Wzorzec konfiguracji obciążenia brzegowego
Duża różnorodność systemów i urządzeń na hali sklepowej może utrudnić konfigurację obciążenia. Ten artykuł zawiera podejścia do jego rozwiązywania.
Kontekst i problem
Firmy produkcyjne, w ramach ich cyfrowej transformacji, koncentrują się coraz częściej na tworzeniu rozwiązań oprogramowania, które mogą być ponownie używane jako udostępnione możliwości. Ze względu na różnorodność urządzeń i systemów na hali produkcyjnej obciążenia modułowe są skonfigurowane do obsługi różnych protokołów, sterowników i formatów danych. Czasami nawet wiele wystąpień obciążenia jest uruchamianych z różnymi konfiguracjami w tej samej lokalizacji brzegowej. W przypadku niektórych obciążeń konfiguracje są aktualizowane więcej niż raz dziennie. W związku z tym zarządzanie konfiguracją jest coraz ważniejsze dla skalowania rozwiązań brzegowych.
Rozwiązanie
Istnieje kilka typowych cech zarządzania konfiguracją dla obciążeń brzegowych:
- Istnieje kilka punktów konfiguracji, które można zgrupować w różnych warstwach, takich jak źródło oprogramowania, potok ciągłej integracji/ciągłego wdrażania, dzierżawa chmury i lokalizacja brzegowa:
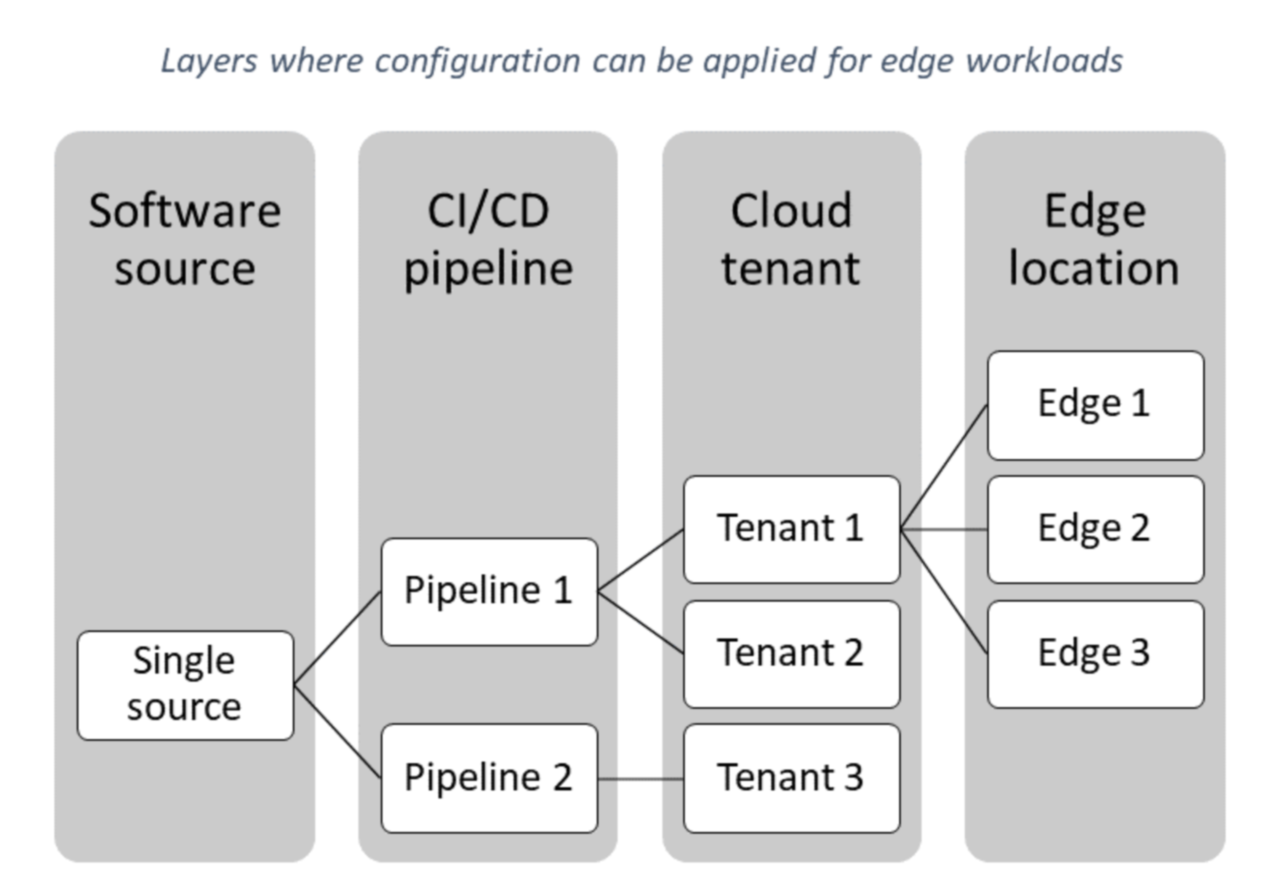
- Różne warstwy mogą być aktualizowane przez różne osoby.
