Tworzenie niezawodnego procesu ciągłej integracji/ciągłego dostarczania (CI/CD) dla architektury mikrousług może być trudne. Poszczególne zespoły muszą mieć możliwość szybkiego i niezawodnego wydawania usług bez zakłócania działania innych zespołów ani destabilizowania całej aplikacji.
W tym artykule opisano przykładowy potok ciągłej integracji/ciągłego wdrażania na potrzeby wdrażania mikrousług w usłudze Azure Kubernetes Service (AKS). Każdy zespół i projekt są różne, więc nie należy przyjmować tego artykułu jako zestawu trudnych i szybkich reguł. Zamiast tego jest to punkt wyjścia do projektowania własnego procesu ciągłej integracji/ciągłego wdrażania.
Cele potoku ciągłej integracji/ciągłego wdrażania dla hostowanych mikrousług platformy Kubernetes można podsumować w następujący sposób:
- Zespoły mogą tworzyć i wdrażać swoje usługi niezależnie.
- Zmiany kodu, które przechodzą proces ciągłej integracji, są automatycznie wdrażane w środowisku przypominającym środowisko produkcyjne.
- Bramy jakości są wymuszane na każdym etapie potoku.
- Nową wersję usługi można wdrożyć obok poprzedniej wersji.
Aby uzyskać więcej informacji, zobacz Ciągła integracja/ciągłe wdrażanie dla architektur mikrousług.
Założenia
Na potrzeby tego przykładu poniżej przedstawiono pewne założenia dotyczące zespołu deweloperów i bazy kodu:
- Repozytorium kodu to monorepo z folderami zorganizowanymi przez mikrousługę.
- Strategia rozgałęziania zespołu opiera się na rozwoju opartym na magistrali.
- Zespół używa gałęzi wydań do zarządzania wydaniami. Oddzielne wydania są tworzone dla każdej mikrousługi.
- Proces ciągłej integracji/ciągłego wdrażania używa usługi Azure Pipelines do kompilowania, testowania i wdrażania mikrousług w usłudze AKS.
- Obrazy kontenerów dla każdej mikrousługi są przechowywane w usłudze Azure Container Registry.
- Zespół używa pakietów Helm do tworzenia pakietów poszczególnych mikrousług.
- Używany jest model wdrażania wypychanego, w którym usługa Azure Pipelines i skojarzone agenci wykonują wdrożenia, łącząc się bezpośrednio z klastrem usługi AKS.
Te założenia napędzają wiele szczegółowych informacji dotyczących potoku ciągłej integracji/ciągłego wdrażania. Jednak podstawowe podejście opisane tutaj można dostosować do innych procesów, narzędzi i usług, takich jak Jenkins lub Docker Hub.
Alternatywy
Poniżej przedstawiono typowe alternatywy, których klienci mogą używać podczas wybierania strategii ciągłej integracji/ciągłego wdrażania w usłudze Azure Kubernetes Service:
- Zamiast używania narzędzia Helm jako narzędzia do zarządzania pakietami i wdrażania usługa Kustomize jest natywnym narzędziem do zarządzania konfiguracją platformy Kubernetes, które wprowadza wolny od szablonu sposób dostosowywania i sparametryzowania konfiguracji aplikacji.
- Zamiast używania usługi Azure DevOps dla repozytoriów i potoków GitHub repozytoria GitHub mogą służyć do prywatnych i publicznych repozytoriów Git, a funkcja GitHub Actions może służyć do potoków ciągłej integracji/ciągłego wdrażania.
- Zamiast korzystania z modelu wdrażania wypychanego można zarządzać konfiguracją platformy Kubernetes na dużą skalę przy użyciu metodyki GitOps (modelu wdrażania ściągania), gdzie operator Kubernetes w klastrze synchronizuje stan klastra na podstawie konfiguracji przechowywanej w repozytorium Git.
Kompilacje weryfikacji
Załóżmy, że deweloper pracuje nad mikrousługą o nazwie Usługa dostarczania. Podczas tworzenia nowej funkcji deweloper sprawdza kod w gałęzi funkcji. Zgodnie z konwencją gałęzie funkcji mają nazwę feature/*.
