Usługa Azure AI Custom Translator dla początkujących
Usługa Azure AI Custom Translator umożliwia tworzenie systemu tłumaczenia, który odzwierciedla terminologię i styl specyficzny dla twojej firmy, branży i domeny. Trenowanie i wdrażanie niestandardowego systemu jest łatwe i nie wymaga żadnych umiejętności programistycznych. Dostosowany system tłumaczenia bezproblemowo integruje się z istniejącymi aplikacjami, przepływami pracy i witrynami internetowymi i jest dostępny na platformie Azure za pośrednictwem tej samej chmurowej usługi interfejsu API tłumaczenia tekstu firmy Microsoft, która codziennie obsługuje miliardy tłumaczeń.
Platforma umożliwia użytkownikom tworzenie i publikowanie niestandardowych systemów tłumaczenia do i z języka angielskiego. Usługa Custom Translator obsługuje ponad 60 języków mapujących bezpośrednio na języki dostępne na potrzeby neuronowego tłumaczenia maszynowego (NMT). Aby uzyskać pełną listę, zobaczObsługa języków w usłudze Translator.
Czy niestandardowy model tłumaczenia jest właściwym wyborem dla mnie?
Dobrze wyszkolony niestandardowy model tłumaczenia zapewnia dokładniejsze tłumaczenia specyficzne dla domeny, ponieważ opiera się na wcześniej przetłumaczonych dokumentach w domenie w celu uczenia się preferowanych tłumaczeń. Usługa Translator używa tych terminów i fraz w kontekście do tworzenia płynnych tłumaczeń w języku docelowym przy jednoczesnym poszanowaniu gramatyki zależnej od kontekstu.
Trenowanie pełnego niestandardowego modelu tłumaczenia wymaga znacznej ilości danych. Jeśli nie masz co najmniej 10 000 zdań wcześniej wytrenowanych dokumentów, nie możesz wytrenować modelu tłumaczenia w pełnym języku. Można jednak wytrenować model tylko do słownika lub użyć wysokiej jakości, wbudowanych tłumaczeń dostępnych za pomocą interfejsu API tłumaczenia tekstu.
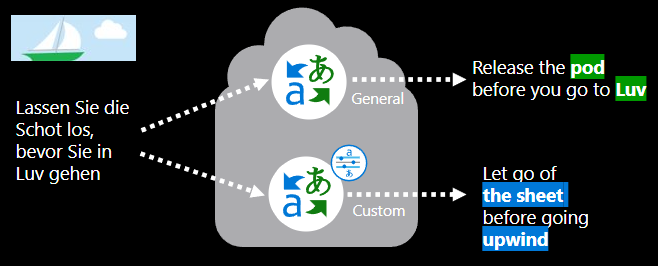
Co obejmuje trenowanie niestandardowego modelu tłumaczenia?
Utworzenie niestandardowego modelu tłumaczenia wymaga:
Opis przypadku użycia.
Uzyskiwanie danych przetłumaczonych w domenie (najlepiej przetłumaczonych przez człowieka).
Ocenianie jakości tłumaczenia lub tłumaczenia języka docelowego.
Jak mogę ocenić mój przypadek użycia?
Mając jasność co do przypadku użycia i jak wygląda sukces, jest pierwszym krokiem w kierunku określania biegłych danych treningowych. Oto kilka zagadnień:
Czy żądany wynik jest określony i jak jest mierzony?
Czy twoja domena biznesowa jest identyfikowana?
Czy masz zdania w domenie podobnej terminologii i stylu?
Czy twój przypadek użycia obejmuje wiele domen? Jeśli tak, czy należy utworzyć jeden system tłumaczenia lub wiele systemów?
Czy masz wymagania wpływające na regionalną rezydencję danych magazynowanych i przesyłanych danych?
Czy użytkownicy docelowi znajdują się w jednym lub wielu regionach?
Jak mogę źródło moje dane?
Znajdowanie danych jakości w domenie jest często trudnym zadaniem, które różni się w zależności od klasyfikacji użytkowników. Oto kilka pytań, które możesz zadać sobie, oceniasz, jakie dane są dostępne dla Ciebie:
Czy twoja firma ma dostępne poprzednie dane tłumaczenia, których można użyć? Przedsiębiorstwa często mają mnóstwo danych tłumaczeń zebranych przez wiele lat przy użyciu tłumaczeń ludzkich.
