Interfejs API GPT-4o Realtime dla mowy i dźwięku (wersja zapoznawcza)
Uwaga
Ta funkcja jest obecnie w publicznej wersji zapoznawczej. Ta wersja zapoznawcza jest udostępniana bez umowy dotyczącej poziomu usług i nie zalecamy korzystania z niej w przypadku obciążeń produkcyjnych. Niektóre funkcje mogą być nieobsługiwane lub ograniczone. Aby uzyskać więcej informacji, zobacz Uzupełniające warunki korzystania z wersji zapoznawczych platformy Microsoft Azure.
Interfejs API usługi Azure OpenAI GPT-4o Realtime dla mowy i dźwięku jest częścią rodziny modeli GPT-4o, która obsługuje interakcje konwersacyjne "mowa w, wypowiedź". Interfejs API audio realtime GPT-4o jest przeznaczony do obsługi interakcji konwersacyjnych w czasie rzeczywistym, małych opóźnień, dzięki czemu doskonale nadaje się do przypadków użycia obejmujących interakcje na żywo między użytkownikiem a modelem, takie jak agenci pomocy technicznej klienta, asystentzy głosowi i tłumacze w czasie rzeczywistym.
Większość użytkowników interfejsu API czasu rzeczywistego musi dostarczać i odbierać dźwięk od użytkownika końcowego w czasie rzeczywistym, w tym aplikacje korzystające z usługi WebRTC lub systemu telefonii. Interfejs API czasu rzeczywistego nie jest przeznaczony do łączenia się bezpośrednio z urządzeniami użytkowników końcowych i opiera się na integracji klientów w celu zakończenia strumieni audio użytkownika końcowego.
Obsługiwane modele
Obecnie tylko gpt-4o-realtime-preview wersja: 2024-10-01-preview obsługuje dźwięk w czasie rzeczywistym.
Model gpt-4o-realtime-preview jest dostępny dla wdrożeń globalnych w regionach Wschodnie stany USA 2 i Szwecja Środkowa.
Ważne
System przechowuje monity i zakończenia zgodnie z opisem w sekcji "Korzystanie z danych i dostęp do monitorowania nadużyć" warunków produktu specyficznych dla usługi dla usługi Azure OpenAI Service, z wyjątkiem tego, że ograniczony wyjątek nie ma zastosowania. Monitorowanie nadużyć zostanie włączone do korzystania z interfejsu gpt-4o-realtime-preview API nawet dla klientów, którzy w przeciwnym razie są zatwierdzani w celu monitorowania zmodyfikowanych nadużyć.
Obsługa interfejsu API
Obsługa interfejsu API czasu rzeczywistego została po raz pierwszy dodana w wersji 2024-10-01-previewinterfejsu API .
Uwaga
Aby uzyskać więcej informacji na temat interfejsu API i architektury, zobacz repozytorium audio GPT-4o usługi Azure OpenAI GPT-4o w czasie rzeczywistym w usłudze GitHub.
Wdrażanie modelu na potrzeby dźwięku w czasie rzeczywistym
Aby wdrożyć gpt-4o-realtime-preview model w portalu azure AI Foundry:
- Przejdź do portalu usługi Azure AI Foundry i upewnij się, że zalogowano się przy użyciu subskrypcji platformy Azure, która ma zasób usługi Azure OpenAI Service (z wdrożeniami modelu lub bez).
- Wybierz plac zabaw audio w czasie rzeczywistym w obszarze Place zabaw w okienku po lewej stronie.
- Wybierz pozycję Utwórz nowe wdrożenie , aby otworzyć okno wdrażania.
- Wyszukaj i wybierz
gpt-4o-realtime-previewmodel, a następnie wybierz pozycję Potwierdź. - W kreatorze wdrażania upewnij się, że wybrano
2024-10-01wersję modelu. - Postępuj zgodnie z instrukcjami kreatora, aby zakończyć wdrażanie modelu.
Teraz, gdy masz wdrożenie gpt-4o-realtime-preview modelu, możesz wchodzić z nim w interakcje w czasie rzeczywistym w portalu Azure AI Foundry w czasie rzeczywistym — plac zabaw audio lub interfejs API czasu rzeczywistego.
Używanie dźwięku GPT-4o w czasie rzeczywistym
Aby porozmawiać z wdrożonym gpt-4o-realtime-preview modelem na placu zabaw audio w czasie rzeczywistym rozwiązania Azure AI Foundry, wykonaj następujące kroki:
Przejdź do strony usługi Azure OpenAI Service w portalu usługi Azure AI Foundry. Upewnij się, że zalogowano się przy użyciu subskrypcji platformy Azure, która ma zasób usługi Azure OpenAI Service i wdrożony
gpt-4o-realtime-previewmodel.Wybierz plac zabaw audio w czasie rzeczywistym w obszarze Place zabaw w okienku po lewej stronie.
