Rozwiązywanie problemów z wąskimi gardłami wydajności w usłudze Azure Databricks
Uwaga
Ten artykuł opiera się na bibliotece open source hostowanej w witrynie GitHub pod adresem : https://github.com/mspnp/spark-monitoring.
Oryginalna biblioteka obsługuje środowiska Azure Databricks Runtimes 10.x (Spark 3.2.x) i starsze.
Usługa Databricks udostępniła zaktualizowaną wersję do obsługi środowiska Azure Databricks Runtimes 11.0 (Spark 3.3.x) i nowszego w l4jv2 gałęzi pod adresem : https://github.com/mspnp/spark-monitoring/tree/l4jv2.
Należy pamiętać, że wersja 11.0 nie jest zgodna z poprzednimi wersjami ze względu na różne systemy rejestrowania używane w środowiskach Databricks Runtime. Pamiętaj, aby użyć poprawnej kompilacji środowiska Databricks Runtime. Biblioteka i repozytorium GitHub są w trybie konserwacji. Nie ma planów dalszych wydań, a pomoc techniczna dotycząca problemów będzie dostępna tylko w najlepszym celu. Aby uzyskać dodatkowe pytania dotyczące biblioteki lub planu monitorowania i rejestrowania środowisk usługi Azure Databricks, skontaktuj się z .azure-spark-monitoring-help@databricks.com
W tym artykule opisano sposób używania pulpitów nawigacyjnych monitorowania do znajdowania wąskich gardeł wydajności w zadaniach platformy Spark w usłudze Azure Databricks.
Azure Databricks to oparta na platformie Apache Spark usługa analityczna, która ułatwia szybkie opracowywanie i wdrażanie analizy danych big data. Monitorowanie i rozwiązywanie problemów z wydajnością ma kluczowe znaczenie w przypadku obsługi produkcyjnych obciążeń usługi Azure Databricks. Aby zidentyfikować typowe problemy z wydajnością, warto użyć wizualizacji monitorowania na podstawie danych telemetrycznych.
Wymagania wstępne
Aby skonfigurować pulpity nawigacyjne narzędzia Grafana pokazane w tym artykule:
Skonfiguruj klaster usługi Databricks w celu wysyłania danych telemetrycznych do obszaru roboczego usługi Log Analytics przy użyciu biblioteki monitorowania usługi Azure Databricks. Aby uzyskać szczegółowe informacje, zobacz plik readme usługi GitHub.
Wdrażanie narzędzia Grafana na maszynie wirtualnej. Aby uzyskać więcej informacji, zobacz Wizualizowanie metryk usługi Azure Databricks przy użyciu pulpitów nawigacyjnych.
Wdrożony pulpit nawigacyjny Grafana zawiera zestaw wizualizacji szeregów czasowych. Każdy wykres to wykres szeregów czasowych metryk związanych z zadaniem platformy Apache Spark, etapami zadania i zadaniami, które składają się na każdy etap.
Omówienie wydajności usługi Azure Databricks
Usługa Azure Databricks jest oparta na platformie Apache Spark, rozproszonym systemie obliczeniowym ogólnego przeznaczenia. Kod aplikacji, znany jako zadanie, jest wykonywany w klastrze Apache Spark koordynowany przez menedżera klastra. Ogólnie rzecz biorąc, zadanie jest jednostką obliczeniową najwyższego poziomu. Zadanie reprezentuje pełną operację wykonywaną przez aplikację Spark. Typowa operacja obejmuje odczytywanie danych ze źródła, stosowanie przekształceń danych i zapisywanie wyników w magazynie lub w innym miejscu docelowym.
Zadania są podzielone na etapy. Zadanie przechodzi przez etapy sekwencyjnie, co oznacza, że późniejsze etapy muszą czekać na wcześniejsze etapy do ukończenia. Etapy zawierają grupy identycznych zadań , które można wykonywać równolegle w wielu węzłach klastra Spark. Zadania to najbardziej szczegółowa jednostka wykonywania, która odbywa się w podzestawie danych.
W następnych sekcjach opisano niektóre wizualizacje pulpitu nawigacyjnego, które są przydatne do rozwiązywania problemów z wydajnością.
