Jak rozpoznawać intencje za pomocą prostego dopasowania wzorca języka
Usługa SDK mowy Azure AI ma wbudowaną funkcję rozpoznawania intencji z dopasowywaniem prostych wzorców językowych. Intencją jest coś, co użytkownik chce zrobić: zamknij okno, zaznacz pole wyboru, wstaw jakiś tekst itp.
W tym przewodniku użyjesz zestawu SDK usługi Mowa do utworzenia aplikacji konsolowej języka C++, która wyprowadza intencje z wypowiedzi użytkownika za pośrednictwem mikrofonu urządzenia. Nauczysz się, jak:
- Tworzenie projektu programu Visual Studio odwołującego się do pakietu NuGet zestawu Speech SDK
- Tworzenie konfiguracji mowy i uzyskiwanie rozpoznawania intencji
- Dodawanie intencji i wzorców za pomocą interfejsu API zestawu SPEECH SDK
- Rozpoznawanie mowy przy użyciu mikrofonu
- Używanie asynchronicznego, opartego na zdarzeniach rozpoznawania ciągłego
Kiedy należy używać dopasowywania wzorców
Użyj dopasowania wzorca, jeśli:
- Interesuje Cię tylko dopasowanie dokładnie tego, co powiedział użytkownik. Te wzorce działają bardziej agresywnie niż rozumienie języka konwersacyjnego (CLU).
- Nie masz dostępu do modelu CLU, ale nadal potrzebujesz intencji.
Aby uzyskać więcej informacji, zobacz przegląd dopasowywania wzorców.
Wymagania wstępne
Przed rozpoczęciem tego przewodnika upewnij się, że masz następujące elementy:
- Zasób usług Azure AI lub zasób ujednoliconej mowy
- Visual Studio 2019 (dowolna wersja).
Mowa i proste wzorce
Proste wzorce są jedną z funkcji w ramach zestawu SDK dla usługi Mowa i wymagają zasobu usług Azure AI lub zasobu Unified Speech.
Wzorzec to fraza zawierająca jednostkę gdzieś w niej. Jednostka jest definiowana przez zawijanie wyrazu w nawiasach klamrowych. W tym przykładzie zdefiniowano jednostkę o identyfikatorze "floorName", która uwzględnia wielkość liter:
Take me to the {floorName}
Wszystkie inne znaki specjalne i znaki interpunkcyjne są ignorowane.
Intencje są dodawane za pomocą wywołań interfejsu API >IntentRecognizer-AddIntent().
Tworzenie projektu
Utwórz nowy projekt aplikacji konsolowej języka C# w programie Visual Studio 2019 i zainstaluj zestaw Speech SDK.
Zacznij od kodu szablonowego
Otwórzmy Program.cs i dodajmy kod, który działa jako szkielet naszego projektu.
using System;
using System.Threading.Tasks;
using Microsoft.CognitiveServices.Speech;
using Microsoft.CognitiveServices.Speech.Intent;
namespace helloworld
{
class Program
{
static void Main(string[] args)
{
IntentPatternMatchingWithMicrophoneAsync().Wait();
}
private static async Task IntentPatternMatchingWithMicrophoneAsync()
{
var config = SpeechConfig.FromSubscription("YOUR_SUBSCRIPTION_KEY", "YOUR_SUBSCRIPTION_REGION");
}
}
}
Tworzenie konfiguracji mowy
Przed zainicjowaniem IntentRecognizer obiektu należy utworzyć konfigurację, która używa klucza i lokalizacji zasobu przewidywania usług Azure AI.
- Zastąp
"YOUR_SUBSCRIPTION_KEY"kluczem predykcji usług Azure AI. - Zastąp
"YOUR_SUBSCRIPTION_REGION"element regionem zasobów Azure AI.
W tym przykładzie użyto metody FromSubscription() do zbudowania SpeechConfig. Aby uzyskać pełną listę dostępnych metod, zobacz SpeechConfig Class (Klasa SpeechConfig).
Zainicjuj IntentRecognizer
Teraz utwórz element IntentRecognizer. Wstaw ten kod bezpośrednio poniżej konfiguracji usługi Mowa.
using (var intentRecognizer = new IntentRecognizer(config))
{
}
Dodaj kilka intencji
Należy skojarzyć pewne wzorce z elementem IntentRecognizer , wywołując polecenie AddIntent().
Dodamy dwie intencje o tym samym identyfikatorze do zmiany pięter, oraz dodatkową intencję z oddzielnym identyfikatorem do otwierania i zamykania drzwi.
