Sprawdzanie kondycji węzła i zasobnika
Ten artykuł jest częścią serii. Zacznij od omówienia.
Jeśli klaster sprawdzi, czy został wykonany w poprzednim kroku, sprawdź kondycję węzłów roboczych usługi Azure Kubernetes Service (AKS). Wykonaj sześć kroków w tym artykule, aby sprawdzić kondycję węzłów, określić przyczynę złej kondycji węzła i rozwiązać problem.
Krok 1. Sprawdzanie kondycji węzłów procesu roboczego
Różne czynniki mogą mieć wpływ na węzły w złej kondycji w klastrze usługi AKS. Jedną z typowych przyczyn jest podział komunikacji między płaszczyzną sterowania a węzłami. Ta błędna komunikacja jest często spowodowana błędami konfiguracji w regułach routingu i zapory.
Podczas konfigurowania klastra usługi AKS na potrzeby routingu zdefiniowanego przez użytkownika należy skonfigurować ścieżki ruchu wychodzącego za pośrednictwem wirtualnego urządzenia sieciowego (WUS) lub zapory, takiej jak zapora platformy Azure. Aby rozwiązać problem z błędną konfiguracją, zalecamy skonfigurowanie zapory tak, aby zezwalała na niezbędne porty i w pełni kwalifikowane nazwy domen (FQDN) zgodnie ze wskazówkami dotyczącymi ruchu wychodzącego usługi AKS.
Innym powodem złej kondycji węzłów może być niewystarczająca ilość zasobów obliczeniowych, pamięci lub magazynu, które tworzą obciążenia kubeletu. W takich przypadkach skalowanie zasobów w górę może skutecznie rozwiązać problem.
W prywatnym klastrze usługi AKS problemy z rozpoznawaniem nazw domen (DNS) mogą powodować problemy z komunikacją między płaszczyzną sterowania a węzłami. Należy sprawdzić, czy nazwa DNS serwera interfejsu API Kubernetes jest rozpoznawana jako prywatny adres IP serwera interfejsu API. Nieprawidłowa konfiguracja niestandardowego serwera DNS jest częstą przyczyną błędów rozpoznawania nazw DNS. Jeśli używasz niestandardowych serwerów DNS, upewnij się, że poprawnie określisz je jako serwery DNS w sieci wirtualnej, w której są aprowidowane węzły. Upewnij się również, że prywatny serwer interfejsu API usługi AKS można rozpoznać za pośrednictwem niestandardowego serwera DNS.
Po rozwiązaniu tych potencjalnych problemów związanych z komunikacją płaszczyzny sterowania i rozpoznawaniem nazw DNS można skutecznie rozwiązać problemy z kondycją węzła w klastrze usługi AKS.
Kondycję węzłów można ocenić przy użyciu jednej z następujących metod.
Widok kondycji kontenerów usługi Azure Monitor
Aby wyświetlić kondycję węzłów, zasobników użytkownika i zasobników systemowych w klastrze usługi AKS, wykonaj następujące kroki:
- W witrynie Azure Portal przejdź do usługi Azure Monitor.
- W sekcji Szczegółowe informacje okienka nawigacji wybierz pozycję Kontenery.
- Wybierz pozycję Monitorowane klastry , aby uzyskać listę monitorowanych klastrów usługi AKS.
- Wybierz klaster usługi AKS z listy, aby wyświetlić kondycję węzłów, zasobników użytkownika i zasobników systemowych.

Widok węzłów usługi AKS
Aby upewnić się, że wszystkie węzły w klastrze usługi AKS są w stanie gotowości, wykonaj następujące kroki:
- W witrynie Azure Portal przejdź do klastra usługi AKS.
- W sekcji Ustawienia okienka nawigacji wybierz pozycję Pule węzłów.
- Wybierz pozycję Węzły.
- Sprawdź, czy wszystkie węzły są w stanie gotowości.

Monitorowanie w klastrze za pomocą rozwiązań Prometheus i Grafana
Jeśli wdrożono rozwiązanie Prometheus i Grafana w klastrze usługi AKS, możesz użyć pulpitu nawigacyjnego szczegółów klastra K8, aby uzyskać szczegółowe informacje. Ten pulpit nawigacyjny przedstawia metryki klastra Prometheus i przedstawia istotne informacje, takie jak użycie procesora CPU, użycie pamięci, aktywność sieciowa i użycie systemu plików. Przedstawia również szczegółowe statystyki poszczególnych zasobników, kontenerów i usług systemowych .
