Pomysły dotyczące rozwiązań
W tym artykule opisano pomysł rozwiązania. Architekt chmury może użyć tych wskazówek, aby ułatwić wizualizowanie głównych składników dla typowej implementacji tej architektury. Skorzystaj z tego artykułu jako punktu wyjścia, aby zaprojektować dobrze zaprojektowane rozwiązanie zgodne z konkretnymi wymaganiami obciążenia.
W tym przykładzie przedstawiono sposób wykonywania przyrostowego ładowania w potoku wyodrębniania, ładowania i przekształcania (ELT). Używa usługi Azure Data Factory do automatyzowania potoku ELT. Potok przyrostowo przenosi najnowsze dane OLTP z lokalnej bazy danych programu SQL Server do usługi Azure Synapse. Dane transakcyjne są przekształcane w model tabelaryczny do analizy.
Architektura

Pobierz plik programu Visio z tą architekturą.
Ta architektura opiera się na architekturze przedstawionej w usłudze Enterprise BI z usługą Azure Synapse Analytics, ale dodaje niektóre funkcje, które są ważne w scenariuszach magazynowania danych przedsiębiorstwa.
- Automatyzacja potoku przy użyciu usługi Data Factory.
- Ładowanie przyrostowe.
- Integrowanie wielu źródeł danych.
- Ładowanie danych binarnych, takich jak dane geoprzestrzenne i obrazy.
Przepływ pracy
Architektura składa się z następujących usług i składników.
Źródła danych
Lokalny program SQL Server. Dane źródłowe znajdują się w lokalnej bazie danych programu SQL Server. Aby zasymulować środowisko lokalne. Przykładowa baza danych OLTP Wide World Importers jest używana jako źródłowa baza danych.
Dane zewnętrzne. Typowym scenariuszem dla magazynów danych jest zintegrowanie wielu źródeł danych. Ta architektura referencyjna ładuje zewnętrzny zestaw danych zawierający populacje miast według roku i integruje go z danymi z bazy danych OLTP. Te dane umożliwiają uzyskiwanie szczegółowych informacji, takich jak: "Czy wzrost sprzedaży w każdym regionie jest zgodny lub przekracza wzrost liczby ludności?"
Pozyskiwanie i przechowywanie danych
Blob Storage. Magazyn obiektów blob jest używany jako obszar przejściowy dla danych źródłowych przed załadowaniem ich do usługi Azure Synapse.
Azure Synapse. Usługa Azure Synapse to rozproszony system przeznaczony do przeprowadzania analiz na dużych danych. Obsługuje równoległe przetwarzanie ogromnej ilości danych (MPP), dzięki czemu pozwala na uruchamianie analiz o wysokiej wydajności.
Azure Data Factory. Data Factory to zarządzana usługa, która organizuje i automatyzuje przenoszenie danych i przekształcanie danych. W tej architekturze koordynuje różne etapy procesu ELT.
Analiza i raportowanie
Azure Analysis Services. Analysis Services to w pełni zarządzana usługa, która zapewnia możliwości modelowania danych. Model semantyczny jest ładowany do usług Analysis Services.
Power BI. Usługa Power BI to zestaw narzędzi do analizy biznesowej do analizowania danych pod kątem analiz biznesowych. W tej architekturze wykonuje zapytania dotyczące modelu semantycznego przechowywanego w usługach Analysis Services.
Uwierzytelnianie
Microsoft Entra ID uwierzytelnia użytkowników, którzy łączą się z serwerem usług Analysis Services za pośrednictwem usługi Power BI.
Usługa Data Factory może również używać identyfikatora Entra firmy Microsoft do uwierzytelniania w usłudze Azure Synapse przy użyciu jednostki usługi lub tożsamości usługi zarządzanej (MSI).