Wstaw ten kod wewnątrz using bloku:
intentRecognizer.AddIntent("Take me to floor {floorName}.", "ChangeFloors");
intentRecognizer.AddIntent("Go to floor {floorName}.", "ChangeFloors");
intentRecognizer.AddIntent("{action} the door.", "OpenCloseDoor");
Uwaga
Nie ma limitu liczby jednostek, które można zadeklarować, ale będą luźno dopasowane. Jeśli dodasz frazę w rodzaju "{action} drzwi", dopasuje się ona za każdym razem, gdy w tekście przed słowem "drzwi" pojawi się dowolny tekst. Intencje są oceniane na podstawie ich liczby jednostek. Jeśli dwa wzorce się pokrywają, zwracany jest ten z większą liczbą zdefiniowanych jednostek.
Rozpoznawanie intencji
Z obiektu IntentRecognizer wywołasz metodę RecognizeOnceAsync(). Ta metoda prosi usługę rozpoznawania mowy o rozpoznawanie mowy w jednej frazie i zaprzestanie rozpoznawania mowy po zidentyfikowaniu frazy. Dla uproszczenia zaczekamy na zakończenie przyszłego powrotu.
Wstaw ten kod poniżej swoich intencji:
Console.WriteLine("Say something...");
var result = await intentRecognizer.RecognizeOnceAsync();
Wyświetlanie wyników rozpoznawania (lub błędów)
Gdy usługa rozpoznawania mowy zwraca wynik, drukujemy wynik.
Wstaw poniższy kod var result = await recognizer.RecognizeOnceAsync();:
string floorName;
switch (result.Reason)
{
case ResultReason.RecognizedSpeech:
Console.WriteLine($"RECOGNIZED: Text= {result.Text}");
Console.WriteLine($" Intent not recognized.");
break;
case ResultReason.RecognizedIntent:
Console.WriteLine($"RECOGNIZED: Text= {result.Text}");
Console.WriteLine($" Intent Id= {result.IntentId}.");
var entities = result.Entities;
if (entities.TryGetValue("floorName", out floorName))
{
Console.WriteLine($" FloorName= {floorName}");
}
if (entities.TryGetValue("action", out floorName))
{
Console.WriteLine($" Action= {floorName}");
}
break;
case ResultReason.NoMatch:
{
Console.WriteLine($"NOMATCH: Speech could not be recognized.");
var noMatch = NoMatchDetails.FromResult(result);
switch (noMatch.Reason)
{
case NoMatchReason.NotRecognized:
Console.WriteLine($"NOMATCH: Speech was detected, but not recognized.");
break;
case NoMatchReason.InitialSilenceTimeout:
Console.WriteLine($"NOMATCH: The start of the audio stream contains only silence, and the service timed out waiting for speech.");
break;
case NoMatchReason.InitialBabbleTimeout:
Console.WriteLine($"NOMATCH: The start of the audio stream contains only noise, and the service timed out waiting for speech.");
break;
case NoMatchReason.KeywordNotRecognized:
Console.WriteLine($"NOMATCH: Keyword not recognized");
break;
}
break;
}
case ResultReason.Canceled:
{
var cancellation = CancellationDetails.FromResult(result);
Console.WriteLine($"CANCELED: Reason={cancellation.Reason}");
if (cancellation.Reason == CancellationReason.Error)
{
Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}");
Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}");
Console.WriteLine($"CANCELED: Did you set the speech resource key and region values?");
}
break;
}
default:
break;
}
Sprawdzanie kodu
Na tym etapie kod powinien wyglądać następująco:
using System;
using System.Threading.Tasks;
using Microsoft.CognitiveServices.Speech;
using Microsoft.CognitiveServices.Speech.Intent;
namespace helloworld
{
class Program
{
static void Main(string[] args)
{
IntentPatternMatchingWithMicrophoneAsync().Wait();
}
private static async Task IntentPatternMatchingWithMicrophoneAsync()
{
var config = SpeechConfig.FromSubscription("YOUR_SUBSCRIPTION_KEY", "YOUR_SUBSCRIPTION_REGION");
using (var intentRecognizer = new IntentRecognizer(config))
{
intentRecognizer.AddIntent("Take me to floor {floorName}.", "ChangeFloors");
intentRecognizer.AddIntent("Go to floor {floorName}.", "ChangeFloors");
