Przetwarzanie języka naturalnego (NLP) ma wiele aplikacji, takich jak analiza tonacji, wykrywanie tematów, wykrywanie języka, wyodrębnianie kluczowych fraz i kategoryzacja dokumentów.
W szczególności możesz użyć nlp do:
- Klasyfikowanie dokumentów, na przykład oznaczanie ich jako poufnych lub niepożądanych.
- Przeprowadź kolejne przetwarzanie lub wyszukiwanie przy użyciu danych wyjściowych nlp.
- Podsumuj tekst, identyfikując jednostki w dokumencie.
- Oznaczanie dokumentów słowami kluczowymi przy użyciu zidentyfikowanych jednostek.
- Przeprowadź wyszukiwanie oparte na zawartości i pobieranie za pomocą tagowania.
- Podsumowanie kluczowych tematów dokumentu przy użyciu zidentyfikowanych jednostek.
- Kategoryzuj dokumenty na potrzeby nawigacji przy użyciu wykrytych tematów.
- Wyliczanie powiązanych dokumentów na podstawie wybranego tematu.
- Ocena tonacji tekstu w celu zrozumienia pozytywnego lub negatywnego tonu.
Dzięki postępom w technologii nlp można nie tylko kategoryzować i analizować dane tekstowe, ale także zwiększyć czytelne funkcje sztucznej inteligencji w różnych domenach. Integracja dużych modeli językowych (LLM) znacznie zwiększa możliwości nlp. Maszyny LLM, takie jak GPT i, mogą generować tekst przypominający kontekstowo, co czyni je wysoce skutecznymi w przypadku złożonych zadań przetwarzania języka. Uzupełniają one istniejące techniki NLP dzięki obsłudze szerszych zadań poznawczych, które poprawiają systemy konwersacji i zaangażowanie klientów, szczególnie w przypadku modeli takich jak Dolly 2.0 usługi Databricks.
Relacje i różnice między modelami językowymi i nlp
NLP to kompleksowe pole obejmujące różne techniki przetwarzania języka ludzkiego. Natomiast modele językowe są określonym podzbiorem w ramach nlp, koncentrując się na uczeniu głębokim w celu wykonywania zadań językowych wysokiego poziomu. Chociaż modele językowe rozszerzają nlp, zapewniając zaawansowane generowanie tekstu i możliwości interpretacji, nie są one synonimem NLP. Zamiast tego służą one jako zaawansowane narzędzia w szerszej domenie NLP, co umożliwia bardziej zaawansowane przetwarzanie języka.
Nuta
Ten artykuł koncentruje się na nlp. Relacja między nlp i modelami językowymi pokazuje, że modele językowe zwiększają procesy NLP poprzez lepsze zrozumienie języka i możliwości generowania.
Apache®, Apache Spark i logo płomienia są zastrzeżonymi znakami towarowymi lub znakami towarowymi fundacji Apache Software Foundation w Stany Zjednoczone i/lub innych krajach. Użycie tych znaków nie jest dorozumiane przez fundację Apache Software Foundation.
Potencjalne przypadki użycia
Scenariusze biznesowe, które mogą korzystać z niestandardowej równoważenia obciążenia sieciowego, obejmują:
- Analiza dokumentów dla dokumentów napisanych odręcznie lub utworzonych maszynowo w sektorze finansów, opieki zdrowotnej, handlu detalicznego, instytucji rządowych i innych sektorów.
- Niezależne od branży zadania NLP do przetwarzania tekstu, takie jak rozpoznawanie jednostek nazw (NER), klasyfikacja, podsumowanie i wyodrębnianie relacji. Te zadania automatyzują proces pobierania, identyfikowania i analizowania informacji o dokumencie, takich jak tekst i dane bez struktury. Przykłady tych zadań obejmują modele stratification ryzyka, klasyfikację ontologii i podsumowania sprzedaży detalicznej.
- Pobieranie informacji i tworzenie grafu wiedzy na potrzeby wyszukiwania semantycznego. Ta funkcja umożliwia tworzenie grafów wiedzy medycznej, które obsługują odnajdywanie leków i badania kliniczne.