Opóźnienie zadania i etapu
Opóźnienie zadania to czas trwania wykonywania zadania od momentu rozpoczęcia, aż zostanie ukończony. Jest on wyświetlany jako percentyle wykonywania zadania dla klastra i identyfikatora aplikacji, aby umożliwić wizualizację wartości odstających. Na poniższym wykresie przedstawiono historię zadań, w której 90. percentyl osiągnął 50 sekund, mimo że 50. percentyl był stale około 10 sekund.
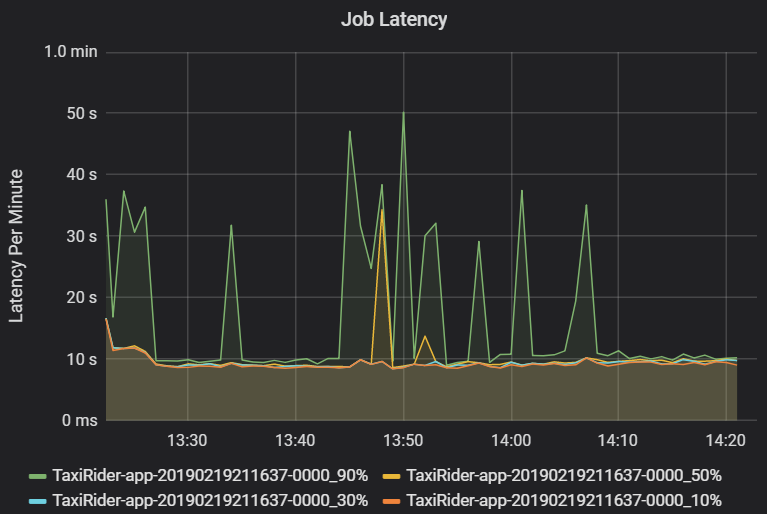
Zbadaj wykonywanie zadań według klastra i aplikacji, szukając skoków opóźnień. Po zidentyfikowaniu klastrów i aplikacji z dużym opóźnieniem przejdź do badania opóźnienia etapu.
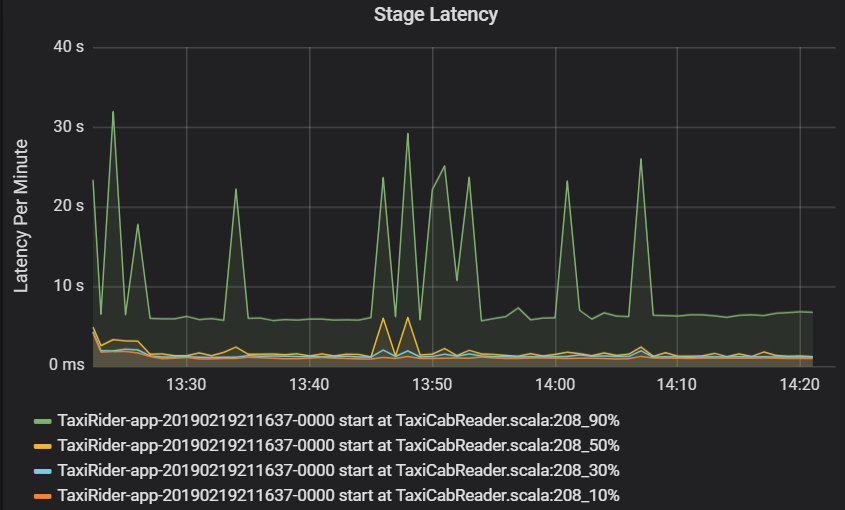
Opóźnienie etapu jest również wyświetlane jako percentyle, aby umożliwić wizualizację wartości odstających. Opóźnienie etapu jest podzielone według nazwy klastra, aplikacji i etapu. Zidentyfikuj skoki opóźnienia zadań na wykresie, aby określić, które zadania powstrzymują ukończenie etapu.
