Omówienie możliwości generowania bramy sztucznej inteligencji w usłudze Azure API Management
DOTYCZY: Wszystkie warstwy usługi API Management
W tym artykule przedstawiono możliwości usługi Azure API Management, które ułatwiają zarządzanie interfejsami API generowania sztucznej inteligencji, takimi jak te udostępniane przez usługę Azure OpenAI Service. Usługa Azure API Management udostępnia szereg zasad, metryk i innych funkcji w celu zwiększenia bezpieczeństwa, wydajności i niezawodności interfejsów API obsługujących inteligentne aplikacje. Zbiorczo te funkcje są nazywane funkcjami bramy generowania sztucznej inteligencji (GenAI) dla interfejsów API generacyjnych sztucznej inteligencji.
Uwaga
- Ten artykuł koncentruje się na możliwościach zarządzania interfejsami API udostępnianymi przez usługę Azure OpenAI Service. Wiele funkcji bramy GenAI ma zastosowanie do innych interfejsów API modelu języka (LLM), w tym dostępnych za pośrednictwem interfejsu API wnioskowania modelu AI platformy Azure.
- Możliwości bramy generowania sztucznej inteligencji to funkcje istniejącej bramy interfejsu API usługi API Management, a nie oddzielnej bramy interfejsu API. Aby uzyskać więcej informacji na temat usługi API Management, zobacz Omówienie usługi Azure API Management.
Wyzwania związane z zarządzaniem interfejsami API generowania sztucznej inteligencji
Jednym z głównych zasobów używanych w generowaniu usług sztucznej inteligencji są tokeny. Usługa Azure OpenAI przypisuje limit przydziału dla wdrożeń modelu wyrażonych w tokenach na minutę (TPM), które są następnie dystrybuowane między użytkownikami modelu — na przykład różne aplikacje, zespoły deweloperów, działy w firmie itp.
Platforma Azure ułatwia łączenie pojedynczej aplikacji z usługą Azure OpenAI Service: możesz połączyć się bezpośrednio przy użyciu klucza interfejsu API z limitem modułu TPM skonfigurowanym bezpośrednio na poziomie wdrożenia modelu. Jednak po rozpoczęciu rozwoju portfolio aplikacji jest wyświetlanych wiele aplikacji wywołujących pojedyncze lub nawet wiele punktów końcowych usługi Azure OpenAI wdrożonych jako wystąpienia z płatnością zgodnie z rzeczywistym użyciem lub aprowizowanie wystąpień jednostek przepływności (PTU). Wiąże się to z pewnymi wyzwaniami:
- Jak jest śledzone użycie tokenów w wielu aplikacjach? Czy można obliczyć opłaty krzyżowe dla wielu aplikacji/zespołów korzystających z modeli usługi Azure OpenAI Service?
- Jak upewnić się, że jedna aplikacja nie korzysta z całego limitu przydziału modułu TPM, pozostawiając inne aplikacje bez opcji używania modeli usługi Azure OpenAI Service?
- Jak klucz interfejsu API jest bezpiecznie dystrybuowany między wieloma aplikacjami?
- W jaki sposób obciążenie jest dystrybuowane między wiele punktów końcowych usługi Azure OpenAI? Czy można upewnić się, że zatwierdzona pojemność w jednostkach PTU jest wyczerpana przed powrotem do wystąpień płatności zgodnie z rzeczywistym użyciem?
W pozostałej części tego artykułu opisano, jak usługa Azure API Management może pomóc w rozwiązywaniu tych problemów.
Importowanie zasobu usługi Azure OpenAI jako interfejsu API
Zaimportuj interfejs API z punktu końcowego usługi Azure OpenAI Service do usługi Azure API Management przy użyciu środowiska pojedynczego kliknięcia. Usługa API Management usprawnia proces dołączania, automatycznie importując schemat interfejsu OpenAPI dla interfejsu API usługi Azure OpenAI i konfigurując uwierzytelnianie do punktu końcowego usługi Azure OpenAI przy użyciu tożsamości zarządzanej, eliminując potrzebę ręcznej konfiguracji. W tym samym środowisku przyjaznym dla użytkownika można wstępnie skonfigurować zasady dotyczące limitów tokenów i emitować metryki tokenu.

