Szybki start: rozpoznawanie intencji za pomocą usługi Mowa i usługi LUIS
Ważne
Usługa LUIS zostanie wycofana 1 października 2025 r. Od 1 kwietnia 2023 r. nie można tworzyć nowych zasobów usługi LUIS. Zalecamy migrację aplikacji LUIS do interpretacji języka konwersacyjnego, aby korzystać z ciągłej pomocy technicznej i wielojęzycznych możliwości produktów.
Usługa Conversational Language Understanding (CLU) jest dostępna dla języków C# i C++ z zestawem Speech SDK w wersji 1.25 lub nowszej. Zobacz przewodnik Szybki start, aby rozpoznawać intencje za pomocą zestawu SPEECH SDK i clu.
Dokumentacja referencyjna Package (NuGet) | Dodatkowe przykłady w witrynie GitHub |
W tym przewodniku Szybki start użyjesz zestawu SDK rozpoznawania mowy i usługi Language Understanding (LUIS) do rozpoznawania intencji z danych audio przechwyconych z mikrofonu. W szczególności użyjesz zestawu SDK usługi Mowa do przechwytywania mowy i wstępnie utworzonej domeny z usługi LUIS, aby zidentyfikować intencje automatyzacji domu, takie jak włączanie i wyłączanie światła.
Wymagania wstępne
- Subskrypcja platformy Azure — utwórz bezpłatnie
- Utwórz zasób języka w witrynie Azure Portal. Możesz użyć warstwy cenowej bezpłatna (
F0), aby wypróbować usługę, a następnie uaktualnić ją do warstwy płatnej dla środowiska produkcyjnego. Tym razem nie będzie potrzebny zasób usługi Mowa. - Pobierz klucz zasobu języka i region. Po wdrożeniu zasobu Language wybierz pozycję Przejdź do zasobu , aby wyświetlić klucze i zarządzać nimi.
Tworzenie aplikacji usługi LUIS na potrzeby rozpoznawania intencji
Aby ukończyć przewodnik Szybki start dotyczący rozpoznawania intencji, musisz utworzyć konto usługi LUIS i projekt przy użyciu portalu usługi LUIS w wersji zapoznawczej. Ten przewodnik Szybki start wymaga subskrypcji usługi LUIS w regionie, w którym jest dostępne rozpoznawanie intencji. Subskrypcja usługi Mowa nie jest wymagana.
Najpierw musisz utworzyć konto usługi LUIS i aplikację przy użyciu portalu usługi LUIS w wersji zapoznawczej. Utworzona aplikacja USŁUGI LUIS będzie używać wstępnie utworzonej domeny do automatyzacji domu, która zapewnia intencje, jednostki i przykładowe wypowiedzi. Po zakończeniu będziesz mieć punkt końcowy usługi LUIS uruchomiony w chmurze, który można wywołać przy użyciu zestawu SPEECH SDK.
Postępuj zgodnie z tymi instrukcjami, aby utworzyć aplikację usługi LUIS:
Gdy wszystko będzie gotowe, potrzebne będą cztery elementy:
- Ponowne publikowanie za pomocą przełączania mowy
- Klucz podstawowy usługi LUIS
- Lokalizacja usługi LUIS
- Identyfikator aplikacji usługi LUIS
Tutaj można znaleźć te informacje w portalu usługi LUIS w wersji zapoznawczej:
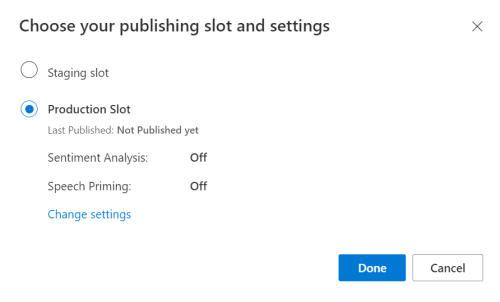
W portalu wersji zapoznawczej usługi LUIS wybierz aplikację, a następnie wybierz przycisk Publikuj .
Wybierz miejsce produkcyjne, jeśli używasz
en-USopcji Zmień ustawienia, a następnie przełącz opcję Zamiana mowy na pozycję Wł. Następnie wybierz przycisk Publikuj .Ważne
Stosowanie priming mowy jest zdecydowanie zalecane, ponieważ poprawi dokładność rozpoznawania mowy.
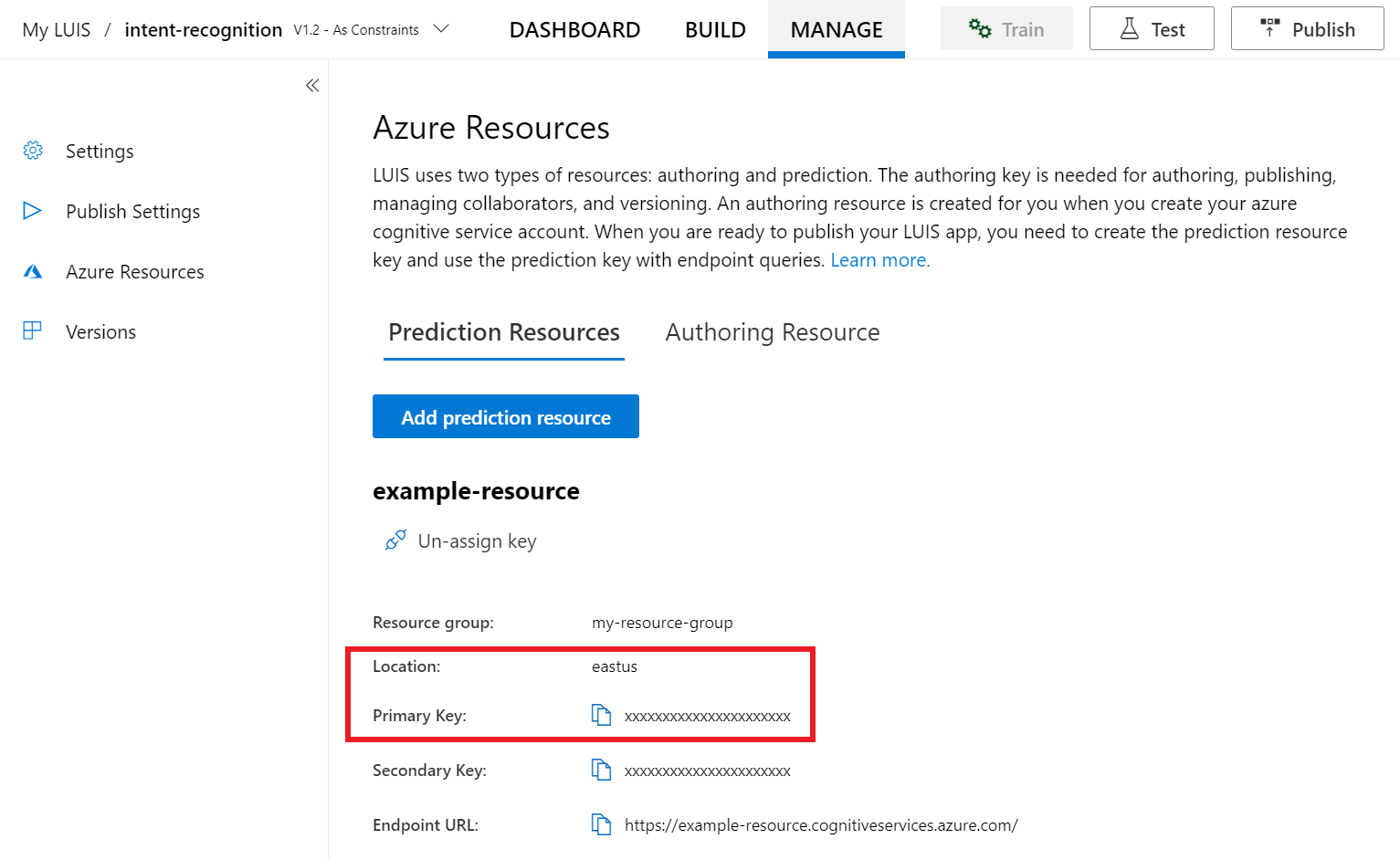
W portalu usługi LUIS w wersji zapoznawczej wybierz pozycję Zarządzaj, a następnie wybierz pozycję Zasoby platformy Azure. Na tej stronie znajdziesz klucz i lokalizację usługi LUIS (czasami nazywaną regionem) zasobu przewidywania usługi LUIS.
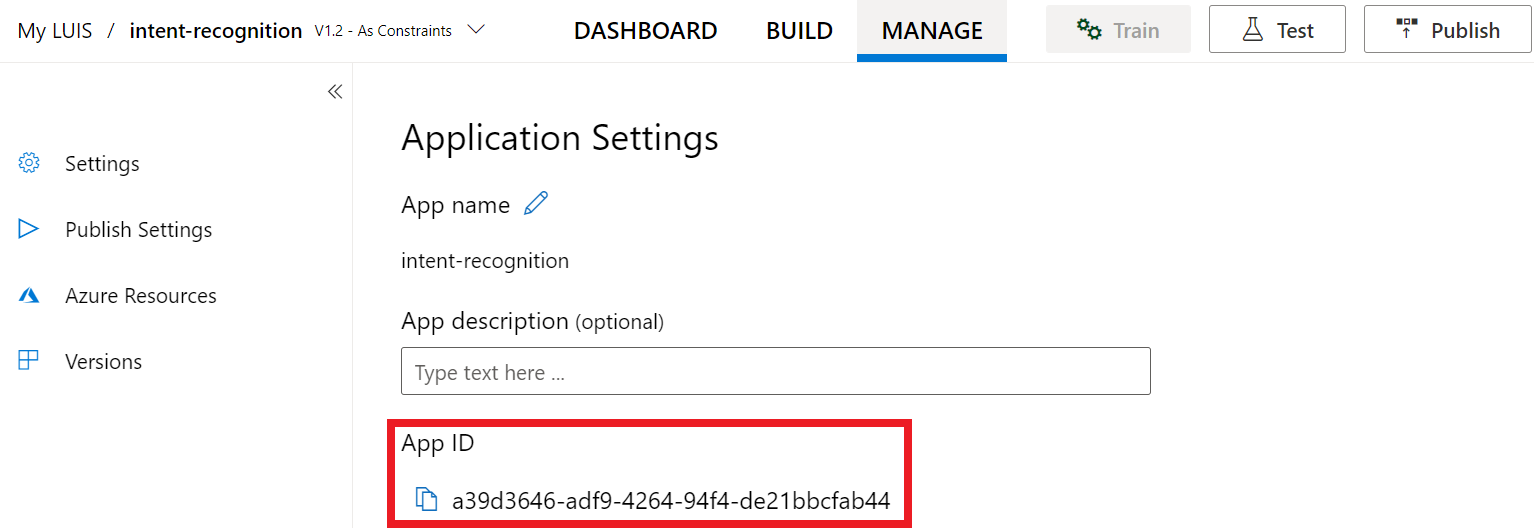
Po utworzeniu klucza i lokalizacji potrzebny będzie identyfikator aplikacji. Wybierz Ustawienia. Identyfikator aplikacji jest dostępny na tej stronie.