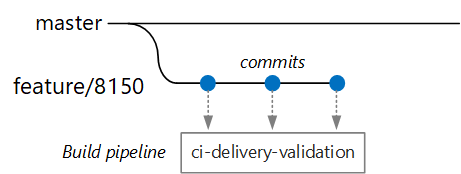
Plik definicji kompilacji zawiera wyzwalacz filtrujący według nazwy gałęzi i ścieżki źródłowej:
trigger:
batch: true
branches:
include:
# for new release to production: release flow strategy
- release/delivery/v*
- refs/release/delivery/v*
- master
- feature/delivery/*
- topic/delivery/*
paths:
include:
- /src/shipping/delivery/
Korzystając z tego podejścia, każdy zespół może mieć własny potok kompilacji. Tylko kod zaewidencjonowany w folderze /src/shipping/delivery wyzwala kompilację usługi dostarczania. Wypychanie zatwierdzeń do gałęzi zgodnej z filtrem wyzwala kompilację ciągłej integracji. W tym momencie w przepływie pracy kompilacja ciągłej integracji uruchamia minimalną weryfikację kodu:
- Skompiluj kod.
- Uruchamianie testów jednostkowych.
Celem jest skrócenie czasu kompilacji, aby deweloper mógł uzyskać szybką opinię. Gdy funkcja będzie gotowa do scalenia z wzorcem, deweloper otworzy żądanie ściągnięcia. Ta operacja wyzwala inną kompilację ciągłej integracji, która wykonuje kilka dodatkowych testów:
- Skompiluj kod.
- Uruchamianie testów jednostkowych.
- Skompiluj obraz kontenera środowiska uruchomieniowego.
- Uruchom skanowanie luk w zabezpieczeniach na obrazie.
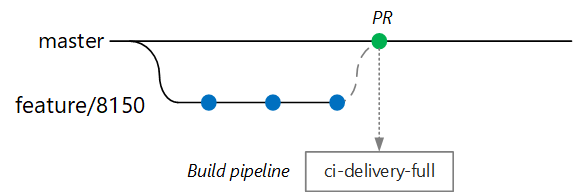
Uwaga
W usłudze Azure DevOps Repos można zdefiniować zasady ochrony gałęzi. Na przykład zasady mogą wymagać pomyślnej kompilacji ciągłej integracji oraz wylogowania z osoby zatwierdzającej w celu scalenia z serwerem głównym.
Pełna kompilacja ciągłej integracji/ciągłego wdrażania
W pewnym momencie zespół jest gotowy do wdrożenia nowej wersji usługi Dostarczania. Menedżer wydania tworzy gałąź z gałęzi głównej z tym wzorcem nazewnictwa: release/<microservice name>/<semver>. Na przykład release/delivery/v1.0.2.
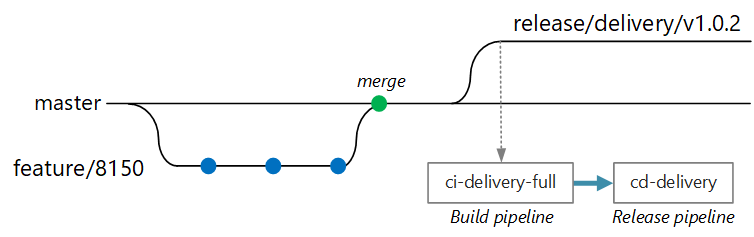
Utworzenie tej gałęzi wyzwala pełną kompilację ciągłej integracji, która uruchamia wszystkie poprzednie kroki oraz:
- Wypchnij obraz kontenera do usługi Azure Container Registry. Obraz jest oznaczony numerem wersji pobranym z nazwy gałęzi.
- Uruchom polecenie
helm package, aby spakować pakiet helm dla usługi. Wykres jest również oznaczony numerem wersji. - Wypchnij pakiet Helm do usługi Container Registry.
Zakładając, że ta kompilacja powiedzie się, wyzwala proces wdrażania (CD) przy użyciu potoku wydania usługi Azure Pipelines. Ten potok obejmuje następujące kroki:
- Wdróż pakiet Helm w środowisku kontroli jakości.
