Zagadnienia dotyczące platformy aplikacji dla obciążeń o znaczeniu krytycznym
Kluczowym obszarem projektowania każdej architektury o znaczeniu krytycznym jest platforma aplikacji. Platforma odwołuje się do składników infrastruktury i usług platformy Azure, które należy aprowizować w celu obsługi aplikacji. Oto kilka nadrzędnych zaleceń.
Projektowanie w warstwach. Wybierz odpowiedni zestaw usług, ich konfigurację i zależności specyficzne dla aplikacji. Takie podejście warstwowe pomaga w tworzeniu segmentacji logicznej i fizycznej. Jest to przydatne podczas definiowania ról i funkcji oraz przypisywania odpowiednich uprawnień i strategii wdrażania. Takie podejście ostatecznie zwiększa niezawodność systemu.
Aplikacja o znaczeniu krytycznym musi być wysoce niezawodna i odporna na awarie centrum danych i awarii regionalnych. Tworzenie nadmiarowości strefowej i regionalnej w konfiguracji aktywne-aktywne jest główną strategią. Podczas wybierania usług platformy Azure dla platformy aplikacji należy wziąć pod uwagę ich Strefy dostępności obsługi i wdrażania oraz wzorców operacyjnych, aby korzystać z wielu regionów świadczenia usługi Azure.
Użyj architektury opartej na jednostkach skalowania do obsługi zwiększonego obciążenia. Jednostki skalowania umożliwiają logiczne grupowanie zasobów i jednostkę można skalować niezależnie od innych jednostek lub usług w architekturze. Użyj modelu pojemności i oczekiwanej wydajności, aby zdefiniować granice, liczbę i skalę bazową każdej jednostki.
W tej architekturze platforma aplikacji składa się z zasobów globalnych, sygnatur wdrożenia i zasobów regionalnych. Zasoby regionalne są aprowizowane w ramach sygnatury wdrożenia. Każda sygnatura jest równa jednostce skalowania i w przypadku, gdy stanie się w złej kondycji, może zostać całkowicie zamieniona.
Zasoby w każdej warstwie mają odrębne cechy. Aby uzyskać więcej informacji, zobacz Wzorzec architektury typowego obciążenia o znaczeniu krytycznym.
| Charakterystyki | Kwestie wymagające rozważenia |
|---|---|
| Okres istnienia | Jaki jest oczekiwany okres istnienia zasobu względem innych zasobów w rozwiązaniu? Czy zasób powinien przetrwać lub udostępnić okres istnienia całej systemowi lub regionowi, czy też powinien być tymczasowy? |
| Stan | Jaki wpływ będzie miał stan utrwalone w tej warstwie na niezawodność lub możliwość zarządzania? |
| Usługa Reach | Czy zasób musi być dystrybuowany globalnie? Czy zasób może komunikować się z innymi zasobami, globalnie lub w regionach? |
| Zależności | Jaka jest zależność od innych zasobów, globalnie lub w innych regionach? |
| Limity skalowania | Jaka jest oczekiwana przepływność dla tego zasobu w tej warstwie? Ile skalowania jest zapewniana przez zasób, aby dopasować je do tego zapotrzebowania? |
| Dostępność/odzyskiwanie po awarii | Jaki jest wpływ na dostępność lub awarię w tej warstwie? Czy może to spowodować awarię systemową lub problem z lokalną pojemnością lub dostępnością? |
Zasoby globalne
Niektóre zasoby w tej architekturze są współużytkowane przez zasoby wdrożone w regionach. W tej architekturze są one używane do dystrybucji ruchu między wieloma regionami, przechowywania stanu trwałego dla całej aplikacji i buforowania globalnych danych statycznych.
