Szybki start: rozpoznawanie i konwertowanie mowy na tekst
Ważne
Elementy oznaczone (wersja zapoznawcza) w tym artykule są obecnie dostępne w publicznej wersji zapoznawczej. Ta wersja zapoznawcza jest udostępniana bez umowy dotyczącej poziomu usług i nie zalecamy korzystania z niej w przypadku obciążeń produkcyjnych. Niektóre funkcje mogą być nieobsługiwane lub ograniczone. Aby uzyskać więcej informacji, zobacz Uzupełniające warunki korzystania z wersji zapoznawczych platformy Microsoft Azure.
W tym przewodniku Szybki start spróbujesz zamianę mowy w czasie rzeczywistym na tekst w usłudze Azure AI Foundry.
Wymagania wstępne
- Subskrypcja platformy Azure — utwórz jedną bezpłatnie.
- Niektóre funkcje usług azure AI są bezpłatne do wypróbowania w portalu usługi Azure AI Foundry. Aby uzyskać dostęp do wszystkich możliwości opisanych w tym artykule, musisz połączyć usługi sztucznej inteligencji w usłudze Azure AI Foundry.
Wypróbuj mowę w czasie rzeczywistym na tekst
Przejdź do projektu usługi Azure AI Foundry. Jeśli musisz utworzyć projekt, zobacz Tworzenie projektu usługi Azure AI Foundry.
Wybierz pozycję Place zabaw w okienku po lewej stronie, a następnie wybierz plac zabaw do użycia. W tym przykładzie wybierz pozycję Wypróbuj plac zabaw dla mowy.
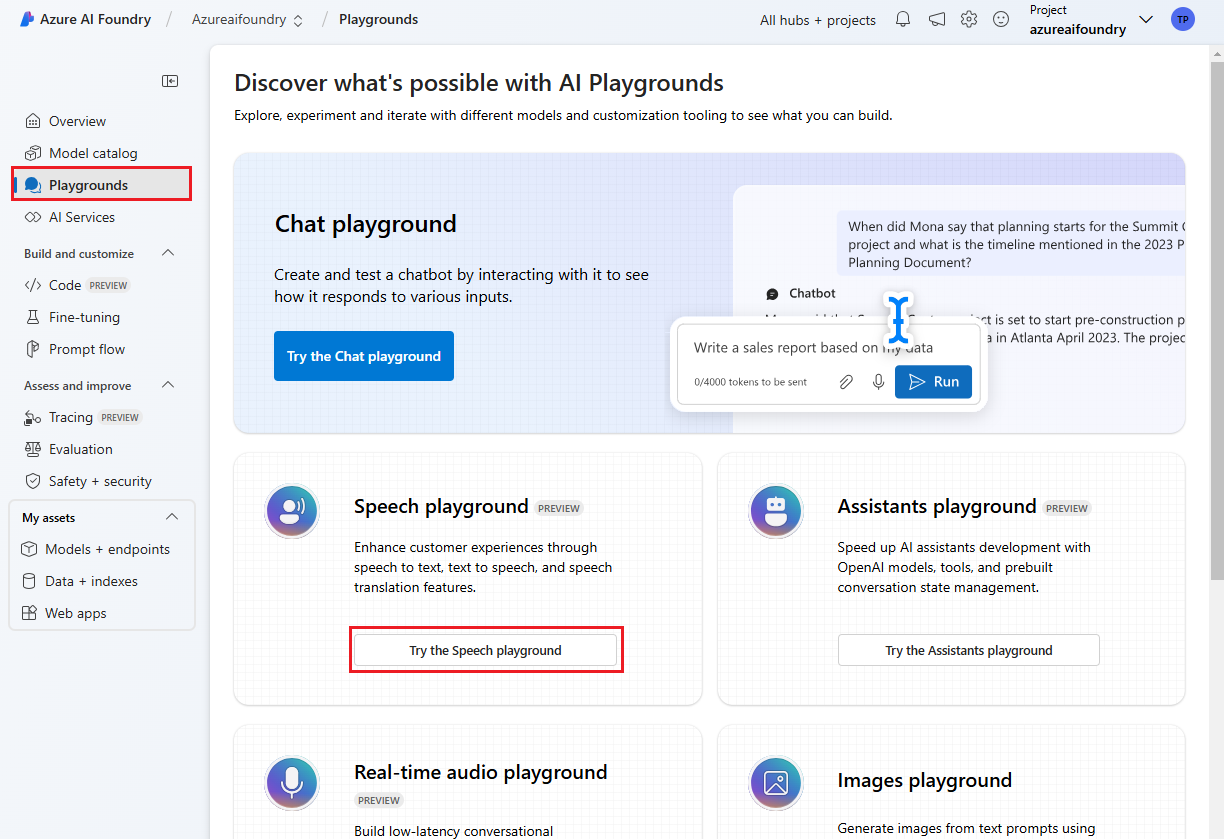
Opcjonalnie możesz wybrać inne połączenie do użycia na placu zabaw. Na placu zabaw dla mowy możesz nawiązać połączenie z zasobami wielosługowymi usług Azure AI Services lub zasobami usługi Mowa.
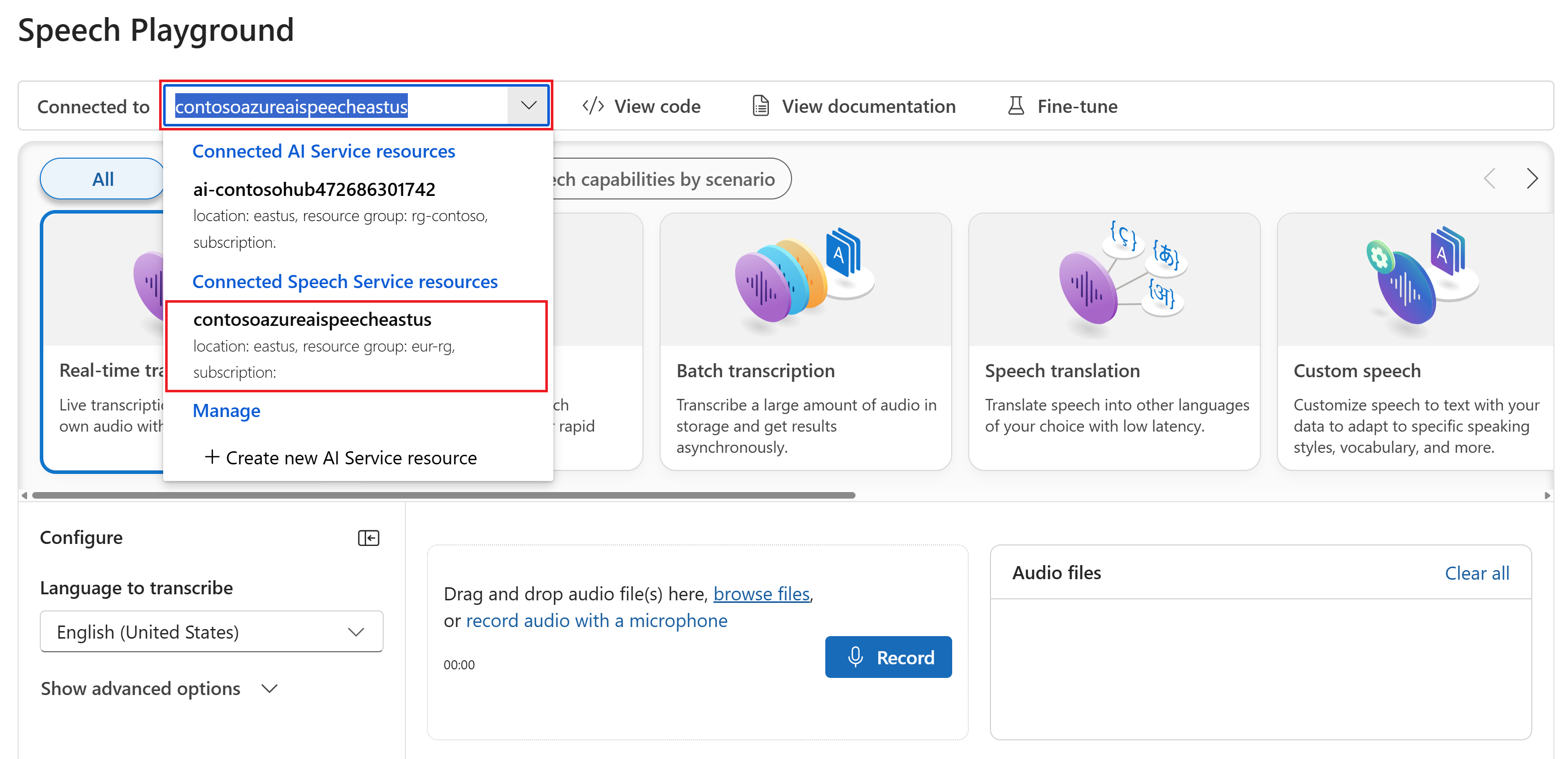
Wybierz pozycję Transkrypcja w czasie rzeczywistym.
Wybierz pozycję Pokaż opcje zaawansowane, aby skonfigurować opcje zamiany mowy na tekst, takie jak:
- Identyfikacja języka: służy do identyfikowania języków mówionych w dźwiękach w porównaniu z listą obsługiwanych języków. Aby uzyskać więcej informacji na temat opcji identyfikacji języka, takich jak na początku i ciągłe rozpoznawanie, zobacz Identyfikacja języka.
- Diaryzacja osoby mówiącej: służy do identyfikowania i oddzielania głośników w dźwięku. Diarization rozróżnia różne osoby mówiące, którzy uczestniczą w konwersacji. Usługa rozpoznawania mowy udostępnia informacje o tym, który mówca mówił określoną część transkrypcji mowy. Aby uzyskać więcej informacji na temat diaryzacji osoby mówiącej, zobacz przewodnik Szybki start dotyczący mowy w czasie rzeczywistym z funkcją diaryzacji osoby mówiącej.
- Niestandardowy punkt końcowy: użyj wdrożonego modelu z niestandardowej mowy, aby zwiększyć dokładność rozpoznawania. Aby użyć modelu bazowego firmy Microsoft, pozostaw ten zestaw na wartość Brak. Aby uzyskać więcej informacji na temat mowy niestandardowej, zobacz Custom Speech.
- Format danych wyjściowych: wybierz między prostymi i szczegółowymi formatami danych wyjściowych. Proste dane wyjściowe obejmują format wyświetlania i znaczniki czasu. Szczegółowe dane wyjściowe obejmują więcej formatów (takich jak wyświetlanie, leksykalne, ITN i maskowane dane ITN), znaczniki czasu i N najlepszych list.
