Ten artykuł zawiera listę elementów, które należy wziąć pod uwagę podczas przenoszenia rozwiązania IoT do środowiska produkcyjnego.
Korzystanie z sygnatur wdrażania
Sygnatury to odrębne jednostki podstawowych składników rozwiązania, które obsługują zdefiniowaną liczbę urządzeń. Każda kopia jest nazywana sygnaturą. lub jednostka skalowania. Na przykład sygnatura może składać się z zestawu populacji urządzeń, usługi IoT Hub, centrum zdarzeń lub innego punktu końcowego routingu oraz składnika przetwarzania. Każda sygnatura obsługuje zdefiniowaną populację urządzeń. Możesz wybrać maksymalną liczbę urządzeń, które może przechowywać sygnatura. Wraz ze wzrostem populacji urządzeń dodawane są wystąpienia sygnatur, a nie niezależne skalowanie w górę różnych części rozwiązania.
Jeśli zamiast dodawać sygnatury, przenosisz pojedyncze wystąpienie rozwiązania IoT do środowiska produkcyjnego, mogą wystąpić następujące ograniczenia:
Limity skalowania: Pojedyncze wystąpienie może napotkać limity skalowania. Na przykład rozwiązanie może używać usług, które mają limity liczby połączeń przychodzących, nazw hostów, gniazd TCP lub innych zasobów.
Nieliniowe skalowanie lub koszt: składniki rozwiązania mogą nie być skalowane liniowo z liczbą żądań lub ilością pozyskanych danych. Zamiast tego w przypadku niektórych składników może wystąpić spadek wydajności lub wzrost kosztów po osiągnięciu progu. Skalowanie w górę z większą pojemnością może nie być tak dobrym rozwiązaniem, jak skalowanie w górę przez dodanie sygnatur.
Separacja klientów: może być konieczne odizolowanie danych niektórych klientów od danych innych klientów. Podobnie może istnieć kilku klientów, którzy wymagają większej ilości zasobów systemowych do obsługi niż inne, i rozważyć grupowanie ich na różnych sygnaturach.
Pojedyncze i wielodostępne wystąpienia: może istnieć wielu klientów, którzy potrzebują własnych niezależnych wystąpień rozwiązania. Możesz również mieć pulę mniejszych klientów, którzy mogą współużytkować wdrożenie wielodostępne.
Złożone wymagania dotyczące wdrażania: może być konieczne wdrożenie aktualizacji w usłudze w kontrolowany sposób i wdrożenie w różnych sygnaturach w różnych momentach.
Częstotliwość aktualizacji: niektórzy klienci, którzy są odporni na częste aktualizacje systemu, podczas gdy inni mogą być niechętni i chcą rzadko aktualizować usługę.
Ograniczenia geograficzne lub geopolityczne: aby zmniejszyć opóźnienia lub spełnić wymagania dotyczące niezależności danych, możesz wdrożyć niektórych klientów w określonych regionach.
Aby uniknąć powyższych problemów, rozważ zgrupowanie usługi w wiele sygnatur. Sygnatury działają niezależnie od siebie i można je wdrażać i aktualizować niezależnie. Pojedynczy region geograficzny może zawierać pojedynczą sygnaturę lub może zawierać wiele sygnatur, aby umożliwić skalowanie w poziomie w poziomie w obrębie regionu. Każda sygnatura zawiera podzbiór klientów.
Używanie wycofywania w przypadku wystąpienia błędu przejściowego
Wszystkie aplikacje, które komunikują się ze zdalnymi usługami i zasobami, muszą być wrażliwe na błędy przejściowe. Jest to szczególnie przypadek aplikacji uruchamianych w chmurze, gdzie charakter środowiska i łączności przez Internet oznacza, że te typy błędów mogą wystąpić częściej. Błędy przejściowe obejmują:
- Chwilowa utrata łączności sieciowej ze składnikami i usługami
- Tymczasowa niedostępność usługi
- Przekroczenia limitu czasu, gdy usługa jest zajęta
- Kolizje spowodowane tym, że urządzenia przesyłają jednocześnie
Te błędy są często samonaprawiające, a jeśli akcja jest powtarzana po odpowiednim opóźnieniu, prawdopodobnie zakończy się powodzeniem. Określenie odpowiednich interwałów między ponownymi próbami jest jednak trudne. Typowe strategie używają następujących typów interwałów ponawiania prób:
- Wycofywanie wykładnicze. Przed pierwszym ponowieniem próby aplikacja czeka przez krótki czas, a następnie wydłuża wykładniczo czas między każdym kolejnym ponowieniem próby. Może na przykład ponowić operację po 3 sekundach, 12 sekundach, 30 sekundach itd.