Wybierz wdrożony
gpt-4o-realtime-previewmodel z listy rozwijanej Wdrażanie .Wybierz pozycję Włącz mikrofon , aby zezwolić przeglądarce na dostęp do mikrofonu. Jeśli udzielono już uprawnień, możesz pominąć ten krok.
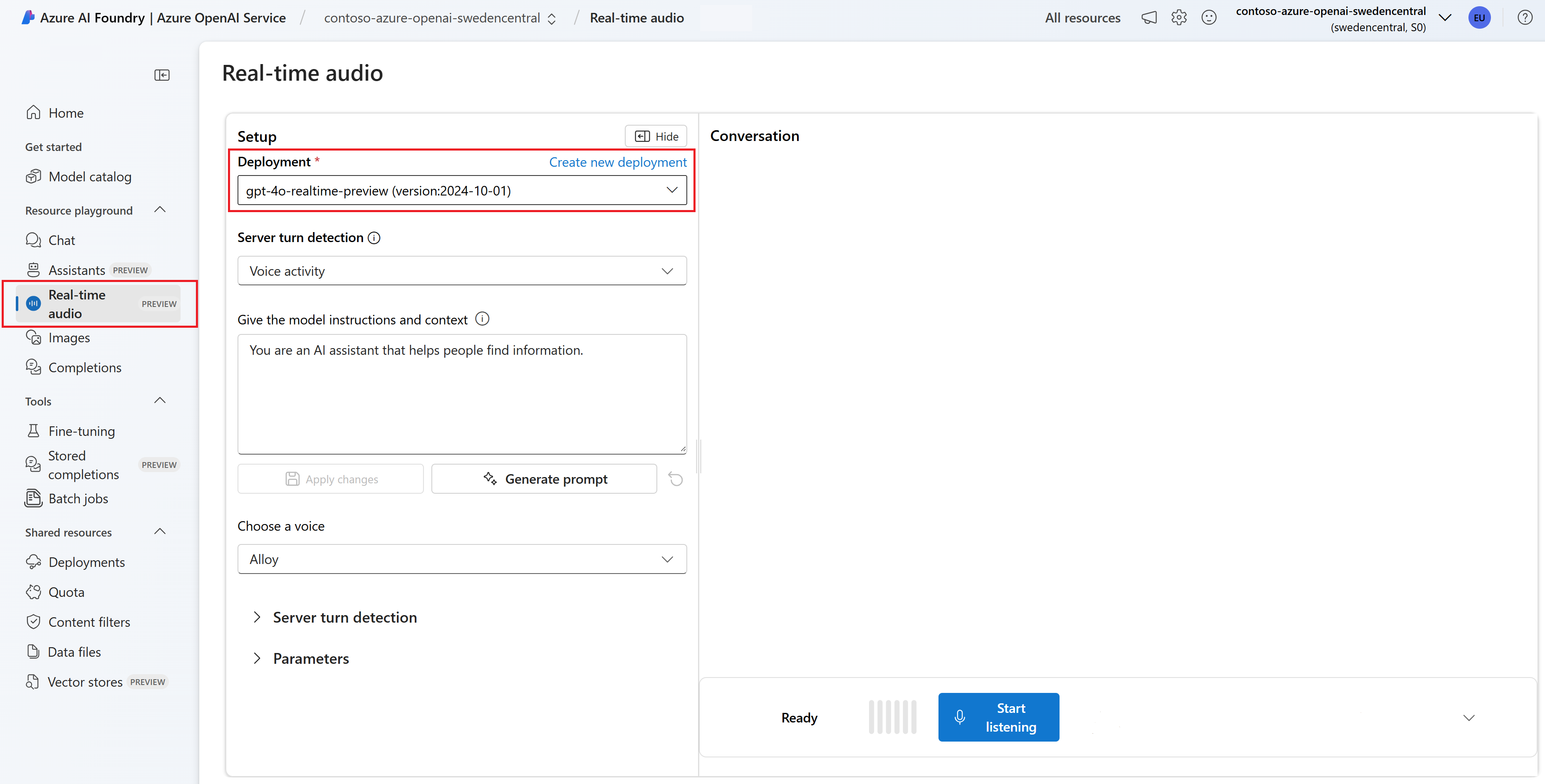
Opcjonalnie możesz edytować zawartość w polu tekstowym Nadaj modelowi instrukcje i kontekst . Przekaż instrukcje dotyczące sposobu działania modelu i dowolnego kontekstu, do którego powinien się odwoływać podczas generowania odpowiedzi. Możesz opisać osobowość asystenta, określić na jakie pytania powinien lub nie powinien odpowiadać i określić, w jaki sposób ma formatować odpowiedzi.
Opcjonalnie zmień ustawienia, takie jak próg, dopełnienie prefiksu i czas trwania ciszy.
