Sukces rozwiązania w chmurze zależy od jego niezawodności. Niezawodność może być szeroko zdefiniowana jako prawdopodobieństwo, że system działa zgodnie z oczekiwaniami w określonych warunkach środowiskowych w określonym czasie. Inżynieria niezawodności lokacji (SRE) to zestaw zasad i praktyk tworzenia skalowalnych i wysoce niezawodnych systemów oprogramowania. Coraz częściej usługa SRE jest używana podczas projektowania usług cyfrowych w celu zapewnienia większej niezawodności.
Aby uzyskać więcej informacji na temat strategii inżynierii niezawodności lokacji, zobacz AZ-400: Opracowywanie strategii inżynierii niezawodności lokacji (SRE).
Potencjalne przypadki użycia
Pojęcia zawarte w tym artykule dotyczą:
- Usługi w chmurze oparte na interfejsie API.
- Publiczne aplikacje internetowe.
- Obciążenia oparte na IoT lub oparte na zdarzeniach.
Architektura

Pobierz plik programu PowerPoint tej architektury.
Architektura, która jest tutaj brana pod uwagę, to skalowalna platforma interfejsu API. Rozwiązanie składa się z wielu mikrousług korzystających z różnych baz danych i usług magazynowania, w tym rozwiązań oprogramowania jako usługi (SaaS), takich jak Dynamics 365 i Microsoft 365.
W tym artykule uwzględniono rozwiązanie obsługujące platformę handlową wysokiego poziomu i przypadki użycia handlu elektronicznego w celu zademonstrowania bloków przedstawionych na diagramie. Przypadki użycia to:
- Przeglądanie produktów.
- Rejestracja i logowanie.
- Wyświetlanie zawartości, takiej jak artykuły z wiadomościami.
- Zarządzanie zamówieniami i subskrypcjami.
Aplikacje klienckie, takie jak aplikacje internetowe, aplikacje mobilne, a nawet aplikacje usług używają usług platformy interfejsu API za pośrednictwem ujednoliconej ścieżki dostępu. https://api.contoso.com
Składniki
- Usługa Azure Front Door zapewnia bezpieczny, ujednolicony punkt wejścia dla wszystkich żądań do rozwiązania. Aby uzyskać więcej informacji, zobacz Omówienie architektury routingu.
- Usługa Azure API Management udostępnia warstwę ładu na wszystkich opublikowanych interfejsach API. Zasady usługi Azure API Management umożliwiają stosowanie dodatkowych funkcji w warstwie interfejsu API, takich jak ograniczenia dostępu, buforowanie i przekształcanie danych. Usługa API Management obsługuje skalowanie automatyczne w warstwach Standardowa i Premium.
- Usługa Azure Kubernetes Service (AKS) to implementacja klastrów Kubernetes typu open source na platformie Azure. Jako hostowana usługa Kubernetes platforma Azure obsługuje krytyczne zadania, takie jak monitorowanie kondycji i konserwacja. Ponieważ wzorce platformy Kubernetes są zarządzane przez platformę Azure, można zarządzać węzłami agenta i obsługiwać je tylko. W tej architekturze wszystkie mikrousługi są wdrażane w usłudze AKS.
- aplikacja systemu Azure Gateway to usługa kontrolera dostarczania aplikacji. Działa w warstwie 7, warstwie aplikacji i ma różne możliwości równoważenia obciążenia. Kontroler ruchu przychodzącego usługi Application Gateway (AGIC) to aplikacja Kubernetes, która umożliwia klientom usługi Azure Kubernetes Service (AKS) korzystanie z natywnego modułu równoważenia obciążenia usługi Azure Application Gateway L7 w celu uwidaczniania oprogramowania w chmurze w Internecie. Skalowanie automatyczne i nadmiarowość stref są obsługiwane w jednostce SKU w wersji 2.
- Usługi Azure Storage, Azure Data Lake Storage, Azure Cosmos DB i Azure SQL mogą przechowywać zarówno zawartość ustrukturyzowaną, jak i niestrukturalnych. Kontenery i bazy danych usługi Azure Cosmos DB można tworzyć przy użyciu przepływności autoskalowania.