- Niezależnie od sposobu aktualizowania konfiguracji, muszą być dokładnie śledzone i poddawane inspekcji.
- W celu zapewnienia ciągłości działania wymagana jest możliwość uzyskania dostępu do konfiguracji w trybie offline na brzegu sieci.
- Jest również wymagany globalny widok konfiguracji dostępnych w chmurze.
Problemy i kwestie do rozważenia
Podczas podejmowania decyzji o sposobie wdrożenia tego wzorca należy rozważyć następujące punkty:
- Zezwalanie na edycję, gdy krawędź nie jest połączona z chmurą, znacznie zwiększa złożoność zarządzania konfiguracją. Istnieje możliwość replikowania zmian w chmurze, ale istnieją wyzwania związane z:
- Uwierzytelnianie użytkownika, ponieważ opiera się na usłudze w chmurze, takiej jak Microsoft Entra ID.
- Rozwiązywanie konfliktów po ponownym połączeniu, jeśli obciążenia otrzymują nieoczekiwane konfiguracje wymagające interwencji ręcznej.
- Środowisko brzegowe może mieć ograniczenia związane z siecią, jeśli topologia spełnia wymagania ISA-95. Takie ograniczenia można przezwyciężyć, wybierając technologię, która oferuje łączność między warstwami, takimi jak hierarchie urządzeń w usłudze Azure IoT Edge.
- Jeśli konfiguracja w czasie wykonywania jest oddzielona od wersji oprogramowania, zmiany konfiguracji muszą być obsługiwane oddzielnie. Aby oferować funkcje historii i wycofywania, należy przechowywać wcześniejsze konfiguracje w magazynie danych w chmurze.
- Błąd w konfiguracji, taki jak składnik łączności skonfigurowany do nieistniejących punktów końcowych, może przerwać obciążenie. W związku z tym ważne jest traktowanie zmian konfiguracji w miarę traktowania innych zdarzeń cyklu życia wdrożenia w rozwiązaniu do obserwacji, dzięki czemu pulpity nawigacyjne z obserwacją mogą pomóc skorelować błędy systemowe ze zmianami konfiguracji. Aby uzyskać więcej informacji na temat obserwacji, zobacz Przewodnik monitorowania chmury: Obserwowanie.
- Poznaj role, które magazyny danych w chmurze i brzegowych odgrywają w ciągłości działania firmy. Jeśli magazyn danych w chmurze jest pojedynczym źródłem prawdy, obciążenia brzegowe powinny być w stanie przywrócić zamierzone stany przy użyciu zautomatyzowanych procesów.
- W celu zapewnienia odporności magazyn danych brzegowych powinien działać jako pamięć podręczna w trybie offline. Ma to pierwszeństwo przed zagadnieniami dotyczącymi opóźnień.
Kiedy używać tego wzorca
Użyj tego wzorca, gdy:
- Istnieje wymóg konfigurowania obciążeń poza cyklem wydawania oprogramowania.
- Różne osoby muszą mieć możliwość odczytywania i aktualizowania konfiguracji.