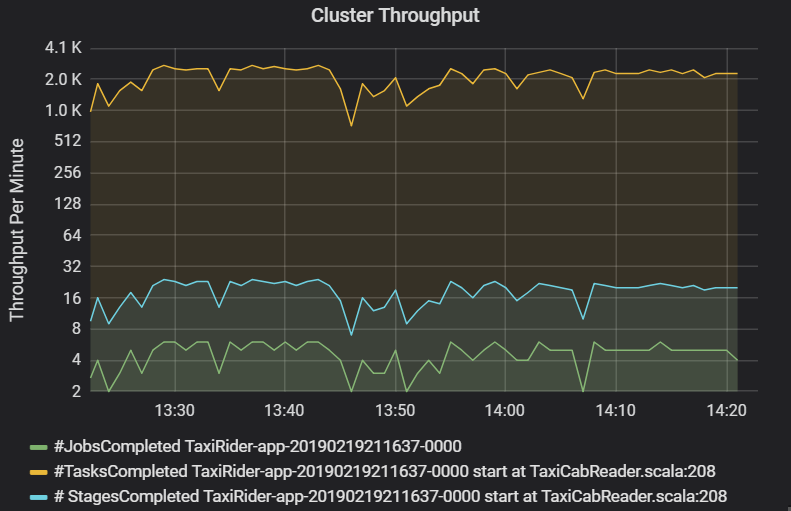
Wykres przepływności klastra przedstawia liczbę zadań, etapów i zadań ukończonych na minutę. Ułatwia to zrozumienie obciążenia pod względem względnej liczby etapów i zadań na zadanie. W tym miejscu widać, że liczba zadań na minutę waha się od 2 do 6, a liczba etapów wynosi około 12– 24 minut.
Suma opóźnienia wykonywania zadania
Ta wizualizacja przedstawia sumę opóźnienia wykonywania zadań na hosta uruchomionego w klastrze. Użyj tego grafu, aby wykryć zadania, które działają powoli z powodu spowolnienia hosta w klastrze lub błędnej alokacji zadań na funkcję wykonawczą. Na poniższym wykresie większość hostów ma sumę około 30 sekund. Jednak dwa hosty mają sumy, które unoszą się około 10 minut. Hosty działają wolno lub liczba zadań na funkcję wykonawczą jest nieprawidłowo przydzielana.
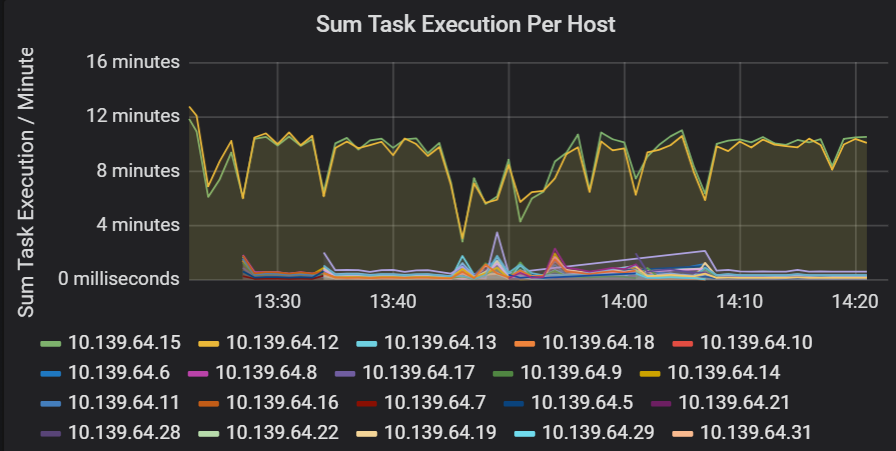
Liczba zadań wykonywanych przez funkcję wykonawczą pokazuje, że do dwóch funkcji wykonawczych przypisano nieproporcjonalną liczbę zadań, co powoduje wąskie gardło.
