Skalowanie w poziomie usług Azure Analysis Services
Dzięki skalowaniu w poziomie zapytania klientów można dystrybuować między wieloma replikami zapytań w puli zapytań, co zmniejsza czas odpowiedzi w przypadku dużych obciążeń zapytań. Można również oddzielić przetwarzanie od puli zapytań, zapewniając, że zapytania klienta nie mają negatywnego wpływu na operacje przetwarzania. Skalowanie w poziomie można skonfigurować w witrynie Azure Portal lub przy użyciu interfejsu API REST usług Analysis Services.
Zwiększanie skali w poziomie jest dostępne dla serwerów w warstwie cenowej Standardowa. Każda replika zapytań jest rozliczana według tej samej stawki co serwer. Wszystkie repliki zapytań są tworzone w tym samym regionie co serwer. Liczba replik zapytań, które można skonfigurować, jest ograniczona przez region, w którym znajduje się serwer. Aby dowiedzieć się więcej, zobacz Dostępność według regionów. Skalowanie w poziomie nie zwiększa ilości dostępnej pamięci dla serwera. Aby zwiększyć ilość pamięci, należy uaktualnić plan.
Dlaczego warto skalować w poziomie?
W typowym wdrożeniu serwera jeden serwer służy zarówno jako serwer przetwarzania, jak i serwer zapytań. Jeśli liczba zapytań klienta względem modeli na serwerze przekracza liczbę jednostek przetwarzania zapytań (QPU) dla planu serwera lub przetwarzanie modelu odbywa się w tym samym czasie co duże obciążenia zapytań, wydajność może się zmniejszyć.
Za pomocą skalowania w poziomie można utworzyć pulę zapytań z maksymalnie siedmioma zasobami repliki zapytań (łącznie z ośmioma zasobami repliki zapytań, w tym serwerem podstawowym ). Liczbę replik w puli zapytań można skalować w celu spełnienia wymagań QPU w krytycznym czasie i w dowolnym momencie można oddzielić serwer przetwarzania od puli zapytań.
Niezależnie od liczby replik zapytań w puli zapytań obciążenia przetwarzania nie są dystrybuowane między replikami zapytań. Serwer podstawowy służy jako serwer przetwarzania. Repliki zapytań obsługują tylko zapytania dotyczące baz danych modelu synchronizowanych między serwerem podstawowym a każdą repliką w puli zapytań.
Skalowanie w poziomie może potrwać do pięciu minut, aby nowe repliki zapytań zostały przyrostowo dodane do puli zapytań. Gdy wszystkie nowe repliki zapytań są uruchomione, nowe połączenia klienckie są ze zrównoważonym obciążeniem między zasobami w puli zapytań. Istniejące połączenia klienckie nie są zmieniane z zasobu, z którego są obecnie połączone. Podczas skalowania w poziomie wszystkie istniejące połączenia klienta z zasobem puli zapytań, który jest usuwany z puli zapytań, zostaną zakończone. Klienci mogą ponownie łączyć się z pozostałym zasobem puli zapytań.
Jak to działa
Podczas konfigurowania skalowania w poziomie po raz pierwszy bazy danych modelu na serwerze podstawowym są automatycznie synchronizowane z nowymi replikami w nowej puli zapytań. Automatyczna synchronizacja odbywa się tylko raz. Podczas automatycznej synchronizacji pliki danych serwera podstawowego (zaszyfrowane w spoczynku w magazynie obiektów blob) są kopiowane do drugiej lokalizacji, również szyfrowane w spoczynku w magazynie obiektów blob. Repliki w puli zapytań są następnie nawilżane danymi z drugiego zestawu plików.
Podczas gdy automatyczna synchronizacja jest wykonywana tylko w przypadku skalowania serwera w poziomie po raz pierwszy, można również przeprowadzić synchronizację ręczną. Synchronizacja zapewnia dane replik w puli zapytań zgodne z serwerem podstawowym. Podczas przetwarzania (odświeżania) modeli na serwerze podstawowym należy przeprowadzić synchronizację po zakończeniu operacji przetwarzania. Ta synchronizacja kopiuje zaktualizowane dane z plików serwera podstawowego w magazynie obiektów blob do drugiego zestawu plików. Repliki w puli zapytań są następnie nawilżane zaktualizowanymi danymi z drugiego zestawu plików w magazynie obiektów blob.
