W tym artykule opisano niektóre strategie partycjonowania danych w różnych magazynach danych platformy Azure. Aby uzyskać ogólne wskazówki dotyczące partycjonowania danych i najlepszych rozwiązań, zobacz Partycjonowanie danych.
Partycjonowanie usługi Azure SQL Database
Ilość danych, które może zawierać jedna baza danych SQL, jest ograniczona. Czynniki związane z architekturą oraz liczba obsługiwanych połączeń współbieżnych ograniczają przepływność.
Pule elastyczne obsługują skalowanie w poziomie dla bazy danych SQL. Za pomocą elastycznych pul można podzielić dane na fragmenty rozłożone na wiele baz danych SQL. Możesz także dodawać lub usuwać fragmenty w miarę zwiększania lub zmniejszania ilości obsługiwanych danych. Elastyczne pule mogą również pomóc zmniejszyć rywalizację poprzez dystrybucję obciążenia między bazami danych.
Każdy fragment jest wdrażany jako oddzielna baza danych SQL. Fragment może zawierać więcej niż jeden zestaw danych (nazywany fragmentem). Każda baza danych zawiera metadane opisujące znajdujące się w tej bazie podfragmenty. Fragmentlet może być pojedynczym elementem danych lub grupą elementów, które współużytkujące ten sam klucz fragmentu. Na przykład w aplikacji wielodostępnej klucz podfragmentu może być identyfikatorem dzierżawy, a wszystkie dane dzierżawy mogą być przechowywane w tym samym podfragmentze.
Aplikacje klienckie są odpowiedzialne za kojarzenie zestawu danych z kluczem podfragmentu. Oddzielna baza danych SQL działa jako globalny menedżer mapy fragmentów. Ta baza danych zawiera listę wszystkich fragmentów i fragmentów w systemie. Aplikacja łączy się z bazą danych menedżera map fragmentów w celu uzyskania kopii mapy fragmentów. Buforuje ona lokalnie mapę fragmentów i używa mapy do kierowania żądań danych do odpowiedniego fragmentu. Ta funkcja jest ukryta za serią interfejsów API zawartych w bibliotece klienta elastic database, która jest dostępna dla języków Java i .NET.
Aby uzyskać więcej informacji na temat elastycznych pul, zobacz Skalowanie w górę za pomocą usługi Azure SQL Database.
Aby zmniejszyć opóźnienia i zwiększyć dostępność, można replikować globalną bazę danych menedżera map fragmentów. W warstwach cenowych Premium można skonfigurować aktywną replikację geograficzną, aby stale kopiować dane do baz danych w różnych regionach.
Alternatywnie użyj usługi Azure SQL Data Sync lub Azure Data Factory , aby replikować bazę danych menedżera map fragmentów w różnych regionach. Ta forma replikacji jest okresowo uruchamiana i jest bardziej odpowiednia, jeśli mapa fragmentów zmienia się rzadko i nie wymaga warstwy Premium.
Funkcja Elastic Database udostępnia dwa schematy mapowania danych na podfragmenty i przechowywania ich we fragmentach:
Mapa fragmentów listy kojarzy pojedynczy klucz z podfragmentem. Na przykład w systemie wielodostępnym dane każdej dzierżawy mogą być skojarzone z unikatowym kluczem i przechowywane w oddzielnym podfragmencie. Aby zagwarantować izolację, każdy fragment może być przechowywany w ramach własnego fragmentu.

Pobierz plik programu Visio z tego diagramu.
Mapa fragmentów zakresu kojarzy zestaw ciągłych wartości kluczy do fragmentu. Można na przykład zgrupować dane dla zestawu dzierżaw (z których każdy ma własny klucz) w ramach tego samego fragmentu. Ten schemat jest mniej kosztowny niż pierwszy, ponieważ dzierżawcy współdzielą magazyn danych, ale mają mniej izolacji.

Pobieranie pliku programu Visio z tego diagramu
Pojedynczy fragment może zawierać dane dla kilku fragmentów. Można na przykład użyć podfragmentów z mapowaniem w postaci listy do przechowywania danych różnych, niesąsiadujących ze sobą dzierżaw w jednym fragmencie. Można również mieszać podfragmenty zakresu i podfragmenty listy w tym samym fragmentzie, chociaż będą one rozwiązywane za pomocą różnych map. Na poniższym diagramie przedstawiono takie podejście:

Pobierz plik programu Visio z tego diagramu.
Elastyczne pule umożliwiają dodawanie i usuwanie fragmentów w miarę zmniejszania i zmniejszania ilości danych. Aplikacje klienckie mogą dynamicznie tworzyć i usuwać fragmenty oraz w sposób niewidoczny aktualizować menedżera map fragmentów. Jednak usunięcie fragmentu jest operacją destrukcyjną, która wymaga również usunięcia wszystkich danych zawartych w tym fragmencie.
Jeśli aplikacja musi podzielić fragment na dwa oddzielne fragmenty lub połączyć fragmenty, użyj narzędzia split-merge. To narzędzie działa jako usługa internetowa platformy Azure i bezpiecznie migruje dane między fragmentami.
Schemat partycjonowania może znacząco wpłynąć na wydajność systemu. Może to również mieć wpływ na szybkość dodawania lub usuwania fragmentów albo ponowne partycjonowanie danych między fragmentami. Rozważ następujące punkty:
Grupuj dane używane razem w tym samym fragmentzie i unikaj operacji, które uzyskują dostęp do danych z wielu fragmentów. Fragment jest własną bazą danych SQL, a sprzężenia między bazami danych muszą być wykonywane po stronie klienta.
Chociaż usługa SQL Database nie obsługuje sprzężeń między bazami danych, można użyć narzędzi Elastic Database do wykonywania zapytań obejmujących wiele fragmentów. Zapytanie obejmujące wiele fragmentów wysyła poszczególne zapytania do każdej bazy danych i scala wyniki.
Nie projektuj systemu, który ma zależności między fragmentami. Ograniczenia integralności referencyjnej, wyzwalacze i procedury składowane w jednej bazie danych nie mogą odwoływać się do obiektów w innej bazie danych.
Jeśli masz dane referencyjne, które są często używane przez zapytania, rozważ replikowanie tych danych między fragmentami. Takie podejście może usunąć konieczność łączenia danych między bazami danych. W idealnym przypadku takie dane powinny być statyczne lub wolno przenoszone, aby zminimalizować nakład pracy związany z replikacją i zmniejszyć prawdopodobieństwo ich nieaktualności.
Fragmenty należące do tej samej mapy fragmentów powinny mieć ten sam schemat. Ta reguła nie jest wymuszana przez usługę SQL Database, ale zarządzanie danymi i wykonywanie zapytań staje się bardzo złożone, jeśli każdy fragmentlet ma inny schemat. Zamiast tego utwórz oddzielne mapy fragmentów dla każdego schematu. Pamiętaj, że dane należące do różnych fragmentów mogą być przechowywane w tym samym fragmentzie.