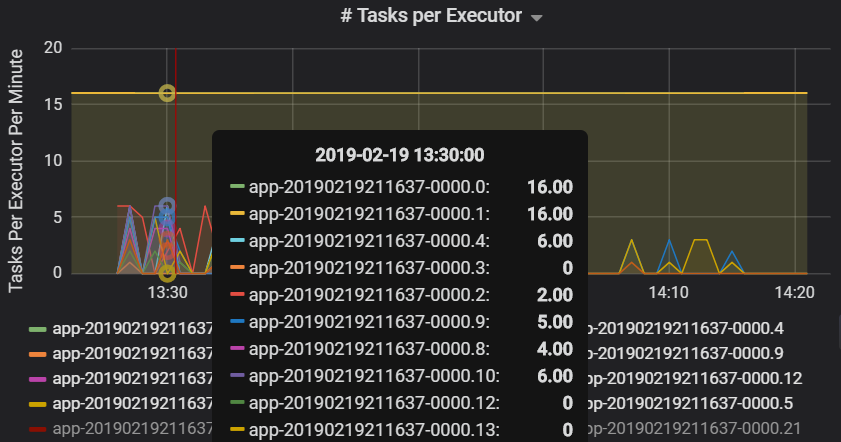
Metryki zadań na etap
Wizualizacja metryk zadań udostępnia podział kosztów na wykonanie zadania. Można go użyć, aby zobaczyć względny czas spędzony na zadaniach, takich jak serializacja i deserializacja. Te dane mogą przedstawiać możliwości optymalizacji — na przykład przy użyciu zmiennych emisji, aby uniknąć wysyłania danych. Metryki zadań pokazują również rozmiar danych mieszania dla zadania oraz czasy mieszania odczytu i zapisu. Jeśli te wartości są wysokie, oznacza to, że wiele danych przenosi się przez sieć.
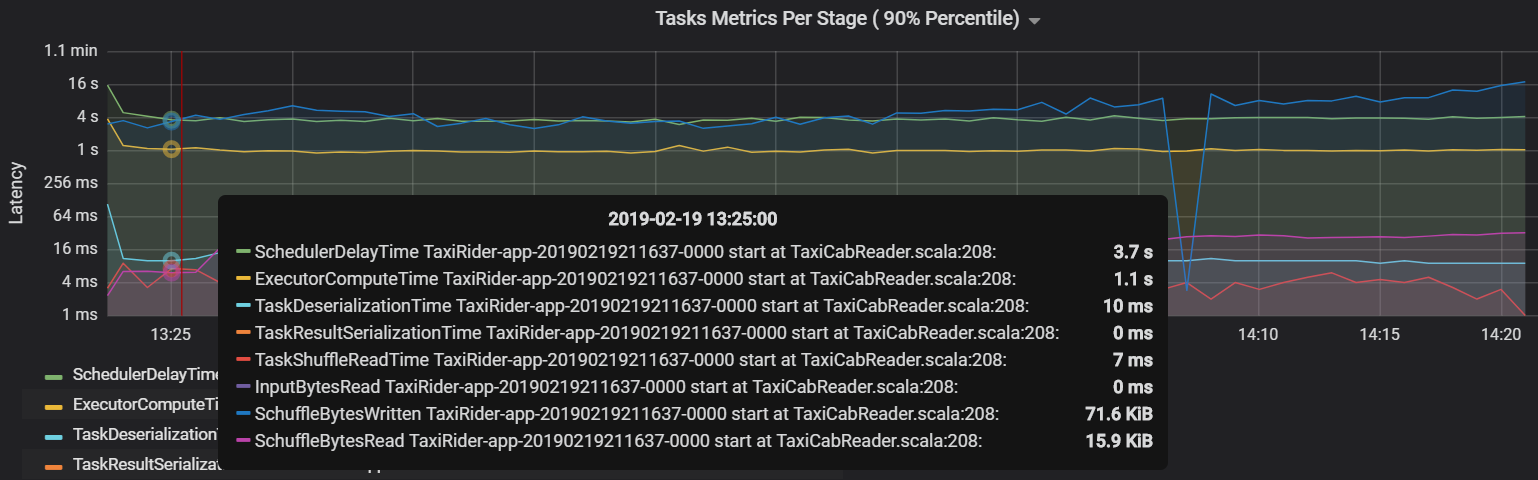
Kolejną metryką zadania jest opóźnienie harmonogramu, które mierzy, jak długo trwa zaplanowanie zadania. W idealnym przypadku ta wartość powinna być niska w porównaniu z czasem obliczeniowym funkcji wykonawczej, czyli czasem spędzonym faktycznie na wykonywaniu zadania.
Na poniższym wykresie przedstawiono czas opóźnienia harmonogramu (3,7 s), który przekracza czas obliczeniowy funkcji wykonawczej (1,1 s). Oznacza to, że więcej czasu poświęca się na zaplanowanie zadań niż wykonywanie rzeczywistej pracy.