Otwieranie projektu w programie Visual Studio
Następnie otwórz projekt w programie Visual Studio.
- Uruchom program Visual Studio 2019.
- Załaduj projekt i otwórz plik
Program.cs.
Zacznij od kodu kociołowego
Dodajmy kod, który działa jako szkielet naszego projektu. Pamiętaj, że utworzono metodę asynchroniową o nazwie RecognizeIntentAsync().
using System;
using System.Threading.Tasks;
using Microsoft.CognitiveServices.Speech;
using Microsoft.CognitiveServices.Speech.Intent;
namespace helloworld
{
class Program
{
public static async Task RecognizeIntentAsync()
{
}
static async Task Main()
{
await RecognizeIntentAsync();
Console.WriteLine("Please press <Return> to continue.");
Console.ReadLine();
}
}
}
Tworzenie konfiguracji mowy
Przed zainicjowaniem IntentRecognizer obiektu należy utworzyć konfigurację, która używa klucza i lokalizacji dla zasobu przewidywania usługi LUIS.
Ważne
Klucz początkowy i klucze tworzenia nie będą działać. Musisz użyć utworzonego wcześniej klucza przewidywania i lokalizacji. Aby uzyskać więcej informacji, zobacz Tworzenie aplikacji usługi LUIS na potrzeby rozpoznawania intencji.
Wstaw ten kod w metodzie RecognizeIntentAsync() . Upewnij się, że zaktualizowano następujące wartości:
- Zastąp
"YourLanguageUnderstandingSubscriptionKey"element kluczem przewidywania usługi LUIS. - Zastąp
"YourLanguageUnderstandingServiceRegion"element lokalizacją usługi LUIS. Użyj identyfikatora regionu z regionu.
Napiwek
Jeśli potrzebujesz pomocy w znalezieniu tych wartości, zobacz Tworzenie aplikacji usługi LUIS na potrzeby rozpoznawania intencji.
Ważne
Pamiętaj, aby usunąć klucz z kodu po zakończeniu i nigdy nie publikować go publicznie. W przypadku środowiska produkcyjnego użyj bezpiecznego sposobu przechowywania i uzyskiwania dostępu do poświadczeń, takich jak usługa Azure Key Vault. Aby uzyskać więcej informacji, zobacz artykuł Dotyczący zabezpieczeń usług Azure AI.
var config = SpeechConfig.FromSubscription(
"YourLanguageUnderstandingSubscriptionKey",
"YourLanguageUnderstandingServiceRegion");
W tym przykładzie użyto FromSubscription() metody do skompilowania klasy SpeechConfig. Aby uzyskać pełną listę dostępnych metod, zobacz SpeechConfig Class (Klasa SpeechConfig).
Zestaw SDK rozpoznawania mowy będzie domyślnie rozpoznawany przy użyciu języka en-us. Zobacz Jak rozpoznawać mowę , aby uzyskać informacje na temat wybierania języka źródłowego.
Inicjowanie intencjiRecognizer
Teraz utwórzmy element IntentRecognizer. Ten obiekt jest tworzony wewnątrz instrukcji using w celu zapewnienia prawidłowego wydania niezarządzanych zasobów. Wstaw ten kod w metodzie RecognizeIntentAsync() bezpośrednio poniżej konfiguracji usługi Mowa.
// Creates an intent recognizer using microphone as audio input.
using (var recognizer = new IntentRecognizer(config))
{
}
Dodawanie elementu LanguageUnderstandingModel i intencji
Musisz skojarzyć element z rozpoznawaniem LanguageUnderstandingModel intencji i dodać intencje, które chcesz rozpoznać. Użyjemy intencji ze wstępnie utworzonej domeny na potrzeby automatyzacji domu. Wstaw ten kod w instrukcji using z poprzedniej sekcji. Upewnij się, że zastąpisz "YourLanguageUnderstandingAppId" element identyfikatorem aplikacji usługi LUIS.
Napiwek
Jeśli potrzebujesz pomocy w znalezieniu tej wartości, zobacz Tworzenie aplikacji usługi LUIS na potrzeby rozpoznawania intencji.
// Creates a Language Understanding model using the app id, and adds specific intents from your model
var model = LanguageUnderstandingModel.FromAppId("YourLanguageUnderstandingAppId");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName1", "id1");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName2", "id2");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName3", "any-IntentId-here");
W tym przykładzie użyto funkcji do indywidualnego dodawania AddIntent() intencji. Jeśli chcesz dodać wszystkie intencje z modelu, użyj AddAllIntents(model) modelu i przekaż go.
Rozpoznawanie intencji
IntentRecognizer Z obiektu wywołasz metodę RecognizeOnceAsync() . Ta metoda pozwala usłudze Rozpoznawanie mowy wiedzieć, że wysyłasz pojedynczą frazę do rozpoznawania i że gdy fraza zostanie zidentyfikowana, aby przestać rozpoznawać mowę.
W instrukcji using dodaj ten kod poniżej modelu.
// Starts recognizing.
Console.WriteLine("Say something...");
// Starts intent recognition, and returns after a single utterance is recognized. The end of a
// single utterance is determined by listening for silence at the end or until a maximum of about 30
// seconds of audio is processed. The task returns the recognition text as result.
// Note: Since RecognizeOnceAsync() returns only a single utterance, it is suitable only for single
// shot recognition like command or query.
// For long-running multi-utterance recognition, use StartContinuousRecognitionAsync() instead.
var result = await recognizer.RecognizeOnceAsync();
Wyświetlanie wyników rozpoznawania (lub błędów)
Gdy wynik rozpoznawania jest zwracany przez usługę rozpoznawania mowy, należy wykonać z nim coś. Zamierzamy zachować prostotę i wydrukować wyniki w konsoli.
W instrukcji using poniżej RecognizeOnceAsync()dodaj następujący kod:
// Checks result.
switch (result.Reason)
{
case ResultReason.RecognizedIntent:
Console.WriteLine($"RECOGNIZED: Text={result.Text}");
Console.WriteLine($" Intent Id: {result.IntentId}.");
var json = result.Properties.GetProperty(PropertyId.LanguageUnderstandingServiceResponse_JsonResult);
Console.WriteLine($" Language Understanding JSON: {json}.");
break;
case ResultReason.RecognizedSpeech:
Console.WriteLine($"RECOGNIZED: Text={result.Text}");
Console.WriteLine($" Intent not recognized.");
break;
case ResultReason.NoMatch:
Console.WriteLine($"NOMATCH: Speech could not be recognized.");
break;
case ResultReason.Canceled:
var cancellation = CancellationDetails.FromResult(result);
Console.WriteLine($"CANCELED: Reason={cancellation.Reason}");
if (cancellation.Reason == CancellationReason.Error)
{
Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}");
Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}");
Console.WriteLine($"CANCELED: Did you update the subscription info?");
}
break;
}
Sprawdzanie kodu
Na tym etapie kod powinien wyglądać następująco:
Uwaga
Dodaliśmy komentarze do tej wersji.
//
// Copyright (c) Microsoft. All rights reserved.
// Licensed under the MIT license. See LICENSE.md file in the project root for full license information.
//
// <skeleton_1>
using System;
using System.Threading.Tasks;
using Microsoft.CognitiveServices.Speech;
using Microsoft.CognitiveServices.Speech.Intent;
namespace helloworld
{
class Program
{
public static async Task RecognizeIntentAsync()
{
// </skeleton_1>
// Creates an instance of a speech config with specified subscription key
// and service region. Note that in contrast to other services supported by
// the Cognitive Services Speech SDK, the Language Understanding service
// requires a specific subscription key from https://www.luis.ai/.
// The Language Understanding service calls the required key 'endpoint key'.
// Once you've obtained it, replace with below with your own Language Understanding subscription key
// and service region (e.g., "westus").
// The default language is "en-us".
// <create_speech_configuration>
var config = SpeechConfig.FromSubscription(
"YourLanguageUnderstandingSubscriptionKey",
"YourLanguageUnderstandingServiceRegion");
// </create_speech_configuration>
// <create_intent_recognizer_1>
// Creates an intent recognizer using microphone as audio input.
using (var recognizer = new IntentRecognizer(config))
{
// </create_intent_recognizer_1>
// <add_intents>
// Creates a Language Understanding model using the app id, and adds specific intents from your model
var model = LanguageUnderstandingModel.FromAppId("YourLanguageUnderstandingAppId");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName1", "id1");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName2", "id2");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName3", "any-IntentId-here");
// </add_intents>
// To add all of the possible intents from a LUIS model to the recognizer, uncomment the line below:
// recognizer.AddAllIntents(model);
// <recognize_intent>
// Starts recognizing.
Console.WriteLine("Say something...");
// Starts intent recognition, and returns after a single utterance is recognized. The end of a
// single utterance is determined by listening for silence at the end or until a maximum of about 30
// seconds of audio is processed. The task returns the recognition text as result.
// Note: Since RecognizeOnceAsync() returns only a single utterance, it is suitable only for single
// shot recognition like command or query.
// For long-running multi-utterance recognition, use StartContinuousRecognitionAsync() instead.
var result = await recognizer.RecognizeOnceAsync();
// </recognize_intent>
// <print_results>
// Checks result.
switch (result.Reason)
{
case ResultReason.RecognizedIntent:
Console.WriteLine($"RECOGNIZED: Text={result.Text}");
Console.WriteLine($" Intent Id: {result.IntentId}.");
var json = result.Properties.GetProperty(PropertyId.LanguageUnderstandingServiceResponse_JsonResult);
Console.WriteLine($" Language Understanding JSON: {json}.");
break;
case ResultReason.RecognizedSpeech:
Console.WriteLine($"RECOGNIZED: Text={result.Text}");
Console.WriteLine($" Intent not recognized.");
break;
case ResultReason.NoMatch:
Console.WriteLine($"NOMATCH: Speech could not be recognized.");
break;
case ResultReason.Canceled:
var cancellation = CancellationDetails.FromResult(result);
Console.WriteLine($"CANCELED: Reason={cancellation.Reason}");
if (cancellation.Reason == CancellationReason.Error)
{
Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}");
Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}");
Console.WriteLine($"CANCELED: Did you update the subscription info?");
}
break;
}
// </print_results>
// <create_intent_recognizer_2>
}
// </create_intent_recognizer_2>
// <skeleton_2>
}
static async Task Main()
{
await RecognizeIntentAsync();
Console.WriteLine("Please press <Return> to continue.");
Console.ReadLine();
}
}
}
// </skeleton_2>
Kompilowanie i uruchamianie aplikacji
Teraz możesz przystąpić do kompilowania aplikacji i testowania rozpoznawania mowy przy użyciu usługi Mowa.
- Skompiluj kod — na pasku menu programu Visual Studio wybierz pozycję Kompiluj rozwiązanie kompilacji>.
- Uruchom aplikację — na pasku menu wybierz pozycję Debuguj>rozpocznij debugowanie lub naciśnij F5.