- Microsoft Dynamics 365 to oferta oprogramowania jako usługi (SaaS) firmy Microsoft, która udostępnia kilka aplikacji biznesowych na potrzeby obsługi klienta, sprzedaży, marketingu i finansów. W tej architekturze usługa Dynamics 365 jest używana głównie do zarządzania katalogami produktów i zarządzania usługami obsługi klienta. Jednostki skalowania zapewniają odporność aplikacji usługi Dynamics 365.
- Platforma Microsoft 365 (dawniej Office 365) jest używana jako system zarządzania zawartością przedsiębiorstwa oparty na programie Microsoft 365 SharePoint na platformie Microsoft 365. Służy do tworzenia i publikowania zawartości, takiej jak zasoby multimedialne i dokumenty, oraz zarządzanie nimi.
Alternatywy
Ponieważ to rozwiązanie korzysta z wysoce skalowalnej architektury opartej na mikrousługach, rozważ następujące alternatywy dla płaszczyzny obliczeniowej:
- Usługa Azure Functions dla usług bezserwerowych interfejsów API
- Mikrousługi oparte na języku Java w usłudze Azure Spring Apps
Odpowiednia niezawodność
Stopień niezawodności wymaganej dla rozwiązania zależy od kontekstu biznesowego. Sklep detaliczny, który jest otwarty przez 14 godzin i ma szczytowe użycie systemu w tym zakresie, ma inne wymagania niż działalność online, która akceptuje zamówienia przez wszystkie godziny. Rozwiązania SRE można dostosować do osiągnięcia odpowiedniego poziomu niezawodności.
Niezawodność jest definiowana i mierzona przy użyciu celów poziomu usług (celów poziomu usług ), które definiują docelowy poziom niezawodności usługi. Osiągnięcie poziomu docelowego zapewnia, że konsumenci są zadowoleni. Cele slo mogą ewoluować lub zmieniać w zależności od wymagań firmy. Jednak właściciele usług powinni stale mierzyć niezawodność względem celów SLO w celu wykrywania problemów i podejmowania działań naprawczych. Cele SLO są zwykle definiowane jako procent osiągnięcia w danym okresie.
Innym ważnym terminem do zanotowania jest wskaźnik poziomu usług (wskaźnik poziomu usług (SLI), który jest metryką używaną do obliczania celu slo. Wskaźniki SLI są oparte na szczegółowych danych pochodzących z danych przechwyconych w miarę korzystania z usługi przez klienta. Wskaźniki SLI są zawsze mierzone z punktu widzenia klienta.
Cele SLO i wskaźniki SLI zawsze idą w parze i są zwykle definiowane w sposób iteracyjny. Cele biznesowe są napędzane kluczowymi celami biznesowymi, natomiast wskaźniki SLI są napędzane przez to, co można zmierzyć podczas implementowania usługi.
Relacja między monitorowaną metryki, wskaźnikiem SLI i slo jest przedstawiona poniżej:
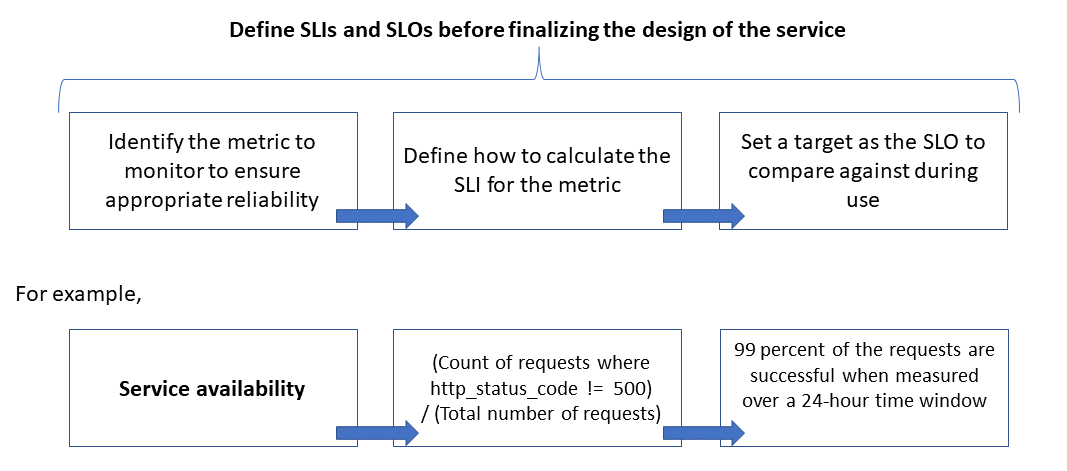
Bardziej szczegółowo wyjaśniono w artykule Definiowanie metryk SLI w celu obliczenia celów SLO.
