnia go danymi. Jeśli transfer danych zakończy się pomyślnie, nazwa pliku tymczasowego zostanie zmieniona na oryginalną nazwę pliku. Ta metoda gwarantuje spójność, nawet jeśli pliki są dostępne podczas kopiowania. Jednak ta metoda generuje więcej operacji zapisu, co spowalnia przenoszenie plików przez pamięć podręczną.
Opcja --inplace zapisuje nowy plik bezpośrednio w lokalizacji końcowej. Pliki nie mają gwarancji spójności podczas transferu, ale nie jest to ważne, jeśli korzystasz z systemu magazynu do późniejszego użycia.
Druga rsync operacja służy jako kontrola spójności dla pierwszej operacji. Ponieważ pliki zostały już skopiowane, druga faza to szybkie skanowanie, aby upewnić się, że pliki w miejscu docelowym są zgodne z plikami w źródle. Jeśli jakiekolwiek pliki nie są zgodne, zostaną one skopiowane ponownie.
Obie fazy można wydać razem w jednym poleceniu:
rsync -azh --inplace <source> <destination> && rsync -azh <source> <destination>
Ta metoda jest prostą i efektywną czasowo metodą zestawów danych do liczby plików, które może obsłużyć wewnętrzny menedżer katalogów. (Zazwyczaj jest to 200 milionów plików dla klastra 3-węzłowego, 500 milionów plików dla klastra z sześciowęźle itd.)
Korzystanie z narzędzia msrsync
Narzędzie msrsync może również służyć do przenoszenia danych do podstawowego programu plików zaplecza dla klastra Avere. To narzędzie zostało zaprojektowane pod kątem optymalizacji użycia przepustowości przez uruchamianie wielu procesów równoległych rsync . Jest ona dostępna w witrynie GitHub pod adresem https://github.com/jbd/msrsync.
msrsync Dzieli katalog źródłowy na oddzielne "zasobniki", a następnie uruchamia poszczególne rsync procesy w każdym zasobniku.
Wstępne testowanie przy użyciu czterordzeniowej maszyny wirtualnej wykazało najlepszą wydajność podczas korzystania z 64 procesów. msrsync Użyj opcji -p , aby ustawić liczbę procesów na 64.
Możesz również użyć argumentu --inplace z msrsync poleceniami. Jeśli używasz tej opcji, rozważ uruchomienie drugiego polecenia (podobnie jak w przypadku narzędzia rsync, opisanego powyżej), aby zapewnić integralność danych.
msrsync może zapisywać tylko do i z woluminów lokalnych. Źródło i miejsce docelowe muszą być dostępne jako lokalne instalacji w sieci wirtualnej klastra.
msrsync Aby wypełnić wolumin w chmurze platformy Azure klastrem Avere, wykonaj następujące instrukcje:
Instalowanie
msrsynci jego wymagania wstępne (rsync i Python 2.6 lub nowszy)Określ całkowitą liczbę plików i katalogów do skopiowania.
Na przykład użyj narzędzia
prime.pyAvere z argumentamiprime.py --directory /path/to/some/directory(dostępnymi przez pobranie adresu URL https://github.com/Azure/Avere/blob/master/src/clientapps/dataingestor/prime.py).Jeśli nie używasz metody , możesz obliczyć liczbę elementów za pomocą
prime.pynarzędzia GNUfindw następujący sposób:find <path> -type f |wc -l # (counts files) find <path> -type d |wc -l # (counts directories) find <path> |wc -l # (counts both)Podziel liczbę elementów na 64, aby określić liczbę elementów na proces. Użyj tej liczby z opcją
-f, aby ustawić rozmiar zasobników podczas uruchamiania polecenia.Wydaj polecenie ,
msrsyncaby skopiować pliki:msrsync -P --stats -p 64 -f <ITEMS_DIV_64> --rsync "-ahv" <SOURCE_PATH> <DESTINATION_PATH>Jeśli używasz
--inplacepolecenia , dodaj drugie wykonanie bez opcji, aby sprawdzić, czy dane są poprawnie skopiowane:msrsync -P --stats -p 64 -f <ITEMS_DIV_64> --rsync "-ahv --inplace" <SOURCE_PATH> <DESTINATION_PATH> && msrsync -P --stats -p 64 -f <ITEMS_DIV_64> --rsync "-ahv" <SOURCE_PATH> <DESTINATION_PATH>Na przykład to polecenie jest przeznaczone do przenoszenia 11 000 plików w 64 procesach z /test/source-repository do /mnt/vfxt/repository:
msrsync -P --stats -p 64 -f 170 --rsync "-ahv --inplace" /test/source-repository/ /mnt/vfxt/repository && msrsync -P --stats -p 64 -f 170 --rsync "-ahv --inplace" /test/source-repository/ /mnt/vfxt/repository
Używanie skryptu kopiowania równoległego
Skrypt parallelcp może być również przydatny do przenoszenia danych do magazynu zaplecza klastra vFXT.