intentRecognizer.AddIntent("{action} the door.", "OpenCloseDoor");
Console.WriteLine("Say something...");
var result = await intentRecognizer.RecognizeOnceAsync();
string floorName;
switch (result.Reason)
{
case ResultReason.RecognizedSpeech:
Console.WriteLine($"RECOGNIZED: Text= {result.Text}");
Console.WriteLine($" Intent not recognized.");
break;
case ResultReason.RecognizedIntent:
Console.WriteLine($"RECOGNIZED: Text= {result.Text}");
Console.WriteLine($" Intent Id= {result.IntentId}.");
var entities = result.Entities;
if (entities.TryGetValue("floorName", out floorName))
{
Console.WriteLine($" FloorName= {floorName}");
}
if (entities.TryGetValue("action", out floorName))
{
Console.WriteLine($" Action= {floorName}");
}
break;
case ResultReason.NoMatch:
{
Console.WriteLine($"NOMATCH: Speech could not be recognized.");
var noMatch = NoMatchDetails.FromResult(result);
switch (noMatch.Reason)
{
case NoMatchReason.NotRecognized:
Console.WriteLine($"NOMATCH: Speech was detected, but not recognized.");
break;
case NoMatchReason.InitialSilenceTimeout:
Console.WriteLine($"NOMATCH: The start of the audio stream contains only silence, and the service timed out waiting for speech.");
break;
case NoMatchReason.InitialBabbleTimeout:
Console.WriteLine($"NOMATCH: The start of the audio stream contains only noise, and the service timed out waiting for speech.");
break;
case NoMatchReason.KeywordNotRecognized:
Console.WriteLine($"NOMATCH: Keyword not recognized");
break;
}
break;
}
case ResultReason.Canceled:
{
var cancellation = CancellationDetails.FromResult(result);
Console.WriteLine($"CANCELED: Reason={cancellation.Reason}");
if (cancellation.Reason == CancellationReason.Error)
{
Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}");
Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}");
Console.WriteLine($"CANCELED: Did you set the speech resource key and region values?");
}
break;
}
default:
break;
}
}
}
}
}
Kompilowanie i uruchamianie aplikacji
Teraz możesz przystąpić do kompilowania aplikacji i testowania rozpoznawania mowy przy użyciu usługi Mowa.
- Skompiluj kod — na pasku menu programu Visual Studio wybierz pozycję Kompilacja>Kompiluj rozwiązanie.
- Uruchom aplikację — na pasku menu wybierz pozycję Debuguj>rozpocznij debugowanie lub naciśnij F5.
- Rozpocznij rozpoznawanie — zachęca cię do powiedzenia czegoś. Domyślnym językiem jest angielski. Twoja mowa jest wysyłana do usługi rozpoznawania mowy, transkrybowana jako tekst i renderowana w konsoli programu .
Na przykład, jeśli powiesz "Zabierz mnie na siódme piętro", to powinno to być efektem:
Say something ...
RECOGNIZED: Text= Take me to floor 7.
Intent Id= ChangeFloors
FloorName= 7
Tworzenie projektu
Utwórz nowy projekt aplikacji konsolowej języka C++ w programie Visual Studio 2019 i zainstaluj zestaw Speech SDK.
Zacznij od kodu szablonowego
Otwórzmy helloworld.cpp i dodajmy kod, który działa jako szkielet naszego projektu.
#include <iostream>
#include <speechapi_cxx.h>
using namespace Microsoft::CognitiveServices::Speech;
using namespace Microsoft::CognitiveServices::Speech::Intent;
int main()
{
std::cout << "Hello World!\n";
auto config = SpeechConfig::FromSubscription("YOUR_SUBSCRIPTION_KEY", "YOUR_SUBSCRIPTION_REGION");
}
Tworzenie konfiguracji mowy
Przed zainicjowaniem IntentRecognizer obiektu należy utworzyć konfigurację, która używa klucza i lokalizacji zasobu przewidywania usług Azure AI.
- Zastąp
"YOUR_SUBSCRIPTION_KEY"kluczem prognozy usług Azure AI. - Zamień
"YOUR_SUBSCRIPTION_REGION"na swój region zasobów usług Azure AI.
W tym przykładzie użyto metody FromSubscription() do zbudowania SpeechConfig. Aby uzyskać pełną listę dostępnych metod, zobacz SpeechConfig Class (Klasa SpeechConfig).