Operacje transakcyjne są obsługiwane tylko w przypadku danych w obrębie fragmentu, a nie między fragmentami. Transakcje mogą obejmować wiele podfragmentów, o ile należą one do jednego fragmentu. W związku z tym, jeśli logika biznesowa musi wykonywać transakcje, zapisz dane w tym samym fragmentze lub zaimplementuj spójność ostateczną.
Umieść fragmenty w pobliżu użytkowników, którzy uzyskują dostęp do danych w tych fragmentach. Ta strategia umożliwia zminimalizowanie opóźnień.
Unikaj posiadania mieszaniny bardzo aktywnych i stosunkowo nieaktywnych fragmentów. Należy dążyć do równomiernego rozłożenia obciążenia fragmentów. Może to wymagać tworzenia skrótów kluczy fragmentowania. Jeśli zastosowano geolokalizację fragmentów, należy upewnić się, że skróty kluczy są mapowane na podfragmenty przechowywane we fragmentach położonych w pobliżu użytkowników, którzy korzystają z danych.
Partycjonowanie usługi Azure Table Storage
Azure Table Storage to magazyn klucz-wartość zaprojektowany wokół partycjonowania. Wszystkie jednostki są przechowywane w partycji, a partycje są zarządzane wewnętrznie przez usługę Azure Table Storage. Każda jednostka przechowywana w tabeli musi zawierać dwuczęściowy klucz, który obejmuje:
Klucz partycji. Jest to wartość ciągu, która określa partycję, w której usługa Azure Table Storage umieści jednostkę. Wszystkie jednostki z tym samym kluczem partycji są przechowywane w tej samej partycji.
Klucz wiersza. Jest to wartość ciągu, która identyfikuje jednostkę w partycji. Wszystkie jednostki w partycji są sortowane leksykalnie, w kolejności rosnącej, według tego klucza. Kombinacja klucza partycji i klucza wiersza musi być unikatowa dla jednostki, a jej długość nie może przekraczać 1 KB.
Jeśli jednostka zostanie dodana do tabeli z wcześniej nieużywanym kluczem partycji, usługa Azure Table Storage utworzy nową partycję dla tej jednostki. Inne jednostki z takim samym kluczem partycji będą przechowywane w tej samej partycji.
Ten mechanizm w praktyce oznacza wdrożenie strategii automatycznego skalowania w poziomie. Każda partycja jest przechowywana na tym samym serwerze w centrum danych platformy Azure, aby zapewnić szybkie uruchamianie zapytań pobierających dane z pojedynczej partycji.
Firma Microsoft opublikowała cele skalowalności dla usługi Azure Storage. Jeśli system prawdopodobnie przekroczy te limity, rozważ podzielenie jednostek na wiele tabel. Zastosuj partycjonowanie pionowe, aby pogrupować pola, które mogą być używane razem.
Na poniższym diagramie przedstawiono strukturę logiczną przykładowego konta magazynu. Konto magazynu zawiera trzy tabele: Dane klientów, Dane produktów i Dane zamówień.
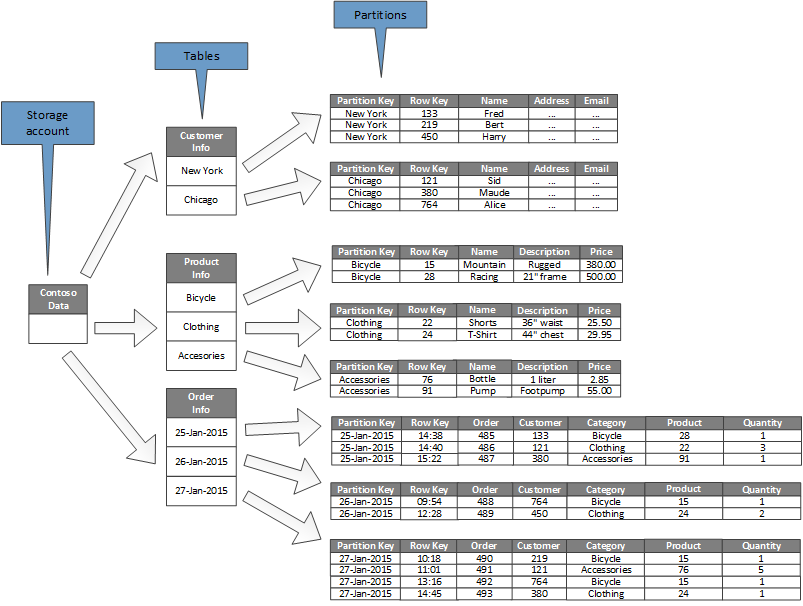
Każda tabela jest podzielona na partycje.
- W tabeli Informacje o kliencie dane są partycjonowane według miasta, w którym znajduje się klient. Klucz wiersza zawiera identyfikator klienta.
- W tabeli Informacje o produkcie produkty są partycjonowane według kategorii produktów, a klucz wiersza zawiera numer produktu.
- W tabeli Informacje o zamówieniu zamówienia zamówienia są partycjonowane według daty zamówienia, a klucz wiersza określa godzinę odebrania zamówienia. Wszystkie dane są uporządkowane według klucza wiersza w każdej partycji.
Podczas projektowania jednostek dla usługi Azure Table Storage należy wziąć pod uwagę następujące kwestie:
Wybierz klucz partycji i klucz wiersza według sposobu uzyskiwania dostępu do danych. Wybierz kombinację klucza partycji i klucza wiersza odpowiednią dla większości wykonywanych zapytań. Najbardziej wydajne zapytania pobierają dane przez określenie klucza partycji i klucza wiersza. Zapytania określające klucz partycji oraz zakres kluczy wierszy mogą zostać wykonane przez skanowanie jednej partycji. Dzieje się to relatywnie szybko, ponieważ dane przechowywane są w kolejności kluczy wiersza. Jeśli zapytania nie określają partycji do skanowania, każda partycja musi zostać przeskanowana.
Jeśli określona jednostka ma jeden, naturalny klucz, użyj go jako klucza partycji, a jako klucz wiersza wprowadź pusty ciąg. Jeśli jednostka ma klucz złożony składający się z dwóch właściwości, wybierz najwolniej zmieniającą właściwość jako klucz partycji, a drugi jako klucz wiersza. Jeśli jednostka ma więcej niż dwie właściwości klucza, użyj połączenia tych właściwości w celu określenia klucza partycji i klucza wiersza.
Jeśli regularnie wykonujesz zapytania, które wyszukują dane przy użyciu pól innych niż klucze partycji i wierszy, rozważ zaimplementowanie wzorca tabeli indeksu lub rozważ użycie innego magazynu danych obsługującego indeksowanie, takiego jak usługa Azure Cosmos DB.
