Dobry projekt interfejsu API jest ważny w architekturze mikrousług, ponieważ każda wymiana danych między usługami odbywa się za pośrednictwem komunikatów lub wywołań interfejsu API. Interfejsy API muszą być wydajne, aby uniknąć tworzenia czatty we/wy. Ponieważ usługi są projektowane przez zespoły działające niezależnie, interfejsy API muszą mieć dobrze zdefiniowane semantyki i schematy przechowywania wersji, aby aktualizacje nie przerywały innych usług.
Ważne jest rozróżnienie między dwoma typami interfejsu API:
- Publiczne interfejsy API wywoływane przez aplikacje klienckie.
- Interfejsy API zaplecza używane do komunikacji międzyusługowej.
Te dwa przypadki użycia mają nieco inne wymagania. Publiczny interfejs API musi być zgodny z aplikacjami klienckimi, zazwyczaj aplikacjami przeglądarki lub natywnymi aplikacjami mobilnymi. W większości przypadków oznacza to, że publiczny interfejs API będzie używać interfejsu REST za pośrednictwem protokołu HTTP. Jednak w przypadku interfejsów API zaplecza należy uwzględnić wydajność sieci. W zależności od stopnia szczegółowości usług komunikacja międzyusługowa może spowodować duży ruch sieciowy. Usługi mogą szybko stać się powiązane we/wy. Z tego powodu zagadnienia, takie jak szybkość serializacji i rozmiar ładunku, stają się ważniejsze. Niektóre popularne alternatywy dla używania interfejsu REST za pośrednictwem protokołu HTTP obejmują biblioteki gRPC, Apache Avro i Apache Thrift. Te protokoły obsługują serializacji binarnej i są ogólnie bardziej wydajne niż HTTP.
Kwestie wymagające rozważenia
Poniżej przedstawiono kilka kwestii, które należy wziąć pod uwagę podczas wybierania sposobu implementowania interfejsu API.
REST a RPC. Rozważ kompromisy między użyciem interfejsu w stylu REST a interfejsem w stylu RPC.
Zasoby modeli REST, które mogą być naturalnym sposobem wyrażania modelu domeny. Definiuje jednolity interfejs oparty na czasownikach HTTP, co zachęca do rozwoju. Ma dobrze zdefiniowaną semantyka pod względem idempotencji, skutków ubocznych i kodów odpowiedzi. Wymusza komunikację bezstanową, co zwiększa skalowalność.
RPC jest bardziej zorientowany na operacje lub polecenia. Ponieważ interfejsy RPC wyglądają jak wywołania metod lokalnych, może to prowadzić do projektowania nadmiernie czatty interfejsów API. Nie oznacza to jednak, że RPC musi być czatty. Oznacza to po prostu, że podczas projektowania interfejsu należy użyć opieki.
W przypadku interfejsu RESTful najczęstszym wyborem jest interfejs REST za pośrednictwem protokołu HTTP przy użyciu formatu JSON. W przypadku interfejsu w stylu RPC istnieje kilka popularnych struktur, w tym gRPC, Apache Avro i Apache Thrift.
Efektywność. Rozważ wydajność pod względem szybkości, pamięci i rozmiaru ładunku. Zazwyczaj interfejs oparty na protokole gRPC jest szybszy niż interfejs REST za pośrednictwem protokołu HTTP.
Język definicji interfejsu (IDL). IDL służy do definiowania metod, parametrów i zwracanych wartości interfejsu API. Kod IDL może służyć do generowania kodu klienta, kodu serializacji i dokumentacji interfejsu API. Listy IDLs mogą być również używane przez narzędzia do testowania interfejsu API. Struktury, takie jak gRPC, Avro i Thrift, definiują własne specyfikacje IDL. Interfejs REST za pośrednictwem protokołu HTTP nie ma standardowego formatu IDL, ale typowym wyborem jest interfejs OpenAPI (dawniej Swagger). Możesz również utworzyć interfejs API REST HTTP bez użycia języka definicji formalnej, ale utracisz korzyści wynikające z generowania i testowania kodu.
Serializacja. W jaki sposób obiekty są serializowane za pośrednictwem przewodu? Opcje obejmują formaty tekstowe (głównie JSON) i formaty binarne, takie jak bufor protokołu. Formaty binarne są zazwyczaj szybsze niż formaty tekstowe. Jednak kod JSON ma zalety w zakresie współdziałania, ponieważ większość języków i struktur obsługuje serializacji JSON. Niektóre formaty serializacji wymagają stałego schematu, a niektóre wymagają skompilowania pliku definicji schematu. W takim przypadku należy uwzględnić ten krok w procesie kompilacji.
