Co to jest osobisty głos dla zamiany tekstu na mowę?
Dzięki osobistemu głosowi możesz umożliwić użytkownikom uzyskanie replikacji sztucznej inteligencji własnych głosów w ciągu kilku sekund. Za pomocą wypowiedzi słownej i krótkiej próbki mowy jako monitu dźwiękowego możesz utworzyć osobisty głos dla użytkowników i umożliwić im generowanie mowy w dowolnym z ponad 90 języków obsługiwanych w ponad 100 ustawieniach regionalnych.
Uwaga
Osobisty głos jest dostępny w następujących regionach: Europa Zachodnia, Wschodnie stany USA, Zachodnie stany USA 2, Azja Południowo-Wschodnia i Azja Wschodnia. Aby uzyskać informacje o obsługiwanych ustawieniach regionalnych, zobacz Obsługa języka głosu osobistego.
W poniższej tabeli przedstawiono podsumowanie różnic między osobistym głosem a profesjonalnym niestandardowym neuronowym głosem.
| Porównanie | Osobisty głos | Profesjonalny głos |
|---|---|---|
| Scenariusze docelowego | Klienci biznesowi mogą utworzyć aplikację, aby umożliwić swoim użytkownikom tworzenie i używanie własnego osobistego głosu w aplikacji. | Profesjonalne scenariusze, takie jak głosy marki i znaków dla czatbotów lub odczytywanie zawartości audio. |
| Przypadki użycia | Ograniczone do ograniczonych przypadków użycia. Zobacz notatkę o przezroczystości. Zatwierdzoni klienci powinni mieć plan obsługi ponad 1000 osobistych głosów. | Ograniczone do ograniczonych przypadków użycia. Zobacz notatkę o przezroczystości. |
| Dane szkoleniowe | Upewnij się, że przestrzegasz kodeksu postępowania. | Przynieś własne dane. Nagrywanie w profesjonalnym studio jest zalecane. |
| Wymagany rozmiar danych | Jedna minuta ludzkiej mowy. | 300–2000 wypowiedzi (około 30 minut do 3 godzin mowy ludzkiej). |
| Czas trenowania | Mniej niż 5 sekund | Około 20–40 godzin obliczeniowych. |
| Jakość głosu | Naturalny | Wysoce naturalne |
| Obsługa wielu języków | Tak. Głos jest w stanie mówić o 100 językach z włączonym automatycznym wykrywaniem języka. | Tak. Musisz wybrać funkcję "Neuronowa — krzyżowa", aby wytrenować model, który mówi innym językiem od danych treningowych. |
| Dostępność | Pokaz w usłudze Speech Studio jest dostępny podczas rejestracji. Dostęp do interfejsu API jest ograniczony do uprawnionych klientów i zatwierdzonych przypadków użycia. Zażądaj dostępu za pośrednictwem formularza do wprowadzania. | Po zatwierdzeniu dostępu można trenować i wdrażać tylko model CNV Pro. Dostęp CNV Pro jest ograniczony na podstawie kryteriów uprawnień i użycia. Zażądaj dostępu za pośrednictwem formularza do wprowadzania. |
| Cennik | Sprawdź szczegóły cennika tutaj1. | Sprawdź szczegóły cennika tutaj. |
| Wymagania dotyczące odpowiedzialnej sztucznej inteligencji | Wymagane jest ustne oświadczenie osoby mówiącej. Nie jest dozwolony niezatwierdzony przypadek użycia. | Wymagane jest ustne oświadczenie osoby mówiącej. Nie jest dozwolony niezatwierdzony przypadek użycia. |
1 Należy pamiętać, że ceny głosu osobistego będą widoczne tylko dla regionów usług, w których ta funkcja jest dostępna, w tym Europa Zachodnia, Wschodnie stany USA, Zachodnie stany USA 2, Azja Południowo-Wschodnia i Azja Wschodnia.
Wypróbuj wersję demonstracyjną
Jeśli masz zasób S0, możesz uzyskać dostęp do pokazu osobistego głosu w usłudze Speech Studio. Aby użyć osobistego interfejsu API głosu, możesz ubiegać się o dostęp tutaj.
Przejdź do usługi Speech Studio
Wybierz kartę Osobisty głos .
Możesz zarejestrować własny głos i wypróbować próbki danych wyjściowych głosu w różnych językach. Pokaz zawiera podzbiór języków obsługiwanych przez osobisty głos.