Składniki
- Azure Blob Storage
- Azure Synapse Analytics
- Azure Data Factory
- Azure Analysis Services
- Power BI
- Tożsamość Microsoft Entra
Szczegóły scenariusza
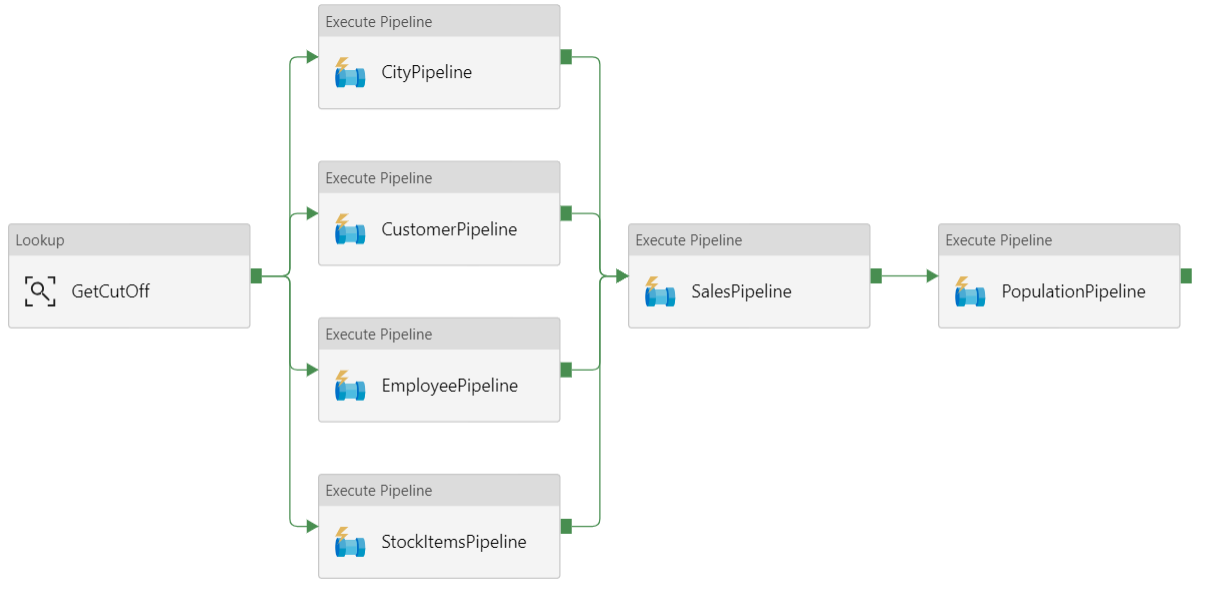
Potok danych
W usłudze Azure Data Factory potok jest logicznym grupowaniem działań używanych do koordynowania zadania — w tym przypadku ładowania i przekształcania danych w usługę Azure Synapse.
Ta architektura referencyjna definiuje potok nadrzędny, który uruchamia sekwencję potoków podrzędnych. Każdy potok podrzędny ładuje dane do co najmniej jednej tabeli magazynu danych.
Zalecenia
Ładowanie przyrostowe
Podczas uruchamiania zautomatyzowanego procesu ETL lub ELT najbardziej wydajne jest ładowanie tylko danych, które uległy zmianie od poprzedniego uruchomienia. Jest to nazywane obciążeniem przyrostowym, a nie pełnym obciążeniem, które ładuje wszystkie dane. Aby wykonać obciążenie przyrostowe, należy określić, które dane uległy zmianie. Najczęstszym podejściem jest użycie wysokiej wartości znaku wodnego, co oznacza śledzenie najnowszej wartości kolumny w tabeli źródłowej, kolumny typu data/godzina lub unikatowej kolumny całkowitej.