Na pulpicie nawigacyjnym wybierz pozycję Warunki węzła, aby wyświetlić metryki dotyczące kondycji i wydajności klastra. Można śledzić węzły, które mogą mieć problemy, takie jak problemy z harmonogramem, siecią, ciśnieniem dysku, ciśnieniem pamięci, proporcjonalnym ciśnieniem pochodnym (PID) lub miejscem na dysku. Monitoruj te metryki, aby proaktywnie identyfikować i rozwiązywać wszelkie potencjalne problemy wpływające na dostępność i wydajność klastra usługi AKS.

Monitorowanie usługi zarządzanej dla rozwiązań Prometheus i Azure Managed Grafana
Do wizualizacji i analizowania metryk rozwiązania Prometheus można użyć wstępnie utworzonych pulpitów nawigacyjnych. W tym celu należy skonfigurować klaster usługi AKS w celu zbierania metryk rozwiązania Prometheus w usłudze zarządzanej Monitor dla rozwiązania Prometheus i połączyć obszar roboczy Monitor z obszarem roboczym usługi Azure Managed Grafana . Te pulpity nawigacyjne zapewniają kompleksowy widok wydajności i kondycji klastra Kubernetes.
Pulpity nawigacyjne są aprowidowane w określonym wystąpieniu usługi Azure Managed Grafana w folderze Managed Prometheus . Niektóre pulpity nawigacyjne obejmują:
- Kubernetes / Zasoby obliczeniowe / Klaster
- Kubernetes / Zasoby obliczeniowe / przestrzeń nazw (zasobniki)
- Kubernetes / Zasoby obliczeniowe / Węzeł (zasobniki)
- Kubernetes / Zasoby obliczeniowe / Zasobnik
- Kubernetes / Zasoby obliczeniowe / przestrzeń nazw (obciążenia)
- Kubernetes / Zasoby obliczeniowe / Obciążenie
- Kubernetes / Kubelet
- Eksporter węzła / METODA USE / Node
- Eksporter węzłów/węzły
- Kubernetes / Zasoby obliczeniowe / Klaster (Windows)
- Kubernetes / Zasoby obliczeniowe / przestrzeń nazw (Windows)
- Kubernetes / Zasoby obliczeniowe / Zasobnik (Windows)
- Kubernetes / USE, metoda / klaster (Windows)
- Kubernetes / USE, metoda / Node (Windows)
Te wbudowane pulpity nawigacyjne są szeroko używane w społeczności open source do monitorowania klastrów Kubernetes za pomocą rozwiązania Prometheus i Grafana. Użyj tych pulpitów nawigacyjnych, aby wyświetlić metryki, takie jak użycie zasobów, kondycja zasobnika i aktywność sieci. Możesz również tworzyć niestandardowe pulpity nawigacyjne dostosowane do potrzeb monitorowania. Pulpity nawigacyjne ułatwiają efektywne monitorowanie i analizowanie metryk rozwiązania Prometheus w klastrze usługi AKS, co umożliwia optymalizowanie wydajności, rozwiązywanie problemów i zapewnienie bezproblemowego działania obciążeń Kubernetes.
Aby wyświetlić metryki dla węzłów agenta systemu Linux, możesz użyć pulpitu nawigacyjnego Kubernetes/Compute Resources/Node (Zasobniki obliczeniowe ). Możesz wizualizować użycie procesora CPU, limit przydziału procesora CPU, użycie pamięci i limit przydziału pamięci dla każdego zasobnika.

Jeśli klaster zawiera węzły agenta systemu Windows, możesz użyć pulpitu nawigacyjnego Kubernetes / USE Method / Node (Windows) w celu wizualizacji metryk Rozwiązania Prometheus zebranych z tych węzłów. Ten pulpit nawigacyjny zapewnia kompleksowy widok zużycia zasobów i wydajności dla węzłów systemu Windows w klastrze.
Skorzystaj z tych dedykowanych pulpitów nawigacyjnych, aby można było łatwo monitorować i analizować ważne metryki związane z procesorem CPU, pamięcią i innymi zasobami w węzłach agenta systemu Linux i Windows. Ta widoczność pozwala zidentyfikować potencjalne wąskie gardła, zoptymalizować alokację zasobów i zapewnić wydajną operację w klastrze usługi AKS.