Inicjowanie IntentRecognizer
Teraz utwórz element IntentRecognizer. Wstaw ten kod bezpośrednio poniżej konfiguracji usługi Mowa.
auto intentRecognizer = IntentRecognizer::FromConfig(config);
Dodaj niektóre intencje
Należy skojarzyć pewne wzorce z elementem IntentRecognizer , wywołując polecenie AddIntent().
Dodamy dwie intencje o tym samym identyfikatorze do zmiany pięter oraz intencję z osobnym identyfikatorem do otwierania i zamykania drzwi.
intentRecognizer->AddIntent("Take me to floor {floorName}.", "ChangeFloors");
intentRecognizer->AddIntent("Go to floor {floorName}.", "ChangeFloors");
intentRecognizer->AddIntent("{action} the door.", "OpenCloseDoor");
Uwaga
Nie ma limitu liczby jednostek, które można zadeklarować, ale będą luźno dopasowane. Jeśli dodasz frazę podobną do "{action} drzwi", dopasujesz ją za każdym razem, gdy tekst występuje przed słowem "drzwi". Intencje są oceniane na podstawie ich liczby jednostek. Jeśli dwa wzorce będą zgodne, zwracany jest ten z bardziej zdefiniowanymi jednostkami.
Rozpoznawanie intencji
Z obiektu IntentRecognizer wywołasz metodę RecognizeOnceAsync(). Ta metoda prosi usługę rozpoznawania mowy o rozpoznawanie mowy w jednej frazie i zaprzestanie rozpoznawania mowy po zidentyfikowaniu frazy. Dla uproszczenia zaczekamy na zakończenie zwróconej przyszłości.
Wstaw ten kod poniżej swoich intencji:
std::cout << "Say something ..." << std::endl;
auto result = intentRecognizer->RecognizeOnceAsync().get();
Wyświetlanie wyników rozpoznawania (lub błędów)
Gdy usługa rozpoznawania mowy zwraca wynik rozpoznawania, wyświetlamy wynik.
Wstaw poniższy kod auto result = intentRecognizer->RecognizeOnceAsync().get();:
switch (result->Reason)
{
case ResultReason::RecognizedSpeech:
std::cout << "RECOGNIZED: Text = " << result->Text.c_str() << std::endl;
std::cout << "NO INTENT RECOGNIZED!" << std::endl;
break;
case ResultReason::RecognizedIntent:
std::cout << "RECOGNIZED: Text = " << result->Text.c_str() << std::endl;
std::cout << " Intent Id = " << result->IntentId.c_str() << std::endl;
auto entities = result->GetEntities();
if (entities.find("floorName") != entities.end())
{
std::cout << " Floor name: = " << entities["floorName"].c_str() << std::endl;
}
if (entities.find("action") != entities.end())
{
std::cout << " Action: = " << entities["action"].c_str() << std::endl;
}
break;
case ResultReason::NoMatch:
{
auto noMatch = NoMatchDetails::FromResult(result);
switch (noMatch->Reason)
{
case NoMatchReason::NotRecognized:
std::cout << "NOMATCH: Speech was detected, but not recognized." << std::endl;
break;
case NoMatchReason::InitialSilenceTimeout:
std::cout << "NOMATCH: The start of the audio stream contains only silence, and the service timed out waiting for speech." << std::endl;
break;
case NoMatchReason::InitialBabbleTimeout:
std::cout << "NOMATCH: The start of the audio stream contains only noise, and the service timed out waiting for speech." << std::endl;
break;
case NoMatchReason::KeywordNotRecognized:
std::cout << "NOMATCH: Keyword not recognized" << std::endl;
break;
}
break;
}
case ResultReason::Canceled:
{
auto cancellation = CancellationDetails::FromResult(result);
if (!cancellation->ErrorDetails.empty())
{
std::cout << "CANCELED: ErrorDetails=" << cancellation->ErrorDetails.c_str() << std::endl;
std::cout << "CANCELED: Did you set the speech resource key and region values?" << std::endl;
}
}
default:
break;
}
Sprawdzanie kodu
Na tym etapie kod powinien wyglądać następująco:
#include <iostream>
#include <speechapi_cxx.h>
using namespace Microsoft::CognitiveServices::Speech;
using namespace Microsoft::CognitiveServices::Speech::Intent;
int main()
{
auto config = SpeechConfig::FromSubscription("YOUR_SUBSCRIPTION_KEY", "YOUR_SUBSCRIPTION_REGION");
auto intentRecognizer = IntentRecognizer::FromConfig(config);