Wybierz pozycję Rozpocznij nasłuchiwanie , aby rozpocząć sesję. Możesz mówić do mikrofonu, aby rozpocząć czat.
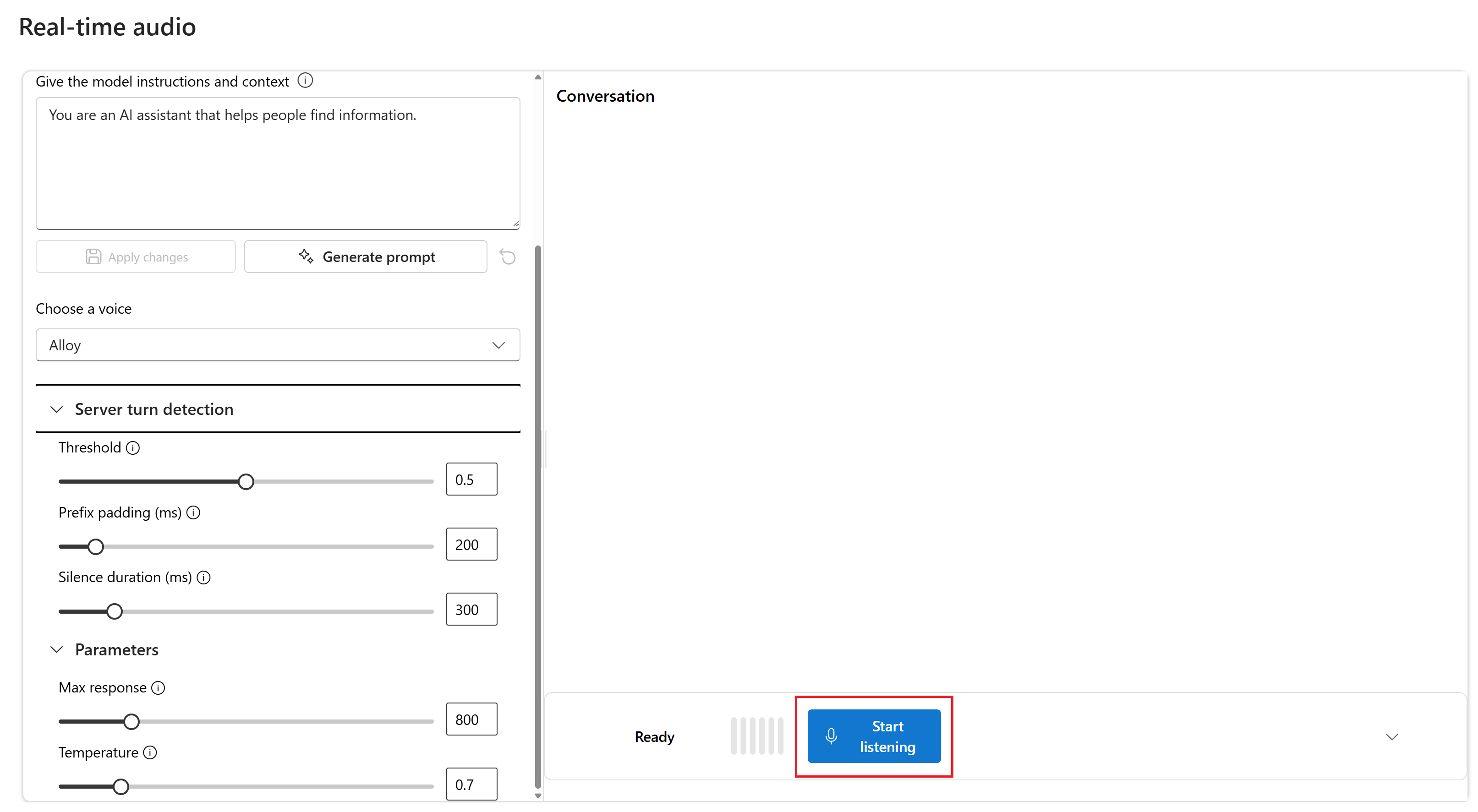
Możesz przerwać czat w dowolnym momencie, mówiąc. Możesz zakończyć czat, wybierając przycisk Zatrzymaj nasłuchiwanie .


Wymagania wstępne
- Subskrypcja platformy Azure — utwórz bezpłatnie
- obsługa Node.js LTS lub ESM.
- Zasób usługi Azure OpenAI utworzony w regionach Wschodnie stany USA 2 lub Szwecja Środkowa. Zobacz Dostępność regionów.
- Następnie należy wdrożyć
gpt-4o-realtime-previewmodel przy użyciu zasobu usługi Azure OpenAI. Aby uzyskać więcej informacji, zobacz Tworzenie zasobu i wdrażanie modelu za pomocą usługi Azure OpenAI.