Obsługa platformy i języka. Protokół HTTP jest obsługiwany w prawie każdej strukturze i języku. Wszystkie biblioteki gRPC, Avro i Thrift mają biblioteki dla języków C++, C#, Java i Python. Biblioteka Thrift i gRPC obsługują również platformę Go.
Zgodność i współdziałanie. Jeśli wybierzesz protokół, taki jak gRPC, może być potrzebna warstwa tłumaczenia protokołu między publicznym interfejsem API i zapleczem. Brama może wykonywać tę funkcję. Jeśli używasz siatki usług, rozważ, które protokoły są zgodne z siatką usług. Na przykład konsolidator Linkerd ma wbudowaną obsługę protokołów HTTP, Thrift i gRPC.
Naszym zaleceniem bazowym jest wybranie interfejsu REST za pośrednictwem protokołu HTTP, chyba że potrzebujesz korzyści z wydajności protokołu binarnego. Interfejs REST za pośrednictwem protokołu HTTP nie wymaga żadnych specjalnych bibliotek. Tworzy minimalne sprzężenie, ponieważ obiekty wywołujące nie potrzebują wycinków klienta do komunikowania się z usługą. Istnieją bogate ekosystemy narzędzi do obsługi definicji schematu, testowania i monitorowania punktów końcowych HTTP RESTful. Na koniec protokół HTTP jest zgodny z klientami przeglądarki, więc nie potrzebujesz warstwy tłumaczenia protokołu między klientem a zapleczem.
Jeśli jednak wybierzesz interfejs REST za pośrednictwem protokołu HTTP, należy przeprowadzić testy wydajnościowe i obciążeniowe na wczesnym etapie procesu programowania, aby sprawdzić, czy działa wystarczająco dobrze w danym scenariuszu.
Projekt interfejsu API RESTful
Istnieje wiele zasobów do projektowania interfejsów API RESTful. Oto niektóre, które mogą okazać się przydatne:
Poniżej przedstawiono kilka konkretnych zagadnień, które należy wziąć pod uwagę.
Zwróć uwagę na interfejsy API, które wyciekają wewnętrzne szczegóły implementacji lub po prostu dubluje wewnętrzny schemat bazy danych. Interfejs API powinien modelować domenę. Jest to kontrakt między usługami i najlepiej zmienić tylko wtedy, gdy dodawana jest nowa funkcja, a nie tylko dlatego, że refaktoryzowano jakiś kod lub znormalizowano tabelę bazy danych.
Różne typy klientów, takie jak aplikacja mobilna i przeglądarka internetowa dla komputerów stacjonarnych, mogą wymagać różnych rozmiarów ładunków lub wzorców interakcji. Rozważ użycie wzorca zaplecza dla frontonów w celu utworzenia oddzielnych zapleczy dla każdego klienta, które uwidacznia optymalny interfejs dla tego klienta.
W przypadku operacji z efektami ubocznymi rozważ ich idempotentne i zaimplementowanie ich jako metod PUT. Umożliwi to bezpieczne ponawianie prób i może poprawić odporność. Bardziej szczegółowo omówiono tę kwestię w artykule Komunikacja międzyusługowa.
