Metody architektury dla sztucznej inteligencji i uczenia maszynowego w rozwiązaniach wielodostępnych
Coraz większa liczba wielodostępnych rozwiązań jest tworzona na podstawie sztucznej inteligencji (AI) i uczenia maszynowego (ML). Wielodostępne rozwiązanie sztucznej inteligencji/uczenia maszynowego to rozwiązanie, które zapewnia podobne możliwości oparte na uczeniu maszynowym do dowolnej liczby dzierżaw. Dzierżawcy zazwyczaj nie widzą ani nie udostępniają danych żadnej innej dzierżawy, ale w niektórych sytuacjach dzierżawcy mogą używać tych samych modeli co inne dzierżawy.
Wielodostępne architektury sztucznej inteligencji/uczenia maszynowego muszą uwzględniać wymagania dotyczące danych i modeli, a także zasoby obliczeniowe wymagane do trenowania modeli i wnioskowania z modeli. Ważne jest, aby wziąć pod uwagę sposób wdrażania, dystrybuowania i organizowania wielodostępnych modeli sztucznej inteligencji/uczenia maszynowego oraz zapewnienia, że rozwiązanie jest dokładne, niezawodne i skalowalne.
Jako technologie generowania sztucznej inteligencji, obsługiwane zarówno przez duże, jak i małe modele językowe, zyskujesz popularność, kluczowe jest ustanowienie skutecznych praktyk operacyjnych i strategii zarządzania tymi modelami w środowiskach produkcyjnych za pośrednictwem wdrażania operacji uczenia maszynowego (MLOps) i GenAIOps (czasami nazywanych LLMOps).
Kluczowe zagadnienia i wymagania
Podczas pracy ze sztuczną inteligencją i uczeniem maszynowym ważne jest, aby oddzielnie wziąć pod uwagę wymagania dotyczące trenowania i wnioskowania. Celem szkolenia jest utworzenie modelu predykcyjnego opartego na zestawie danych. Wnioskowanie jest wykonywane, gdy używasz modelu do przewidywania czegoś w aplikacji. Każdy z tych procesów ma inne wymagania. W rozwiązaniu wielodostępnym należy rozważyć, w jaki sposób model dzierżawy wpływa na każdy proces. Biorąc pod uwagę każde z tych wymagań, możesz upewnić się, że rozwiązanie zapewnia dokładne wyniki, działa dobrze pod obciążeniem, jest opłacalne i może skalować w przyszłości.
Izolacja dzierżawy
Upewnij się, że dzierżawy nie uzyskują nieautoryzowanego ani niechcianego dostępu do danych lub modeli innych dzierżaw. Traktuj modele z podobną poufnością do danych pierwotnych, które je wytrenowały. Upewnij się, że dzierżawcy rozumieją, w jaki sposób ich dane są używane do trenowania modeli i jak modele trenowane na danych innych dzierżaw mogą być używane do celów wnioskowania na ich obciążeniach.
Istnieją trzy typowe podejścia do pracy z modelami uczenia maszynowego w rozwiązaniach wielodostępnych: modele specyficzne dla dzierżawy, modele udostępnione i dostrojone modele udostępnione.