| Charakterystyki | Zagadnienia dotyczące warstw |
|---|---|
| Okres istnienia | Oczekuje się, że te zasoby będą długotrwałe. Ich okres istnienia obejmuje żywotność systemu lub dłużej. Często zasoby są zarządzane za pomocą aktualizacji płaszczyzny sterowania i danych w miejscu, przy założeniu, że obsługują operacje aktualizacji bez przestojów. |
| Stan | Ponieważ te zasoby istnieją przez co najmniej okres istnienia systemu, ta warstwa jest często odpowiedzialna za przechowywanie globalnego, zreplikowanego geograficznie stanu. |
| Usługa Reach | Zasoby powinny być dystrybuowane globalnie. Zaleca się, aby te zasoby komunikowały się z zasobami regionalnymi lub innymi zasobami z małym opóźnieniem i żądaną spójnością. |
| Zależności | Zasoby powinny unikać zależności od zasobów regionalnych, ponieważ ich niedostępność może być przyczyną awarii globalnej. Na przykład certyfikaty lub wpisy tajne przechowywane w jednym magazynie mogą mieć globalny wpływ, jeśli wystąpi awaria regionalna, w której znajduje się magazyn. |
| Limity skalowania | Często te zasoby są pojedynczymi wystąpieniami w systemie i w związku z tym powinny być w stanie skalować takie, że mogą obsługiwać przepływność systemu jako całości. |
| Dostępność/odzyskiwanie po awarii | Ze względu na to, że zasoby regionalne i sygnaturowe mogą korzystać z zasobów globalnych lub są frontowane przez nie, ważne jest, aby zasoby globalne były konfigurowane z wysoką dostępnością i odzyskiwaniem po awarii dla kondycji całego systemu. |
W tej architekturze zasoby warstwy globalnej to usługi Azure Front Door, Azure Cosmos DB, Azure Container Registry i Azure Log Analytics do przechowywania dzienników i metryk z innych zasobów warstwy globalnej.
W tym projekcie istnieją inne podstawowe zasoby, takie jak Microsoft Entra ID i Azure DNS. Zostały one pominięte na tym obrazie w celu zwięzłości.

Globalny moduł równoważenia obciążenia
Usługa Azure Front Door jest używana jako jedyny punkt wejścia dla ruchu użytkowników. Platforma Azure gwarantuje, że usługa Azure Front Door dostarczy żądaną zawartość bez błędu 99,99% czasu. Aby uzyskać więcej informacji, zobacz Limity usługi Front Door. Jeśli usługa Front Door stanie się niedostępna, użytkownik końcowy zobaczy system jako wyłączony.
Wystąpienie usługi Front Door wysyła ruch do skonfigurowanych usług zaplecza, takich jak klaster obliczeniowy hostujący interfejs API i spa frontonu. Błędy konfiguracji zaplecza w usłudze Front Door mogą prowadzić do awarii. Aby uniknąć awarii z powodu błędów konfiguracji, należy intensywnie przetestować ustawienia usługi Front Door.
Inny typowy błąd może pochodzić z błędnie skonfigurowanych lub brakujących certyfikatów TLS, co może uniemożliwić użytkownikom korzystanie z frontonu lub usługi Front Door komunikujących się z zapleczem. Środki zaradcze mogą wymagać interwencji ręcznej. Możesz na przykład wycofać poprzednią konfigurację i ponownie wydać certyfikat, jeśli to możliwe. Niezależnie od tego, spodziewaj się niedostępności podczas wprowadzania zmian. Korzystanie z certyfikatów zarządzanych oferowanych przez usługę Front Door jest zalecane w celu zmniejszenia nakładu pracy, takiego jak obsługa wygaśnięcia.
Usługa Front Door oferuje wiele dodatkowych funkcji oprócz globalnego routingu ruchu. Ważną funkcją jest zapora aplikacji internetowej (WAF), ponieważ usługa Front Door może sprawdzać ruch przechodzący. Po skonfigurowaniu w trybie zapobiegania będzie blokowany podejrzany ruch, zanim jeszcze dotrze do dowolnego zaplecza.
