Architektura danych big data jest przeznaczona do obsługi pozyskiwania, przetwarzania i analizy danych, które są zbyt duże lub złożone dla tradycyjnych systemów baz danych.

Rozwiązania do obsługi danych big data zwykle obejmują co najmniej jeden z następujących typów obciążeń:
- Przetwarzanie wsadowe źródeł danych big data magazynowanych.
- Przetwarzanie danych big data w czasie rzeczywistym w ruchu.
- Interaktywna eksploracja danych big data.
- Analiza predykcyjna i uczenie maszynowe.
Większość architektur danych big data obejmuje niektóre lub wszystkie następujące składniki:
Źródła danych: wszystkie rozwiązania do obsługi danych big data zaczynają się od co najmniej jednego źródła danych. Przykładami:
- Magazyny danych aplikacji, takie jak relacyjne bazy danych.
- Pliki statyczne tworzone przez aplikacje, takie jak pliki dziennika serwera internetowego.
- Źródła danych w czasie rzeczywistym, takie jak urządzenia IoT.
magazyn danych: dane na potrzeby operacji przetwarzania wsadowego są zwykle przechowywane w rozproszonym magazynie plików, który może przechowywać duże ilości dużych plików w różnych formatach. Ten rodzaj magazynu jest często nazywany data lake. Opcje implementacji tego magazynu obejmują usługę Azure Data Lake Store lub kontenery obiektów blob w usłudze Azure Storage.
przetwarzania wsadowego: ponieważ zestawy danych są tak duże, często rozwiązanie do przetwarzania danych big data musi przetwarzać pliki danych przy użyciu długotrwałych zadań wsadowych w celu filtrowania, agregowania i przygotowywania w inny sposób danych do analizy. Zazwyczaj te zadania obejmują odczytywanie plików źródłowych, ich przetwarzanie i zapisywanie danych wyjściowych w nowych plikach. Opcje obejmują używanie przepływów danych, potoków danych w usłudze Microsoft Fabric.
pozyskiwanie komunikatów w czasie rzeczywistym: jeśli rozwiązanie zawiera źródła czasu rzeczywistego, architektura musi zawierać sposób przechwytywania i przechowywania komunikatów w czasie rzeczywistym na potrzeby przetwarzania strumienia. Może to być prosty magazyn danych, w którym przychodzące komunikaty są porzucane do folderu do przetwarzania. Jednak wiele rozwiązań wymaga magazynu pozyskiwania komunikatów do działania jako buforu dla komunikatów oraz obsługi przetwarzania skalowalnego w poziomie, niezawodnego dostarczania i innych semantyki kolejkowania komunikatów. Opcje obejmują usługi Azure Event Hubs, Azure IoT Hubs i Kafka.
przetwarzanie strumienia: po przechwyceniu komunikatów w czasie rzeczywistym rozwiązanie musi je przetworzyć, filtrując, agregując i w inny sposób przygotowując dane do analizy. Przetworzone dane strumienia są następnie zapisywane w ujściu danych wyjściowych. Usługa Azure Stream Analytics udostępnia zarządzaną usługę przetwarzania strumienia opartą na wiecznie uruchomionych zapytaniach SQL działających na niezwiązanych strumieniach. Inną opcją jest użycie analizy w czasie rzeczywistym w usłudze Microsoft Fabric, która umożliwia uruchamianie zapytań KQL w miarę pozyskiwania danych.
magazyn danych analitycznych: wiele rozwiązań do analizy danych big data przygotowuje dane do analizy, a następnie obsługuje przetworzone dane w formacie ustrukturyzowanym, do którego można wykonywać zapytania przy użyciu narzędzi analitycznych. Magazyn danych analitycznych używany do obsługi tych zapytań może być magazynem danych relacyjnych w stylu Kimball, jak widać w większości tradycyjnych rozwiązań analizy biznesowej (BI) lub lakehouse z architekturą medalonu (Bronze, Silver i Gold). Usługa Azure Synapse Analytics udostępnia zarządzaną usługę do magazynowania danych na dużą skalę w chmurze. Alternatywnie usługa Microsoft Fabric udostępnia obie opcje — magazyn i magazyn typu lakehouse — które można wykonywać zapytania odpowiednio przy użyciu języka SQL i platformy Spark.