Zasady limitu tokenów
Skonfiguruj zasady limitu tokenów usługi Azure OpenAI w celu zarządzania limitami i wymuszania limitów dla użytkownika interfejsu API na podstawie użycia tokenów usługi Azure OpenAI Service. Za pomocą tych zasad można ustawić limity wyrażone w tokenach na minutę (TPM).
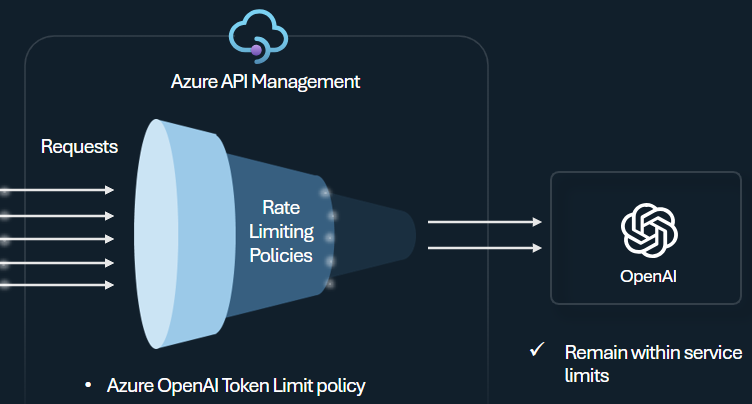
Te zasady zapewniają elastyczność przypisywania limitów opartych na tokenach na dowolnym kluczu licznika, takim jak klucz subskrypcji, źródłowy adres IP lub dowolny klucz zdefiniowany za pomocą wyrażenia zasad. Zasady umożliwiają również wstępne obliczanie tokenów monitów po stronie usługi Azure API Management, minimalizując niepotrzebne żądania do zaplecza usługi Azure OpenAI, jeśli monit już przekracza limit.
W poniższym przykładzie podstawowym pokazano, jak ustawić limit modułu TPM 500 na klucz subskrypcji:
<azure-openai-token-limit counter-key="@(context.Subscription.Id)"
tokens-per-minute="500" estimate-prompt-tokens="false" remaining-tokens-variable-name="remainingTokens">
</azure-openai-token-limit>
Napiwek
Aby zarządzać limitami tokenów dla interfejsów API LLM dostępnych za pośrednictwem interfejsu API wnioskowania modelu AI platformy Azure i wymuszać je, usługa API Management udostępnia równoważne zasady limitu tokenów llm.
Emituj zasady metryki tokenu
Zasady metryki tokenu emitowania usługi Azure OpenAI wysyłają metryki do usługi Application Insights dotyczące użycia tokenów LLM za pośrednictwem interfejsów API usługi Azure OpenAI Service. Te zasady ułatwiają omówienie wykorzystania modeli usługi Azure OpenAI Service w wielu aplikacjach lub użytkownikach interfejsu API. Te zasady mogą być przydatne w scenariuszach obciążenia zwrotnego, monitorowaniu i planowaniu pojemności.
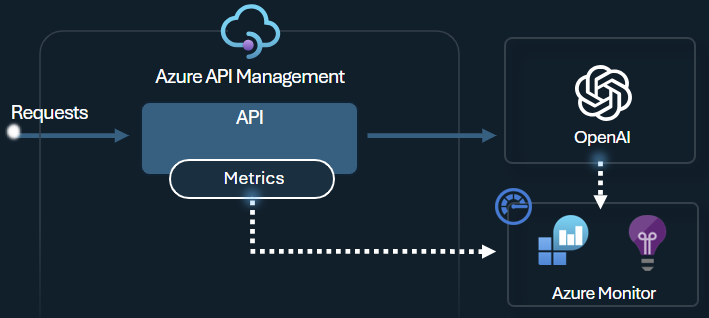
Te zasady przechwytują monity, uzupełnienia i łączne metryki użycia tokenu oraz wysyłają je do wybranej przestrzeni nazw usługi Application Insights. Ponadto można skonfigurować lub wybrać z wstępnie zdefiniowanych wymiarów, aby podzielić metryki użycia tokenu, aby przeanalizować metryki według identyfikatora subskrypcji, adresu IP lub wybranego wymiaru niestandardowego.