- Tłumaczenie tekstu dla konwersacyjnych systemów sztucznej inteligencji w aplikacjach przeznaczonych dla klientów w branży handlu detalicznego, finansów, podróży i innych branż.
- Tonacja i ulepszona inteligencja emocjonalna w analizie, szczególnie w przypadku monitorowania percepcji marki i analizy opinii klientów.
- Automatyczne generowanie raportów. Syntetyzowanie i generowanie kompleksowych raportów tekstowych na podstawie strukturalnych danych wejściowych, pomocnych sektorów, takich jak finanse i zgodność, w przypadku gdy wymagana jest szczegółowa dokumentacja.
- Interfejsy aktywowane głosowo w celu ulepszenia interakcji użytkownika w aplikacjach IoT i inteligentnych urządzeń dzięki integracji nlp na potrzeby rozpoznawania głosu i naturalnych możliwości konwersacji.
- Dostosowywanie modeli językowych w celu dynamicznego dostosowywania danych wyjściowych języka do różnych poziomów zrozumienia odbiorców, co ma kluczowe znaczenie dla treści edukacyjnych i ulepszeń ułatwień dostępu.
- Analiza tekstu cyberbezpieczeństwa w celu analizowania wzorców komunikacyjnych i użycia języka w czasie rzeczywistym w celu zidentyfikowania potencjalnych zagrożeń bezpieczeństwa w komunikacji cyfrowej, poprawy wykrywania prób wyłudzania informacji lub dezinformacji.
Platforma Apache Spark jako niestandardowa struktura NLP
Apache Spark to zaawansowana platforma przetwarzania równoległego, która zwiększa wydajność aplikacji analitycznych big data dzięki przetwarzaniu w pamięci. Azure Synapse Analytics, azure HDInsighti azure Databricks nadal zapewniają niezawodny dostęp do możliwości przetwarzania platformy Spark, zapewniając bezproblemowe wykonywanie operacji danych na dużą skalę.