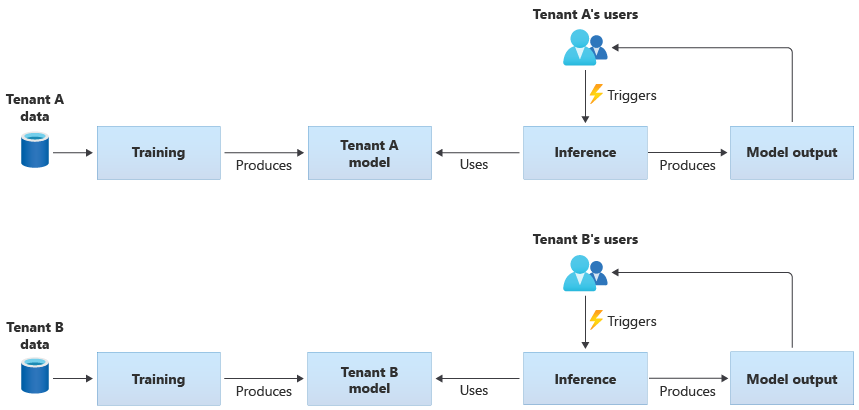
Modele specyficzne dla dzierżawy
Modele specyficzne dla dzierżawy są trenowane tylko na danych dla jednej dzierżawy, a następnie są stosowane do tej pojedynczej dzierżawy. Modele specyficzne dla dzierżawy są odpowiednie, gdy dane dzierżawy są poufne lub gdy istnieje niewielki zakres, aby dowiedzieć się na podstawie danych dostarczonych przez jedną dzierżawę i zastosować model do innej dzierżawy. Na poniższym diagramie przedstawiono sposób tworzenia rozwiązania z modelami specyficznymi dla dzierżawy dla dwóch dzierżaw:
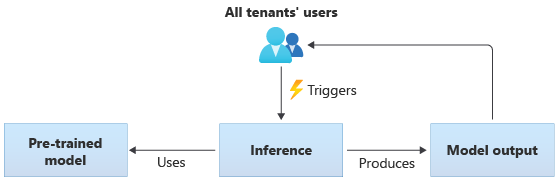
Modele udostępnione
W rozwiązaniach korzystających z modeli udostępnionych wszystkie dzierżawy wykonują wnioskowanie na podstawie tego samego modelu udostępnionego. Modele udostępnione mogą być wstępnie wytrenowane, które uzyskujesz lub uzyskujesz ze źródła społeczności. Na poniższym diagramie przedstawiono sposób użycia pojedynczego wstępnie wytrenowanego modelu do wnioskowania przez wszystkich dzierżawców:
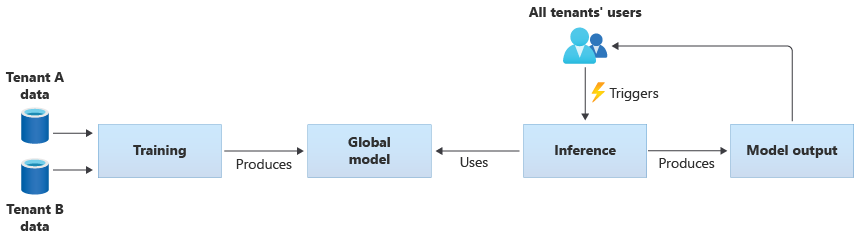
Możesz również tworzyć własne modele udostępnione, szkoląc je na podstawie danych dostarczonych przez wszystkie dzierżawy. Na poniższym diagramie przedstawiono pojedynczy model udostępniony, który jest trenowany na danych ze wszystkich dzierżaw:
Ważne
Jeśli wytrenujesz model udostępniony na podstawie danych dzierżawy, upewnij się, że dzierżawcy rozumieją i zgadzają się na korzystanie z ich danych. Upewnij się, że informacje identyfikujące są usuwane z danych dzierżawców.
Rozważ, co zrobić, jeśli obiekty dzierżawy do ich danych są używane do trenowania modelu, który zostanie zastosowany do innej dzierżawy. Czy na przykład można wykluczyć dane określonych dzierżaw z zestawu danych treningowych?
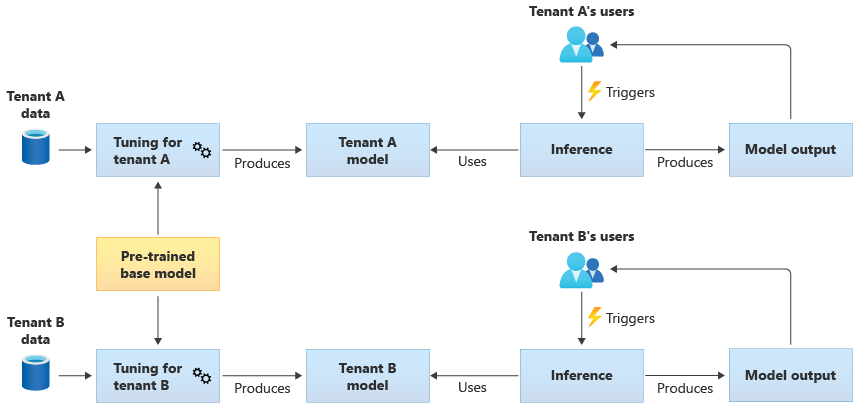
Dostrojone modele udostępnione
Możesz również uzyskać wstępnie wytrenowany model podstawowy, a następnie przeprowadzić dalsze dostrajanie modelu, aby zastosować go do każdej dzierżawy na podstawie własnych danych. Na poniższym diagramie przedstawiono to podejście:
Skalowalność
Zastanów się, jak rozwój rozwiązania wpływa na użycie składników sztucznej inteligencji i uczenia maszynowego. Wzrost może odnosić się do zwiększenia liczby dzierżaw, ilości danych przechowywanych dla każdej dzierżawy, liczby użytkowników i liczby żądań do rozwiązania.