Na przykład następujące zasady wysyła metryki do usługi Application Insights podzielone według adresu IP klienta, interfejsu API i użytkownika:
<azure-openai-emit-token-metric namespace="openai">
<dimension name="Client IP" value="@(context.Request.IpAddress)" />
<dimension name="API ID" value="@(context.Api.Id)" />
<dimension name="User ID" value="@(context.Request.Headers.GetValueOrDefault("x-user-id", "N/A"))" />
</azure-openai-emit-token-metric>
Napiwek
Aby wysyłać metryki dla interfejsów API LLM dostępnych za pośrednictwem interfejsu API wnioskowania modelu AI platformy Azure, usługa API Management udostępnia równoważne zasady metryki llm-emit-token-metric .
Moduł równoważenia obciążenia zaplecza i wyłącznik
Jednym z wyzwań związanych z tworzeniem inteligentnych aplikacji jest zapewnienie, że aplikacje są odporne na błędy zaplecza i mogą obsługiwać duże obciążenia. Konfigurując punkty końcowe usługi Azure OpenAI przy użyciu zapleczy w usłudze Azure API Management, możesz równoważyć obciążenie między nimi. Możesz również zdefiniować reguły wyłącznika, aby zatrzymać przekazywanie żądań do zapleczy usługi Azure OpenAI Service, jeśli nie odpowiadają.
Moduł równoważenia obciążenia zaplecza obsługuje działanie okrężne, ważone i oparte na priorytetach równoważenie obciążenia, co zapewnia elastyczność definiowania strategii dystrybucji obciążenia spełniającej określone wymagania. Na przykład zdefiniuj priorytety w ramach konfiguracji modułu równoważenia obciążenia, aby zapewnić optymalne wykorzystanie określonych punktów końcowych usługi Azure OpenAI, szczególnie tych zakupionych jako jednostki PTU.
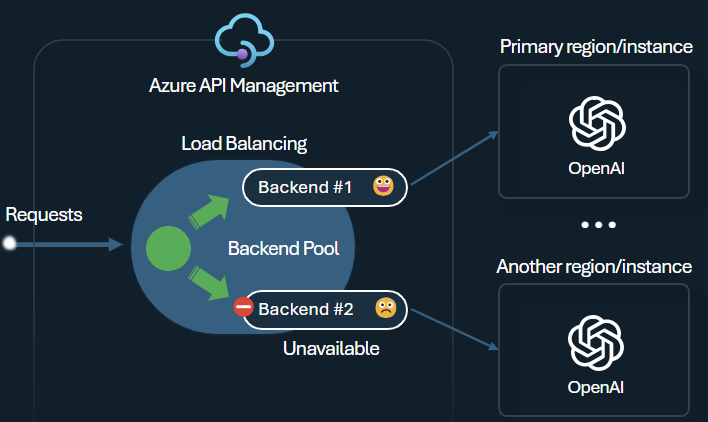
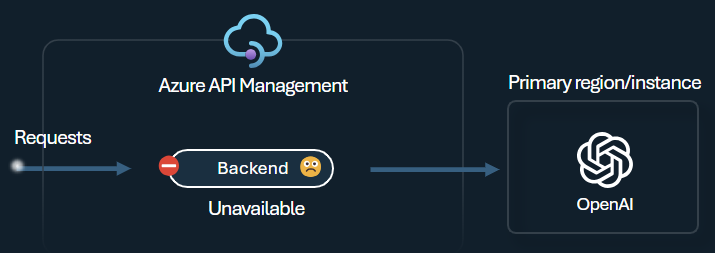
Wyłącznik zaplecza zawiera dynamiczny czas trwania podróży, stosując wartości z nagłówka Retry-After dostarczonego przez zaplecze. Zapewnia to precyzyjne i terminowe odzyskiwanie zapleczy, maksymalizując wykorzystanie priorytetowych zapleczy.