W przypadku dostosowanych obciążeń NLP platforma Spark NLP pozostaje wydajną strukturą umożliwiającą przetwarzanie ogromnych ilości tekstu. Ta biblioteka typu open source udostępnia rozbudowane funkcje za pośrednictwem bibliotek Python, Java i Scala, które zapewniają wyrafinowanie znalezione w wybitnych bibliotekach NLP, takich jak spaCy i NLTK. Usługa Spark NLP obejmuje zaawansowane funkcje, takie jak sprawdzanie pisowni, analiza tonacji i klasyfikacja dokumentów, spójnie zapewniając najnowocześniejsze dokładność i skalowalność.
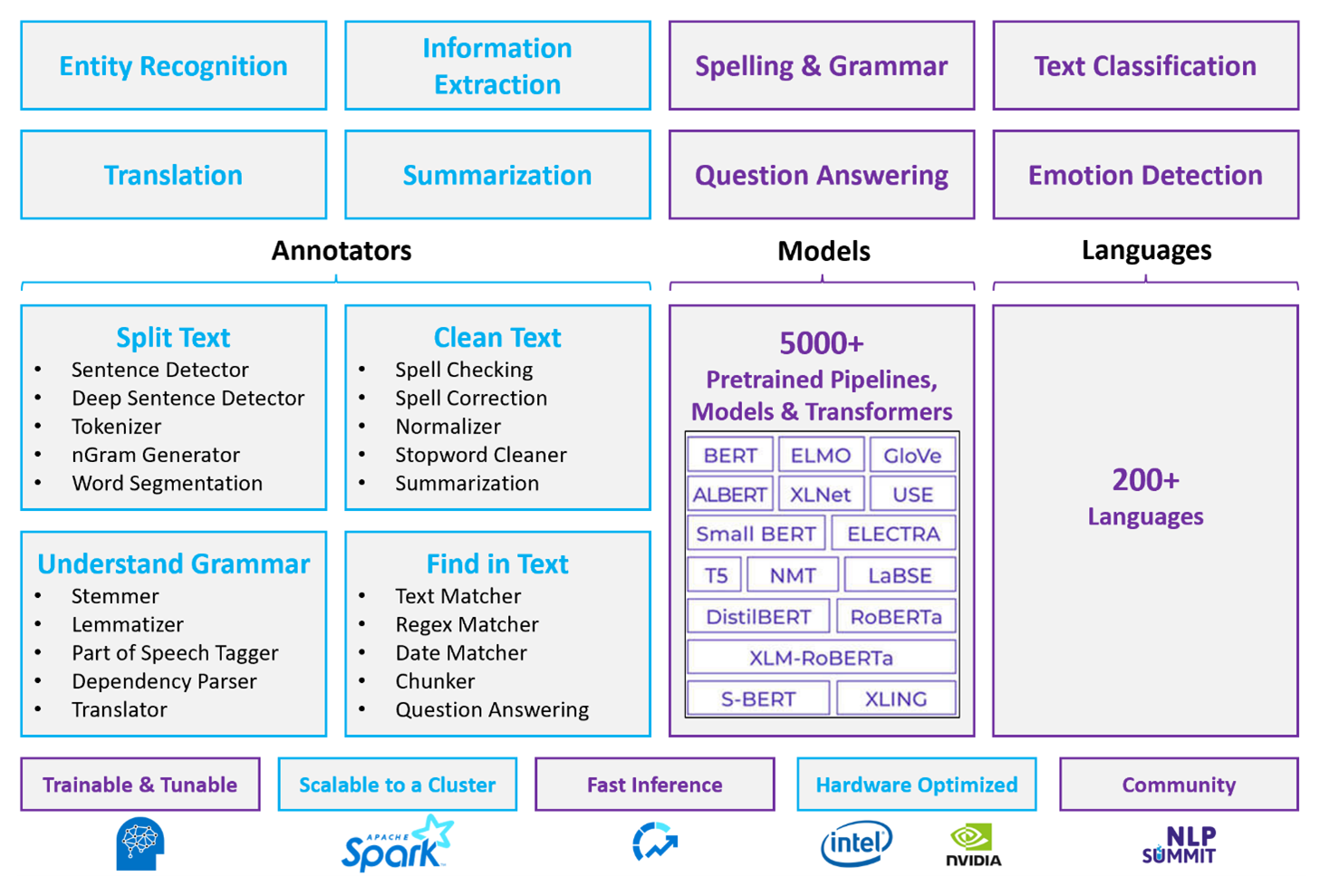
Ostatnie publiczne testy porównawcze podkreślają wydajność usługi Spark NLP, pokazując znaczne ulepszenia szybkości w innych bibliotekach przy zachowaniu porównywalnej dokładności trenowania modeli niestandardowych. W szczególności integracja modeli Llama-2 i OpenAI Whisper zwiększa interfejsy konwersacyjne i wielojęzyczne rozpoznawanie mowy, co oznacza znaczące postępy w zoptymalizowanych możliwościach przetwarzania.
W unikatowy sposób usługa Spark NLP efektywnie wykorzystuje rozproszony klaster Spark, działający jako natywne rozszerzenie spark ML, które działa bezpośrednio w ramkach danych. Ta integracja obsługuje zwiększone wzrosty wydajności w klastrach, ułatwiając tworzenie ujednoliconych potoków NLP i uczenia maszynowego dla zadań, takich jak klasyfikacja dokumentów i przewidywanie ryzyka. Wprowadzenie osadzeń MPNet i rozbudowane funkcje ONNX dodatkowo wzbogacają te możliwości, co pozwala na precyzyjne i kontekstowe przetwarzanie.
Poza zaletami wydajności platforma Spark NLP zapewnia najnowocześniejsze dokładność w rozszerzającej się tablicy zadań NLP. Biblioteka zawiera wstępnie utworzone modele uczenia głębokiego do rozpoznawania jednostek nazwanych, klasyfikacji dokumentów, wykrywania tonacji i nie tylko. Jego rozbudowany projekt obejmuje wstępnie wytrenowane modele językowe obsługujące osadzanie wyrazów, fragmentów, zdań i dokumentów.