analizy i raportowania: celem większości rozwiązań do obsługi danych big data jest zapewnienie wglądu w dane za pośrednictwem analizy i raportowania. Aby umożliwić użytkownikom analizowanie danych, architektura może obejmować warstwę modelowania danych, taką jak wielowymiarowy moduł OLAP lub model danych tabelarycznych w usługach Azure Analysis Services. Może również obsługiwać samoobsługową usługę BI przy użyciu technologii modelowania i wizualizacji w usłudze Microsoft Power BI lub Microsoft Excel. Analiza i raportowanie mogą również mieć formę interaktywnej eksploracji danych przez analityków danych lub analityków danych. W tych scenariuszach usługa Microsoft Fabric udostępnia narzędzia, takie jak notesy, w których użytkownik może wybrać język SQL lub język programowania.
Orchestration: większość rozwiązań do przetwarzania danych big data składa się z powtarzających się operacji przetwarzania danych, hermetyzowanego w przepływach pracy, które przekształcają dane źródłowe, przenoszą dane między wieloma źródłami i ujściami, ładują przetworzone dane do magazynu danych analitycznych lub wypychają wyniki bezpośrednio do raportu lub pulpitu nawigacyjnego. Aby zautomatyzować te przepływy pracy, możesz użyć technologii orkiestracji, takiej jak potoki usługi Azure Data Factory lub Microsoft Fabric.
Platforma Azure obejmuje wiele usług, które mogą być używane w architekturze danych big data. Należą one mniej więcej do dwóch kategorii:
- Usługi zarządzane, w tym Microsoft Fabric, Azure Data Lake Store, Azure Synapse Analytics, Azure Stream Analytics, Azure Event Hubs, Azure IoT Hub i Azure Data Factory.
- Technologie typu open source oparte na platformie Apache Hadoop, w tym HDFS, HBase, Hive, Spark i Kafka. Te technologie są dostępne na platformie Azure w usłudze Azure HDInsight.
Te opcje nie wykluczają się wzajemnie, a wiele rozwiązań łączy technologie open source z usługami platformy Azure.
Kiedy należy używać tej architektury
Rozważ ten styl architektury, jeśli musisz:
- Przechowywanie i przetwarzanie danych w woluminach zbyt dużych dla tradycyjnej bazy danych.
- Przekształcanie danych bez struktury na potrzeby analizy i raportowania.
- Przechwytywanie, przetwarzanie i analizowanie niezwiązanych strumieni danych w czasie rzeczywistym lub z małym opóźnieniem.
- Użyj usługi Azure Machine Learning lub Azure Cognitive Services.
Korzyści
- Opcje technologii. Możesz mieszać i dopasowywać usługi zarządzane platformy Azure i technologie Apache w klastrach usługi HDInsight, aby wykorzystać istniejące umiejętności lub inwestycje technologiczne.
- wydajność dzięki równoległości. Rozwiązania do obsługi danych big data korzystają z równoległości, umożliwiając rozwiązania o wysokiej wydajności, które są skalowane do dużych ilości danych.
- elastyczne skalowanie. Wszystkie składniki architektury danych big data obsługują aprowizację skalowaną w poziomie, dzięki czemu można dostosować rozwiązanie do małych lub dużych obciążeń i płacić tylko za używane zasoby.
- współdziałanie z istniejącymi rozwiązaniami. Składniki architektury danych big data są również używane do przetwarzania IoT i rozwiązań analizy biznesowej w przedsiębiorstwie, umożliwiając tworzenie zintegrowanego rozwiązania między obciążeniami danych.
Wyzwania
- złożoność. Rozwiązania do obsługi danych big data mogą być niezwykle złożone, z wieloma składnikami do obsługi pozyskiwania danych z wielu źródeł danych. Tworzenie, testowanie i rozwiązywanie problemów z procesami danych big data może być trudne. Ponadto może istnieć duża liczba ustawień konfiguracji w wielu systemach, które muszą być używane w celu optymalizacji wydajności.
- zestaw umiejętności. Wiele technologii danych big data jest wysoce wyspecjalizowanych i używa struktur i języków, które nie są typowe dla bardziej ogólnych architektur aplikacji. Z drugiej strony technologie danych big data ewoluują nowe interfejsy API, które opierają się na bardziej znanych językach.