Modelowanie oczekiwań dotyczących skalowania i wydajności
W przypadku systemu oprogramowania wydajność zwykle odnosi się do ogólnej reakcji systemu podczas wykonywania akcji w określonym czasie, podczas gdy skalowalność jest możliwością obsługi zwiększonych obciążeń użytkowników bez szkody w wydajności.
System jest uważany za skalowalny, jeśli bazowe zasoby są udostępniane dynamicznie w celu obsługi wzrostu obciążenia. Aplikacje w chmurze muszą być zaprojektowane pod kątem skalowania, a ruch jest trudny do przewidzenia w czasie. Sezonowe skoki mogą zwiększyć wymagania dotyczące skalowania, zwłaszcza gdy usługa obsługuje żądania dla wielu dzierżaw.
Dobrym rozwiązaniem jest zaprojektowanie aplikacji w celu automatycznego skalowania zasobów w chmurze w górę i w dół zgodnie z potrzebami w celu spełnienia obciążenia. Zasadniczo system powinien dostosować się do wzrostu obciążenia przez aprowizowanie lub przydzielanie zasobów w sposób przyrostowy w celu zaspokojenia zapotrzebowania. Skalowalność dotyczy nie tylko wystąpień obliczeniowych, ale także innych elementów, takich jak magazyn danych i infrastruktura obsługi komunikatów.
W tym artykule pokazano, jak zapewnić odpowiednią niezawodność aplikacji w chmurze, przeprowadzając modelowanie skalowania i wydajności scenariuszy obciążeń oraz używając wyników do zdefiniowania monitorów, wskaźników SLA i celów SLO.
Kwestie wymagające rozważenia
Zapoznaj się z filarami niezawodności i wydajności platformy Azure Well Architected Framework , aby uzyskać wskazówki dotyczące tworzenia skalowalnych i niezawodnych aplikacji.
W tym artykule opisano sposób stosowania technik modelowania skalowalności i wydajności w celu dostosowania architektury i projektowania rozwiązań. Te techniki identyfikują zmiany przepływów transakcji w celu uzyskania optymalnego środowiska użytkownika. Należy podjąć decyzje techniczne dotyczące wymagań niefunkcjonanych rozwiązania. Proces jest:
- Zidentyfikuj wymagania dotyczące skalowalności.
- Modelowanie oczekiwanego obciążenia.
- Zdefiniuj wskaźniki SLA i cele SLO dla scenariuszy użytkownika.
Uwaga
aplikacja systemu Azure Insights, część usługi Azure Monitor, to zaawansowane narzędzie do zarządzania wydajnością aplikacji (APM), które można łatwo zintegrować z aplikacjami w celu wysyłania danych telemetrycznych i analizowania metryk specyficznych dla aplikacji. Udostępnia również gotowe do użycia pulpity nawigacyjne i eksplorator metryk, za pomocą którego można analizować dane w celu eksplorowania potrzeb biznesowych.