Wymagania wstępne dotyczące identyfikatora entra firmy Microsoft
W przypadku zalecanego uwierzytelniania bez klucza za pomocą identyfikatora Entra firmy Microsoft należy wykonać następujące czynności:
- Zainstaluj interfejs wiersza polecenia platformy Azure używany do uwierzytelniania bez klucza za pomocą identyfikatora Entra firmy Microsoft.
Cognitive Services UserPrzypisz rolę do konta użytkownika. Role można przypisać w witrynie Azure Portal w obszarze Kontrola dostępu (IAM)>Dodawanie przypisania roli.
Wdrażanie modelu na potrzeby dźwięku w czasie rzeczywistym
Aby wdrożyć gpt-4o-realtime-preview model w portalu azure AI Foundry:
- Przejdź do portalu usługi Azure AI Foundry i upewnij się, że zalogowano się przy użyciu subskrypcji platformy Azure, która ma zasób usługi Azure OpenAI Service (z wdrożeniami modelu lub bez).
- Wybierz plac zabaw audio w czasie rzeczywistym w obszarze Place zabaw w okienku po lewej stronie.
- Wybierz pozycję Utwórz nowe wdrożenie , aby otworzyć okno wdrażania.
- Wyszukaj i wybierz
gpt-4o-realtime-previewmodel, a następnie wybierz pozycję Potwierdź. - W kreatorze wdrażania upewnij się, że wybrano
2024-10-01wersję modelu. - Postępuj zgodnie z instrukcjami kreatora, aby zakończyć wdrażanie modelu.
Teraz, gdy masz wdrożenie gpt-4o-realtime-preview modelu, możesz wchodzić z nim w interakcje w czasie rzeczywistym w portalu Azure AI Foundry w czasie rzeczywistym — plac zabaw audio lub interfejs API czasu rzeczywistego.
Konfiguruj
Utwórz nowy folder
realtime-audio-quickstartzawierający aplikację i otwórz program Visual Studio Code w tym folderze za pomocą następującego polecenia:mkdir realtime-audio-quickstart && code realtime-audio-quickstartUtwórz element
package.jsonza pomocą następującego polecenia:npm init -yZaktualizuj element do ecMAScript
package.jsonza pomocą następującego polecenia:npm pkg set type=moduleZainstaluj bibliotekę klienta audio w czasie rzeczywistym dla języka JavaScript za pomocą następujących funkcji:
npm install https://github.com/Azure-Samples/aoai-realtime-audio-sdk/releases/download/js/v0.5.2/rt-client-0.5.2.tgzAby uzyskać zalecane uwierzytelnianie bez klucza za pomocą identyfikatora Entra firmy Microsoft, zainstaluj pakiet za
@azure/identitypomocą polecenia:npm install @azure/identity
Pobieranie informacji o zasobie
Aby uwierzytelnić aplikację przy użyciu zasobu usługi Azure OpenAI, musisz pobrać następujące informacje:
| Nazwa zmiennej | Wartość |
|---|---|
AZURE_OPENAI_ENDPOINT |
Tę wartość można znaleźć w sekcji Klucze i punkt końcowy podczas badania zasobu w witrynie Azure Portal. |
AZURE_OPENAI_DEPLOYMENT_NAME |
Ta wartość będzie odpowiadać nazwie niestandardowej wybranej dla wdrożenia podczas wdrażania modelu. Tę wartość można znaleźć w obszarze Wdrożenia modelu zarządzania>zasobami w witrynie Azure Portal. |
OPENAI_API_VERSION |
Dowiedz się więcej o wersjach interfejsu API. |
Dowiedz się więcej na temat uwierzytelniania bez klucza i ustawiania zmiennych środowiskowych.
Uwaga
Aby użyć zalecanego uwierzytelniania bez klucza z zestawem SDK, upewnij się, że zmienna AZURE_OPENAI_API_KEY środowiskowa nie jest ustawiona.
Tekst w dźwięku wychodzący
text-in-audio-out.jsUtwórz plik przy użyciu następującego kodu:import { DefaultAzureCredential } from "@azure/identity"; import { LowLevelRTClient } from "rt-client"; import dotenv from "dotenv"; dotenv.config(); async function text_in_audio_out() { // Set environment variables or edit the corresponding values here. const endpoint = process.env["AZURE_OPENAI_ENDPOINT"] || "yourEndpoint"; const deployment = "gpt-4o-realtime-preview"; if (!endpoint || !deployment) { throw new Error("You didn't set the environment variables."); } const client = new LowLevelRTClient(new URL(endpoint), new DefaultAzureCredential(), { deployment: deployment }); try { await client.send({ type: "response.create", response: { modalities: ["audio", "text"], instructions: "Please assist the user." } }); for await (const message of client.messages()) { switch (message.type) { case "response.done": { break; } case "error": { console.error(message.error); break; } case "response.audio_transcript.delta": { console.log(`Received text delta: ${message.delta}`); break; } case "response.audio.delta": { const buffer = Buffer.from(message.delta, "base64"); console.log(`Received ${buffer.length} bytes of audio data.`); break; } } if (message.type === "response.done" || message.type === "error") { break; } } } finally { client.close(); } } await text_in_audio_out();Zaloguj się do platformy Azure przy użyciu następującego polecenia:
az loginUruchom plik JavaScript.
node text-in-audio-out.js
Poczekaj chwilę, aby uzyskać odpowiedź.