Krok 2. Weryfikowanie łączności płaszczyzny sterowania i węzła roboczego
Jeśli węzły procesu roboczego są w dobrej kondycji, należy zbadać łączność między zarządzaną płaszczyzną sterowania usługi AKS a węzłami procesu roboczego klastra. Usługa AKS umożliwia komunikację między serwerem interfejsu API Kubernetes i pojedynczym węzłem kubelets za pośrednictwem bezpiecznej metody komunikacji tunelu. Te składniki mogą komunikować się nawet wtedy, gdy są w różnych sieciach wirtualnych. Tunel jest chroniony za pomocą szyfrowania mutual Transport Layer Security (mTLS). Podstawowy tunel używany przez usługę AKS nosi nazwę Konnectivity (wcześniej znany jako apiserver-network-proxy). Upewnij się, że wszystkie reguły sieci i nazwy FQDN są zgodne z wymaganymi regułami sieci platformy Azure.
Aby sprawdzić łączność między zarządzaną płaszczyzną sterowania usługi AKS a węzłami procesu roboczego klastra usługi AKS, możesz użyć narzędzia wiersza polecenia kubectl .
Aby upewnić się, że zasobniki agenta konnectivity działają prawidłowo, uruchom następujące polecenie:
kubectl get deploy konnectivity-agent -n kube-system
Upewnij się, że zasobniki są w stanie gotowości.
Jeśli występuje problem z łącznością między płaszczyzną sterowania a węzłami procesu roboczego, ustanów łączność po upewnieniu się, że wymagane reguły ruchu wychodzącego usługi AKS są dozwolone.
Uruchom następujące polecenie, aby ponownie uruchomić konnectivity-agent zasobniki:
kubectl rollout restart deploy konnectivity-agent -n kube-system
Jeśli ponowne uruchomienie zasobników nie rozwiąże problemu z połączeniem, sprawdź dzienniki pod kątem żadnych anomalii. Uruchom następujące polecenie, aby wyświetlić dzienniki konnectivity-agent zasobników:
kubectl logs -l app=konnectivity-agent -n kube-system --tail=50
Dzienniki powinny zawierać następujące dane wyjściowe:
I1012 12:27:43.521795 1 options.go:102] AgentCert set to "/certs/client.crt".
I1012 12:27:43.521831 1 options.go:103] AgentKey set to "/certs/client.key".
I1012 12:27:43.521834 1 options.go:104] CACert set to "/certs/ca.crt".
I1012 12:27:43.521837 1 options.go:105] ProxyServerHost set to "sethaks-47983508.hcp.switzerlandnorth.azmk8s.io".
I1012 12:27:43.521841 1 options.go:106] ProxyServerPort set to 443.
I1012 12:27:43.521844 1 options.go:107] ALPNProtos set to [konnectivity].
I1012 12:27:43.521851 1 options.go:108] HealthServerHost set to
I1012 12:27:43.521948 1 options.go:109] HealthServerPort set to 8082.
I1012 12:27:43.521956 1 options.go:110] AdminServerPort set to 8094.
I1012 12:27:43.521959 1 options.go:111] EnableProfiling set to false.
I1012 12:27:43.521962 1 options.go:112] EnableContentionProfiling set to false.
I1012 12:27:43.521965 1 options.go:113] AgentID set to b7f3182c-995e-4364-aa0a-d569084244e4.
I1012 12:27:43.521967 1 options.go:114] SyncInterval set to 1s.
I1012 12:27:43.521972 1 options.go:115] ProbeInterval set to 1s.
I1012 12:27:43.521980 1 options.go:116] SyncIntervalCap set to 10s.
I1012 12:27:43.522020 1 options.go:117] Keepalive time set to 30s.
I1012 12:27:43.522042 1 options.go:118] ServiceAccountTokenPath set to "".
I1012 12:27:43.522059 1 options.go:119] AgentIdentifiers set to .
I1012 12:27:43.522083 1 options.go:120] WarnOnChannelLimit set to false.
I1012 12:27:43.522104 1 options.go:121] SyncForever set to false.