- Osoba zatwierdzająca podpisuje się przed przeniesieniem pakietu do środowiska produkcyjnego. Zobacz Kontrola wdrażania wydania przy użyciu zatwierdzeń.
- Zataguj ponownie obraz platformy Docker dla produkcyjnej przestrzeni nazw w usłudze Azure Container Registry. Jeśli na przykład bieżący tag to
myrepo.azurecr.io/delivery:v1.0.2, tag produkcyjny tomyrepo.azurecr.io/prod/delivery:v1.0.2. - Wdróż wykres Helm w środowisku produkcyjnym.
Nawet w monorepo te zadania mogą być ograniczone do poszczególnych mikrousług, aby zespoły mogły wdrażać z dużą szybkością. Proces zawiera kilka ręcznych kroków: zatwierdzanie żądań ściągnięcia, tworzenie gałęzi wydania i zatwierdzanie wdrożeń w klastrze produkcyjnym. Te kroki są wykonywane ręcznie; mogą być zautomatyzowane, jeśli organizacja woli.
Izolacja środowisk
Będziesz mieć wiele środowisk, w których wdrażasz usługi, w tym środowiska do programowania, testowania weryfikacyjnego kompilacji, testowania integracji, testowania obciążenia, a na koniec środowiska produkcyjnego. Te środowiska wymagają pewnego poziomu izolacji. Na platformie Kubernetes masz wybór między izolacją fizyczną a izolacją logiczną. Izolacja fizyczna oznacza wdrażanie w oddzielnych klastrach. Izolacja logiczna używa przestrzeni nazw i zasad zgodnie z wcześniejszym opisem.
Naszym zaleceniem jest utworzenie dedykowanego klastra produkcyjnego wraz z oddzielnym klastrem dla środowisk deweloperskich/testowych. Użyj izolacji logicznej, aby oddzielić środowiska w klastrze deweloperskim/testowym. Usługi wdrożone w klastrze deweloperskim/testowym nigdy nie powinny mieć dostępu do magazynów danych, które przechowują dane biznesowe.
Proces kompilacji
Jeśli to możliwe, spakuj proces kompilacji do kontenera platformy Docker. Ta konfiguracja umożliwia tworzenie artefaktów kodu przy użyciu platformy Docker i bez konfigurowania środowiska kompilacji na każdej maszynie kompilacji. Konteneryzowany proces kompilacji ułatwia skalowanie potoku ciągłej integracji przez dodanie nowych agentów kompilacji. Ponadto każdy deweloper zespołu może skompilować kod po prostu, uruchamiając kontener kompilacji.
Korzystając z wieloetapowych kompilacji na platformie Docker, można zdefiniować środowisko kompilacji i obraz środowiska uruchomieniowego w jednym pliku Dockerfile. Oto na przykład plik Dockerfile, który kompiluje aplikację .NET:
FROM mcr.microsoft.com/dotnet/core/runtime:3.1 AS base
WORKDIR /app
FROM mcr.microsoft.com/dotnet/core/sdk:3.1 AS build
WORKDIR /src/Fabrikam.Workflow.Service
COPY Fabrikam.Workflow.Service/Fabrikam.Workflow.Service.csproj .
RUN dotnet restore Fabrikam.Workflow.Service.csproj
COPY Fabrikam.Workflow.Service/. .
RUN dotnet build Fabrikam.Workflow.Service.csproj -c release -o /app --no-restore
FROM build AS testrunner
WORKDIR /src/tests
COPY Fabrikam.Workflow.Service.Tests/*.csproj .
RUN dotnet restore Fabrikam.Workflow.Service.Tests.csproj
COPY Fabrikam.Workflow.Service.Tests/. .
ENTRYPOINT ["dotnet", "test", "--logger:trx"]
FROM build AS publish
RUN dotnet publish Fabrikam.Workflow.Service.csproj -c Release -o /app
FROM base AS final
WORKDIR /app
COPY --from=publish /app .