Dzięki zoptymalizowanym kompilacjom dla procesorów CPU, procesorów GPU i najnowszych układów Intel Xeon infrastruktura NLP platformy Spark została zaprojektowana pod kątem skalowalności, umożliwiając trenowanie i wnioskowanie procesów w pełni korzystających z klastrów Spark. Zapewnia to wydajną obsługę zadań NLP w różnych środowiskach i aplikacjach, utrzymując swoje stanowisko w czołówce innowacji NLP.
Wyzwania
Przetwarzanie zasobów: Przetwarzanie kolekcji dokumentów tekstowych w dowolnej formie wymaga znacznej ilości zasobów obliczeniowych, a przetwarzanie jest również czasochłonne. Tego rodzaju przetwarzanie często wiąże się z wdrożeniem obliczeń procesora GPU. Ostatnie postępy, takie jak optymalizacje w architekturach NLP platformy Spark, takich jak Llama-2, które obsługują kwantyzację, pomagają usprawnić te intensywne zadania, co zwiększa wydajność alokacji zasobów.
Problemy ze standaryzacją: bez standardowego formatu dokumentu, uzyskanie spójnych dokładnych wyników przy użyciu przetwarzania tekstu w dowolnej formie może być trudne do wyodrębnienia określonych faktów z dokumentu. Na przykład wyodrębnienie numeru faktury i daty z różnych faktur stanowi wyzwanie. Integracja dostosowanych modeli NLP, takich jak M2M100, ulepszona dokładność przetwarzania w wielu językach i formatach, ułatwiając większą spójność w wynikach.
Różnorodność i złożoność danych: Rozwiązywanie różnych struktur dokumentów i niuansów językowych pozostaje złożone. Innowacje, takie jak osadzanie MPNet, zapewniają ulepszone zrozumienie kontekstowe, oferując bardziej intuicyjną obsługę różnych formatów tekstowych i poprawę ogólnej niezawodności przetwarzania danych.
Kluczowe kryteria wyboru
Na platformie Azure usługi Spark, takie jak Azure Databricks, Microsoft Fabric i Azure HDInsight, zapewniają funkcję NLP w przypadku użycia z usługą Spark NLP. Usługi Azure AI to kolejna opcja funkcji NLP. Aby zdecydować, która usługa ma być używana, należy wziąć pod uwagę następujące pytania:
Czy chcesz używać wstępnie utworzonych lub wstępnie wytrenowanych modeli? Jeśli tak, rozważ użycie interfejsów API oferowanych przez usługi Azure AI lub pobranie wybranego modelu za pomocą usługi Spark NLP, który zawiera teraz zaawansowane modele, takie jak Llama-2 i MPNet, w celu uzyskania rozszerzonych możliwości.
Czy musisz wytrenować modele niestandardowe względem dużego korpusu danych tekstowych? Jeśli tak, rozważ użycie usługi Azure Databricks, Microsoft Fabric lub Azure HDInsight z usługą Spark NLP. Te platformy zapewniają moc obliczeniową i elastyczność wymaganą do szerokiego trenowania modelu.
Czy potrzebujesz funkcji nlp niskiego poziomu, takich jak tokenizacja, stemming, lemmatization i częstotliwość terminów/odwrotna częstotliwość dokumentu (TF/IDF)? Jeśli tak, rozważ użycie usługi Azure Databricks, Microsoft Fabric lub Azure HDInsight z usługą Spark NLP. Alternatywnie możesz użyć biblioteki oprogramowania typu open source w wybranym narzędziu przetwarzania.
Czy potrzebujesz prostych funkcji nlp wysokiego poziomu, takich jak identyfikacja jednostek i intencji, wykrywanie tematów, sprawdzanie pisowni lub analiza tonacji? Jeśli tak, rozważ użycie interfejsów API, które oferuje usługi Azure AI. Możesz też pobrać wybrany model za pomocą usługi Spark NLP, aby wykorzystać wstępnie utworzone funkcje dla tych zadań.
Macierz możliwości
W poniższych tabelach podsumowano kluczowe różnice w możliwościach usług NLP.