- Rozpocznij rozpoznawanie — monituje o wypowiadanie frazy w języku angielskim. Twoja mowa jest wysyłana do usługi rozpoznawania mowy, transkrybowana jako tekst i renderowana w konsoli programu .
Dokumentacja referencyjna Package (NuGet) | Dodatkowe przykłady w witrynie GitHub |
W tym przewodniku Szybki start użyjesz zestawu SDK rozpoznawania mowy i usługi Language Understanding (LUIS) do rozpoznawania intencji z danych audio przechwyconych z mikrofonu. W szczególności użyjesz zestawu SDK usługi Mowa do przechwytywania mowy i wstępnie utworzonej domeny z usługi LUIS, aby zidentyfikować intencje automatyzacji domu, takie jak włączanie i wyłączanie światła.
Wymagania wstępne
- Subskrypcja platformy Azure — utwórz bezpłatnie
- Utwórz zasób języka w witrynie Azure Portal. Możesz użyć warstwy cenowej bezpłatna (
F0), aby wypróbować usługę, a następnie uaktualnić ją do warstwy płatnej dla środowiska produkcyjnego. Tym razem nie będzie potrzebny zasób usługi Mowa. - Pobierz klucz zasobu języka i region. Po wdrożeniu zasobu Language wybierz pozycję Przejdź do zasobu , aby wyświetlić klucze i zarządzać nimi.
Tworzenie aplikacji usługi LUIS na potrzeby rozpoznawania intencji
Aby ukończyć przewodnik Szybki start dotyczący rozpoznawania intencji, musisz utworzyć konto usługi LUIS i projekt przy użyciu portalu usługi LUIS w wersji zapoznawczej. Ten przewodnik Szybki start wymaga subskrypcji usługi LUIS w regionie, w którym jest dostępne rozpoznawanie intencji. Subskrypcja usługi Mowa nie jest wymagana.
Najpierw musisz utworzyć konto usługi LUIS i aplikację przy użyciu portalu usługi LUIS w wersji zapoznawczej. Utworzona aplikacja USŁUGI LUIS będzie używać wstępnie utworzonej domeny do automatyzacji domu, która zapewnia intencje, jednostki i przykładowe wypowiedzi. Po zakończeniu będziesz mieć punkt końcowy usługi LUIS uruchomiony w chmurze, który można wywołać przy użyciu zestawu SPEECH SDK.
Postępuj zgodnie z tymi instrukcjami, aby utworzyć aplikację usługi LUIS:
Gdy wszystko będzie gotowe, potrzebne będą cztery elementy:
- Ponowne publikowanie za pomocą przełączania mowy
- Klucz podstawowy usługi LUIS
- Lokalizacja usługi LUIS
- Identyfikator aplikacji usługi LUIS
Tutaj można znaleźć te informacje w portalu usługi LUIS w wersji zapoznawczej:
W portalu wersji zapoznawczej usługi LUIS wybierz aplikację, a następnie wybierz przycisk Publikuj .
Wybierz miejsce produkcyjne, jeśli używasz
en-USopcji Zmień ustawienia, a następnie przełącz opcję Zamiana mowy na pozycję Wł. Następnie wybierz przycisk Publikuj .Ważne
Stosowanie priming mowy jest zdecydowanie zalecane, ponieważ poprawi dokładność rozpoznawania mowy.
W portalu usługi LUIS w wersji zapoznawczej wybierz pozycję Zarządzaj, a następnie wybierz pozycję Zasoby platformy Azure. Na tej stronie znajdziesz klucz i lokalizację usługi LUIS (czasami nazywaną regionem) zasobu przewidywania usługi LUIS.
Po utworzeniu klucza i lokalizacji potrzebny będzie identyfikator aplikacji. Wybierz Ustawienia. Identyfikator aplikacji jest dostępny na tej stronie.
Otwieranie projektu w programie Visual Studio
Następnie otwórz projekt w programie Visual Studio.
- Uruchom program Visual Studio 2019.
- Załaduj projekt i otwórz plik
helloworld.cpp.
Zacznij od kodu kociołowego
Dodajmy kod, który działa jako szkielet naszego projektu. Pamiętaj, że utworzono metodę asynchroniową o nazwie recognizeIntent().
#include "stdafx.h"
#include <iostream>
#include <speechapi_cxx.h>
using namespace std;
using namespace Microsoft::CognitiveServices::Speech;
using namespace Microsoft::CognitiveServices::Speech::Intent;
void recognizeIntent()
{
}
int wmain()
{
try
{
recognizeIntent();
}
catch (exception e)
{
cout << e.what();
}
cout << "Please press a key to continue.\n";
cin.get();
return 0;
}
Tworzenie konfiguracji mowy
Przed zainicjowaniem IntentRecognizer obiektu należy utworzyć konfigurację, która używa klucza i lokalizacji dla zasobu przewidywania usługi LUIS.
Ważne
Klucz początkowy i klucze tworzenia nie będą działać. Musisz użyć utworzonego wcześniej klucza przewidywania i lokalizacji. Aby uzyskać więcej informacji, zobacz Tworzenie aplikacji usługi LUIS na potrzeby rozpoznawania intencji.
Wstaw ten kod w metodzie recognizeIntent() . Upewnij się, że zaktualizowano następujące wartości:
- Zastąp
"YourLanguageUnderstandingSubscriptionKey"element kluczem przewidywania usługi LUIS. - Zastąp
"YourLanguageUnderstandingServiceRegion"element lokalizacją usługi LUIS. Użyj identyfikatora regionu z regionu.
Napiwek
Jeśli potrzebujesz pomocy w znalezieniu tych wartości, zobacz Tworzenie aplikacji usługi LUIS na potrzeby rozpoznawania intencji.
Ważne
Pamiętaj, aby usunąć klucz z kodu po zakończeniu i nigdy nie publikować go publicznie. W przypadku środowiska produkcyjnego użyj bezpiecznego sposobu przechowywania i uzyskiwania dostępu do poświadczeń, takich jak usługa Azure Key Vault. Aby uzyskać więcej informacji, zobacz artykuł Dotyczący zabezpieczeń usług Azure AI.
auto config = SpeechConfig::FromSubscription(
"YourLanguageUnderstandingSubscriptionKey",
"YourLanguageUnderstandingServiceRegion");
W tym przykładzie użyto FromSubscription() metody do skompilowania klasy SpeechConfig. Aby uzyskać pełną listę dostępnych metod, zobacz SpeechConfig Class (Klasa SpeechConfig).
Zestaw SDK rozpoznawania mowy będzie domyślnie rozpoznawany przy użyciu języka en-us. Zobacz Jak rozpoznawać mowę , aby uzyskać informacje na temat wybierania języka źródłowego.
Inicjowanie intencjiRecognizer
Teraz utwórzmy element IntentRecognizer. Wstaw ten kod w metodzie recognizeIntent() bezpośrednio poniżej konfiguracji usługi Mowa.
// Creates an intent recognizer using microphone as audio input.
auto recognizer = IntentRecognizer::FromConfig(config);
Dodawanie elementu LanguageUnderstandingModel i intents
Musisz skojarzyć element z rozpoznawaniem LanguageUnderstandingModel intencji i dodać intencje, które chcesz rozpoznać. Użyjemy intencji ze wstępnie utworzonej domeny na potrzeby automatyzacji domu.
Wstaw ten kod poniżej pliku IntentRecognizer. Upewnij się, że zastąpisz "YourLanguageUnderstandingAppId" element identyfikatorem aplikacji usługi LUIS.
Napiwek
Jeśli potrzebujesz pomocy w znalezieniu tej wartości, zobacz Tworzenie aplikacji usługi LUIS na potrzeby rozpoznawania intencji.
// Creates a Language Understanding model using the app id, and adds specific intents from your model
auto model = LanguageUnderstandingModel::FromAppId("YourLanguageUnderstandingAppId");
recognizer->AddIntent(model, "YourLanguageUnderstandingIntentName1", "id1");
recognizer->AddIntent(model, "YourLanguageUnderstandingIntentName2", "id2");
recognizer->AddIntent(model, "YourLanguageUnderstandingIntentName3", "any-IntentId-here");
W tym przykładzie użyto funkcji do indywidualnego dodawania AddIntent() intencji. Jeśli chcesz dodać wszystkie intencje z modelu, użyj AddAllIntents(model) modelu i przekaż go.
Rozpoznawanie intencji
IntentRecognizer Z obiektu wywołasz metodę RecognizeOnceAsync() . Ta metoda pozwala usłudze Rozpoznawanie mowy wiedzieć, że wysyłasz pojedynczą frazę do rozpoznawania i że gdy fraza zostanie zidentyfikowana, aby przestać rozpoznawać mowę. Dla uproszczenia zaczekamy na zakończenie przyszłego powrotu.
Wstaw ten kod poniżej modelu:
cout << "Say something...\n";
// Starts intent recognition, and returns after a single utterance is recognized. The end of a
// single utterance is determined by listening for silence at the end or until a maximum of about 30
// seconds of audio is processed. The task returns the recognition text as result.
// Note: Since RecognizeOnceAsync() returns only a single utterance, it is suitable only for single
// shot recognition like command or query.
// For long-running multi-utterance recognition, use StartContinuousRecognitionAsync() instead.
auto result = recognizer->RecognizeOnceAsync().get();
Wyświetlanie wyników rozpoznawania (lub błędów)
Gdy wynik rozpoznawania jest zwracany przez usługę rozpoznawania mowy, należy wykonać z nim coś. Zachowamy prostotę i wyświetlimy wynik w konsoli.
Wstaw poniższy kod auto result = recognizer->RecognizeOnceAsync().get();:
// Checks result.
if (result->Reason == ResultReason::RecognizedIntent)
{
cout << "RECOGNIZED: Text=" << result->Text << std::endl;
cout << " Intent Id: " << result->IntentId << std::endl;
cout << " Intent Service JSON: " << result->Properties.GetProperty(PropertyId::LanguageUnderstandingServiceResponse_JsonResult) << std::endl;
}
else if (result->Reason == ResultReason::RecognizedSpeech)
{
cout << "RECOGNIZED: Text=" << result->Text << " (intent could not be recognized)" << std::endl;
}
else if (result->Reason == ResultReason::NoMatch)
{
cout << "NOMATCH: Speech could not be recognized." << std::endl;
}
else if (result->Reason == ResultReason::Canceled)
{
auto cancellation = CancellationDetails::FromResult(result);
cout << "CANCELED: Reason=" << (int)cancellation->Reason << std::endl;
if (cancellation->Reason == CancellationReason::Error)
{
cout << "CANCELED: ErrorCode=" << (int)cancellation->ErrorCode << std::endl;
cout << "CANCELED: ErrorDetails=" << cancellation->ErrorDetails << std::endl;
cout << "CANCELED: Did you update the subscription info?" << std::endl;
}
}
Sprawdzanie kodu
Na tym etapie kod powinien wyglądać następująco:
Uwaga
Dodaliśmy komentarze do tej wersji.
//
// Copyright (c) Microsoft. All rights reserved.
// Licensed under the MIT license. See LICENSE.md file in the project root for full license information.