Podczas kolejnej operacji skalowania w poziomie, na przykład zwiększenie liczby replik w puli zapytań z dwóch do pięciu, nowe repliki są nawodnione przy użyciu danych z drugiego zestawu plików w magazynie obiektów blob. Brak synchronizacji. Jeśli następnie wykonasz synchronizację po skalowaniu w górę, nowe repliki w puli zapytań zostaną dwukrotnie nawodnione — nadmiarowe nawodnienie. Podczas wykonywania kolejnej operacji skalowania w poziomie należy pamiętać o:
Wykonaj synchronizację przed operacją skalowania w poziomie, aby uniknąć nadmiarowego nawodnienia dodanych replik. Współbieżne operacje synchronizacji i skalowania w poziomie działające w tym samym czasie nie są dozwolone.
Podczas automatyzowania operacji przetwarzania i skalowania w poziomie ważne jest, aby najpierw przetwarzać dane na serwerze podstawowym, a następnie przeprowadzić synchronizację, a następnie wykonać operację skalowania w poziomie. Ta sekwencja zapewnia minimalny wpływ na QPU i zasoby pamięci.
Podczas operacji skalowania w poziomie wszystkie serwery w puli zapytań, w tym serwer podstawowy, są tymczasowo w trybie offline.
Synchronizacja jest dozwolona nawet wtedy, gdy w puli zapytań nie ma żadnych replik. Jeśli przeprowadzasz skalowanie z zera do co najmniej jednej repliki z nowymi danymi z operacji przetwarzania na serwerze podstawowym, najpierw przeprowadź synchronizację bez replik w puli zapytań, a następnie przeprowadź skalowanie w poziomie. Synchronizacja przed skalowaniem w pionie pozwala uniknąć nadmiarowego nawodnienia nowo dodanych replik.
Gdy usuniesz modelową bazę danych z serwera podstawowego, nie zostanie ona automatycznie usunięta z replik w puli zapytań. Należy wykonać operację synchronizacji przy użyciu polecenia Sync-AzAnalysisServicesInstance programu PowerShell, które usuwa pliki dla tej bazy danych z udostępnionej lokalizacji magazynu obiektów blob repliki, a następnie usuwa bazę danych modelu na replikach w puli zapytań. Aby określić, czy modelowa baza danych istnieje na replikach w puli zapytań, ale nie na serwerze podstawowym, upewnij się, że ustawienie Rozdziel serwer przetwarzania przed wykonywaniem zapytań w puli ma wartość Tak. Następnie użyj programu SQL Server Management Studio (SSMS), aby nawiązać połączenie z serwerem podstawowym przy użyciu
:rwkwalifikatora, aby sprawdzić, czy baza danych istnieje. Następnie nawiąż połączenie z replikami w puli zapytań, łącząc się bez:rwkwalifikatora, aby sprawdzić, czy ta sama baza danych również istnieje. Jeśli baza danych istnieje na replikach w puli zapytań, ale nie na serwerze podstawowym, uruchom operację synchronizacji.Zmiana nazwy bazy danych na serwerze podstawowym jest kolejnym krokiem niezbędnym do zapewnienia prawidłowej synchronizacji bazy danych z dowolnymi replikami. Po zmianie nazwy wykonaj synchronizację przy użyciu polecenia Sync-AzAnalysisServicesInstance określającego
-Databaseparametr ze starą nazwą bazy danych. Ta synchronizacja usuwa bazę danych i pliki ze starą nazwą z wszystkich replik. Następnie wykonaj kolejną synchronizację-Databaseokreślającą parametr z nową nazwą bazy danych. Druga synchronizacja kopiuje nowo nazwaną bazę danych do drugiego zestawu plików i nawilża wszystkie repliki. Tych synchronizacji nie można wykonać przy użyciu polecenia Synchronizuj model w portalu.
Tryb synchronizacji
Domyślnie repliki zapytań są przywracane w całości, a nie przyrostowo. Ponowne wypełnianie odbywa się na etapach. Są one odłączone i dołączone dwa naraz (przy założeniu, że istnieją co najmniej trzy repliki), aby upewnić się, że co najmniej jedna replika jest w trybie online dla zapytań w danym momencie. W niektórych przypadkach klienci mogą wymagać ponownego nawiązania połączenia z jedną z replik online podczas wykonywania tego procesu. Za pomocą ustawienia ReplicaSyncMode można teraz określić synchronizację repliki zapytań odbywa się równolegle. Synchronizacja równoległa zapewnia następujące korzyści:
- Znaczna redukcja czasu synchronizacji.
- Dane między replikami są bardziej prawdopodobne, aby były spójne podczas procesu synchronizacji.