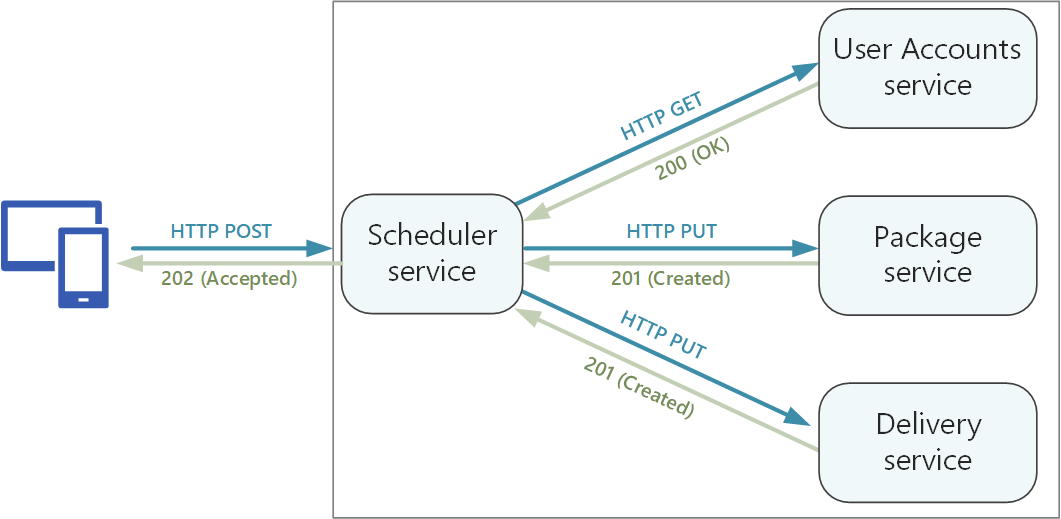
Metody HTTP mogą mieć semantyka asynchroniczna, w której metoda natychmiast zwraca odpowiedź, ale usługa wykonuje operację asynchronicznie. W takim przypadku metoda powinna zwrócić kod odpowiedzi HTTP 202 , który wskazuje, że żądanie zostało zaakceptowane do przetworzenia, ale przetwarzanie nie zostało jeszcze ukończone. Aby uzyskać więcej informacji, zobacz Asynchroniczny wzorzec żądania-odpowiedzi.
Mapowanie wzorców REST na wzorce DDD
Wzorce, takie jak jednostka, agregacja i obiekt wartości, zostały zaprojektowane w celu umieszczenia pewnych ograniczeń dotyczących obiektów w modelu domeny. W wielu dyskusjach dotyczących DDD wzorce są modelowane przy użyciu pojęć języka zorientowanego na obiekt (OO), takich jak konstruktory lub metody pobierania właściwości i ustawiacze. Na przykład obiekty wartości mają być niezmienne. W języku programowania OO należy wymusić to przez przypisanie wartości w konstruktorze i utworzenie właściwości tylko do odczytu:
export class Location {
readonly latitude: number;
readonly longitude: number;
constructor(latitude: number, longitude: number) {
if (latitude < -90 || latitude > 90) {
throw new RangeError('latitude must be between -90 and 90');
}
if (longitude < -180 || longitude > 180) {
throw new RangeError('longitude must be between -180 and 180');
}
this.latitude = latitude;
this.longitude = longitude;
}
}
Takie praktyki kodowania są szczególnie ważne podczas tworzenia tradycyjnej aplikacji monolitycznej. W przypadku dużej bazy kodu wiele podsystemów może używać Location obiektu, dlatego ważne jest, aby obiekt wymuszał prawidłowe zachowanie.
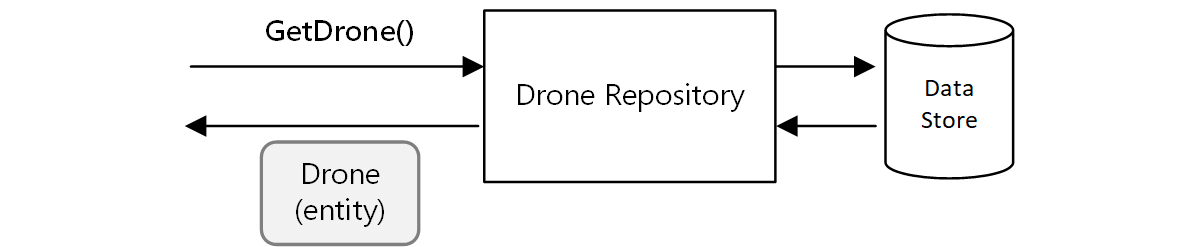
Innym przykładem jest wzorzec repozytorium, który gwarantuje, że inne części aplikacji nie wykonują bezpośrednich operacji odczytu ani zapisu w magazynie danych:
Jednak w architekturze mikrousług usługi nie współużytkują tej samej bazy kodu i nie udostępniają magazynów danych. Zamiast tego komunikują się za pośrednictwem interfejsów API. Rozważmy przypadek, w którym usługa Scheduler żąda informacji o dronie z usługi Drone. Usługa Drone ma swój wewnętrzny model drona wyrażony za pomocą kodu. Ale harmonogram nie widzi tego. Zamiast tego zwraca reprezentację jednostki drona — być może obiekt JSON w odpowiedzi HTTP.
Ten przykład jest idealny dla przemysłu lotniczego i lotniczego.