Począwszy od programu SQL Server 2016, można użyć tabel czasowych. Są to tabele w wersji systemowej, które zachowują pełną historię zmian danych. Aparat bazy danych automatycznie rejestruje historię każdej zmiany w oddzielnej tabeli historii. Możesz wykonywać zapytania dotyczące danych historycznych, dodając klauzulę FOR SYSTEM_TIME do zapytania. Aparat bazy danych wysyła zapytanie do tabeli historii, ale jest to niewidoczne dla aplikacji.
Uwaga
W przypadku wcześniejszych wersji programu SQL Server można użyć funkcji przechwytywania zmian danych (CDC). Takie podejście jest mniej wygodne niż tabele czasowe, ponieważ trzeba wykonywać zapytania dotyczące oddzielnej tabeli zmian, a zmiany są śledzone przez numer sekwencji dzienników, a nie sygnaturę czasową.
Tabele czasowe są przydatne w przypadku danych wymiarów, które mogą ulec zmianie w czasie. Tabele faktów zwykle reprezentują niezmienną transakcję, taką jak sprzedaż, w takim przypadku utrzymywanie historii wersji systemu nie ma sensu. Zamiast tego transakcje mają zwykle kolumnę reprezentującą datę transakcji, która może być używana jako wartość limitu. Na przykład w bazie danych OLTP Wide World Importers tabele Sales.Invoices i Sales.InvoiceLines mają LastEditedWhen pole domyślne .sysdatetime()
Oto ogólny przepływ potoku ELT:
Dla każdej tabeli w źródłowej bazie danych śledź czas odcięcia po uruchomieniu ostatniego zadania ELT. Zapisz te informacje w magazynie danych. (W początkowej konfiguracji wszystkie czasy są ustawione na "1-1-1900".
W kroku eksportowania danych czas odcięcia jest przekazywany jako parametr do zestawu procedur składowanych w źródłowej bazie danych. Te procedury składowane wysyłają zapytania o wszelkie rekordy, które zostały zmienione lub utworzone po upływie czasu odcięcia. W tabeli faktów Sales jest używana kolumna
LastEditedWhen. W przypadku danych wymiarów używane są tabele czasowe w wersji systemowej.Po zakończeniu migracji danych zaktualizuj tabelę, która przechowuje czasy odcięcia.
Warto również zarejestrować pochodzenie dla każdego przebiegu ELT. W przypadku danego rekordu pochodzenie kojarzy ten rekord z uruchomieniem ELT, które wygenerowało dane. Dla każdego przebiegu ETL jest tworzony nowy rekord pochodzenia dla każdej tabeli, pokazujący czasy ładowania początkowego i końcowego. Klucze pochodzenia dla każdego rekordu są przechowywane w tabelach wymiarów i faktów.
Po załadowaniu nowej partii danych do magazynu odśwież model tabelaryczny usług Analysis Services. Zobacz Odświeżanie asynchroniczne za pomocą interfejsu API REST.
Czyszczenie danych
Czyszczenie danych powinno być częścią procesu ELT. W tej architekturze referencyjnej jednym źródłem nieprawidłowych danych jest tabela populacji miasta, w której niektóre miasta mają zero populacji, być może dlatego, że żadne dane nie były dostępne. Podczas przetwarzania potok ELT usuwa te miasta z tabeli populacji miasta. Przeprowadź czyszczenie danych w tabelach przejściowych, a nie na tabelach zewnętrznych.
Zewnętrzne źródła danych
Magazyny danych często konsoliduje dane z wielu źródeł. Na przykład zewnętrzne źródło danych zawierające dane demograficzne. Ten zestaw danych jest dostępny w usłudze Azure Blob Storage w ramach przykładu WorldWideImportersDW .
Usługa Azure Data Factory może kopiować bezpośrednio z magazynu obiektów blob przy użyciu łącznika magazynu obiektów blob. Jednak łącznik wymaga parametry połączenia lub sygnatury dostępu współdzielonego, więc nie może służyć do kopiowania obiektu blob z publicznym dostępem do odczytu. Aby obejść ten problem, możesz użyć technologii PolyBase do utworzenia tabeli zewnętrznej w usłudze Blob Storage, a następnie skopiować tabele zewnętrzne do usługi Azure Synapse.