W przypadku generowania kluczy partycji przy użyciu sekwencji monotonicznej (takiej jak "0001", "0002", "0003") i każda partycja zawiera tylko ograniczoną ilość danych, usługa Azure Table Storage może fizycznie zgrupować te partycje na tym samym serwerze. Usługa Azure Storage zakłada, że aplikacja najprawdopodobniej wykonuje zapytania w ciągłym zakresie partycji (zapytania zakresu) i jest zoptymalizowana pod kątem tego przypadku. Jednak takie podejście może prowadzić do hotspotów, ponieważ wszystkie wstawienia nowych jednostek mogą być skoncentrowane na jednym końcu ciągłego zakresu. Innym następstwem może być ograniczenie skalowalności. Aby jeszcze bardziej równomiernie rozłożyć obciążenie, rozważ utworzenie skrótu klucza partycji.
Usługa Azure Table Storage obsługuje operacje transakcyjne dla jednostek należących do tej samej partycji. Aplikacja może wykonywać wiele operacji wstawiania, aktualizowania, usuwania, zastępowania lub scalania jako jednostki niepodzielnej, o ile transakcja nie zawiera więcej niż 100 jednostek, a ładunek żądania nie przekracza 4 MB. Operacje obejmujące wiele partycji nie są transakcyjne i mogą wymagać zaimplementowania spójności ostatecznej. Aby uzyskać więcej informacji na temat magazynu tabel i transakcji, zobacz Wykonywanie transakcji grupy jednostek.
Rozważ stopień szczegółowości klucza partycji:
Użycie tego samego klucza partycji dla każdej jednostki powoduje utworzenie pojedynczej partycji przechowywanej na jednym serwerze. Zapobiega to skalowaniu partycji w poziomie i skupia obciążenie na jednym serwerze. W związku z tym takie podejście jest odpowiednie tylko do przechowywania niewielkiej liczby jednostek. Jednak zapewnia, że wszystkie jednostki mogą uczestniczyć w transakcjach grupy jednostek.
Użycie unikatowego klucza partycji dla każdej jednostki powoduje utworzenie oddzielnej partycji dla każdej jednostki, co może spowodować powstanie dużej liczby małych partycji. Takie rozwiązanie zapewnia większą skalowalność niż użycie jednego klucza partycji, ale uniemożliwia wykonywanie transakcji grup jednostek. Ponadto zapytania pobierające dane z większej liczby jednostek mogą wymagać odczytu danych z większej liczby serwerów. Jeśli jednak aplikacja wykonuje zapytania zakresu, użycie sekwencji monotonicznej dla kluczy partycji może pomóc w optymalizacji tych zapytań.
Udostępnianie klucza partycji w podzestawie jednostek umożliwia grupowanie powiązanych jednostek w tej samej partycji. Operacje na powiązanych jednostkach można wykonywać przy użyciu transakcji grup jednostek, a zapytania pobierające zestaw powiązanych jednostek wymagają dostępu tylko do jednego serwera.
Aby uzyskać więcej informacji, zobacz Przewodnik projektowania tabel usługi Azure Storage i Skalowalna strategia partycjonowania.
Partycjonowanie usługi Azure Blob Storage
Usługa Azure Blob Storage umożliwia przechowywanie dużych obiektów binarnych. Blokowe obiekty blob można używać w scenariuszach, gdy trzeba szybko przekazać lub pobrać duże ilości danych. Stronicowe obiekty blob są odpowiednie dla aplikacji wymagających losowego, a nie szeregowego dostępu do różnych części danych.
Każdy obiekt blob (blok lub strona) jest przechowywany w kontenerze na koncie usługi Azure Storage. Kontenery umożliwiają grupowanie powiązanych obiektów blob, mających takie same wymagania dotyczące zabezpieczeń. To grupowanie ma charakter logiczny, a nie fizyczny. Każdy obiekt blob w kontenerze ma unikatową nazwę.
Na klucz partycji obiektu blob składa się nazwa konta, nazwa kontenera i nazwa obiektu blob. Klucz partycji jest używany do partycjonowania danych na zakresy, a te zakresy są zrównoważone w całym systemie. Obiekty blob mogą być przechowywane na wielu serwerach, aby zapewnić skalowanie dostępu do nich, ale jeden obiekt blob może być obsługiwany tylko przez jeden serwer.
Jeśli schemat nazewnictwa używa sygnatur czasowych lub identyfikatorów liczbowych, może to prowadzić do nadmiernego ruchu przechodzącego do jednej partycji, ograniczając system od efektywnego równoważenia obciążenia. Jeśli na przykład masz codzienne operacje, które używają obiektu blob z sygnaturą czasową, taką jak rrrr-mm-dd, cały ruch dla tej operacji będzie przechodzić do pojedynczego serwera partycji. Zamiast tego należy rozważyć prefiksowanie nazwy z trzycyfrowym skrótem. Aby uzyskać więcej informacji, zobacz Partition Naming Convention (Konwencja nazewnictwa partycji).
Akcje zapisu pojedynczego bloku lub strony są niepodzielne, ale operacje obejmujące bloki, strony lub obiekty blob nie są. Jeśli konieczne jest zapewnienie spójności podczas wykonywania operacji zapisu obejmujących więcej bloków, stron lub obiektów blob, uzyskaj blokadę zapisu przy użyciu dzierżawy obiektu blob.
Partycjonowanie kolejek usługi Azure Storage
Kolejki usługi Azure Storage umożliwiają implementowanie asynchronicznych komunikatów między procesami. Konto usługi Azure Storage może zawierać dowolną liczbę kolejek, a każda kolejka może zawierać dowolną liczbę komunikatów. Jedynym ograniczeniem jest dostępna przestrzeń na koncie magazynu. Maksymalny rozmiar jednego komunikatu wynosi 64 KB. Jeśli potrzebujesz większych komunikatów, rozważ użycie kolejek usługi Azure Service Bus.
Każda kolejka magazynu ma unikatową nazwę w ramach konta magazynu. Na platformie Azure kolejki są partycjonowane na podstawie nazwy. Wszystkie komunikaty w ramach jednej kolejki są przechowywane w jednej partycji, kontrolowanej przez jeden serwer. Różnymi kolejkami może zarządzać większa liczba serwerów, co umożliwia równoważenie obciążenia. Kolejki są przydzielane do serwerów w sposób niewidoczny dla aplikacji i użytkowników.
W aplikacji na dużą skalę nie używaj tej samej kolejki magazynu dla wszystkich wystąpień aplikacji, ponieważ takie podejście może spowodować, że serwer hostujący kolejkę stanie się punktem gorącym. Zamiast tego użyj różnych kolejek dla różnych obszarów funkcjonalnych aplikacji. Kolejki usługi Azure Storage nie obsługują transakcji, więc kierowanie komunikatów do różnych kolejek powinno mieć niewielki wpływ na spójność komunikatów.