Wymagania dotyczące skalowalności przechwytywania
Załóżmy, że te metryki szczytowego obciążenia:
- Liczba użytkowników korzystających z platformy INTERFEJSu API: 1,5 miliona
- Aktywni użytkownicy godzinowi (30 procent z 1,5 miliona): 450 000
- Procent obciążenia dla każdego działania:
- Przeglądanie produktów: 75 procent
- Rejestracja, w tym tworzenie profilu i logowanie: 10 procent
- Zarządzanie zamówieniami i subskrypcjami: 10 procent
- Wyświetlanie zawartości: 5 procent
Obciążenie generuje następujące wymagania dotyczące skalowania w ramach normalnego szczytowego obciążenia dla interfejsów API hostowanych przez platformę:
- Mikrousługa produktu: około 500 żądań na sekundę (RPS)
- Mikrousługa profilu: około 100 RPS
- Zamówienia i mikrousługi płatnicze: około 100 RPS
- Mikrousługa zawartości: około 50 RPS
Te wymagania dotyczące skalowania nie uwzględniają sezonowych i losowych szczytów oraz szczytów podczas wydarzeń specjalnych, takich jak promocje marketingowe. Podczas szczytów wymaganie skalowania niektórych działań użytkownika wynosi do 10 razy normalne obciążenie szczytowe. Należy pamiętać o tych ograniczeniach i oczekiwaniach podczas wprowadzania wyborów projektowych dla mikrousług.
Definiowanie metryk SLI do obliczania celów SLO
Metryki SLI wskazują stopień, w jakim usługa zapewnia zadowalające środowisko i może być wyrażona jako stosunek dobrych zdarzeń do łącznej liczby zdarzeń.
W przypadku usługi interfejsu API zdarzenia odnoszą się do metryk specyficznych dla aplikacji, które są przechwytywane podczas wykonywania jako dane telemetryczne lub przetwarzane. W tym przykładzie przedstawiono następujące metryki SLI:
| Metryczne | Popis |
|---|---|
| Dostępność | Czy żądanie zostało obsługiwane przez interfejs API |
| Opóźnienie | Czas przetwarzania żądania i zwracania odpowiedzi przez interfejs API |
| Produktywność | Liczba żądań obsługiwanych przez interfejs API |
| Wskaźnik powodzenia | Liczba żądań obsługiwanych pomyślnie przez interfejs API |
| Częstotliwość błędów | Liczba błędów żądań obsługiwanych przez interfejs API |
| Świeżość | Ile razy użytkownik otrzymał najnowsze dane dotyczące operacji odczytu w interfejsie API, mimo że podstawowy magazyn danych jest aktualizowany przy użyciu określonego opóźnienia zapisu |
Uwaga
Pamiętaj, aby zidentyfikować wszelkie dodatkowe wskaźniki SLI, które są ważne dla twojego rozwiązania.
Oto przykłady wskaźników SLI:
- (Liczba żądań zakończonych pomyślnie w mniej niż 1000 ms) / (liczba żądań)
- (Liczba wyników wyszukiwania, które zwracają w ciągu trzech sekund wszystkie produkty opublikowane w katalogu) / (Liczba wyszukiwań)
Po zdefiniowaniu wskaźników SLI określ, jakie zdarzenia lub dane telemetryczne mają zostać przechwycone w celu ich zmierzenia. Na przykład w celu mierzenia dostępności przechwytuje się zdarzenia wskazujące, czy usługa interfejsu API pomyślnie przetworzyła żądanie. W przypadku usług opartych na protokole HTTP powodzenie lub niepowodzenie jest wskazywane przy użyciu kodów stanu HTTP. Projekt i implementacja interfejsu API muszą zawierać odpowiednie kody. Ogólnie rzecz biorąc, metryki SLI są ważnymi danymi wejściowymi implementacji interfejsu API.
W przypadku systemów opartych na chmurze można uzyskać niektóre metryki przy użyciu obsługi diagnostyki i monitorowania, które są dostępne dla zasobów. Usługa Azure Monitor to kompleksowe rozwiązanie do zbierania, analizowania i działania na podstawie danych telemetrycznych z usług w chmurze. W zależności od wymagań dotyczących wskaźnika SLI można przechwycić więcej danych monitorowania w celu obliczenia metryk.
Korzystanie z rozkładów percentylu
Niektóre wskaźniki SLI są obliczane przy użyciu techniki rozkładu percentylu. Daje to lepsze wyniki, jeśli istnieją wartości odstające, które mogą wypaczyć inne techniki, takie jak średnie lub mediana rozkładów.