Obsługa dużych danych binarnych
Na przykład w źródłowej bazie danych tabela City (Miasto) zawiera kolumnę Location (Lokalizacja), która zawiera typ danych przestrzennych geografii . Usługa Azure Synapse nie obsługuje natywnie typu geografii , więc to pole jest konwertowane na typ varbinary podczas ładowania. (Zobacz Obejścia nieobsługiwanych typów danych).
Jednak technologia PolyBase obsługuje maksymalny rozmiar kolumny varbinary(8000), co oznacza, że niektóre dane mogą zostać obcięte. Obejściem tego problemu jest podzielenie danych na fragmenty podczas eksportowania, a następnie ponowne utworzenie fragmentów w następujący sposób:
Utwórz tymczasową tabelę przejściową dla kolumny Lokalizacja.
Dla każdego miasta podziel dane lokalizacji na fragmenty 8000 bajtów, co powoduje 1–N wierszy dla każdego miasta.
Aby ponownie połączyć fragmenty, użyj operatora T-SQL PIVOT , aby przekonwertować wiersze na kolumny, a następnie połączyć wartości kolumn dla każdego miasta.
Wyzwaniem jest to, że każde miasto będzie podzielone na inną liczbę wierszy w zależności od rozmiaru danych geograficznych. Aby operator PIVOT działał, każde miasto musi mieć taką samą liczbę wierszy. Aby wykonać tę pracę, zapytanie T-SQL wykonuje pewne sztuczki, aby wypełnić wiersze pustymi wartościami, dzięki czemu każde miasto ma taką samą liczbę kolumn po tabeli przestawnej. Wynikowe zapytanie okazuje się być znacznie szybsze niż pętla przez wiersze pojedynczo.
To samo podejście jest używane w przypadku danych obrazów.
Powolne zmienianie wymiarów
Dane wymiarów są stosunkowo statyczne, ale mogą ulec zmianie. Na przykład produkt może zostać ponownie przydzielony do innej kategorii produktów. Istnieje kilka podejść do obsługi wolno zmieniających się wymiarów. Typową techniką o nazwie Type 2 jest dodanie nowego rekordu za każdym razem, gdy zmienia się wymiar.
Aby zaimplementować podejście typu 2, tabele wymiarów wymagają dodatkowych kolumn określających zakres dat obowiązujących dla danego rekordu. Ponadto klucze podstawowe ze źródłowej bazy danych zostaną zduplikowane, więc tabela wymiarów musi mieć sztuczny klucz podstawowy.
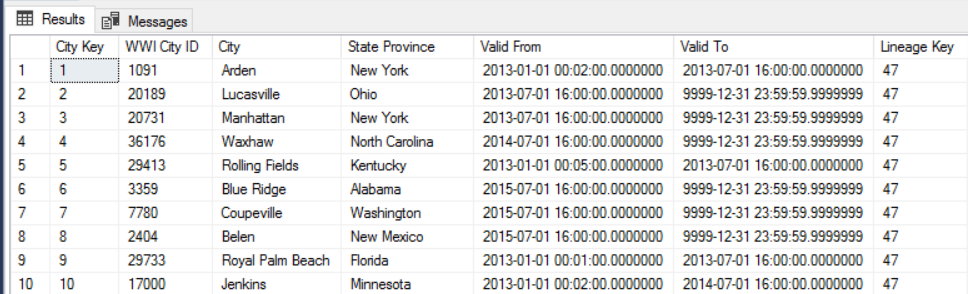
Na przykład na poniższej ilustracji przedstawiono tabelę Dimension.City. Kolumna WWI City ID jest kluczem podstawowym ze źródłowej bazy danych. Kolumna City Key jest kluczem sztucznym wygenerowanym podczas potoku ETL. Zwróć również uwagę, że tabela zawiera Valid From kolumny i Valid To , które definiują zakres, gdy każdy wiersz był prawidłowy. Bieżące wartości mają wartość równą Valid To '9999-12-31'.