- Lista fraz: popraw dokładność transkrypcji, podając listę znanych fraz, takich jak nazwy osób lub określonych lokalizacji. Użyj przecinków lub średników, aby oddzielić każdą wartość na liście fraz. Aby uzyskać więcej informacji na temat list fraz, zobacz Listy fraz.
Wybierz plik audio do przekazania lub nagraj dźwięk w czasie rzeczywistym. W tym przykładzie używamy pliku dostępnego
Call1_separated_16k_health_insurance.wavw repozytorium zestawu SPEECH SDK w usłudze GitHub. Możesz pobrać plik lub użyć własnego pliku audio.
Transkrypcja w czasie rzeczywistym można wyświetlić w dolnej części strony.
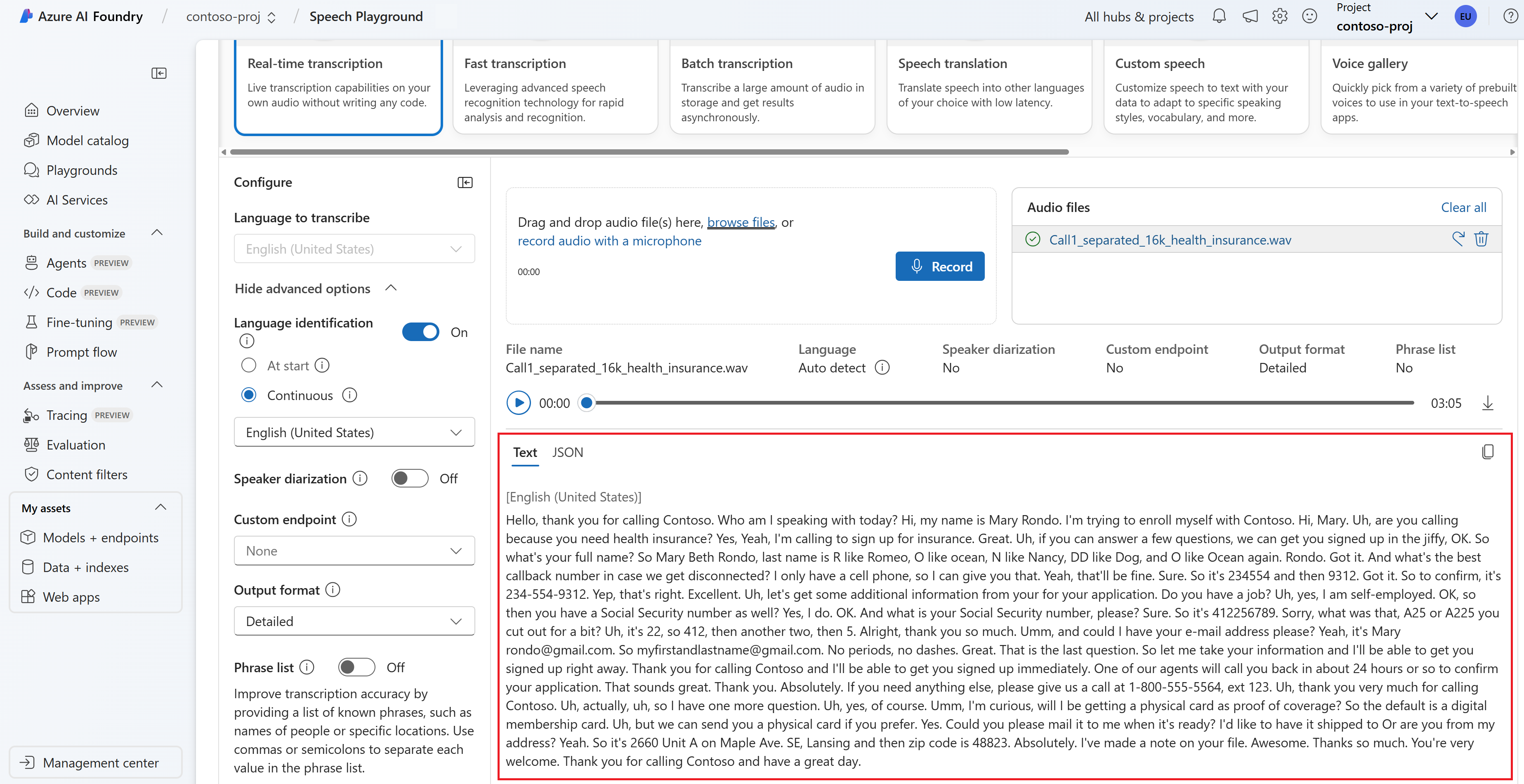
Możesz wybrać kartę JSON, aby wyświetlić dane wyjściowe JSON transkrypcji. Właściwości obejmują
Offset, ,Duration,DisplayRecognitionStatusLexical,ITNi inne.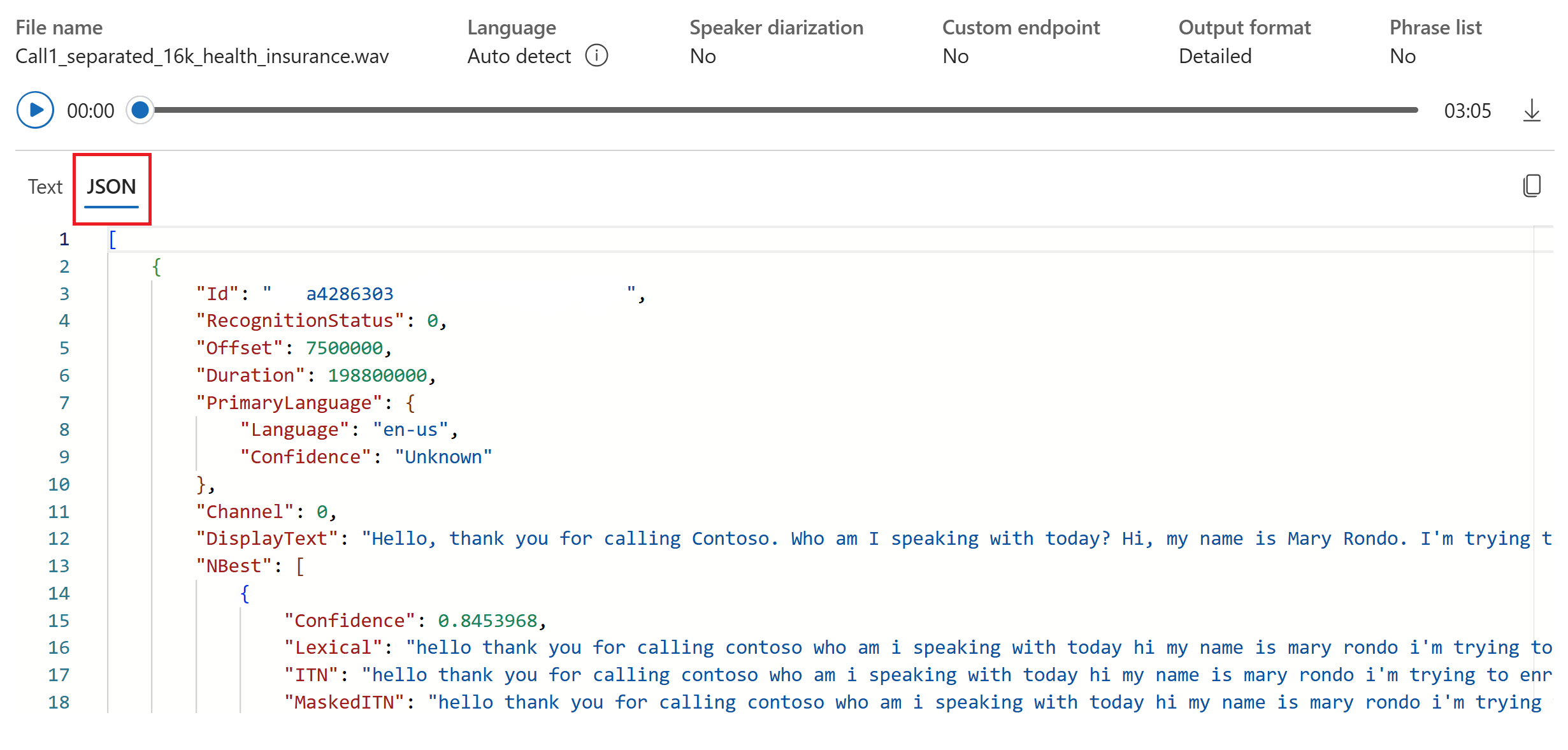





Dokumentacja referencyjna Package (NuGet) | Dodatkowe przykłady w witrynie GitHub |
W tym przewodniku Szybki start utworzysz i uruchomisz aplikację w celu rozpoznawania i transkrypcji mowy na tekst w czasie rzeczywistym.
Aby zamiast tego transkrypcji plików audio asynchronicznie, zobacz Co to jest transkrypcja wsadowa. Jeśli nie masz pewności, które rozwiązanie zamiany mowy na tekst jest odpowiednie dla Ciebie, zobacz Co to jest zamiana mowy na tekst?
Wymagania wstępne
- Subskrypcja platformy Azure. Możesz utworzyć go bezpłatnie.
- Utwórz zasób usługi Mowa w witrynie Azure Portal.
- Pobierz klucz zasobu usługi Mowa i region. Po wdrożeniu zasobu usługi Mowa wybierz pozycję Przejdź do zasobu , aby wyświetlić klucze i zarządzać nimi.
Konfigurowanie środowiska
Zestaw SPEECH SDK jest dostępny jako pakiet NuGet i implementuje platformę .NET Standard 2.0. Zestaw SPEECH SDK zostanie zainstalowany w dalszej części tego przewodnika. Aby uzyskać informacje o innych wymaganiach, zobacz Instalowanie zestawu SPEECH SDK.
Ustawianie zmiennych środowiskowych
Aby uzyskać dostęp do usług Azure AI, musisz uwierzytelnić aplikację. W tym artykule pokazano, jak używać zmiennych środowiskowych do przechowywania poświadczeń. Następnie możesz uzyskać dostęp do zmiennych środowiskowych z kodu w celu uwierzytelnienia aplikacji. W przypadku środowiska produkcyjnego użyj bezpieczniejszego sposobu przechowywania poświadczeń i uzyskiwania do nich dostępu.
Ważne
Zalecamy uwierzytelnianie za pomocą identyfikatora Entra firmy Microsoft z tożsamościami zarządzanymi dla zasobów platformy Azure, aby uniknąć przechowywania poświadczeń przy użyciu aplikacji uruchamianych w chmurze.