Trenowanie: istnieje kilka czynników mających wpływ na zasoby wymagane do trenowania modeli. Czynniki te obejmują liczbę modeli potrzebnych do wytrenowania, ilość danych trenowanych za pomocą modeli oraz częstotliwość trenowania lub ponownego trenowania modeli. Jeśli tworzysz modele specyficzne dla dzierżawy, wraz ze wzrostem liczby dzierżaw, ilość potrzebnych zasobów obliczeniowych i magazynu również będzie prawdopodobnie rosnąć. Jeśli tworzysz modele udostępnione i trenujesz je na podstawie danych ze wszystkich dzierżaw, mniej prawdopodobne jest, że zasoby na potrzeby trenowania będą skalowane w tym samym tempie co wzrost liczby dzierżaw. Jednak zwiększenie ogólnej ilości danych treningowych wpłynie na używane zasoby w celu wytrenowania zarówno modeli udostępnionych, jak i modeli specyficznych dla dzierżawy.
Wnioskowanie: zasoby wymagane do wnioskowania są zwykle proporcjonalne do liczby żądań, które uzyskują dostęp do modeli na potrzeby wnioskowania. W miarę wzrostu liczby dzierżaw, liczba żądań może również wzrosnąć.
Dobrym rozwiązaniem jest użycie usług platformy Azure, które dobrze skaluje się. Ponieważ obciążenia sztucznej inteligencji/uczenia maszynowego mają tendencję do korzystania z kontenerów, usługi Azure Kubernetes Service (AKS) i usługi Azure Container Instances (ACI) zwykle są typowymi opcjami obciążeń sztucznej inteligencji/uczenia maszynowego. Usługa AKS jest zazwyczaj dobrym wyborem do włączenia dużej skali i dynamicznego skalowania zasobów obliczeniowych na podstawie zapotrzebowania. W przypadku małych obciążeń usługa ACI może być prostą platformą obliczeniową do skonfigurowania, chociaż nie jest tak łatwo skalowana jak usługa AKS.
Wydajność
Weź pod uwagę wymagania dotyczące wydajności składników sztucznej inteligencji/uczenia maszynowego rozwiązania w celu trenowania i wnioskowania. Ważne jest, aby wyjaśnić wymagania dotyczące opóźnień i wydajności dla każdego procesu, aby można było mierzyć i ulepszać zgodnie z potrzebami.
Trenowanie: trenowanie jest często wykonywane jako proces wsadowy, co oznacza, że może nie być tak wrażliwe na wydajność, jak inne części obciążenia. Należy jednak upewnić się, że aprowizujesz wystarczające zasoby do wydajnego trenowania modelu, w tym w miarę skalowania.
Wnioskowanie: wnioskowanie jest procesem wrażliwym na opóźnienia, często wymagającym szybkiej, a nawet w czasie rzeczywistym odpowiedzi. Nawet jeśli nie musisz wnioskować w czasie rzeczywistym, upewnij się, że monitorujesz wydajność rozwiązania i używasz odpowiednich usług do optymalizacji obciążenia.