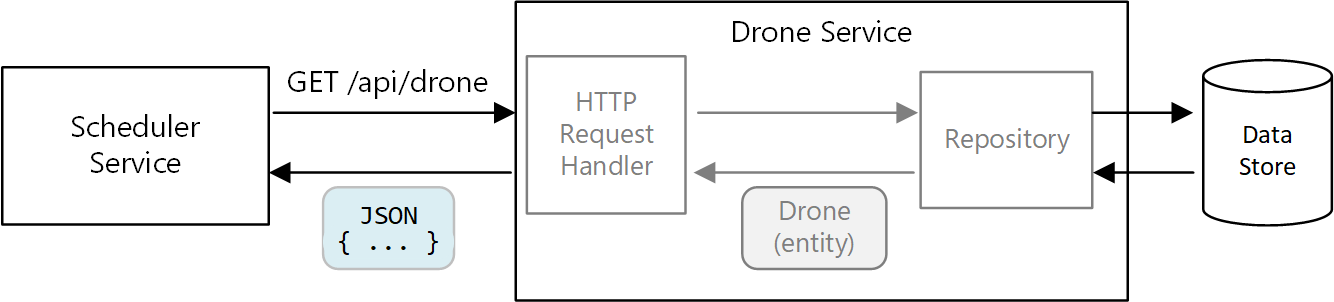
Usługa Scheduler nie może modyfikować wewnętrznych modeli usługi Drone ani zapisywać ich w magazynie danych usługi Drone. Oznacza to, że kod implementujący usługę Drone ma mniejszy obszar powierzchni, w porównaniu z kodem w tradycyjnym monolicie. Jeśli usługa Drone definiuje klasę Location, zakres tej klasy jest ograniczony — żadna inna usługa nie będzie bezpośrednio korzystać z klasy.
Z tych powodów te wskazówki nie koncentrują się na praktykach kodowania, ponieważ odnoszą się one do taktycznych wzorców DDD. Okazuje się jednak, że można również modelować wiele wzorców DDD za pomocą interfejsów API REST.
Na przykład:
Agregacje są mapowane naturalnie na zasoby w architekturze REST. Na przykład agregacja dostarczania będzie widoczna jako zasób przez interfejs API dostarczania.
Agregacje to granice spójności. Operacje na agregacjach nigdy nie powinny pozostawiać agregacji w stanie niespójnym. Dlatego należy unikać tworzenia interfejsów API, które umożliwiają klientowi manipulowanie stanem wewnętrznym agregacji. Zamiast tego faworyzować gruboziarniste interfejsy API, które uwidaczniają agregacje jako zasoby.
Jednostki mają unikatowe tożsamości. W interfejsie REST zasoby mają unikatowe identyfikatory w postaci adresów URL. Utwórz adresy URL zasobów, które odpowiadają tożsamości domeny jednostki. Mapowanie z adresu URL do tożsamości domeny może być nieprzezroczyste do klienta.
Jednostki podrzędne agregacji można uzyskać, przechodząc z jednostki głównej. Jeśli przestrzegasz zasad HATEOAS , jednostki podrzędne można uzyskać za pośrednictwem linków w reprezentacji jednostki nadrzędnej.
Ponieważ obiekty wartości są niezmienne, aktualizacje są wykonywane przez zastąpienie całego obiektu wartości. W interfejsie REST zaimplementuj aktualizacje za pomocą żądań PUT lub PATCH.
Repozytorium umożliwia klientom wykonywanie zapytań, dodawanie lub usuwanie obiektów w kolekcji, abstrakcję szczegółów bazowego magazynu danych. W architekturze REST kolekcja może być odrębnym zasobem z metodami wykonywania zapytań dotyczących kolekcji lub dodawania nowych jednostek do kolekcji.
Podczas projektowania interfejsów API zastanów się, jak wyrażają model domeny, nie tylko dane w modelu, ale także operacje biznesowe i ograniczenia dotyczące danych.
| Koncepcja DDD | Odpowiednik REST | Przykład |
|---|---|---|
| Agregacja | Zasób | { "1":1234, "status":"pending"... } |
| Tożsamość | URL | https://delivery-service/deliveries/1 |
| Jednostki podrzędne | Linki | { "href": "/deliveries/1/confirmation" } |
| Aktualizowanie obiektów wartości | PUT lub PATCH | PUT https://delivery-service/deliveries/1/dropoff |
| Repozytorium | Kolekcja | https://delivery-service/deliveries?status=pending |
Obsługa wersji interfejsu API
Interfejs API to kontrakt między usługą a klientami lub konsumentami tej usługi. Jeśli interfejs API ulegnie zmianie, istnieje ryzyko przerwania klientów, którzy zależą od interfejsu API, niezależnie od tego, czy są to klienci zewnętrzni, czy inne mikrousługi. W związku z tym dobrym pomysłem jest zminimalizowanie liczby w wprowadzania zmian interfejsu API. Często zmiany w implementacji bazowej nie wymagają żadnych zmian w interfejsie API. Realistycznie jednak w pewnym momencie warto dodać nowe funkcje lub nowe funkcje, które wymagają zmiany istniejącego interfejsu API.