Jeśli używasz klucza interfejsu API, zapisz go bezpiecznie w innym miejscu, na przykład w usłudze Azure Key Vault. Nie dołączaj klucza interfejsu API bezpośrednio do kodu i nigdy nie publikuj go publicznie.
Aby uzyskać więcej informacji na temat zabezpieczeń usług sztucznej inteligencji, zobacz Uwierzytelnianie żądań w usługach Azure AI.
Aby ustawić zmienne środowiskowe dla klucza i regionu zasobu usługi Mowa, otwórz okno konsoli i postępuj zgodnie z instrukcjami dotyczącymi systemu operacyjnego i środowiska programistycznego.
- Aby ustawić zmienną
SPEECH_KEYśrodowiskową, zastąp klucz jednym z kluczy zasobu. - Aby ustawić zmienną
SPEECH_REGIONśrodowiskową, zastąp region jednym z regionów zasobu.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Uwaga
Jeśli musisz uzyskać dostęp tylko do zmiennych środowiskowych w bieżącej konsoli, możesz ustawić zmienną środowiskową z wartością setsetxzamiast .
Po dodaniu zmiennych środowiskowych może być konieczne ponowne uruchomienie wszystkich programów, które muszą odczytać zmienne środowiskowe, w tym okno konsoli. Jeśli na przykład używasz programu Visual Studio jako edytora, uruchom ponownie program Visual Studio przed uruchomieniem przykładu.
Rozpoznawanie mowy przy użyciu mikrofonu
Napiwek
Wypróbuj zestaw narzędzi Azure AI Speech Toolkit , aby łatwo kompilować i uruchamiać przykłady w programie Visual Studio Code.
Wykonaj następujące kroki, aby utworzyć aplikację konsolową i zainstalować zestaw SPEECH SDK.
Otwórz okno wiersza polecenia w folderze, w którym chcesz utworzyć nowy projekt. Uruchom to polecenie, aby utworzyć aplikację konsolową przy użyciu interfejsu wiersza polecenia platformy .NET.
dotnet new consoleTo polecenie tworzy plik Program.cs w katalogu projektu.
Zainstaluj zestaw SPEECH SDK w nowym projekcie przy użyciu interfejsu wiersza polecenia platformy .NET.
dotnet add package Microsoft.CognitiveServices.SpeechZastąp zawartość pliku Program.cs następującym kodem:
using System; using System.IO; using System.Threading.Tasks; using Microsoft.CognitiveServices.Speech; using Microsoft.CognitiveServices.Speech.Audio; class Program { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" static string speechKey = Environment.GetEnvironmentVariable("SPEECH_KEY"); static string speechRegion = Environment.GetEnvironmentVariable("SPEECH_REGION"); static void OutputSpeechRecognitionResult(SpeechRecognitionResult speechRecognitionResult) { switch (speechRecognitionResult.Reason) { case ResultReason.RecognizedSpeech: Console.WriteLine($"RECOGNIZED: Text={speechRecognitionResult.Text}"); break; case ResultReason.NoMatch: Console.WriteLine($"NOMATCH: Speech could not be recognized."); break; case ResultReason.Canceled: var cancellation = CancellationDetails.FromResult(speechRecognitionResult); Console.WriteLine($"CANCELED: Reason={cancellation.Reason}"); if (cancellation.Reason == CancellationReason.Error) { Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}"); Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}"); Console.WriteLine($"CANCELED: Did you set the speech resource key and region values?"); } break; } } async static Task Main(string[] args) { var speechConfig = SpeechConfig.FromSubscription(speechKey, speechRegion); speechConfig.SpeechRecognitionLanguage = "en-US"; using var audioConfig = AudioConfig.FromDefaultMicrophoneInput(); using var speechRecognizer = new SpeechRecognizer(speechConfig, audioConfig); Console.WriteLine("Speak into your microphone."); var speechRecognitionResult = await speechRecognizer.RecognizeOnceAsync(); OutputSpeechRecognitionResult(speechRecognitionResult); } }Aby zmienić język rozpoznawania mowy, zastąp
en-USelement innym obsługiwanym językiem. Na przykład użyj dlaes-ESjęzyka hiszpańskiego (Hiszpania). Jeśli nie określisz języka, wartość domyślna toen-US. Aby uzyskać szczegółowe informacje na temat identyfikowania jednego z wielu języków, które mogą być mówione, zobacz Identyfikacja języka.Uruchom nową aplikację konsolową, aby rozpocząć rozpoznawanie mowy z mikrofonu:
dotnet runWażne
Upewnij się, że ustawiono
SPEECH_KEYzmienne środowiskowe iSPEECH_REGION. Jeśli nie ustawisz tych zmiennych, przykład zakończy się niepowodzeniem z komunikatem o błędzie.Po wyświetleniu monitu porozmawiaj z mikrofonem. To, co mówisz, powinno być wyświetlane jako tekst:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
Uwagi
Oto kilka innych zagadnień:
W tym przykładzie użyto
RecognizeOnceAsyncoperacji do transkrypcji wypowiedzi do 30 sekund lub do momentu wykrycia ciszy. Aby uzyskać informacje na temat ciągłego rozpoznawania dłuższego dźwięku, w tym konwersacji wielojęzycznych, zobacz Jak rozpoznawać mowę.Aby rozpoznać mowę z pliku audio, użyj polecenia
FromWavFileInputzamiastFromDefaultMicrophoneInput:using var audioConfig = AudioConfig.FromWavFileInput("YourAudioFile.wav");W przypadku skompresowanych plików audio, takich jak MP4, zainstaluj GStreamer i użyj polecenia
PullAudioInputStreamlubPushAudioInputStream. Aby uzyskać więcej informacji, zobacz Jak używać skompresowanego dźwięku wejściowego.
Czyszczenie zasobów
Aby usunąć utworzony zasób usługi Mowa, możesz użyć witryny Azure Portal lub interfejsu wiersza polecenia platformy Azure.
Dokumentacja referencyjna Package (NuGet) | Dodatkowe przykłady w witrynie GitHub |
W tym przewodniku Szybki start utworzysz i uruchomisz aplikację w celu rozpoznawania i transkrypcji mowy na tekst w czasie rzeczywistym.
Aby zamiast tego transkrypcji plików audio asynchronicznie, zobacz Co to jest transkrypcja wsadowa. Jeśli nie masz pewności, które rozwiązanie zamiany mowy na tekst jest odpowiednie dla Ciebie, zobacz Co to jest zamiana mowy na tekst?
Wymagania wstępne
- Subskrypcja platformy Azure. Możesz utworzyć go bezpłatnie.
- Utwórz zasób usługi Mowa w witrynie Azure Portal.
- Pobierz klucz zasobu usługi Mowa i region. Po wdrożeniu zasobu usługi Mowa wybierz pozycję Przejdź do zasobu , aby wyświetlić klucze i zarządzać nimi.
Konfigurowanie środowiska
Zestaw SPEECH SDK jest dostępny jako pakiet NuGet i implementuje platformę .NET Standard 2.0. Zestaw SPEECH SDK zostanie zainstalowany w dalszej części tego przewodnika. Aby uzyskać inne wymagania, zobacz Instalowanie zestawu SPEECH SDK.
Ustawianie zmiennych środowiskowych
Aby uzyskać dostęp do usług Azure AI, musisz uwierzytelnić aplikację. W tym artykule pokazano, jak używać zmiennych środowiskowych do przechowywania poświadczeń. Następnie możesz uzyskać dostęp do zmiennych środowiskowych z kodu w celu uwierzytelnienia aplikacji. W przypadku środowiska produkcyjnego użyj bezpieczniejszego sposobu przechowywania poświadczeń i uzyskiwania do nich dostępu.
Ważne
Zalecamy uwierzytelnianie za pomocą identyfikatora Entra firmy Microsoft z tożsamościami zarządzanymi dla zasobów platformy Azure, aby uniknąć przechowywania poświadczeń przy użyciu aplikacji uruchamianych w chmurze.
Jeśli używasz klucza interfejsu API, zapisz go bezpiecznie w innym miejscu, na przykład w usłudze Azure Key Vault. Nie dołączaj klucza interfejsu API bezpośrednio do kodu i nigdy nie publikuj go publicznie.
Aby uzyskać więcej informacji na temat zabezpieczeń usług sztucznej inteligencji, zobacz Uwierzytelnianie żądań w usługach Azure AI.
Aby ustawić zmienne środowiskowe dla klucza i regionu zasobu usługi Mowa, otwórz okno konsoli i postępuj zgodnie z instrukcjami dotyczącymi systemu operacyjnego i środowiska programistycznego.
- Aby ustawić zmienną
SPEECH_KEYśrodowiskową, zastąp klucz jednym z kluczy zasobu. - Aby ustawić zmienną
SPEECH_REGIONśrodowiskową, zastąp region jednym z regionów zasobu.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Uwaga
Jeśli musisz uzyskać dostęp tylko do zmiennych środowiskowych w bieżącej konsoli, możesz ustawić zmienną środowiskową z wartością setsetxzamiast .
Po dodaniu zmiennych środowiskowych może być konieczne ponowne uruchomienie wszystkich programów, które muszą odczytać zmienne środowiskowe, w tym okno konsoli. Jeśli na przykład używasz programu Visual Studio jako edytora, uruchom ponownie program Visual Studio przed uruchomieniem przykładu.
Rozpoznawanie mowy przy użyciu mikrofonu
Napiwek
Wypróbuj zestaw narzędzi Azure AI Speech Toolkit , aby łatwo kompilować i uruchamiać przykłady w programie Visual Studio Code.
Wykonaj następujące kroki, aby utworzyć aplikację konsolową i zainstalować zestaw SPEECH SDK.