//
// <skeleton_1>
#include "stdafx.h"
#include <iostream>
#include <speechapi_cxx.h>
using namespace std;
using namespace Microsoft::CognitiveServices::Speech;
using namespace Microsoft::CognitiveServices::Speech::Intent;
void recognizeIntent()
{
// </skeleton_1>
// Creates an instance of a speech config with specified subscription key
// and service region. Note that in contrast to other services supported by
// the Cognitive Services Speech SDK, the Language Understanding service
// requires a specific subscription key from https://www.luis.ai/.
// The Language Understanding service calls the required key 'endpoint key'.
// Once you've obtained it, replace with below with your own Language Understanding subscription key
// and service region (e.g., "westus").
// The default recognition language is "en-us".
// <create_speech_configuration>
auto config = SpeechConfig::FromSubscription(
"YourLanguageUnderstandingSubscriptionKey",
"YourLanguageUnderstandingServiceRegion");
// </create_speech_configuration>
// <create_intent_recognizer>
// Creates an intent recognizer using microphone as audio input.
auto recognizer = IntentRecognizer::FromConfig(config);
// </create_intent_recognizer>
// <add_intents>
// Creates a Language Understanding model using the app id, and adds specific intents from your model
auto model = LanguageUnderstandingModel::FromAppId("YourLanguageUnderstandingAppId");
recognizer->AddIntent(model, "YourLanguageUnderstandingIntentName1", "id1");
recognizer->AddIntent(model, "YourLanguageUnderstandingIntentName2", "id2");
recognizer->AddIntent(model, "YourLanguageUnderstandingIntentName3", "any-IntentId-here");
// </add_intents>
// To add all of the possible intents from a LUIS model to the recognizer, uncomment the line below:
// recognizer->AddAllIntents(model);
// <recognize_intent>
cout << "Say something...\n";
// Starts intent recognition, and returns after a single utterance is recognized. The end of a
// single utterance is determined by listening for silence at the end or until a maximum of about 30
// seconds of audio is processed. The task returns the recognition text as result.
// Note: Since RecognizeOnceAsync() returns only a single utterance, it is suitable only for single
// shot recognition like command or query.
// For long-running multi-utterance recognition, use StartContinuousRecognitionAsync() instead.
auto result = recognizer->RecognizeOnceAsync().get();
// </recognize_intent>
// <print_results>
// Checks result.
if (result->Reason == ResultReason::RecognizedIntent)
{
cout << "RECOGNIZED: Text=" << result->Text << std::endl;
cout << " Intent Id: " << result->IntentId << std::endl;
cout << " Intent Service JSON: " << result->Properties.GetProperty(PropertyId::LanguageUnderstandingServiceResponse_JsonResult) << std::endl;
}
else if (result->Reason == ResultReason::RecognizedSpeech)
{
cout << "RECOGNIZED: Text=" << result->Text << " (intent could not be recognized)" << std::endl;
}
else if (result->Reason == ResultReason::NoMatch)
{
cout << "NOMATCH: Speech could not be recognized." << std::endl;
}
else if (result->Reason == ResultReason::Canceled)
{
auto cancellation = CancellationDetails::FromResult(result);
cout << "CANCELED: Reason=" << (int)cancellation->Reason << std::endl;
if (cancellation->Reason == CancellationReason::Error)
{
cout << "CANCELED: ErrorCode=" << (int)cancellation->ErrorCode << std::endl;
cout << "CANCELED: ErrorDetails=" << cancellation->ErrorDetails << std::endl;
cout << "CANCELED: Did you update the subscription info?" << std::endl;
}
}
// </print_results>
// <skeleton_2>
}
int wmain()
{
try
{
recognizeIntent();
}
catch (exception e)
{
cout << e.what();
}
cout << "Please press a key to continue.\n";
cin.get();
return 0;
}
// </skeleton_2>
Kompilowanie i uruchamianie aplikacji
Teraz możesz przystąpić do kompilowania aplikacji i testowania rozpoznawania mowy przy użyciu usługi Mowa.
- Skompiluj kod — na pasku menu programu Visual Studio wybierz pozycję Kompiluj rozwiązanie kompilacji>.
- Uruchom aplikację — na pasku menu wybierz pozycję Debuguj>rozpocznij debugowanie lub naciśnij F5.
- Rozpocznij rozpoznawanie — monituje o wypowiadanie frazy w języku angielskim. Twoja mowa jest wysyłana do usługi rozpoznawania mowy, transkrybowana jako tekst i renderowana w konsoli programu .
| Dokumentacja referencyjna Dodatkowe przykłady w usłudze GitHub
W tym przewodniku Szybki start użyjesz zestawu SDK rozpoznawania mowy i usługi Language Understanding (LUIS) do rozpoznawania intencji z danych audio przechwyconych z mikrofonu. W szczególności użyjesz zestawu SDK usługi Mowa do przechwytywania mowy i wstępnie utworzonej domeny z usługi LUIS, aby zidentyfikować intencje automatyzacji domu, takie jak włączanie i wyłączanie światła.
Wymagania wstępne
- Subskrypcja platformy Azure — utwórz bezpłatnie
- Utwórz zasób języka w witrynie Azure Portal. Możesz użyć warstwy cenowej bezpłatna (
F0), aby wypróbować usługę, a następnie uaktualnić ją do warstwy płatnej dla środowiska produkcyjnego. Tym razem nie będzie potrzebny zasób usługi Mowa. - Pobierz klucz zasobu języka i region. Po wdrożeniu zasobu Language wybierz pozycję Przejdź do zasobu , aby wyświetlić klucze i zarządzać nimi.
Tworzenie aplikacji usługi LUIS na potrzeby rozpoznawania intencji
Aby ukończyć przewodnik Szybki start dotyczący rozpoznawania intencji, musisz utworzyć konto usługi LUIS i projekt przy użyciu portalu usługi LUIS w wersji zapoznawczej. Ten przewodnik Szybki start wymaga subskrypcji usługi LUIS w regionie, w którym jest dostępne rozpoznawanie intencji. Subskrypcja usługi Mowa nie jest wymagana.
Najpierw musisz utworzyć konto usługi LUIS i aplikację przy użyciu portalu usługi LUIS w wersji zapoznawczej. Utworzona aplikacja USŁUGI LUIS będzie używać wstępnie utworzonej domeny do automatyzacji domu, która zapewnia intencje, jednostki i przykładowe wypowiedzi. Po zakończeniu będziesz mieć punkt końcowy usługi LUIS uruchomiony w chmurze, który można wywołać przy użyciu zestawu SPEECH SDK.
Postępuj zgodnie z tymi instrukcjami, aby utworzyć aplikację usługi LUIS:
Gdy wszystko będzie gotowe, potrzebne będą cztery elementy:
- Ponowne publikowanie za pomocą przełączania mowy
- Klucz podstawowy usługi LUIS
- Lokalizacja usługi LUIS
- Identyfikator aplikacji usługi LUIS
Tutaj można znaleźć te informacje w portalu usługi LUIS w wersji zapoznawczej:
W portalu wersji zapoznawczej usługi LUIS wybierz aplikację, a następnie wybierz przycisk Publikuj .
Wybierz miejsce produkcyjne, jeśli używasz
en-USopcji Zmień ustawienia, a następnie przełącz opcję Zamiana mowy na pozycję Wł. Następnie wybierz przycisk Publikuj .Ważne
Stosowanie priming mowy jest zdecydowanie zalecane, ponieważ poprawi dokładność rozpoznawania mowy.
W portalu usługi LUIS w wersji zapoznawczej wybierz pozycję Zarządzaj, a następnie wybierz pozycję Zasoby platformy Azure. Na tej stronie znajdziesz klucz i lokalizację usługi LUIS (czasami nazywaną regionem) zasobu przewidywania usługi LUIS.
Po utworzeniu klucza i lokalizacji potrzebny będzie identyfikator aplikacji. Wybierz Ustawienia. Identyfikator aplikacji jest dostępny na tej stronie.
Otwórz projekt
- Otwórz preferowane środowisko IDE.
- Załaduj projekt i otwórz plik
Main.java.
Zacznij od kodu kociołowego
Dodajmy kod, który działa jako szkielet naszego projektu.
package speechsdk.quickstart;
import com.microsoft.cognitiveservices.speech.*;
import com.microsoft.cognitiveservices.speech.intent.*;
/**
* Quickstart: recognize speech using the Speech SDK for Java.
*/
public class Main {
/**
* @param args Arguments are ignored in this sample.
*/
public static void main(String[] args) {
} catch (Exception ex) {
System.out.println("Unexpected exception: " + ex.getMessage());
assert(false);
System.exit(1);
}
}
}
Tworzenie konfiguracji mowy
Przed zainicjowaniem IntentRecognizer obiektu należy utworzyć konfigurację, która używa klucza i lokalizacji dla zasobu przewidywania usługi LUIS.
Wstaw ten kod w bloku try/catch w pliku main(). Upewnij się, że zaktualizowano następujące wartości:
- Zastąp
"YourLanguageUnderstandingSubscriptionKey"element kluczem przewidywania usługi LUIS. - Zastąp
"YourLanguageUnderstandingServiceRegion"element lokalizacją usługi LUIS. Używanie identyfikatora regionu z regionu
Napiwek
Jeśli potrzebujesz pomocy w znalezieniu tych wartości, zobacz Tworzenie aplikacji usługi LUIS na potrzeby rozpoznawania intencji.
Ważne
Pamiętaj, aby usunąć klucz z kodu po zakończeniu i nigdy nie publikować go publicznie. W przypadku środowiska produkcyjnego użyj bezpiecznego sposobu przechowywania i uzyskiwania dostępu do poświadczeń, takich jak usługa Azure Key Vault. Aby uzyskać więcej informacji, zobacz artykuł Dotyczący zabezpieczeń usług Azure AI.
// Replace below with with specified subscription key (called 'endpoint key' by the Language Understanding service)
String languageUnderstandingSubscriptionKey = "YourLanguageUnderstandingSubscriptionKey";
// Replace below with your own service region (e.g., "westus").
String languageUnderstandingServiceRegion = "YourLanguageUnderstandingServiceRegion";
// Creates an instance of intent recognizer with a given speech configuration.
// Recognizer is created with the default microphone audio input and default language "en-us".
try (SpeechConfig config = SpeechConfig.fromSubscription(languageUnderstandingSubscriptionKey, languageUnderstandingServiceRegion);
W tym przykładzie użyto FromSubscription() metody do skompilowania klasy SpeechConfig. Aby uzyskać pełną listę dostępnych metod, zobacz SpeechConfig Class (Klasa SpeechConfig).
Zestaw SDK rozpoznawania mowy będzie domyślnie rozpoznawany przy użyciu języka en-us. Zobacz Jak rozpoznawać mowę , aby uzyskać informacje na temat wybierania języka źródłowego.
Inicjowanie intencjiRecognizer
Teraz utwórzmy element IntentRecognizer. Wstaw ten kod bezpośrednio poniżej konfiguracji usługi Mowa.