Czy masz ogromną ilość monolingualnych danych? Monolingual data to dane tylko w jednym języku. Jeśli tak, czy możesz uzyskać tłumaczenia dla tych danych?
Czy można przeszukiwać portale online, aby zbierać zdania źródłowe i syntetyzować zdania docelowe?
Co należy użyć do materiałów treningowych?
| Źródło | Wyniki działania | Reguły do naśladowania |
|---|---|---|
| Dokumenty szkoleniowe dwujęzyczne | Uczy systemu terminologii i stylu. | Bądź liberalny. Każde tłumaczenie ludzkie w domenie jest lepsze niż tłumaczenie maszynowe. Dodaj i usuń dokumenty podczas pracy i spróbuj poprawić wynik BLEU. |
| Dostrajanie dokumentów | Trenuje parametry neuronowego tłumaczenia maszynowego. | Bądź ścisły. Redaguj je, aby być optymalnie reprezentatywnym dla tego, co zamierzasz przetłumaczyć w przyszłości. |
| Testowanie dokumentów | Oblicz wynik BLEU. | Bądź ścisły. Utwórz dokumenty testowe, aby być optymalnie reprezentatywne dla tego, co planujesz przetłumaczyć w przyszłości. |
| Słownik fraz | Wymusza tłumaczenie 100% czasu. | Bądź restrykcyjny. Słownik fraz jest uwzględniany w wielkości liter, a wszystkie wymienione wyrazy lub frazy są tłumaczone w sposób określony przez Użytkownika. W wielu przypadkach lepiej nie używać słownika fraz i pozwolić systemowi się uczyć. |
| Słownik zdań | Wymusza tłumaczenie 100% czasu. | Bądź ścisły. Słownik zdań jest niewrażliwy na wielkość liter i jest dobry dla typowych w krótkich zdaniach domeny. Aby wystąpiło dopasowanie słownika zdań, całe przesłane zdanie musi być zgodne z wpisem słownika źródłowego. Jeśli tylko część zdania jest zgodna, wpis nie jest zgodny. |
Co to jest wskaźnik BLEU?
BLEU (Dwujęzyczna ocena understudy) to algorytm oceny dokładności lub dokładności tekstu przetłumaczonego z jednego języka na inny. Usługa Azure AI Custom Translator używa metryki BLEU jako jednego ze sposobów przekazywania dokładności tłumaczenia.
Wynik BLEU jest liczbą z zakresu od zera do 100. Wynik zerowy wskazuje tłumaczenie niskiej jakości, w którym nic w tłumaczeniu nie pasuje do odwołania. Wynik 100 wskazuje idealne tłumaczenie, które jest identyczne z odwołaniem. Nie jest konieczne uzyskanie wyniku 100 - wynik BLEU z zakresu od 40 do 60 wskazuje wysokiej jakości tłumaczenie.
Co się stanie, jeśli nie przesyłam danych dostrajania ani testowania?
Dostrajanie i testowanie zdań jest optymalnie reprezentatywne dla tego, co planujesz przetłumaczyć w przyszłości. Jeśli nie przesyłasz żadnych danych dostrajania ani testowania, usługa Azure AI Custom Translator automatycznie wyklucza zdania z dokumentów szkoleniowych do użycia jako dane dostrajania i testowania.
| Wygenerowany przez system | Wybór ręczny |
|---|---|
| Dogodny. | Umożliwia dostrajanie pod kątem przyszłych potrzeb. |
| Dobrze, jeśli wiesz, że dane szkoleniowe są reprezentatywne dla tego, co planujesz przetłumaczyć. | Zapewnia większą swobodę tworzenia danych szkoleniowych. |
| Łatwe ponowne wdrożenie podczas zwiększania lub zmniejszania domeny. | Umożliwia uzyskanie większej ilości danych i lepszego pokrycia domeny. |
| Zmienia każdy przebieg trenowania. | Pozostaje statyczny w przypadku powtarzających się przebiegów trenowania |
W jaki sposób materiał szkoleniowy jest przetwarzany przez usługę Azure AI Custom Translator?