intentRecognizer->AddIntent("Take me to floor {floorName}.", "ChangeFloors");
intentRecognizer->AddIntent("Go to floor {floorName}.", "ChangeFloors");
intentRecognizer->AddIntent("{action} the door.", "OpenCloseDoor");
std::cout << "Say something ..." << std::endl;
auto result = intentRecognizer->RecognizeOnceAsync().get();
switch (result->Reason)
{
case ResultReason::RecognizedSpeech:
std::cout << "RECOGNIZED: Text = " << result->Text.c_str() << std::endl;
std::cout << "NO INTENT RECOGNIZED!" << std::endl;
break;
case ResultReason::RecognizedIntent:
std::cout << "RECOGNIZED: Text = " << result->Text.c_str() << std::endl;
std::cout << " Intent Id = " << result->IntentId.c_str() << std::endl;
auto entities = result->GetEntities();
if (entities.find("floorName") != entities.end())
{
std::cout << " Floor name: = " << entities["floorName"].c_str() << std::endl;
}
if (entities.find("action") != entities.end())
{
std::cout << " Action: = " << entities["action"].c_str() << std::endl;
}
break;
case ResultReason::NoMatch:
{
auto noMatch = NoMatchDetails::FromResult(result);
switch (noMatch->Reason)
{
case NoMatchReason::NotRecognized:
std::cout << "NOMATCH: Speech was detected, but not recognized." << std::endl;
break;
case NoMatchReason::InitialSilenceTimeout:
std::cout << "NOMATCH: The start of the audio stream contains only silence, and the service timed out waiting for speech." << std::endl;
break;
case NoMatchReason::InitialBabbleTimeout:
std::cout << "NOMATCH: The start of the audio stream contains only noise, and the service timed out waiting for speech." << std::endl;
break;
case NoMatchReason::KeywordNotRecognized:
std::cout << "NOMATCH: Keyword not recognized." << std::endl;
break;
}
break;
}
case ResultReason::Canceled:
{
auto cancellation = CancellationDetails::FromResult(result);
if (!cancellation->ErrorDetails.empty())
{
std::cout << "CANCELED: ErrorDetails=" << cancellation->ErrorDetails.c_str() << std::endl;
std::cout << "CANCELED: Did you set the speech resource key and region values?" << std::endl;
}
}
default:
break;
}
}
Kompilowanie i uruchamianie aplikacji
Teraz możesz przystąpić do kompilowania aplikacji i testowania rozpoznawania mowy przy użyciu usługi Mowa.
- Skompiluj kod — na pasku menu programu Visual Studio wybierz Kompilacja>Kompiluj rozwiązanie.
- Uruchom aplikację — na pasku menu wybierz pozycję Debuguj>rozpocznij debugowanie lub naciśnij F5.
- Rozpocznij rozpoznawanie — zachęca cię do powiedzenia czegoś. Domyślnym językiem jest angielski. Twoja mowa jest wysyłana do usługi rozpoznawania mowy, transkrybowana jako tekst i renderowana w konsoli programu .
Jeśli na przykład zostanie wyświetlony komunikat "Take me to floor 7", powinny to być dane wyjściowe:
Say something ...
RECOGNIZED: Text = Take me to floor 7.
Intent Id = ChangeFloors
Floor name: = 7
| Dokumentacja referencyjna Dodatkowe przykłady w usłudze GitHub
W tym przewodniku szybkiego startu zainstalujesz zestaw Speech SDK dla języka Java.
Wymagania dotyczące platformy
Wybierz środowisko docelowe:
Zestaw SPEECH SDK dla języka Java jest zgodny z systemami Windows, Linux i macOS.
W systemie Windows należy użyć architektury docelowej 64-bitowej. Wymagany jest system Windows 10 lub nowszy.
Zainstaluj Pakiet redystrybucyjny Microsoft Visual C++ dla Visual Studio 2015, 2017, 2019 i 2022 na swojej platformie. Zainstalowanie tego pakietu po raz pierwszy może wymagać ponownego uruchomienia.
Zestaw Speech SDK dla języka Java nie obsługuje systemu Windows na ARM64.
Zainstaluj zestaw Java Development Kit, taki jak Azul Zulu OpenJDK. Pakiet Microsoft Build OpenJDK lub preferowane JDK powinno również działać.
Instalowanie zestawu SPEECH SDK dla języka Java
Niektóre instrukcje używają określonej wersji zestawu SDK, takiej jak 1.43.0. Aby sprawdzić najnowszą wersję, wyszukaj nasze repozytorium GitHub.