Ogólne możliwości
| Możliwość | Usługa Spark (Azure Databricks, Microsoft Fabric, Azure HDInsight) z usługą Spark NLP | Usługi platformy Azure AI |
|---|---|---|
| Udostępnia wstępnie wytrenowane modele jako usługę | Tak | Tak |
| Interfejs API REST | Tak | Tak |
| Możliwości programowania | Python, Scala | Aby uzyskać informacje o obsługiwanych językach, zobacz Dodatkowe zasoby |
| Obsługuje przetwarzanie zestawów danych big data i dużych dokumentów | Tak | Nie. |
Funkcje równoważenia obciążenia sieciowego niskiego poziomu
Możliwości adnotacji
| Możliwość | Usługa Spark (Azure Databricks, Microsoft Fabric, Azure HDInsight) z usługą Spark NLP | Usługi platformy Azure AI |
|---|---|---|
| Detektor zdań | Tak | Nie. |
| Wykrywacz głębokich zdań | Tak | Tak |
| Tokenizer | Tak | Tak |
| Generator N-gram | Tak | Nie. |
| Segmentacja wyrazów | Tak | Tak |
| Stemmer | Tak | Nie. |
| Lemmatizer | Tak | Nie. |
| Tagowanie części mowy | Tak | Nie. |
| Analizator zależności | Tak | Nie. |
| Tłumaczenie | Tak | Nie. |
| Czyszczenie stopwordów | Tak | Nie. |
| Korekta pisowni | Tak | Nie. |
| Normalizer | Tak | Tak |
| Dopasowywanie tekstu | Tak | Nie. |
| TF/IDF | Tak | Nie. |
| Dopasowywanie wyrażeń regularnych | Tak | Osadzone w usłudze Conversational Language Understanding (CLU) |
| Dopasowywanie dat | Tak | Możliwe w clu za pomocą funkcji rozpoznawania daty/godziny |
| Fragmentator | Tak | Nie. |
Nuta
Usługa Microsoft Language Understanding (LUIS) zostanie wycofana 1 października 2025 r. Zachęcamy istniejące aplikacje usługi LUIS do migrowania do usługi Conversational Language Understanding (CLU), możliwości usług Azure AI Services for Language, co zwiększa możliwości interpretacji języka i oferuje nowe funkcje.
Ogólne możliwości równoważenia obciążenia sieciowego
| Możliwość | Usługa Spark (Azure Databricks, Microsoft Fabric, Azure HDInsight) z usługą Spark NLP | Usługi platformy Azure AI |
|---|---|---|
| Sprawdzanie pisowni | Tak | Nie. |
| Podsumowanie | Tak | Tak |
| Odpowiadanie na pytania | Tak | Tak |
| Wykrywanie tonacji | Tak | Tak |
| Wykrywanie emocji | Tak | Wspiera górnictwo opinii |
| klasyfikacja tokenów | Tak | Tak, za pośrednictwem modeli niestandardowych |
| Klasyfikacja tekstu | Tak | Tak, za pośrednictwem modeli niestandardowych |
| Reprezentacja tekstu | Tak | Nie. |
| NER | Tak | Tak — analiza tekstu udostępnia zestaw jednostek NER, a modele niestandardowe są w funkcji rozpoznawania jednostek |
| Rozpoznawanie jednostek | Tak | Tak, za pośrednictwem modeli niestandardowych |
| Wykrywanie języka | Tak | Tak |
| Obsługuje języki poza językiem angielskim | Tak, obsługuje ponad 200 języków | Tak, obsługuje ponad 97 języków |
Konfigurowanie usługi Spark NLP na platformie Azure
Aby zainstalować usługę Spark NLP, użyj następującego kodu, ale zastąp <version> ciąg najnowszym numerem wersji. Aby uzyskać więcej informacji, zobacz dokumentację usługi Spark NLP.
# Install Spark NLP from PyPI.
pip install spark-nlp==<version>
# Install Spark NLP from Anacodna or Conda.
conda install -c johnsnowlabs spark-nlp
# Load Spark NLP with Spark Shell.
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP with PySpark.
pyspark --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP with Spark Submit.
spark-submit --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP as an external JAR after compiling and building Spark NLP by using sbt assembly.
spark-shell --jars spark-nlp-assembly-3 <version>.jar
Opracowywanie potoków nlp
W przypadku kolejności wykonywania potoku NLP platforma Spark NLP jest zgodna z tą samą koncepcją programowania co tradycyjne modele uczenia maszynowego spark ML, stosując wyspecjalizowane techniki NLP.
