Omówienie skalowania automatycznego klastra w usłudze Azure Kubernetes Service (AKS)
Aby nadążyć za wymaganiami aplikacji w usłudze Azure Kubernetes Service (AKS), może być konieczne dostosowanie liczby węzłów, które uruchamiają obciążenia. Składnik automatycznego skalowania klastra obserwuje zasobniki w klastrze, których nie można zaplanować z powodu ograniczeń zasobów. Gdy narzędzie do automatycznego skalowania klastra wykryje nieplanowane zasobniki, skaluje w górę liczbę węzłów w puli węzłów, aby zaspokoić zapotrzebowanie aplikacji. Regularnie sprawdza również węzły, które nie mają żadnych zaplanowanych zasobników i skaluje w dół liczbę węzłów zgodnie z potrzebami.
Ten artykuł pomaga zrozumieć, jak działa narzędzie do automatycznego skalowania klastra w usłudze AKS. Zawiera również wskazówki, najlepsze rozwiązania i zagadnienia dotyczące konfigurowania narzędzia do automatycznego skalowania klastra dla obciążeń usługi AKS. Jeśli chcesz włączyć, wyłączyć lub zaktualizować automatyczne skalowanie klastra dla obciążeń usługi AKS, zobacz Używanie narzędzia do automatycznego skalowania klastra w usłudze AKS.
Informacje o autoskalatorze klastra
Klastry często wymagają sposobu automatycznego skalowania w celu dostosowania się do zmieniających się wymagań aplikacji, takich jak między dni roboczymi a wieczorami lub weekendami. Klastry usługi AKS mogą być skalowane w następujący sposób:
- Narzędzie do automatycznego skalowania klastra okresowo sprawdza zasobniki, których nie można zaplanować w węzłach z powodu ograniczeń zasobów. Następnie klaster automatycznie zwiększa liczbę węzłów. Skalowanie ręczne jest wyłączone w przypadku korzystania z narzędzia do automatycznego skalowania klastra. Aby uzyskać więcej informacji, zobacz Jak działa skalowanie w górę?.
- Narzędzie Horizontal Pod Autoscaler używa serwera metryk w klastrze Kubernetes do monitorowania zapotrzebowania na zasoby zasobników. Jeśli aplikacja potrzebuje większej ilości zasobów, liczba zasobników zostanie automatycznie zwiększona, aby zaspokoić zapotrzebowanie.
- Narzędzie Do automatycznego skalowania pionowych zasobników automatycznie ustawia żądania zasobów i limity kontenerów na obciążenie na podstawie wcześniejszego użycia, aby upewnić się, że zasobniki są zaplanowane na węzły, które mają wymagane zasoby procesora CPU i pamięci.
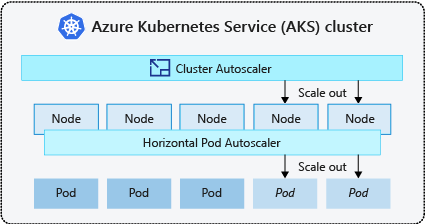
Typowym rozwiązaniem jest włączenie autoskalowania klastra dla węzłów i skalowania pionowego zasobnika zasobnika lub narzędzia Horizontal Pod Autoscaler dla zasobników. Po włączeniu automatycznego skalowania klastra stosuje określone reguły skalowania, gdy rozmiar puli węzłów jest niższy niż minimalna liczba węzłów do maksymalnej liczby węzłów. Narzędzie do automatycznego skalowania klastra czeka, aż nowy węzeł będzie potrzebny w puli węzłów lub do momentu bezpiecznego usunięcia węzła z bieżącej puli węzłów. Aby uzyskać więcej informacji, zobacz Jak działa skalowanie w dół?
Najlepsze rozwiązania i zagadnienia
- Podczas implementowania stref dostępności za pomocą narzędzia do automatycznego skalowania klastra zalecamy użycie pojedynczej puli węzłów dla każdej strefy. Parametr można ustawić
--balance-similar-node-groupstak, abyTruezachować zrównoważony rozkład węzłów między strefami dla obciążeń podczas operacji skalowania w górę. Jeśli takie podejście nie jest zaimplementowane, operacje skalowania w dół mogą zakłócać równowagę węzłów między strefami. - W przypadku klastrów z ponad 400 węzłami zalecamy użycie warstwy Azure CNI lub nakładki usługi Azure CNI.