- Konfiguracje muszą być dostępne, nawet jeśli nie ma połączenia z chmurą.
Przykładowe obciążenia:
- Rozwiązania łączące się z elementami zawartości na hali sklepowej w celu pozyskiwania danych — na przykład wydawcy OPC — oraz poleceń i kontroli
- Obciążenia uczenia maszynowego na potrzeby konserwacji predykcyjnej
- Obciążenia uczenia maszynowego, które sprawdzają w czasie rzeczywistym pod kątem jakości na linii produkcyjnej
Przykłady
Rozwiązanie do konfigurowania obciążeń brzegowych w czasie wykonywania może być oparte na zewnętrznym kontrolerze konfiguracji lub wewnętrznym dostawcy konfiguracji.
Odmiana zewnętrznego kontrolera konfiguracji
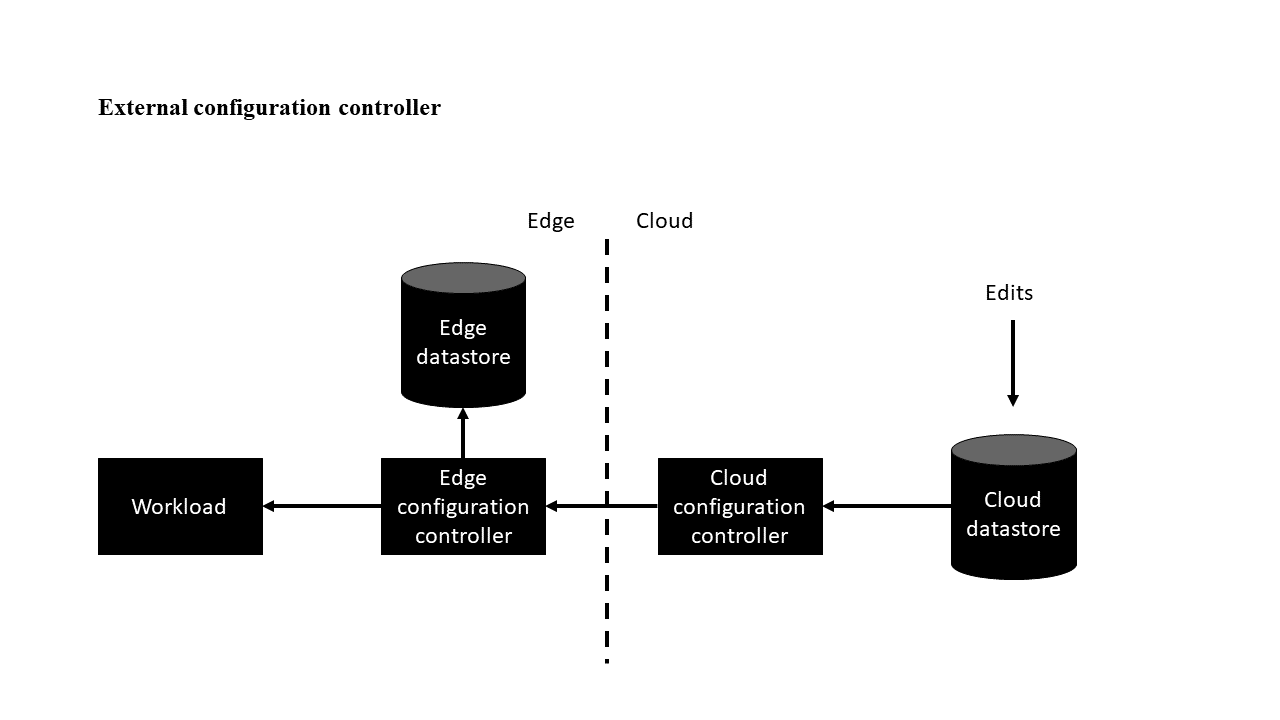
Ta odmiana ma kontroler konfiguracji, który jest zewnętrzny dla obciążenia. Rolą składnika kontrolera konfiguracji chmury jest wypychanie edycji z magazynu danych w chmurze do obciążenia za pośrednictwem kontrolera konfiguracji brzegowej. Krawędź zawiera również magazyn danych, dzięki czemu system działa nawet po odłączeniu od chmury.