Wybierz środowisko docelowe:
W tym przewodniku pokazano, jak zainstalować zestaw Speech SDK dla języka Java w środowisku uruchomieniowym Java.
Obsługiwane systemy operacyjne
Pakiet Speech SDK dla języka Java jest dostępny dla następujących systemów operacyjnych:
- Windows: tylko 64-bitowy.
- Mac: macOS X w wersji 10.14 lub nowszej.
- Linux: zobacz obsługiwane dystrybucje systemu Linux i architektury docelowe.
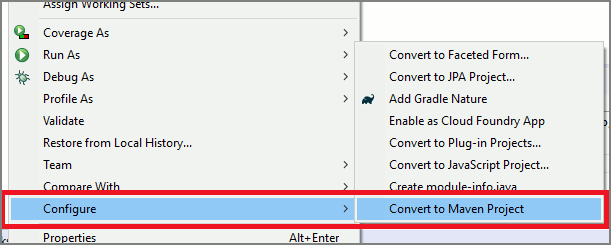
Wykonaj następujące kroki, aby zainstalować zestaw SPEECH SDK dla języka Java przy użyciu narzędzia Apache Maven:
Zainstaluj narzędzie Apache Maven.
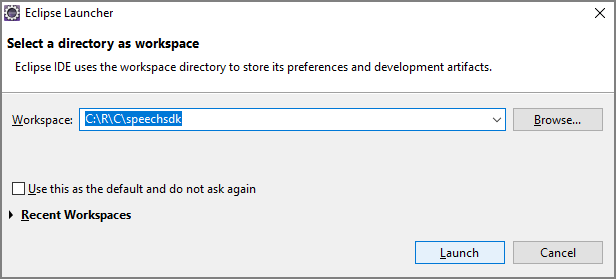
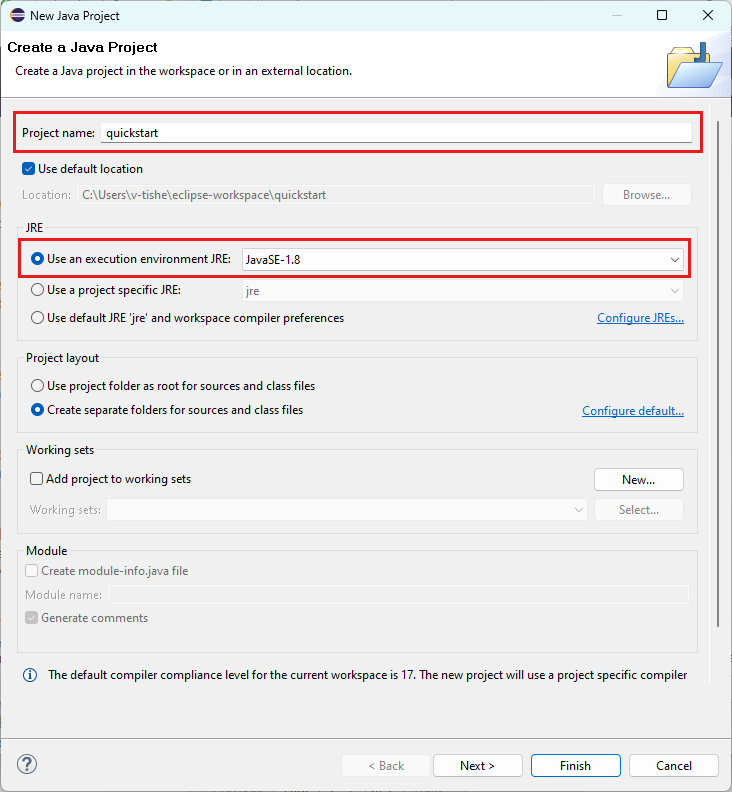
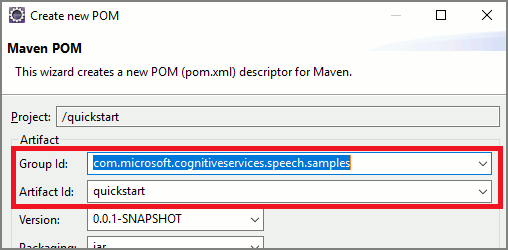
Otwórz wiersz polecenia, w którym chcesz utworzyć nowy projekt, i utwórz nowy plik pom.xml .