Aby uzyskać informacje na temat możliwości usługi Front Door, zobacz Często zadawane pytania dotyczące usługi Azure Front Door.
Aby zapoznać się z innymi zagadnieniami dotyczącymi globalnego rozkładu ruchu, zobacz Wskazówki dotyczące krytycznego misji w dobrze zaprojektowanej strukturze: routing globalny.
Container Registry
Usługa Azure Container Registry służy do przechowywania artefaktów Open Container Initiative (OCI), w szczególności wykresów helm i obrazów kontenerów. Nie uczestniczy w przepływie żądań i jest uzyskiwany dostęp tylko okresowo. Rejestr kontenerów jest wymagany do istnienia przed wdrożeniem zasobów sygnatury i nie powinien mieć zależności od zasobów warstwy regionalnej.
Włącz nadmiarowość strefy i replikację geograficzną rejestrów, aby dostęp środowiska uruchomieniowego do obrazów był szybki i odporny na awarie. W przypadku niedostępności wystąpienie może następnie przejść w tryb failover do regionów repliki, a żądania są automatycznie przekierowywane ponownie do innego regionu. Spodziewaj się przejściowych błędów podczas ściągania obrazów do czasu zakończenia pracy w trybie failover.
Błędy mogą również wystąpić, jeśli obrazy są usuwane przypadkowo, nowe węzły obliczeniowe nie będą mogły ściągać obrazów, ale istniejące węzły nadal mogą używać buforowanych obrazów. Podstawową strategią odzyskiwania po awarii jest ponowne wdrożenie. Artefakty w rejestrze kontenerów można wygenerować ponownie z potoków. Rejestr kontenerów musi być w stanie wytrzymać wiele współbieżnych połączeń w celu obsługi wszystkich wdrożeń.
Zaleca się użycie jednostki SKU Premium do włączenia replikacji geograficznej. Funkcja nadmiarowości strefy zapewnia odporność i wysoką dostępność w określonym regionie. W przypadku awarii regionalnej repliki w innych regionach są nadal dostępne dla operacji płaszczyzny danych. Dzięki tej jednostce SKU można ograniczyć dostęp do obrazów za pośrednictwem prywatnych punktów końcowych.
Aby uzyskać więcej informacji, zobacz Najlepsze rozwiązania dotyczące usługi Azure Container Registry.
baza danych
Zaleca się, aby cały stan był przechowywany globalnie w bazie danych oddzielonej od sygnatur regionalnych. Tworzenie nadmiarowości przez wdrożenie bazy danych w różnych regionach. W przypadku obciążeń o znaczeniu krytycznym synchronizacja danych między regionami powinna być głównym problemem. Ponadto w przypadku awarii żądania zapisu w bazie danych powinny nadal działać.
Replikacja danych w konfiguracji aktywne-aktywne jest zdecydowanie zalecana. Aplikacja powinna mieć możliwość natychmiastowego nawiązania połączenia z innym regionem. Wszystkie wystąpienia powinny mieć możliwość obsługi żądań odczytu i zapisu.
Aby uzyskać więcej informacji, zobacz Platforma danych dla obciążeń o znaczeniu krytycznym.
Monitorowanie globalne
Usługa Azure Log Analytics służy do przechowywania dzienników diagnostycznych ze wszystkich zasobów globalnych. Zaleca się ograniczenie dziennego limitu przydziału w magazynie, szczególnie w środowiskach używanych do testowania obciążenia. Ponadto ustaw zasady przechowywania. Te ograniczenia uniemożliwią wszelkie nadmierne wydatki, które są naliczane przez przechowywanie danych, które nie są potrzebne poza limitem.
Zagadnienia dotyczące podstawowych usług
System może używać innych krytycznych usług platformy, które mogą spowodować, że cały system będzie zagrożony, na przykład Azure DNS i Microsoft Entra ID. Usługa Azure DNS gwarantuje umowę SLA dotyczącą dostępności 100% dla prawidłowych żądań DNS. Firma Microsoft Entra gwarantuje co najmniej 99,99% czasu pracy. Mimo to należy pamiętać o wpływie na awarię.