Rozważ użycie możliwości obliczeń o wysokiej wydajności platformy Azure dla obciążeń sztucznej inteligencji i uczenia maszynowego. Platforma Azure udostępnia wiele różnych typów maszyn wirtualnych i innych wystąpień sprzętu. Zastanów się, czy rozwiązanie może korzystać z procesorów CPU, procesorów GPU, układów FPGA lub innych środowisk przyspieszanych sprzętowo. Platforma Azure zapewnia również wnioskowanie w czasie rzeczywistym z procesorami GPU FIRMY NVIDIA, w tym serwerami wnioskowania NVIDIA Triton. W przypadku wymagań obliczeniowych o niskim priorytcie rozważ użycie pul węzłów typu spot usługi AKS. Aby dowiedzieć się więcej na temat optymalizowania usług obliczeniowych w rozwiązaniu wielodostępnym, zobacz Podejścia architektury do obliczeń w rozwiązaniach wielodostępnych.
Trenowanie modelu zwykle wymaga wielu interakcji z magazynami danych, dlatego ważne jest również, aby wziąć pod uwagę strategię danych i wydajność zapewnianą przez warstwę danych. Aby uzyskać więcej informacji na temat wielodostępności i usług danych, zobacz Metody architektury magazynowania i danych w rozwiązaniach wielodostępnych.
Rozważ profilowanie wydajności rozwiązania. Na przykład usługa Azure Machine Learning udostępnia możliwości profilowania, których można użyć podczas opracowywania i instrumentowania rozwiązania.
Złożoność implementacji
Podczas tworzenia rozwiązania do używania sztucznej inteligencji i uczenia maszynowego możesz użyć wstępnie utworzonych składników lub utworzyć składniki niestandardowe. Istnieją dwie kluczowe decyzje, które należy podjąć. Pierwsza to platforma lub usługa używana na potrzeby sztucznej inteligencji i uczenia maszynowego. Drugim jest to, czy używasz wstępnie wytrenowanych modeli, czy tworzysz własne modele niestandardowe.
Platformy: istnieje wiele usług platformy Azure, których można używać na potrzeby obciążeń sztucznej inteligencji i uczenia maszynowego. Na przykład usługi Azure AI Services i Azure OpenAI Service udostępniają interfejsy API do wnioskowania względem wstępnie utworzonych modeli, a firma Microsoft zarządza bazowymi zasobami. Usługi Azure AI umożliwiają szybkie wdrażanie nowego rozwiązania, ale zapewnia mniejszą kontrolę nad sposobem trenowania i wnioskowania oraz może nie odpowiadać każdemu typowi obciążenia. Z kolei usługa Azure Machine Learning to platforma, która umożliwia tworzenie, trenowanie i używanie własnych modeli uczenia maszynowego. Usługa Azure Machine Learning zapewnia kontrolę i elastyczność, ale zwiększa złożoność projektu i implementacji. Zapoznaj się z produktami i technologiami uczenia maszynowego firmy Microsoft , aby podjąć świadomą decyzję podczas wybierania podejścia.
Modele: nawet jeśli nie używasz pełnego modelu udostępnianego przez usługę, takiej jak usługi Azure AI Services, nadal możesz przyspieszyć opracowywanie przy użyciu wstępnie wytrenowanego modelu. Jeśli wstępnie wytrenowany model nie pasuje dokładnie do Twoich potrzeb, rozważ rozszerzenie wstępnie wytrenowanego modelu, stosując technikę o nazwie uczenie transferowe lub dostrajanie. Uczenie transferowe umożliwia rozszerzenie istniejącego modelu i zastosowanie go do innej domeny. Jeśli na przykład tworzysz wielodostępną usługę rekomendacji dotyczących muzyki, możesz rozważyć utworzenie wstępnie wytrenowanego modelu zaleceń dotyczących muzyki i użycie uczenia transferowego w celu wytrenowania modelu dla preferencji dotyczących muzyki określonego użytkownika.
Korzystając ze wstępnie utworzonych platform uczenia maszynowego, takich jak usługi Azure AI Services lub Azure OpenAI Service lub wstępnie wytrenowanego modelu, można znacznie zmniejszyć początkowe koszty badań i programowania. Korzystanie ze wstępnie utworzonych platform może zaoszczędzić wiele miesięcy badań i uniknąć konieczności rekrutacji wysoko wykwalifikowanych analityków danych do trenowania, projektowania i optymalizowania modeli.