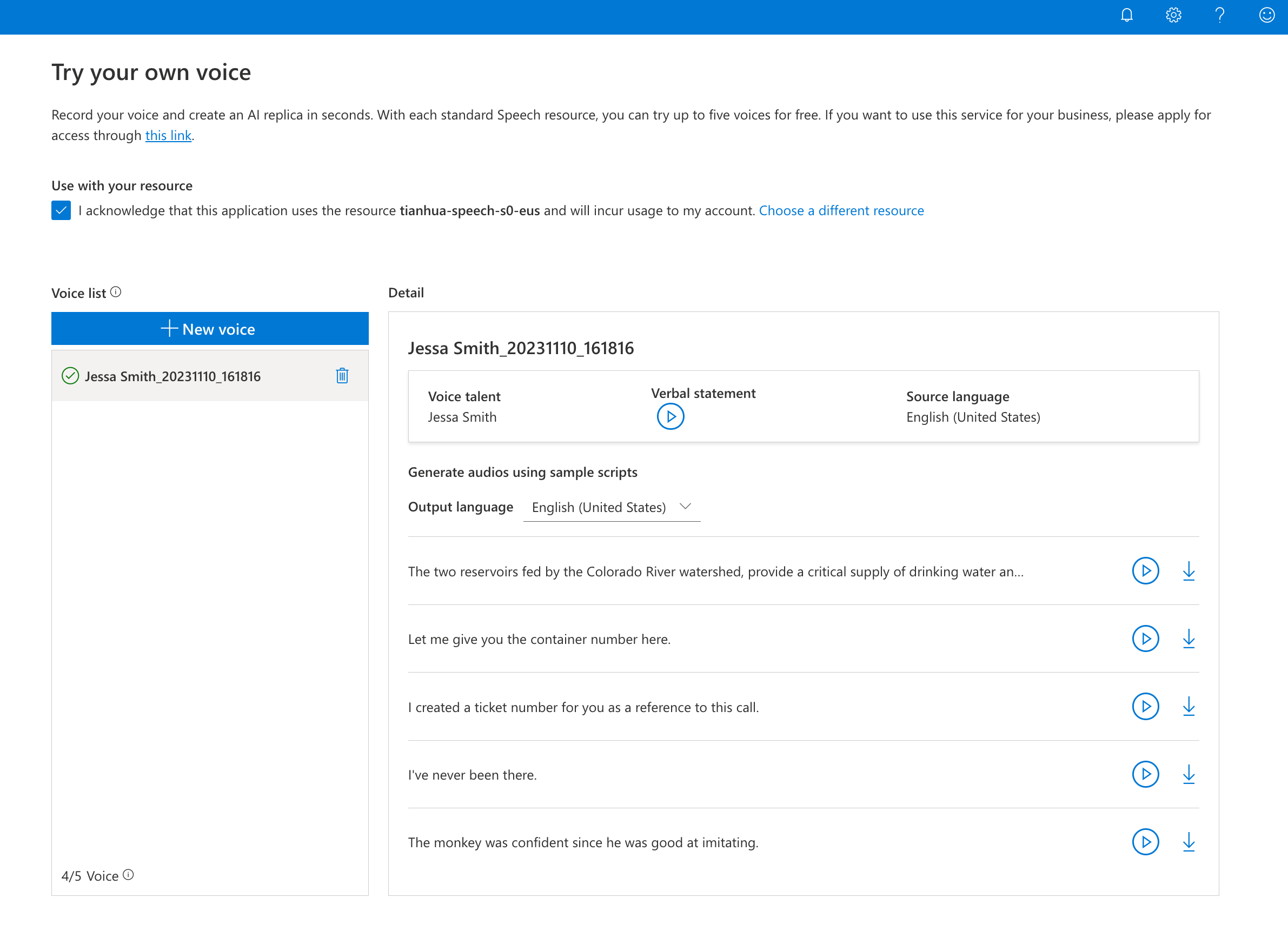

Jak utworzyć osobisty głos
Aby rozpocząć, poniżej przedstawiono podsumowanie kroków tworzenia osobistego głosu:
- Utwórz projekt.
- Przekaż plik zgody. Funkcja głosu osobistego wymaga, aby każdy głos był tworzony z jawną zgodą użytkownika. Zarejestrowana instrukcja od użytkownika jest wymagana z potwierdzeniem, że klient (właściciel zasobu usługi Azure AI Speech) utworzy i użyje swojego głosu.
-
Uzyskaj identyfikator profilu osoby mówiącej dla osobistego głosu. Otrzymasz identyfikator profilu osoby mówiącej na podstawie ustnego oświadczenia zgody osoby mówiącej i monitu audio. Cechy głosu użytkownika są kodowane we właściwości używanej
speakerProfileIddo zamiany tekstu na mowę.
Gdy masz osobisty głos, możesz użyć go do syntezowania mowy w dowolnym z 91 języków obsługiwanych w 100+ ustawieniach regionalnych. Tag ustawień regionalnych nie jest wymagany. Osobisty głos używa automatycznego wykrywania języka na poziomie zdania. Aby uzyskać więcej informacji, zobacz Używanie głosu osobistego w aplikacji.
Napiwek
Zapoznaj się z przykładami kodu w repozytorium zestawu Speech SDK w usłudze GitHub , aby zobaczyć, jak używać osobistego głosu w aplikacji.
Dokumentacja referencyjna
Odpowiedzialne AI
Zależy nam na osobach korzystających ze sztucznej inteligencji i ludzi, którzy będą na nią wpływać tak samo, jak zależy nam na technologii. Aby uzyskać więcej informacji, zobacz Informacje o przejrzystości odpowiedzialnej sztucznej inteligencji.
Następne kroki
- Utwórz projekt.
- Dowiedz się więcej o niestandardowym neuronowym głosie w omówieniu.
- Dowiedz się więcej o usłudze Speech Studio w omówieniu.