ENTRYPOINT ["dotnet", "Fabrikam.Workflow.Service.dll"]
Ten plik Dockerfile definiuje kilka etapów kompilacji. Zwróć uwagę, że etap o nazwie base używa środowiska uruchomieniowego platformy .NET, podczas gdy etap o nazwie build używa pełnego zestawu .NET SDK. Etap build służy do kompilowania projektu platformy .NET. Jednak końcowy kontener środowiska uruchomieniowego jest kompilowany z baseprogramu , który zawiera tylko środowisko uruchomieniowe i jest znacznie mniejszy niż pełny obraz zestawu SDK.
Tworzenie modułu uruchamiającego testy
Innym dobrym rozwiązaniem jest uruchamianie testów jednostkowych w kontenerze. Na przykład poniżej znajduje się część pliku platformy Docker, który kompiluje moduł uruchamiający testy:
FROM build AS testrunner
WORKDIR /src/tests
COPY Fabrikam.Workflow.Service.Tests/*.csproj .
RUN dotnet restore Fabrikam.Workflow.Service.Tests.csproj
COPY Fabrikam.Workflow.Service.Tests/. .
ENTRYPOINT ["dotnet", "test", "--logger:trx"]
Deweloper może użyć tego pliku platformy Docker do uruchamiania testów lokalnie:
docker build . -t delivery-test:1 --target=testrunner
docker run delivery-test:1
Potok ciągłej integracji powinien również uruchamiać testy w ramach kroku weryfikacji kompilacji.
Należy pamiętać, że ten plik używa polecenia platformy Docker ENTRYPOINT do uruchamiania testów, a nie polecenia platformy Docker RUN .
- Jeśli używasz
RUNpolecenia , testy są uruchamiane za każdym razem, gdy kompilujesz obraz. Przy użyciuENTRYPOINTmetody testy są opt-in. Są one uruchamiane tylko w przypadku jawnego określania celu etaputestrunner. - Test kończący się niepowodzeniem nie powoduje niepowodzenia polecenia platformy Docker
build. Dzięki temu można odróżnić błędy kompilacji kontenera od niepowodzeń testów. - Wyniki testów można zapisać na zainstalowanym woluminie.
Najlepsze rozwiązania dotyczące kontenerów
Oto kilka innych najlepszych rozwiązań, które należy wziąć pod uwagę w przypadku kontenerów:
Zdefiniuj konwencje dla całej organizacji dotyczące tagów kontenerów, przechowywania wersji i konwencji nazewnictwa zasobów wdrożonych w klastrze (zasobników, usług itd.). Ułatwia to diagnozowanie problemów z wdrażaniem.
Podczas cyklu programowania i testowania proces ciągłej integracji/ciągłego wdrażania skompiluje wiele obrazów kontenerów. Tylko niektóre z tych obrazów są kandydatami do wydania, a następnie tylko niektórzy z tych kandydatów do wydania zostaną awansowane do produkcji. Masz wyraźną strategię przechowywania wersji, aby wiedzieć, które obrazy są obecnie wdrażane w środowisku produkcyjnym i w razie potrzeby ułatwić wycofanie się z poprzedniej wersji.
Zawsze wdrażaj określone tagi wersji kontenera, a nie
latest.Użyj przestrzeni nazw w usłudze Azure Container Registry, aby odizolować obrazy zatwierdzone do produkcji z obrazów, które są nadal testowane. Nie przenosij obrazu do produkcyjnej przestrzeni nazw, dopóki nie będzie można go wdrożyć w środowisku produkcyjnym. Jeśli połączysz tę praktykę z semantycznym przechowywaniem wersji obrazów kontenerów, może to zmniejszyć prawdopodobieństwo przypadkowego wdrożenia wersji, która nie została zatwierdzona do wydania.
Postępuj zgodnie z zasadą najniższych uprawnień, uruchamiając kontenery jako nieuprzywilejowanego użytkownika. Na platformie Kubernetes można utworzyć zasady zabezpieczeń zasobnika, które uniemożliwiają uruchamianie kontenerów jako katalog główny.