Kolejka usługi Azure Storage może obsługiwać maksymalnie 2000 komunikatów na sekundę. Jeśli potrzebujesz szybszego przetwarzania komunikatów, rozważ utworzenie większej liczby kolejek. Na przykład w aplikacji globalnej możesz utworzyć oddzielne kolejki magazynu na oddzielnych kontach magazynu dla wystąpień aplikacji uruchomionych w poszczególnych regionach.
Partycjonowanie usługi Azure Service Bus
Komunikaty wysyłane do kolejki lub tematu usługi Azure Service Bus są obsługiwane przy użyciu brokera komunikatów. Domyślnie wszystkie komunikaty wysłane do kolejki lub tematu są obsługiwane przez ten sam proces brokera komunikatów. Ta architektura może ograniczać ogólną przepływność kolejki komunikatów. Można jednak również partycjonować tworzone kolejki lub tematy. W tym celu należy ustawić wartość true dla właściwości EnablePartitioning kolejki lub tematu.
Partycjonowanie polega na podzieleniu kolejki lub tematu na fragmenty, z których każdy jest obsługiwany przez oddzielny magazyn komunikatów i oddzielnego brokera komunikatów. Usługa Service Bus odpowiada za utworzenie tych fragmentów i zarządzanie nimi. Gdy aplikacja wysyła komunikat do kolejki lub tematu z partycjami, usługa Service Bus przydziela ten komunikat do odpowiedniego fragmentu kolejki lub tematu. Gdy aplikacja otrzymuje komunikat z kolejki lub subskrypcji, usługa Service Bus sprawdza poszczególne fragmenty w poszukiwaniu kolejnego dostępnego komunikatu, a następnie przekazuje go do aplikacji w celu przetworzenia.
Taka struktura przyczynia się do rozłożenia obciążenia między brokerami i magazynami komunikatów, zwiększając skalowalność i dostępność. Jeśli broker lub magazyn komunikatów dla określonego fragmentu jest tymczasowo niedostępny, usługa Service Bus może pobrać komunikaty z jednego z pozostałych, dostępnych fragmentów.
Usługa Service Bus przypisuje komunikaty do fragmentów w następujący sposób:
Jeśli komunikat należy do sesji, wszystkie komunikaty o tej samej wartości właściwości SessionId są wysyłane do tego samego fragmentu.
Jeśli komunikat nie należy do sesji, ale nadawca określił wartość właściwości PartitionKey, wszystkie komunikaty z taką samą wartością PartitionKey są wysyłane do tego samego fragmentu.
Uwaga
Jeśli określono zarówno właściwość SessionId, jak i PartitionKey, muszą one mieć taką samą wartość — w przeciwnym razie komunikat zostanie odrzucony.
Jeśli nie określono wartości właściwości SessionId ani PartitionKey dla komunikatu, ale włączono funkcję wykrywania duplikatów, zostanie użyta właściwość MessageId. Wszystkie komunikaty z taką samą wartością właściwości MessageId zostaną skierowane do tego samego fragmentu.
Jeśli komunikaty nie mają właściwości SessionId, PartitionKey, ani MessageId, zostaną przypisane do fragmentów w usłudze Service Bus sekwencyjnie. Jeśli określony fragment jest niedostępny, usługa Service Bus przejdzie do kolejnego. To oznacza, że tymczasowy błąd w infrastrukturze komunikacji nie spowoduje niepowodzenia operacji wysyłania komunikatu.
Podejmując decyzję o partycjonowaniu (lub sposobie partycjonowania) kolejki komunikatów lub tematu w usłudze Service Bus, weź pod uwagę następujące kwestie:
Kolejki i tematy usługi Service Bus są tworzone w ramach przestrzeni nazw usługi Service Bus. Obecnie w usłudze Service Bus można utworzyć maksymalnie 100 partycjonowanych kolejek lub tematów w każdej przestrzeni nazw.
W każdej przestrzeni nazw usługi Service Bus obowiązują limity przydziału dostępnych zasobów, na przykład liczby subskrypcji w temacie, liczby równoczesnych żądań wysyłania i odbierania na sekundę, czy maksymalnej liczby nawiązywanych połączeń współbieżnych. Te przydziały są udokumentowane w temacie Limity przydziału usługi Service Bus. Jeśli spodziewasz się, że te wartości zostaną przekroczone, utwórz dodatkowe przestrzenie nazw, zawierające dodatkowe kolejki i tematy, a następnie rozdziel obciążenie między te przestrzenie nazw. Na przykład w przypadku aplikacji globalnej możesz utworzyć oddzielne przestrzenie nazw w poszczególnych regionach i skonfigurować wystąpienia aplikacji tak, aby używały kolejek i tematów znajdujących się w najbliższej przestrzeni nazw.
Komunikaty wysyłane w ramach transakcji muszą określać klucz partycji. Może to być właściwość SessionId, PartitionKey lub MessageId. Wszystkie komunikaty wysyłane w ramach tej samej transakcji muszą określać ten sam klucz partycji, ponieważ muszą być obsługiwane przez ten sam proces brokera komunikatów. Nie można wysyłać komunikatów do wielu kolejek lub tematów w ramach jednej transakcji.
Nie można skonfigurować automatycznego usuwania nieaktywnych partycjonowanych kolejek i tematów.
Obecnie nie można używać partycjonowanych kolejek i tematów z protokołem Advanced Message Queuing Protocol (AMQP) w przypadku tworzenia rozwiązań międzyplatformowych i hybrydowych.
Partycjonowanie usługi Azure Cosmos DB
Usługa Azure Cosmos DB for NoSQL to baza danych NoSQL służąca do przechowywania dokumentów JSON. Dokument w bazie danych usługi Azure Cosmos DB jest serializowaną reprezentacją obiektu lub innego elementu danych w formacie JSON. Nie jest wymuszane stosowanie żadnego określonego schematu, ale każdy dokument musi zawierać unikatowy identyfikator.
Dokumenty są uporządkowane w kolekcjach. Kolekcje umożliwiają grupowanie powiązanych dokumentów. Na przykład w systemie do zarządzania wpisami w blogu można przechowywać zawartość każdego wpisu jako dokument w kolekcji. Można także utworzyć kolekcje dla poszczególnych tematów. Natomiast w aplikacji wielodostępnej, na przykład w systemie, w którym różni autorzy zarządzają własnymi wpisami w blogach, można wdrożyć partycjonowanie blogów według autorów i utworzyć oddzielną kolekcję dla każdego autora. Miejsce do magazynowania przydzielone do kolekcji jest elastyczne i może zwiększać się lub zmniejszać stosownie do potrzeb.