Zasady buforowania semantycznego
Skonfiguruj zasady buforowania semantycznego usługi Azure OpenAI, aby zoptymalizować użycie tokenu, przechowując uzupełnienia dla podobnych monitów.
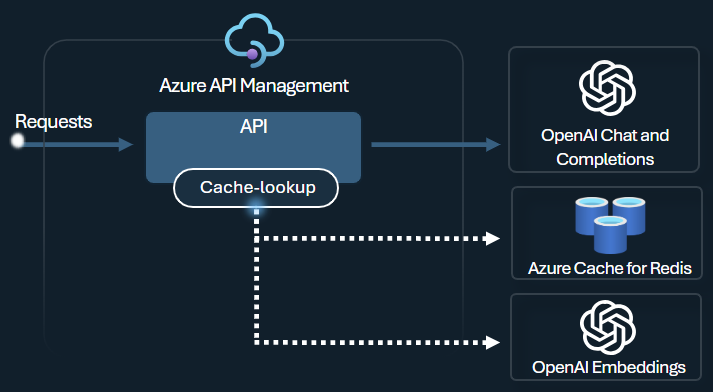
W usłudze API Management włącz buforowanie semantyczne przy użyciu usługi Azure Redis Enterprise lub innej zewnętrznej pamięci podręcznej zgodnej z usługą RediSearch i dołączonej do usługi Azure API Management. Korzystając z interfejsu API osadzania usługi Azure OpenAI, magazyn azure-openai-semantic-cache-store i azure-openai-semantic-cache-lookup policies store i pobierz semantycznie podobne uzupełnianie monitów z pamięci podręcznej. Takie podejście zapewnia ponowne użycie ukończenia, co skutkuje zmniejszeniem użycia tokenów i lepszą wydajnością odpowiedzi.
Napiwek
Aby włączyć buforowanie semantyczne dla interfejsów API LLM dostępnych za pośrednictwem interfejsu API wnioskowania modelu AI platformy Azure, usługa API Management udostępnia równoważne zasady llm-semantic-cache-store-policy i llm-semantic-cache-lookup-policy .
Laboratoria i przykłady
- Laboratoria dotyczące możliwości bramy GenAI usługi Azure API Management
- Azure API Management (APIM) — przykład usługi Azure OpenAI (Node.js)
- Przykładowy kod języka Python do korzystania z usługi Azure OpenAI z usługą API Management
Zagadnienia dotyczące architektury i projektowania
- Architektura referencyjna bramy GenAI korzystająca z usługi API Management
- Akcelerator strefy docelowej bramy centrum sztucznej inteligencji
- Projektowanie i implementowanie rozwiązania bramy przy użyciu zasobów usługi Azure OpenAI
- Używanie bramy przed wieloma wdrożeniami lub wystąpieniami usługi Azure OpenAI
Powiązana zawartość
- Blog: Wprowadzenie do funkcji GenAI w usłudze Azure API Management
- Blog: integrowanie bezpieczeństwa zawartości platformy Azure z usługą API Management dla punktów końcowych usługi Azure OpenAI
- Szkolenie: zarządzanie wygenerowanymi interfejsami API sztucznej inteligencji za pomocą usługi Azure API Management
- Inteligentne równoważenie obciążenia dla punktów końcowych openAI i usługi Azure API Management
- Uwierzytelnianie i autoryzacja dostępu do interfejsów API usługi Azure OpenAI przy użyciu usługi Azure API Management