Podjęcie twardej zależności od podstawowych usług jest nieuniknione, ponieważ wiele usług platformy Azure zależy od nich. Spodziewaj się zakłóceń w systemie, jeśli są one niedostępne. Przykład:
- Usługa Azure Front Door używa usługi Azure DNS do uzyskania dostępu do zaplecza i innych usług globalnych.
- Usługa Azure Container Registry używa usługi Azure DNS do przełączania żądań w tryb failover do innego regionu.
W obu przypadkach będzie to miało wpływ na obie usługi platformy Azure, jeśli usługa Azure DNS jest niedostępna. Rozpoznawanie nazw dla żądań użytkowników z usługi Front Door zakończy się niepowodzeniem; Obrazy platformy Docker nie zostaną pobrane z rejestru. Użycie zewnętrznej usługi DNS jako kopii zapasowej nie ogranicza ryzyka, ponieważ wiele usług platformy Azure nie zezwala na taką konfigurację i polega na wewnętrznym systemie DNS. Spodziewaj się pełnej awarii.
Podobnie identyfikator Entra firmy Microsoft jest używany do wykonywania operacji płaszczyzny sterowania, takich jak tworzenie nowych węzłów usługi AKS, ściąganie obrazów z usługi Container Registry lub uzyskiwanie dostępu do usługi Key Vault podczas uruchamiania zasobnika. Jeśli identyfikator Entra firmy Microsoft jest niedostępny, istniejące składniki nie powinny mieć wpływu, ale ogólna wydajność może być obniżona. Nowe zasobniki lub węzły usługi AKS nie będą działać. Dlatego w przypadku, gdy operacje skalowania w poziomie są wymagane w tym czasie, spodziewaj się mniejszego środowiska użytkownika.
Zasoby sygnatur wdrożenia regionalnego
W tej architekturze sygnatura wdrożenia wdraża obciążenie i aprowizuje zasoby, które uczestniczą w realizacji transakcji biznesowych. Sygnatura zazwyczaj odpowiada wdrożeniu w regionie świadczenia usługi Azure. Chociaż region może mieć więcej niż jedną sygnaturę.
| Charakterystyki | Kwestie wymagające rozważenia |
|---|---|
| Okres istnienia | Oczekuje się, że zasoby będą miały krótki okres życia (efemeryczny) z zamiarem, że mogą one zostać dodane i usunięte dynamicznie, podczas gdy zasoby regionalne poza sygnaturą będą nadal utrwalane. Efemeryczny charakter jest potrzebny, aby zapewnić większą odporność, skalę i bliskość użytkowników. |
| Stan | Ponieważ sygnatury są efemeryczne i mogą być niszczone w dowolnym momencie, sygnatura powinna być bezstanowa jak najwięcej. |
| Usługa Reach | Może komunikować się z zasobami regionalnymi i globalnymi. Należy jednak unikać komunikacji z innymi regionami lub innymi sygnaturami. W tej architekturze nie ma potrzeby globalnego dystrybuowania tych zasobów. |
| Zależności | Zasoby sygnatury muszą być niezależne. Oznacza to, że nie powinny one polegać na innych sygnaturach ani składnikach w innych regionach. Oczekuje się, że będą one mieć zależności regionalne i globalne. Głównym składnikiem udostępnionym jest warstwa bazy danych i rejestr kontenerów. Ten składnik wymaga synchronizacji w czasie wykonywania. |
| Limity skalowania | Przepływność jest ustanawiana przez testowanie. Przepływność ogólnej sygnatury jest ograniczona do najmniej wydajnego zasobu. Przepływność sygnatur musi uwzględniać szacowany wysoki poziom zapotrzebowania i wszelkie przejścia w tryb failover w wyniku wystąpienia innej sygnatury w regionie, która stanie się niedostępna. |
| Dostępność/odzyskiwanie po awarii | Ze względu na tymczasowy charakter sygnatur odzyskiwanie po awarii odbywa się poprzez ponowne wdrożenie sygnatury. Jeśli zasoby są w złej kondycji, sygnatura jako całość może zostać zniszczona i wdrożona ponownie. |
W tej architekturze zasoby sygnatur to Azure Kubernetes Service, Azure Event Hubs, Azure Key Vault i Azure Blob Storage.