Usługa Azure Cosmos DB obsługuje automatyczne partycjonowanie danych na podstawie klucza partycji zdefiniowanego przez aplikację. Partycja logiczna to partycja, w której przechowywane są wszystkie dane związane z jedną wartością klucza partycji. Wszystkie dokumenty mające tę samą wartość klucza partycji są umieszczane w jednej partycji logicznej. Usługa Azure Cosmos DB dystrybuuje wartości według skrótu klucza partycji. Partycja logiczna ma maksymalny rozmiar 20 GB. Dlatego wybór klucza partycji stanowi ważną decyzję, którą należy podjąć w czasie projektowania. Wybierz właściwość mającą szeroki zakres wartości, a nawet wzorców dostępu. Aby uzyskać więcej informacji, zobacz Partition and scale in Azure Cosmos DB (Partycjonowanie i skalowanie w usłudze Azure Cosmos DB).
Uwaga
Każda baza danych usługi Azure Cosmos DB ma poziom wydajności, który określa ilość pobieranych zasobów. Poziom wydajności jest związany z limitem jednostek żądań. Limit jednostek żądań określa ilość zasobów zarezerwowanych i dostępnych do wyłącznego użytku przez daną kolekcję. Koszt kolekcji zależy od wybranego dla niej poziomu wydajności. Im wyższy poziom wydajności (i limit jednostek żądań), tym wyższe opłaty. Poziom wydajności kolekcji można dostosować w witrynie Azure Portal. Aby uzyskać więcej informacji, zobacz Jednostki żądań w usłudze Azure Cosmos DB.
Jeśli mechanizm partycjonowania zapewniany przez usługę Azure Cosmos DB nie jest wystarczający, może być konieczne podzielenie danych na poziomie aplikacji. Kolekcje dokumentów oferują naturalny mechanizm partycjonowania danych w jednej bazie danych. Najprostszym sposobem wdrożenia fragmentowania jest utworzenie oddzielnej kolekcji dla każdego fragmentu. Kontenery są zasobami logicznymi i mogą znajdować się na jednym serwerze lub na wielu. Kontenery o stałym rozmiarze mają maksymalny limit 20 GB i 10 000 RU/s przepływności. Kontenery bez ograniczeń nie mają maksymalnego rozmiaru magazynu, ale muszą określać klucz partycji. W przypadku fragmentowania na poziomie aplikacji to aplikacja kliencka musi kierować żądania do właściwego fragmentu — zazwyczaj przy użyciu własnego mechanizmu mapowania opartego na określonych atrybutach danych, które definiują klucz fragmentu.
Wszystkie bazy danych są tworzone w kontekście konta bazy danych usługi Azure Cosmos DB. Jedno konto może zawierać większą liczbę baz danych i określa regiony, w których te bazy danych zostały utworzone. Każde konto wymusza także własne mechanizmy kontroli dostępu. Konta usługi Azure Cosmos DB można używać do lokalizowania fragmentów geograficznych (kolekcji w bazach danych) blisko użytkowników, którzy muszą uzyskać do nich dostęp, i wymuszać ograniczenia, aby tylko ci użytkownicy mogli się z nimi łączyć.
Podczas podejmowania decyzji o sposobie partycjonowania danych za pomocą usługi Azure Cosmos DB for NoSQL należy wziąć pod uwagę następujące kwestie:
Zasoby dostępne dla bazy danych usługi Azure Cosmos DB podlegają ograniczeniom przydziału konta. Każda baza danych może zawierać wiele kolekcji, a każda kolekcja ma przypisany poziom wydajności, określający limit jednostek żądań (zarezerwowaną przepływność) dla tej kolekcji. Aby uzyskać więcej informacji, zobacz Limity, przydziały i ograniczenia usług i subskrypcji platformy Azure.
Każdy dokument musi mieć atrybut, którego można użyć jako unikatowego identyfikatora tego dokumentu w ramach zawierającej go kolekcji. Ten atrybut różni się od klucza fragmentu, określającego, która kolekcja zawiera ten dokument. Kolekcja może zawierać wiele dokumentów. Teoretycznie jedynym ograniczeniem jest maksymalna długość identyfikatora dokumentu. Identyfikator dokumentu może zawierać maksymalnie 255 znaków.
Wszystkie operacje na dokumencie są wykonywane w kontekście transakcji. Zakres transakcji wyznacza kolekcja, w której znajduje się dokument. W przypadku niepowodzenia operacji praca wykonana w ramach tej operacji jest wycofywana. Podczas wykonywania operacji na dokumencie wszelkie wprowadzone zmiany są objęte izolacją na poziomie migawki. Ten mechanizm gwarantuje na przykład, że w przypadku niepowodzenia żądania utworzenia nowego dokumentu inny użytkownik, wysyłający zapytanie do bazy danych w tym samym czasie, nie zobaczy częściowo utworzonego dokumentu, który zostanie następnie usunięty.
Zapytania do bazy danych również są ograniczone do poziomu kolekcji. Jedno zapytanie może pobierać dane tylko z jednej kolekcji. Jeśli chcesz pobierać dane z wielu kolekcji, konieczne będzie wysłanie oddzielnych zapytań do poszczególnych kolekcji i scalenie wyników w kodzie aplikacji.
Usługa Azure Cosmos DB obsługuje programowalne elementy, które mogą być przechowywane w kolekcji wraz z dokumentami. Są to między innymi procedury składowane, funkcje zdefiniowane przez użytkownika i wyzwalacze (w języku JavaScript). Te elementy mogą uzyskiwać dostęp do dowolnego dokumentu znajdującego się w tej samej kolekcji. Ponadto te elementy są uruchamiane w ramach transakcji otoczenia (w przypadku wyzwalacza uruchamianego w wyniku operacji tworzenia, usuwania lub zamieniania dokumentu) lub przez rozpoczęcie nowej transakcji (w przypadku procedury składowanej uruchamianej w wyniku jawnego żądania klienta). Jeśli kod elementu programowalnego zwraca wyjątek, transakcja jest wycofywana. Za pomocą procedur składowanych i wyzwalaczy można zapewnić integralność i spójność dokumentów, ale wszystkie te dokumenty muszą należeć do tej samej kolekcji.
Przekroczenie ograniczeń przepływności, które określa poziom wydajności kolekcji, przez kolekcje przechowywane w bazach danych powinno być mało prawdopodobne. Aby uzyskać więcej informacji, zobacz Jednostki żądań w usłudze Azure Cosmos DB. Jeśli spodziewasz się, że te wartości mogą zostać przekroczone, rozważ podzielenie kolekcji między bazy danych przechowywane na różnych kontach, aby zmniejszyć obciążenie poszczególnych kolekcji.
Partycjonowanie usługi Azure Search
Wyszukiwanie danych jest często podstawową metodą nawigacji i eksploracji w wielu aplikacjach internetowych. Umożliwia użytkownikom szybkie znajdowanie zasobów (na przykład produktów w aplikacji do handlu elektronicznego) na podstawie kombinacji kryteriów wyszukiwania. Usługa Azure Search udostępnia mechanizm wyszukiwania pełnotekstowego w zawartości internetowej wraz z funkcjami uzupełniania przy wpisywaniu, sugestii podobnych zapytań i nawigacji aspektowej. Aby uzyskać więcej informacji, zobacz Co to jest usługa Azure Search?.
