Dostosowywanie modelu za pomocą dostrajania
Usługa Azure OpenAI Service umożliwia dostosowanie naszych modeli do osobistych zestawów danych przy użyciu procesu znanego jako dostrajanie. Ten etap dostosowywania pozwala w pełni wykorzystać usługę, zapewniając:
- Wyniki o wyższej jakości niż to, co można uzyskać tylko z monitów inżynieryjnych
- Możliwość trenowania na więcej przykładów niż może mieścić się w maksymalnym limicie kontekstu żądania modelu.
- Oszczędności tokenów z powodu krótszych monitów
- Żądania o mniejsze opóźnienia, szczególnie w przypadku korzystania z mniejszych modeli.
W przeciwieństwie do uczenia kilku strzałów, dostrajanie precyzyjne poprawia model poprzez trenowanie na wiele innych przykładów, niż można zmieścić się w monicie, co pozwala uzyskać lepsze wyniki w wielu zadaniach. Ponieważ dostrajanie precyzyjne dostosowuje wagi modelu podstawowego, aby poprawić wydajność określonego zadania, nie trzeba uwzględniać tak wielu przykładów ani instrukcji w monicie. Oznacza to, że mniej tekstu jest wysyłanych i mniej tokenów przetwarzanych na każdym wywołaniu interfejsu API, potencjalnie oszczędza koszt i poprawia opóźnienie żądań.
Używamy metody LoRA lub przybliżenia niskiej rangi, aby dostosować modele w sposób, który zmniejsza ich złożoność bez znaczącego wpływu na wydajność. Ta metoda działa przez przybliżenie oryginalnej macierzy o wysokiej rangi z niższą rangą, dzięki czemu tylko dostrajanie mniejszego podzestawu ważnych parametrów w fazie trenowania nadzorowanego, dzięki czemu model jest bardziej zarządzany i wydajny. Dla użytkowników sprawia to, że szkolenie jest szybsze i bardziej przystępne niż inne techniki.
W portalu usługi Azure AI Foundry dostępne są dwa unikatowe środowiska dostrajania:
- Widok centrum/projektu — obsługuje dostrajanie modeli od wielu dostawców, takich jak Azure OpenAI, Meta Llama, Microsoft Phi itp.
- Widok skoncentrowany na usłudze Azure OpenAI — obsługuje tylko dostrajanie modeli Azure OpenAI, ale obsługuje dodatkowe funkcje, takie jak integracja wagi i biases (W&B).
Jeśli dostrajasz tylko modele usługi Azure OpenAI, zalecamy precyzyjne dostrajanie interfejsu Azure OpenAI, które jest dostępne, przechodząc do strony https://oai.azure.com.
Wymagania wstępne
- Przeczytaj przewodnik po dostrajaniu interfejsu Azure OpenAI dotyczący używania interfejsu OpenAI.
- Subskrypcja Azure. Utwórz je bezpłatnie.
- Zasób usługi Azure OpenAI, który znajduje się w regionie obsługującym dostrajanie modelu Azure OpenAI. Sprawdź tabelę podsumowania modelu i dostępność regionów, aby uzyskać listę dostępnych modeli według regionów i obsługiwanych funkcji. Aby uzyskać więcej informacji, zobacz Tworzenie zasobu i wdrażanie modelu za pomocą usługi Azure OpenAI.
- Dostęp do dostrajania wymaga współautora interfejsu OpenAI usług Cognitive Services.
- Jeśli nie masz jeszcze dostępu do wyświetlania limitu przydziału i wdrażania modeli w portalu usługi Azure AI Foundry, będziesz potrzebować dodatkowych uprawnień.
Modele
Następujące modele obsługują dostrajanie:
babbage-002davinci-002gpt-35-turbo(0613)gpt-35-turbo(1106)gpt-35-turbo(0125)gpt-4(0613)*gpt-4o(2024-08-06)gpt-4o-mini(2024-07-18)
* Dostrajanie tego modelu jest obecnie dostępne w publicznej wersji zapoznawczej.
Możesz też dostosować wcześniej dostosowany model, sformatowany jako model podstawowy.ft-{jobid}.
Zapoznaj się ze stroną modeli, aby sprawdzić, które regiony obecnie obsługują dostrajanie.
Zapoznaj się z przepływem pracy rozwiązania Azure AI Foundry
Poświać chwilę na przejrzenie przepływu pracy dostrajania na potrzeby korzystania z usługi Azure AI Foundry:
- Przygotuj dane szkoleniowe i weryfikacyjne.
- Użyj kreatora Tworzenie modelu niestandardowego w portalu Azure AI Foundry, aby wytrenować model niestandardowy.
- Wybierz model podstawowy.
- Wybierz dane szkoleniowe.
- Opcjonalnie wybierz dane weryfikacji.