Utwórz nowy projekt konsoli języka C++ w programie Visual Studio Community o nazwie
SpeechRecognition.Wybierz pozycję Narzędzia Nuget>Menedżer pakietów> Menedżer pakietów Konsola. W konsoli Menedżer pakietów uruchom następujące polecenie:
Install-Package Microsoft.CognitiveServices.SpeechZastąp zawartość
SpeechRecognition.cppnastępującym kodem:#include <iostream> #include <stdlib.h> #include <speechapi_cxx.h> using namespace Microsoft::CognitiveServices::Speech; using namespace Microsoft::CognitiveServices::Speech::Audio; std::string GetEnvironmentVariable(const char* name); int main() { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" auto speechKey = GetEnvironmentVariable("SPEECH_KEY"); auto speechRegion = GetEnvironmentVariable("SPEECH_REGION"); if ((size(speechKey) == 0) || (size(speechRegion) == 0)) { std::cout << "Please set both SPEECH_KEY and SPEECH_REGION environment variables." << std::endl; return -1; } auto speechConfig = SpeechConfig::FromSubscription(speechKey, speechRegion); speechConfig->SetSpeechRecognitionLanguage("en-US"); auto audioConfig = AudioConfig::FromDefaultMicrophoneInput(); auto speechRecognizer = SpeechRecognizer::FromConfig(speechConfig, audioConfig); std::cout << "Speak into your microphone.\n"; auto result = speechRecognizer->RecognizeOnceAsync().get(); if (result->Reason == ResultReason::RecognizedSpeech) { std::cout << "RECOGNIZED: Text=" << result->Text << std::endl; } else if (result->Reason == ResultReason::NoMatch) { std::cout << "NOMATCH: Speech could not be recognized." << std::endl; } else if (result->Reason == ResultReason::Canceled) { auto cancellation = CancellationDetails::FromResult(result); std::cout << "CANCELED: Reason=" << (int)cancellation->Reason << std::endl; if (cancellation->Reason == CancellationReason::Error) { std::cout << "CANCELED: ErrorCode=" << (int)cancellation->ErrorCode << std::endl; std::cout << "CANCELED: ErrorDetails=" << cancellation->ErrorDetails << std::endl; std::cout << "CANCELED: Did you set the speech resource key and region values?" << std::endl; } } } std::string GetEnvironmentVariable(const char* name) { #if defined(_MSC_VER) size_t requiredSize = 0; (void)getenv_s(&requiredSize, nullptr, 0, name); if (requiredSize == 0) { return ""; } auto buffer = std::make_unique<char[]>(requiredSize); (void)getenv_s(&requiredSize, buffer.get(), requiredSize, name); return buffer.get(); #else auto value = getenv(name); return value ? value : ""; #endif }Aby zmienić język rozpoznawania mowy, zastąp
en-USelement innym obsługiwanym językiem. Na przykład użyj dlaes-ESjęzyka hiszpańskiego (Hiszpania). Jeśli nie określisz języka, wartość domyślna toen-US. Aby uzyskać szczegółowe informacje na temat identyfikowania jednego z wielu języków, które mogą być mówione, zobacz Identyfikacja języka.Skompiluj i uruchom nową aplikację konsolową, aby rozpocząć rozpoznawanie mowy z mikrofonu.
Ważne
Upewnij się, że ustawiono
SPEECH_KEYzmienne środowiskowe iSPEECH_REGION. Jeśli nie ustawisz tych zmiennych, przykład zakończy się niepowodzeniem z komunikatem o błędzie.Po wyświetleniu monitu porozmawiaj z mikrofonem. To, co mówisz, powinno być wyświetlane jako tekst:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
Uwagi
Oto kilka innych zagadnień:
W tym przykładzie użyto
RecognizeOnceAsyncoperacji do transkrypcji wypowiedzi do 30 sekund lub do momentu wykrycia ciszy. Aby uzyskać informacje na temat ciągłego rozpoznawania dłuższego dźwięku, w tym konwersacji wielojęzycznych, zobacz Jak rozpoznawać mowę.Aby rozpoznać mowę z pliku audio, użyj polecenia
FromWavFileInputzamiastFromDefaultMicrophoneInput:auto audioConfig = AudioConfig::FromWavFileInput("YourAudioFile.wav");W przypadku skompresowanych plików audio, takich jak MP4, zainstaluj GStreamer i użyj polecenia
PullAudioInputStreamlubPushAudioInputStream. Aby uzyskać więcej informacji, zobacz Jak używać skompresowanego dźwięku wejściowego.
Czyszczenie zasobów
Aby usunąć utworzony zasób usługi Mowa, możesz użyć witryny Azure Portal lub interfejsu wiersza polecenia platformy Azure.
Dokumentacja referencyjna Package (Go) | Dodatkowe przykłady w witrynie GitHub |
W tym przewodniku Szybki start utworzysz i uruchomisz aplikację w celu rozpoznawania i transkrypcji mowy na tekst w czasie rzeczywistym.
Aby zamiast tego transkrypcji plików audio asynchronicznie, zobacz Co to jest transkrypcja wsadowa. Jeśli nie masz pewności, które rozwiązanie zamiany mowy na tekst jest odpowiednie dla Ciebie, zobacz Co to jest zamiana mowy na tekst?
Wymagania wstępne
- Subskrypcja platformy Azure. Możesz utworzyć go bezpłatnie.
- Utwórz zasób usługi Mowa w witrynie Azure Portal.
- Pobierz klucz zasobu usługi Mowa i region. Po wdrożeniu zasobu usługi Mowa wybierz pozycję Przejdź do zasobu , aby wyświetlić klucze i zarządzać nimi.
Konfigurowanie środowiska
Zainstaluj zestaw SPEECH SDK dla języka Go. Aby uzyskać wymagania i instrukcje, zobacz Instalowanie zestawu SPEECH SDK.
Ustawianie zmiennych środowiskowych
Aby uzyskać dostęp do usług Azure AI, musisz uwierzytelnić aplikację. W tym artykule pokazano, jak używać zmiennych środowiskowych do przechowywania poświadczeń. Następnie możesz uzyskać dostęp do zmiennych środowiskowych z kodu w celu uwierzytelnienia aplikacji. W przypadku środowiska produkcyjnego użyj bezpieczniejszego sposobu przechowywania poświadczeń i uzyskiwania do nich dostępu.
Ważne
Zalecamy uwierzytelnianie za pomocą identyfikatora Entra firmy Microsoft z tożsamościami zarządzanymi dla zasobów platformy Azure, aby uniknąć przechowywania poświadczeń przy użyciu aplikacji uruchamianych w chmurze.
Jeśli używasz klucza interfejsu API, zapisz go bezpiecznie w innym miejscu, na przykład w usłudze Azure Key Vault. Nie dołączaj klucza interfejsu API bezpośrednio do kodu i nigdy nie publikuj go publicznie.
Aby uzyskać więcej informacji na temat zabezpieczeń usług sztucznej inteligencji, zobacz Uwierzytelnianie żądań w usługach Azure AI.
Aby ustawić zmienne środowiskowe dla klucza i regionu zasobu usługi Mowa, otwórz okno konsoli i postępuj zgodnie z instrukcjami dotyczącymi systemu operacyjnego i środowiska programistycznego.
- Aby ustawić zmienną
SPEECH_KEYśrodowiskową, zastąp klucz jednym z kluczy zasobu. - Aby ustawić zmienną
SPEECH_REGIONśrodowiskową, zastąp region jednym z regionów zasobu.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Uwaga
Jeśli musisz uzyskać dostęp tylko do zmiennych środowiskowych w bieżącej konsoli, możesz ustawić zmienną środowiskową z wartością setsetxzamiast .
Po dodaniu zmiennych środowiskowych może być konieczne ponowne uruchomienie wszystkich programów, które muszą odczytać zmienne środowiskowe, w tym okno konsoli. Jeśli na przykład używasz programu Visual Studio jako edytora, uruchom ponownie program Visual Studio przed uruchomieniem przykładu.
Rozpoznawanie mowy przy użyciu mikrofonu
Wykonaj następujące kroki, aby utworzyć moduł GO.
Otwórz okno wiersza polecenia w folderze, w którym chcesz utworzyć nowy projekt. Utwórz nowy plik o nazwie speech-recognition.go.
Skopiuj następujący kod do funkcji rozpoznawania mowy.go:
package main import ( "bufio" "fmt" "os" "github.com/Microsoft/cognitive-services-speech-sdk-go/audio" "github.com/Microsoft/cognitive-services-speech-sdk-go/speech" ) func sessionStartedHandler(event speech.SessionEventArgs) { defer event.Close() fmt.Println("Session Started (ID=", event.SessionID, ")") } func sessionStoppedHandler(event speech.SessionEventArgs) { defer event.Close() fmt.Println("Session Stopped (ID=", event.SessionID, ")") } func recognizingHandler(event speech.SpeechRecognitionEventArgs) { defer event.Close() fmt.Println("Recognizing:", event.Result.Text) } func recognizedHandler(event speech.SpeechRecognitionEventArgs) { defer event.Close() fmt.Println("Recognized:", event.Result.Text) } func cancelledHandler(event speech.SpeechRecognitionCanceledEventArgs) { defer event.Close() fmt.Println("Received a cancellation: ", event.ErrorDetails) fmt.Println("Did you set the speech resource key and region values?") } func main() { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" speechKey := os.Getenv("SPEECH_KEY") speechRegion := os.Getenv("SPEECH_REGION") audioConfig, err := audio.NewAudioConfigFromDefaultMicrophoneInput() if err != nil { fmt.Println("Got an error: ", err) return } defer audioConfig.Close() speechConfig, err := speech.NewSpeechConfigFromSubscription(speechKey, speechRegion) if err != nil { fmt.Println("Got an error: ", err) return } defer speechConfig.Close() speechRecognizer, err := speech.NewSpeechRecognizerFromConfig(speechConfig, audioConfig) if err != nil { fmt.Println("Got an error: ", err) return } defer speechRecognizer.Close() speechRecognizer.SessionStarted(sessionStartedHandler) speechRecognizer.SessionStopped(sessionStoppedHandler) speechRecognizer.Recognizing(recognizingHandler) speechRecognizer.Recognized(recognizedHandler) speechRecognizer.Canceled(cancelledHandler) speechRecognizer.StartContinuousRecognitionAsync() defer speechRecognizer.StopContinuousRecognitionAsync() bufio.NewReader(os.Stdin).ReadBytes('\n') }Uruchom następujące polecenia, aby utworzyć plik go.mod , który łączy się ze składnikami hostowanymi w usłudze GitHub:
go mod init speech-recognition go get github.com/Microsoft/cognitive-services-speech-sdk-goWażne
Upewnij się, że ustawiono
SPEECH_KEYzmienne środowiskowe iSPEECH_REGION. Jeśli nie ustawisz tych zmiennych, przykład zakończy się niepowodzeniem z komunikatem o błędzie.Skompiluj i uruchom kod:
go build go run speech-recognition
Czyszczenie zasobów
Aby usunąć utworzony zasób usługi Mowa, możesz użyć witryny Azure Portal lub interfejsu wiersza polecenia platformy Azure.
| Dokumentacja referencyjna Dodatkowe przykłady w usłudze GitHub
W tym przewodniku Szybki start utworzysz i uruchomisz aplikację w celu rozpoznawania i transkrypcji mowy na tekst w czasie rzeczywistym.
