Metryki dla usługi Application Gateway
Usługa Application Gateway publikuje punkty danych w usłudze Azure Monitor w celu uzyskania wydajności usługi Application Gateway i wystąpień zaplecza. Te punkty danych są nazywane metrykami i są wartościami liczbowymi w uporządkowanym zestawie danych szeregów czasowych. Metryki opisują jakiś aspekt bramy aplikacji w określonym czasie. Jeśli istnieją żądania przepływające przez usługę Application Gateway, mierzy i wysyła metryki w 60-sekundowych odstępach czasu. Jeśli nie ma żadnych żądań przepływających przez usługę Application Gateway lub brak danych dla metryki, metryka nie jest zgłaszana. Aby uzyskać więcej informacji, zobacz Metryki usługi Azure Monitor.
Metryki obsługiwane przez jednostkę SKU usługi Application Gateway w wersji 2
Uwaga
Informacje dotyczące serwera proxy TLS/TCP można znaleźć w dokumentacji danych.
Metryki chronometrażu
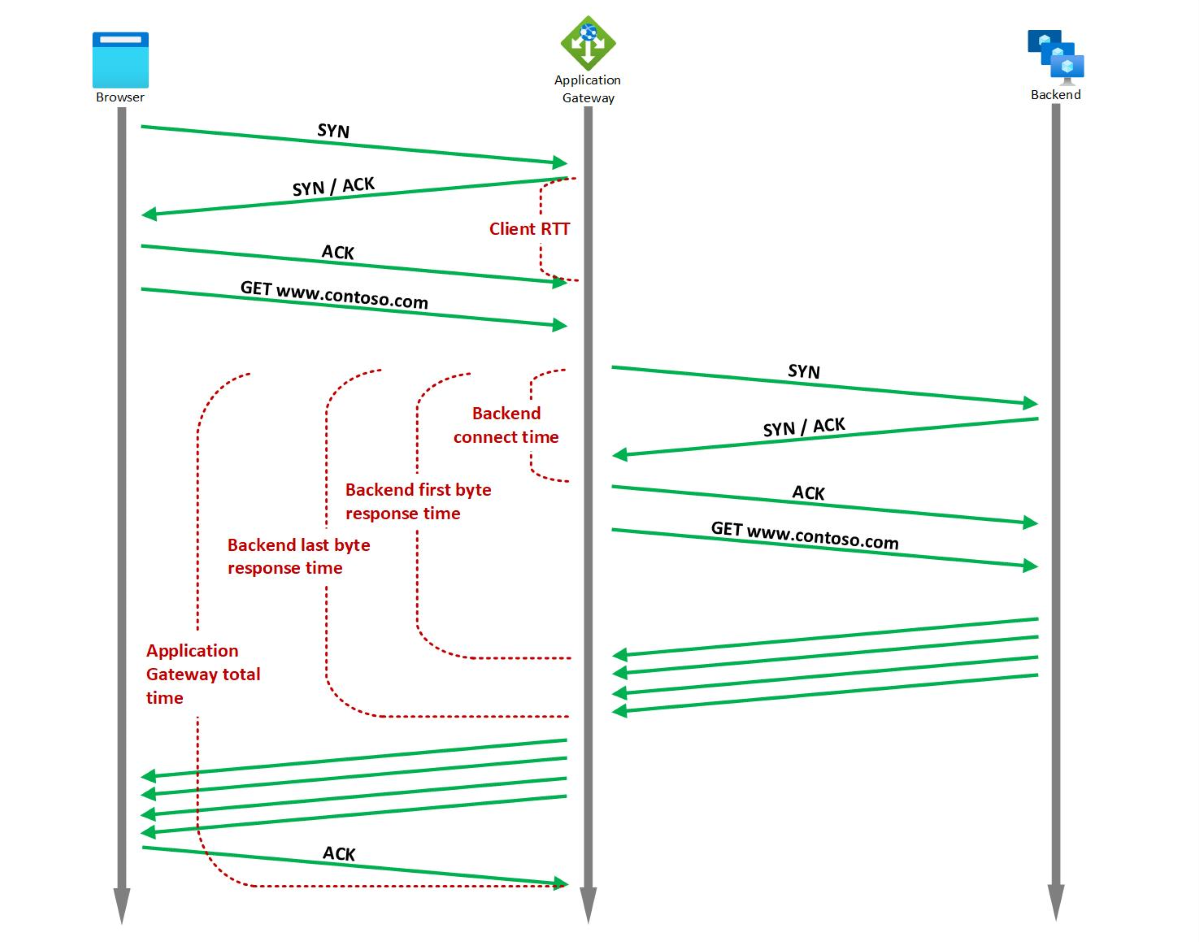
Usługa Application Gateway udostępnia kilka wbudowanych metryk chronometrażu związanych z żądaniem i odpowiedzią, które są mierzone w milisekundach.