Wyjście
Skrypt pobiera odpowiedź z modelu i wyświetla odebrane dane transkrypcji i audio.
Dane wyjściowe będą wyglądać podobnie do następujących:
Received text delta: Hello
Received text delta: !
Received text delta: How
Received text delta: can
Received text delta: I
Received 4800 bytes of audio data.
Received 7200 bytes of audio data.
Received text delta: help
Received 12000 bytes of audio data.
Received text delta: you
Received text delta: today
Received text delta: ?
Received 12000 bytes of audio data.
Received 12000 bytes of audio data.
Received 12000 bytes of audio data.
Received 24000 bytes of audio data.
Przykład aplikacji internetowej
Nasz przykład internetowy w języku JavaScript w usłudze GitHub pokazuje, jak używać interfejsu API GPT-4o Realtime do interakcji z modelem w czasie rzeczywistym. Przykładowy kod zawiera prosty interfejs internetowy, który przechwytuje dźwięk z mikrofonu użytkownika i wysyła go do modelu na potrzeby przetwarzania. Model odpowiada tekstem i dźwiękiem, który przykładowy kod jest renderowany w interfejsie internetowym.
Przykładowy kod można uruchomić lokalnie na maszynie, wykonując następujące kroki. Aby uzyskać najbardziej aktualne instrukcje, zapoznaj się z repozytorium w witrynie GitHub .
Jeśli nie masz zainstalowanego Node.js, pobierz i zainstaluj wersję LTS Node.js.
Sklonuj repozytorium na komputer lokalny:
git clone https://github.com/Azure-Samples/aoai-realtime-audio-sdk.gitPrzejdź do
javascript/samples/webfolderu w preferowanym edytorze kodu.cd ./javascript/samplesUruchom
download-pkg.ps1polecenie lubdownload-pkg.shpobierz wymagane pakiety.Przejdź do
webfolderu z./javascript/samplesfolderu .cd ./webUruchom polecenie
npm install, aby zainstalować zależności pakietów.Uruchom polecenie
npm run dev, aby uruchomić serwer internetowy, przechodząc do wszystkich monitów o uprawnienia zapory zgodnie z potrzebami.Przejdź do dowolnego z podanych identyfikatorów URI z danych wyjściowych konsoli (takich jak
http://localhost:5173/) w przeglądarce.Wprowadź następujące informacje w interfejsie internetowym:
- Punkt końcowy: punkt końcowy zasobu usługi Azure OpenAI. Nie musisz dołączać ścieżki
/realtime. Przykładową strukturą może byćhttps://my-azure-openai-resource-from-portal.openai.azure.com. - Klucz interfejsu API: odpowiedni klucz interfejsu API dla zasobu usługi Azure OpenAI.
- Wdrożenie: nazwa
gpt-4o-realtime-previewmodelu wdrożonego w poprzedniej sekcji. - Komunikat systemowy: Opcjonalnie możesz podać komunikat systemowy, taki jak "Zawsze mówisz jak przyjazny pirat".
- Temperatura: opcjonalnie możesz podać niestandardową temperaturę.
- Głos: opcjonalnie możesz wybrać głos.
- Punkt końcowy: punkt końcowy zasobu usługi Azure OpenAI. Nie musisz dołączać ścieżki
Wybierz przycisk Rekord, aby rozpocząć sesję. Zaakceptuj uprawnienia do korzystania z mikrofonu, jeśli zostanie wyświetlony monit.
W głównych danych wyjściowych powinien zostać wyświetlony
<< Session Started >>komunikat. Następnie możesz mówić do mikrofonu, aby rozpocząć czat.Możesz przerwać czat w dowolnym momencie, mówiąc. Możesz zakończyć czat, wybierając przycisk Zatrzymaj.
Wymagania wstępne
- Subskrypcja platformy Azure. Utwórz je bezpłatnie.
- Środowisko Python w wersji 3.8 lub nowszej. Zalecamy używanie języka Python w wersji 3.10 lub nowszej, ale wymagana jest co najmniej wersja python 3.8. Jeśli nie masz zainstalowanej odpowiedniej wersji języka Python, możesz postępować zgodnie z instrukcjami w samouczku języka Python programu VS Code, aby uzyskać najprostszy sposób instalowania języka Python w systemie operacyjnym.