I1012 12:27:43.567902 1 client.go:255] "Connect to" server="e9df3653-9bd4-4b09-b1a7-261f6104f5d0"
Uwaga
Po skonfigurowaniu klastra usługi AKS przy użyciu integracji sieci wirtualnej serwera interfejsu API oraz interfejsu sieciowego kontenera platformy Azure (CNI) lub interfejsu CNI platformy Azure z dynamicznym przypisaniem adresu IP zasobnika nie trzeba wdrażać agentów Konnectivity. Zintegrowane zasobniki serwera interfejsu API mogą ustanowić bezpośrednią komunikację z węzłami procesu roboczego klastra za pośrednictwem sieci prywatnej.
Jednak w przypadku korzystania z integracji sieci wirtualnej serwera interfejsu API z nakładką usługi Azure CNI lub używania własnego interfejsu CNI (BYOCNI) usługa Konnectivity jest wdrażana w celu ułatwienia komunikacji między serwerami interfejsu API i adresami IP zasobników. Komunikacja między serwerami interfejsu API a węzłami procesu roboczego pozostaje bezpośrednia.
Możesz również przeszukać dzienniki kontenera w usłudze rejestrowania i monitorowania, aby pobrać dzienniki. Aby zapoznać się z przykładem, który wyszukuje błędy łączności usługi aks-link , zobacz Wykonywanie zapytań dotyczących dzienników ze szczegółowych informacji o kontenerze.
Uruchom następujące zapytanie, aby pobrać dzienniki:
ContainerLogV2
| where _ResourceId =~ "/subscriptions/<subscription-ID>/resourceGroups/<resource-group-name>/providers/Microsoft.ContainerService/managedClusters/<cluster-ID>" // Use the IDs and names of your resources for these values.
| where ContainerName has "aks-link"
| project LogSource,LogMessage, TimeGenerated, Computer, PodName, ContainerName, ContainerId
| order by TimeGenerated desc
| limit 200
Uruchom następujące zapytanie, aby wyszukać dzienniki kontenera dla dowolnego zasobnika, który zakończył się niepowodzeniem w określonej przestrzeni nazw:
let KubePodInv = KubePodInventory
| where TimeGenerated >= startTime and TimeGenerated < endTime
| where _ResourceId =~ "<cluster-resource-ID>" // Use your resource ID for this value.
| where Namespace == "<pod-namespace>" // Use your target namespace for this value.
| where PodStatus == "Failed"
| extend ContainerId = ContainerID
| summarize arg_max(TimeGenerated, *) by ContainerId, PodStatus, ContainerStatus
| project ContainerId, PodStatus, ContainerStatus;
KubePodInv
| join
(
ContainerLogV2
| where TimeGenerated >= startTime and TimeGenerated < endTime
| where PodNamespace == "<pod-namespace>" //update with target namespace
) on ContainerId
| project TimeGenerated, PodName, PodStatus, ContainerName, ContainerId, ContainerStatus, LogMessage, LogSource
Jeśli nie możesz pobrać dzienników przy użyciu zapytań lub narzędzia kubectl, użyj uwierzytelniania protokołu Secure Shell (SSH). W tym przykładzie znajduje zasobnik tunnelfront po nawiązaniu połączenia z węzłem za pośrednictwem protokołu SSH.
kubectl pods -n kube-system -o wide | grep tunnelfront
ssh azureuser@<agent node pod is on, output from step above>
docker ps | grep tunnelfront
docker logs …
nslookup <ssh-server_fqdn>
ssh -vv azureuser@<ssh-server_fqdn> -p 9000
docker exec -it <tunnelfront_container_id> /bin/bash -c "ping bing.com"
kubectl get pods -n kube-system -o wide | grep <agent_node_where_tunnelfront_is_running>
kubectl delete po <kube_proxy_pod> -n kube-system
Krok 3. Weryfikowanie rozpoznawania nazw DNS podczas ograniczania ruchu wychodzącego
Rozpoznawanie nazw DNS jest kluczowym aspektem klastra usługi AKS. Jeśli rozpoznawanie nazw DNS nie działa poprawnie, może to spowodować błędy płaszczyzny sterowania lub błędy ściągania obrazu kontenera. Aby upewnić się, że rozpoznawanie nazw DNS na serwerze interfejsu API Kubernetes działa prawidłowo, wykonaj następujące kroki:
Uruchom polecenie kubectl exec, aby otworzyć powłokę poleceń w kontenerze uruchomionym w zasobniku.
kubectl exec --stdin --tty your-pod --namespace <namespace-name> -- /bin/bashSprawdź, czy w kontenerze są zainstalowane narzędzia nslookup lub dig .