Rozważmy na przykład, że metryka jest opóźnieniem żądań interfejsu API, a trzy sekundy to próg optymalnej wydajności. Posortowane czasy odpowiedzi dla godziny żądań interfejsu API pokazują, że kilka żądań trwa dłużej niż trzy sekundy, a większość odpowiedzi otrzymuje w ramach limitu progowego. Jest to oczekiwane zachowanie systemu.
Rozkład percentylu jest przeznaczony do wykluczania wartości odstających spowodowanych sporadycznymi problemami. Jeśli na przykład prawidłowe odpowiedzi usługi znajdują się w 90. lub 95. percentylu, cel slo jest uznawany za spełniony.
Wybieranie odpowiednich okresów pomiaru
Okres pomiaru definiowania celu slo jest bardzo ważny. Musi przechwytywać działanie, a nie bezczynność, aby wyniki byłyby istotne dla środowiska użytkownika. To okno może potrwać od pięciu minut do 24 godzin, w zależności od sposobu monitorowania i obliczania metryki SLI.
Ustanawianie procesu zapewniania ładu w zakresie wydajności
Wydajność interfejsu API musi być zarządzana od jego powstania, dopóki nie zostanie wycofana lub wycofana. Należy zapewnić niezawodny proces zapewniania ładu, aby upewnić się, że problemy z wydajnością są wykrywane i rozwiązywane wcześnie, zanim spowodują one poważne awarie wpływające na firmę.
Oto elementy ładu w zakresie wydajności:
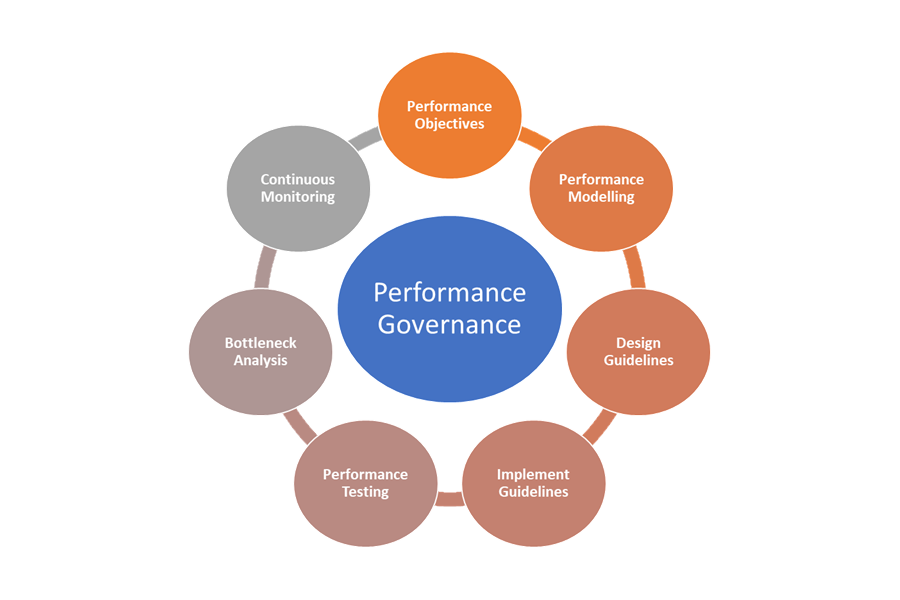
- Cele wydajności: zdefiniuj aspiracyjne cele wydajności dla scenariuszy biznesowych.
- Modelowanie wydajności: identyfikowanie przepływów pracy i transakcji krytycznych dla działania firmy oraz przeprowadzanie modelowania w celu zrozumienia skutków związanych z wydajnością. Przechwyć te informacje na poziomie szczegółowym, aby uzyskać dokładniejsze przewidywania.
- Wytyczne dotyczące projektowania: Przygotuj wytyczne dotyczące projektowania wydajności i zalecamy odpowiednie modyfikacje przepływu pracy biznesowego. Upewnij się, że zespoły rozumieją te wytyczne.