- Bazy danych są przechowywane w trybie online we wszystkich replikach przez cały proces synchronizacji, więc klienci nie muszą ponownie nawiązywać połączenia.
- Pamięć podręczna w pamięci jest aktualizowana przyrostowo tylko przy użyciu zmienionych danych, które mogą być szybsze niż pełne ponowne wypełnianie modelu.
Ustawianie funkcji ReplicaSyncMode
Użyj programu SSMS, aby ustawić wartość ReplicaSyncMode we właściwościach zaawansowanych. Możliwe wartości to:
-
1(ustawienie domyślne): ponowne wypełnianie bazy danych pełnej repliki na etapach (przyrostowe). -
2: Zoptymalizowana synchronizacja równolegle.
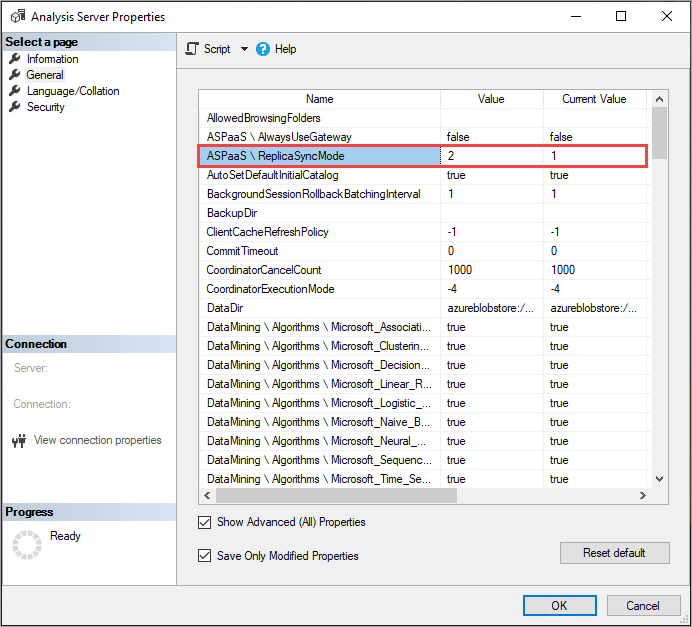
W przypadku ustawiania parametru ReplicaSyncMode=2, w zależności od ilości pamięci podręcznej, więcej pamięci może być zużywanych przez repliki zapytań. Aby zachować bazę danych w trybie online i być dostępna dla zapytań, w zależności od tego, ile danych uległo zmianie, operacja może wymagać nawet dwukrotnego podwojenia pamięci w repliki, ponieważ zarówno stare, jak i nowe segmenty są przechowywane jednocześnie w pamięci. Węzły repliki mają tę samą alokację pamięci co węzeł podstawowy i zwykle w węźle podstawowym jest dodatkowa pamięć na potrzeby operacji odświeżania, więc może być mało prawdopodobne, że repliki zabraknie pamięci. Ponadto typowym scenariuszem jest to, że baza danych jest przyrostowo aktualizowana w węźle podstawowym, dlatego wymaganie dotyczące dwukrotnego użycia pamięci powinno być nietypowe. Jeśli operacja synchronizacji napotka błąd braku pamięci, ponawia próbę przy użyciu techniki domyślnej (dołączanie/odłączanie dwóch naraz).
Oddzielanie przetwarzania od puli zapytań
Aby uzyskać maksymalną wydajność operacji przetwarzania i zapytań, można oddzielić serwer przetwarzania od puli zapytań. Po oddzieleniu nowe połączenia klienta są przypisywane tylko do replik zapytań w puli zapytań. Jeśli operacje przetwarzania zajmują tylko krótki czas, możesz oddzielić serwer przetwarzania od puli zapytań tylko przez czas potrzebny do wykonania operacji przetwarzania i synchronizacji, a następnie dołączyć go z powrotem do puli zapytań. Oddzielenie serwera przetwarzania z puli zapytań lub dodanie go z powrotem do puli zapytań może potrwać do pięciu minut, aż operacja zostanie ukończona.
Monitorowanie użycia funkcji QPU
Aby określić, czy konieczne jest skalowanie w poziomie serwera, monitoruj metryki serwera w witrynie Azure Portal. Jeśli funkcja QPU regularnie przekracza limit QPU dla planu, oznacza to, że liczba zapytań względem modeli przekracza limit QPU dla planu. Metryka długość kolejki zadań puli zapytań zwiększa się również, gdy liczba zapytań w kolejce puli wątków zapytania przekracza dostępną metrykę QPU.