- Zasób usługi Azure OpenAI utworzony w regionach Wschodnie stany USA 2 lub Szwecja Środkowa. Zobacz Dostępność regionów.
- Następnie należy wdrożyć
gpt-4o-realtime-previewmodel przy użyciu zasobu usługi Azure OpenAI. Aby uzyskać więcej informacji, zobacz Tworzenie zasobu i wdrażanie modelu za pomocą usługi Azure OpenAI.
Wymagania wstępne dotyczące identyfikatora entra firmy Microsoft
W przypadku zalecanego uwierzytelniania bez klucza za pomocą identyfikatora Entra firmy Microsoft należy wykonać następujące czynności:
- Zainstaluj interfejs wiersza polecenia platformy Azure używany do uwierzytelniania bez klucza za pomocą identyfikatora Entra firmy Microsoft.
Cognitive Services UserPrzypisz rolę do konta użytkownika. Role można przypisać w witrynie Azure Portal w obszarze Kontrola dostępu (IAM)>Dodawanie przypisania roli.
Wdrażanie modelu na potrzeby dźwięku w czasie rzeczywistym
Aby wdrożyć gpt-4o-realtime-preview model w portalu azure AI Foundry:
- Przejdź do portalu usługi Azure AI Foundry i upewnij się, że zalogowano się przy użyciu subskrypcji platformy Azure, która ma zasób usługi Azure OpenAI Service (z wdrożeniami modelu lub bez).
- Wybierz plac zabaw audio w czasie rzeczywistym w obszarze Place zabaw w okienku po lewej stronie.
- Wybierz pozycję Utwórz nowe wdrożenie , aby otworzyć okno wdrażania.
- Wyszukaj i wybierz
gpt-4o-realtime-previewmodel, a następnie wybierz pozycję Potwierdź. - W kreatorze wdrażania upewnij się, że wybrano
2024-10-01wersję modelu. - Postępuj zgodnie z instrukcjami kreatora, aby zakończyć wdrażanie modelu.
Teraz, gdy masz wdrożenie gpt-4o-realtime-preview modelu, możesz wchodzić z nim w interakcje w czasie rzeczywistym w portalu Azure AI Foundry w czasie rzeczywistym — plac zabaw audio lub interfejs API czasu rzeczywistego.
Konfiguruj
Utwórz nowy folder
realtime-audio-quickstartzawierający aplikację i otwórz program Visual Studio Code w tym folderze za pomocą następującego polecenia:mkdir realtime-audio-quickstart && code realtime-audio-quickstartTworzenie środowiska wirtualnego. Jeśli masz już zainstalowany język Python w wersji 3.10 lub nowszej, możesz utworzyć środowisko wirtualne przy użyciu następujących poleceń:
Aktywowanie środowiska języka Python oznacza, że po uruchomieniu
pythonlubpipw wierszu polecenia należy użyć interpretera języka Python zawartego.venvw folderze aplikacji. Możesz użyćdeactivatepolecenia , aby zamknąć środowisko wirtualne języka Python i później ponownie aktywować je w razie potrzeby.Napiwek
Zalecamy utworzenie i aktywowanie nowego środowiska języka Python w celu zainstalowania pakietów potrzebnych na potrzeby tego samouczka. Nie instaluj pakietów w globalnej instalacji języka Python. Zawsze należy używać środowiska wirtualnego lub conda podczas instalowania pakietów języka Python. W przeciwnym razie możesz przerwać globalną instalację języka Python.
Zainstaluj bibliotekę klienta audio w czasie rzeczywistym dla języka Python za pomocą następujących elementów:
pip install "https://github.com/Azure-Samples/aoai-realtime-audio-sdk/releases/download/py%2Fv0.5.3/rtclient-0.5.3.tar.gz"Aby uzyskać zalecane uwierzytelnianie bez klucza za pomocą identyfikatora Entra firmy Microsoft, zainstaluj pakiet za
azure-identitypomocą polecenia:pip install azure-identity
Pobieranie informacji o zasobie
Aby uwierzytelnić aplikację przy użyciu zasobu usługi Azure OpenAI, musisz pobrać następujące informacje:
| Nazwa zmiennej | Wartość |
|---|---|
AZURE_OPENAI_ENDPOINT |
Tę wartość można znaleźć w sekcji Klucze i punkt końcowy podczas badania zasobu w witrynie Azure Portal. |
AZURE_OPENAI_DEPLOYMENT_NAME |
Ta wartość będzie odpowiadać nazwie niestandardowej wybranej dla wdrożenia podczas wdrażania modelu. Tę wartość można znaleźć w obszarze Wdrożenia modelu zarządzania>zasobami w witrynie Azure Portal. |
OPENAI_API_VERSION |
Dowiedz się więcej o wersjach interfejsu API. |
Dowiedz się więcej na temat uwierzytelniania bez klucza i ustawiania zmiennych środowiskowych.