- Implementowanie wytycznych: Implementowanie wytycznych dotyczących projektowania wydajności dla składników rozwiązania, w tym instrumentacji w celu przechwytywania metryk. Przeprowadzanie przeglądów projektu wydajności. Śledzenie wszystkich tych elementów przy użyciu elementów listy prac architektury dla różnych zespołów ma kluczowe znaczenie.
- Testowanie wydajności: przeprowadź testy obciążenia i obciążenia zgodnie z rozkładem profilu obciążenia, aby przechwycić metryki powiązane z kondycją platformy. Można również przeprowadzić te testy pod kątem ograniczonego obciążenia, aby porównać wymagania dotyczące infrastruktury rozwiązania.
- Analiza wąskich gardeł: użyj inspekcji kodu i przeglądów kodu, aby identyfikować, analizować i usuwać wąskie gardła wydajności w różnych składnikach. Zidentyfikuj ulepszenia skalowania w poziomie lub w pionie, które są wymagane do obsługi obciążeń szczytowych.
- Ciągłe monitorowanie: ustanów infrastrukturę ciągłego monitorowania i zgłaszania alertów w ramach procesów DevOps. Upewnij się, że zainteresowane zespoły są powiadamiane, gdy czasy odpowiedzi znacznie się obniżają w porównaniu z testami porównawczymi.
- Nadzór nad wydajnością: ustanów nadzór nad wydajnością składający się z dobrze zdefiniowanych procesów i zespołów w celu utrzymania celów SLO dotyczących wydajności. Śledź zgodność po każdej wersji, aby uniknąć pogorszenia z powodu uaktualnień kompilacji. Okresowo przeprowadzaj przeglądy w celu oceny pod kątem zwiększonego obciążenia w celu zidentyfikowania uaktualnień rozwiązań.
Pamiętaj, aby powtórzyć kroki w trakcie opracowywania rozwiązań w ramach progresywnego procesu opracowywania.
Śledzenie celów wydajności i oczekiwań na liście prac
Śledzenie celów wydajności w celu zapewnienia ich osiągnięcia. Przechwyć szczegółowe i szczegółowe historie użytkowników do śledzenia. Pomoże to zagwarantować, że zespoły programistyczne będą mieć wysoki priorytet dla działań związanych z zarządzaniem wydajnością.
Ustanawianie aspiracyjnych celów slo dla rozwiązania docelowego
Poniżej przedstawiono przykładowe aspiracyjne cele SLO dla rozwiązania platformy interfejsu API, które należy wziąć pod uwagę:
- Odpowiada na 95 procent wszystkich żądań ODCZYTU w ciągu jednego dnia w ciągu jednej sekundy.
- Odpowiada na 95 procent wszystkich żądań CREATE i UPDATE w ciągu trzech sekund.
- Odpowiada na 99% wszystkich żądań w ciągu pięciu sekund bez błędów.
- Odpowiada na 99,9% wszystkich żądań w ciągu dnia w ciągu pięciu minut.
- Mniej niż jeden procent żądań podczas szczytowego błędu okna jednogodzinnego.
Cele SLO można dostosować do określonych wymagań aplikacji. Jednak niezwykle ważne jest, aby mieć wystarczająco szczegółową przejrzystość w celu zapewnienia niezawodności.
Mierzenie początkowych celów SLO opartych na danych z dzienników
Dzienniki monitorowania są tworzone automatycznie, gdy usługa interfejsu API jest używana. Załóżmy, że tydzień danych pokazuje następujące dane:
- Żądania: 123 456
- Pomyślne żądania: 123 204
- 90. opóźnienie percentylu: 497 ms
- 95. opóźnienie percentylu: 870 ms
- 99. opóźnienie percentylu: 1024 ms
Te dane generują następujące początkowe wskaźniki SLA:
- Dostępność = (123 204 / 123 456) = 99,8 procent
- Opóźnienie = co najmniej 90 procent żądań zostało obsłużone w ciągu 500 ms
- Opóźnienie = około 98 procent żądań zostało obsłużone w ciągu 1000 ms
Załóżmy, że podczas planowania cel SLO opóźnienia aspiracji polega na tym, że 90 procent żądań jest przetwarzanych w ciągu 500 ms z współczynnikiem sukcesu wynoszącym 99 procent w okresie jednego tygodnia. Przy użyciu danych dziennika można łatwo określić, czy cel slo został spełniony. Jeśli wykonujesz tę analizę przez kilka tygodni, możesz zacząć widzieć trendy dotyczące zgodności slo.