Zaletą tego podejścia jest zachowanie danych historycznych, które mogą być przydatne do analizy. Jednak oznacza to również, że będzie wiele wierszy dla tej samej jednostki. Oto na przykład rekordy zgodne WWI City ID = 28561:
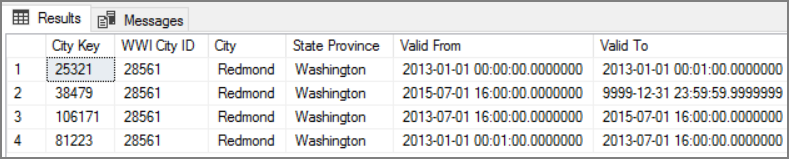
Dla każdego faktu Sales (Sprzedaż) chcesz skojarzyć ten fakt z pojedynczym wierszem w tabeli wymiarów Miasto odpowiadającym dacie faktury.
Kwestie wymagające rozważenia
Te zagadnienia implementują filary struktury Azure Well-Architected Framework, która jest zestawem wytycznych, które mogą służyć do poprawy jakości obciążenia. Aby uzyskać więcej informacji, zobacz Microsoft Azure Well-Architected Framework.
Zabezpieczenia
Zabezpieczenia zapewniają ochronę przed celowymi atakami i nadużyciami cennych danych i systemów. Aby uzyskać więcej informacji, zobacz Lista kontrolna przeglądu projektu dotyczącazabezpieczeń.
Aby uzyskać dodatkowe zabezpieczenia, możesz użyć punktów końcowych usługi sieci wirtualnej, aby zabezpieczyć zasoby usługi platformy Azure tylko w sieci wirtualnej. Spowoduje to całkowite usunięcie publicznego dostępu do Internetu do tych zasobów, co pozwala na ruch tylko z sieci wirtualnej.
Dzięki temu podejściu utworzysz sieć wirtualną na platformie Azure, a następnie utworzysz prywatne punkty końcowe usługi dla usług platformy Azure. Te usługi są następnie ograniczone do ruchu z tej sieci wirtualnej. Możesz również uzyskać do nich dostęp z sieci lokalnej za pośrednictwem bramy.
Należy pamiętać o następujących ograniczeniach:
Jeśli punkty końcowe usługi są włączone dla usługi Azure Storage, technologia PolyBase nie może kopiować danych z usługi Storage do usługi Azure Synapse. Istnieje ograniczenie ryzyka dla tego problemu. Aby uzyskać więcej informacji, zobacz Wpływ używania punktów końcowych usługi sieci wirtualnej z usługą Azure Storage.
Aby przenieść dane ze środowiska lokalnego do usługi Azure Storage, musisz zezwolić na publiczne adresy IP ze środowiska lokalnego lub usługi ExpressRoute. Aby uzyskać szczegółowe informacje, zobacz Zabezpieczanie usług platformy Azure w sieciach wirtualnych.
Aby umożliwić usługom Analysis Services odczytywanie danych z usługi Azure Synapse, wdróż maszynę wirtualną z systemem Windows w sieci wirtualnej, która zawiera punkt końcowy usługi Azure Synapse. Zainstaluj lokalną bramę danych platformy Azure na tej maszynie wirtualnej. Następnie połącz usługę Azure Analysis z bramą danych.
Optymalizacja kosztów
Optymalizacja kosztów dotyczy sposobów zmniejszenia niepotrzebnych wydatków i poprawy wydajności operacyjnej. Aby uzyskać więcej informacji, zobacz Lista kontrolna przeglądu projektu dlaoptymalizacji kosztów.