Pakiety programu Helm
Rozważ użycie programu Helm do zarządzania tworzeniem i wdrażaniem usług. Oto niektóre funkcje programu Helm, które ułatwiają ciągłą integrację/ciągłe wdrażanie:
- Często pojedyncza mikrousługa jest definiowana przez wiele obiektów Kubernetes. Program Helm umożliwia spakować te obiekty do pojedynczego wykresu programu Helm.
- Wykres można wdrożyć za pomocą jednego polecenia helm, a nie serii poleceń kubectl.
- Wykresy są jawnie wersjonowane. Użyj programu Helm, aby zwolnić wersję, wyświetlić wydania i przywrócić poprzednią wersję. Śledzenie aktualizacji i poprawek przy użyciu semantycznego przechowywania wersji oraz możliwość wycofania się z poprzedniej wersji.
- Wykresy programu Helm używają szablonów, aby uniknąć duplikowania informacji, takich jak etykiety i selektory, w wielu plikach.
- Program Helm może zarządzać zależnościami między wykresami.
- Wykresy można przechowywać w repozytorium programu Helm, takim jak Usługa Azure Container Registry, i zintegrowane z potokiem kompilacji.
Aby uzyskać więcej informacji na temat używania usługi Container Registry jako repozytorium helm, zobacz Używanie usługi Azure Container Registry jako repozytorium Helm dla wykresów aplikacji.
Pojedyncza mikrousługa może obejmować wiele plików konfiguracji platformy Kubernetes. Aktualizowanie usługi może oznaczać dotknięcie wszystkich tych plików w celu zaktualizowania selektorów, etykiet i tagów obrazów. Program Helm traktuje je jako pojedynczy pakiet nazywany wykresem i umożliwia łatwe aktualizowanie plików YAML przy użyciu zmiennych. Program Helm używa języka szablonu (opartego na szablonach języka Go), aby umożliwić pisanie sparametryzowanych plików konfiguracji YAML.
Oto na przykład część pliku YAML definiującego wdrożenie:
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ include "package.fullname" . | replace "." "" }}
labels:
app.kubernetes.io/name: {{ include "package.name" . }}
app.kubernetes.io/instance: {{ .Release.Name }}
annotations:
kubernetes.io/change-cause: {{ .Values.reason }}
...
spec:
containers:
- name: &package-container_name fabrikam-package
image: {{ .Values.dockerregistry }}/{{ .Values.image.repository }}:{{ .Values.image.tag }}
imagePullPolicy: {{ .Values.image.pullPolicy }}
env:
- name: LOG_LEVEL
value: {{ .Values.log.level }}
Widać, że nazwa wdrożenia, etykiety i specyfikacje kontenera używają wszystkich parametrów szablonu, które są udostępniane w czasie wdrażania. Na przykład z wiersza polecenia:
helm install $HELM_CHARTS/package/ \
--set image.tag=0.1.0 \
--set image.repository=package \
--set dockerregistry=$ACR_SERVER \
--namespace backend \
--name package-v0.1.0
Mimo że potok ciągłej integracji/ciągłego wdrażania może zainstalować wykres bezpośrednio na platformie Kubernetes, zalecamy utworzenie archiwum wykresu (plik tgz) i wypchnięcie wykresu do repozytorium helm, takiego jak usługa Azure Container Registry. Aby uzyskać więcej informacji, zobacz Package Docker-based apps in Helm charts in Azure Pipelines (Tworzenie pakietów aplikacji opartych na platformie Docker na wykresach helm w usłudze Azure Pipelines).
Poprawki
Wykresy programu Helm zawsze mają numer wersji, który musi używać semantycznego przechowywania wersji. Wykres może również mieć element appVersion. To pole jest opcjonalne i nie musi być powiązane z wersją wykresu. Niektóre zespoły mogą chcieć korzystać z wersji aplikacji niezależnie od aktualizacji wykresów. Jednak prostszą metodą jest użycie jednego numeru wersji, więc istnieje relacja 1:1 między wersją wykresu a wersją aplikacji. Dzięki temu można przechowywać jeden wykres na wydanie i łatwo wdrożyć odpowiednią wersję:
helm install <package-chart-name> --version <desiredVersion>
Innym dobrym rozwiązaniem jest zapewnienie adnotacji powodującej zmianę w szablonie wdrożenia:
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ include "delivery.fullname" . | replace "." "" }}
labels:
...