Skopiuj następującą zawartość XML do pom.xml:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.microsoft.cognitiveservices.speech.samples</groupId> <artifactId>quickstart-eclipse</artifactId> <version>1.0.0-SNAPSHOT</version> <build> <sourceDirectory>src</sourceDirectory> <plugins> <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>3.7.0</version> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> </plugins> </build> <dependencies> <dependency> <groupId>com.microsoft.cognitiveservices.speech</groupId> <artifactId>client-sdk</artifactId> <version>1.43.0</version> </dependency> </dependencies> </project>Uruchom następujące polecenie narzędzia Maven, aby zainstalować zestaw SPEECH SDK i zależności.
mvn clean dependency:copy-dependencies

Zacznij od kodu szablonowego
Otwórz
Main.javaz katalogu src.Zastąp zawartość pliku następującym kodem:
package quickstart;
import java.util.Dictionary;
import java.util.concurrent.ExecutionException;
import com.microsoft.cognitiveservices.speech.*;
import com.microsoft.cognitiveservices.speech.intent.*;
public class Program {
public static void main(String[] args) throws InterruptedException, ExecutionException {
IntentPatternMatchingWithMicrophone();
}
public static void IntentPatternMatchingWithMicrophone() throws InterruptedException, ExecutionException {
SpeechConfig config = SpeechConfig.fromSubscription("YOUR_SUBSCRIPTION_KEY", "YOUR_SUBSCRIPTION_REGION");
}
}
Tworzenie konfiguracji mowy
Przed zainicjowaniem IntentRecognizer obiektu należy utworzyć konfigurację, która używa klucza i lokalizacji zasobu przewidywania usług Azure AI.
- Zastąp
"YOUR_SUBSCRIPTION_KEY"element kluczem przewidywania usług Azure AI. - Zastąp
"YOUR_SUBSCRIPTION_REGION"regionem zasobów dla usług Azure AI.
W tym przykładzie użyto metody FromSubscription() do zbudowania SpeechConfig. Aby uzyskać pełną listę dostępnych metod, zobacz SpeechConfig Class (Klasa SpeechConfig).
Inicjowanie IntentRecognizer
Teraz utwórz element IntentRecognizer. Wstaw ten kod bezpośrednio poniżej konfiguracji usługi Mowa.
try (IntentRecognizer intentRecognizer = new IntentRecognizer(config)) {
}
Dodaj intencje
Należy skojarzyć pewne wzorce z elementem IntentRecognizer , wywołując polecenie addIntent().
Dodamy 2 intencje o tym samym identyfikatorze do zmiany podłogi, a inną intencję z oddzielnym identyfikatorem do otwierania i zamykania drzwi.
Wstaw ten kod wewnątrz try bloku:
intentRecognizer.addIntent("Take me to floor {floorName}.", "ChangeFloors");
intentRecognizer.addIntent("Go to floor {floorName}.", "ChangeFloors");
intentRecognizer.addIntent("{action} the door.", "OpenCloseDoor");
Uwaga
Nie ma limitu liczby jednostek, które można zadeklarować, ale będą luźno dopasowane. Jeśli dodasz frazę podobną do "{action} door", będzie ona zgodna w dowolnym momencie, gdy tekst będzie występować przed wyrazem "door". Intencje są oceniane na podstawie ich liczby elementów. Jeśli dwa wzorce pasują, zwracany jest ten z większą liczbą zdefiniowanych jednostek.
Rozpoznawanie intencji
Wywołasz metodę recognizeOnceAsync() z obiektu IntentRecognizer. Ta metoda prosi usługę rozpoznawania mowy o rozpoznawanie mowy w jednej frazie i zaprzestanie rozpoznawania mowy po zidentyfikowaniu frazy. Dla uproszczenia zaczekamy na zakończenie przyszłego powrotu.
Wstaw ten kod poniżej swoich intencji:
System.out.println("Say something...");
IntentRecognitionResult result = intentRecognizer.recognizeOnceAsync().get();
Wyświetlanie wyników rozpoznawania (lub błędów)
Gdy wynik rozpoznawania zostanie zwrócony przez usługę Rozpoznawanie mowy, wyświetlimy wynik.