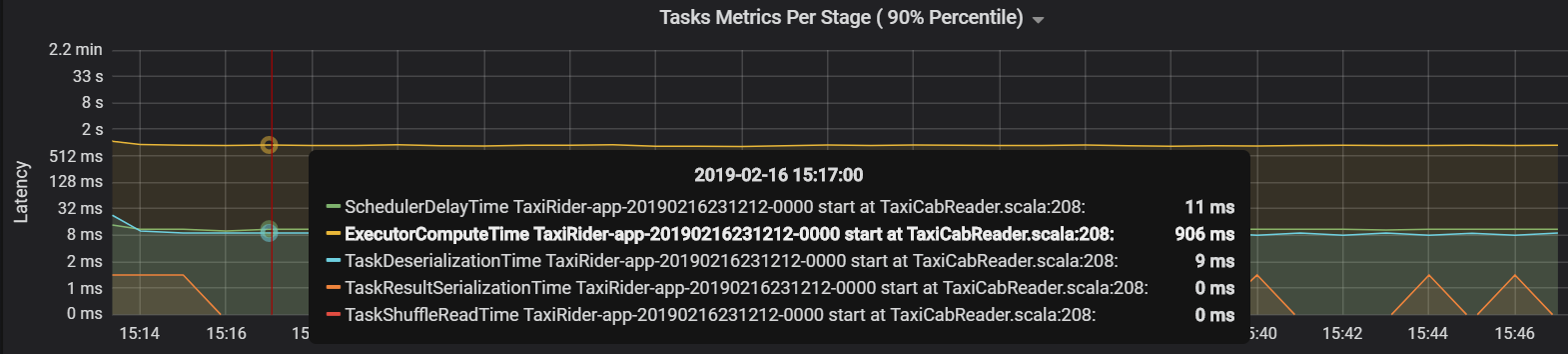
W tym przypadku problem został spowodowany zbyt dużą liczbą partycji, co spowodowało duże obciążenie. Zmniejszenie liczby partycji obniżyło czas opóźnienia harmonogramu. Następny graf pokazuje, że większość czasu poświęca się na wykonywanie zadania.
Przepływność i opóźnienie przesyłania strumieniowego
Przepływność przesyłania strumieniowego jest bezpośrednio związana ze strukturą przesyłania strumieniowego. Istnieją dwie ważne metryki skojarzone z przepływnością przesyłania strumieniowego: wiersze wejściowe na sekundę i przetworzone wiersze na sekundę. Jeśli wiersze wejściowe na sekundę przewyższają przetworzone wiersze na sekundę, oznacza to, że system przetwarzania strumieniowego spada z tyłu. Ponadto jeśli dane wejściowe pochodzą z usługi Event Hubs lub platformy Kafka, wiersze wejściowe na sekundę powinny być na bieżąco z szybkością pozyskiwania danych na frontonie.
Dwa zadania mogą mieć podobną przepływność klastra, ale bardzo różne metryki przesyłania strumieniowego. Poniższy zrzut ekranu przedstawia dwa różne obciążenia. Są one podobne pod względem przepływności klastra (zadań, etapów i zadań na minutę). Jednak drugi przebieg przetwarza 12 000 wierszy na sekundę w porównaniu z 4000 wierszami na sekundę.