Usługa Azure Search przechowuje zawartość, którą można przeszukiwać, w postaci dokumentów JSON w bazie danych. Możesz zdefiniować indeksy określające pola z możliwością wyszukiwania w tych dokumentach i przekazać te definicje do usługi Azure Search. Po przesłaniu żądania wyszukiwania przez użytkownika usługa Azure Search znajduje pasujące elementy przy użyciu odpowiednich indeksów.
Można zmniejszyć poziom rywalizacji, dzieląc magazyn używany przez usługę Azure Search na wybraną liczbę partycji (1, 2, 3, 4, 6 lub 12), z których każda może mieć maksymalnie 6 replik. Iloczyn liczby partycji i liczby replik określa liczbę jednostek wyszukiwania. Jedno wystąpienie usługi Azure Search może zawierać maksymalnie 36 jednostek wyszukiwania (w przypadku baz danych z 12 partycjami maksymalna liczba replik wynosi 3).
Opłaty są naliczane za każdą jednostkę wyszukiwania przydzieloną do usługi. Możesz dodawać jednostki wyszukiwania do istniejącego wystąpienia usługi Azure Search, aby obsługiwać dodatkowe obciążenie pojawiające się w miarę wzrostu ilości zawartości, którą można przeszukiwać, lub liczby żądań wyszukiwania. Usługa Azure Search automatycznie rozdziela dokumenty równomiernie między poszczególne partycje. Nie są obecnie obsługiwane żadne strategie ręcznego partycjonowania.
Maksymalny rozmiar jednej partycji wynosi 15 milionów dokumentów lub 300 GB (obowiązuje mniejsza wartość). Możesz utworzyć maksymalnie 50 indeksów. Wydajność usługi jest zmienna i zależy od złożoności dokumentów, dostępnych indeksów oraz opóźnienia sieci. Jedna replika (1 jednostka wyszukiwania) powinna umożliwiać obsługę średnio 15 zapytań na sekundę, zalecamy jednak przeprowadzenie testów porównawczych z użyciem własnych danych w celu bardziej precyzyjnego pomiaru przepływności. Aby uzyskać więcej informacji, zobacz Limity usługi w usłudze Azure Search.
Uwaga
W dokumentach z możliwością wyszukiwania można przechowywać ograniczony zestaw typów danych, w tym ciągi, wartości logiczne, dane liczbowe, dane daty i godziny oraz niektóre typy danych geograficznych. Aby uzyskać więcej informacji, zobacz stronę Obsługiwane typy danych (Azure Search) w witrynie internetowej firmy Microsoft.
Możesz tylko w ograniczonym zakresie wpływać na sposób partycjonowania danych związanych z poszczególnymi wystąpieniami usługi Azure Search. Możesz jednak dodatkowo zwiększyć wydajność i zredukować opóźnienie oraz poziom rywalizacji w środowisku globalnym, partycjonując samą usługę przy użyciu jednej z następujących strategii:
Utwórz wystąpienie usługi Azure Search w każdym regionie geograficznym i upewnij się, że aplikacje klienckie są kierowane do najbliższego dostępnego wystąpienia. Ta strategia wymaga replikowania wszelkich aktualizacji zawartości, którą można przeszukiwać, w odpowiednim czasie we wszystkich wystąpieniach usługi.
Utwórz dwie warstwy usługi Azure Search:
- Usługę lokalną w każdym regionie, zawierającą dane najczęściej używane przez użytkowników z tego regionu. Użytkownicy mogą wysyłać do niej żądania, aby szybko uzyskać ograniczone wyniki.
- Usługę globalną, zawierającą wszystkie dane. Użytkownicy mogą wysyłać do niej żądania, aby uzyskać pełniejsze wyniki, ale przy wolniejszym działaniu.
Ta metoda jest odpowiednia w sytuacjach, w których poszczególne regiony istotnie różnią się pod względem wyszukiwanych danych.
Partycjonowanie usługi Azure Cache for Redis
Usługa Azure Cache for Redis udostępnia udostępnioną usługę buforowania w chmurze opartą na magazynie danych klucz-wartość usługi Redis. Jak sama nazwa wskazuje, usługa Azure Cache for Redis jest przeznaczona jako rozwiązanie buforowania. Należy używać jej tylko do przejściowego przechowywania danych, a nie jako stałego magazynu danych. Aplikacje korzystające z usługi Azure Cache for Redis powinny mieć możliwość kontynuowania działania, jeśli pamięć podręczna jest niedostępna. Usługa Azure Cache for Redis obsługuje replikację podstawową/pomocniczą w celu zapewnienia wysokiej dostępności, ale obecnie ogranicza maksymalny rozmiar pamięci podręcznej do 53 GB. Jeśli potrzebujesz więcej miejsca, utwórz dodatkowe pamięci podręczne. Aby uzyskać więcej informacji, zobacz Pamięć podręczna Azure Cache for Redis.
Partycjonowanie magazynu danych Redis polega na podziale danych między wystąpieniami usługi Redis. Każde wystąpienie stanowi oddzielną partycję. Usługa Azure Cache for Redis abstruje usługi Redis za fasadą i nie udostępnia ich bezpośrednio. Najprostszym sposobem implementacji partycjonowania jest utworzenie wielu wystąpień usługi Azure Cache for Redis i rozłożenie na nie danych.
Każdy element danych można skojarzyć z identyfikatorem (kluczem partycji), określającym, w której pamięci podręcznej zostanie zapisany ten element. Następnie logika aplikacji klienckiej może na podstawie tego identyfikatora kierować żądania do odpowiednich partycji. Ten schemat jest bardzo prosty, ale jeśli schemat partycjonowania ulegnie zmianie (na przykład w przypadku utworzenia dodatkowych wystąpień usługi Azure Cache for Redis), aplikacje klienckie mogą wymagać ponownej konfiguracji.
Natywna usługa Redis (a nie usługa Azure Cache for Redis) obsługuje partycjonowanie po stronie serwera na podstawie klastrowania Usługi Redis. W takim przypadku możesz podzielić dane równomiernie między poszczególne serwery przy użyciu mechanizmu wyznaczania wartości skrótu. Na każdym serwerze Redis przechowywane są metadane opisujące zakres kluczy skrótu, które zawiera dana partycja, a także informacje o kluczach skrótu znajdujących się w partycjach na pozostałych serwerach.
Aplikacje klienckie po prostu wysyłają żądania do dowolnego członkowskiego serwera Redis (najprawdopodobniej tego znajdującego się najbliżej). Serwer Redis sprawdza żądanie klienta. Jeśli serwer może obsłużyć żądanie lokalnie, wykonuje żądaną operację. W przeciwnym razie przekazuje żądanie do właściwego serwera.