IntentRecognizer recognizer = new IntentRecognizer(config)) {
Dodawanie elementu LanguageUnderstandingModel i intents
Musisz skojarzyć element z rozpoznawaniem LanguageUnderstandingModel intencji i dodać intencje, które chcesz rozpoznać. Użyjemy intencji ze wstępnie utworzonej domeny na potrzeby automatyzacji domu.
Wstaw ten kod poniżej pliku IntentRecognizer. Upewnij się, że zastąpisz "YourLanguageUnderstandingAppId" element identyfikatorem aplikacji usługi LUIS.
Napiwek
Jeśli potrzebujesz pomocy w znalezieniu tej wartości, zobacz Tworzenie aplikacji usługi LUIS na potrzeby rozpoznawania intencji.
// Creates a language understanding model using the app id, and adds specific intents from your model
LanguageUnderstandingModel model = LanguageUnderstandingModel.fromAppId("YourLanguageUnderstandingAppId");
recognizer.addIntent(model, "YourLanguageUnderstandingIntentName1", "id1");
recognizer.addIntent(model, "YourLanguageUnderstandingIntentName2", "id2");
recognizer.addIntent(model, "YourLanguageUnderstandingIntentName3", "any-IntentId-here");
W tym przykładzie użyto funkcji do indywidualnego dodawania addIntent() intencji. Jeśli chcesz dodać wszystkie intencje z modelu, użyj addAllIntents(model) modelu i przekaż go.
Rozpoznawanie intencji
IntentRecognizer Z obiektu wywołasz metodę recognizeOnceAsync() . Ta metoda pozwala usłudze Rozpoznawanie mowy wiedzieć, że wysyłasz pojedynczą frazę do rozpoznawania i że gdy fraza zostanie zidentyfikowana, aby przestać rozpoznawać mowę.
Wstaw ten kod poniżej modelu:
System.out.println("Say something...");
// Starts recognition. It returns when the first utterance has been recognized.
IntentRecognitionResult result = recognizer.recognizeOnceAsync().get();
Wyświetlanie wyników rozpoznawania (lub błędów)
Gdy wynik rozpoznawania jest zwracany przez usługę rozpoznawania mowy, należy wykonać z nim coś. Zachowamy prostotę i wyświetlimy wynik w konsoli.
Wstaw ten kod poniżej wywołania metody recognizeOnceAsync().
// Checks result.
if (result.getReason() == ResultReason.RecognizedIntent) {
System.out.println("RECOGNIZED: Text=" + result.getText());
System.out.println(" Intent Id: " + result.getIntentId());
System.out.println(" Intent Service JSON: " + result.getProperties().getProperty(PropertyId.LanguageUnderstandingServiceResponse_JsonResult));
}
else if (result.getReason() == ResultReason.RecognizedSpeech) {
System.out.println("RECOGNIZED: Text=" + result.getText());
System.out.println(" Intent not recognized.");
}
else if (result.getReason() == ResultReason.NoMatch) {
System.out.println("NOMATCH: Speech could not be recognized.");
}
else if (result.getReason() == ResultReason.Canceled) {
CancellationDetails cancellation = CancellationDetails.fromResult(result);
System.out.println("CANCELED: Reason=" + cancellation.getReason());
if (cancellation.getReason() == CancellationReason.Error) {
System.out.println("CANCELED: ErrorCode=" + cancellation.getErrorCode());
System.out.println("CANCELED: ErrorDetails=" + cancellation.getErrorDetails());
System.out.println("CANCELED: Did you update the subscription info?");
}
}
Sprawdzanie kodu
Na tym etapie kod powinien wyglądać następująco:
Uwaga
Dodaliśmy komentarze do tej wersji.
//
// Copyright (c) Microsoft. All rights reserved.
// Licensed under the MIT license. See LICENSE.md file in the project root for full license information.
//
// <skeleton_1>
package speechsdk.quickstart;
import com.microsoft.cognitiveservices.speech.*;
import com.microsoft.cognitiveservices.speech.intent.*;
/**
* Quickstart: recognize speech using the Speech SDK for Java.
*/
public class Main {
/**
* @param args Arguments are ignored in this sample.
*/
public static void main(String[] args) {
// </skeleton_1>
// <create_speech_configuration>
// Replace below with with specified subscription key (called 'endpoint key' by the Language Understanding service)
String languageUnderstandingSubscriptionKey = "YourLanguageUnderstandingSubscriptionKey";
// Replace below with your own service region (e.g., "westus").
String languageUnderstandingServiceRegion = "YourLanguageUnderstandingServiceRegion";
// Creates an instance of intent recognizer with a given speech configuration.
// Recognizer is created with the default microphone audio input and default language "en-us".
try (SpeechConfig config = SpeechConfig.fromSubscription(languageUnderstandingSubscriptionKey, languageUnderstandingServiceRegion);
// </create_speech_configuration>
// <create_intent_recognizer>
IntentRecognizer recognizer = new IntentRecognizer(config)) {
// </create_intent_recognizer>
// <add_intents>
// Creates a language understanding model using the app id, and adds specific intents from your model
LanguageUnderstandingModel model = LanguageUnderstandingModel.fromAppId("YourLanguageUnderstandingAppId");
recognizer.addIntent(model, "YourLanguageUnderstandingIntentName1", "id1");
recognizer.addIntent(model, "YourLanguageUnderstandingIntentName2", "id2");
recognizer.addIntent(model, "YourLanguageUnderstandingIntentName3", "any-IntentId-here");
// </add_intents>
// To add all of the possible intents from a LUIS model to the recognizer, uncomment the line below:
// recognizer.addAllIntents(model);
// <recognize_intent>
System.out.println("Say something...");
// Starts recognition. It returns when the first utterance has been recognized.
IntentRecognitionResult result = recognizer.recognizeOnceAsync().get();
// </recognize_intent>
// <print_result>
// Checks result.
if (result.getReason() == ResultReason.RecognizedIntent) {
System.out.println("RECOGNIZED: Text=" + result.getText());
System.out.println(" Intent Id: " + result.getIntentId());
System.out.println(" Intent Service JSON: " + result.getProperties().getProperty(PropertyId.LanguageUnderstandingServiceResponse_JsonResult));
}
else if (result.getReason() == ResultReason.RecognizedSpeech) {
System.out.println("RECOGNIZED: Text=" + result.getText());
System.out.println(" Intent not recognized.");
}
else if (result.getReason() == ResultReason.NoMatch) {
System.out.println("NOMATCH: Speech could not be recognized.");
}
else if (result.getReason() == ResultReason.Canceled) {
CancellationDetails cancellation = CancellationDetails.fromResult(result);
System.out.println("CANCELED: Reason=" + cancellation.getReason());
if (cancellation.getReason() == CancellationReason.Error) {
System.out.println("CANCELED: ErrorCode=" + cancellation.getErrorCode());
System.out.println("CANCELED: ErrorDetails=" + cancellation.getErrorDetails());
System.out.println("CANCELED: Did you update the subscription info?");
}
}
// </print_result>
// <skeleton_2>
} catch (Exception ex) {
System.out.println("Unexpected exception: " + ex.getMessage());
assert(false);
System.exit(1);
}
}
}
// </skeleton_2>
Kompilowanie i uruchamianie aplikacji
Naciśnij F11 lub wybierz pozycję Uruchom>debugowanie. Następne 15 sekund mowy z mikrofonu zostanie rozpoznane i zarejestrowane w oknie konsoli.
Dokumentacja referencyjna | Package (npm) | Dodatkowe przykłady w kodzie źródłowym biblioteki GitHub |
W tym przewodniku Szybki start użyjesz zestawu SDK rozpoznawania mowy i usługi Language Understanding (LUIS) do rozpoznawania intencji z danych audio przechwyconych z mikrofonu. W szczególności użyjesz zestawu SDK usługi Mowa do przechwytywania mowy i wstępnie utworzonej domeny z usługi LUIS, aby zidentyfikować intencje automatyzacji domu, takie jak włączanie i wyłączanie światła.
Wymagania wstępne
- Subskrypcja platformy Azure — utwórz bezpłatnie
- Utwórz zasób języka w witrynie Azure Portal. Możesz użyć warstwy cenowej bezpłatna (
F0), aby wypróbować usługę, a następnie uaktualnić ją do warstwy płatnej dla środowiska produkcyjnego. Tym razem nie będzie potrzebny zasób usługi Mowa. - Pobierz klucz zasobu języka i region. Po wdrożeniu zasobu Language wybierz pozycję Przejdź do zasobu , aby wyświetlić klucze i zarządzać nimi.
Tworzenie aplikacji usługi LUIS na potrzeby rozpoznawania intencji
Aby ukończyć przewodnik Szybki start dotyczący rozpoznawania intencji, musisz utworzyć konto usługi LUIS i projekt przy użyciu portalu usługi LUIS w wersji zapoznawczej. Ten przewodnik Szybki start wymaga subskrypcji usługi LUIS w regionie, w którym jest dostępne rozpoznawanie intencji. Subskrypcja usługi Mowa nie jest wymagana.
Najpierw musisz utworzyć konto usługi LUIS i aplikację przy użyciu portalu usługi LUIS w wersji zapoznawczej. Utworzona aplikacja USŁUGI LUIS będzie używać wstępnie utworzonej domeny do automatyzacji domu, która zapewnia intencje, jednostki i przykładowe wypowiedzi. Po zakończeniu będziesz mieć punkt końcowy usługi LUIS uruchomiony w chmurze, który można wywołać przy użyciu zestawu SPEECH SDK.
Postępuj zgodnie z tymi instrukcjami, aby utworzyć aplikację usługi LUIS:
Gdy wszystko będzie gotowe, potrzebne będą cztery elementy:
- Ponowne publikowanie za pomocą przełączania mowy
- Klucz podstawowy usługi LUIS
- Lokalizacja usługi LUIS
- Identyfikator aplikacji usługi LUIS
Tutaj można znaleźć te informacje w portalu usługi LUIS w wersji zapoznawczej:
W portalu wersji zapoznawczej usługi LUIS wybierz aplikację, a następnie wybierz przycisk Publikuj .
Wybierz miejsce produkcyjne, jeśli używasz
en-USopcji Zmień ustawienia, a następnie przełącz opcję Zamiana mowy na pozycję Wł. Następnie wybierz przycisk Publikuj .Ważne
Stosowanie priming mowy jest zdecydowanie zalecane, ponieważ poprawi dokładność rozpoznawania mowy.
W portalu usługi LUIS w wersji zapoznawczej wybierz pozycję Zarządzaj, a następnie wybierz pozycję Zasoby platformy Azure. Na tej stronie znajdziesz klucz i lokalizację usługi LUIS (czasami nazywaną regionem) zasobu przewidywania usługi LUIS.
Po utworzeniu klucza i lokalizacji potrzebny będzie identyfikator aplikacji. Wybierz Ustawienia. Identyfikator aplikacji jest dostępny na tej stronie.
Zacznij od kodu kociołowego
Dodajmy kod, który działa jako szkielet naszego projektu.