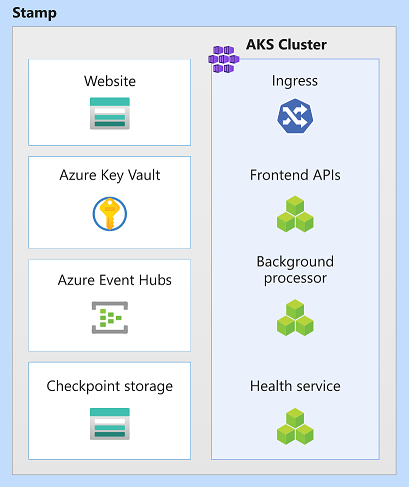
Jednostka skalowania
Sygnaturę można również traktować jako jednostkę skalowania (SU). Wszystkie składniki i usługi w ramach danej sygnatury są konfigurowane i testowane pod kątem obsługi żądań w danym zakresie. Oto przykład jednostki skalowania używanej w implementacji.
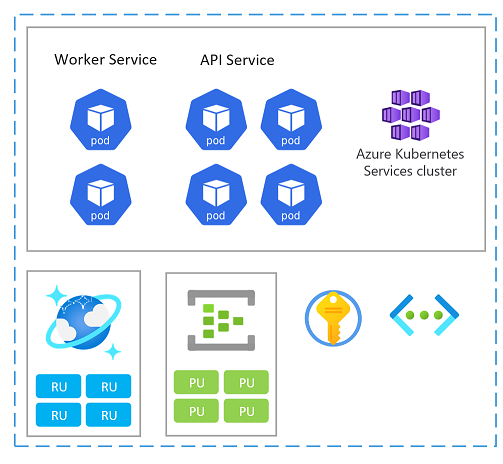
Każda jednostka skalowania jest wdrażana w regionie świadczenia usługi Azure i dlatego obsługuje głównie ruch z danego obszaru (chociaż może przejąć ruch z innych regionów w razie potrzeby). Ten rozkład geograficzny prawdopodobnie spowoduje wzorce obciążenia i godziny pracy, które mogą się różnić od regionu do regionu, a w związku z tym każda liczba jednostek jednostki SU jest przeznaczona do skalowania w poziomie/w dół w przypadku bezczynności.
Możesz wdrożyć nową sygnaturę do skalowania. Wewnątrz sygnatury poszczególne zasoby mogą być również jednostkami skalowania.
Poniżej przedstawiono niektóre zagadnienia dotyczące skalowania i dostępności podczas wybierania usług platformy Azure w ramach lekcji:
Oceń relacje pojemności między wszystkimi zasobami w jednostce skalowania. Na przykład do obsługi 100 żądań przychodzących potrzebne będzie 5 zasobników kontrolera ruchu przychodzącego i 3 zasobników usługi katalogu oraz 1000 jednostek RU w usłudze Azure Cosmos DB. Dlatego podczas automatycznego skalowania zasobników ruchu przychodzącego oczekiwano skalowania usługi katalogu i jednostek RU usługi Azure Cosmos DB, biorąc pod uwagę te zakresy.
Przetestuj obciążenie usług , aby określić zakres, w którym będą obsługiwane żądania. Na podstawie wyników skonfiguruj minimalne i maksymalne wystąpienia oraz metryki docelowe. Po osiągnięciu celu można zautomatyzować skalowanie całej lekcji.