Jeśli to możliwe, wprowadź zmiany interfejsu API zgodne z poprzednimi wersjami. Na przykład należy unikać usuwania pola z modelu, ponieważ może to uszkodzić klientów, którzy oczekują, że pole będzie tam znajdować. Dodanie pola nie powoduje przerwania zgodności, ponieważ klienci powinni ignorować wszystkie pola, które nie rozumieją w odpowiedzi. Jednak usługa musi obsługiwać przypadek, w którym starszy klient pomija nowe pole w żądaniu.
Obsługa przechowywania wersji w umowie interfejsu API. W przypadku wprowadzenia zmiany powodującej niezgodność interfejsu API wprowadź nową wersję interfejsu API. Kontynuuj obsługę poprzedniej wersji i pozwól klientom wybrać wersję do wywołania. Istnieje kilka sposobów, aby to zrobić. Jednym z nich jest po prostu uwidocznienie obu wersji w tej samej usłudze. Inną opcją jest uruchomienie dwóch wersji usługi obok siebie i kierowanie żądań do jednej lub drugiej wersji na podstawie reguł routingu HTTP.
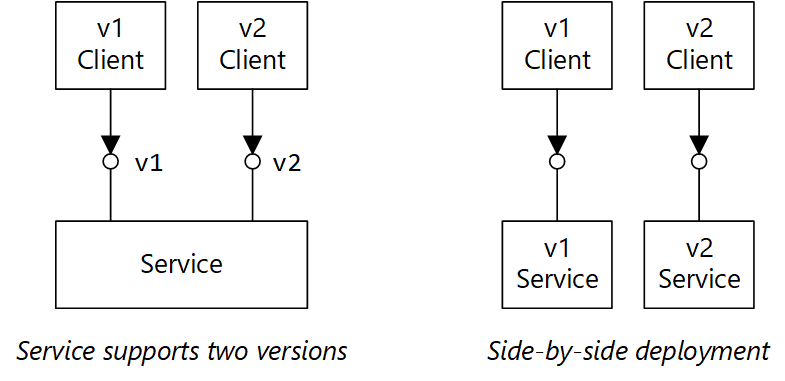
Diagram ma dwie części. Opcja "Usługa obsługuje dwie wersje" pokazuje klienta w wersji 1 i klienta w wersji 2 wskazującą jedną usługę. Polecenie "Wdrożenie równoległe" pokazuje klienta w wersji 1 wskazującego usługę w wersji 1, a klient w wersji 2 wskazuje usługę w wersji 2.
Istnieje koszt obsługi wielu wersji, jeśli chodzi o czas dewelopera, testowanie i nakład pracy operacyjnej. W związku z tym warto jak najszybciej wycofać stare wersje. W przypadku wewnętrznych interfejsów API zespół, który jest właścicielem interfejsu API, może współpracować z innymi zespołami, aby ułatwić im migrację do nowej wersji. Dzieje się tak, gdy proces zapewniania ładu między zespołami jest przydatny. W przypadku zewnętrznych (publicznych) interfejsów API może być trudniej wycofać wersję interfejsu API, zwłaszcza jeśli interfejs API jest używany przez inne firmy lub aplikacje klienckie natywne.
Gdy implementacja usługi ulegnie zmianie, warto oznaczyć zmianę wersją. Wersja zawiera ważne informacje podczas rozwiązywania problemów z błędami. Analiza głównej przyczyny może być bardzo przydatna, aby wiedzieć dokładnie, która wersja usługi została wywołana. Rozważ użycie semantycznego przechowywania wersji dla wersji usług. Przechowywanie wersji semantycznych używa majora . MAŁOLETNI. Format PATCH . Jednak klienci powinni wybrać interfejs API tylko według numeru wersji głównej lub ewentualnie wersji pomocniczej, jeśli między wersjami pomocniczymi występują istotne (ale niezwiązane) zmiany. Innymi słowy, klienci mogą wybrać wersję 1 do 2 interfejsu API, ale nie wybrać wersji 2.1.3. Jeśli zezwolisz na ten poziom szczegółowości, ryzykujesz, że trzeba obsługiwać rozprzestrzenianie się wersji.