- Dojrzałość technologii. Wiele technologii używanych w danych big data ewoluuje. Podczas gdy podstawowe technologie Hadoop, takie jak Hive i spark, ustabilizowały się, nowe technologie, takie jak delta lub góra lodowa, wprowadziły obszerne zmiany i ulepszenia. Usługi zarządzane, takie jak Microsoft Fabric, są stosunkowo młode, w porównaniu z innymi usługami platformy Azure i prawdopodobnie ewoluują wraz z upływem czasu.
- Security. Rozwiązania do obsługi danych big data zwykle polegają na przechowywaniu wszystkich danych statycznych w scentralizowanym magazynie data lake. Zabezpieczanie dostępu do tych danych może być trudne, zwłaszcza gdy dane muszą być pozyskiwane i używane przez wiele aplikacji i platform.
Najlepsze rozwiązania
Wykorzystanie równoległości. Większość technologii przetwarzania danych big data dystrybuuje obciążenie w wielu jednostkach przetwarzania. Wymaga to utworzenia i przechowywania plików danych statycznych w formacie splittable. Rozproszone systemy plików, takie jak system plików HDFS, mogą zoptymalizować wydajność odczytu i zapisu, a rzeczywiste przetwarzanie jest wykonywane przez wiele węzłów klastra równolegle, co skraca ogólny czas zadania. Korzystanie z formatu danych z możliwością dzielenia jest zdecydowanie zalecane, na przykład Parquet.
Partycjonowanie danych. Przetwarzanie wsadowe zwykle odbywa się zgodnie z harmonogramem cyklicznym — na przykład co tydzień lub co miesiąc. Partycjonowanie plików danych i struktur danych, takich jak tabele, na podstawie okresów, które są zgodne z harmonogramem przetwarzania. Upraszcza to pozyskiwanie danych i planowanie zadań oraz ułatwia rozwiązywanie problemów z błędami. Ponadto partycjonowanie tabel używanych w zapytaniach Hive, Spark lub SQL może znacznie zwiększyć wydajność zapytań.
zastosuj semantyka schematu do odczytu. Korzystanie z usługi Data Lake umożliwia łączenie magazynu dla plików w wielu formatach, strukturalnych, częściowo ustrukturyzowanych lub bez struktury. Użyj semantyki do odczytu schematu, które projektują schemat na danych podczas przetwarzania danych, a nie podczas przechowywania danych. Zwiększa to elastyczność rozwiązania i zapobiega wąskim gardłom podczas pozyskiwania danych spowodowanego weryfikacją danych i sprawdzaniem typów.
Przetwarzanie danych w miejscu. Tradycyjne rozwiązania analizy biznesowej często używają procesu wyodrębniania, przekształcania i ładowania (ETL) w celu przeniesienia danych do magazynu danych. W przypadku większych ilości danych i większej gamy formatów rozwiązania do obsługi danych big data zwykle używają odmian ETL, takich jak przekształcanie, wyodrębnianie i ładowanie (TEL). Dzięki temu podejściu dane są przetwarzane w rozproszonym magazynie danych, przekształcając je w wymaganą strukturę przed przeniesieniem przekształconych danych do magazynu danych analitycznych.
Równoważenie użycia i kosztów czasu. W przypadku zadań przetwarzania wsadowego należy wziąć pod uwagę dwa czynniki: koszt jednostkowy węzłów obliczeniowych i koszt użycia tych węzłów do ukończenia zadania za minutę. Na przykład zadanie wsadowe może potrwać osiem godzin z czterema węzłami klastra. Jednak może się okazać, że zadanie używa wszystkich czterech węzłów tylko w ciągu pierwszych dwóch godzin, a potem wymagane są tylko dwa węzły. W takim przypadku uruchomienie całego zadania na dwóch węzłach zwiększyłoby całkowity czas zadania, ale nie podwoiłoby go, więc łączny koszt byłby mniejszy. W niektórych scenariuszach biznesowych dłuższy czas przetwarzania może być lepszy od wyższego kosztu korzystania z niedostatecznie używanych zasobów klastra.
oddzielne zasoby. Jeśli to możliwe, należy oddzielić zasoby na podstawie obciążeń, aby uniknąć scenariuszy takich jak jedno obciążenie przy użyciu wszystkich zasobów, podczas gdy inne oczekują.
orkiestracji pozyskiwania danych. W niektórych przypadkach istniejące aplikacje biznesowe mogą zapisywać pliki danych do przetwarzania wsadowego bezpośrednio do kontenerów obiektów blob usługi Azure Storage, gdzie mogą być używane przez usługi podrzędne, takie jak Microsoft Fabric. Jednak często konieczne jest organizowanie pozyskiwania danych z lokalnych lub zewnętrznych źródeł danych do usługi Data Lake. Użyj przepływu pracy orkiestracji lub potoku, takiego jak te obsługiwane przez usługę Azure Data Factory lub Microsoft Fabric, aby osiągnąć to w przewidywalny i centralnie zarządzany sposób.