Aby zamiast tego transkrypcji plików audio asynchronicznie, zobacz Co to jest transkrypcja wsadowa. Jeśli nie masz pewności, które rozwiązanie zamiany mowy na tekst jest odpowiednie dla Ciebie, zobacz Co to jest zamiana mowy na tekst?
Wymagania wstępne
- Subskrypcja platformy Azure. Możesz utworzyć go bezpłatnie.
- Utwórz zasób usługi Mowa w witrynie Azure Portal.
- Pobierz klucz zasobu usługi Mowa i region. Po wdrożeniu zasobu usługi Mowa wybierz pozycję Przejdź do zasobu , aby wyświetlić klucze i zarządzać nimi.
Konfigurowanie środowiska
Aby skonfigurować środowisko, zainstaluj zestaw SPEECH SDK. Przykład w tym przewodniku Szybki start współpracuje ze środowiskiem uruchomieniowym Języka Java.
Zainstaluj narzędzie Apache Maven. Następnie uruchom polecenie
mvn -v, aby potwierdzić pomyślną instalację.Utwórz nowy
pom.xmlplik w katalogu głównym projektu i skopiuj do niego następujący kod:<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.microsoft.cognitiveservices.speech.samples</groupId> <artifactId>quickstart-eclipse</artifactId> <version>1.0.0-SNAPSHOT</version> <build> <sourceDirectory>src</sourceDirectory> <plugins> <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>3.7.0</version> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> </plugins> </build> <dependencies> <dependency> <groupId>com.microsoft.cognitiveservices.speech</groupId> <artifactId>client-sdk</artifactId> <version>1.42.0</version> </dependency> </dependencies> </project>Zainstaluj zestaw SPEECH SDK i zależności.
mvn clean dependency:copy-dependencies
Ustawianie zmiennych środowiskowych
Aby uzyskać dostęp do usług Azure AI, musisz uwierzytelnić aplikację. W tym artykule pokazano, jak używać zmiennych środowiskowych do przechowywania poświadczeń. Następnie możesz uzyskać dostęp do zmiennych środowiskowych z kodu w celu uwierzytelnienia aplikacji. W przypadku środowiska produkcyjnego użyj bezpieczniejszego sposobu przechowywania poświadczeń i uzyskiwania do nich dostępu.
Ważne
Zalecamy uwierzytelnianie za pomocą identyfikatora Entra firmy Microsoft z tożsamościami zarządzanymi dla zasobów platformy Azure, aby uniknąć przechowywania poświadczeń przy użyciu aplikacji uruchamianych w chmurze.
Jeśli używasz klucza interfejsu API, zapisz go bezpiecznie w innym miejscu, na przykład w usłudze Azure Key Vault. Nie dołączaj klucza interfejsu API bezpośrednio do kodu i nigdy nie publikuj go publicznie.
Aby uzyskać więcej informacji na temat zabezpieczeń usług sztucznej inteligencji, zobacz Uwierzytelnianie żądań w usługach Azure AI.
Aby ustawić zmienne środowiskowe dla klucza i regionu zasobu usługi Mowa, otwórz okno konsoli i postępuj zgodnie z instrukcjami dotyczącymi systemu operacyjnego i środowiska programistycznego.
- Aby ustawić zmienną
SPEECH_KEYśrodowiskową, zastąp klucz jednym z kluczy zasobu. - Aby ustawić zmienną
SPEECH_REGIONśrodowiskową, zastąp region jednym z regionów zasobu.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Uwaga
Jeśli musisz uzyskać dostęp tylko do zmiennych środowiskowych w bieżącej konsoli, możesz ustawić zmienną środowiskową z wartością setsetxzamiast .
Po dodaniu zmiennych środowiskowych może być konieczne ponowne uruchomienie wszystkich programów, które muszą odczytać zmienne środowiskowe, w tym okno konsoli. Jeśli na przykład używasz programu Visual Studio jako edytora, uruchom ponownie program Visual Studio przed uruchomieniem przykładu.
Rozpoznawanie mowy przy użyciu mikrofonu
Wykonaj następujące kroki, aby utworzyć aplikację konsolową do rozpoznawania mowy.
Utwórz nowy plik o nazwie SpeechRecognition.java w tym samym katalogu głównym projektu.
Skopiuj następujący kod do SpeechRecognition.java:
import com.microsoft.cognitiveservices.speech.*; import com.microsoft.cognitiveservices.speech.audio.AudioConfig; import java.util.concurrent.ExecutionException; import java.util.concurrent.Future; public class SpeechRecognition { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" private static String speechKey = System.getenv("SPEECH_KEY"); private static String speechRegion = System.getenv("SPEECH_REGION"); public static void main(String[] args) throws InterruptedException, ExecutionException { SpeechConfig speechConfig = SpeechConfig.fromSubscription(speechKey, speechRegion); speechConfig.setSpeechRecognitionLanguage("en-US"); recognizeFromMicrophone(speechConfig); } public static void recognizeFromMicrophone(SpeechConfig speechConfig) throws InterruptedException, ExecutionException { AudioConfig audioConfig = AudioConfig.fromDefaultMicrophoneInput(); SpeechRecognizer speechRecognizer = new SpeechRecognizer(speechConfig, audioConfig); System.out.println("Speak into your microphone."); Future<SpeechRecognitionResult> task = speechRecognizer.recognizeOnceAsync(); SpeechRecognitionResult speechRecognitionResult = task.get(); if (speechRecognitionResult.getReason() == ResultReason.RecognizedSpeech) { System.out.println("RECOGNIZED: Text=" + speechRecognitionResult.getText()); } else if (speechRecognitionResult.getReason() == ResultReason.NoMatch) { System.out.println("NOMATCH: Speech could not be recognized."); } else if (speechRecognitionResult.getReason() == ResultReason.Canceled) { CancellationDetails cancellation = CancellationDetails.fromResult(speechRecognitionResult); System.out.println("CANCELED: Reason=" + cancellation.getReason()); if (cancellation.getReason() == CancellationReason.Error) { System.out.println("CANCELED: ErrorCode=" + cancellation.getErrorCode()); System.out.println("CANCELED: ErrorDetails=" + cancellation.getErrorDetails()); System.out.println("CANCELED: Did you set the speech resource key and region values?"); } } System.exit(0); } }Aby zmienić język rozpoznawania mowy, zastąp
en-USelement innym obsługiwanym językiem. Na przykład użyj dlaes-ESjęzyka hiszpańskiego (Hiszpania). Jeśli nie określisz języka, wartość domyślna toen-US. Aby uzyskać szczegółowe informacje na temat identyfikowania jednego z wielu języków, które mogą być mówione, zobacz Identyfikacja języka.Uruchom nową aplikację konsolową, aby rozpocząć rozpoznawanie mowy z mikrofonu:
javac SpeechRecognition.java -cp ".;target\dependency\*" java -cp ".;target\dependency\*" SpeechRecognitionWażne
Upewnij się, że ustawiono
SPEECH_KEYzmienne środowiskowe iSPEECH_REGION. Jeśli nie ustawisz tych zmiennych, przykład zakończy się niepowodzeniem z komunikatem o błędzie.Po wyświetleniu monitu porozmawiaj z mikrofonem. To, co mówisz, powinno być wyświetlane jako tekst:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
Uwagi
Oto kilka innych zagadnień:
W tym przykładzie użyto
RecognizeOnceAsyncoperacji do transkrypcji wypowiedzi do 30 sekund lub do momentu wykrycia ciszy. Aby uzyskać informacje na temat ciągłego rozpoznawania dłuższego dźwięku, w tym konwersacji wielojęzycznych, zobacz Jak rozpoznawać mowę.Aby rozpoznać mowę z pliku audio, użyj polecenia
fromWavFileInputzamiastfromDefaultMicrophoneInput:AudioConfig audioConfig = AudioConfig.fromWavFileInput("YourAudioFile.wav");W przypadku skompresowanych plików audio, takich jak MP4, zainstaluj GStreamer i użyj polecenia
PullAudioInputStreamlubPushAudioInputStream. Aby uzyskać więcej informacji, zobacz Jak używać skompresowanego dźwięku wejściowego.
Czyszczenie zasobów
Aby usunąć utworzony zasób usługi Mowa, możesz użyć witryny Azure Portal lub interfejsu wiersza polecenia platformy Azure.
Dokumentacja referencyjna | Package (npm) | Dodatkowe przykłady w kodzie źródłowym biblioteki GitHub |
W tym przewodniku Szybki start utworzysz i uruchomisz aplikację w celu rozpoznawania i transkrypcji mowy na tekst w czasie rzeczywistym.
Aby zamiast tego transkrypcji plików audio asynchronicznie, zobacz Co to jest transkrypcja wsadowa. Jeśli nie masz pewności, które rozwiązanie zamiany mowy na tekst jest odpowiednie dla Ciebie, zobacz Co to jest zamiana mowy na tekst?
Wymagania wstępne
- Subskrypcja platformy Azure. Możesz utworzyć go bezpłatnie.
- Utwórz zasób usługi Mowa w witrynie Azure Portal.
- Pobierz klucz zasobu usługi Mowa i region. Po wdrożeniu zasobu usługi Mowa wybierz pozycję Przejdź do zasobu , aby wyświetlić klucze i zarządzać nimi.
Potrzebny jest również plik audio .wav na komputerze lokalnym. Możesz użyć własnego pliku .wav (do 30 sekund) lub pobrać https://crbn.us/whatstheweatherlike.wav przykładowy plik.
Konfigurowanie środowiska
Aby skonfigurować środowisko, zainstaluj zestaw SPEECH SDK dla języka JavaScript. Uruchom następujące polecenie: npm install microsoft-cognitiveservices-speech-sdk. Aby uzyskać instrukcje instalacji z przewodnikiem, zobacz Instalowanie zestawu SPEECH SDK.
Ustawianie zmiennych środowiskowych
Aby uzyskać dostęp do usług Azure AI, musisz uwierzytelnić aplikację. W tym artykule pokazano, jak używać zmiennych środowiskowych do przechowywania poświadczeń. Następnie możesz uzyskać dostęp do zmiennych środowiskowych z kodu w celu uwierzytelnienia aplikacji. W przypadku środowiska produkcyjnego użyj bezpieczniejszego sposobu przechowywania poświadczeń i uzyskiwania do nich dostępu.
Ważne
Zalecamy uwierzytelnianie za pomocą identyfikatora Entra firmy Microsoft z tożsamościami zarządzanymi dla zasobów platformy Azure, aby uniknąć przechowywania poświadczeń przy użyciu aplikacji uruchamianych w chmurze.