Aby uzyskać więcej informacji na temat przechowywania wersji interfejsu API, zobacz Przechowywanie wersji internetowego interfejsu API RESTful.
Operacje idempotentne
Operacja jest idempotentna , jeśli może być wywoływana wiele razy bez wytwarzania dodatkowych skutków ubocznych po pierwszym wywołaniu. Idempotency może być przydatną strategią odporności, ponieważ umożliwia usłudze nadrzędnej bezpieczne wywoływanie operacji wiele razy. Aby zapoznać się z tą kwestią, zobacz Transakcje rozproszone.
Specyfikacja HTTP wskazuje, że metody GET, PUT i DELETE muszą być idempotentne. Metody POST nie mają gwarancji, że są idempotentne. Jeśli metoda POST tworzy nowy zasób, zazwyczaj nie ma gwarancji, że ta operacja jest idempotentna. Specyfikacja definiuje idempotentne w ten sposób:
Metoda żądania jest uznawana za "idempotentną", jeśli zamierzony wpływ na serwer wielu identycznych żądań z tą metodą jest taki sam jak efekt pojedynczego takiego żądania. (RFC 7231)
Ważne jest, aby zrozumieć różnicę między semantyki PUT i POST podczas tworzenia nowej jednostki. W obu przypadkach klient wysyła reprezentację jednostki w treści żądania. Ale znaczenie identyfikatora URI jest inne.
W przypadku metody POST identyfikator URI reprezentuje zasób nadrzędny nowej jednostki, taki jak kolekcja. Na przykład aby utworzyć nowe dostarczanie, identyfikator URI może mieć wartość
/api/deliveries. Serwer tworzy jednostkę i przypisuje mu nowy identyfikator URI, taki jak/api/deliveries/39660. Ten identyfikator URI jest zwracany w nagłówku Location odpowiedzi. Za każdym razem, gdy klient wysyła żądanie, serwer utworzy nową jednostkę z nowym identyfikatorem URI.W przypadku metody PUT identyfikator URI identyfikuje jednostkę. Jeśli istnieje już jednostka o tym identyfikatorze URI, serwer zastępuje istniejącą jednostkę wersją żądania. Jeśli żadna jednostka nie istnieje z tym identyfikatorem URI, serwer go utworzy. Załóżmy na przykład, że klient wysyła żądanie PUT do
api/deliveries/39660. Zakładając, że nie ma dostarczania z tym identyfikatorem URI, serwer tworzy nowy. Teraz, jeśli klient ponownie wyśle to samo żądanie, serwer zastąpi istniejącą jednostkę.
Oto implementacja metody PUT usługi dostarczania.
[HttpPut("{id}")]
[ProducesResponseType(typeof(Delivery), 201)]
[ProducesResponseType(typeof(void), 204)]
public async Task<IActionResult> Put([FromBody]Delivery delivery, string id)
{
logger.LogInformation("In Put action with delivery {Id}: {@DeliveryInfo}", id, delivery.ToLogInfo());
try
{
var internalDelivery = delivery.ToInternal();
// Create the new delivery entity.
await deliveryRepository.CreateAsync(internalDelivery);
// Create a delivery status event.
var deliveryStatusEvent = new DeliveryStatusEvent { DeliveryId = delivery.Id, Stage = DeliveryEventType.Created };
await deliveryStatusEventRepository.AddAsync(deliveryStatusEvent);
// Return HTTP 201 (Created)
return CreatedAtRoute("GetDelivery", new { id= delivery.Id }, delivery);
}
catch (DuplicateResourceException)
{
// This method is mainly used to create deliveries. If the delivery already exists then update it.
logger.LogInformation("Updating resource with delivery id: {DeliveryId}", id);
var internalDelivery = delivery.ToInternal();
await deliveryRepository.UpdateAsync(id, internalDelivery);
// Return HTTP 204 (No Content)
return NoContent();
}
}
Oczekuje się, że większość żądań utworzy nową jednostkę, więc metoda optymistycznie wywołuje CreateAsync obiekt repozytorium, a następnie obsługuje wszelkie wyjątki zduplikowanych zasobów, aktualizując zasób.
Następne kroki
Dowiedz się więcej o korzystaniu z bramy interfejsu API na granicy między aplikacjami klienckimi i mikrousługami.