Optymalizacja kosztów
Ogólnie rzecz biorąc, obciążenia sztucznej inteligencji i uczenia maszynowego generują największy odsetek kosztów z zasobów obliczeniowych wymaganych do trenowania i wnioskowania modelu. Zapoznaj się z podejściami architektury do obliczeń w rozwiązaniach wielodostępnych, aby zrozumieć, jak zoptymalizować koszt obciążenia obliczeniowego pod kątem wymagań.
Podczas planowania kosztów sztucznej inteligencji i uczenia maszynowego należy wziąć pod uwagę następujące wymagania:
- Określanie jednostek SKU obliczeniowych na potrzeby trenowania. Zapoznaj się na przykład ze wskazówkami dotyczącymi tego, jak to zrobić za pomocą usługi Azure Machine Learning.
- Określanie jednostek SKU obliczeniowych na potrzeby wnioskowania. Aby zapoznać się z przykładowym oszacowaniem kosztów wnioskowania, zapoznaj się ze wskazówkami dotyczącymi usługi Azure Machine Learning.
- Monitoruj wykorzystanie. Obserwując wykorzystanie zasobów obliczeniowych, możesz określić, czy należy zmniejszyć lub zwiększyć ich pojemność, wdrażając różne jednostki SKU, czy skalowając zasoby obliczeniowe w miarę zmiany wymagań. Zobacz Azure Machine Learning Monitor.
- Zoptymalizuj środowisko klastrowania obliczeniowego. W przypadku korzystania z klastrów obliczeniowych należy monitorować użycie klastra lub konfigurować skalowanie automatyczne w celu skalowania węzłów obliczeniowych w dół.
- Udostępnianie zasobów obliczeniowych. Zastanów się, czy możesz zoptymalizować koszt zasobów obliczeniowych, udostępniając je w wielu dzierżawach.
- Rozważ budżet. Dowiedz się, czy masz stały budżet i odpowiednio monitoruj zużycie. Budżety można skonfigurować, aby zapobiec nadmiernym wypłaceniu i przydzielić limity przydziału na podstawie priorytetu dzierżawy.
Podejścia i wzorce do rozważenia
Platforma Azure udostępnia zestaw usług umożliwiających obsługę obciążeń sztucznej inteligencji i uczenia maszynowego. Istnieje kilka typowych metod architektury używanych w rozwiązaniach wielodostępnych: do używania wstępnie utworzonych rozwiązań sztucznej inteligencji/uczenia maszynowego w celu utworzenia niestandardowej architektury sztucznej inteligencji/uczenia maszynowego przy użyciu usługi Azure Machine Learning i korzystania z jednej z platform analitycznych platformy Azure.
Korzystanie ze wstępnie utworzonych usług sztucznej inteligencji/uczenia maszynowego
Dobrym rozwiązaniem jest wypróbowanie wstępnie utworzonych usług sztucznej inteligencji/uczenia maszynowego, gdzie można. Na przykład twoja organizacja może zaczynać patrzeć na sztuczną inteligencję/uczenie maszynowe i szybko integrować się z przydatną usługą. Możesz też mieć podstawowe wymagania, które nie wymagają niestandardowego trenowania i opracowywania modeli uczenia maszynowego. Wstępnie utworzone usługi uczenia maszynowego umożliwiają korzystanie z wnioskowania bez tworzenia i trenowania własnych modeli.
Platforma Azure oferuje kilka usług, które zapewniają technologię sztucznej inteligencji i uczenia maszynowego w różnych domenach, w tym informacje o języku, rozpoznawanie mowy, wiedzę, rozpoznawanie dokumentów i formularzy oraz przetwarzanie obrazów. Wstępnie utworzone usługi sztucznej inteligencji/uczenia maszynowego platformy Azure obejmują usługi Azure AI, Azure OpenAI Service, Azure AI Search i Azure AI Document Intelligence. Każda usługa udostępnia prosty interfejs do integracji oraz kolekcję wstępnie wytrenowanych i przetestowanych modeli. Jako usługi zarządzane zapewniają umowy dotyczące poziomu usług i wymagają niewielkiej konfiguracji lub ciągłego zarządzania. Nie musisz opracowywać ani testować własnych modeli, aby korzystać z tych usług.