Jeśli używasz klucza interfejsu API, zapisz go bezpiecznie w innym miejscu, na przykład w usłudze Azure Key Vault. Nie dołączaj klucza interfejsu API bezpośrednio do kodu i nigdy nie publikuj go publicznie.
Aby uzyskać więcej informacji na temat zabezpieczeń usług sztucznej inteligencji, zobacz Uwierzytelnianie żądań w usługach Azure AI.
Aby ustawić zmienne środowiskowe dla klucza i regionu zasobu usługi Mowa, otwórz okno konsoli i postępuj zgodnie z instrukcjami dotyczącymi systemu operacyjnego i środowiska programistycznego.
- Aby ustawić zmienną
SPEECH_KEYśrodowiskową, zastąp klucz jednym z kluczy zasobu. - Aby ustawić zmienną
SPEECH_REGIONśrodowiskową, zastąp region jednym z regionów zasobu.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Uwaga
Jeśli musisz uzyskać dostęp tylko do zmiennych środowiskowych w bieżącej konsoli, możesz ustawić zmienną środowiskową z wartością setsetxzamiast .
Po dodaniu zmiennych środowiskowych może być konieczne ponowne uruchomienie wszystkich programów, które muszą odczytać zmienne środowiskowe, w tym okno konsoli. Jeśli na przykład używasz programu Visual Studio jako edytora, uruchom ponownie program Visual Studio przed uruchomieniem przykładu.
Rozpoznawanie mowy z pliku
Napiwek
Wypróbuj zestaw narzędzi Azure AI Speech Toolkit , aby łatwo kompilować i uruchamiać przykłady w programie Visual Studio Code.
Wykonaj następujące kroki, aby utworzyć aplikację konsolową Node.js na potrzeby rozpoznawania mowy.
Otwórz okno wiersza polecenia, w którym chcesz utworzyć nowy projekt, i utwórz nowy plik o nazwie SpeechRecognition.js.
Zainstaluj zestaw SPEECH SDK dla języka JavaScript:
npm install microsoft-cognitiveservices-speech-sdkSkopiuj następujący kod do SpeechRecognition.js:
const fs = require("fs"); const sdk = require("microsoft-cognitiveservices-speech-sdk"); // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" const speechConfig = sdk.SpeechConfig.fromSubscription(process.env.SPEECH_KEY, process.env.SPEECH_REGION); speechConfig.speechRecognitionLanguage = "en-US"; function fromFile() { let audioConfig = sdk.AudioConfig.fromWavFileInput(fs.readFileSync("YourAudioFile.wav")); let speechRecognizer = new sdk.SpeechRecognizer(speechConfig, audioConfig); speechRecognizer.recognizeOnceAsync(result => { switch (result.reason) { case sdk.ResultReason.RecognizedSpeech: console.log(`RECOGNIZED: Text=${result.text}`); break; case sdk.ResultReason.NoMatch: console.log("NOMATCH: Speech could not be recognized."); break; case sdk.ResultReason.Canceled: const cancellation = sdk.CancellationDetails.fromResult(result); console.log(`CANCELED: Reason=${cancellation.reason}`); if (cancellation.reason == sdk.CancellationReason.Error) { console.log(`CANCELED: ErrorCode=${cancellation.ErrorCode}`); console.log(`CANCELED: ErrorDetails=${cancellation.errorDetails}`); console.log("CANCELED: Did you set the speech resource key and region values?"); } break; } speechRecognizer.close(); }); } fromFile();W SpeechRecognition.js zastąp YourAudioFile.wav własnym plikiem .wav. Ten przykład rozpoznaje tylko mowę z pliku .wav . Aby uzyskać informacje o innych formatach dźwięku, zobacz How to use compressed input audio (Jak używać skompresowanego dźwięku wejściowego). Ten przykład obsługuje maksymalnie 30 sekund dźwięku.
Aby zmienić język rozpoznawania mowy, zastąp
en-USelement innym obsługiwanym językiem. Na przykład użyj dlaes-ESjęzyka hiszpańskiego (Hiszpania). Jeśli nie określisz języka, wartość domyślna toen-US. Aby uzyskać szczegółowe informacje na temat identyfikowania jednego z wielu języków, które mogą być mówione, zobacz Identyfikacja języka.Uruchom nową aplikację konsolową, aby rozpocząć rozpoznawanie mowy z pliku:
node.exe SpeechRecognition.jsWażne
Upewnij się, że ustawiono
SPEECH_KEYzmienne środowiskowe iSPEECH_REGION. Jeśli nie ustawisz tych zmiennych, przykład zakończy się niepowodzeniem z komunikatem o błędzie.Mowa z pliku audio powinna być wyjściowa jako tekst:
RECOGNIZED: Text=I'm excited to try speech to text.
Uwagi
W tym przykładzie użyto recognizeOnceAsync operacji do transkrypcji wypowiedzi do 30 sekund lub do momentu wykrycia ciszy. Aby uzyskać informacje na temat ciągłego rozpoznawania dłuższego dźwięku, w tym konwersacji wielojęzycznych, zobacz Jak rozpoznawać mowę.
Uwaga
Rozpoznawanie mowy z mikrofonu nie jest obsługiwane w Node.js. Jest on obsługiwany tylko w środowisku JavaScript opartym na przeglądarce. Aby uzyskać więcej informacji, zobacz przykład React i implementację mowy na tekst z mikrofonu w usłudze GitHub.
Przykład platformy React przedstawia wzorce projektowe dotyczące wymiany tokenów uwierzytelniania i zarządzania nimi. Przedstawia również przechwytywanie dźwięku z mikrofonu lub pliku do konwersji mowy na tekst.
Czyszczenie zasobów
Aby usunąć utworzony zasób usługi Mowa, możesz użyć witryny Azure Portal lub interfejsu wiersza polecenia platformy Azure.
Dokumentacja referencyjna | Package (PyPi) | Dodatkowe przykłady w witrynie GitHub
W tym przewodniku Szybki start utworzysz i uruchomisz aplikację w celu rozpoznawania i transkrypcji mowy na tekst w czasie rzeczywistym.
Aby zamiast tego transkrypcji plików audio asynchronicznie, zobacz Co to jest transkrypcja wsadowa. Jeśli nie masz pewności, które rozwiązanie zamiany mowy na tekst jest odpowiednie dla Ciebie, zobacz Co to jest zamiana mowy na tekst?
Wymagania wstępne
- Subskrypcja platformy Azure. Możesz utworzyć go bezpłatnie.
- Utwórz zasób usługi Mowa w witrynie Azure Portal.
- Pobierz klucz zasobu usługi Mowa i region. Po wdrożeniu zasobu usługi Mowa wybierz pozycję Przejdź do zasobu , aby wyświetlić klucze i zarządzać nimi.
Konfigurowanie środowiska
Zestaw SPEECH SDK dla języka Python jest dostępny jako moduł PyPI (Python Package Index). Zestaw SPEECH SDK dla języka Python jest zgodny z systemami Windows, Linux i macOS.
- W przypadku systemu Windows zainstaluj platformę Microsoft Pakiet redystrybucyjny Visual C++ dla Visual Studio 2015, 2017, 2019 i 2022. Zainstalowanie tego pakietu po raz pierwszy może wymagać ponownego uruchomienia.
- W systemie Linux należy użyć architektury docelowej x64.
Zainstaluj wersję języka Python z wersji 3.7 lub nowszej. Aby uzyskać inne wymagania, zobacz Instalowanie zestawu SPEECH SDK.
Ustawianie zmiennych środowiskowych
Aby uzyskać dostęp do usług Azure AI, musisz uwierzytelnić aplikację. W tym artykule pokazano, jak używać zmiennych środowiskowych do przechowywania poświadczeń. Następnie możesz uzyskać dostęp do zmiennych środowiskowych z kodu w celu uwierzytelnienia aplikacji. W przypadku środowiska produkcyjnego użyj bezpieczniejszego sposobu przechowywania poświadczeń i uzyskiwania do nich dostępu.
Ważne
Zalecamy uwierzytelnianie za pomocą identyfikatora Entra firmy Microsoft z tożsamościami zarządzanymi dla zasobów platformy Azure, aby uniknąć przechowywania poświadczeń przy użyciu aplikacji uruchamianych w chmurze.
Jeśli używasz klucza interfejsu API, zapisz go bezpiecznie w innym miejscu, na przykład w usłudze Azure Key Vault. Nie dołączaj klucza interfejsu API bezpośrednio do kodu i nigdy nie publikuj go publicznie.
Aby uzyskać więcej informacji na temat zabezpieczeń usług sztucznej inteligencji, zobacz Uwierzytelnianie żądań w usługach Azure AI.
Aby ustawić zmienne środowiskowe dla klucza i regionu zasobu usługi Mowa, otwórz okno konsoli i postępuj zgodnie z instrukcjami dotyczącymi systemu operacyjnego i środowiska programistycznego.
- Aby ustawić zmienną
SPEECH_KEYśrodowiskową, zastąp klucz jednym z kluczy zasobu. - Aby ustawić zmienną
SPEECH_REGIONśrodowiskową, zastąp region jednym z regionów zasobu.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Uwaga
Jeśli musisz uzyskać dostęp tylko do zmiennych środowiskowych w bieżącej konsoli, możesz ustawić zmienną środowiskową z wartością setsetxzamiast .
Po dodaniu zmiennych środowiskowych może być konieczne ponowne uruchomienie wszystkich programów, które muszą odczytać zmienne środowiskowe, w tym okno konsoli. Jeśli na przykład używasz programu Visual Studio jako edytora, uruchom ponownie program Visual Studio przed uruchomieniem przykładu.
Rozpoznawanie mowy przy użyciu mikrofonu
Napiwek
Wypróbuj zestaw narzędzi Azure AI Speech Toolkit , aby łatwo kompilować i uruchamiać przykłady w programie Visual Studio Code.
Wykonaj następujące kroki, aby utworzyć aplikację konsolową.
Otwórz okno wiersza polecenia w folderze, w którym chcesz utworzyć nowy projekt. Utwórz nowy plik o nazwie speech_recognition.py.