Wskazówki dotyczące ograniczania ryzyka technicznego
Skorzystaj z poniższej listy kontrolnej zalecanych rozwiązań, aby ograniczyć skalowalność i ryzyko związane z wydajnością:
- Projektowanie pod kątem skalowania i wydajności.
- Upewnij się, że przechwytujesz wymagania dotyczące skalowania dla każdego scenariusza użytkownika i obciążenia, w tym sezonowości i szczytów.
- Przeprowadzanie modelowania wydajności w celu identyfikowania ograniczeń i wąskich gardeł systemu
- Zarządzanie długiem technicznym.
- Wykonaj obszerne śledzenie metryk wydajności.
- Rozważ użycie skryptów do uruchamiania narzędzi, takich jak K6.io, Karate i JMeter w środowisku przejściowym programowania z zakresem obciążeń użytkownika — na przykład od 50 do 100 RPS. Spowoduje to udostępnienie informacji w dziennikach dotyczących wykrywania problemów z projektowaniem i implementacją.
- Zintegruj skrypty testów automatycznych w ramach procesów ciągłego wdrażania (CD), aby wykrywać przerwy kompilacji.
- Mieć sposób myślenia produkcyjnego.
- Dostosuj progi skalowania automatycznego zgodnie ze statystykami kondycji.
- Preferuj techniki skalowania poziomego w pionie.
- Bądź proaktywny dzięki skalowaniu w celu obsługi sezonowości.
- Preferuj wdrożenie oparte na pierścieniu.
- Użyj budżetów błędów do eksperymentowania.
Cennik
Niezawodność, wydajność i optymalizacja kosztów są przydatne. Usługi platformy Azure, które są używane w architekturze, pomagają zmniejszyć koszty, ponieważ są skalowane automatycznie w celu dostosowania się do zmieniających się obciążeń użytkowników.
W przypadku usługi AKS można początkowo rozpocząć pracę z maszynami wirtualnymi o standardowym rozmiarze dla puli węzłów. Następnie można monitorować wymagania dotyczące zasobów podczas programowania lub użycia produkcyjnego i odpowiednio dostosować je.
Optymalizacja kosztów jest filarem platformy Microsoft Azure Well-Architected Framework. Aby uzyskać więcej informacji, zobacz Omówienie filaru optymalizacji kosztów. Aby oszacować koszt produktów i konfiguracji platformy Azure, użyj kalkulatora cen.
Współautorzy
Ten artykuł jest obsługiwany przez firmę Microsoft. Pierwotnie został napisany przez następujących współautorów.
Główny autor:
- Subhajit Chatterjee | Główny inżynier oprogramowania
Następne kroki
- Dokumentacja platformy Azure
- Platforma Microsoft Azure — dobrze zaprojektowana struktura
- Styl architektury mikrousług
- Projektowanie w celu skalowania w poziomie
- Wybieranie usługi obliczeniowej platformy Azure dla aplikacji
- Architektura mikrousług w usłudze Azure Kubernetes Service
- Co to jest usługa Azure Front Door?
- Informacje o usłudze API Management
- Co to jest kontroler ruchu przychodzącego usługi Application Gateway?
- Azure Kubernetes Service
- Skalowanie automatyczne i strefowo nadmiarowa brama aplikacji (wersja 2)
- Automatyczne skalowanie klastra w celu spełnienia wymagań aplikacji w usłudze Azure Kubernetes Service (AKS)
- Tworzenie kontenerów i baz danych usługi Azure Cosmos DB z przepływnością autoskalowania
- Dokumentacja usługi Microsoft Dynamics 365
- Dokumentacja platformy Microsoft 365
- Dokumentacja inżynierii niezawodności lokacji
- AZ-400: Opracowywanie strategii inżynierii niezawodności lokacji (SRE)
- Podstawowa aplikacja internetowa z nadmiarowością stref