annotations:
kubernetes.io/change-cause: {{ .Values.reason }}
Dzięki temu można wyświetlić pole zmiany przyczyny dla każdej poprawki przy użyciu kubectl rollout history polecenia . W poprzednim przykładzie przyczyna zmiany jest dostarczana jako parametr wykresu Helm.
kubectl rollout history deployments/delivery-v010 -n backend
deployment.extensions/delivery-v010
REVISION CHANGE-CAUSE
1 Initial deployment
Możesz również użyć helm list polecenia , aby wyświetlić historię poprawek:
helm list
NAME REVISION UPDATED STATUS CHART APP VERSION NAMESPACE
delivery-v0.1.0 1 Sun Apr 7 00:25:30 2020 DEPLOYED delivery-v0.1.0 v0.1.0 backend
Potok usługi Azure DevOps
W usłudze Azure Pipelines potoki są podzielone na potoki kompilacji i potoki wydania. Potok kompilacji uruchamia proces ciągłej integracji i tworzy artefakty kompilacji. W przypadku architektury mikrousług na platformie Kubernetes te artefakty to obrazy kontenerów i wykresy helm definiujące każdą mikrousługę. Potok wydania uruchamia ten proces ciągłego wdrażania, który wdraża mikrousługę w klastrze.
Na podstawie przepływu ciągłej integracji opisanego wcześniej w tym artykule potok kompilacji może składać się z następujących zadań:
Skompiluj kontener modułu uruchamiającego testy przy użyciu
Dockerzadania .Uruchom testy, wywołując polecenie docker run względem kontenera modułu uruchamiającego testy.
DockerUżywa tego zadania.Opublikuj wyniki testu przy użyciu
PublishTestResultszadania . Zobacz Tworzenie obrazu.Skompiluj kontener środowiska uruchomieniowego przy użyciu lokalnej kompilacji platformy Docker i
Dockerzadania lub przy użyciu kompilacji usługi Azure Container Registry iAzureCLIzadania.Wypchnij obraz kontenera do usługi Azure Container Registry (lub innego rejestru kontenerów) przy użyciu zadań
DockerlubAzureCLI.Spakuj wykres Helm przy użyciu
HelmDeployzadania .Wypchnij pakiet Helm do usługi Azure Container Registry (lub innego repozytorium Helm) przy użyciu
HelmDeployzadania .
Dane wyjściowe z potoku ciągłej integracji to obraz kontenera gotowy do produkcji i zaktualizowany wykres helm dla mikrousługi. W tym momencie potok wydania może przejąć. Dla każdej mikrousługi będzie dostępny unikatowy potok wydania. Potok wydania zostanie skonfigurowany tak, aby źródło wyzwalacza było ustawione na potok ciągłej integracji, który opublikował artefakt. Ten potok umożliwia niezależne wdrożenia każdej mikrousługi. Potok wydania wykonuje następujące czynności:
- Wdróż pakiet Helm w środowiskach deweloperskich/qa/przejściowych. Polecenie
helm upgrademoże być używane z flagą--installdo obsługi pierwszej instalacji i kolejnych uaktualnień. - Poczekaj na zatwierdzenie lub odrzucenie wdrożenia przez osoby zatwierdzające.
- Ponownetaguj obraz kontenera pod kątem wydania
- Wypchnij tag wydania do rejestru kontenerów.
- Wdróż wykres Helm w klastrze produkcyjnym.
Aby uzyskać więcej informacji na temat tworzenia potoku wydania, zobacz Release pipelines, draft releases, and release options (Potoki wydania, wersje robocze i opcje wydania).