Aby przygotować się do szkolenia, dokumenty przechodzą serię kroków przetwarzania i filtrowania. Znajomość procesu filtrowania może pomóc w zrozumieniu liczby wyświetlanych zdań, a także kroków, które można wykonać w celu przygotowania dokumentów szkoleniowych do trenowania za pomocą usługi Azure AI Custom Translator. Kroki filtrowania są następujące:
Wyrównanie zdań
Jeśli dokument nie jest w
XLIFFformacie , ,XLSXTMXlubALIGN, usługa Azure AI Custom Translator dopasowuje zdania źródłowych i docelowych dokumentów do siebie, zdania po zdaniu. Usługa Translator nie wykonuje wyrównania dokumentu — jest zgodna z konwencją nazewnictwa dokumentów w celu znalezienia pasującego dokumentu w innym języku. W tekście źródłowym usługa Azure AI Custom Translator próbuje znaleźć odpowiednie zdanie w języku docelowym. Używa on znaczników dokumentów, takich jak osadzone tagi HTML, aby ułatwić wyrównanie.Jeśli zobaczysz dużą rozbieżność między liczbą zdań w dokumentach źródłowych i docelowych, dokument źródłowy nie może być równoległy lub nie można go wyrównać. Dokument zawiera dużą różnicę (>10%) zdań po każdej stronie gwarantuje drugie spojrzenie, aby upewnić się, że są one rzeczywiście równoległe.
Dostrajanie i testowanie wyodrębniania danych
Dostrajanie i testowanie danych jest opcjonalne. Jeśli go nie podasz, system usunie odpowiedni procent z dokumentów szkoleniowych do użycia do dostrajania i testowania. Usunięcie odbywa się dynamicznie w ramach procesu trenowania. Ponieważ ten krok występuje w ramach trenowania, przekazane dokumenty nie mają wpływu. Po pomyślnym zakończeniu trenowania, testowania i słownika końcowe liczby zdań używanych dla każdej kategorii danych — trenowania, testowania i słownika — można znaleźć na stronie Szczegóły modelu.
Filtr długości
- Usuwa zdania z tylko jednym wyrazem po obu stronach.
- Usuwa zdania z więcej niż 100 wyrazami po obu stronach. Chiński, japoński, koreański są zwolnione.
- Usuwa zdania z mniej niż trzema znakami. Chiński, japoński, koreański są zwolnione.
- Usuwa zdania z ponad 2000 znakami dla chińskich, japońskich, koreańskich.
- Usuwa zdania z mniej niż 1% znakami alfanumerycznymi.
- Usuwa wpisy słownika zawierające więcej niż 50 wyrazów.
Odstępu
- Zastępuje dowolną sekwencję znaków odstępów, w tym tabulatory i sekwencje CR/LF pojedynczym znakiem spacji.
- Usuwa spację prowadzącą lub końcową w zdaniu.
Znak interpunkcyjny końca zdania
Zamienia wiele znaków interpunkcyjnych na jedno wystąpienie. Normalizacja znaków japońskich.
Konwertuje pełne litery i cyfry na znaki o połowie szerokości.
Unescaped XML tags (Niezasłane tagi XML)
Przekształca niezasłane tagi na tagi ucieczki:
Tag Staje się < & Lt; > & Gt; & & Amp; Nieprawidłowe znaki
Usługa Azure AI Custom Translator usuwa zdania zawierające znaki Unicode U+FFFD. Znak U+FFFD wskazuje na nieudaną konwersję kodowania.
Jakie kroki należy wykonać przed przekazaniem danych?
- Usuń zdania z nieprawidłowym kodowaniem.
- Usuń znaki sterujące Unicode.
- Wyrównuj zdania (źródło-cel), jeśli jest to możliwe.
- Usuń zdania źródłowe i docelowe, które nie pasują do języków źródłowych i docelowych.
- Gdy zdania źródłowe i docelowe mają języki mieszane, upewnij się, że nieprzetłumaczone wyrazy są zamierzone, na przykład nazwy organizacji i produktów.
- Unikaj nauczania błędów w modelu, upewniając się, że gramatyka i typografia są poprawne.
- Mieć jedno zdanie źródłowe zamapowane na jedno zdanie docelowe. Mimo że nasz proces trenowania obsługuje wiersze źródłowe i docelowe zawierające wiele zdań, mapowanie jeden do jednego jest najlepszym rozwiązaniem.
Jak mogę ocenić wyniki?
Po pomyślnym wytrenowanym modelu możesz wyświetlić wynik BLEU modelu i wynik BLEU modelu bazowego na stronie szczegółów modelu. Używamy tego samego zestawu danych testowych, aby wygenerować zarówno wynik BLEU modelu, jak i wynik BLEU punktu odniesienia. Te dane ułatwiają podejmowanie świadomych decyzji dotyczących tego, który model byłby lepszy dla danego przypadku użycia.