- Aby efektywnie uruchamiać obciążenia współbieżnie zarówno w pulach węzłów typu spot, jak i w stałych węzłach, rozważ użycie rozszerzeń priorytetu. Takie podejście umożliwia planowanie zasobników na podstawie priorytetu puli węzłów.
- Zachowaj ostrożność podczas przypisywania żądań procesora CPU/pamięci na zasobnikach. Narzędzie do automatycznego skalowania klastra jest skalowane w górę na podstawie oczekujących zasobników, a nie procesora CPU/pamięci na węzłach.
- W przypadku klastrów hostujących jednocześnie zarówno długotrwałe obciążenia, jak aplikacje internetowe, jak i obciążenia zadań krótkich/pękniętych, zalecamy rozdzielenie ich na odrębne pule węzłów za pomocą rozszerzeń reguł/koligacji lub użycie modułu PodDisruptionBudget, aby zapobiec niepotrzebnemu opróżnianiu węzłów lub skalowaniu operacji w dół. Określenie adnotacji cluster-autoscaler.kubernetes.io/safe-to-evict: "false" w specyfikacji zasobnika uniemożliwi również eksmitowanie zasobników. Użyj tej adnotacji z ostrożnością, ponieważ może to spowodować, że narzędzie do automatycznego skalowania klastra napotka problemy podczas opróżniania węzła z uruchomionym zasobnikem zawierającym tę adnotację.
- W puli węzłów z obsługą skalowania automatycznego skaluj węzły w dół, usuwając obciążenia zamiast ręcznie zmniejszając liczbę węzłów. Może to być problematyczne, jeśli pula węzłów jest już w maksymalnej pojemności lub jeśli istnieją aktywne obciążenia uruchomione w węzłach, potencjalnie powodując nieoczekiwane zachowanie przez narzędzie do automatycznego skalowania klastra.
- Węzły nie są skalowane w górę, jeśli zasobniki mają wartość PriorityClass poniżej -10. Priorytet -10 jest zarezerwowany dla zasobników nadmiernej aprowizacji. Aby uzyskać więcej informacji, zobacz Using the cluster autoscaler with Pod Priority and Preemption (Używanie narzędzia do automatycznego skalowania klastra z priorytetem zasobnika i wywłaszczeniem).
- Nie łącz innych mechanizmów skalowania automatycznego węzłów, takich jak autoskalatory zestawu skalowania maszyn wirtualnych, z funkcją automatycznego skalowania klastra.
- Narzędzie do automatycznego skalowania klastra może nie być w stanie skalować w dół, jeśli zasobniki nie mogą się przenosić, na przykład w następujących sytuacjach:
- Bezpośrednio utworzony zasobnik nie jest wspierany przez obiekt kontrolera, taki jak wdrożenie lub zestaw replik.
- Budżet na zakłócenia zasobnika (PDB), który jest zbyt restrykcyjny i nie pozwala na spadek liczby zasobników poniżej określonego progu.
- Zasobnik używa selektorów węzłów lub anty-koligacji, których nie można przestrzegać, jeśli jest to zaplanowane w innym węźle. Aby uzyskać więcej informacji, zobacz What types of pods can prevent the cluster autoscaler from removing a node? (Jakie typy zasobników mogą uniemożliwić automatyczne skalowanie klastra przed usunięciem węzła?).
Ważne
Nie wprowadzaj zmian w poszczególnych węzłach w pulach węzłów skalowanych automatycznie. Wszystkie węzły w tej samej grupie węzłów powinny mieć uruchomioną jednolitą pojemność, etykiety, defekty i zasobniki systemowe.