Uruchom to polecenie, aby zainstalować zestaw SPEECH SDK:
pip install azure-cognitiveservices-speechSkopiuj następujący kod do speech_recognition.py:
import os import azure.cognitiveservices.speech as speechsdk def recognize_from_microphone(): # This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" speech_config = speechsdk.SpeechConfig(subscription=os.environ.get('SPEECH_KEY'), region=os.environ.get('SPEECH_REGION')) speech_config.speech_recognition_language="en-US" audio_config = speechsdk.audio.AudioConfig(use_default_microphone=True) speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_config) print("Speak into your microphone.") speech_recognition_result = speech_recognizer.recognize_once_async().get() if speech_recognition_result.reason == speechsdk.ResultReason.RecognizedSpeech: print("Recognized: {}".format(speech_recognition_result.text)) elif speech_recognition_result.reason == speechsdk.ResultReason.NoMatch: print("No speech could be recognized: {}".format(speech_recognition_result.no_match_details)) elif speech_recognition_result.reason == speechsdk.ResultReason.Canceled: cancellation_details = speech_recognition_result.cancellation_details print("Speech Recognition canceled: {}".format(cancellation_details.reason)) if cancellation_details.reason == speechsdk.CancellationReason.Error: print("Error details: {}".format(cancellation_details.error_details)) print("Did you set the speech resource key and region values?") recognize_from_microphone()Aby zmienić język rozpoznawania mowy, zastąp
en-USelement innym obsługiwanym językiem. Na przykład użyj dlaes-ESjęzyka hiszpańskiego (Hiszpania). Jeśli nie określisz języka, wartość domyślna toen-US. Aby uzyskać szczegółowe informacje na temat identyfikowania jednego z wielu języków, które mogą być mówione, zobacz identyfikacja języka.Uruchom nową aplikację konsolową, aby rozpocząć rozpoznawanie mowy z mikrofonu:
python speech_recognition.pyWażne
Upewnij się, że ustawiono
SPEECH_KEYzmienne środowiskowe iSPEECH_REGION. Jeśli nie ustawisz tych zmiennych, przykład zakończy się niepowodzeniem z komunikatem o błędzie.Po wyświetleniu monitu porozmawiaj z mikrofonem. To, co mówisz, powinno być wyświetlane jako tekst:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
Uwagi
Oto kilka innych zagadnień:
W tym przykładzie użyto
recognize_once_asyncoperacji do transkrypcji wypowiedzi do 30 sekund lub do momentu wykrycia ciszy. Aby uzyskać informacje na temat ciągłego rozpoznawania dłuższego dźwięku, w tym konwersacji wielojęzycznych, zobacz Jak rozpoznawać mowę.Aby rozpoznać mowę z pliku audio, użyj polecenia
filenamezamiastuse_default_microphone:audio_config = speechsdk.audio.AudioConfig(filename="YourAudioFile.wav")W przypadku skompresowanych plików audio, takich jak MP4, zainstaluj GStreamer i użyj polecenia
PullAudioInputStreamlubPushAudioInputStream. Aby uzyskać więcej informacji, zobacz Jak używać skompresowanego dźwięku wejściowego.
Czyszczenie zasobów
Aby usunąć utworzony zasób usługi Mowa, możesz użyć witryny Azure Portal lub interfejsu wiersza polecenia platformy Azure.
Dokumentacja referencyjna Package (download) | Dodatkowe przykłady w usłudze GitHub |
W tym przewodniku Szybki start utworzysz i uruchomisz aplikację w celu rozpoznawania i transkrypcji mowy na tekst w czasie rzeczywistym.
Aby zamiast tego transkrypcji plików audio asynchronicznie, zobacz Co to jest transkrypcja wsadowa. Jeśli nie masz pewności, które rozwiązanie zamiany mowy na tekst jest odpowiednie dla Ciebie, zobacz Co to jest zamiana mowy na tekst?
Wymagania wstępne
- Subskrypcja platformy Azure. Możesz utworzyć go bezpłatnie.
- Utwórz zasób usługi Mowa w witrynie Azure Portal.
- Pobierz klucz zasobu usługi Mowa i region. Po wdrożeniu zasobu usługi Mowa wybierz pozycję Przejdź do zasobu , aby wyświetlić klucze i zarządzać nimi.
Konfigurowanie środowiska
Zestaw SPEECH SDK dla języka Swift jest dystrybuowany jako pakiet platformy. Platforma obsługuje język Objective-C i Swift zarówno w systemach iOS, jak i macOS.
Zestaw SPEECH SDK może być używany w projektach Xcode jako cocoaPod lub pobierany bezpośrednio i połączony ręcznie. W tym przewodniku jest używany program CocoaPod. Zainstaluj menedżera zależności CocoaPod zgodnie z opisem w instrukcjach instalacji.
Ustawianie zmiennych środowiskowych
Aby uzyskać dostęp do usług Azure AI, musisz uwierzytelnić aplikację. W tym artykule pokazano, jak używać zmiennych środowiskowych do przechowywania poświadczeń. Następnie możesz uzyskać dostęp do zmiennych środowiskowych z kodu w celu uwierzytelnienia aplikacji. W przypadku środowiska produkcyjnego użyj bezpieczniejszego sposobu przechowywania poświadczeń i uzyskiwania do nich dostępu.
Ważne
Zalecamy uwierzytelnianie za pomocą identyfikatora Entra firmy Microsoft z tożsamościami zarządzanymi dla zasobów platformy Azure, aby uniknąć przechowywania poświadczeń przy użyciu aplikacji uruchamianych w chmurze.
Jeśli używasz klucza interfejsu API, zapisz go bezpiecznie w innym miejscu, na przykład w usłudze Azure Key Vault. Nie dołączaj klucza interfejsu API bezpośrednio do kodu i nigdy nie publikuj go publicznie.
Aby uzyskać więcej informacji na temat zabezpieczeń usług sztucznej inteligencji, zobacz Uwierzytelnianie żądań w usługach Azure AI.
Aby ustawić zmienne środowiskowe dla klucza i regionu zasobu usługi Mowa, otwórz okno konsoli i postępuj zgodnie z instrukcjami dotyczącymi systemu operacyjnego i środowiska programistycznego.
- Aby ustawić zmienną
SPEECH_KEYśrodowiskową, zastąp klucz jednym z kluczy zasobu. - Aby ustawić zmienną
SPEECH_REGIONśrodowiskową, zastąp region jednym z regionów zasobu.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Uwaga
Jeśli musisz uzyskać dostęp tylko do zmiennych środowiskowych w bieżącej konsoli, możesz ustawić zmienną środowiskową z wartością setsetxzamiast .
Po dodaniu zmiennych środowiskowych może być konieczne ponowne uruchomienie wszystkich programów, które muszą odczytać zmienne środowiskowe, w tym okno konsoli. Jeśli na przykład używasz programu Visual Studio jako edytora, uruchom ponownie program Visual Studio przed uruchomieniem przykładu.
Rozpoznawanie mowy przy użyciu mikrofonu
Wykonaj następujące kroki, aby rozpoznać mowę w aplikacji systemu macOS.
Sklonuj repozytorium Azure-Samples/cognitive-services-speech-sdk , aby uzyskać przykładowy projekt Rozpoznawanie mowy z mikrofonu w języku Swift w systemie macOS . Repozytorium zawiera również przykłady dla systemu iOS.
Przejdź do katalogu pobranej przykładowej aplikacji (
helloworld) w terminalu.Uruchom polecenie
pod install. To polecenie generujehelloworld.xcworkspaceobszar roboczy Xcode zawierający zarówno przykładową aplikację, jak i zestaw Speech SDK jako zależność.Otwórz obszar roboczy w programie
helloworld.xcworkspaceXcode.Otwórz plik o nazwie AppDelegate.swift i znajdź
applicationDidFinishLaunchingmetody irecognizeFromMic, jak pokazano tutaj.import Cocoa @NSApplicationMain class AppDelegate: NSObject, NSApplicationDelegate { var label: NSTextField! var fromMicButton: NSButton! var sub: String! var region: String! @IBOutlet weak var window: NSWindow! func applicationDidFinishLaunching(_ aNotification: Notification) { print("loading") // load subscription information sub = ProcessInfo.processInfo.environment["SPEECH_KEY"] region = ProcessInfo.processInfo.environment["SPEECH_REGION"] label = NSTextField(frame: NSRect(x: 100, y: 50, width: 200, height: 200)) label.textColor = NSColor.black label.lineBreakMode = .byWordWrapping label.stringValue = "Recognition Result" label.isEditable = false self.window.contentView?.addSubview(label) fromMicButton = NSButton(frame: NSRect(x: 100, y: 300, width: 200, height: 30)) fromMicButton.title = "Recognize" fromMicButton.target = self fromMicButton.action = #selector(fromMicButtonClicked) self.window.contentView?.addSubview(fromMicButton) } @objc func fromMicButtonClicked() { DispatchQueue.global(qos: .userInitiated).async { self.recognizeFromMic() } } func recognizeFromMic() { var speechConfig: SPXSpeechConfiguration? do { try speechConfig = SPXSpeechConfiguration(subscription: sub, region: region) } catch { print("error \(error) happened") speechConfig = nil } speechConfig?.speechRecognitionLanguage = "en-US" let audioConfig = SPXAudioConfiguration() let reco = try! SPXSpeechRecognizer(speechConfiguration: speechConfig!, audioConfiguration: audioConfig) reco.addRecognizingEventHandler() {reco, evt in print("intermediate recognition result: \(evt.result.text ?? "(no result)")") self.updateLabel(text: evt.result.text, color: .gray) } updateLabel(text: "Listening ...", color: .gray) print("Listening...") let result = try! reco.recognizeOnce() print("recognition result: \(result.text ?? "(no result)"), reason: \(result.reason.rawValue)") updateLabel(text: result.text, color: .black) if result.reason != SPXResultReason.recognizedSpeech { let cancellationDetails = try! SPXCancellationDetails(fromCanceledRecognitionResult: result) print("cancelled: \(result.reason), \(cancellationDetails.errorDetails)") print("Did you set the speech resource key and region values?") updateLabel(text: "Error: \(cancellationDetails.errorDetails)", color: .red) } } func updateLabel(text: String?, color: NSColor) { DispatchQueue.main.async { self.label.stringValue = text! self.label.textColor = color } } }W pliku AppDelegate.m użyj zmiennych środowiskowych ustawionych wcześniej dla klucza zasobu usługi Mowa i regionu.
sub = ProcessInfo.processInfo.environment["SPEECH_KEY"] region = ProcessInfo.processInfo.environment["SPEECH_REGION"]Aby zmienić język rozpoznawania mowy, zastąp
en-USelement innym obsługiwanym językiem. Na przykład użyj dlaes-ESjęzyka hiszpańskiego (Hiszpania). Jeśli nie określisz języka, wartość domyślna toen-US. Aby uzyskać szczegółowe informacje na temat identyfikowania jednego z wielu języków, które mogą być mówione, zobacz Identyfikacja języka.Aby wyświetlić dane wyjściowe debugowania, wybierz pozycję Wyświetl>obszar>debugowania Aktywuj konsolę.