<!DOCTYPE html>
<html>
<head>
<title>Microsoft Azure AI Speech SDK JavaScript Quickstart</title>
<meta charset="utf-8" />
</head>
<body style="font-family:'Helvetica Neue',Helvetica,Arial,sans-serif; font-size:13px;">
</body>
</html>
Dodawanie elementów interfejsu użytkownika
Teraz dodamy podstawowy interfejs użytkownika dla pól wejściowych, odwołamy się do języka JavaScript zestawu SDK usługi Mowa i pobierzemy token autoryzacji, jeśli jest dostępny.
Ważne
Pamiętaj, aby usunąć klucz z kodu po zakończeniu i nigdy nie publikować go publicznie. W przypadku środowiska produkcyjnego użyj bezpiecznego sposobu przechowywania i uzyskiwania dostępu do poświadczeń, takich jak usługa Azure Key Vault. Aby uzyskać więcej informacji, zobacz artykuł Dotyczący zabezpieczeń usług Azure AI.
<body style="font-family:'Helvetica Neue',Helvetica,Arial,sans-serif; font-size:13px;">
<div id="content" style="display:none">
<table width="100%">
<tr>
<td></td>
<td><h1 style="font-weight:500;">Microsoft Azure AI Speech SDK JavaScript Quickstart</h1></td>
</tr>
<tr>
<td align="right"><a href="https://learn.microsoft.com/azure/ai-services/speech-service/overview" target="_blank">Subscription</a>:</td>
<td><input id="subscriptionKey" type="text" size="40" value="subscription"></td>
</tr>
<tr>
<td align="right">Region</td>
<td><input id="serviceRegion" type="text" size="40" value="YourServiceRegion"></td>
</tr>
<tr>
<td align="right">Application ID:</td>
<td><input id="appId" type="text" size="60" value="YOUR_LANGUAGE_UNDERSTANDING_APP_ID"></td>
</tr>
<tr>
<td></td>
<td><button id="startIntentRecognizeAsyncButton">Start Intent Recognition</button></td>
</tr>
<tr>
<td align="right" valign="top">Input Text</td>
<td><textarea id="phraseDiv" style="display: inline-block;width:500px;height:200px"></textarea></td>
</tr>
<tr>
<td align="right" valign="top">Result</td>
<td><textarea id="statusDiv" style="display: inline-block;width:500px;height:100px"></textarea></td>
</tr>
</table>
</div>
<script src="microsoft.cognitiveservices.speech.sdk.bundle.js"></script>
<script>
// Note: Replace the URL with a valid endpoint to retrieve
// authorization tokens for your subscription.
var authorizationEndpoint = "token.php";
function RequestAuthorizationToken() {
if (authorizationEndpoint) {
var a = new XMLHttpRequest();
a.open("GET", authorizationEndpoint);
a.setRequestHeader("Content-Type", "application/x-www-form-urlencoded");
a.send("");
a.onload = function() {
var token = JSON.parse(atob(this.responseText.split(".")[1]));
serviceRegion.value = token.region;
authorizationToken = this.responseText;
subscriptionKey.disabled = true;
subscriptionKey.value = "using authorization token (hit F5 to refresh)";
console.log("Got an authorization token: " + token);
}
}
}
</script>
<script>
// status fields and start button in UI
var phraseDiv;
var statusDiv;
var startIntentRecognizeAsyncButton;
// subscription key, region, and appId for LUIS services.
var subscriptionKey, serviceRegion, appId;
var authorizationToken;
var SpeechSDK;
var recognizer;
document.addEventListener("DOMContentLoaded", function () {
startIntentRecognizeAsyncButton = document.getElementById("startIntentRecognizeAsyncButton");
subscriptionKey = document.getElementById("subscriptionKey");
serviceRegion = document.getElementById("serviceRegion");
appId = document.getElementById("appId");
phraseDiv = document.getElementById("phraseDiv");
statusDiv = document.getElementById("statusDiv");
startIntentRecognizeAsyncButton.addEventListener("click", function () {
startIntentRecognizeAsyncButton.disabled = true;
phraseDiv.innerHTML = "";
statusDiv.innerHTML = "";
});
if (!!window.SpeechSDK) {
SpeechSDK = window.SpeechSDK;
startIntentRecognizeAsyncButton.disabled = false;
document.getElementById('content').style.display = 'block';
document.getElementById('warning').style.display = 'none';
// in case we have a function for getting an authorization token, call it.
if (typeof RequestAuthorizationToken === "function") {
RequestAuthorizationToken();
}
}
});
</script>
Tworzenie konfiguracji mowy
Przed zainicjowaniem obiektu należy utworzyć konfigurację SpeechRecognizer , która używa klucza subskrypcji i regionu subskrypcji. Wstaw ten kod w metodzie startRecognizeOnceAsyncButton.addEventListener() .
Uwaga
Zestaw SDK rozpoznawania mowy będzie domyślnie rozpoznawany przy użyciu języka en-us. Zobacz Jak rozpoznawać mowę , aby uzyskać informacje na temat wybierania języka źródłowego.
// if we got an authorization token, use the token. Otherwise use the provided subscription key
var speechConfig;
if (authorizationToken) {
speechConfig = SpeechSDK.SpeechConfig.fromAuthorizationToken(authorizationToken, serviceRegion.value);
} else {
if (subscriptionKey.value === "" || subscriptionKey.value === "subscription") {
alert("Please enter your Microsoft Azure AI Speech subscription key!");
return;
}
startIntentRecognizeAsyncButton.disabled = false;
speechConfig = SpeechSDK.SpeechConfig.fromSubscription(subscriptionKey.value, serviceRegion.value);
}
speechConfig.speechRecognitionLanguage = "en-US";
Tworzenie konfiguracji audio
Teraz musisz utworzyć AudioConfig obiekt wskazujący urządzenie wejściowe. Wstaw ten kod w metodzie startIntentRecognizeAsyncButton.addEventListener() bezpośrednio poniżej konfiguracji usługi Mowa.
var audioConfig = SpeechSDK.AudioConfig.fromDefaultMicrophoneInput();
Inicjowanie intencjiRecognizer
Teraz utwórzmy IntentRecognizer obiekt przy użyciu SpeechConfig utworzonych wcześniej obiektów i AudioConfig . Wstaw ten kod w metodzie startIntentRecognizeAsyncButton.addEventListener() .
recognizer = new SpeechSDK.IntentRecognizer(speechConfig, audioConfig);
Dodawanie elementu LanguageUnderstandingModel i intents
Musisz skojarzyć element z rozpoznawaniem LanguageUnderstandingModel intencji i dodać intencje, które chcesz rozpoznać. Użyjemy intencji ze wstępnie utworzonej domeny na potrzeby automatyzacji domu.
Wstaw ten kod poniżej pliku IntentRecognizer. Upewnij się, że zastąpisz "YourLanguageUnderstandingAppId" element identyfikatorem aplikacji usługi LUIS.
if (appId.value !== "" && appId.value !== "YOUR_LANGUAGE_UNDERSTANDING_APP_ID") {
var lm = SpeechSDK.LanguageUnderstandingModel.fromAppId(appId.value);
recognizer.addAllIntents(lm);
}
Uwaga
Zestaw SPEECH SDK obsługuje tylko punkty końcowe usługi LUIS w wersji 2.0. Należy ręcznie zmodyfikować adres URL punktu końcowego w wersji 3.0 znaleziony w przykładowym polu zapytania, aby użyć wzorca adresu URL w wersji 2.0. Punkty końcowe usługi LUIS w wersji 2.0 zawsze są zgodne z jednym z następujących dwóch wzorców:
https://{AzureResourceName}.cognitiveservices.azure.com/luis/v2.0/apps/{app-id}?subscription-key={subkey}&verbose=true&q=https://{Region}.api.cognitive.microsoft.com/luis/v2.0/apps/{app-id}?subscription-key={subkey}&verbose=true&q=
Rozpoznawanie intencji
IntentRecognizer Z obiektu wywołasz metodę recognizeOnceAsync() . Ta metoda pozwala usłudze Rozpoznawanie mowy wiedzieć, że wysyłasz pojedynczą frazę do rozpoznawania i że gdy fraza zostanie zidentyfikowana, aby przestać rozpoznawać mowę.
Wstaw ten kod poniżej dodawania modelu:
recognizer.recognizeOnceAsync(
function (result) {
window.console.log(result);
phraseDiv.innerHTML = result.text + "\r\n";
statusDiv.innerHTML += "(continuation) Reason: " + SpeechSDK.ResultReason[result.reason];
switch (result.reason) {
case SpeechSDK.ResultReason.RecognizedSpeech:
statusDiv.innerHTML += " Text: " + result.text;
break;
case SpeechSDK.ResultReason.RecognizedIntent:
statusDiv.innerHTML += " Text: " + result.text + " IntentId: " + result.intentId;
// The actual JSON returned from Language Understanding is a bit more complex to get to, but it is available for things like
// the entity name and type if part of the intent.
statusDiv.innerHTML += " Intent JSON: " + result.properties.getProperty(SpeechSDK.PropertyId.LanguageUnderstandingServiceResponse_JsonResult);
phraseDiv.innerHTML += result.properties.getProperty(SpeechSDK.PropertyId.LanguageUnderstandingServiceResponse_JsonResult) + "\r\n";
break;
case SpeechSDK.ResultReason.NoMatch:
var noMatchDetail = SpeechSDK.NoMatchDetails.fromResult(result);
statusDiv.innerHTML += " NoMatchReason: " + SpeechSDK.NoMatchReason[noMatchDetail.reason];
break;
case SpeechSDK.ResultReason.Canceled:
var cancelDetails = SpeechSDK.CancellationDetails.fromResult(result);
statusDiv.innerHTML += " CancellationReason: " + SpeechSDK.CancellationReason[cancelDetails.reason];
if (cancelDetails.reason === SpeechSDK.CancellationReason.Error) {
statusDiv.innerHTML += ": " + cancelDetails.errorDetails;
}
break;
}
statusDiv.innerHTML += "\r\n";
startIntentRecognizeAsyncButton.disabled = false;
},
function (err) {
window.console.log(err);
phraseDiv.innerHTML += "ERROR: " + err;
startIntentRecognizeAsyncButton.disabled = false;
});
Sprawdzanie kodu
<!DOCTYPE html>
<html>
<head>
<title>Microsoft Cognitive Services Speech SDK JavaScript Quickstart</title>
<meta charset="utf-8" />
</head>
<body style="font-family:'Helvetica Neue',Helvetica,Arial,sans-serif; font-size:13px;">
<div id="warning">
<h1 style="font-weight:500;">Speech Recognition Speech SDK not found (microsoft.cognitiveservices.speech.sdk.bundle.js missing).</h1>
</div>
<div id="content" style="display:none">
<table width="100%">
<tr>
<td></td>
<td><h1 style="font-weight:500;">Microsoft Cognitive Services Speech SDK JavaScript Quickstart</h1></td>
</tr>
<tr>
<td align="right"><a href="https://docs.microsoft.com/azure/cognitive-services/speech-service/quickstarts/intent-recognition?pivots=programming-language-csharp#create-a-luis-app-for-intent-recognition" target="_blank">LUIS Primary Key</a>:</td>
<td><input id="subscriptionKey" type="text" size="40" value="subscription"></td>
</tr>
<tr>
<td align="right">LUIS Location</td>
<td><input id="serviceRegion" type="text" size="40" value="YourServiceRegion"></td>
</tr>
<tr>
<td align="right">LUIS App ID:</td>
<td><input id="appId" type="text" size="60" value="YOUR_LANGUAGE_UNDERSTANDING_APP_ID"></td>
</tr>
<tr>
<td></td>
<td><button id="startIntentRecognizeAsyncButton">Start Intent Recognition</button></td>
</tr>
<tr>
<td align="right" valign="top">Input Text</td>
<td><textarea id="phraseDiv" style="display: inline-block;width:500px;height:200px"></textarea></td>
</tr>
<tr>
<td align="right" valign="top">Result</td>
<td><textarea id="statusDiv" style="display: inline-block;width:500px;height:100px"></textarea></td>
</tr>
</table>
</div>
<!-- Speech SDK reference sdk. -->
<script src="https://aka.ms/csspeech/jsbrowserpackageraw"></script>
<!-- Speech SDK USAGE -->
<script>
// status fields and start button in UI
var phraseDiv;
var statusDiv;
var startIntentRecognizeAsyncButton;
// subscription key and region for speech services.