Zapoznaj się z limitami skalowania i limitami przydziałów subskrypcji platformy Azure, aby obsługiwać pojemność i model kosztów ustawiony zgodnie z wymaganiami biznesowymi. Sprawdź również limity poszczególnych usług, które należy wziąć pod uwagę. Ponieważ jednostki są zwykle wdrażane razem, należy uwzględnić limity zasobów subskrypcji, które są wymagane dla wdrożeń kanarowych. Aby uzyskać więcej informacji, zobacz Limity usług platformy Azure.
Wybierz usługi, które obsługują strefy dostępności w celu utworzenia nadmiarowości. Może to ograniczyć wybór technologii. Aby uzyskać szczegółowe informacje, zobacz Strefy dostępności.
Aby zapoznać się z innymi zagadnieniami dotyczącymi rozmiaru jednostki i kombinacji zasobów, zobacz Wskazówki krytyczne dla misji w dobrze zaprojektowanej strukturze: architektura jednostek skalowania.
Klaster obliczeniowy
Aby konteneryzować obciążenie, każda sygnatura musi uruchomić klaster obliczeniowy. W tej architekturze wybrano usługę Azure Kubernetes Service (AKS), ponieważ platforma Kubernetes jest najpopularniejszą platformą obliczeniową dla nowoczesnych, konteneryzowanych aplikacji.
Okres istnienia klastra usługi AKS jest powiązany z efemerycznym charakterem sygnatury. Klaster jest bezstanowy i nie ma trwałych woluminów. Używa on efemerycznych dysków systemu operacyjnego zamiast dysków zarządzanych, ponieważ nie powinny odbierać konserwacji aplikacji ani na poziomie systemu.
Aby zwiększyć niezawodność, klaster jest skonfigurowany do używania wszystkich trzech stref dostępności w danym regionie. Ponadto, aby włączyć umowę SLA czasu pracy usługi AKS z gwarantowaną dostępnością umowy SLA na poziomie 99,95% dla płaszczyzny sterowania usługi AKS, klaster powinien używać warstwy Standardowa lub Premium . Aby dowiedzieć się więcej, zobacz Warstwy cenowe usługi AKS.
Inne czynniki, takie jak limity skalowania, pojemność obliczeniowa, limit przydziału subskrypcji mogą również mieć wpływ na niezawodność. Jeśli nie osiągnięto wystarczającej pojemności lub limitów, skalowanie w poziomie i skalowanie w górę zakończy się niepowodzeniem, ale oczekuje się, że istniejące zasoby obliczeniowe będą działać.
Klaster ma włączone skalowanie automatyczne, aby umożliwić pule węzłów automatyczne skalowanie w poziomie w razie potrzeby, co zwiększa niezawodność. W przypadku korzystania z wielu pul węzłów wszystkie pule węzłów powinny być skalowane automatycznie.
Na poziomie zasobnika narzędzie Horizontal Pod Autoscaler (HPA) skaluje zasobniki na podstawie skonfigurowanego procesora CPU, pamięci lub metryk niestandardowych. Przetestuj obciążenia składniki obciążenia, aby ustanowić punkt odniesienia dla wartości autoskalatora i HPA.
Klaster jest również skonfigurowany do automatycznego uaktualniania obrazu węzła i do odpowiedniego skalowania podczas tych uaktualnień. To skalowanie umożliwia zerowy przestój podczas wykonywania uaktualnień. Jeśli klaster w jednej sygnaturze ulegnie awarii podczas uaktualniania, inne klastry w innych sygnaturach nie powinny mieć wpływu, ale uaktualnienia między sygnaturami powinny wystąpić w różnych momentach, aby zachować dostępność. Ponadto uaktualnienia klastra są automatycznie wdrażane w węzłach, dzięki czemu nie są one jednocześnie niedostępne.
Niektóre składniki, takie jak cert-manager i ingress-nginx, wymagają obrazów kontenerów z zewnętrznych rejestrów kontenerów. Jeśli te repozytoria lub obrazy są niedostępne, nowe wystąpienia w nowych węzłach (gdzie obraz nie jest buforowany) mogą nie być w stanie uruchomić. To ryzyko można ograniczyć przez zaimportowanie tych obrazów do usługi Azure Container Registry środowiska.
Obserwowanie ma kluczowe znaczenie w tej architekturze, ponieważ sygnatury są efemeryczne. Ustawienia diagnostyczne są skonfigurowane do przechowywania wszystkich danych dzienników i metryk w regionalnym obszarze roboczym usługi Log Analytics. Ponadto usługa AKS Container Insights jest włączona za pośrednictwem agenta pakietu OMS w klastrze. Ten agent umożliwia klastrowi wysyłanie danych monitorowania do obszaru roboczego usługi Log Analytics.
Aby zapoznać się z innymi zagadnieniami dotyczącymi klastra obliczeniowego, zobacz Przewodniki o znaczeniu krytycznym w dobrze zaprojektowanej strukturze: orkiestracja kontenerów i platforma Kubernetes.
Key Vault
Usługa Azure Key Vault służy do przechowywania globalnych wpisów tajnych, takich jak parametry połączenia do bazy danych i sygnatur wpisów tajnych, takich jak usługa Event Hubs parametry połączenia.
Ta architektura używa sterownika CSI magazynu wpisów tajnych w klastrze obliczeniowym do pobierania wpisów tajnych z usługi Key Vault. Wpisy tajne są potrzebne podczas tworzenia nowych zasobników. Jeśli usługa Key Vault jest niedostępna, nowe zasobniki mogą nie rozpocząć pracy. W związku z tym mogą wystąpić zakłócenia; Może to mieć wpływ na operacje skalowania w poziomie, aktualizacje mogą zakończyć się niepowodzeniem, nie można wykonać nowych wdrożeń.
Usługa Key Vault ma limit liczby operacji. Ze względu na automatyczną aktualizację wpisów tajnych można osiągnąć limit, jeśli istnieje wiele zasobników. Możesz zmniejszyć częstotliwość aktualizacji, aby uniknąć tej sytuacji.
Aby zapoznać się z innymi zagadnieniami dotyczącymi zarządzania wpisami tajnymi, zobacz Wskazówki dotyczące krytycznego misji w dobrze zaprojektowanej strukturze: ochrona integralności danych.
Event Hubs
Jedyną usługą stanową w sygnaturze jest broker komunikatów, Azure Event Hubs, który przechowuje żądania przez krótki okres. Broker obsługuje potrzebę buforowania i niezawodnej obsługi komunikatów. Przetworzone żądania są utrwalane w globalnej bazie danych.
W tej architekturze używana jest jednostka SKU w warstwie Standardowa, a nadmiarowość stref jest włączona w celu zapewnienia wysokiej dostępności.
Kondycja usługi Event Hubs jest weryfikowana przez składnik HealthService uruchomiony w klastrze obliczeniowym. Wykonuje okresowe kontrole względem różnych zasobów. Jest to przydatne w wykrywaniu warunków złej kondycji. Jeśli na przykład nie można wysłać komunikatów do centrum zdarzeń, sygnatura będzie bezużyteczna dla żadnych operacji zapisu. Usługa HealthService powinna automatycznie wykryć ten warunek i zgłosić stan złej kondycji do usługi Front Door, co spowoduje wylogowanie z rotacji.
W celu zapewnienia skalowalności zaleca się włączenie automatycznego rozszerzania.
Aby uzyskać więcej informacji, zobacz Usługi obsługi komunikatów dla obciążeń o znaczeniu krytycznym.