Na poniższym diagramie przedstawiono pełny proces ciągłej integracji/ciągłego wdrażania opisany w tym artykule:
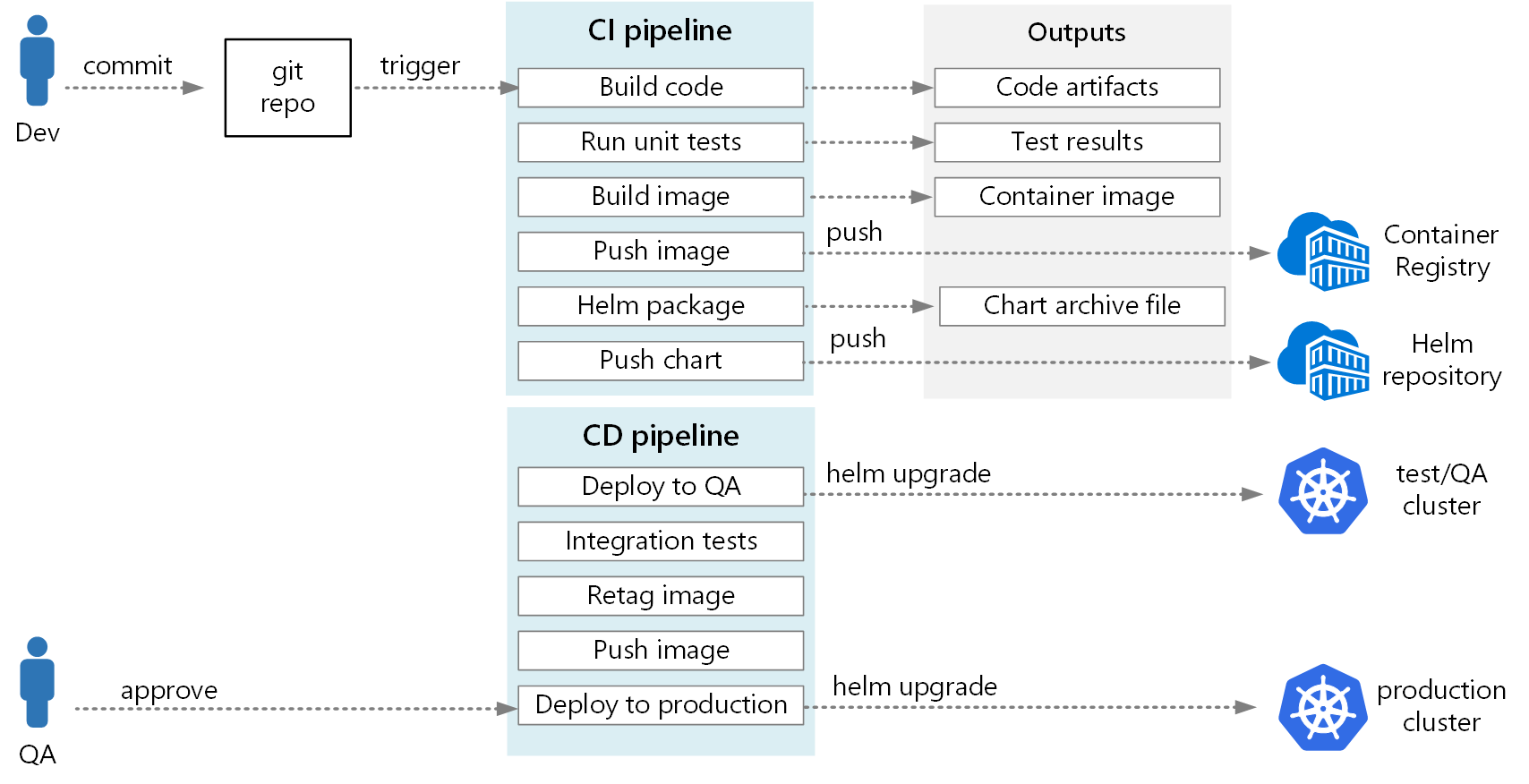
Następne kroki
- Adopt a Git branching strategy (Stosowanie strategii rozgałęziania systemu Git)
- Co to jest usługa Azure Pipelines?
- Potoki wydania, wersje robocze i opcje wydania
- Kontrolowanie wdrożenia wydania przy użyciu zatwierdzeń
- Wprowadzenie do rejestrów kontenerów na platformie Azure