Jeśli żadne narzędzie nie jest zainstalowane w zasobniku, uruchom następujące polecenie, aby utworzyć zasobnik narzędzia w tej samej przestrzeni nazw.
kubectl run -i --tty busybox --image=busybox --namespace <namespace-name> --rm=true -- shAdres serwera interfejsu API można pobrać ze strony przeglądu klastra usługi AKS w witrynie Azure Portal lub uruchomić następujące polecenie.
az aks show --name <aks-name> --resource-group <resource-group-name> --query fqdn --output tsvUruchom następujące polecenie, aby spróbować rozwiązać problem z serwerem interfejsu API usługi AKS. Aby uzyskać więcej informacji, zobacz Rozwiązywanie problemów z błędami rozpoznawania nazw DNS z zasobnika, ale nie z węzła roboczego.
nslookup myaks-47983508.hcp.westeurope.azmk8s.ioSprawdź nadrzędny serwer DNS z zasobnika, aby określić, czy rozpoznawanie nazw DNS działa prawidłowo. Na przykład w przypadku usługi Azure DNS uruchom
nslookuppolecenie .nslookup microsoft.com 168.63.129.16Jeśli poprzednie kroki nie zapewniają szczegółowych informacji, połącz się z jednym z węzłów roboczych i spróbuj rozpoznać system DNS z węzła. Ten krok pomaga określić, czy problem jest związany z usługą AKS, czy konfiguracją sieci.
Jeśli rozpoznawanie nazw DNS z węzła, ale nie z zasobnika, problem może być związany z systemem DNS kubernetes. Aby uzyskać instrukcje debugowania rozpoznawania nazw DNS z zasobnika, zobacz Rozwiązywanie problemów z błędami rozpoznawania nazw DNS.
Jeśli rozpoznawanie nazw DNS nie powiedzie się z węzła, przejrzyj konfigurację sieci, aby upewnić się, że odpowiednie ścieżki routingu i porty są otwarte w celu ułatwienia rozpoznawania nazw DNS.
Krok 4. Sprawdzanie błędów narzędzia kubelet