- Narzędzie do automatycznego skalowania klastra nie jest odpowiedzialne za wymuszanie "maksymalnej liczby węzłów" w puli węzłów klastra niezależnie od zagadnień związanych z planowaniem zasobników. Jeśli jakikolwiek aktor automatycznego skalowania nieklastrowego ustawia liczbę puli węzłów na liczbę poza maksymalną skonfigurowaną wartością automatyczną klastra, narzędzie do automatycznego skalowania klastra nie usuwa automatycznie węzłów. Zachowanie skalowania automatycznego klastra w dół pozostaje ograniczone do usuwania tylko węzłów, które nie mają zaplanowanych zasobników. Jedynym celem konfiguracji maksymalnej liczby węzłów klastra jest wymuszenie górnego limitu operacji skalowania w górę. Nie ma to żadnego wpływu na zagadnienia dotyczące skalowania w dół.
Profil skalowania automatycznego klastra
Profil narzędzia do automatycznego skalowania klastra to zestaw parametrów, które kontrolują zachowanie narzędzia do automatycznego skalowania klastra. Profil automatycznego skalowania klastra można skonfigurować podczas tworzenia klastra lub aktualizowania istniejącego klastra.
Optymalizowanie profilu skalowania automatycznego klastra
Ustawienia profilu automatycznego skalowania klastra należy dostosować zgodnie z konkretnymi scenariuszami obciążenia, a jednocześnie rozważyć kompromisy między wydajnością a kosztami. Ta sekcja zawiera przykłady, które pokazują te kompromisy.
Należy pamiętać, że ustawienia profilu automatycznego skalowania klastra są szeroko stosowane do wszystkich pul węzłów z włączoną funkcją automatycznego skalowania. Wszelkie akcje skalowania, które mają miejsce w jednej puli węzłów, mogą mieć wpływ na zachowanie skalowania automatycznego innych pul węzłów, co może prowadzić do nieoczekiwanych wyników. Upewnij się, że stosujesz spójne i zsynchronizowane konfiguracje profilów we wszystkich odpowiednich pulach węzłów, aby upewnić się, że uzyskasz żądane wyniki.
Przykład 1. Optymalizowanie pod kątem wydajności
W przypadku klastrów obsługujących znaczne i zwiększone obciążenia z głównym naciskiem na wydajność zalecamy zwiększenie scan-interval i zmniejszenie wartości scale-down-utilization-threshold. Te ustawienia pomagają wsadowić wiele operacji skalowania w jedno wywołanie, optymalizowanie czasu skalowania i wykorzystanie przydziałów odczytu/zapisu obliczeniowego. Pomaga również ograniczyć ryzyko szybkiego skalowania operacji w dół na nie w pełni wykorzystanych węzłach, zwiększając wydajność planowania zasobników. Ponadto zwiększ wartość ok-total-unready-counti max-total-unready-percentage.
W przypadku klastrów z zasobnikami demononset zalecamy ustawienie wartości ignore-daemonsets-utilization true, co skutecznie ignoruje wykorzystanie węzłów przez zasobniki demononset i minimalizuje niepotrzebne operacje skalowania w dół. Zobacz profil pod kątem obciążeń z rozerwaniem
Przykład 2. Optymalizowanie pod kątem kosztów
Jeśli chcesz mieć profil zoptymalizowany pod kątem kosztów, zalecamy ustawienie następujących konfiguracji parametrów:
- Zmniejsz
scale-down-unneeded-timewartość , czyli ilość czasu, przez jaki węzeł powinien być niepotrzebny, zanim kwalifikuje się do skalowania w dół. - Zmniejsz
scale-down-delay-after-addwartość , czyli czas oczekiwania po dodaniu węzła przed rozważeniem go pod kątem skalowania w dół. - Zwiększ
scale-down-utilization-thresholdwartość , która jest progiem wykorzystania dla usuwania węzłów. - Zwiększ
max-empty-bulk-deletewartość , która jest maksymalną liczbą węzłów, które można usunąć w jednym wywołaniu. - Ustaw
skip-nodes-with-local-storagewartość false. - Zwiększ
ok-total-unready-countimax-total-unready-percentage.
Typowe problemy i zalecenia dotyczące ograniczania ryzyka
Wyświetlanie niepowodzeń skalowania i niezzwolonych zdarzeń skalowania w górę za pośrednictwem interfejsu wiersza polecenia lub portalu.