Skompiluj i uruchom przykładowy kod, wybierając pozycję Product Run (Uruchom produkt>) z menu lub wybierając przycisk Play (Odtwórz).
Ważne
Upewnij się, że ustawiono
SPEECH_KEYzmienne środowiskowe iSPEECH_REGION. Jeśli nie ustawisz tych zmiennych, przykład zakończy się niepowodzeniem z komunikatem o błędzie.
Po wybraniu przycisku w aplikacji i napisaniu kilku słów powinien zostać wyświetlony tekst, który wypowiedział się w dolnej części ekranu. Po pierwszym uruchomieniu aplikacji zostanie wyświetlony monit o udzielenie aplikacji dostępu do mikrofonu komputera.
Uwagi
W tym przykładzie użyto recognizeOnce operacji do transkrypcji wypowiedzi do 30 sekund lub do momentu wykrycia ciszy. Aby uzyskać informacje na temat ciągłego rozpoznawania dłuższego dźwięku, w tym konwersacji wielojęzycznych, zobacz Jak rozpoznawać mowę.
Objective-C
Zestaw SPEECH SDK dla języka Objective-C udostępnia biblioteki klienckie i dokumentację referencyjną zestawu Speech SDK dla języka Swift. Aby zapoznać się z przykładami kodu Objective-C, zobacz przykładowy projekt rozpoznawania mowy z mikrofonu w języku Objective-C w systemie macOS w usłudze GitHub.
Czyszczenie zasobów
Aby usunąć utworzony zasób usługi Mowa, możesz użyć witryny Azure Portal lub interfejsu wiersza polecenia platformy Azure.
Interfejs API REST zamiany mowy na tekst — dokumentacja | interfejsu API REST zamiany mowy na tekst w celu uzyskania krótkiej dokumentacji | audio Dodatkowe przykłady w usłudze GitHub
W tym przewodniku Szybki start utworzysz i uruchomisz aplikację w celu rozpoznawania i transkrypcji mowy na tekst w czasie rzeczywistym.
Aby zamiast tego transkrypcji plików audio asynchronicznie, zobacz Co to jest transkrypcja wsadowa. Jeśli nie masz pewności, które rozwiązanie zamiany mowy na tekst jest odpowiednie dla Ciebie, zobacz Co to jest zamiana mowy na tekst?
Wymagania wstępne
- Subskrypcja platformy Azure. Możesz utworzyć go bezpłatnie.
- Utwórz zasób usługi Mowa w witrynie Azure Portal.
- Pobierz klucz zasobu usługi Mowa i region. Po wdrożeniu zasobu usługi Mowa wybierz pozycję Przejdź do zasobu , aby wyświetlić klucze i zarządzać nimi.
Potrzebny jest również plik audio .wav na komputerze lokalnym. Możesz użyć własnego pliku .wav do 60 sekund lub pobrać https://crbn.us/whatstheweatherlike.wav przykładowy plik.
Ustawianie zmiennych środowiskowych
Aby uzyskać dostęp do usług Azure AI, musisz uwierzytelnić aplikację. W tym artykule pokazano, jak używać zmiennych środowiskowych do przechowywania poświadczeń. Następnie możesz uzyskać dostęp do zmiennych środowiskowych z kodu w celu uwierzytelnienia aplikacji. W przypadku środowiska produkcyjnego użyj bezpieczniejszego sposobu przechowywania poświadczeń i uzyskiwania do nich dostępu.
Ważne
Zalecamy uwierzytelnianie za pomocą identyfikatora Entra firmy Microsoft z tożsamościami zarządzanymi dla zasobów platformy Azure, aby uniknąć przechowywania poświadczeń przy użyciu aplikacji uruchamianych w chmurze.
Jeśli używasz klucza interfejsu API, zapisz go bezpiecznie w innym miejscu, na przykład w usłudze Azure Key Vault. Nie dołączaj klucza interfejsu API bezpośrednio do kodu i nigdy nie publikuj go publicznie.
Aby uzyskać więcej informacji na temat zabezpieczeń usług sztucznej inteligencji, zobacz Uwierzytelnianie żądań w usługach Azure AI.
Aby ustawić zmienne środowiskowe dla klucza i regionu zasobu usługi Mowa, otwórz okno konsoli i postępuj zgodnie z instrukcjami dotyczącymi systemu operacyjnego i środowiska programistycznego.
- Aby ustawić zmienną
SPEECH_KEYśrodowiskową, zastąp klucz jednym z kluczy zasobu. - Aby ustawić zmienną
SPEECH_REGIONśrodowiskową, zastąp region jednym z regionów zasobu.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Uwaga
Jeśli musisz uzyskać dostęp tylko do zmiennych środowiskowych w bieżącej konsoli, możesz ustawić zmienną środowiskową z wartością setsetxzamiast .
Po dodaniu zmiennych środowiskowych może być konieczne ponowne uruchomienie wszystkich programów, które muszą odczytać zmienne środowiskowe, w tym okno konsoli. Jeśli na przykład używasz programu Visual Studio jako edytora, uruchom ponownie program Visual Studio przed uruchomieniem przykładu.
Rozpoznawanie mowy z pliku
Otwórz okno konsoli i uruchom następujące polecenie cURL. Zastąp YourAudioFile.wav ścieżką i nazwą pliku audio.
curl --location --request POST "https://%SPEECH_REGION%.stt.speech.microsoft.com/speech/recognition/conversation/cognitiveservices/v1?language=en-US&format=detailed" ^
--header "Ocp-Apim-Subscription-Key: %SPEECH_KEY%" ^
--header "Content-Type: audio/wav" ^
--data-binary "@YourAudioFile.wav"
Ważne
Upewnij się, że ustawiono SPEECH_KEY zmienne środowiskowe i SPEECH_REGION. Jeśli nie ustawisz tych zmiennych, przykład zakończy się niepowodzeniem z komunikatem o błędzie.
Powinna zostać wyświetlona odpowiedź podobna do przedstawionej tutaj. Powinien DisplayText to być tekst rozpoznany z pliku audio. Polecenie rozpoznaje do 60 sekund dźwięku i konwertuje go na tekst.
{
"RecognitionStatus": "Success",
"DisplayText": "My voice is my passport, verify me.",
"Offset": 6600000,
"Duration": 32100000
}
Aby uzyskać więcej informacji, zobacz Interfejs API REST zamiany mowy na tekst w celu uzyskania krótkiego dźwięku.
Czyszczenie zasobów
Aby usunąć utworzony zasób usługi Mowa, możesz użyć witryny Azure Portal lub interfejsu wiersza polecenia platformy Azure.
W tym przewodniku Szybki start utworzysz i uruchomisz aplikację w celu rozpoznawania i transkrypcji mowy na tekst w czasie rzeczywistym.
Aby zamiast tego transkrypcji plików audio asynchronicznie, zobacz Co to jest transkrypcja wsadowa. Jeśli nie masz pewności, które rozwiązanie zamiany mowy na tekst jest odpowiednie dla Ciebie, zobacz Co to jest zamiana mowy na tekst?
Wymagania wstępne
- Subskrypcja platformy Azure. Możesz utworzyć go bezpłatnie.
- Utwórz zasób usługi Mowa w witrynie Azure Portal.
- Pobierz klucz zasobu usługi Mowa i region. Po wdrożeniu zasobu usługi Mowa wybierz pozycję Przejdź do zasobu , aby wyświetlić klucze i zarządzać nimi.
Konfigurowanie środowiska
Wykonaj następujące kroki i zapoznaj się z przewodnikiem Szybki start interfejsu wiersza polecenia usługi Mowa, aby uzyskać inne wymagania dotyczące platformy.
Uruchom następujące polecenie interfejsu wiersza polecenia platformy .NET, aby zainstalować interfejs wiersza polecenia usługi Mowa:
dotnet tool install --global Microsoft.CognitiveServices.Speech.CLIUruchom następujące polecenia, aby skonfigurować klucz zasobu usługi Mowa i region. Zastąp
SUBSCRIPTION-KEYciąg kluczem zasobu usługi Mowa i zastąpREGIONelement regionem zasobu usługi Mowa.spx config @key --set SUBSCRIPTION-KEY spx config @region --set REGION
Rozpoznawanie mowy przy użyciu mikrofonu
Uruchom następujące polecenie, aby uruchomić rozpoznawanie mowy z mikrofonu:
spx recognize --microphone --source en-USPorozmawiaj z mikrofonem i zobaczysz transkrypcję słów w tekście w czasie rzeczywistym. Interfejs wiersza polecenia usługi Mowa zatrzymuje się po upływie okresu ciszy, 30 sekund lub po wybraniu Ctrl+C.
Connection CONNECTED... RECOGNIZED: I'm excited to try speech to text.
Uwagi
Oto kilka innych zagadnień:
Aby rozpoznać mowę z pliku audio, użyj polecenia
--filezamiast--microphone. W przypadku skompresowanych plików audio, takich jak MP4, zainstaluj usługę GStreamer i użyj polecenia--format. Aby uzyskać więcej informacji, zobacz Jak używać skompresowanego dźwięku wejściowego.spx recognize --file YourAudioFile.wav spx recognize --file YourAudioFile.mp4 --format anyAby zwiększyć dokładność rozpoznawania określonych słów lub wypowiedzi, użyj listy fraz. Lista fraz jest dołączana w wierszu lub z plikiem tekstowym wraz z poleceniem
recognize:spx recognize --microphone --phrases "Contoso;Jessie;Rehaan;" spx recognize --microphone --phrases @phrases.txtAby zmienić język rozpoznawania mowy, zastąp
en-USelement innym obsługiwanym językiem. Na przykład użyj dlaes-ESjęzyka hiszpańskiego (Hiszpania). Jeśli nie określisz języka, wartość domyślna toen-US.spx recognize --microphone --source es-ESW celu ciągłego rozpoznawania dźwięku dłuższego niż 30 sekund dołącz :
--continuousspx recognize --microphone --source es-ES --continuousUruchom to polecenie, aby uzyskać więcej informacji o opcjach rozpoznawania mowy, takich jak dane wejściowe i wyjściowe pliku:
spx help recognize
Czyszczenie zasobów
Aby usunąć utworzony zasób usługi Mowa, możesz użyć witryny Azure Portal lub interfejsu wiersza polecenia platformy Azure.