Tekst w dźwięku wychodzący
text-in-audio-out.pyUtwórz plik przy użyciu następującego kodu:import base64 import asyncio from azure.identity.aio import DefaultAzureCredential from rtclient import ( ResponseCreateMessage, RTLowLevelClient, ResponseCreateParams ) # Set environment variables or edit the corresponding values here. endpoint = os.environ["AZURE_OPENAI_ENDPOINT"] deployment = "gpt-4o-realtime-preview" async def text_in_audio_out(): async with RTLowLevelClient( url=endpoint, azure_deployment=deployment, token_credential=DefaultAzureCredential(), ) as client: await client.send( ResponseCreateMessage( response=ResponseCreateParams( modalities={"audio", "text"}, instructions="Please assist the user." ) ) ) done = False while not done: message = await client.recv() match message.type: case "response.done": done = True case "error": done = True print(message.error) case "response.audio_transcript.delta": print(f"Received text delta: {message.delta}") case "response.audio.delta": buffer = base64.b64decode(message.delta) print(f"Received {len(buffer)} bytes of audio data.") case _: pass async def main(): await text_in_audio_out() asyncio.run(main())Uruchom plik języka Python.
python text-in-audio-out.py
Poczekaj chwilę, aby uzyskać odpowiedź.
Wyjście
Skrypt pobiera odpowiedź z modelu i wyświetla odebrane dane transkrypcji i audio.
Dane wyjściowe będą wyglądać podobnie do następujących:
Received text delta: Hello
Received text delta: !
Received text delta: How
Received 4800 bytes of audio data.
Received 7200 bytes of audio data.
Received text delta: can
Received 12000 bytes of audio data.
Received text delta: I
Received text delta: assist
Received text delta: you
Received 12000 bytes of audio data.
Received 12000 bytes of audio data.
Received text delta: today
Received text delta: ?
Received 12000 bytes of audio data.
Received 12000 bytes of audio data.
Received 12000 bytes of audio data.
Received 12000 bytes of audio data.
Received 28800 bytes of audio data.
Wymagania wstępne
- Subskrypcja platformy Azure — utwórz bezpłatnie
- obsługa Node.js LTS lub ESM.
- Język TypeScript zainstalowany globalnie.
- Zasób usługi Azure OpenAI utworzony w regionach Wschodnie stany USA 2 lub Szwecja Środkowa. Zobacz Dostępność regionów.
- Następnie należy wdrożyć
gpt-4o-realtime-previewmodel przy użyciu zasobu usługi Azure OpenAI. Aby uzyskać więcej informacji, zobacz Tworzenie zasobu i wdrażanie modelu za pomocą usługi Azure OpenAI.
Wymagania wstępne dotyczące identyfikatora entra firmy Microsoft
W przypadku zalecanego uwierzytelniania bez klucza za pomocą identyfikatora Entra firmy Microsoft należy wykonać następujące czynności:
- Zainstaluj interfejs wiersza polecenia platformy Azure używany do uwierzytelniania bez klucza za pomocą identyfikatora Entra firmy Microsoft.
Cognitive Services UserPrzypisz rolę do konta użytkownika. Role można przypisać w witrynie Azure Portal w obszarze Kontrola dostępu (IAM)>Dodawanie przypisania roli.
Wdrażanie modelu na potrzeby dźwięku w czasie rzeczywistym
Aby wdrożyć gpt-4o-realtime-preview model w portalu azure AI Foundry:
- Przejdź do portalu usługi Azure AI Foundry i upewnij się, że zalogowano się przy użyciu subskrypcji platformy Azure, która ma zasób usługi Azure OpenAI Service (z wdrożeniami modelu lub bez).
- Wybierz plac zabaw audio w czasie rzeczywistym w obszarze Place zabaw w okienku po lewej stronie.
- Wybierz pozycję Utwórz nowe wdrożenie , aby otworzyć okno wdrażania.
- Wyszukaj i wybierz
gpt-4o-realtime-previewmodel, a następnie wybierz pozycję Potwierdź. - W kreatorze wdrażania upewnij się, że wybrano
2024-10-01wersję modelu. - Postępuj zgodnie z instrukcjami kreatora, aby zakończyć wdrażanie modelu.
Teraz, gdy masz wdrożenie gpt-4o-realtime-preview modelu, możesz wchodzić z nim w interakcje w czasie rzeczywistym w portalu Azure AI Foundry w czasie rzeczywistym — plac zabaw audio lub interfejs API czasu rzeczywistego.