Kolejną dobrą metrykę do obejrzenia jest średnia QPU przez ServerResourceType. Ta metryka porównuje średnią QPU dla serwera podstawowego z pulą zapytań.
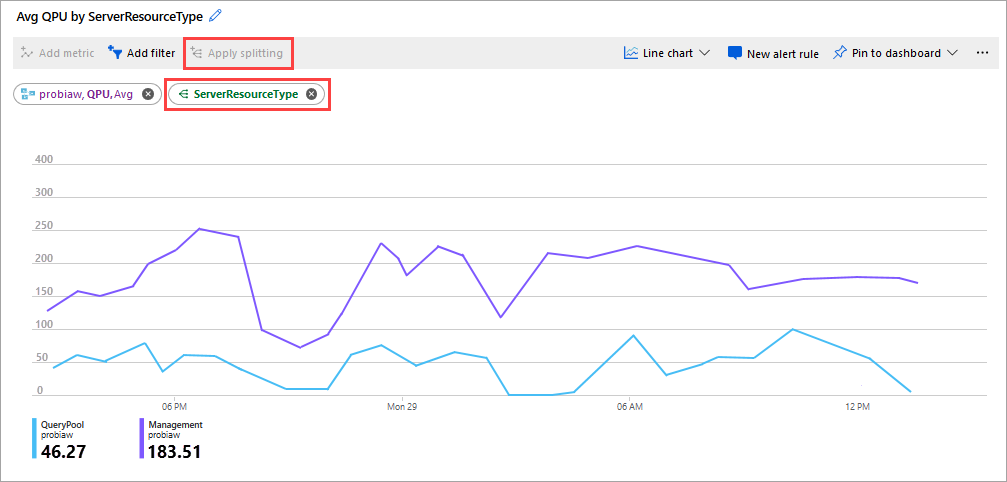
Aby skonfigurować QPU według serverResourceType
- Na wykresie liniowym Metryki kliknij pozycję Dodaj metrykę.
- W obszarze ZASÓB wybierz serwer, a następnie w obszarze PRZESTRZEŃ NAZW METRYKI wybierz pozycję Metryki standardowe usług Analysis Services, a następnie w obszarze METRYKA wybierz pozycję QPU, a następnie w obszarze AGREGACJA wybierz pozycję Średnia.
- Kliknij przycisk Zastosuj dzielenie.
- W obszarze WARTOŚCI wybierz pozycję ServerResourceType.
Szczegółowe rejestrowanie diagnostyczne
Użyj dzienników usługi Azure Monitor, aby uzyskać bardziej szczegółową diagnostykę skalowanych zasobów serwera w poziomie. Za pomocą dzienników można użyć zapytań usługi Log Analytics, aby rozbić QPU i pamięć według serwera i repliki. Aby uzyskać więcej informacji, zobacz Analizowanie dzienników w obszarze roboczym usługi Log Analytics. Przykładowe zapytania można znaleźć w temacie Sample Kusto queries (Przykładowe zapytania Kusto).
Konfigurowanie zwiększania skali w poziomie
W witrynie Azure Portal
W portalu kliknij pozycję Skaluj w poziomie. Użyj suwaka, aby wybrać liczbę serwerów repliki zapytań. Liczba wybieranych replik jest dodatkiem do istniejącego serwera.
W obszarze Oddziel serwer przetwarzania z puli zapytań wybierz pozycję Tak, aby wykluczyć serwer przetwarzania z serwerów zapytań. Połączenia klienta przy użyciu domyślnej parametry połączenia (bez
:rw) są przekierowywane do replik w puli zapytań.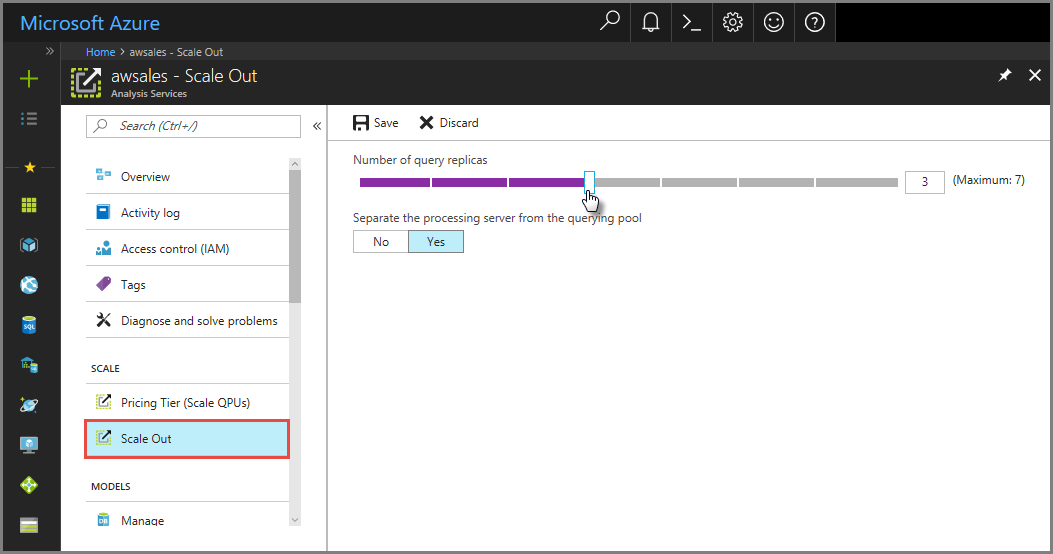
Kliknij przycisk Zapisz , aby aprowizować nowe serwery repliki zapytań.