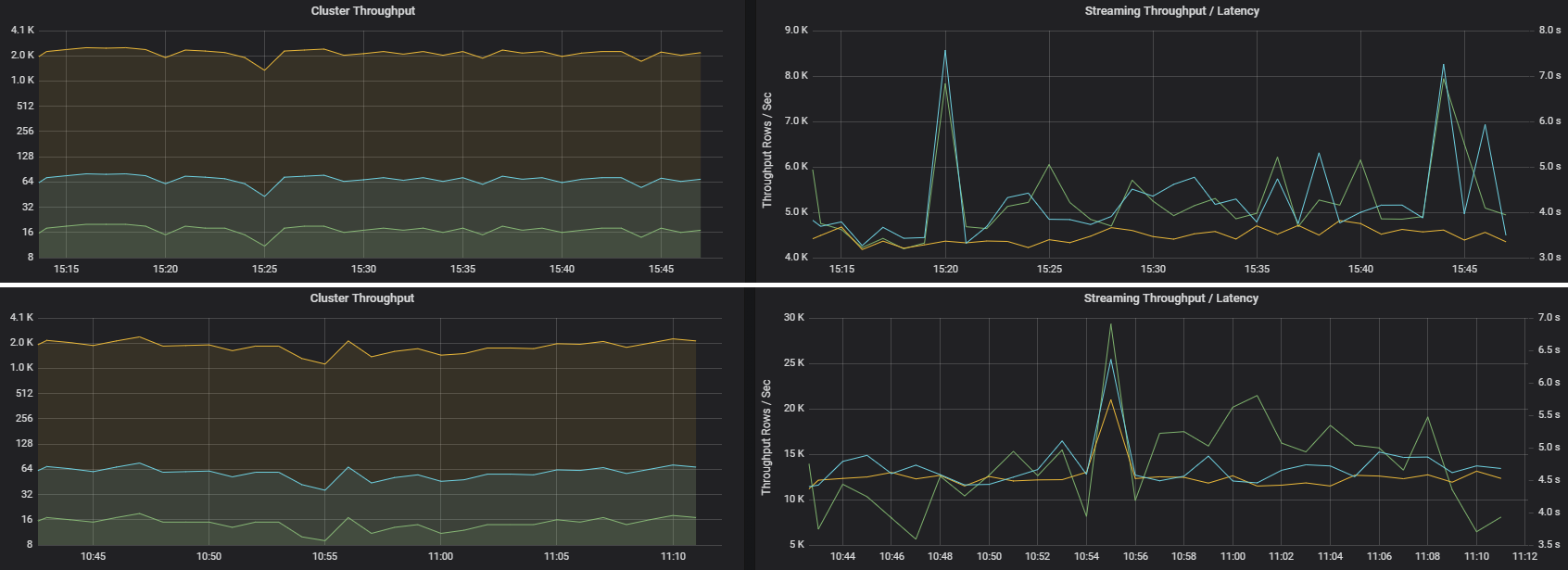
Przepływność przesyłania strumieniowego jest często lepszą metryką biznesową niż przepływność klastra, ponieważ mierzy liczbę przetwarzanych rekordów danych.
Użycie zasobów na funkcję wykonawcza
Te metryki pomagają zrozumieć pracę wykonywaną przez poszczególne funkcje wykonawcze.
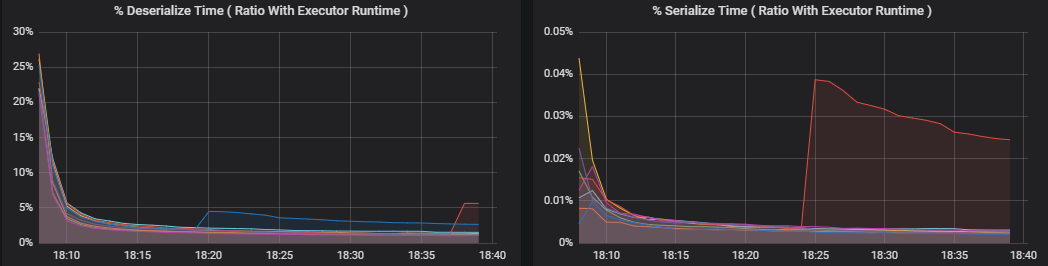
Metryki procentowe mierzą , ile czasu spędza wykonawca na różne elementy, wyrażone jako stosunek czasu spędzonego w porównaniu z ogólnym czasem obliczeniowym funkcji wykonawczej. Te metryki to:
- % czasu serializacji
- % deserializacji czasu
- % czasu wykonywania procesora CPU
- % czasu JVM
Te wizualizacje pokazują, ile każda z tych metryk przyczynia się do ogólnego przetwarzania funkcji wykonawczej.
Metryki shuffle to metryki związane z mieszania danych w funkcjach wykonawczych.
- Shuffle We/Wy
- Przetasuj pamięć
- Użycie systemu plików
- Użycie dysku
Typowe wąskie gardła wydajności
Dwa typowe wąskie gardła wydajności na platformie Spark to marudery zadań i liczba partycji bez optymalnej.