Sprawdź stan procesu kubelet, który jest uruchamiany w każdym węźle roboczym, i upewnij się, że nie jest pod żadnym ciśnieniem. Potencjalne wykorzystanie może dotyczyć procesora CPU, pamięci lub magazynu. Aby sprawdzić stan poszczególnych węzłów kubelets, możesz użyć jednej z następujących metod.
Skoroszyt kubelet usługi AKS
Aby upewnić się, że polecenia kubelety węzła agenta działają prawidłowo, wykonaj następujące kroki:
Przejdź do klastra usługi AKS w witrynie Azure Portal.
W sekcji Monitorowanie okienka nawigacji wybierz pozycję Skoroszyty.
Wybierz skoroszyt Kubelet.
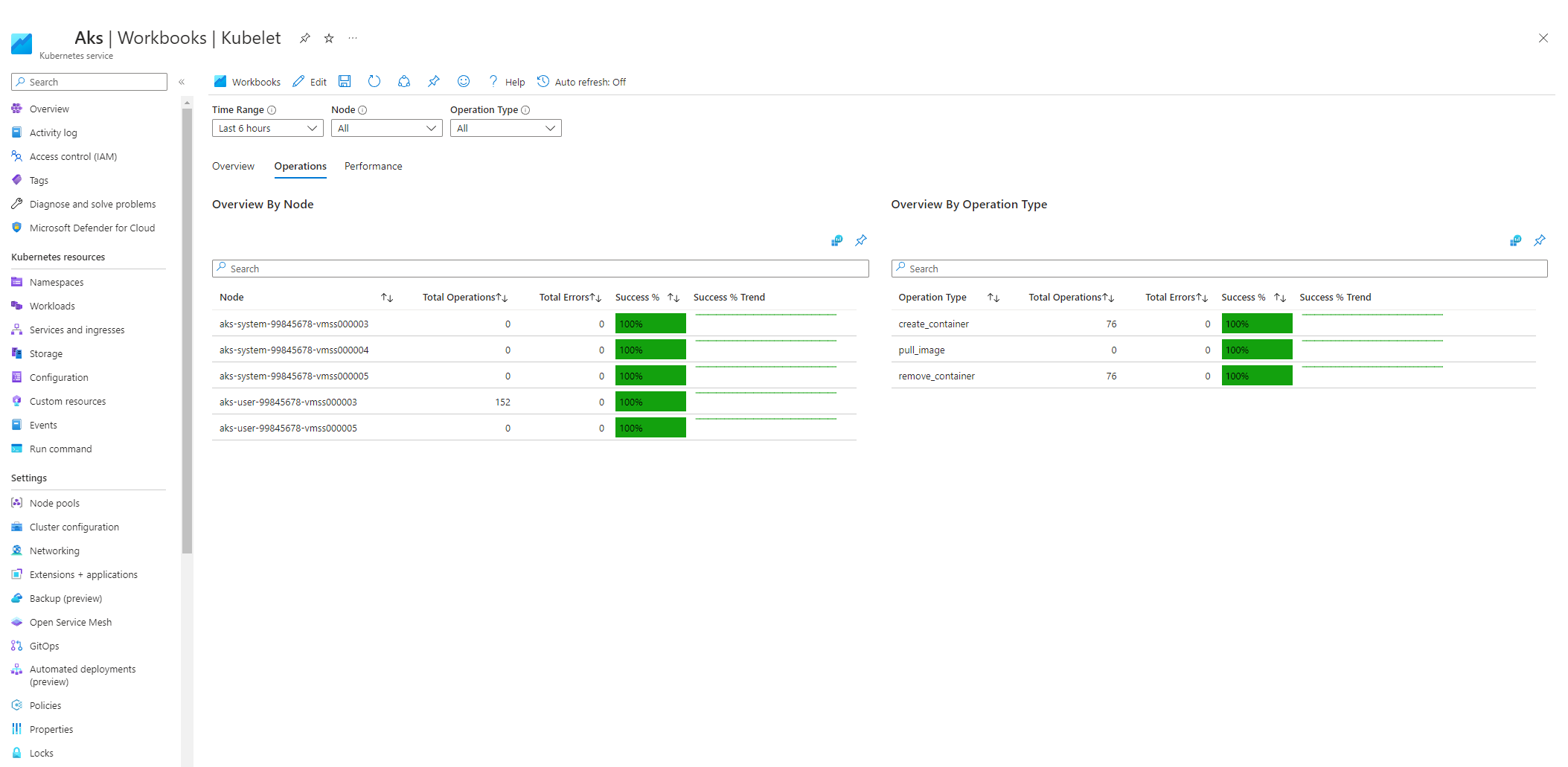
Wybierz pozycję Operacje i upewnij się, że operacje dla wszystkich węzłów procesu roboczego zostały ukończone.


Monitorowanie w klastrze za pomocą rozwiązań Prometheus i Grafana
Jeśli wdrożono rozwiązanie Prometheus i Grafana w klastrze usługi AKS, możesz użyć pulpitu nawigacyjnego Kubernetes/Kubelet , aby uzyskać szczegółowe informacje na temat kondycji i wydajności poszczególnych węzłów kubelets.

Monitorowanie usługi zarządzanej dla rozwiązań Prometheus i Azure Managed Grafana
Możesz użyć wstępnie utworzonego pulpitu nawigacyjnego kubernetes/Kubelet , aby wizualizować i analizować metryki rozwiązania Prometheus dla węzła roboczego kubelets. W tym celu należy skonfigurować klaster usługi AKS w celu zbierania metryk rozwiązania Prometheus w usłudze zarządzanej Monitor dla rozwiązania Prometheus i połączyć obszar roboczy Monitor z obszarem roboczym usługi Azure Managed Grafana .

Ciśnienie zwiększa się, gdy kubelet uruchamia się ponownie i powoduje sporadyczne, nieprzewidywalne zachowanie. Upewnij się, że liczba błędów nie rośnie w sposób ciągły. Sporadyczny błąd jest akceptowalny, ale stały wzrost wskazuje podstawowy problem, który należy zbadać i rozwiązać.