Wiele zarządzanych usług uczenia maszynowego nie wymaga trenowania modelu ani danych, więc zwykle nie ma problemów z izolacją danych dzierżawy. Jednak podczas pracy z wyszukiwaniem sztucznej inteligencji w rozwiązaniu wielodostępnym zapoznaj się z artykułem Wzorce projektowania dla wielodostępnych aplikacji SaaS i usługi Azure AI Search.
Weź pod uwagę wymagania dotyczące skalowania składników w rozwiązaniu. Na przykład wiele interfejsów API w usługach Azure AI obsługuje maksymalną liczbę żądań na sekundę. Jeśli wdrożysz pojedynczy zasób usług sztucznej inteligencji, który będzie współużytkować w dzierżawach, w miarę wzrostu liczby dzierżaw może być konieczne skalowanie do wielu zasobów.
Uwaga
Niektóre usługi zarządzane umożliwiają trenowanie przy użyciu własnych danych, w tym usługi Custom Vision, interfejsu API rozpoznawania twarzy, modeli niestandardowych analizy dokumentów i niektórych modeli OpenAI, które obsługują dostosowywanie i precyzyjne tworzenie. Podczas pracy z tymi usługami ważne jest, aby wziąć pod uwagę wymagania dotyczące izolacji danych dzierżawy.
Niestandardowa architektura sztucznej inteligencji/uczenia maszynowego
Jeśli twoje rozwiązanie wymaga modeli niestandardowych lub pracujesz w domenie, która nie jest objęta usługą zarządzanego uczenia maszynowego, rozważ utworzenie własnej architektury sztucznej inteligencji/uczenia maszynowego. Usługa Azure Machine Learning udostępnia zestaw funkcji do organizowania trenowania i wdrażania modeli uczenia maszynowego. Usługa Azure Machine Learning obsługuje wiele bibliotek uczenia maszynowego typu open source, w tym PyTorch, TensorFlow, Scikiti Keras. Możesz stale monitorować metryki wydajności modeli, wykrywać dryf danych i wyzwalać ponowne trenowanie w celu zwiększenia wydajności modelu. W całym cyklu życia modeli uczenia maszynowego usługa Azure Machine Learning umożliwia inspekcję i ład dzięki wbudowanym śledzeniu i pochodzeniem wszystkich artefaktów uczenia maszynowego.
Podczas pracy w rozwiązaniu wielodostępnym należy wziąć pod uwagę wymagania dotyczące izolacji dzierżaw podczas etapów trenowania i wnioskowania. Należy również określić proces trenowania i wdrażania modelu. Usługa Azure Machine Learning udostępnia potok do trenowania modeli i wdrażania ich w środowisku, które ma być używane do wnioskowania. W kontekście wielodostępnym należy rozważyć, czy modele powinny być wdrażane w udostępnionych zasobach obliczeniowych, czy też każda dzierżawa ma dedykowane zasoby. Zaprojektuj potoki wdrażania modelu na podstawie modelu izolacji i procesu wdrażania dzierżawy.
W przypadku korzystania z modeli typu open source może być konieczne ponowne trenowanie tych modeli przy użyciu uczenia transferowego lub dostrajania. Zastanów się, jak zarządzać różnymi modelami i danymi treningowymi dla każdej dzierżawy, a także wersjami modelu.
Na poniższym diagramie przedstawiono przykładową architekturę korzystającą z usługi Azure Machine Learning. W przykładzie użyto podejścia izolacji modeli specyficznych dla dzierżawy.
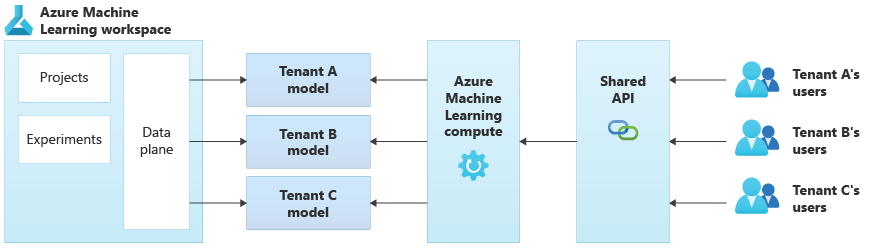
Zintegrowane rozwiązania sztucznej inteligencji/uczenia maszynowego
Platforma Azure udostępnia kilka zaawansowanych platform analitycznych, które mogą być używane w wielu celach. Te platformy obejmują usługi Azure Synapse Analytics, Databricks i Apache Spark.