Ten model jest implementowany przy użyciu klastrowania Redis i został bardziej szczegółowo opisany na stronie Redis cluster tutorial (Samouczek dotyczący klastrów Redis) w witrynie internetowej usługi Redis. Klastrowanie Redis odbywa się w sposób niewidoczny dla aplikacji klienckich. Dodatkowe serwery Redis można dodać do klastra (a dane można ponownie partycjonować) bez konieczności ponownego konfigurowania klientów.
Ważne
Usługa Azure Cache for Redis obecnie obsługuje klastrowanie usługi Redis tylko w warstwie Premium.
Strona Partitioning: how to split data among multiple Redis instances (Partycjonowanie: jak dzielić dane pomiędzy wystąpienia pamięci podręcznej Redis) w witrynie internetowej usługi Redis zawiera więcej informacji o implementowaniu partycjonowania przy użyciu usługi Redis. W dalszej części tej sekcji założono, że korzystasz z partycjonowania po stronie klienta lub z użyciem serwera proxy.
Podczas podejmowania decyzji o sposobie partycjonowania danych za pomocą usługi Azure Cache for Redis należy wziąć pod uwagę następujące kwestie:
Usługa Azure Cache for Redis nie jest przeznaczona do działania jako trwały magazyn danych, dlatego niezależnie od wdrożonego schematu partycjonowania kod aplikacji musi mieć możliwość pobierania danych z lokalizacji, która nie jest pamięcią podręczną.
Dane często używane razem powinny być przechowywane w tej samej partycji. Redis to zaawansowany magazyn danych w postaci par klucz-wartość, oferujący kilka wysoce zoptymalizowanych mechanizmów tworzenia struktury danych. Dostępne mechanizmy to:
- zwykłe ciągi (dane binarne o długości do 512 MB),
- typy zagregowane, na przykład listy (które mogą pełnić rolę kolejek i stosów),
- zestawy (uporządkowane i nieuporządkowane),
- skróty (które umożliwiają grupowanie powiązanych pól, na przykład elementów reprezentujących pola w obiekcie).
Typy zagregowane umożliwiają skojarzenie wielu powiązanych wartości z jednym kluczem. Klucz usługi Redis określa listę, zestaw lub skrót, a nie zawarte w nich elementy danych. Wszystkie te typy są dostępne w usłudze Azure Cache for Redis i są opisane na stronie Typy danych w witrynie internetowej usługi Redis. Na przykład w systemie do handlu elektronicznego śledzącym zamówienia składane przez klientów można przechowywać dane poszczególnych klientów przy użyciu skrótu usługi Redis z kluczem utworzonym na podstawie identyfikatora klienta. Każdy skrót może zawierać zbiór identyfikatorów zamówień tego klienta. W oddzielnym zestawie usługi Redis można przechowywać zamówienia, również przy użyciu struktury skrótów, z kluczem utworzonym na podstawie identyfikatora zamówienia. Rysunek 8 przedstawia tę strukturę. Należy pamiętać, że usługa Redis w żaden sposób nie wymusza zachowania więzów integralności, dlatego to do dewelopera należy zapewnienie utrzymania relacji między danymi klientów i zamówień.
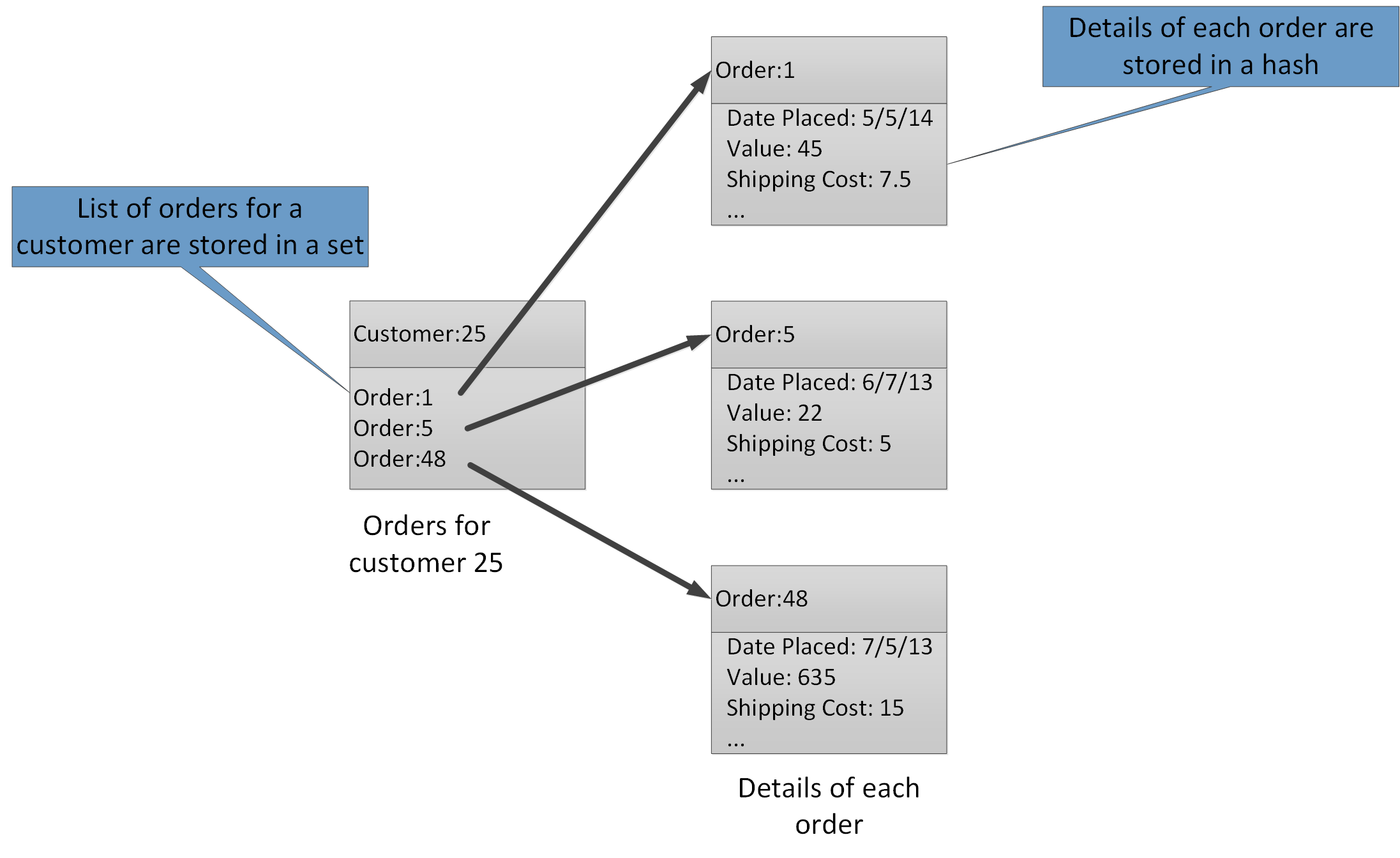
Rysunek 8. Sugerowana struktura w magazynie Redis na potrzeby rejestrowania zamówień klientów i ich szczegółów.
