Co to jest magazyn typu „data lake”?
Usługa Data Lake to repozytorium magazynu, które przechowuje dużą ilość danych w natywnym, nieprzetworzonym formacie. Magazyny data lake są zoptymalizowane pod kątem skalowania ich rozmiaru do terabajtów i petabajtów danych. Dane zazwyczaj pochodzą z wielu różnych źródeł i mogą obejmować dane ustrukturyzowane, częściowo ustrukturyzowane lub nieustrukturyzowane. Usługa Data Lake pomaga przechowywać wszystko w oryginalnym, nieprzetłumaczonym stanie. Ta metoda różni się od tradycyjnego magazynu danych, który przekształca i przetwarza dane w czasie pozyskiwania.
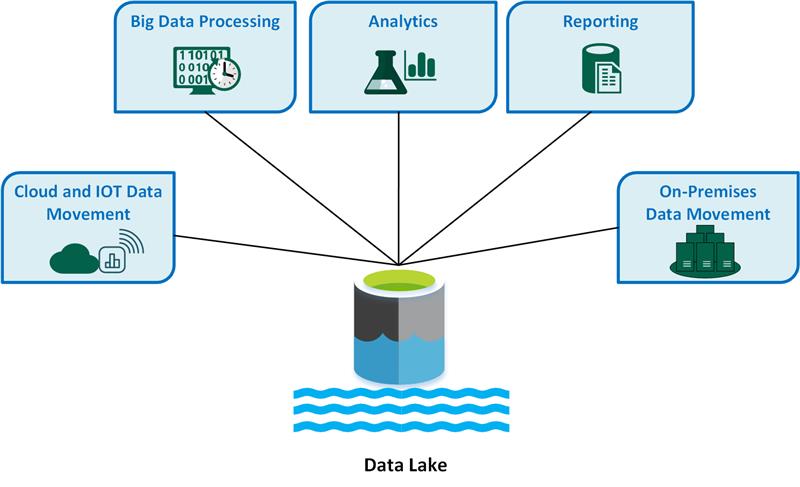
Przypadki użycia usługi Key Data Lake obejmują:
- Przenoszenie danych w chmurze i Internetu rzeczy (IoT).
- Przetwarzanie danych big data.
- Analiza.
- Reporting.
- Lokalne przenoszenie danych.
Rozważ następujące zalety usługi Data Lake:
Usługa Data Lake nigdy nie usuwa danych, ponieważ przechowuje dane w formacie nieprzetworzonym. Ta funkcja jest szczególnie przydatna w środowisku danych big data, ponieważ możesz nie wiedzieć z wyprzedzeniem, jakie szczegółowe informacje można uzyskać z danych.
Użytkownicy mogą eksplorować dane i tworzyć własne zapytania.
Usługa Data Lake może być szybsza niż tradycyjne narzędzia do wyodrębniania, przekształcania, ładowania (ETL).
Usługa Data Lake jest bardziej elastyczna niż magazyn danych, ponieważ może przechowywać dane bez struktury i częściowo ustrukturyzowane.
Kompletne rozwiązanie typu data lake składa się zarówno z magazynu, jak i przetwarzania. Usługa Data Lake Storage została zaprojektowana pod kątem odporności na uszkodzenia, nieskończonej skalowalności i pozyskiwania o wysokiej przepływności różnych kształtów i rozmiarów danych. Przetwarzanie w usłudze Data Lake obejmuje co najmniej jeden aparat przetwarzania, który może uwzględniać te cele i może działać na danych przechowywanych w magazynie data lake na dużą skalę.
Kiedy należy używać usługi Data Lake
Zalecamy użycie magazynu data lake do eksploracji danych, analizy danych i uczenia maszynowego.
Usługa Data Lake może pełnić rolę źródła danych dla magazynu danych. Gdy używasz tej metody, usługa Data Lake pozyskuje nieprzetworzone dane, a następnie przekształca je w ustrukturyzowany format zapytań. Zazwyczaj ta transformacja używa potoku wyodrębniania, ładowania, przekształcania (ELT), w którym dane są pozyskiwane i przekształcane. Dane relacyjne źródła mogą przechodzić bezpośrednio do magazynu danych za pośrednictwem procesu ETL i pomijać magazyn danych typu data lake.