Krok 5. Używanie narzędzia do wykrywania problemów węzła (NPD) w celu sprawdzenia kondycji węzła
NPD to narzędzie Kubernetes, którego można użyć do identyfikowania i zgłaszania problemów związanych z węzłem. Działa jako usługa systemowa w każdym węźle w klastrze. Zbiera metryki i informacje o systemie, takie jak użycie procesora CPU, użycie dysku i stan łączności sieciowej. Po wykryciu problemu narzędzie NPD generuje raport dotyczący zdarzeń i warunku węzła. W usłudze AKS narzędzie NPD służy do monitorowania węzłów klastra Kubernetes hostowanego w chmurze platformy Azure i zarządzania nimi. Aby uzyskać więcej informacji, zobacz NPD w węzłach usługi AKS.
Krok 6. Sprawdzanie operacji we/wy dysku na sekundę (IOPS) pod kątem ograniczania przepustowości
Aby upewnić się, że liczba operacji we/wy na sekundę nie jest ograniczana i wpływa na usługi i obciążenia w klastrze usługi AKS, możesz użyć jednej z następujących metod.
Skoroszyt we/wy dysku węzła usługi AKS
Aby monitorować metryki we/wy dysku węzłów procesu roboczego w klastrze usługi AKS, możesz użyć skoroszytu we/ wy dysku węzła. Wykonaj następujące kroki, aby uzyskać dostęp do skoroszytu:
Przejdź do klastra usługi AKS w witrynie Azure Portal.
W sekcji Monitorowanie okienka nawigacji wybierz pozycję Skoroszyty.
Wybierz skoroszyt We/Wy dysku węzła.
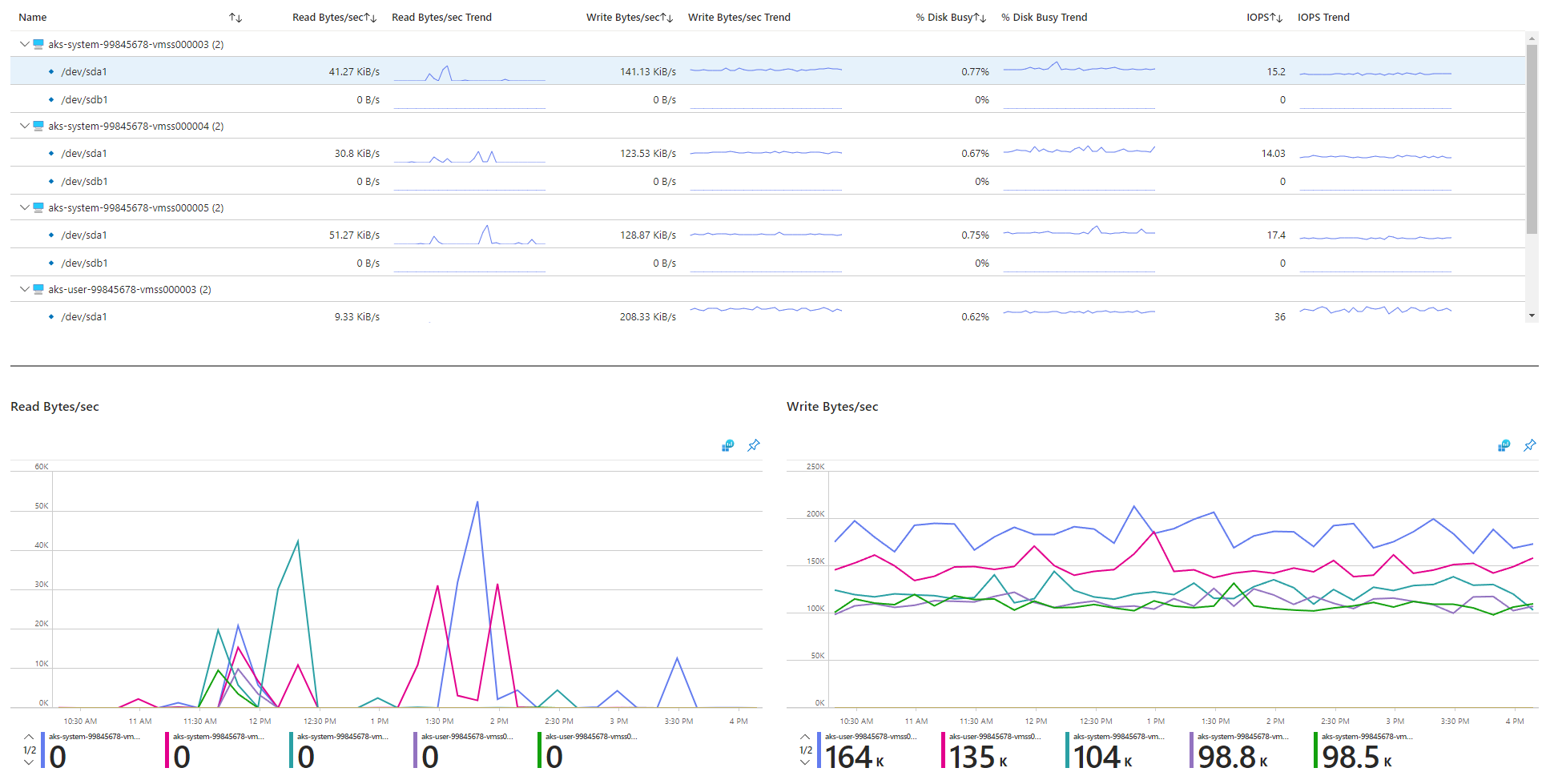
Przejrzyj metryki związane z we/wy.