Uwaga
Jeśli w usłudze Application Gateway istnieje więcej niż jeden odbiornik, zawsze filtruj według wymiaru odbiornika , porównując różne metryki opóźnienia, aby uzyskać znaczące wnioskowanie.
Uwaga
Opóźnienie może być obserwowane w danych metryk, ponieważ wszystkie metryki są agregowane w odstępach jednej minuty. To opóźnienie może się różnić w przypadku różnych wystąpień bramy aplikacji na podstawie czasu rozpoczęcia metryki.
Metryki chronometrażu umożliwiają określenie, czy zaobserwowane spowolnienie jest spowodowane siecią klienta, wydajnością usługi Application Gateway, siecią zaplecza i nasyceniem stosu TCP serwera zaplecza, wydajnością aplikacji zaplecza lub dużym rozmiarem plików. Aby uzyskać więcej informacji, zobacz Metryki chronometrażu.
Jeśli na przykład występuje wzrost trendu czasu odpowiedzi pierwszego bajtu zaplecza, ale trend czasu połączenia zaplecza jest stabilny, możesz wywnioskować, że brama aplikacji do opóźnienia zaplecza i czas potrzebny na nawiązanie połączenia jest stabilny. Wzrost jest spowodowany wzrostem czasu odpowiedzi aplikacji zaplecza. Z drugiej strony, jeśli skok czasu odpowiedzi pierwszego bajtu zaplecza jest skojarzony z odpowiednim wzrostem czasu połączenia zaplecza, można określić, że sieć między usługą Application Gateway i serwerem zaplecza lub stos TCP serwera zaplecza jest nasycony.
Jeśli zauważysz wzrost czasu odpowiedzi ostatniego bajtu zaplecza, ale czas odpowiedzi pierwszego bajtu zaplecza jest stabilny, możesz wyłudić, że skok jest spowodowany większym żądanym plikiem.
Podobnie, jeśli łączny czas bramy aplikacji ma gwałtowny wzrost, ale czas odpowiedzi ostatniego bajtu zaplecza jest stabilny, może to być oznaką wąskiego gardła wydajności w usłudze Application Gateway lub wąskim gardłem w sieci między klientem a usługą Application Gateway. Ponadto jeśli rTT klienta ma również odpowiedni skok, oznacza to, że spadek jest spowodowany siecią między klientem a usługą Application Gateway.
Metryki usługi Application Gateway
W przypadku usługi Application Gateway dostępnych jest kilka metryk. Aby uzyskać listę, zobacz Metryki usługi Application Gateway.
Metryki zaplecza
W przypadku usługi Application Gateway dostępnych jest kilka metryk zaplecza. Aby uzyskać listę, zobacz Metryki zaplecza.
Metryki zapory aplikacji internetowej
Aby uzyskać informacje na temat monitorowania zapory aplikacji internetowej, zobacz Metryki zapory aplikacji internetowej w wersji 2 i metryki zapory aplikacji internetowej w wersji 1.
Wizualizacja metryk
Przejdź do bramy aplikacji w obszarze Monitorowanie wybierz pozycję Metryki. Aby wyświetlić dostępne wartości, wybierz listę rozwijaną METRYKA.
Na poniższej ilustracji przedstawiono przykład z trzema metrykami wyświetlanymi przez ostatnie 30 minut:

Aby wyświetlić bieżącą listę metryk, zobacz Obsługiwane metryki w usłudze Azure Monitor.
Reguły alertów dotyczące metryk
Reguły alertów można uruchomić na podstawie metryk dla zasobu. Na przykład alert może wywołać element webhook lub wysłać wiadomość e-mail do administratora, jeśli przepływność bramy aplikacji jest wyższa, niższa lub na poziomie progu dla określonego okresu.
Poniższy przykład przeprowadzi Cię przez proces tworzenia reguły alertu, która wysyła wiadomość e-mail do administratora po naruszeniu progu przepływności:
wybierz pozycję Dodaj alert metryki, aby otworzyć stronę Dodawanie reguły . Możesz również uzyskać dostęp do tej strony ze strony metryk.