Podczas konfigurowania skalowania w poziomie dla serwera po raz pierwszy modele na serwerze podstawowym są automatycznie synchronizowane z replikami w puli zapytań. Automatyczna synchronizacja odbywa się tylko raz, podczas pierwszego konfigurowania skalowania w poziomie do co najmniej jednej repliki. Kolejne zmiany liczby replik na tym samym serwerze nie wyzwalają kolejnej automatycznej synchronizacji. Automatyczna synchronizacja nie występuje ponownie, nawet jeśli serwer zostanie ustawiony na zero replik, a następnie ponownie przeprowadź skalowanie w poziomie do dowolnej liczby replik.
Synchronizuj
Operacje synchronizacji muszą być wykonywane ręcznie lub przy użyciu interfejsu API REST.
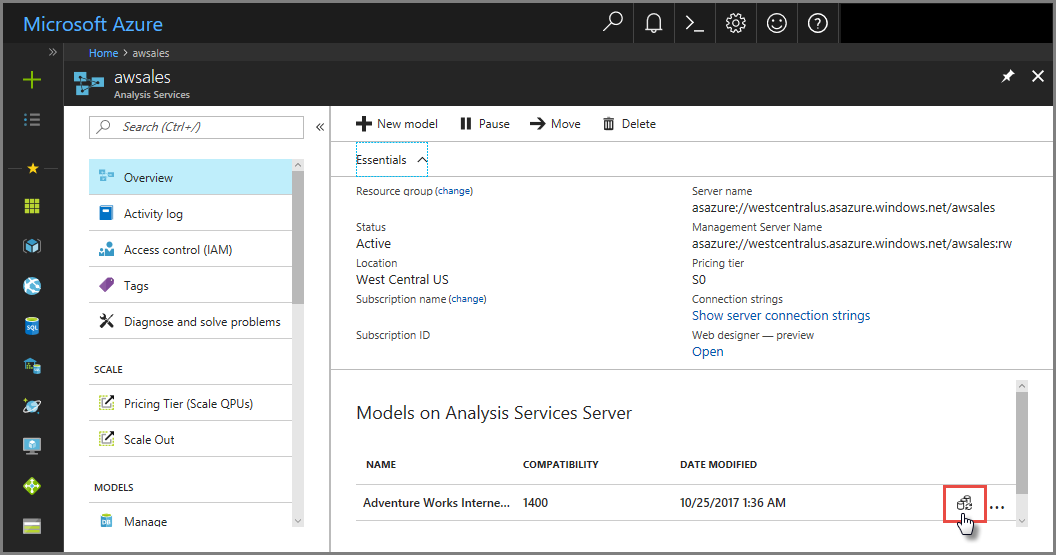
W witrynie Azure Portal
W obszarze Model przeglądu> Synchronizuj model>.
Interfejs API REST
Użyj operacji synchronizacji.
Synchronizowanie modelu
POST https://<region>.asazure.windows.net/servers/<servername>:rw/models/<modelname>/sync
Uzyskiwanie stanu synchronizacji
GET https://<region>.asazure.windows.net/servers/<servername>/models/<modelname>/sync
Kody stanu powrotu:
| Kod | opis |
|---|---|
| -1 | Nieprawidłowy |
| 0 | Replikowanie |
| 1 | Ponowne wypełnianie |
| 2 | Ukończone |
| 3 | Niepowodzenie |
| 100 | Finalizacji |
PowerShell
Uwaga
Do interakcji z platformą Azure zalecamy używanie modułu Azure Az w programie PowerShell. Zobacz Instalowanie programu Azure PowerShell, aby rozpocząć. Aby dowiedzieć się, jak przeprowadzić migrację do modułu Az PowerShell, zobacz Migracja programu Azure PowerShell z modułu AzureRM do modułu Az.