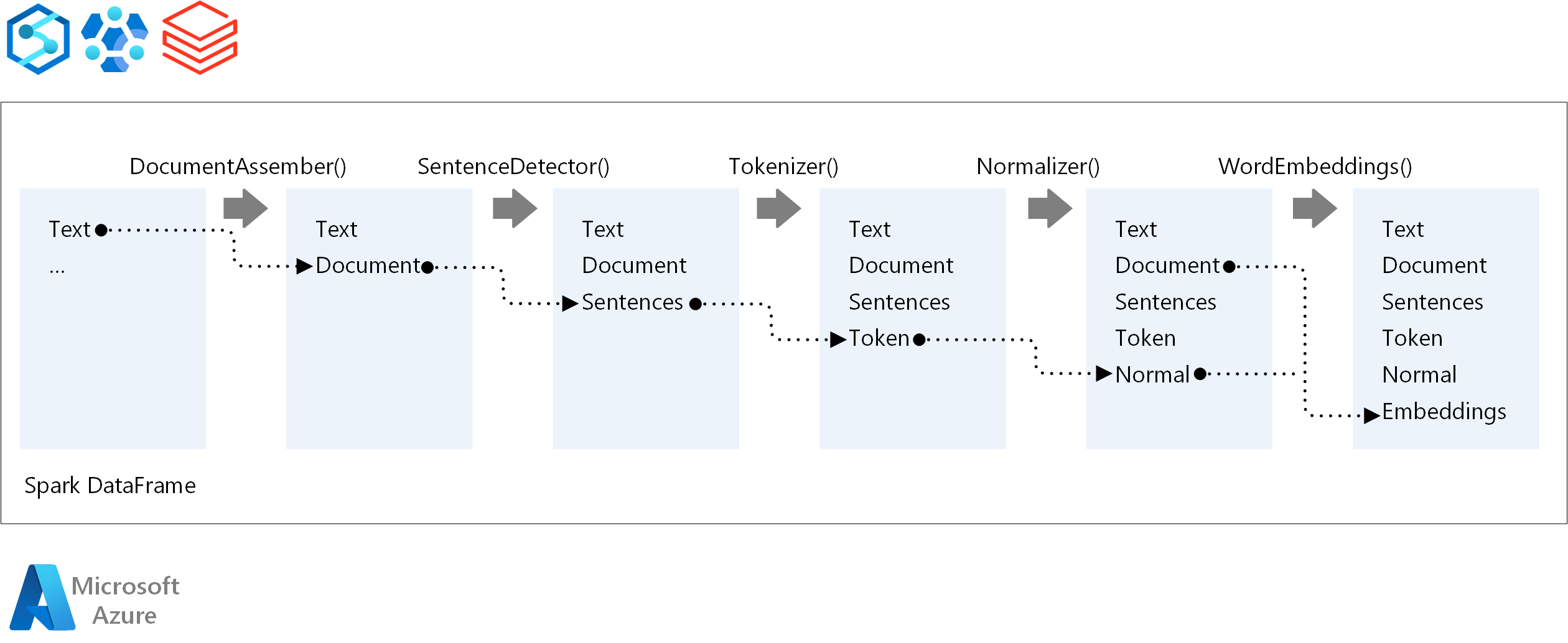
Podstawowe składniki potoku równoważenia obciążenia sieciowego platformy Spark to:
documentAssembler: transformator, który przygotowuje dane, konwertując je na format, który może przetworzyć nlp platformy Spark. Ten etap jest punktem wejścia dla każdego potoku nlp platformy Spark. Usługa DocumentAssembler odczytuje kolumnę
StringlubArray[String]z opcjami wstępnego przetwarzania tekstu przy użyciusetCleanupMode, która jest domyślnie wyłączona.SentenceDetector: adnotacja identyfikująca granice zdań przy użyciu wstępnie zdefiniowanych metod. Może zwrócić każde wykryte zdanie w
Arraylub w osobnych wierszach, gdyexplodeSentencesjest ustawiona na true.Tokenizer: adnotacja dzieląca nieprzetworzone tekst na tokeny dyskretne — wyrazy, liczby i symbole — wyprowadzając je jako
TokenizedSentence. Tokenizer jest niezgodny i używa konfiguracji danych wejściowych wRuleFactorydo tworzenia reguł tokenizowania. Reguły niestandardowe można dodawać, gdy wartości domyślne są niewystarczające.Normalizer: Annotator z zadaniem uściśliania tokenów. Normalizer stosuje wyrażenia regularne i przekształcenia słownika w celu czyszczenia tekstu i usuwania dodatkowych znaków.