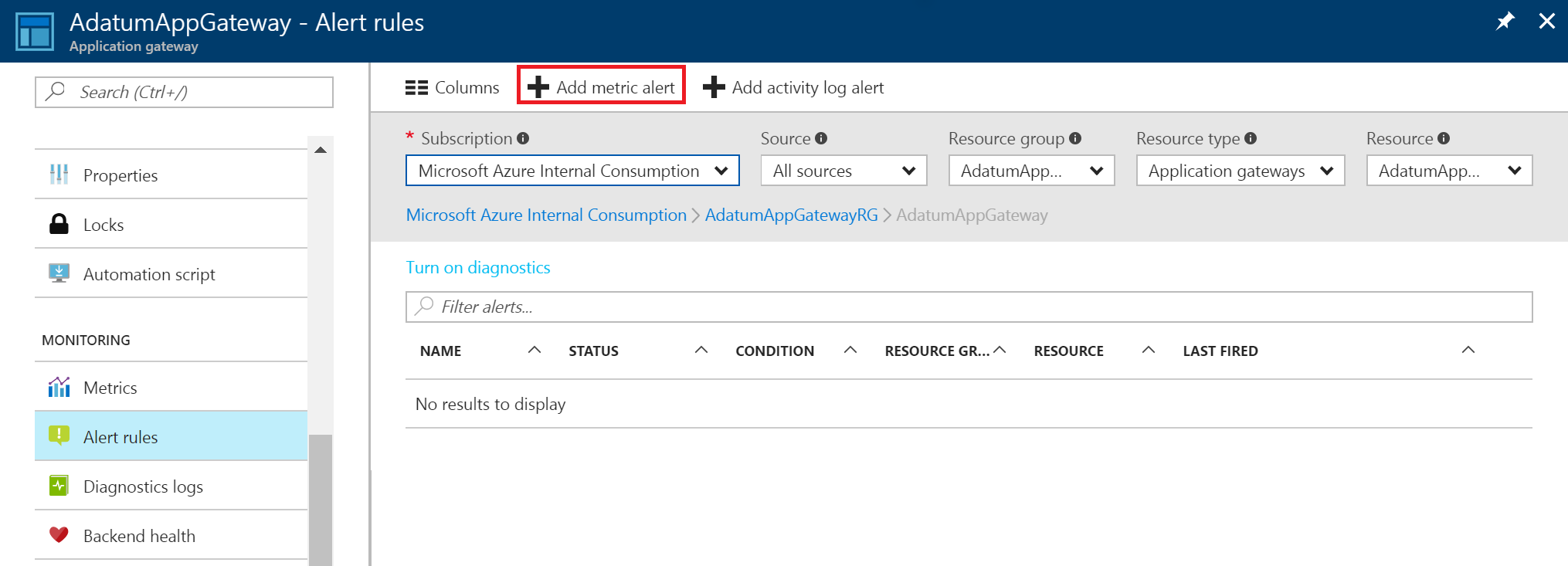
Na stronie Dodawanie reguły wypełnij sekcje nazwy, warunku i powiadamiania, a następnie wybierz przycisk OK.
W selektorze Warunek wybierz jedną z czterech wartości: Większe niż, Większe niż lub równe, Mniejsze niż lub Mniejsze lub równe.
W selektorze Okres wybierz okres od pięciu minut do sześciu godzin.
Jeśli wybierzesz pozycję Właściciele poczty e-mail, współautorzy i czytelnicy, wiadomość e-mail może być dynamiczna na podstawie użytkowników, którzy mają dostęp do tego zasobu. W przeciwnym razie możesz podać rozdzielaną przecinkami listę użytkowników w polu Dodatkowe adresy e-mail administratora.
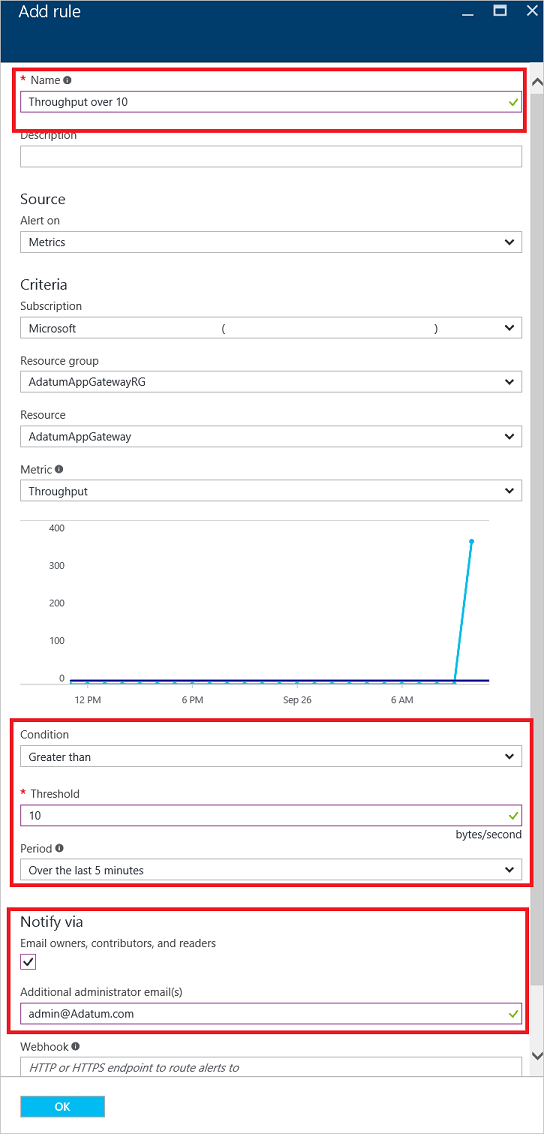
Jeśli próg zostanie naruszony, zostanie zwrócona wiadomość e-mail podobna do tej na poniższej ilustracji:
Po utworzeniu alertu dotyczącego metryk zostanie wyświetlona lista alertów. Zawiera omówienie wszystkich reguł alertów.