Nie wyzwalanie operacji skalowania w górę
| Typowe przyczyny | Zalecenia dotyczące ograniczania ryzyka |
|---|---|
| Trwałe konflikty koligacji węzłówvolume, które mogą wystąpić podczas korzystania z narzędzia do automatycznego skalowania klastra z wieloma strefami dostępności lub gdy strefa zasobnika lub trwałego woluminu różni się od strefy węzła. | Użyj jednej puli węzłów na strefę dostępności i włącz .--balance-similar-node-groups Można również ustawić volumeBindingMode pole na WaitForFirstConsumer w specyfikacji zasobnika, aby zapobiec powiązaniu woluminu z węzłem do momentu utworzenia zasobnika przy użyciu woluminu. |
| Taints i Tolerations/Konflikty koligacji węzła | Oceń defekty przypisane do węzłów i przejrzyj tolerancje zdefiniowane w zasobnikach. W razie potrzeby wprowadź zmiany w defektach i tolerancjach , aby upewnić się, że zasobniki mogą być efektywnie zaplanowane na węzłach. |
Niepowodzenia operacji skalowania w górę
| Typowe przyczyny | Zalecenia dotyczące ograniczania ryzyka |
|---|---|
| Wyczerpanie adresów IP w podsieci | Dodaj kolejną podsieć w tej samej sieci wirtualnej i dodaj kolejną pulę węzłów do nowej podsieci. |
| Wyczerpanie limitu przydziału rdzeni | Zatwierdzony limit przydziału rdzeni został wyczerpany. Zażądaj zwiększenia limitu przydziału. Narzędzie do automatycznego skalowania klastra wprowadza stan wycofywania wykładniczego w ramach określonej grupy węzłów, gdy wystąpi wiele nieudanych prób skalowania w górę. |
| Maksymalny rozmiar puli węzłów | Zwiększ maksymalną liczbę węzłów w puli węzłów lub utwórz nową pulę węzłów. |
| Żądania/wywołania przekraczają limit szybkości | Zobacz błędy 429 Zbyt wiele żądań. |
Niepowodzenia operacji skalowania w dół
| Typowe przyczyny | Zalecenia dotyczące ograniczania ryzyka |
|---|---|
| Zasobnik uniemożliwiający opróżnianie węzła/Nie można wykluczyć zasobnika | • Wyświetlanie typów zasobników, które mogą zapobiegać skalowaniu w dół. • W przypadku zasobników korzystających z magazynu lokalnego, takiego jak hostPath i emptyDir, ustaw flagę skip-nodes-with-local-storage profilu automatycznego skalowania klastra na falsewartość . • W specyfikacji zasobnika ustaw adnotację cluster-autoscaler.kubernetes.io/safe-to-evict na true. • Sprawdź plik PDB, ponieważ może być restrykcyjny. |
| Minimalny rozmiar puli węzłów | Zmniejsz minimalny rozmiar puli węzłów. |
| Żądania/wywołania przekraczają limit szybkości | Zobacz błędy 429 Zbyt wiele żądań. |
| Zablokowane operacje zapisu | Nie wprowadzaj żadnych zmian w w pełni zarządzanej grupie zasobów usługi AKS (zobacz zasady pomocy technicznej usługi AKS). Usuń lub zresetuj wszystkie blokady zasobów, które zostały wcześniej zastosowane do grupy zasobów. |
Inne problemy
| Typowe przyczyny | Zalecenia dotyczące ograniczania ryzyka |
|---|---|
| PriorityConfigMapNotMatchedGroup | Upewnij się, że wszystkie grupy węzłów wymagają skalowania automatycznego do pliku konfiguracji ekspandera. |
Pula węzłów w wycofywaniu
Pula węzłów w wycofywaniu została wprowadzona w wersji 0.6.2 i powoduje, że narzędzie do automatycznego skalowania klastra wycofało się ze skalowania puli węzłów po awarii.
W zależności od tego, jak długo występują błędy operacji skalowania, wykonanie kolejnej próby może potrwać do 30 minut. Stan wycofywania puli węzłów można zresetować, wyłączając i ponownie włączając skalowanie automatyczne.

Azure Kubernetes Service