WordEmbeddings: adnotacje odnośników mapujące tokeny na wektory, ułatwiając przetwarzanie semantyczne. Niestandardowy słownik osadzania można określić przy użyciu
setStoragePath, gdzie każdy wiersz zawiera token i jego wektor oddzielony spacjami. Nierozwiązane tokeny są domyślne do zera wektorów.
Równoważenie obciążenia sieciowego platformy Spark korzysta z potoków Biblioteki MLlib platformy Spark z natywną obsługą platformy MLflow, platformy typu open source, która zarządza cyklem życia uczenia maszynowego. Kluczowe składniki platformy MLflow obejmują:
śledzenia MLflow: rejestruje przebiegi eksperymentalne i zapewnia niezawodne możliwości wykonywania zapytań na potrzeby analizowania wyników.
MLflow Projects: umożliwia wykonywanie kodu nauki o danych na różnych platformach, zwiększając przenośność i powtarzalność.
modeli MLflow: obsługuje uniwersalne wdrażanie modeli w różnych środowiskach za pomocą spójnej struktury.
Model Registry: zapewnia kompleksowe zarządzanie modelami, przechowywanie wersji centralnie w celu usprawnienia dostępu i wdrażania, ułatwiając gotowość produkcyjną.
Rozwiązanie MLflow jest zintegrowane z platformami, takimi jak Azure Databricks, ale można je również zainstalować w innych środowiskach opartych na platformie Spark w celu zarządzania eksperymentami i śledzenia ich. Ta integracja umożliwia korzystanie z rejestru modeli MLflow do udostępniania modeli w celach produkcyjnych, a tym samym usprawnianie procesu wdrażania i utrzymywanie ładu modelu.
Korzystając z platformy MLflow obok platformy Spark NLP, można zapewnić efektywne zarządzanie potokami NLP i wdrażanie ich, uwzględniając nowoczesne wymagania dotyczące skalowalności i integracji, jednocześnie obsługując zaawansowane techniki, takie jak osadzanie słów i adaptacje dużych modeli językowych.
Współautorzy
Ten artykuł jest obsługiwany przez firmę Microsoft. Pierwotnie został napisany przez następujących współautorów.
Autorzy zabezpieczeń:
- Freddy Ayala | Architekt rozwiązań w chmurze
- Moritz Steller | Starszy architekt rozwiązań w chmurze
Następne kroki
Dokumentacja nlp platformy Spark:
- Równoważenie obciążenia sieciowego platformy Spark
- Ogólna dokumentacja usługi Spark NLP
- Usługa GitHub równoważenia obciążenia sieciowego platformy Spark
- Pokaz równoważenia obciążenia sieciowego platformy Spark
- Potoki równoważenia obciążenia sieciowego platformy Spark
- Adnotacje nlp platformy Spark
- Transformatory NLP platformy Spark
Składniki platformy Azure:
Zasoby platformy Learn:
Powiązane zasoby
- Wybieranie technologii sztucznej inteligencji platformy Microsoft Azure
- Porównanie produktów i technologii uczenia maszynowego firmy Microsoft
- Przepływ uczenia maszynowego i usługa Azure Machine Learning
- Wzbogacanie sztucznej inteligencji przy użyciu obrazów i przetwarzania języka naturalnego w usłudze Azure Cognitive Search