Poniższy skrypt doda plik wykonywalny parallelcp. (Ten skrypt jest przeznaczony dla systemu Ubuntu; w przypadku korzystania z innej dystrybucji należy zainstalować parallel oddzielnie).
sudo touch /usr/bin/parallelcp && sudo chmod 755 /usr/bin/parallelcp && sudo sh -c "/bin/cat >/usr/bin/parallelcp" <<EOM
#!/bin/bash
display_usage() {
echo -e "\nUsage: \$0 SOURCE_DIR DEST_DIR\n"
}
if [ \$# -le 1 ] ; then
display_usage
exit 1
fi
if [[ ( \$# == "--help") || \$# == "-h" ]] ; then
display_usage
exit 0
fi
SOURCE_DIR="\$1"
DEST_DIR="\$2"
if [ ! -d "\$SOURCE_DIR" ] ; then
echo "Source directory \$SOURCE_DIR does not exist, or is not a directory"
display_usage
exit 2
fi
if [ ! -d "\$DEST_DIR" ] && ! mkdir -p \$DEST_DIR ; then
echo "Destination directory \$DEST_DIR does not exist, or is not a directory"
display_usage
exit 2
fi
if [ ! -w "\$DEST_DIR" ] ; then
echo "Destination directory \$DEST_DIR is not writeable, or is not a directory"
display_usage
exit 3
fi
if ! which parallel > /dev/null ; then
sudo apt-get update && sudo apt install -y parallel
fi
DIRJOBS=225
JOBS=225
find \$SOURCE_DIR -mindepth 1 -type d -print0 | sed -z "s/\$SOURCE_DIR\///" | parallel --will-cite -j\$DIRJOBS -0 "mkdir -p \$DEST_DIR/{}"
find \$SOURCE_DIR -mindepth 1 ! -type d -print0 | sed -z "s/\$SOURCE_DIR\///" | parallel --will-cite -j\$JOBS -0 "cp -P \$SOURCE_DIR/{} \$DEST_DIR/{}"
EOM
Przykład kopiowania równoległego
W tym przykładzie użyto równoległego skryptu kopiowania do skompilowania glibc przy użyciu plików źródłowych z klastra Avere.
Pliki źródłowe są przechowywane w punkcie instalacji klastra Avere, a pliki obiektów są przechowywane na lokalnym dysku twardym.
Ten skrypt używa powyższego skryptu kopiowania równoległego. -j Opcja jest używana z elementami parallelcp i make w celu uzyskania równoległego przetwarzania.
sudo apt-get update
sudo apt install -y gcc bison gcc binutils make parallel
cd
wget https://mirrors.kernel.org/gnu/libc/glibc-2.27.tar.bz2
tar jxf glibc-2.27.tar.bz2
ln -s /nfs/node1 avere
time parallelcp glibc-2.27 avere/glibc-2.27
cd
mkdir obj
mkdir usr
cd obj
/home/azureuser/avere/glibc-2.27/configure --prefix=/home/azureuser/usr
time make -j