Możesz rozważyć użycie tych platform na potrzeby sztucznej inteligencji/uczenia maszynowego, gdy konieczne jest skalowanie możliwości uczenia maszynowego do bardzo dużej liczby dzierżaw, a także w przypadku potrzeby dużej liczby zasobów obliczeniowych i orkiestracji na dużą skalę. Możesz również rozważyć użycie tych platform dla sztucznej inteligencji/uczenia maszynowego, jeśli potrzebujesz szerokiej platformy analitycznej dla innych części rozwiązania, takich jak analiza danych i integracja z raportowaniem za pośrednictwem usługi Microsoft Power BI. Możesz wdrożyć jedną platformę, która obejmuje wszystkie potrzeby analizy i sztucznej inteligencji/uczenia maszynowego. Podczas implementowania platform danych w rozwiązaniu wielodostępnym zapoznaj się z artykułem Architektury dotyczące magazynowania i danych w rozwiązaniach wielodostępnych.
Model operacyjny uczenia maszynowego
W przypadku wdrażania sztucznej inteligencji i uczenia maszynowego, w tym praktyk generowania sztucznej inteligencji, dobrym rozwiązaniem jest ciągłe ulepszanie i ocenianie możliwości organizacji w zarządzaniu nimi. Wprowadzenie metodyki MLOps i metodyki GenAIOps obiektywnie zapewnia platformę umożliwiającą ciągłe rozszerzanie możliwości praktyk sztucznej inteligencji i uczenia maszynowego w organizacji. Aby uzyskać więcej wskazówek, zapoznaj się z dokumentami modelu dojrzałości MLOps i modelu dojrzałości LLMOps.
Antywzorzecy, aby uniknąć
- Nie można rozważyć wymagań dotyczących izolacji. Ważne jest, aby dokładnie rozważyć sposób izolowania danych i modeli dzierżaw, zarówno na potrzeby trenowania, jak i wnioskowania. Nie można tego zrobić, może naruszać wymagania prawne lub umowne. Może również zmniejszyć dokładność modeli do trenowania danych wielu dzierżaw, jeśli dane są znacznie inne.
- Hałaśli sąsiedzi. Zastanów się, czy procesy trenowania lub wnioskowania mogą podlegać problemowi Hałaśliwemu sąsiadowi. Jeśli na przykład masz kilka dużych dzierżaw i jednej małej dzierżawy, upewnij się, że trenowanie modelu dla dużych dzierżaw nie przypadkowo zużywa wszystkich zasobów obliczeniowych i głoduje mniejszych dzierżaw. Użyj nadzoru i monitorowania zasobów, aby ograniczyć ryzyko obciążenia obliczeniowego dzierżawy, które ma wpływ na aktywność innych dzierżaw.
Współautorzy
Ten artykuł jest obsługiwany przez firmę Microsoft. Pierwotnie został napisany przez następujących współautorów.
Główny autor:
- Kevin Ashley | Starszy inżynier klienta, fasttrack dla platformy Azure
Inni współautorzy:
- Paul Burpo | Główny inżynier klienta, fasttrack dla platformy Azure
- John Downs | Główny inżynier oprogramowania
- Daniel Scott-Raynsford | Partner TechnologyStrateg
- Arsen Vladimirskiy | Główny inżynier klienta, fasttrack dla platformy Azure
- Vic Perdana | Architekt rozwiązań partnera niezależnego dostawcy oprogramowania
Następne kroki
- Zapoznaj się z podejściami architektury do obliczeń w rozwiązaniach wielodostępnych.
- Aby dowiedzieć się więcej na temat projektowania potoków usługi Azure Machine Learning w celu obsługi wielu dzierżaw, zobacz A Solution for ML Pipeline in Multi-tenancy Manner (Rozwiązanie dla potoku uczenia maszynowego w wielu dzierżawach).