Uwaga
W usłudze Redis wszystkie klucze są binarnymi wartościami danych (tak, jak ciągi usługi Redis) i mogą zawierać maksymalnie 512 MB danych. Teoretycznie klucz może zawierać niemal dowolne informacje. Zalecane jest jednak stosowanie spójnej konwencji nazewnictwa kluczy, uwzględniającej opis typów danych i jednostek w możliwe krótkiej formie. Popularnym rozwiązaniem jest tworzenie kluczy o postaci „jednostka_typ:identyfikator”. Możesz na przykład użyć ciągu „klient:99” jako klucza klienta o identyfikatorze 99.
Możesz zastosować partycjonowanie pionowe, zapisując powiązane informacje w różnych agregacjach w ramach bazy danych. Na przykład w aplikacji do handlu elektronicznego możesz przechowywać często używane informacje o produktach w jednym skrócie usługi Redis, a rzadziej używane informacje szczegółowe w innym. W obu skrótach częścią klucza może być ten sam identyfikator produktu. Na przykład możesz użyć wartości "product: nn" (gdzie nn jest identyfikatorem produktu) dla informacji o produkcie i "product_details: nn" dla szczegółowych danych. Ta strategia pozwala zmniejszyć ilość danych pobieranych przez większość zapytań.
Ponowne partycjonowanie magazynu danych jest możliwe, ale należy pamiętać, że jest to złożone i czasochłonne zadanie. Klastrowanie usługi Redis może automatycznie ponownie partycjonować dane, ale ta funkcja nie jest dostępna w usłudze Azure Cache for Redis. Dlatego podczas planowania schematu partycjonowania należy w miarę możliwości pozostawić w poszczególnych partycjach ilość wolnego miejsca odpowiednią do przewidywanego wzrostu ilości danych w przyszłości. Należy jednak pamiętać, że usługa Azure Cache for Redis jest przeznaczona do tymczasowego buforowania danych, a dane przechowywane w pamięci podręcznej mogą mieć ograniczony okres istnienia określony jako wartość czasu wygaśnięcia (TTL). Czas wygaśnięcia może być krótki w przypadku relatywnie nietrwałych danych, a znacznie dłuższy w przypadku danych statycznych. Unikaj przechowywania dużych ilości trwałych danych w pamięci podręcznej, jeśli mogą one zapełnić pamięć podręczną. Możesz określić zasady eksmisji, które powodują, że usługa Azure Cache for Redis usuwa dane, jeśli miejsce jest w warstwie Premium.
Uwaga
W przypadku korzystania z usługi Azure Cache for Redis należy określić maksymalny rozmiar pamięci podręcznej (od 250 MB do 53 GB), wybierając odpowiednią warstwę cenową. Jednak po utworzeniu usługi Azure Cache for Redis nie można zwiększyć (ani zmniejszyć) jej rozmiaru.
Partie i transakcje usługi Redis nie mogą obejmować wielu połączeń, dlatego wszystkie dane objęte partią lub transakcją powinny być przechowywane w tej samej bazie danych (w tym samym fragmencie).
Uwaga
Sekwencja operacji wykonywanych w ramach transakcji usługi Redis nie musi być niepodzielna. Polecenia składające się na transakcję są przed uruchomieniem weryfikowane i dodawane do kolejki. Błąd na tym etapie powoduje odrzucenie całej kolejki. Natomiast po pomyślnym przesłaniu transakcji polecenia dodane do kolejki są uruchamiane sekwencyjnie. Błąd podczas wykonywania polecenia powoduje zatrzymanie tylko tego polecenia. Wszystkie poprzednie i dalsze polecenia w kolejce są wykonywane. Aby uzyskać więcej informacji, zobacz stronę Transactions (Transakcje) w witrynie internetowej usługi Redis.
Usługa Redis obsługuje ograniczony zbiór niepodzielnych operacji. Jedyne operacje tego typu obsługujące wiele kluczy i wartości to operacje MGET i MSET. Operacje MGET zwracają zbiór wartości dla podanej listy kluczy, a operacje MSET zapisują zbiór wartości dla podanej listy kluczy. Jeśli musisz wykonywać te operacje, pary klucz-wartość, do których odwołują się polecenia MSET i MGET, muszą być przechowywane w tej samej bazie danych.
Partycjonowanie usługi Azure Service Fabric
Azure Service Fabric to platforma mikrousług, zapewniająca środowisko uruchomieniowe dla aplikacji rozproszonych w chmurze. Usługa Service Fabric obsługuje pliki wykonywalne gościa platformy .NET, usługi stanowe i bezstanowe oraz kontenery. Usługi stanowe udostępniają elementy Reliable Collection umożliwiające trwałe przechowywanie danych w kolekcji par klucz-wartość w klastrze usługi Service Fabric. Aby uzyskać więcej informacji na temat strategii partycjonowania kluczy w niezawodnej kolekcji, zobacz Wytyczne i zalecenia dotyczące niezawodnych kolekcji w usłudze Azure Service Fabric.
Następne kroki
Artykuł Omówienie usługi Azure Service Fabric zawiera wprowadzenie do usługi Azure Service Fabric.
Artykuł Partition Service Fabric reliable services (Partycjonowanie usług Reliable Services w ramach usługi Service Fabric) zawiera więcej informacji na temat usług Reliable Services w usłudze Azure Service Fabric.
Partycjonowanie usługi Azure Event Hubs
Usługa Azure Event Hubs umożliwia przesyłanie strumieniowe danych na masową skalę, a partycjonowanie umożliwiające skalowanie w poziomie jest wbudowaną funkcją tej usługi. Każdy użytkownik odczytuje tylko określoną partycję strumienia komunikatów.
Wydawca zdarzeń ma informacje tylko o kluczu partycji, a nie partycji, na której publikowane są zdarzenia. To oddzielenie klucza od partycji powoduje, że nadawca nie musi wiedzieć zbyt dużo o przetwarzaniu podrzędnym. Można również wysyłać zdarzenia bezpośrednio do określonej partycji, ale na ogół nie jest to zalecane rozwiązanie.
Wybierając liczbę partycji, uwzględnij perspektywę długoterminową. Po utworzeniu centrum zdarzeń nie można zmienić liczby partycji.
Następne kroki
Aby uzyskać więcej informacji na temat używania partycji w usłudze Event Hubs, zobacz Co to jest usługa Event Hubs?.
Aby zapoznać się z zagadnieniami równowagi między dostępnością a spójnością, zobacz Availability and consistency in Event Hubs (Dostępność i spójność w usłudze Event Hubs).