Konfiguruj
Utwórz nowy folder
realtime-audio-quickstartzawierający aplikację i otwórz program Visual Studio Code w tym folderze za pomocą następującego polecenia:mkdir realtime-audio-quickstart && code realtime-audio-quickstartUtwórz element
package.jsonza pomocą następującego polecenia:npm init -yZaktualizuj element do ecMAScript
package.jsonza pomocą następującego polecenia:npm pkg set type=moduleZainstaluj bibliotekę klienta audio w czasie rzeczywistym dla języka JavaScript za pomocą następujących funkcji:
npm install https://github.com/Azure-Samples/aoai-realtime-audio-sdk/releases/download/js/v0.5.2/rt-client-0.5.2.tgzAby uzyskać zalecane uwierzytelnianie bez klucza za pomocą identyfikatora Entra firmy Microsoft, zainstaluj pakiet za
@azure/identitypomocą polecenia:npm install @azure/identity
Pobieranie informacji o zasobie
Aby uwierzytelnić aplikację przy użyciu zasobu usługi Azure OpenAI, musisz pobrać następujące informacje:
| Nazwa zmiennej | Wartość |
|---|---|
AZURE_OPENAI_ENDPOINT |
Tę wartość można znaleźć w sekcji Klucze i punkt końcowy podczas badania zasobu w witrynie Azure Portal. |
AZURE_OPENAI_DEPLOYMENT_NAME |
Ta wartość będzie odpowiadać nazwie niestandardowej wybranej dla wdrożenia podczas wdrażania modelu. Tę wartość można znaleźć w obszarze Wdrożenia modelu zarządzania>zasobami w witrynie Azure Portal. |
OPENAI_API_VERSION |
Dowiedz się więcej o wersjach interfejsu API. |
Dowiedz się więcej na temat uwierzytelniania bez klucza i ustawiania zmiennych środowiskowych.
Uwaga
Aby użyć zalecanego uwierzytelniania bez klucza z zestawem SDK, upewnij się, że zmienna AZURE_OPENAI_API_KEY środowiskowa nie jest ustawiona.
Tekst w dźwięku wychodzący
text-in-audio-out.tsUtwórz plik przy użyciu następującego kodu:import { DefaultAzureCredential } from "@azure/identity"; import { LowLevelRTClient } from "rt-client"; import dotenv from "dotenv"; dotenv.config(); async function text_in_audio_out() { // Set environment variables or edit the corresponding values here. const endpoint: string = process.env["AZURE_OPENAI_ENDPOINT"] || "yourEndpoint"; const deployment = "gpt-4o-realtime-preview"; if (!endpoint || !deployment) { throw new Error("You didn't set the environment variables."); } const client = new LowLevelRTClient( new URL(endpoint), new DefaultAzureCredential(), {deployment: deployment} ); try { await client.send({ type: "response.create", response: { modalities: ["audio", "text"], instructions: "Please assist the user." } }); for await (const message of client.messages()) { switch (message.type) { case "response.done": { break; } case "error": { console.error(message.error); break; } case "response.audio_transcript.delta": { console.log(`Received text delta: ${message.delta}`); break; } case "response.audio.delta": { const buffer = Buffer.from(message.delta, "base64"); console.log(`Received ${buffer.length} bytes of audio data.`); break; } } if (message.type === "response.done" || message.type === "error") { break; } } } finally { client.close(); } } await text_in_audio_out();Utwórz plik do
tsconfig.jsontranspilowania kodu TypeScript i skopiuj następujący kod dla języka ECMAScript.{ "compilerOptions": { "module": "NodeNext", "target": "ES2022", // Supports top-level await "moduleResolution": "NodeNext", "skipLibCheck": true, // Avoid type errors from node_modules "strict": true // Enable strict type-checking options }, "include": ["*.ts"] }Transpiluj z języka TypeScript do języka JavaScript.
tscZaloguj się do platformy Azure przy użyciu następującego polecenia:
az loginUruchom kod za pomocą następującego polecenia:
node text-in-audio-out.js
Poczekaj chwilę, aby uzyskać odpowiedź.
Wyjście
Skrypt pobiera odpowiedź z modelu i wyświetla odebrane dane transkrypcji i audio.
Dane wyjściowe będą wyglądać podobnie do następujących:
Received text delta: Hello
Received text delta: !
Received text delta: How
Received text delta: can
Received text delta: I
Received 4800 bytes of audio data.
Received 7200 bytes of audio data.
Received text delta: help
Received 12000 bytes of audio data.
Received text delta: you
Received text delta: today
Received text delta: ?
Received 12000 bytes of audio data.
Received 12000 bytes of audio data.
Received 12000 bytes of audio data.
Received 24000 bytes of audio data.
Powiązana zawartość
- Dowiedz się więcej o sposobie korzystania z interfejsu API czasu rzeczywistego
- Zobacz dokumentację interfejsu API czasu rzeczywistego
- Dowiedz się więcej o limitach przydziałów i limitach usługi Azure OpenAI