- Opcjonalnie skonfiguruj parametry zadania dla zadania dostrajania.
- Przejrzyj wybrane opcje i wytrenuj nowy model niestandardowy.
- Sprawdź stan niestandardowego modelu dostosowanego.
- Wdróż model niestandardowy do użycia.
- Użyj modelu niestandardowego.
- Opcjonalnie przeanalizuj model niestandardowy pod kątem wydajności i dopasowania.
Przygotowywanie danych treningowych i weryfikacyjnych
Dane szkoleniowe i zestawy danych do walidacji składają się z przykładów wejściowych i wyjściowych pokazujących, jak ma działać model.
Różne typy modeli wymagają innego formatu danych treningowych.
Używane dane trenowania i walidacji muszą być sformatowane jako dokument JSON Lines (JSONL). W przypadku gpt-35-turbo (wszystkich wersji) gpt-4zestaw gpt-4o-minigpt-4odanych dostrajania musi być sformatowany w formacie konwersacji używanym przez interfejs API uzupełniania czatów.
Jeśli chcesz zapoznać się z przewodnikiem krok po kroku dotyczącym dostrajania gpt-4o-mini modelu (2024-07-18), zapoznaj się z samouczkiem dostosowywania interfejsu Azure OpenAI.
Przykładowy format pliku
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "Is Xbox better than PlayStation?"}, {"role": "assistant", "content": "I apologize, but I cannot provide personal opinions. My primary job is to assist you with any issues related to your Xbox device. Do you have any Xbox-related issues that need addressing?"}]}
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "Can I play PC games on my Xbox?"}, {"role": "assistant", "content": "While Xbox consoles don't natively support PC games, they can play an array of Xbox games, many of which are also available on PC. Can I assist you with finding games compatible with your Xbox device?"}]}
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "I'm having trouble connecting my Xbox to the Wi-Fi."}, {"role": "assistant", "content": "No worries, let's go through the network settings on your Xbox. Can you please tell me what happens when you try to connect it to the Wi-Fi?"}]}
Multi-turn chat file format Azure OpenAI
Obsługiwane jest również wiele kolei konwersacji w jednym wierszu pliku szkoleniowego jsonl. Aby pominąć dostosowywanie określonych komunikatów asystenta, dodaj opcjonalną weight parę wartości klucza. Obecnie weight można ustawić wartość 0 lub 1.
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already.", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "William Shakespeare", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "384,400 kilometers", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters.", "weight": 1}]}
Kończenia czatów z wizją
{"messages": [{"role": "user", "content": [{"type": "text", "text": "What's in this image?"}, {"type": "image_url", "image_url": {"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png"}}]}, {"role": "assistant", "content": "The image appears to be a watercolor painting of a city skyline, featuring tall buildings and a recognizable structure often associated with Seattle, like the Space Needle. The artwork uses soft colors and brushstrokes to create a somewhat abstract and artistic representation of the cityscape."}]}
Oprócz formatu JSONL pliki danych trenowania i walidacji muszą być zakodowane w formacie UTF-8 i zawierać znak porządku bajtów (BOM). Rozmiar pliku musi być mniejszy niż 512 MB.
Tworzenie zestawów danych trenowania i walidacji
Tym więcej przykładów treningowych, tym lepiej. Zadania dostrajania nie będą kontynuowane bez co najmniej 10 przykładów treningowych, ale taka mała liczba nie wystarczy, aby zauważalnie wpłynąć na odpowiedzi modelu. Najlepszym rozwiązaniem jest zapewnienie setek, jeśli nie tysięcy, przykładów szkoleniowych, które mają być skuteczne.
Ogólnie rzecz biorąc, podwojenie rozmiaru zestawu danych może prowadzić do liniowego wzrostu jakości modelu. Należy jednak pamiętać, że przykłady niskiej jakości mogą negatywnie wpływać na wydajność. Jeśli wytrenujesz model na dużej ilości danych wewnętrznych, bez uprzedniego przycinania zestawu danych tylko do najlepszych przykładów jakości, można utworzyć model, który działa znacznie gorzej niż oczekiwano.
Korzystanie z Kreatora tworzenia modelu niestandardowego
Usługa Azure AI Foundry udostępnia Kreatora tworzenia modelu niestandardowego, dzięki czemu możesz interaktywnie tworzyć i trenować dostosowany model dla zasobu platformy Azure.
Otwórz usługę Azure AI Foundry na stronie https://oai.azure.com/ i zaloguj się przy użyciu poświadczeń, które mają dostęp do zasobu usługi Azure OpenAI. Podczas przepływu pracy logowania wybierz odpowiedni katalog, subskrypcję platformy Azure i zasób usługi Azure OpenAI.