var subscriptionKey, serviceRegion, appId;
var SpeechSDK;
var recognizer;
document.addEventListener("DOMContentLoaded", function () {
startIntentRecognizeAsyncButton = document.getElementById("startIntentRecognizeAsyncButton");
subscriptionKey = document.getElementById("subscriptionKey");
serviceRegion = document.getElementById("serviceRegion");
appId = document.getElementById("appId");
phraseDiv = document.getElementById("phraseDiv");
statusDiv = document.getElementById("statusDiv");
startIntentRecognizeAsyncButton.addEventListener("click", function () {
startIntentRecognizeAsyncButton.disabled = true;
phraseDiv.innerHTML = "";
statusDiv.innerHTML = "";
let audioConfig = SpeechSDK.AudioConfig.fromDefaultMicrophoneInput();
if (subscriptionKey.value === "" || subscriptionKey.value === "subscription") {
alert("Please enter your Microsoft Cognitive Services Speech subscription key!");
startIntentRecognizeAsyncButton.disabled = false;
return;
}
var speechConfig = SpeechSDK.SpeechConfig.fromSubscription(subscriptionKey.value, serviceRegion.value);
speechConfig.speechRecognitionLanguage = "en-US";
recognizer = new SpeechSDK.IntentRecognizer(speechConfig, audioConfig);
// Set up a Language Understanding Model from Language Understanding Intelligent Service (LUIS).
// See https://www.luis.ai/home for more information on LUIS.
if (appId.value !== "" && appId.value !== "YOUR_LANGUAGE_UNDERSTANDING_APP_ID") {
var lm = SpeechSDK.LanguageUnderstandingModel.fromAppId(appId.value);
recognizer.addAllIntents(lm);
}
recognizer.recognizeOnceAsync(
function (result) {
window.console.log(result);
phraseDiv.innerHTML = result.text + "\r\n";
statusDiv.innerHTML += "(continuation) Reason: " + SpeechSDK.ResultReason[result.reason];
switch (result.reason) {
case SpeechSDK.ResultReason.RecognizedSpeech:
statusDiv.innerHTML += " Text: " + result.text;
break;
case SpeechSDK.ResultReason.RecognizedIntent:
statusDiv.innerHTML += " Text: " + result.text + " IntentId: " + result.intentId;
// The actual JSON returned from Language Understanding is a bit more complex to get to, but it is available for things like
// the entity name and type if part of the intent.
statusDiv.innerHTML += " Intent JSON: " + result.properties.getProperty(SpeechSDK.PropertyId.LanguageUnderstandingServiceResponse_JsonResult);
phraseDiv.innerHTML += result.properties.getProperty(SpeechSDK.PropertyId.LanguageUnderstandingServiceResponse_JsonResult) + "\r\n";
break;
case SpeechSDK.ResultReason.NoMatch:
var noMatchDetail = SpeechSDK.NoMatchDetails.fromResult(result);
statusDiv.innerHTML += " NoMatchReason: " + SpeechSDK.NoMatchReason[noMatchDetail.reason];
break;
case SpeechSDK.ResultReason.Canceled:
var cancelDetails = SpeechSDK.CancellationDetails.fromResult(result);
statusDiv.innerHTML += " CancellationReason: " + SpeechSDK.CancellationReason[cancelDetails.reason];
if (cancelDetails.reason === SpeechSDK.CancellationReason.Error) {
statusDiv.innerHTML += ": " + cancelDetails.errorDetails;
}
break;
}
statusDiv.innerHTML += "\r\n";
startIntentRecognizeAsyncButton.disabled = false;
},
function (err) {
window.console.log(err);
phraseDiv.innerHTML += "ERROR: " + err;
startIntentRecognizeAsyncButton.disabled = false;
});
});
if (!!window.SpeechSDK) {
SpeechSDK = window.SpeechSDK;
startIntentRecognizeAsyncButton.disabled = false;
document.getElementById('content').style.display = 'block';
document.getElementById('warning').style.display = 'none';
}
});
</script>
</body>
</html>
Tworzenie źródła tokenu (opcjonalnie)
W przypadku, gdy chcesz udostępnić stronę internetową na serwerze internetowym, możesz opcjonalnie podać źródło tokenu dla swojej aplikacji pokazowej. W ten sposób Twój klucz subskrypcji nigdy nie opuści serwera, ale jednocześnie umożliwi użytkownikom korzystanie z możliwości funkcji rozpoznawania mowy bez wprowadzania przez nich kodu autoryzacji.
Utwórz nowy plik o nazwie token.php. W tym przykładzie założono, że serwer internetowy obsługuje język skryptów PHP z włączonym curl. Wprowadź następujące kod:
<?php
header('Access-Control-Allow-Origin: ' . $_SERVER['SERVER_NAME']);
// Replace with your own subscription key and service region (e.g., "westus").
$subscriptionKey = 'YourSubscriptionKey';
$region = 'YourServiceRegion';
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'https://' . $region . '.api.cognitive.microsoft.com/sts/v1.0/issueToken');
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, '{}');
curl_setopt($ch, CURLOPT_HTTPHEADER, array('Content-Type: application/json', 'Ocp-Apim-Subscription-Key: ' . $subscriptionKey));
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
echo curl_exec($ch);
?>
Uwaga
Tokeny autoryzacji mają tylko ograniczony okres istnienia. Ten uproszczony przykład nie pokazuje, jak automatycznie odświeżać tokeny autoryzacji. Jako użytkownik możesz ręcznie ponownie załadować stronę lub nacisnąć klawisz F5, aby odświeżyć.
Lokalne kompilowanie i uruchamianie przykładu
Aby uruchomić aplikację, kliknij dwukrotnie plik index.html lub otwórz plik index.html za pomocą swojej ulubionej przeglądarki internetowej. Spowoduje to wyświetlenie prostego graficznego interfejsu użytkownika umożliwiającego wprowadzenie klucza usługi LUIS, regionu usługi LUIS i identyfikatora aplikacji usługi LUIS. Po wprowadzeniu tych pól możesz kliknąć odpowiedni przycisk, aby wyzwolić rozpoznawanie przy użyciu mikrofonu.
Uwaga
Ta metoda nie działa w przeglądarce Safari. W przeglądarce Safari przykładowa strona internetowa musi być hostowana na serwerze internetowym; Przeglądarka Safari nie zezwala na używanie mikrofonu przez witryny internetowe załadowane z pliku lokalnego.
Kompilowanie i uruchamianie przykładu za pomocą serwera internetowego
Aby uruchomić aplikację, otwórz ulubioną przeglądarkę internetową i wskaż jej publiczny adres URL hostujący folder, wprowadź region usługi LUIS oraz identyfikator aplikacji usługi LUIS i wyzwól rozpoznawanie przy użyciu mikrofonu. W przypadku skonfigurowania uzyska token ze źródła tokenu i rozpocznie rozpoznawanie poleceń mówionych.
Dokumentacja referencyjna | Package (PyPi) | Dodatkowe przykłady w witrynie GitHub
W tym przewodniku Szybki start użyjesz zestawu SDK rozpoznawania mowy i usługi Language Understanding (LUIS) do rozpoznawania intencji z danych audio przechwyconych z mikrofonu. W szczególności użyjesz zestawu SDK usługi Mowa do przechwytywania mowy i wstępnie utworzonej domeny z usługi LUIS, aby zidentyfikować intencje automatyzacji domu, takie jak włączanie i wyłączanie światła.
Wymagania wstępne
- Subskrypcja platformy Azure — utwórz bezpłatnie
- Utwórz zasób języka w witrynie Azure Portal. Możesz użyć warstwy cenowej bezpłatna (
F0), aby wypróbować usługę, a następnie uaktualnić ją do warstwy płatnej dla środowiska produkcyjnego. Tym razem nie będzie potrzebny zasób usługi Mowa. - Pobierz klucz zasobu języka i region. Po wdrożeniu zasobu Language wybierz pozycję Przejdź do zasobu , aby wyświetlić klucze i zarządzać nimi.
Tworzenie aplikacji usługi LUIS na potrzeby rozpoznawania intencji
Aby ukończyć przewodnik Szybki start dotyczący rozpoznawania intencji, musisz utworzyć konto usługi LUIS i projekt przy użyciu portalu usługi LUIS w wersji zapoznawczej. Ten przewodnik Szybki start wymaga subskrypcji usługi LUIS w regionie, w którym jest dostępne rozpoznawanie intencji. Subskrypcja usługi Mowa nie jest wymagana.
Najpierw musisz utworzyć konto usługi LUIS i aplikację przy użyciu portalu usługi LUIS w wersji zapoznawczej. Utworzona aplikacja USŁUGI LUIS będzie używać wstępnie utworzonej domeny do automatyzacji domu, która zapewnia intencje, jednostki i przykładowe wypowiedzi. Po zakończeniu będziesz mieć punkt końcowy usługi LUIS uruchomiony w chmurze, który można wywołać przy użyciu zestawu SPEECH SDK.
Postępuj zgodnie z tymi instrukcjami, aby utworzyć aplikację usługi LUIS:
Gdy wszystko będzie gotowe, potrzebne będą cztery elementy:
- Ponowne publikowanie za pomocą przełączania mowy
- Klucz podstawowy usługi LUIS
- Lokalizacja usługi LUIS
- Identyfikator aplikacji usługi LUIS
Tutaj można znaleźć te informacje w portalu usługi LUIS w wersji zapoznawczej:
W portalu wersji zapoznawczej usługi LUIS wybierz aplikację, a następnie wybierz przycisk Publikuj .
Wybierz miejsce produkcyjne, jeśli używasz
en-USopcji Zmień ustawienia, a następnie przełącz opcję Zamiana mowy na pozycję Wł. Następnie wybierz przycisk Publikuj .Ważne
Stosowanie priming mowy jest zdecydowanie zalecane, ponieważ poprawi dokładność rozpoznawania mowy.