Monitorowanie w klastrze za pomocą rozwiązań Prometheus i Grafana
Jeśli wdrożono rozwiązanie Prometheus i Grafana w klastrze usługi AKS, możesz użyć pulpitu nawigacyjnego USE Method /Node , aby uzyskać szczegółowe informacje o we/wy dysku dla węzłów procesu roboczego klastra.

Monitorowanie usługi zarządzanej dla rozwiązań Prometheus i Azure Managed Grafana
Za pomocą wstępnie utworzonego pulpitu nawigacyjnego eksportera/węzłów węzłów można wizualizować i analizować metryki związane z we/wy dysku z węzłów roboczych. W tym celu należy skonfigurować klaster usługi AKS w celu zbierania metryk rozwiązania Prometheus w usłudze zarządzanej Monitor dla rozwiązania Prometheus i połączyć obszar roboczy Monitor z obszarem roboczym usługi Azure Managed Grafana .

Operacje we/wy na sekundę i dyski platformy Azure
Fizyczne urządzenia magazynujące mają nieodłączne ograniczenia dotyczące przepustowości i maksymalnej liczby operacji na plikach, które mogą obsłużyć. Dyski platformy Azure są używane do przechowywania systemu operacyjnego działającego w węzłach usługi AKS. Dyski podlegają tym samym ograniczeniom magazynu fizycznego co system operacyjny.
Rozważmy koncepcję przepływności. Średni rozmiar operacji we/wy można pomnożyć przez liczbę operacji we/wy na sekundę, aby określić przepływność w megabajtach na sekundę (MB/s). Większe rozmiary operacji we/wy przekładają się na niższą liczbę operacji we/wy na sekundę ze względu na stałą przepływność dysku.
Gdy obciążenie przekroczy maksymalne limity liczby operacji we/wy przypisane do dysków platformy Azure, klaster może nie odpowiadać i wprowadzić stan oczekiwania we/wy. W systemach opartych na systemie Linux wiele składników jest traktowanych jako pliki, takie jak gniazda sieciowe, CNI, Docker i inne usługi zależne od operacji we/wy sieci. W związku z tym, jeśli nie można odczytać dysku, błąd rozciąga się na wszystkie te pliki.
Kilka zdarzeń i scenariuszy może wyzwalać ograniczanie liczby operacji we/wy na sekundę, w tym:
Znaczna liczba kontenerów uruchamianych w węzłach, ponieważ we/wy platformy Docker współużytkuje dysk systemu operacyjnego.
Niestandardowe lub inne narzędzia używane do zabezpieczeń, monitorowania i rejestrowania, które mogą generować dodatkowe operacje we/wy na dysku systemu operacyjnego.
Zdarzenia trybu failover węzła i okresowe zadania, które intensyfikują obciążenie lub skalują liczbę zasobników. To zwiększone obciążenie zwiększa prawdopodobieństwo wystąpienia ograniczania przepustowości, co potencjalnie powoduje przejście wszystkich węzłów do stanu gotowości do momentu zakończenia operacji we/wy.
Współautorzy
Ten artykuł jest obsługiwany przez firmę Microsoft. Pierwotnie został napisany przez następujących współautorów.
Autorzy zabezpieczeń:
- Paolo Salvatori | Główny inżynier klienta
- Franciszek Simy FrancisZki | Starszy specjalista techniczny
Aby wyświetlić niepubalne profile serwisu LinkedIn, zaloguj się do serwisu LinkedIn.