Marudery zadań
Etapy zadania są wykonywane sekwencyjnie i wcześniejsze etapy blokują późniejsze. Jeśli jedno zadanie wykonuje partycjonowanie z mieszaniem wolniej niż inne zadania, wszystkie zadania w klastrze muszą czekać, aż powolne zadanie je dogoni, zanim będzie można zakończyć etap. Może się to zdarzyć z następujących powodów:
Host lub grupa hostów działa wolno. Objawy: wysokie opóźnienie zadania, etapu lub zadania oraz niska przepływność klastra. Sumowanie opóźnień zadań na hosta nie będzie równomiernie dystrybuowane. Jednak użycie zasobów będzie równomiernie dystrybuowane między funkcjami wykonawczych.
Zadania mają kosztowną agregację do wykonania (niesymetryczność danych). Objawy: duże opóźnienie zadania, duże opóźnienie, duże opóźnienie zadania lub niska przepływność klastra, ale sumowanie opóźnień na hosta jest równomiernie rozłożone. Użycie zasobów będzie równomiernie dystrybuowane między funkcjami wykonawczych.
Jeśli partycje mają nierówny rozmiar, większa partycja może spowodować niezrównoważone wykonanie zadania (niesymetryczność partycji). Objawy: Użycie zasobów funkcji wykonawczej jest wysokie w porównaniu z innymi funkcjami wykonawczych uruchomionymi w klastrze. Wszystkie zadania uruchomione w ramach tego modułu wykonawczego będą działać wolno i będą przechowywać wykonywanie etapu w potoku. Mówi się, że te etapy są barierami etapowymi.
Liczba partycji bez optymalnego mieszania
Podczas zapytania przesyłania strumieniowego ze strukturą przypisanie zadania do funkcji wykonawczej jest operacją intensywnie korzystającą z zasobów dla klastra. Jeśli dane mieszania nie są optymalnym rozmiarem, opóźnienie zadania wpłynie negatywnie na przepływność i opóźnienie. Jeśli istnieje zbyt mało partycji, rdzenie w klastrze będą niedostatecznie wykorzystywane, co może spowodować nieefektywność przetwarzania. Z drugiej strony, jeśli istnieje zbyt wiele partycji, istnieje wiele obciążeń związanych z zarządzaniem niewielką liczbą zadań.
Użyj metryk użycia zasobów, aby rozwiązać problemy ze niesymetrycznością partycji i błędną alokacją funkcji wykonawczych w klastrze. Jeśli partycja jest niesymetryczna, zasoby funkcji wykonawczej zostaną podniesione w porównaniu z innymi funkcjami wykonawczych uruchomionymi w klastrze.
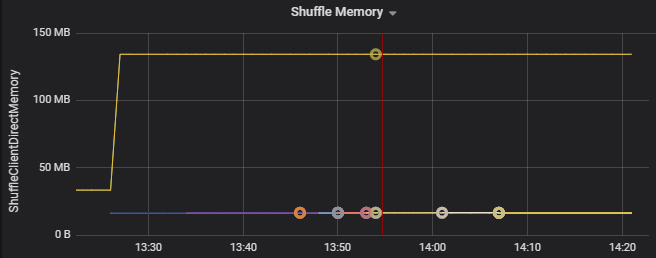
Na przykład na poniższym wykresie pokazano, że pamięć używana przez przetasowanie w dwóch pierwszych funkcjach wykonawczych jest 90 X większa niż inne funkcje wykonawcze:
Następne kroki
- Monitorowanie usługi Azure Databricks w obszarze roboczym usługi Azure Log Analytics
- Ścieżka szkoleniowa: tworzenie i obsługa rozwiązań uczenia maszynowego za pomocą usługi Azure Databricks
- Dokumentacja usługi Azure Databricks
- Omówienie usługi Azure Monitor
Powiązane zasoby
- Monitorowanie usługi Azure Databricks
- Wysyłanie dzienników aplikacji usługi Azure Databricks do usługi Azure Monitor
- Wizualizowanie metryk usługi Azure Databricks za pomocą pulpitów nawigacyjnych
- Nowoczesna architektura analizy za pomocą usługi Azure Databricks
- Pozyskiwanie, ETL (wyodrębnianie, przekształcanie, ładowanie) i potoki przetwarzania strumieniowego za pomocą usługi Azure Databricks