Usługi Data Lake Store można używać w scenariuszach przesyłania strumieniowego zdarzeń lub IoT, ponieważ magazyny danych mogą utrwalać duże ilości danych relacyjnych i nierelacyjnych bez przekształcania ani definicji schematu. Magazyny Data Lake mogą obsługiwać duże ilości małych zapisów przy małych opóźnieniach i są zoptymalizowane pod kątem ogromnej przepływności.
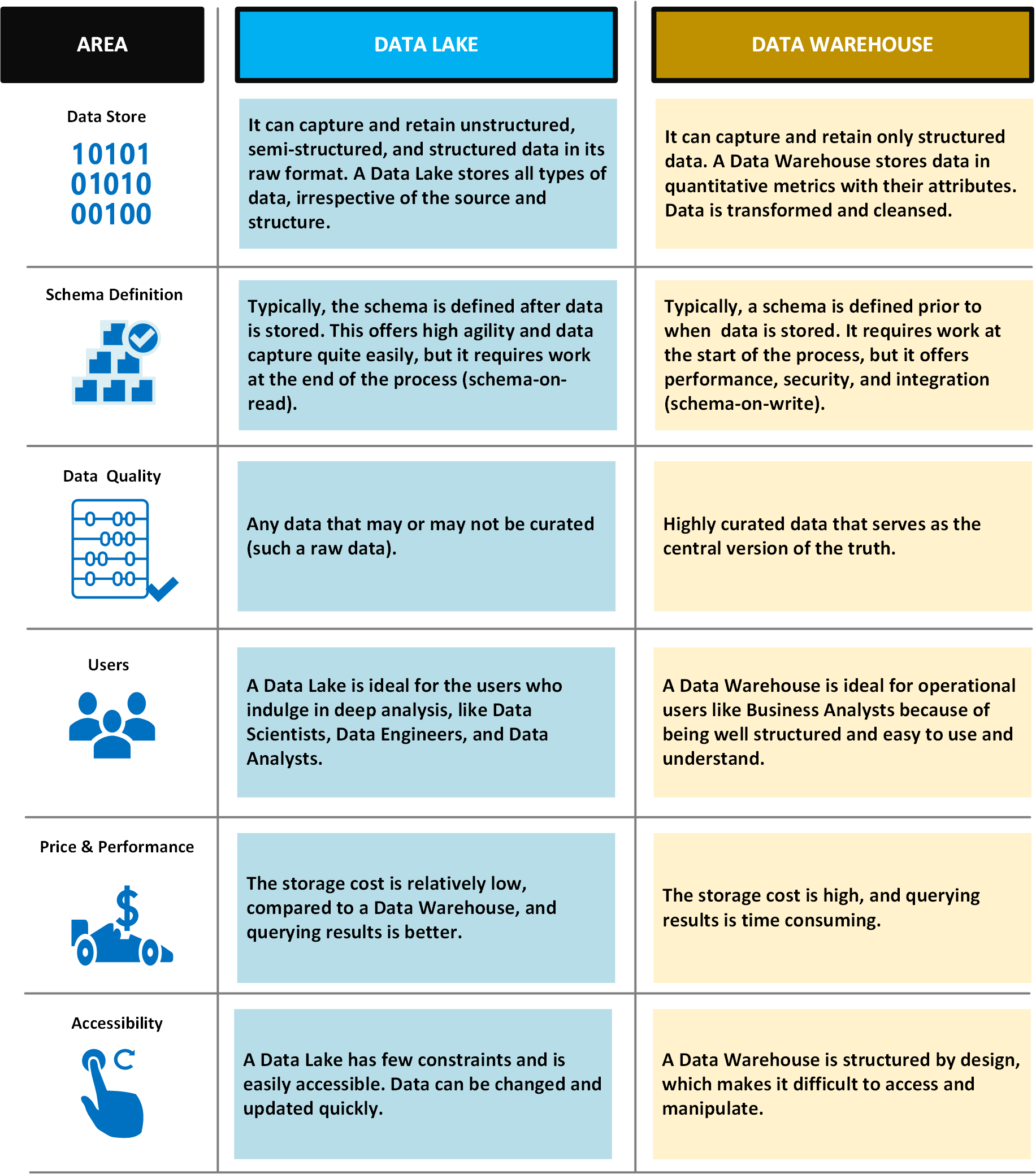
W poniższej tabeli porównano magazyny danych i magazyny danych.