- Interwały regularne. Aplikacja oczekuje stały odstęp czasu między kolejnymi próbami. Może na przykład ponawiać operację co 3 sekundy.
- Natychmiastowe ponowienie próby. Czasami błąd przejściowy jest krótki, być może ze względu na zdarzenie, takie jak kolizja pakietów sieciowych lub wzrost składnika sprzętowego. W takim przypadku natychmiastowe ponowienie operacji jest odpowiednie, ponieważ jeśli błąd ustąpi w czasie, jaki zajmuje aplikacji utworzenie i wysłanie kolejnego żądania, operacja ma szansę zakończyć się powodzeniem. Jednak nigdy nie powinno istnieć więcej niż jedna natychmiastowa próba ponawiania prób i należy przełączyć się na alternatywne strategie, takie jak wycofywanie wykładnicze lub akcje rezerwowe, jeśli natychmiastowe ponowienie nie powiedzie się.
- Generowanie losowe. Każda z powyższych strategii ponawiania może zawierać element randomizacji, aby zapobiec wysyłaniu kolejnych prób w tym samym czasie wielu wystąpień klienta.
Unikaj również następujących wzorców antywłaściwych:
- Implementacje nie powinny zawierać zduplikowanych warstw kodu ponawiania.
- Nigdy nie implementuj mechanizmu nieskończonego ponawiania prób.
- Nigdy nie przeprowadzaj natychmiastowego ponawiania próby więcej niż raz.
- Unikaj regularnego interwału ponawiania prób.
- Zapobiegaj możliwości generowania przez wiele wystąpień tego samego klienta lub wiele wystąpień różnych klientów ponownych prób w tym samym czasie.
Korzystanie z bezobsługowej aprowizacji
Aprowizowanie to czynność rejestrowania urządzenia w usłudze Azure IoT Hub. Aprowizowanie sprawia, że usługa IoT Hub jest świadoma urządzenia i mechanizmu zaświadczania używanego przez urządzenie. Możesz użyć usługi Azure IoT Hub Device Provisioning Service (DPS) lub aprowizować bezpośrednio za pośrednictwem interfejsów API menedżera rejestru usługi IoT Hub. Użycie usługi DPS zapewnia korzyści wynikające z opóźnionego powiązania, co umożliwia usuwanie i ponowne aprowizowanie urządzeń w usłudze IoT Hub bez zmieniania oprogramowania urządzenia.
W poniższym przykładzie pokazano, jak zaimplementować przepływ pracy przejścia środowiska test-środowisko produkcyjne przy użyciu usługi DPS.
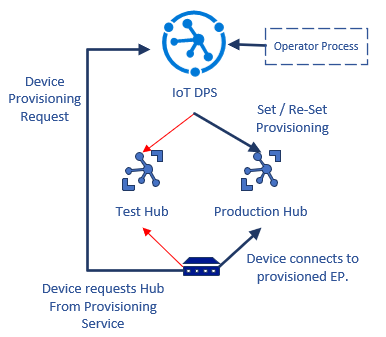
- Deweloper rozwiązań łączy chmury testowe i produkcyjne IoT z usługą aprowizacji.
- Urządzenie implementuje protokół DPS w celu znalezienia usługi IoT Hub, jeśli nie jest już aprowizowany. Urządzenie jest początkowo aprowidowane w środowisku testowym.
- Ponieważ urządzenie jest zarejestrowane w środowisku testowym, łączy się tam i odbywa się testowanie.
- Deweloper ponownie aprowizuje urządzenie w środowisku produkcyjnym i usuwa je z centrum Test. Centrum testowe odrzuca urządzenie przy następnym ponownym połączeniu.
- Urządzenie łączy się i ponownie negocjuje przepływ aprowizacji. Usługa DPS kieruje teraz urządzenie do środowiska produkcyjnego, a urządzenie łączy się z nim i uwierzytelnia tam.
Współautorzy
Ten artykuł jest obsługiwany przez firmę Microsoft. Pierwotnie został napisany przez następujących współautorów.
Autorzy zabezpieczeń:
- Matthew Cosner | Główny menedżer inżynierów oprogramowania
- Ansley Yeo | Główny menedżer programu
Aby wyświetlić niepubalne profile serwisu LinkedIn, zaloguj się do serwisu LinkedIn.