W usłudze IoT Edge kontroler konfiguracji krawędzi można zaimplementować jako moduł, a konfiguracje można stosować z bliźniaczymi reprezentacjami modułów. Bliźniacze reprezentacje modułu mają limit rozmiaru; jeśli konfiguracja przekroczy limit, rozwiązanie można rozszerzyć za pomocą usługi Azure Blob Storage lub fragmentując większe ładunki za pośrednictwem metod bezpośrednich.
Zalety tej odmiany to:
- Samo obciążenie nie musi być świadome systemu konfiguracji. Ta funkcja jest wymagana, jeśli kod źródłowy obciążenia nie jest edytowalny — na przykład w przypadku korzystania z modułu z witryny Azure IoT Edge Marketplace.
- Można jednocześnie zmienić konfigurację wielu obciążeń, koordynując zmiany za pośrednictwem kontrolera konfiguracji chmury.
- Dodatkową walidację można zaimplementować w ramach potoku wypychania — na przykład w celu zweryfikowania istnienia punktów końcowych na brzegu przed wypchnięciem konfiguracji do obciążenia.
Odmiana wewnętrznego dostawcy konfiguracji
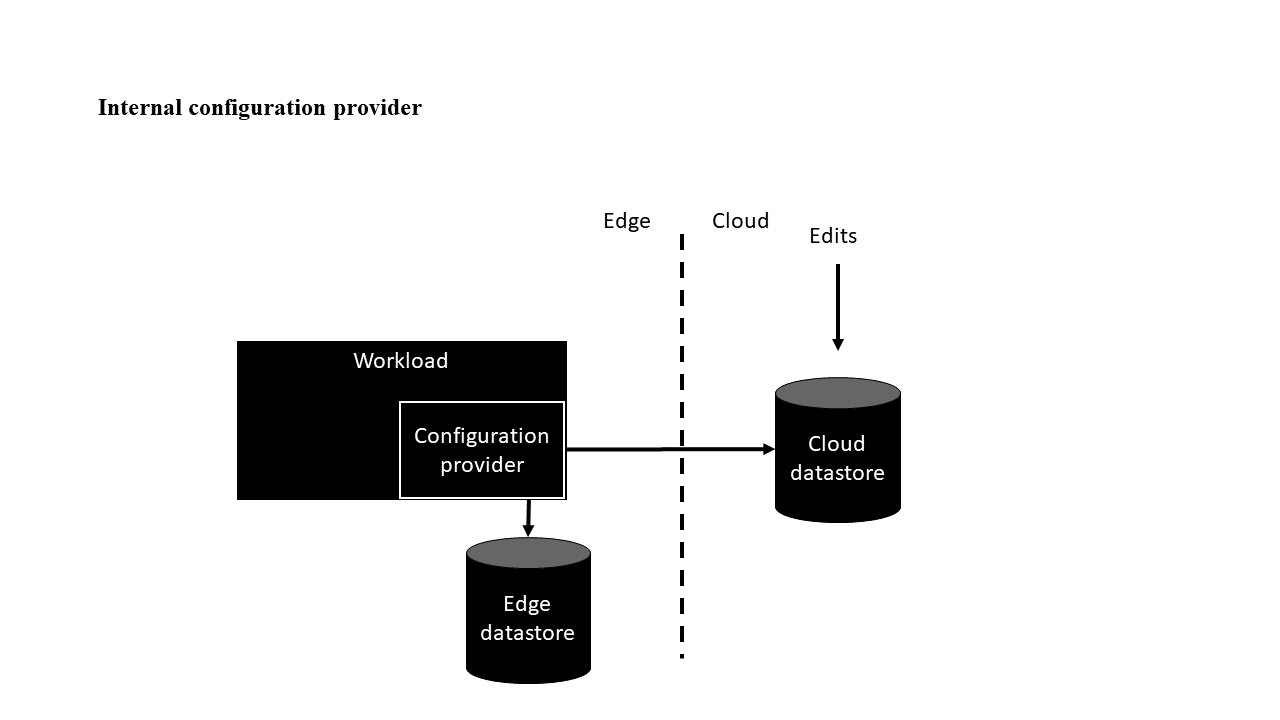
W odmianie wewnętrznego dostawcy konfiguracji obciążenie pobiera konfiguracje od dostawcy konfiguracji. Aby zapoznać się z przykładem implementacji, zobacz Implementowanie niestandardowego dostawcy konfiguracji na platformie .NET. W tym przykładzie użyto języka C#, ale można użyć innych języków.