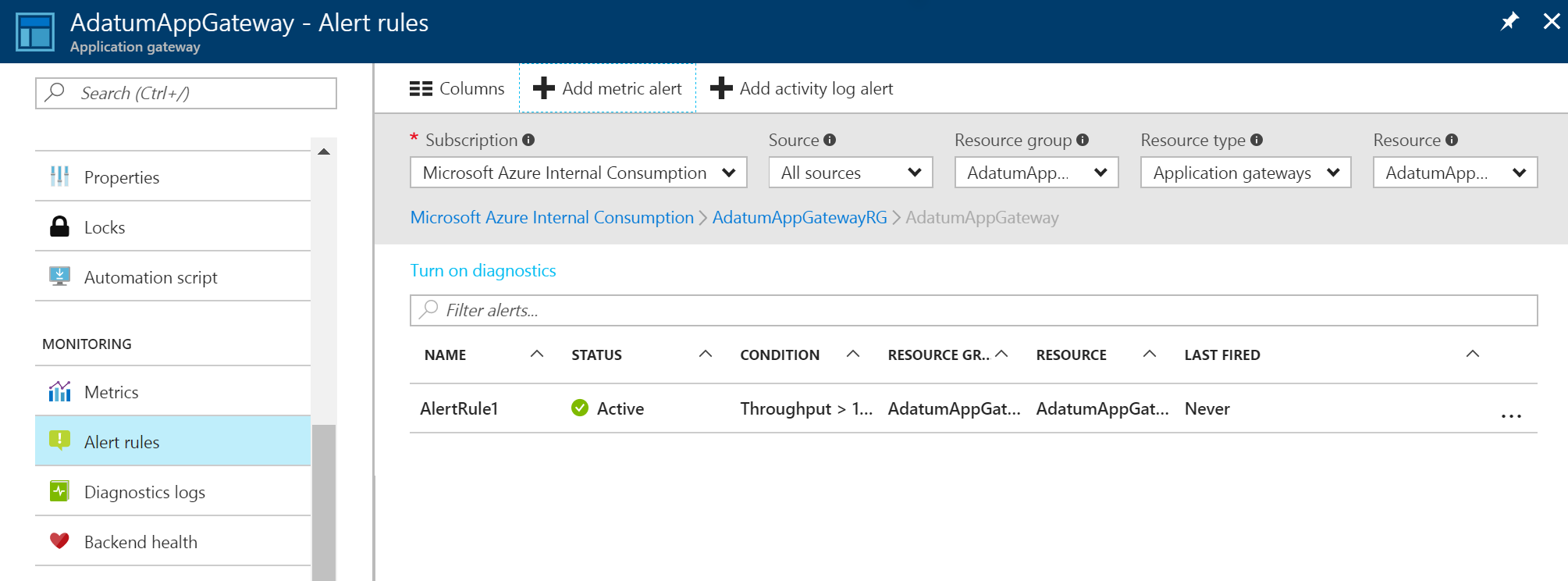
Aby dowiedzieć się więcej na temat powiadomień o alertach, zobacz Odbieranie powiadomień o alertach.
Aby dowiedzieć się więcej o elementach webhook i sposobie ich używania z alertami, odwiedź stronę Konfigurowanie elementu webhook w alercie metryk platformy Azure.
Następne kroki
- Wizualizowanie dzienników liczników i zdarzeń przy użyciu dzienników usługi Azure Monitor.
- Wizualizowanie dziennika aktywności platformy Azure za pomocą wpisu w blogu usługi Power BI .
- Wyświetlanie i analizowanie dzienników aktywności platformy Azure w usłudze Power BI i więcej wpisu w blogu.