Wstaw poniższy kod IntentRecognitionResult result = recognizer.recognizeOnceAsync().get();:
if (result.getReason() == ResultReason.RecognizedSpeech) {
System.out.println("RECOGNIZED: Text= " + result.getText());
System.out.println(String.format("%17s", "Intent not recognized."));
}
else if (result.getReason() == ResultReason.RecognizedIntent) {
System.out.println("RECOGNIZED: Text= " + result.getText());
System.out.println(String.format("%17s %s", "Intent Id=", result.getIntentId() + "."));
Dictionary<String, String> entities = result.getEntities();
if (entities.get("floorName") != null) {
System.out.println(String.format("%17s %s", "FloorName=", entities.get("floorName")));
}
if (entities.get("action") != null) {
System.out.println(String.format("%17s %s", "Action=", entities.get("action")));
}
}
else if (result.getReason() == ResultReason.NoMatch) {
System.out.println("NOMATCH: Speech could not be recognized.");
}
else if (result.getReason() == ResultReason.Canceled) {
CancellationDetails cancellation = CancellationDetails.fromResult(result);
System.out.println("CANCELED: Reason=" + cancellation.getReason());
if (cancellation.getReason() == CancellationReason.Error)
{
System.out.println("CANCELED: ErrorCode=" + cancellation.getErrorCode());
System.out.println("CANCELED: ErrorDetails=" + cancellation.getErrorDetails());
System.out.println("CANCELED: Did you update the subscription info?");
}
}
Sprawdzanie kodu
Na tym etapie kod powinien wyglądać następująco:
package quickstart;
import java.util.Dictionary;
import java.util.concurrent.ExecutionException;
import com.microsoft.cognitiveservices.speech.*;
import com.microsoft.cognitiveservices.speech.intent.*;
public class Main {
public static void main(String[] args) throws InterruptedException, ExecutionException {
IntentPatternMatchingWithMicrophone();
}
public static void IntentPatternMatchingWithMicrophone() throws InterruptedException, ExecutionException {
SpeechConfig config = SpeechConfig.fromSubscription("YOUR_SUBSCRIPTION_KEY", "YOUR_SUBSCRIPTION_REGION");
try (IntentRecognizer intentRecognizer = new IntentRecognizer(config)) {
intentRecognizer.addIntent("Take me to floor {floorName}.", "ChangeFloors");
intentRecognizer.addIntent("Go to floor {floorName}.", "ChangeFloors");
intentRecognizer.addIntent("{action} the door.", "OpenCloseDoor");
System.out.println("Say something...");
IntentRecognitionResult result = intentRecognizer.recognizeOnceAsync().get();
if (result.getReason() == ResultReason.RecognizedSpeech) {
System.out.println("RECOGNIZED: Text= " + result.getText());
System.out.println(String.format("%17s", "Intent not recognized."));
}
else if (result.getReason() == ResultReason.RecognizedIntent) {
System.out.println("RECOGNIZED: Text= " + result.getText());
System.out.println(String.format("%17s %s", "Intent Id=", result.getIntentId() + "."));
Dictionary<String, String> entities = result.getEntities();
if (entities.get("floorName") != null) {
System.out.println(String.format("%17s %s", "FloorName=", entities.get("floorName")));
}
if (entities.get("action") != null) {
System.out.println(String.format("%17s %s", "Action=", entities.get("action")));
}
}
else if (result.getReason() == ResultReason.NoMatch) {
System.out.println("NOMATCH: Speech could not be recognized.");
}
else if (result.getReason() == ResultReason.Canceled) {
CancellationDetails cancellation = CancellationDetails.fromResult(result);
System.out.println("CANCELED: Reason=" + cancellation.getReason());
if (cancellation.getReason() == CancellationReason.Error)
{
System.out.println("CANCELED: ErrorCode=" + cancellation.getErrorCode());
System.out.println("CANCELED: ErrorDetails=" + cancellation.getErrorDetails());
System.out.println("CANCELED: Did you update the subscription info?");
}
}
}
}
}
Kompilowanie i uruchamianie aplikacji
Teraz jesteś gotowy, aby zbudować swoją aplikację i przetestować nasze rozpoznawanie intencji przy użyciu usługi rozpoznawania mowy oraz wbudowanego dopasowywania wzorców.
Wybierz przycisk uruchamiania w środowisku Eclipse lub naciśnij Ctrl+F11, a następnie obserwuj dane wyjściowe w poszukiwaniu komunikatu "Powiedz coś...". Gdy pojawi się komunikat, powiedz swoją wypowiedź i obejrzyj dane wyjściowe.
Na przykład, jeśli powiesz "Zabierz mnie na 7 piętro", to powinien być rezultat:
Say something ...
RECOGNIZED: Text= Take me to floor 7.
Intent Id= ChangeFloors
FloorName= 7
Następne kroki
Popraw dopasowywanie wzorca przy użyciu niestandardowych jednostek.