Koszty możesz szacować za pomocą kalkulatora cen platformy Azure. Poniżej przedstawiono niektóre zagadnienia dotyczące usług używanych w tej architekturze referencyjnej.
Azure Data Factory
Usługa Azure Data Factory automatyzuje potok ELT. Potok przenosi dane z lokalnej bazy danych programu SQL Server do usługi Azure Synapse. Dane są następnie przekształcane w model tabelaryczny na potrzeby analizy. W tym scenariuszu ceny zaczynają się od 0,001 USD przebiegów działań miesięcznie, w tym działań, wyzwalaczy i przebiegów debugowania. Ta cena jest podstawową opłatą tylko za aranżację. Opłaty są również naliczane za działania związane z wykonywaniem, takie jak kopiowanie danych, wyszukiwanie i działania zewnętrzne. Każde działanie jest wyceniane indywidualnie. Opłaty są również naliczane za potoki bez skojarzonych wyzwalaczy ani przebiegów w ciągu miesiąca. Wszystkie działania są proporcjonalnie do minuty i zaokrąglane w górę.
Przykładowa analiza kosztów
Rozważ przypadek użycia, w którym istnieją dwa działania odnośników z dwóch różnych źródeł. Jedna zajmuje 1 minutę i 2 sekundy (zaokrąglone do 2 minut), a druga zajmuje 1 minutę, co daje całkowity czas 3 minut. Jedno działanie kopiowania danych trwa 10 minut. Jedno działanie procedury składowanej trwa 2 minuty. Łączna aktywność jest uruchamiana przez 4 minuty. Koszt jest obliczany w następujący sposób:
Uruchomienia działania: 4 * $ 0.001 = $0.004
Wyszukiwanie: 3 * ($0.005 / 60) = $0.00025
Procedura składowana: 2 * ($0.00025 / 60) = $0.000008
Kopiowanie danych: 10 * ($0.25 / 60) * 4 jednostka integracji danych (DIU) = $0.167
- Całkowity koszt uruchomienia potoku: 0,17 USD.
- Uruchamiany raz dziennie przez 30 dni: $5.1 miesiąc.
- Uruchamiany raz dziennie na 100 tabel przez 30 dni: $ 510
Każde działanie ma skojarzony koszt. Zapoznaj się z modelem cenowym i skorzystaj z kalkulatora cen usługi ADF, aby uzyskać rozwiązanie zoptymalizowane nie tylko pod kątem wydajności, ale także pod kątem kosztów. Zarządzaj kosztami, uruchamiając, zatrzymując, wstrzymując i skalując usługi.
Azure Synapse
Usługa Azure Synapse jest idealna w przypadku obciążeń intensywnie korzystających z wydajności zapytań i skalowalności obliczeń. Możesz wybrać model płatności zgodnie z rzeczywistym użyciem lub użyć planów zarezerwowanych jednego roku (37% oszczędności) lub 3 lat (65% oszczędności).
Opłata za magazyn danych jest naliczana oddzielnie. Inne usługi, takie jak odzyskiwanie po awarii i wykrywanie zagrożeń, są również naliczane oddzielnie.
Aby uzyskać więcej informacji, zobacz Cennik usługi Azure Synapse.
Analysis Services
Ceny usług Azure Analysis Services zależą od warstwy. Implementacja referencyjna tej architektury korzysta z warstwy Deweloper , która jest zalecana do scenariuszy oceny, programowania i testowania. Inne warstwy to warstwa Podstawowa , która jest zalecana dla małego środowiska produkcyjnego; warstwa Standardowa dla aplikacji produkcyjnych o krytycznym znaczeniu. Aby uzyskać więcej informacji, zobacz Właściwa warstwa, gdy jest potrzebna.
W przypadku wstrzymania wystąpienia nie są naliczane żadne opłaty.
Aby uzyskać więcej informacji, zobacz Cennik usług Azure Analysis Services.