Wyzwania
Duże ilości danych: zarządzanie ogromnymi ilościami nieprzetworzonych i nieustrukturyzowanych danych może być złożone i intensywnie korzystające z zasobów, dzięki czemu potrzebujesz niezawodnej infrastruktury i narzędzi.
Potencjalne wąskie gardła: Przetwarzanie danych może powodować opóźnienia i nieefektywność, szczególnie w przypadku dużych ilości danych i różnych typów danych.
Ryzyko uszkodzenia danych: Niewłaściwe sprawdzanie poprawności i monitorowanie danych powoduje ryzyko uszkodzenia danych, co może naruszyć integralność usługi Data Lake.
Problemy z kontrolą jakości: Właściwa jakość danych jest wyzwaniem ze względu na różne źródła danych i formaty. Należy wdrożyć rygorystyczne rozwiązania dotyczące ładu w zakresie danych.
Problemy z wydajnością: wydajność zapytań może ulec pogorszeniu w miarę wzrostu magazynu i przetwarzania, dlatego należy zoptymalizować strategie magazynowania i przetwarzania.
Wybór technologi
Podczas tworzenia kompleksowego rozwiązania data lake na platformie Azure należy wziąć pod uwagę następujące technologie:
Usługa Azure Data Lake Storage łączy usługę Azure Blob Storage z funkcjami typu data lake, która zapewnia dostęp zgodny z usługą Apache Hadoop, hierarchiczne możliwości przestrzeni nazw i ulepszone zabezpieczenia na potrzeby wydajnej analizy danych big data.
Azure Databricks to ujednolicona platforma, której można używać do przetwarzania, przechowywania, analizowania i zarabiania danych. Obsługuje ona procesy ETL, pulpity nawigacyjne, zabezpieczenia, eksplorację danych, uczenie maszynowe i generowanie sztucznej inteligencji.
Azure Synapse Analytics to ujednolicona usługa, której można użyć do pozyskiwania, eksplorowania, przygotowywania i udostępniania danych oraz zarządzania nimi na potrzeby natychmiastowej analizy biznesowej i uczenia maszynowego. Integruje się głęboko z usługą Azure Data Lake, dzięki czemu można wydajnie wykonywać zapytania i analizować duże zestawy danych.
Azure Data Factory to oparta na chmurze usługa integracji danych, której można użyć do tworzenia przepływów pracy opartych na danych w celu organizowania i automatyzowania przenoszenia i przekształcania danych.
Microsoft Fabric to kompleksowa platforma danych, która łączy inżynierię danych, naukę o danych, magazynowanie danych, analizę w czasie rzeczywistym i analizę biznesową w jednym rozwiązaniu.
Współautorzy
Ten artykuł jest obsługiwany przez firmę Microsoft. Pierwotnie został napisany przez następujących współautorów.
Główny autor:
- Avijit Prasad | Konsultant ds. chmury
Aby wyświetlić niepubalne profile serwisu LinkedIn, zaloguj się do serwisu LinkedIn.
Następne kroki
- Co to jest OneLake?
- Wprowadzenie do usługi Data Lake Storage
- Dokumentacja usługi Azure Data Lake Analytics
- Szkolenie: wprowadzenie do usługi Data Lake Storage
- Integracja usług Hadoop i Azure Data Lake Storage
- Nawiązywanie połączenia z usługą Data Lake Storage i usługą Blob Storage
- Ładowanie danych do usługi Data Lake Storage za pomocą usługi Azure Data Factory