W portalu usługi LUIS w wersji zapoznawczej wybierz pozycję Zarządzaj, a następnie wybierz pozycję Zasoby platformy Azure. Na tej stronie znajdziesz klucz i lokalizację usługi LUIS (czasami nazywaną regionem) zasobu przewidywania usługi LUIS.
Po utworzeniu klucza i lokalizacji potrzebny będzie identyfikator aplikacji. Wybierz Ustawienia. Identyfikator aplikacji jest dostępny na tej stronie.
Otwórz projekt
- Otwórz preferowane środowisko IDE.
- Utwórz nowy projekt i utwórz plik o nazwie
quickstart.py, a następnie otwórz go.
Zacznij od kodu kociołowego
Dodajmy kod, który działa jako szkielet naszego projektu.
import azure.cognitiveservices.speech as speechsdk
print("Say something...")
Tworzenie konfiguracji mowy
Przed zainicjowaniem IntentRecognizer obiektu należy utworzyć konfigurację, która używa klucza i lokalizacji dla zasobu przewidywania usługi LUIS.
Wstaw ten kod w pliku quickstart.py. Upewnij się, że zaktualizowano następujące wartości:
- Zastąp
"YourLanguageUnderstandingSubscriptionKey"element kluczem przewidywania usługi LUIS. - Zastąp
"YourLanguageUnderstandingServiceRegion"element lokalizacją usługi LUIS. Używanie identyfikatora regionu z regionu
Napiwek
Jeśli potrzebujesz pomocy w znalezieniu tych wartości, zobacz Tworzenie aplikacji usługi LUIS na potrzeby rozpoznawania intencji.
Ważne
Pamiętaj, aby usunąć klucz z kodu po zakończeniu i nigdy nie publikować go publicznie. W przypadku środowiska produkcyjnego użyj bezpiecznego sposobu przechowywania i uzyskiwania dostępu do poświadczeń, takich jak usługa Azure Key Vault. Aby uzyskać więcej informacji, zobacz artykuł Dotyczący zabezpieczeń usług Azure AI.
# Set up the config for the intent recognizer (remember that this uses the Language Understanding key, not the Speech Services key)!
intent_config = speechsdk.SpeechConfig(
subscription="YourLanguageUnderstandingSubscriptionKey",
region="YourLanguageUnderstandingServiceRegion")
Ten przykład tworzy SpeechConfig obiekt przy użyciu klucza i regionu usługi LUIS. Aby uzyskać pełną listę dostępnych metod, zobacz SpeechConfig Class (Klasa SpeechConfig).
Zestaw SDK rozpoznawania mowy będzie domyślnie rozpoznawany przy użyciu języka en-us. Zobacz Jak rozpoznawać mowę , aby uzyskać informacje na temat wybierania języka źródłowego.
Inicjowanie intencjiRecognizer
Teraz utwórzmy element IntentRecognizer. Wstaw ten kod bezpośrednio poniżej konfiguracji usługi Mowa.
# Set up the intent recognizer
intent_recognizer = speechsdk.intent.IntentRecognizer(speech_config=intent_config)
Dodawanie elementu LanguageUnderstandingModel i intents
Musisz skojarzyć element z rozpoznawaniem LanguageUnderstandingModel intencji i dodać intencje, które chcesz rozpoznać. Użyjemy intencji ze wstępnie utworzonej domeny na potrzeby automatyzacji domu.
Wstaw ten kod poniżej pliku IntentRecognizer. Upewnij się, że zastąpisz "YourLanguageUnderstandingAppId" element identyfikatorem aplikacji usługi LUIS.
Napiwek
Jeśli potrzebujesz pomocy w znalezieniu tej wartości, zobacz Tworzenie aplikacji usługi LUIS na potrzeby rozpoznawania intencji.
# set up the intents that are to be recognized. These can be a mix of simple phrases and
# intents specified through a LanguageUnderstanding Model.
model = speechsdk.intent.LanguageUnderstandingModel(app_id="YourLanguageUnderstandingAppId")
intents = [
(model, "HomeAutomation.TurnOn"),
(model, "HomeAutomation.TurnOff"),
("This is a test.", "test"),
("Switch to channel 34.", "34"),
("what's the weather like", "weather"),
]
intent_recognizer.add_intents(intents)
W tym przykładzie użyto add_intents() funkcji , aby dodać listę jawnie zdefiniowanych intencji. Jeśli chcesz dodać wszystkie intencje z modelu, użyj add_all_intents(model) modelu i przekaż go.
Rozpoznawanie intencji
IntentRecognizer Z obiektu wywołasz metodę recognize_once() . Ta metoda pozwala usłudze Rozpoznawanie mowy wiedzieć, że wysyłasz pojedynczą frazę do rozpoznawania i że gdy fraza zostanie zidentyfikowana, aby przestać rozpoznawać mowę.
Wstaw ten kod poniżej modelu.
intent_result = intent_recognizer.recognize_once()
Wyświetlanie wyników rozpoznawania (lub błędów)
Gdy wynik rozpoznawania jest zwracany przez usługę rozpoznawania mowy, należy wykonać z nim coś. Zachowamy prostotę i wyświetlimy wynik w konsoli.
Pod wywołaniem recognize_once()metody dodaj ten kod.
# Check the results
if intent_result.reason == speechsdk.ResultReason.RecognizedIntent:
print("Recognized: \"{}\" with intent id `{}`".format(intent_result.text, intent_result.intent_id))
elif intent_result.reason == speechsdk.ResultReason.RecognizedSpeech:
print("Recognized: {}".format(intent_result.text))
elif intent_result.reason == speechsdk.ResultReason.NoMatch:
print("No speech could be recognized: {}".format(intent_result.no_match_details))
elif intent_result.reason == speechsdk.ResultReason.Canceled:
print("Intent recognition canceled: {}".format(intent_result.cancellation_details.reason))
if intent_result.cancellation_details.reason == speechsdk.CancellationReason.Error:
print("Error details: {}".format(intent_result.cancellation_details.error_details))
Sprawdzanie kodu
W tym momencie kod powinien wyglądać następująco.
Uwaga
Dodaliśmy komentarze do tej wersji.
# Copyright (c) Microsoft. All rights reserved.
# Licensed under the MIT license. See LICENSE.md file in the project root for full license information.
# <skeleton>
import azure.cognitiveservices.speech as speechsdk
print("Say something...")
# </skeleton>
"""performs one-shot intent recognition from input from the default microphone"""
# <create_speech_configuration>
# Set up the config for the intent recognizer (remember that this uses the Language Understanding key, not the Speech Services key)!
intent_config = speechsdk.SpeechConfig(
subscription="YourLanguageUnderstandingSubscriptionKey",
region="YourLanguageUnderstandingServiceRegion")
# </create_speech_configuration>
# <create_intent_recognizer>
# Set up the intent recognizer
intent_recognizer = speechsdk.intent.IntentRecognizer(speech_config=intent_config)
# </create_intent_recognizer>
# <add_intents>
# set up the intents that are to be recognized. These can be a mix of simple phrases and
# intents specified through a LanguageUnderstanding Model.
model = speechsdk.intent.LanguageUnderstandingModel(app_id="YourLanguageUnderstandingAppId")
intents = [
(model, "HomeAutomation.TurnOn"),
(model, "HomeAutomation.TurnOff"),
("This is a test.", "test"),
("Switch to channel 34.", "34"),
("what's the weather like", "weather"),
]
intent_recognizer.add_intents(intents)
# </add_intents>
# To add all of the possible intents from a LUIS model to the recognizer, uncomment the line below:
# intent_recognizer.add_all_intents(model)
# Starts intent recognition, and returns after a single utterance is recognized. The end of a
# single utterance is determined by listening for silence at the end or until a maximum of about 30
# seconds of audio is processed. It returns the recognition text as result.
# Note: Since recognize_once() returns only a single utterance, it is suitable only for single
# shot recognition like command or query.
# For long-running multi-utterance recognition, use start_continuous_recognition() instead.
# <recognize_intent>
intent_result = intent_recognizer.recognize_once()
# </recognize_intent>
# <print_results>
# Check the results
if intent_result.reason == speechsdk.ResultReason.RecognizedIntent:
print("Recognized: \"{}\" with intent id `{}`".format(intent_result.text, intent_result.intent_id))
elif intent_result.reason == speechsdk.ResultReason.RecognizedSpeech:
print("Recognized: {}".format(intent_result.text))
elif intent_result.reason == speechsdk.ResultReason.NoMatch:
print("No speech could be recognized: {}".format(intent_result.no_match_details))
elif intent_result.reason == speechsdk.ResultReason.Canceled:
print("Intent recognition canceled: {}".format(intent_result.cancellation_details.reason))
if intent_result.cancellation_details.reason == speechsdk.CancellationReason.Error:
print("Error details: {}".format(intent_result.cancellation_details.error_details))
# </print_results>
Kompilowanie i uruchamianie aplikacji
Uruchom przykład z konsoli programu lub w środowisku IDE:
python quickstart.py
Następne 15 sekund mowy z mikrofonu zostanie rozpoznane i zarejestrowane w oknie konsoli.
Dokumentacja referencyjna Package (Go) | Dodatkowe przykłady w witrynie GitHub |
Zestaw SPEECH SDK dla języka Go nie obsługuje rozpoznawania intencji. Wybierz inny język programowania lub odwołanie do języka Go i przykłady połączone od początku tego artykułu.
Dokumentacja referencyjna Package (download) | Dodatkowe przykłady w usłudze GitHub |
Zestaw SPEECH SDK dla języka Objective-C obsługuje rozpoznawanie intencji, ale nie dołączyliśmy jeszcze tutaj przewodnika. Wybierz inny język programowania, aby rozpocząć pracę i poznać koncepcje, lub zapoznaj się z dokumentacją języka Objective-C i przykładami połączonymi od początku tego artykułu.
Dokumentacja referencyjna Package (download) | Dodatkowe przykłady w usłudze GitHub |
Zestaw SPEECH SDK dla języka Swift obsługuje rozpoznawanie intencji, ale nie dołączyliśmy tu przewodnika. Wybierz inny język programowania, aby rozpocząć pracę i dowiedzieć się więcej o pojęciach, lub zapoznaj się z dokumentacją i przykładami usługi Swift połączonymi od początku tego artykułu.
Interfejs API REST zamiany mowy na tekst — dokumentacja | interfejsu API REST zamiany mowy na tekst w celu uzyskania krótkiej dokumentacji | audio Dodatkowe przykłady w usłudze GitHub
Możesz użyć interfejsu API REST do rozpoznawania intencji, ale jeszcze nie dołączyliśmy tutaj przewodnika. Wybierz inny język programowania, aby rozpocząć pracę i dowiedzieć się więcej o pojęciach.
Interfejs wiersza polecenia rozpoznawania mowy obsługuje rozpoznawanie intencji, ale nie dołączyliśmy tu przewodnika. Wybierz inny język programowania, aby rozpocząć pracę i dowiedzieć się więcej na temat pojęć, lub zobacz Omówienie interfejsu wiersza polecenia usługi Mowa, aby uzyskać więcej informacji na temat interfejsu wiersza polecenia.