W tej odmianie obciążenia mają unikatowe identyfikatory, dzięki czemu ten sam kod źródłowy działający w różnych środowiskach może mieć różne konfiguracje. Jednym ze sposobów konstruowania identyfikatora jest połączenie hierarchicznej relacji obciążenia z grupowaniem najwyższego poziomu, takim jak dzierżawa. W przypadku usługi IoT Edge może to być kombinacja grupy zasobów platformy Azure, nazwy centrum IoT, nazwy urządzenia usługi IoT Edge i identyfikatora modułu. Te wartości tworzą unikatowy identyfikator, który działa jako klucz w magazynach danych.
Mimo że do unikatowego identyfikatora można dodać wersję modułu, często wymagane jest utrwalanie konfiguracji w ramach aktualizacji oprogramowania. Jeśli wersja jest częścią identyfikatora, stara wersja konfiguracji powinna zostać zmigrowana do przodu z dodatkową implementacją.
Zalety tej odmiany to:
- Inne niż magazyny danych rozwiązanie nie wymaga składników, co zmniejsza złożoność.
- Logika migracji z niezgodnych starych wersji może być obsługiwana w ramach implementacji obciążenia.
Rozwiązania oparte na usłudze IoT Edge
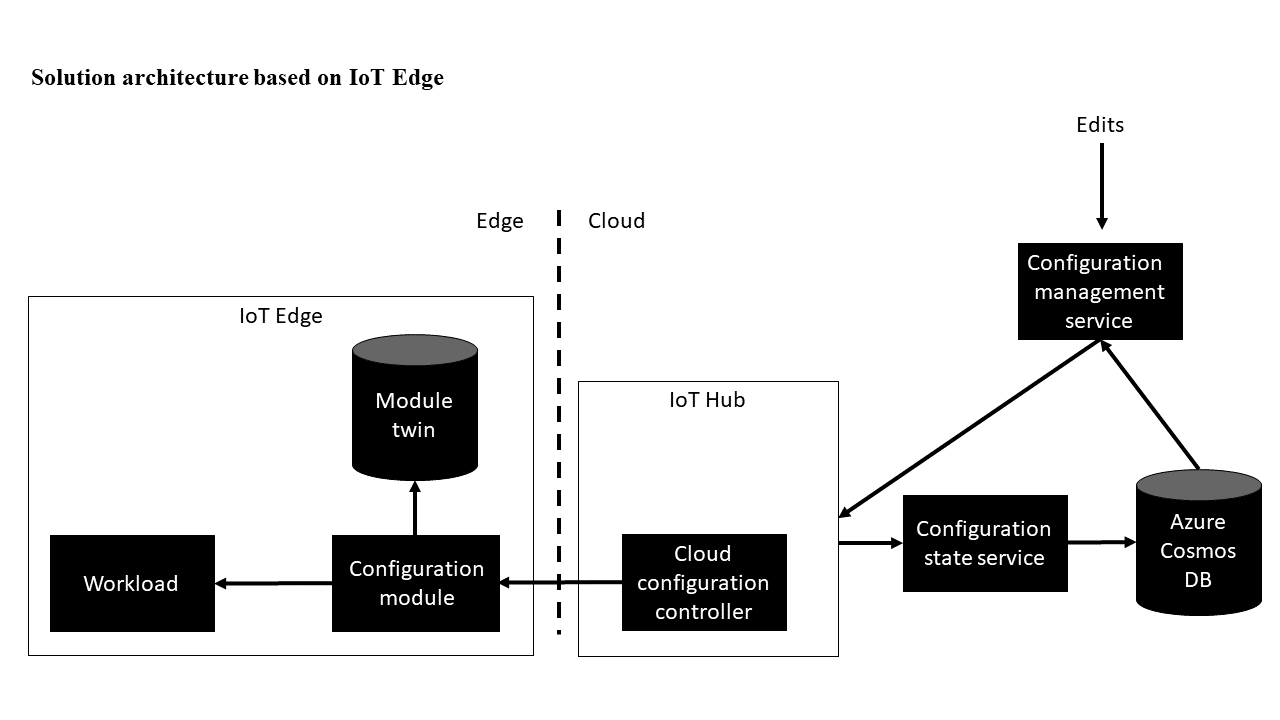
Składnik chmury implementacji referencyjnej usługi IoT Edge składa się z centrum IoT Działającego jako kontroler konfiguracji chmury. Funkcja bliźniaczej reprezentacji modułu usługi Azure IoT Hub propaguje zmiany konfiguracji i informacje o aktualnie stosowanej konfiguracji przy użyciu żądanych i zgłoszonych właściwości bliźniaczej reprezentacji modułu. Usługa zarządzania konfiguracją działa jako źródło konfiguracji. Może to być również interfejs użytkownika do zarządzania konfiguracjami, systemem kompilacji i innymi narzędziami używanymi do tworzenia konfiguracji obciążeń.
Baza danych usługi Azure Cosmos DB przechowuje wszystkie konfiguracje. Może ona współdziałać z wieloma centrami IoT i zapewnia historię konfiguracji.