Czyszczenie poufnych danych na początku. Przepływ pracy pozyskiwania danych powinien na wczesnym etapie procesu wyczyścić poufne dane, aby uniknąć ich przechowywania w usłudze Data Lake.
Architektura IoT
Internet rzeczy (IoT) to wyspecjalizowany podzestaw rozwiązań do obsługi danych big data. Na poniższym diagramie przedstawiono możliwą architekturę logiczną dla IoT. Diagram podkreśla składniki przesyłania strumieniowego zdarzeń architektury.
diagram 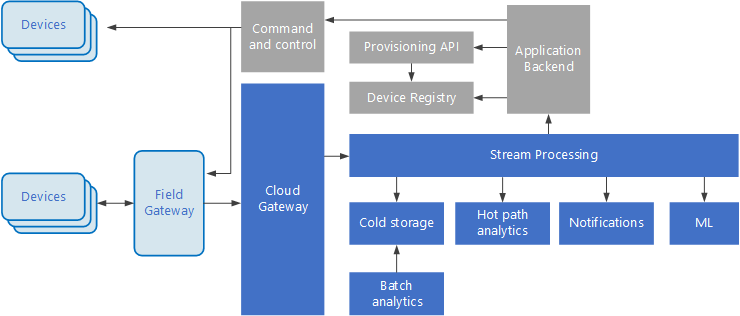
Brama w chmurze pozyskiwać zdarzenia urządzeń na granicy chmury przy użyciu niezawodnego systemu obsługi komunikatów o małych opóźnieniach.
Urządzenia mogą wysyłać zdarzenia bezpośrednio do bramy w chmurze lub za pośrednictwem bramy pola. Brama pola jest wyspecjalizowanym urządzeniem lub oprogramowaniem, które zwykle jest kolokowane z urządzeniami, które odbiera zdarzenia i przekazuje je do bramy w chmurze. Brama pola może również wstępnie przetworzyć nieprzetworzone zdarzenia urządzenia, wykonując funkcje, takie jak filtrowanie, agregacja lub przekształcanie protokołu.
Po pozyskaniu zdarzenia przechodzą przez co najmniej jeden procesor strumienia , które mogą kierować dane (na przykład do magazynu) lub wykonywać analizy i inne przetwarzanie.
Poniżej przedstawiono niektóre typowe typy przetwarzania. (Ta lista z pewnością nie jest wyczerpująca).
Zapisywanie danych zdarzeń w zimnym magazynie na potrzeby archiwizowania lub analizy wsadowej.
Analiza ścieżek gorących, analizowanie strumienia zdarzeń w czasie rzeczywistym (niemal) w celu wykrywania anomalii, rozpoznawania wzorców w oknach kroczenia lub wyzwalania alertów w przypadku wystąpienia określonego warunku w strumieniu.
Obsługa specjalnych typów komunikatów niezwiązanych z telemetrią z urządzeń, takich jak powiadomienia i alarmy.
Uczenie maszynowe.
Pola, które są zacienione szare, pokazują składniki systemu IoT, które nie są bezpośrednio związane z przesyłaniem strumieniowym zdarzeń, ale są uwzględnione tutaj w celu zapewnienia kompletności.
Rejestr urządzeń to baza danych aprowizowanego urządzenia, w tym identyfikatory urządzeń i zazwyczaj metadane urządzenia, takie jak lokalizacja.
Interfejs API aprowizacji jest typowym interfejsem zewnętrznym umożliwiającym aprowizowanie i rejestrowanie nowych urządzeń.
Niektóre rozwiązania IoT umożliwiają wysyłanie komunikatów poleceń i sterowania do urządzeń.
W tej sekcji przedstawiono bardzo ogólny widok IoT i istnieje wiele subtelności i wyzwań, które należy wziąć pod uwagę. Aby uzyskać więcej informacji, zobacz architektury IoT.