Blob Storage
Rozważ użycie funkcji pojemności zarezerwowanej usługi Azure Storage, aby obniżyć koszty magazynowania. Dzięki temu modelowi uzyskasz rabat, jeśli możesz zatwierdzić rezerwację dla stałej pojemności magazynu przez jeden lub trzy lata. Aby uzyskać więcej informacji, zobacz Optymalizowanie kosztów magazynu obiektów blob przy użyciu pojemności zarezerwowanej.
Aby uzyskać więcej informacji, zobacz sekcję Koszt w witrynie Microsoft Azure Well-Architected Framework.
Doskonałość operacyjna
Doskonałość operacyjna obejmuje procesy operacyjne, które wdrażają aplikację i działają w środowisku produkcyjnym. Aby uzyskać więcej informacji, zobacz Lista kontrolna przeglądu projektu dotycząca doskonałości operacyjnej.
Utwórz oddzielne grupy zasobów dla środowisk produkcyjnych, programistycznych i testowych. Oddzielne grupy zasobów ułatwiają zarządzanie wdrożeniami, usuwanie wdrożeń testowych i przypisywanie praw dostępu.
Umieść każde obciążenie w osobnym szablonie wdrożenia i zapisz zasoby w systemach kontroli źródła. Szablony można wdrażać razem lub indywidualnie w ramach procesu ciągłej integracji/ciągłego wdrażania, co ułatwia proces automatyzacji.
W tej architekturze istnieją trzy główne obciążenia:
- Serwer magazynu danych, usługi Analysis Services i powiązane zasoby.
- Azure Data Factory.
- Scenariusz symulowany w środowisku lokalnym do chmury.
Każde obciążenie ma własny szablon wdrożenia.
Serwer magazynu danych jest konfigurowany przy użyciu poleceń interfejsu wiersza polecenia platformy Azure, które są zgodne z imperatywne podejściem praktyk IaC. Rozważ użycie skryptów wdrażania i zintegruj je w procesie automatyzacji.
Rozważ przemieszczanie obciążeń. Wdróż na różnych etapach i uruchom testy weryfikacyjne na każdym etapie przed przejściem do następnego etapu. Dzięki temu można wypychać aktualizacje do środowisk produkcyjnych w sposób wysoce kontrolowany i zminimalizować nieprzewidziane problemy z wdrażaniem. Użyj strategii wdrażania Blue-green i wydania Canary w celu aktualizowania środowisk produkcyjnych na żywo.
Mają dobrą strategię wycofywania do obsługi wdrożeń, które zakończyły się niepowodzeniem. Możesz na przykład automatycznie ponownie wdrożyć wcześniejsze, pomyślne wdrożenie z historii wdrożenia. Zobacz parametr flagi --rollback-on-error w interfejsie wiersza polecenia platformy Azure.
Usługa Azure Monitor jest zalecaną opcją analizowania wydajności magazynu danych i całej platformy azure analytics w celu uzyskania zintegrowanego środowiska monitorowania. Usługa Azure Synapse Analytics udostępnia środowisko monitorowania w witrynie Azure Portal, aby wyświetlić szczegółowe informacje dotyczące obciążenia magazynu danych. Witryna Azure Portal jest zalecanym narzędziem do monitorowania magazynu danych, ponieważ zapewnia konfigurowalne okresy przechowywania, alerty, zalecenia i konfigurowalne wykresy i pulpity nawigacyjne dla metryk i dzienników.
Następne kroki
- Wprowadzenie do usługi Azure Synapse Analytics
- Wprowadzenie do usługi Azure Synapse Analytics
- Wprowadzenie do usługi Azure Data Factory
- Co to jest usługa Azure Data Factory?
- Samouczki dotyczące usługi Azure Data Factory
Powiązane zasoby
Warto zapoznać się z następującymi przykładowymi scenariuszami platformy Azure, które przedstawiają konkretne rozwiązania korzystające z niektórych tych samych technologii: