W tym artykule opisano sposób, w jaki zespół programistyczny używał metryk do znajdowania wąskich gardeł i poprawiania wydajności systemu rozproszonego. Artykuł jest oparty na rzeczywistym testowaniu obciążenia, które zostało wykonana dla przykładowej aplikacji. Aplikacja pochodzi z planu bazowego Azure Kubernetes Service (AKS) dla mikrousług wraz z projektem testu obciążeniowego programu Visual Studio używanym do generowania wyników.
Ten artykuł jest częścią serii. Przeczytaj pierwszą część tutaj.
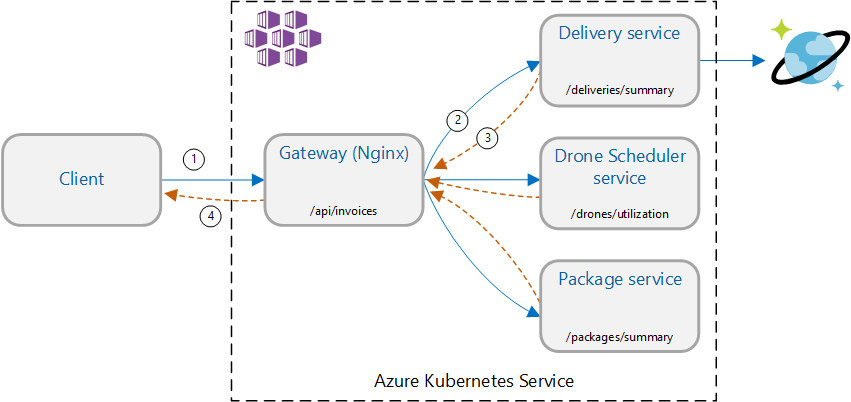
Scenariusz: wywołaj wiele usług zaplecza, aby pobrać informacje, a następnie zagregować wyniki.
Ten scenariusz obejmuje aplikację dostarczania dronów. Klienci mogą wysyłać zapytania do interfejsu API REST, aby uzyskać najnowsze informacje o fakturze. Faktura zawiera podsumowanie dostaw, pakietów i całkowitego wykorzystania dronów przez klienta. Ta aplikacja używa architektury mikrousług działających w usłudze AKS, a informacje potrzebne do faktury są rozłożone na kilka mikrousług.
Zamiast klienta wywołującego każdą usługę bezpośrednio, aplikacja implementuje wzorzec agregacji bramy . Korzystając z tego wzorca, klient wysyła pojedyncze żądanie do usługi bramy. Brama z kolei wywołuje usługi zaplecza równolegle, a następnie agreguje wyniki w jeden ładunek odpowiedzi.
Test 1. Wydajność punktu odniesienia
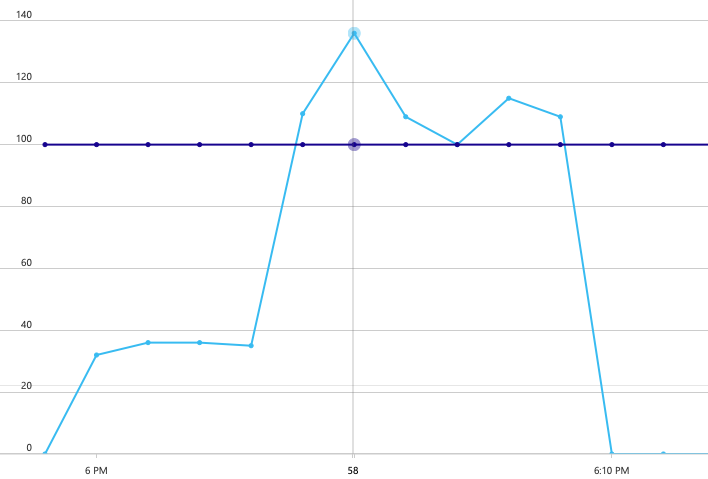
Aby ustanowić punkt odniesienia, zespół programistyczny rozpoczął test obciążenia krokowego, co zwiększa obciążenie od jednego symulowanego użytkownika do 40 użytkowników w łącznym czasie trwania 8 minut. Poniższy wykres, pobrany z programu Visual Studio, pokazuje wyniki. Fioletowa linia pokazuje obciążenie użytkownika, a pomarańczowa linia pokazuje przepływność (średnie żądania na sekundę).
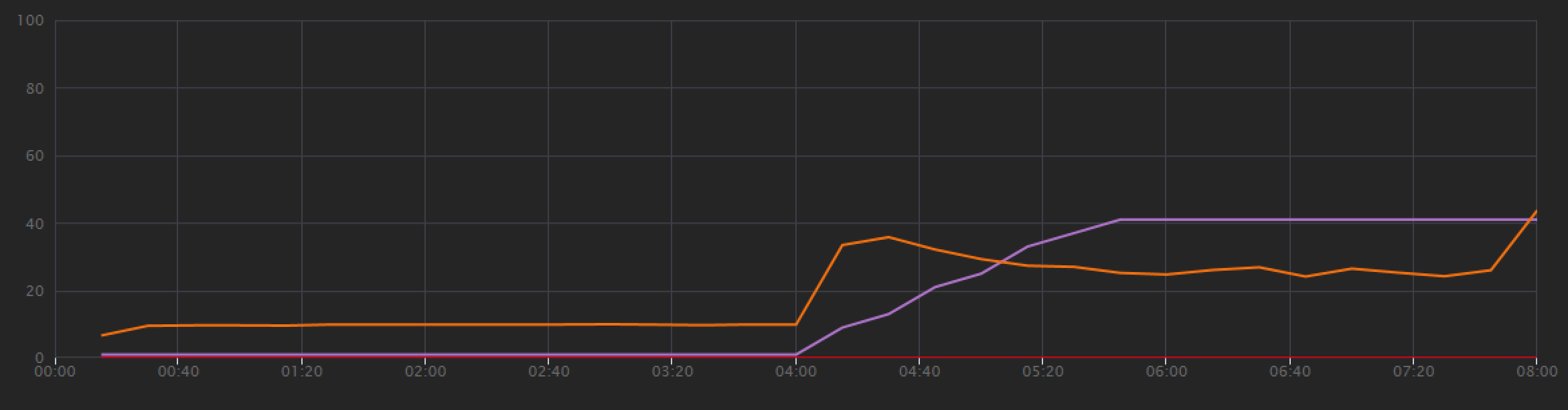
Czerwona linia u dołu wykresu pokazuje, że do klienta nie zostały zwrócone żadne błędy, co jest zachęcające. Jednak średnia przepływność osiąga około połowy testu, a następnie spada dla pozostałej części, nawet gdy obciążenie nadal rośnie. Oznacza to, że zaplecze nie jest w stanie nadążyć. Wzorzec widoczny tutaj jest typowy, gdy system zaczyna osiągać limity zasobów — po osiągnięciu maksymalnej przepływności faktycznie spada znacznie. Rywalizacja o zasoby, błędy przejściowe lub wzrost liczby wyjątków może przyczynić się do tego wzorca.
Zapoznajmy się z danymi monitorowania, aby dowiedzieć się, co dzieje się w systemie. Następny wykres jest pobierany z usługi Application Insights. Przedstawia on średni czas trwania wywołań HTTP z bramy do usług zaplecza.
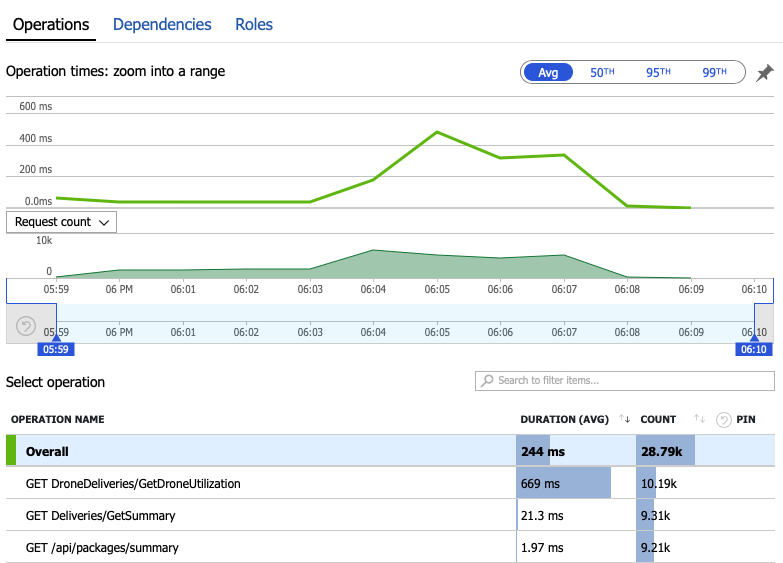
Ten wykres pokazuje, że jedna operacja, w szczególności , GetDroneUtilizationtrwa średnio znacznie dłużej — o kolejność wielkości. Brama wykonuje te wywołania równolegle, więc najwolniejsza operacja określa, jak długo trwa ukończenie całego żądania.
Oczywiście następnym krokiem jest zapoznanie się z operacją GetDroneUtilization i wyszukiwanie wszelkich wąskich gardeł. Jedną z możliwości jest wyczerpanie zasobów. Być może ta konkretna usługa zaplecza zabraknie procesora CPU lub pamięci. W przypadku klastra usługi AKS te informacje są dostępne w Azure Portal za pośrednictwem funkcji szczegółowych informacji o kontenerze usługi Azure Monitor. Na poniższych wykresach przedstawiono wykorzystanie zasobów na poziomie klastra:
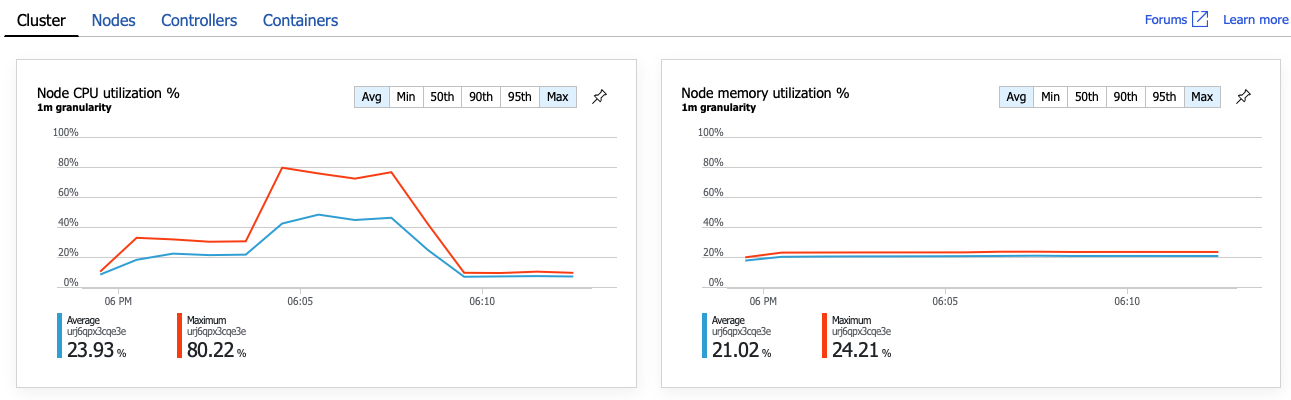
Na tym zrzucie ekranu są wyświetlane zarówno wartości średnie, jak i maksymalne. Ważne jest, aby przyjrzeć się więcej niż tylko średniej, ponieważ średnia może ukryć skoki danych. W tym miejscu średnie wykorzystanie procesora CPU pozostaje poniżej 50%, ale istnieje kilka skoków do 80%. Jest to blisko pojemności, ale nadal w granicach tolerancji. Coś innego powoduje wąskie gardło.
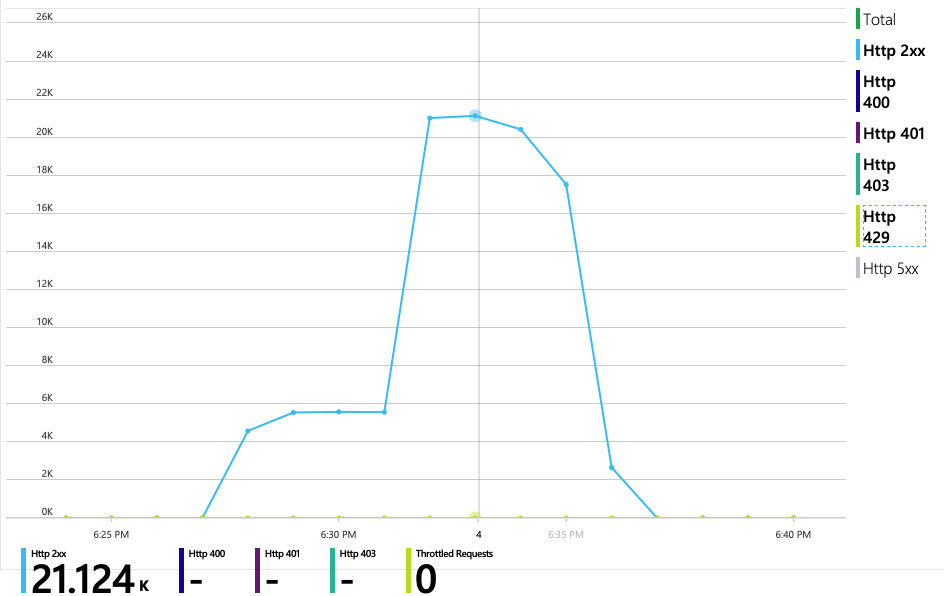
Następny wykres ujawnia prawdziwego winowajcę. Na tym wykresie przedstawiono kody odpowiedzi HTTP z bazy danych zaplecza usługi dostarczania, co w tym przypadku jest usługą Azure Cosmos DB. Niebieska linia reprezentuje kody powodzenia (HTTP 2xx), podczas gdy zielona linia reprezentuje błędy HTTP 429. Kod powrotny HTTP 429 oznacza, że usługa Azure Cosmos DB tymczasowo ogranicza żądania, ponieważ obiekt wywołujący zużywa więcej jednostek zasobów (RU) niż aprowizacji.
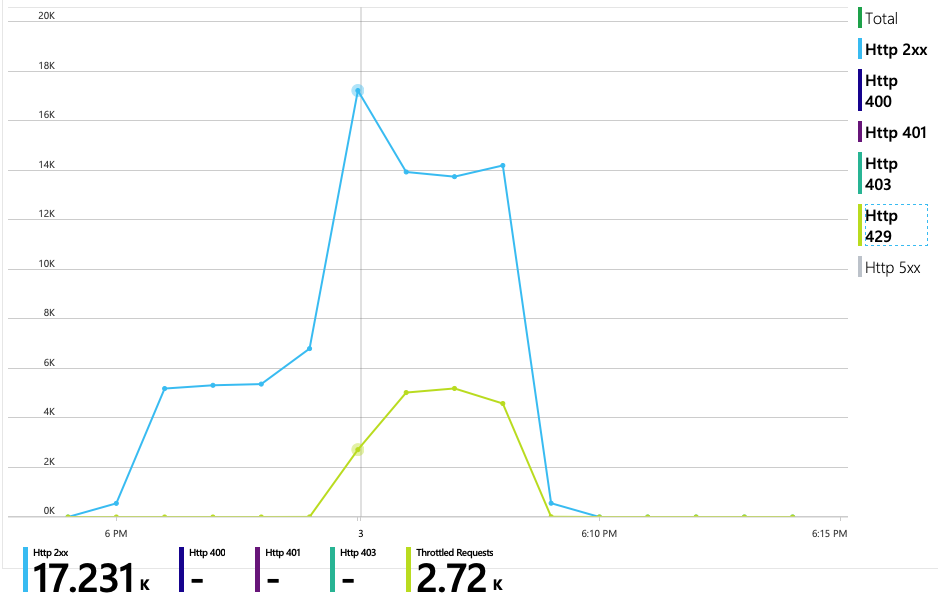
Aby uzyskać dalsze szczegółowe informacje, zespół programistyczny użył usługi Application Insights do wyświetlania kompleksowej telemetrii dla reprezentatywnej próbki żądań. Oto jedno wystąpienie:
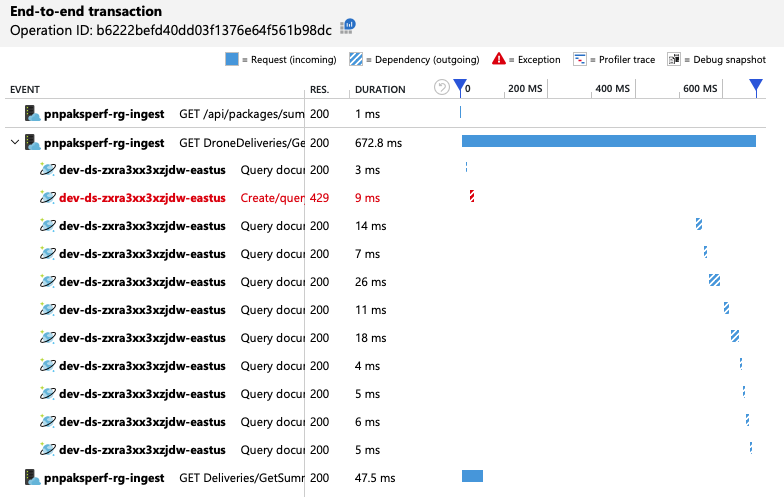
Ten widok przedstawia wywołania związane z pojedynczym żądaniem klienta wraz z informacjami o chronometrażu i kodami odpowiedzi. Wywołania najwyższego poziomu pochodzą z bramy do usług zaplecza. Wywołanie metody jest GetDroneUtilization rozwinięte w celu wyświetlania wywołań zależności zewnętrznych — w tym przypadku do usługi Azure Cosmos DB. Wywołanie w kolorze czerwonym zwróciło błąd HTTP 429.
Zwróć uwagę na dużą lukę między błędem HTTP 429 a następnym wywołaniem. Gdy biblioteka kliencka usługi Azure Cosmos DB otrzyma błąd HTTP 429, automatycznie cofnie się i czeka na ponowną próbę wykonania operacji. Ten widok pokazuje, że w ciągu 672 ms ta operacja zajęła większość czasu oczekiwania na ponowienie próby w usłudze Azure Cosmos DB.
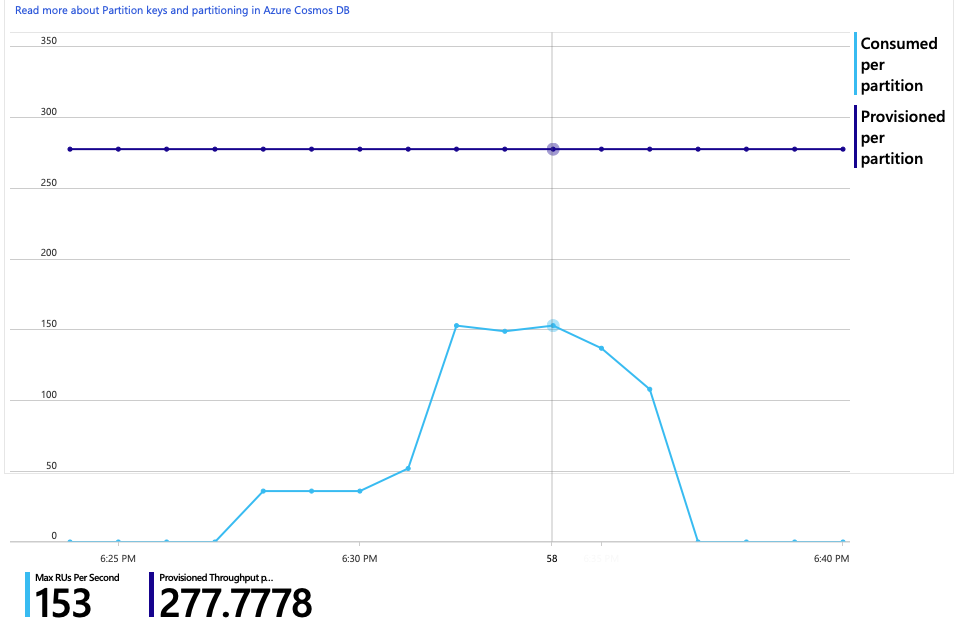
Oto kolejny interesujący wykres dla tej analizy. Pokazuje użycie jednostek RU na partycję fizyczną w porównaniu z aprowizowaną jednostkami RU na partycję fizyczną:
Aby zrozumieć ten wykres, musisz zrozumieć, jak usługa Azure Cosmos DB zarządza partycjami. Kolekcje w usłudze Azure Cosmos DB mogą mieć klucz partycji. Każda możliwa wartość klucza definiuje partycję logiczną danych w kolekcji. Usługa Azure Cosmos DB dystrybuuje te partycje logiczne na co najmniej jednej partycji fizycznej . Zarządzanie partycjami fizycznymi jest obsługiwane automatycznie przez usługę Azure Cosmos DB. W miarę przechowywania większej ilości danych usługa Azure Cosmos DB może przenosić partycje logiczne do nowych partycji fizycznych, aby rozłożyć obciążenie na partycje fizyczne.
Na potrzeby tego testu obciążeniowego kolekcja usługi Azure Cosmos DB została aprowizowana przy użyciu 900 jednostek RU. Wykres przedstawia 100 RU na partycję fizyczną, co oznacza łącznie dziewięć partycji fizycznych. Chociaż usługa Azure Cosmos DB automatycznie obsługuje fragmentowanie partycji fizycznych, wiedza o liczbie partycji może zapewnić wgląd w wydajność. Zespół deweloperów będzie później używać tych informacji, ponieważ będą nadal optymalizować. Jeśli niebieska linia przekracza fioletową linię poziomą, użycie jednostek RU przekroczyło aprowizowaną liczbę jednostek RU. Jest to punkt, w którym usługa Azure Cosmos DB zacznie ograniczać wywołania.
Test 2. Zwiększanie liczby jednostek zasobów
W przypadku drugiego testu obciążeniowego zespół przeskalował kolekcję usługi Azure Cosmos DB z 900 RU do 2500 RU. Przepływność wzrosła z 19 żądań/sekund do 23 żądań/sekund, a średnie opóźnienie spadło z 669 ms do 569 ms.
| Metric | Test 1 | Test 2 |
|---|---|---|
| Przepływność (req/s) | 19 | 23 |
| Średnie opóźnienie (ms) | 669 | 569 |
| Żądania zakończone powodzeniem | 9,8 K | 11 K |
Nie są to ogromne zyski, ale patrząc na wykres w czasie pokazuje bardziej kompletny obraz:
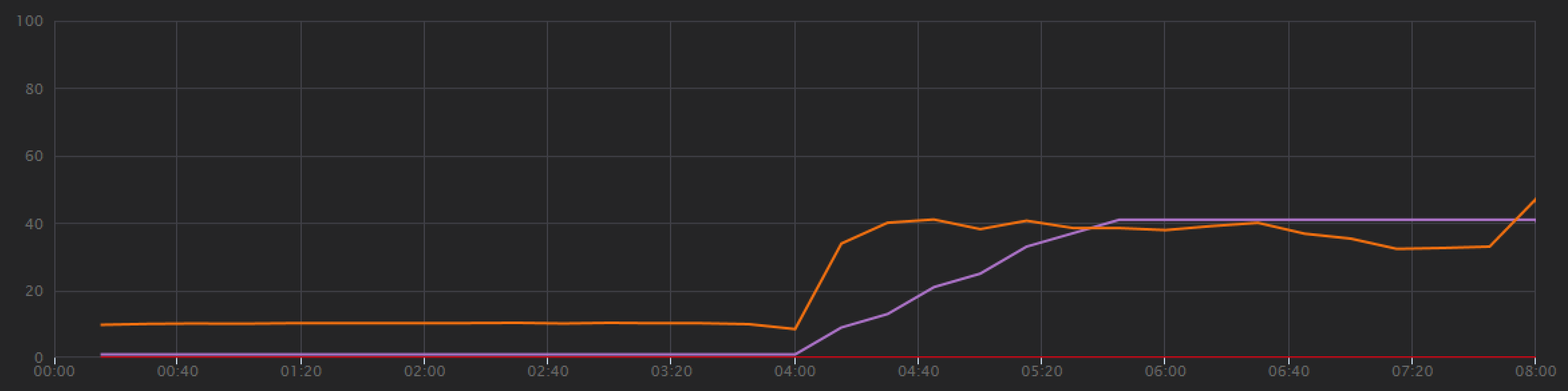
Podczas gdy poprzedni test wykazał początkowy wzrost po gwałtownym spadku, ten test pokazuje bardziej spójną przepływność. Maksymalna przepływność nie jest jednak znacznie wyższa.
Wszystkie żądania do usługi Azure Cosmos DB zwróciły stan 2xx, a błędy HTTP 429 zostały wycofane:
Wykres użycia jednostek RU w porównaniu z aprowizowaną jednostkami RU pokazuje, że istnieje mnóstwo miejsca na głowę. Istnieje około 275 jednostek RU na partycję fizyczną, a test obciążenia osiągnął około 100 jednostek RU zużywanych na sekundę.
Kolejną interesującą metryczką jest liczba wywołań do usługi Azure Cosmos DB na pomyślną operację:
| Metric | Test 1 | Test 2 |
|---|---|---|
| Wywołania na operację | 11 | 9 |
Przy założeniu, że liczba wywołań nie powinna być zgodna z rzeczywistym planem zapytania. W takim przypadku operacja obejmuje zapytanie obejmujące wiele partycji, które trafia do wszystkich dziewięciu partycji fizycznych. Wyższa wartość w pierwszym teście obciążeniowym odzwierciedla liczbę wywołań, które zwróciły błąd 429.
Ta metryka została obliczona przez uruchomienie niestandardowego zapytania usługi Log Analytics:
let start=datetime("2020-06-18T20:59:00.000Z");
let end=datetime("2020-07-24T21:10:00.000Z");
let operationNameToEval="GET DroneDeliveries/GetDroneUtilization";
let dependencyType="Azure DocumentDB";
let dataset=requests
| where timestamp > start and timestamp < end
| where success == true
| where name == operationNameToEval;
dataset
| project reqOk=itemCount
| summarize
SuccessRequests=sum(reqOk),
TotalNumberOfDepCalls=(toscalar(dependencies
| where timestamp > start and timestamp < end
| where type == dependencyType
| summarize sum(itemCount)))
| project
OperationName=operationNameToEval,
DependencyName=dependencyType,
SuccessRequests,
AverageNumberOfDepCallsPerOperation=(TotalNumberOfDepCalls/SuccessRequests)
Podsumowując, drugi test obciążeniowy pokazuje poprawę.
GetDroneUtilization Jednak operacja nadal trwa o rzędu wielkości dłużej niż najwolniejsza operacja. Spojrzenie na kompleksowe transakcje pomaga wyjaśnić, dlaczego:
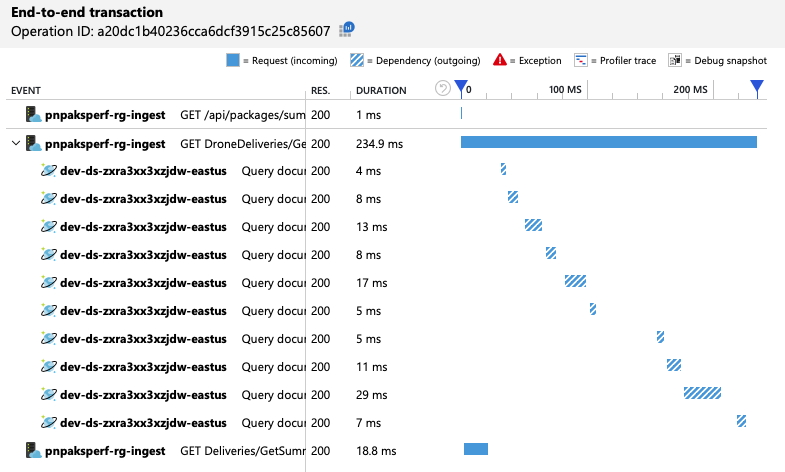
Jak wspomniano wcześniej, GetDroneUtilization operacja obejmuje zapytanie obejmujące wiele partycji do usługi Azure Cosmos DB. Oznacza to, że klient usługi Azure Cosmos DB musi wymyślić zapytanie do każdej partycji fizycznej i zebrać wyniki. W widoku kompleksowej transakcji te zapytania są wykonywane szeregowo. Operacja trwa tak długo, jak suma wszystkich zapytań — i ten problem będzie się pogarszać tylko w miarę wzrostu rozmiaru danych i dodawania większej liczby partycji fizycznych.
Test 3. Zapytania równoległe
Na podstawie poprzednich wyników oczywistym sposobem zmniejszenia opóźnienia jest równoległe wystawianie zapytań. Zestaw SDK klienta usługi Azure Cosmos DB ma ustawienie, które kontroluje maksymalny stopień równoległości.
| Wartość | Opis |
|---|---|
| 0 | Brak równoległości (wartość domyślna) |
| > 0 | Maksymalna liczba wywołań równoległych |
| -1 | Zestaw SDK klienta wybiera optymalny stopień równoległości |
W przypadku trzeciego testu obciążeniowego to ustawienie zostało zmienione z zakresu od 0 do -1. Poniższa tabela zawiera podsumowanie wyników:
| Metric | Test 1 | Test 2 | Test 3 |
|---|---|---|---|
| Przepływność (req/s) | 19 | 23 | 42 |
| Średnie opóźnienie (ms) | 669 | 569 | 215 |
| Żądania zakończone powodzeniem | 9,8 K | 11 K | 20 K |
| Żądania ograniczone | 2,72 K | 0 | 0 |
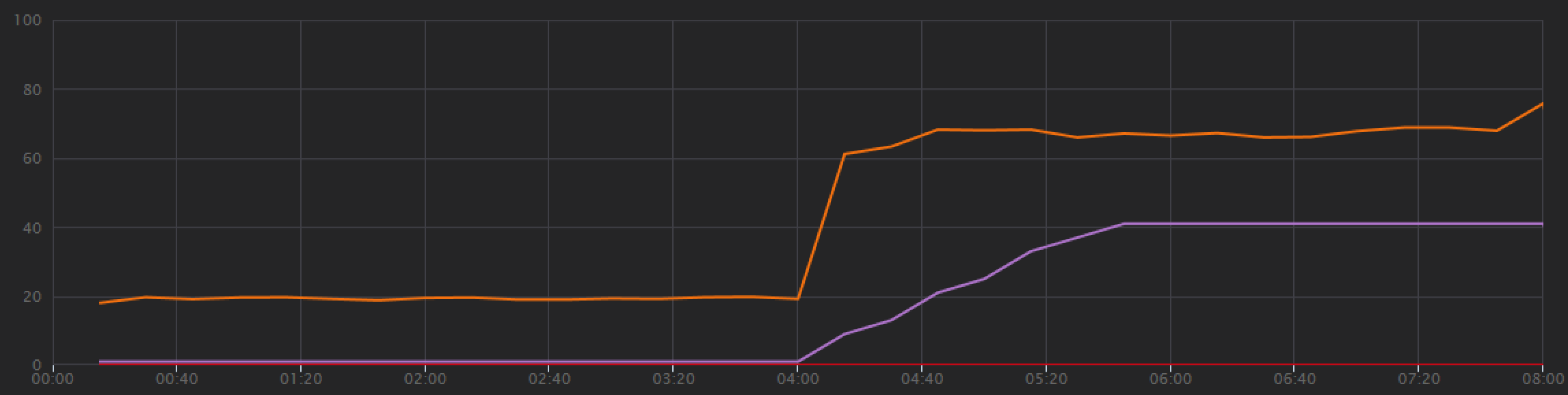
Na wykresie testu obciążeniowego nie tylko ogólna przepływność jest znacznie wyższa (pomarańczowa linia), ale przepływność utrzymuje również tempo z obciążeniem (fioletowa linia).
Możemy sprawdzić, czy klient usługi Azure Cosmos DB wykonuje zapytania równolegle, sprawdzając widok kompleksowej transakcji:
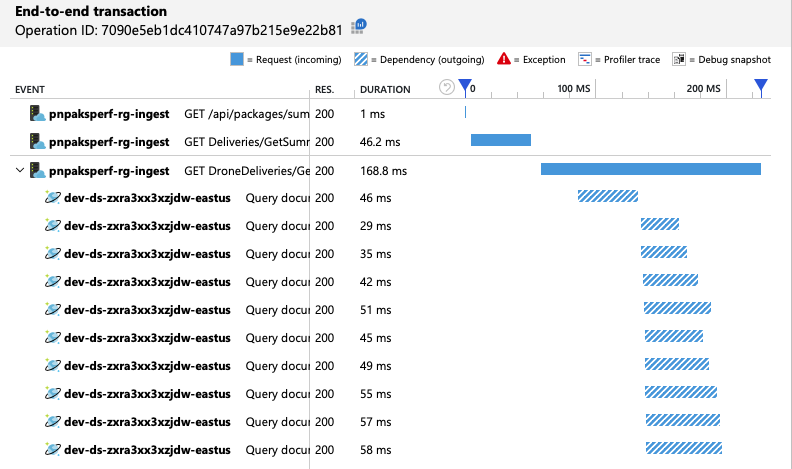
Co ciekawe, efekt uboczny zwiększenia przepływności polega na tym, że liczba jednostek RU zużywanych na sekundę również zwiększa się. Mimo że usługa Azure Cosmos DB nie ograniczała żadnych żądań podczas tego testu, użycie było zbliżone do aprowizowanego limitu jednostek RU:
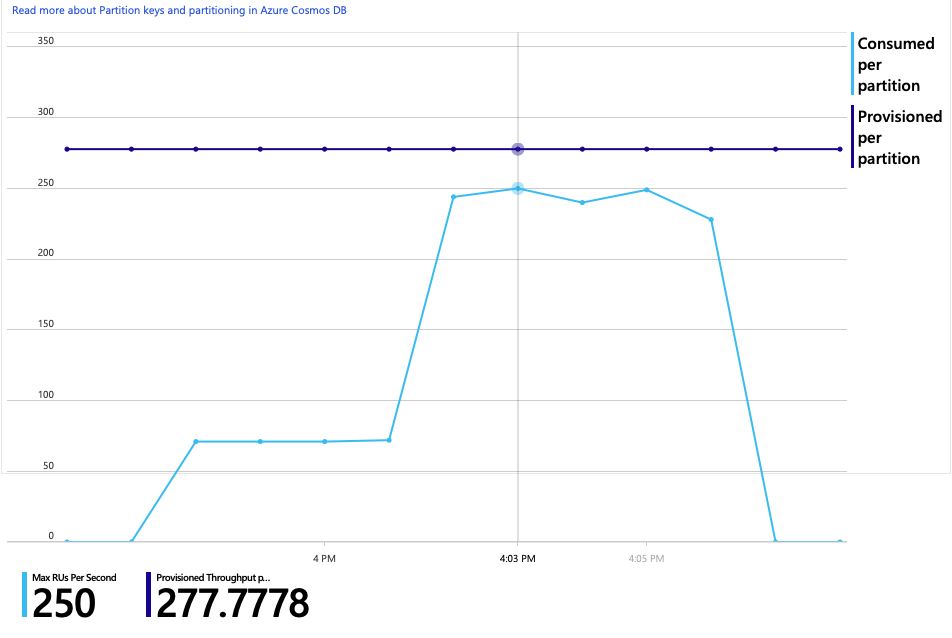
Ten graf może być sygnałem do dalszego skalowania bazy danych w poziomie. Okazuje się jednak, że możemy zamiast tego zoptymalizować zapytanie.
Krok 4. Optymalizowanie zapytania
Poprzedni test obciążeniowy wykazał lepszą wydajność pod względem opóźnienia i przepływności. Średnie opóźnienie żądań zostało zmniejszone o 68%, a przepływność wzrosła o 220%. Jednak zapytanie obejmujące wiele partycji jest problemem.
Problem z zapytaniami między partycjami polega na tym, że płacisz za jednostkę RU na każdej partycji. Jeśli zapytanie jest uruchamiane tylko od czasu do czasu — powiedzmy raz na godzinę — może nie mieć znaczenia. Jednak za każdym razem, gdy widzisz duże obciążenie odczytu, które obejmuje zapytanie obejmujące wiele partycji, należy sprawdzić, czy zapytanie można zoptymalizować, uwzględniając klucz partycji. (Może być konieczne przeprojektowanie kolekcji w celu użycia innego klucza partycji).
Oto zapytanie dotyczące tego konkretnego scenariusza:
SELECT * FROM c
WHERE c.ownerId = <ownerIdValue> and
c.year = <yearValue> and
c.month = <monthValue>
To zapytanie wybiera rekordy zgodne z określonym identyfikatorem właściciela i miesiącem/rokiem. W oryginalnym projekcie żadna z tych właściwości nie jest kluczem partycji. Wymaga to od klienta wypychania zapytania do każdej partycji fizycznej i zbierania wyników. Aby poprawić wydajność zapytań, zespół deweloperów zmienił projekt tak, aby identyfikator właściciela był kluczem partycji dla kolekcji. W ten sposób zapytanie może dotyczyć określonej partycji fizycznej. (Usługa Azure Cosmos DB obsługuje to automatycznie; nie trzeba zarządzać mapowaniem między wartościami klucza partycji i partycjami fizycznymi).
Po przełączeniu kolekcji na nowy klucz partycji nastąpiła dramatyczna poprawa zużycia jednostek RU, co przekłada się bezpośrednio na niższe koszty.
| Metric | Test 1 | Test 2 | Test 3 | Test 4 |
|---|---|---|---|---|
| Liczba jednostek RU na operację | 29 | 29 | 29 | 3.4 |
| Wywołania na operację | 11 | 9 | 10 | 1 |
Widok kompleksowej transakcji pokazuje, że zgodnie z przewidywaniami zapytanie odczytuje tylko jedną partycję fizyczną:
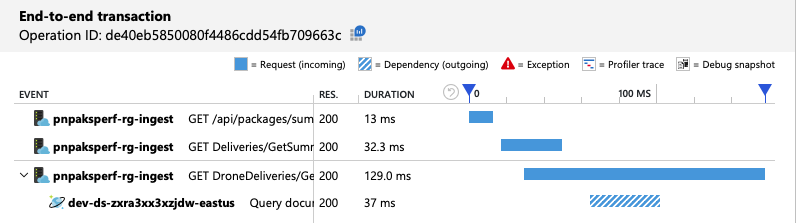
Test obciążeniowy pokazuje zwiększoną przepływność i opóźnienie:
| Metric | Test 1 | Test 2 | Test 3 | Test 4 |
|---|---|---|---|---|
| Przepływność (req/s) | 19 | 23 | 42 | 59 |
| Średnie opóźnienie (ms) | 669 | 569 | 215 | 176 |
| Żądania zakończone powodzeniem | 9,8 K | 11 K | 20 K | 29 K |
| Żądania ograniczone | 2,72 K | 0 | 0 | 0 |
Konsekwencją poprawy wydajności jest to, że wykorzystanie procesora CPU węzła staje się bardzo wysokie:
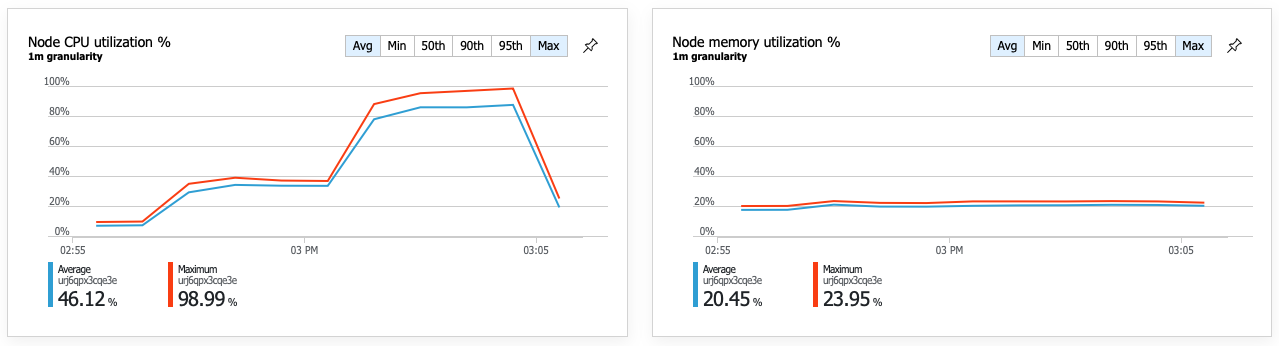
Pod koniec testu obciążeniowego średni procesor osiągnął około 90%, a maksymalny procesor osiągnął 100%. Ta metryka wskazuje, że procesor CPU jest kolejnym wąskim gardłem w systemie. Jeśli potrzebna jest większa przepływność, następnym krokiem może być skalowanie usługi dostarczania do większej liczby wystąpień.
Podsumowanie
W tym scenariuszu zidentyfikowano następujące wąskie gardła:
- Żądania ograniczania przepustowości usługi Azure Cosmos DB z powodu niewystarczającej liczby aprowizowania jednostek RU.
- Duże opóźnienie spowodowane wykonywaniem zapytań dotyczących wielu partycji bazy danych w szeregowych.
- Nieefektywne zapytanie obejmujące wiele partycji, ponieważ kwerenda nie zawierała klucza partycji.
Ponadto wykorzystanie procesora CPU zostało zidentyfikowane jako potencjalne wąskie gardło na większą skalę. Aby zdiagnozować te problemy, zespół programistyczny przejrzał:
- Opóźnienie i przepływność z testu obciążeniowego.
- Błędy usługi Azure Cosmos DB i użycie jednostek RU.
- Widok kompleksowej transakcji w usłudze Application Insights.
- Wykorzystanie procesora CPU i pamięci w szczegółowych informacji o kontenerze usługi Azure Monitor.
Następne kroki
Przegląd antywzorzeców wydajności