Aby zapoznać się z innymi zagadnieniami dotyczącymi obsługi komunikatów, zobacz Wskazówki dotyczące krytycznego misji w dobrze zaprojektowanej strukturze: asynchroniczna obsługa komunikatów.
Konta magazynu
W tej architekturze aprowizowane są dwa konta magazynu. Oba konta są wdrażane w trybie strefowo nadmiarowym (ZRS).
Jedno konto jest używane do tworzenia punktów kontrolnych usługi Event Hubs. Jeśli to konto nie odpowiada, sygnatura nie będzie mogła przetwarzać komunikatów z usługi Event Hubs, a nawet może mieć wpływ na inne usługi w sygnaturze. Ten warunek jest okresowo sprawdzany przez usługę HealthService, która jest jednym ze składników aplikacji uruchomionych w klastrze obliczeniowym.
Druga jest używana do hostowania aplikacji jednostronicowej interfejsu użytkownika. Jeśli obsługa statycznej witryny internetowej ma jakiekolwiek problemy, usługa Front Door wykryje problem i nie wyśle ruchu do tego konta magazynu. W tym czasie usługa Front Door może używać buforowanej zawartości.
Aby uzyskać więcej informacji na temat odzyskiwania, zobacz Odzyskiwanie po awarii i tryb failover konta magazynu.
Zasoby regionalne
System może mieć zasoby wdrożone w regionie, ale przeżyć zasoby sygnatury. W tej architekturze dane dotyczące obserwacji zasobów sygnatur są przechowywane w regionalnych magazynach danych.
| Charakterystyki | Kwestie wymagające rozważenia |
|---|---|
| Okres istnienia | Zasoby współdzielą okres istnienia regionu i na żywo zasoby sygnatury. |
| Stan | Stan przechowywany w regionie nie może przekraczać okresu istnienia regionu. Jeśli stan musi być współużytkowany w różnych regionach, rozważ użycie globalnego magazynu danych. |
| Usługa Reach | Zasoby nie muszą być dystrybuowane globalnie. Bezpośrednia komunikacja z innymi regionami powinna być unikana kosztem. |
| Zależności | Zasoby mogą mieć zależności od zasobów globalnych, ale nie zasobów sygnatur, ponieważ sygnatury mają być krótkotrwałe. |
| Limity skalowania | Określ limit skali zasobów regionalnych, łącząc wszystkie sygnatury w regionie. |
Monitorowanie danych dla zasobów sygnatury
Wdrażanie zasobów monitorowania jest typowym przykładem zasobów regionalnych. W tej architekturze każdy region ma oddzielny obszar roboczy usługi Log Analytics skonfigurowany do przechowywania wszystkich danych dzienników i metryk emitowanych z zasobów sygnatury. Ze względu na to, że zasoby regionalne przejmą zasoby sygnatury na żywo, dane są dostępne nawet wtedy, gdy sygnatura zostanie usunięta.
Usługa Azure Log Analytics i aplikacja systemu Azure Insights służą do przechowywania dzienników i metryk z platformy. Zaleca się ograniczenie dziennego limitu przydziału w magazynie, szczególnie w środowiskach używanych do testowania obciążenia. Ponadto ustaw zasady przechowywania, aby przechowywać wszystkie dane. Te ograniczenia uniemożliwią wszelkie nadmierne wydatki, które są naliczane przez przechowywanie danych, które nie są potrzebne poza limitem.
Podobnie usługa Application Insights jest również wdrażana jako zasób regionalny w celu zbierania wszystkich danych monitorowania aplikacji.
Aby uzyskać zalecenia dotyczące projektowania dotyczące monitorowania, zobacz Wskazówki o znaczeniu krytycznym w artykule Well-architected Framework: Health modeling (Dobrze zaprojektowana struktura: modelowanie kondycji).
Następne kroki
Wdróż implementację referencyjną, aby uzyskać pełną wiedzę na temat zasobów i ich konfiguracji używanej w tej architekturze.