Gdy urządzenie brzegowe wskaże za pośrednictwem zgłoszonych właściwości, które zostały zastosowane, usługa stanu konfiguracji zanotuje zdarzenie w wystąpieniu bazy danych.
Po utworzeniu nowej konfiguracji w usłudze zarządzania konfiguracją jest ona przechowywana w usłudze Azure Cosmos DB, a żądane właściwości modułu brzegowego zostaną zmienione w centrum IoT, w którym znajduje się urządzenie. Konfiguracja jest następnie przesyłana przez usługę IoT Hub do urządzenia brzegowego. Oczekuje się, że moduł brzegowy zastosuje konfigurację i raport za pośrednictwem bliźniaczej reprezentacji modułu stanu konfiguracji. Następnie usługa stanu konfiguracji nasłuchuje zdarzeń zmiany reprezentacji bliźniaczej, a po wykryciu, że moduł zgłasza zmianę stanu konfiguracji, rejestruje odpowiednią zmianę w bazie danych usługi Azure Cosmos DB.
Składnik brzegowy może używać zewnętrznego kontrolera konfiguracji lub wewnętrznego dostawcy konfiguracji. W obu implementacjach konfiguracja jest przesyłana we żądanych właściwościach bliźniaczej reprezentacji modułu lub w przypadku konieczności przesyłania dużych konfiguracji żądane właściwości bliźniaczej reprezentacji modułu zawierają adres URL do usługi Azure Blob Storage lub do innej usługi, która może służyć do pobierania konfiguracji. Następnie moduł sygnalizuje w bliźniaczej reprezentacji modułu właściwości, czy nowa konfiguracja została zastosowana pomyślnie i jaka konfiguracja jest obecnie stosowana.
Współautorzy
Ten artykuł jest obsługiwany przez firmę Microsoft. Pierwotnie został napisany przez następujących współautorów.
Główny autor:
- Heather Camm | Starszy menedżer programu
Aby wyświetlić niepubalne profile serwisu LinkedIn, zaloguj się do serwisu LinkedIn.
Następne kroki
- Azure IoT Edge
- Co to jest usługa Azure IoT Edge?
- Azure IoT Hub
- Pojęcia dotyczące IoT i usługa Azure IoT Hub
- Azure Cosmos DB
- Azure Cosmos DB — Zapraszamy!
- Azure Blob Storage
- Wprowadzenie do usługi Azure Blob Storage