Przed rozpoczęciem korzystania z programu PowerShell zainstaluj lub zaktualizuj najnowszy moduł programu Azure PowerShell.
Aby uruchomić synchronizację, użyj polecenia Sync-AzAnalysisServicesInstance.
Aby ustawić liczbę replik zapytań, użyj polecenia Set-AzAnalysisServicesServer. Określ opcjonalny -ReadonlyReplicaCount parametr.
Aby oddzielić serwer przetwarzania od puli zapytań, użyj polecenia Set-AzAnalysisServicesServer. Określ opcjonalny -DefaultConnectionMode parametr do użycia Readonly.
Aby dowiedzieć się więcej, zobacz Using a service principal with the Az.AnalysisServices module (Używanie jednostki usługi za pomocą modułu Az.AnalysisServices).
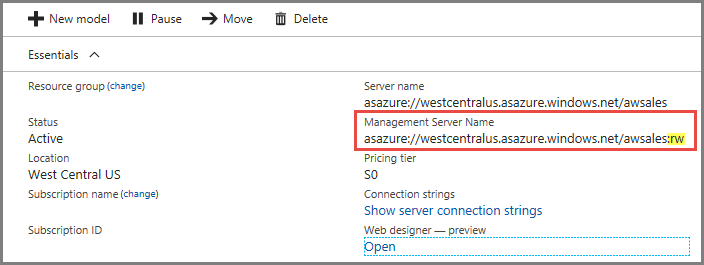
Połączenia
Na stronie Przegląd serwera istnieją dwie nazwy serwerów. Jeśli nie skonfigurowano jeszcze skalowania w poziomie dla serwera, obie nazwy serwerów działają tak samo. Po skonfigurowaniu skalowania w poziomie dla serwera należy określić odpowiednią nazwę serwera w zależności od typu połączenia.
W przypadku połączeń klienckich użytkowników końcowych, takich jak Power BI Desktop, Excel i aplikacje niestandardowe, użyj nazwy serwera.
W przypadku programów SSMS, Visual Studio i parametry połączenia w programie PowerShell, aplikacjach funkcji platformy Azure i aplikacji AMO użyj nazwy serwera zarządzania. Nazwa serwera zarządzania zawiera specjalny :rw kwalifikator (odczyt-zapis). Wszystkie operacje przetwarzania są wykonywane na serwerze zarządzania (podstawowym).
Skalowanie w górę, skalowanie w dół a skalowanie w poziomie
Możesz zmienić warstwę cenową na serwerze z wieloma replikami. Ta sama warstwa cenowa ma zastosowanie do wszystkich replik. Operacja skalowania najpierw powoduje wyłączenie wszystkich replik jednocześnie, a następnie wyświetlenie wszystkich replik w nowej warstwie cenowej.
Rozwiązywanie problemów
Problem: Użytkownicy otrzymują błąd nie może odnaleźć wystąpienia serwera "<Nazwa serwera>" w trybie połączenia "ReadOnly".
Rozwiązanie: Podczas wybierania opcji Rozdziel serwer przetwarzania z puli zapytań połączenia klientów przy użyciu domyślnej parametry połączenia (bez :rw) są przekierowywane do replik puli zapytań. Jeśli repliki w puli zapytań nie są jeszcze w trybie online, ponieważ synchronizacja nie została jeszcze ukończona, przekierowane połączenia klienckie mogą zakończyć się niepowodzeniem. Aby zapobiec nieudanym połączeniom, podczas synchronizacji musi znajdować się co najmniej dwa serwery w puli zapytań. Każdy serwer jest synchronizowany indywidualnie, podczas gdy inne pozostają w trybie online. Jeśli zdecydujesz się nie mieć serwera przetwarzania w puli zapytań podczas przetwarzania, możesz usunąć go z puli do przetwarzania, a następnie dodać go z powrotem do puli po zakończeniu przetwarzania, ale przed synchronizacją. Monitorowanie stanu synchronizacji za pomocą metryk pamięci i QPU.
Informacje pokrewne
Monitorowanie usług Azure Analysis Services— zarządzanie usługami Azure Analysis Services