W portalu Azure AI Foundry przejdź do okienka Narzędzia > dostrajania i wybierz pozycję Dostosuj model.
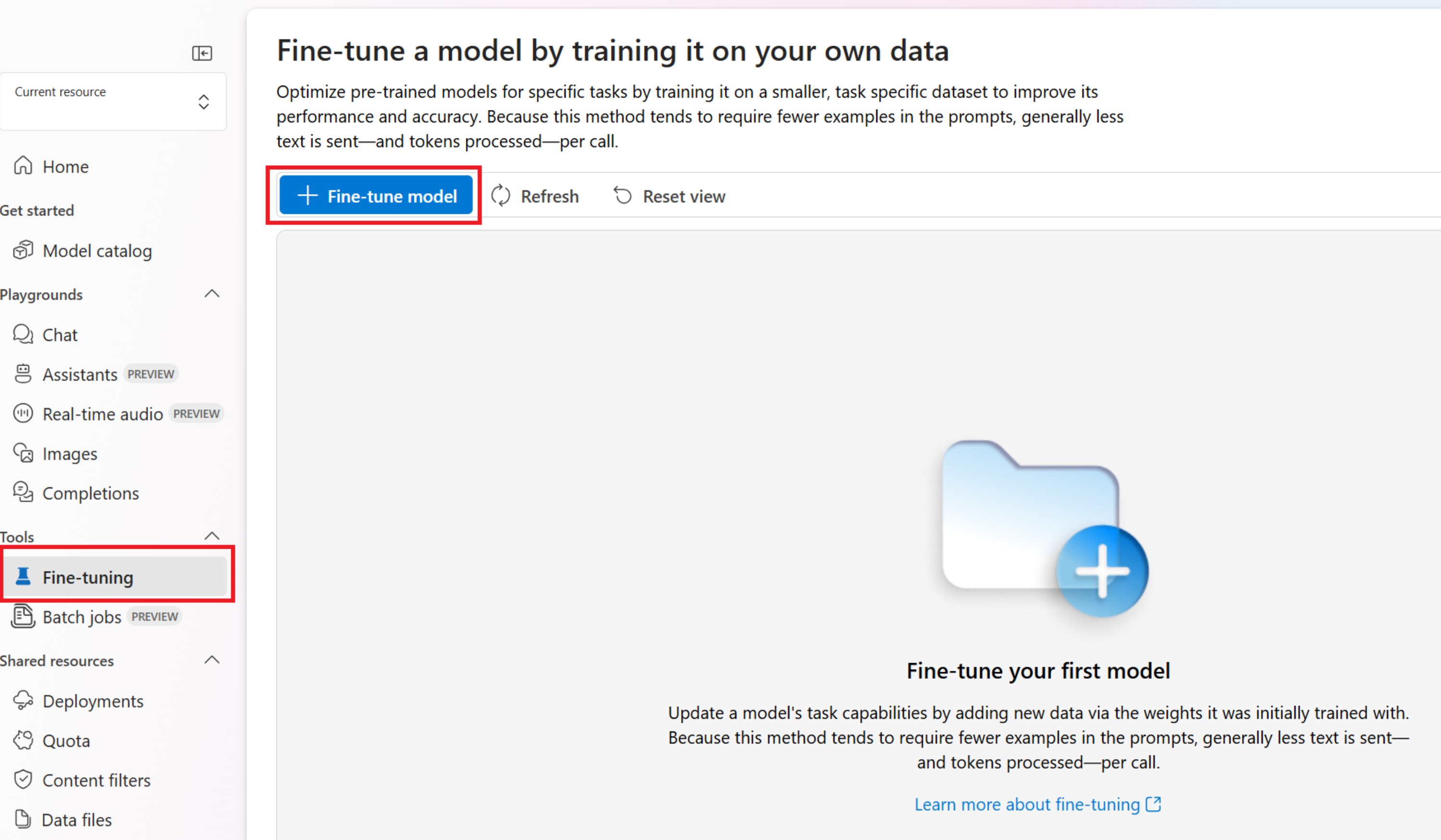

Zostanie otwarty kreator Tworzenie modelu niestandardowego.
Wybieranie modelu podstawowego
Pierwszym krokiem tworzenia modelu niestandardowego jest wybranie modelu podstawowego. Okienko Model podstawowy umożliwia wybranie modelu podstawowego do użycia dla modelu niestandardowego. Wybór wpływa zarówno na wydajność, jak i koszt modelu.
Wybierz model podstawowy z listy rozwijanej Typ modelu podstawowego, a następnie wybierz przycisk Dalej, aby kontynuować.
Model niestandardowy można utworzyć na podstawie jednego z następujących dostępnych modeli podstawowych:
babbage-002davinci-002gpt-35-turbo(0613)gpt-35-turbo(1106)gpt-35-turbo(0125)gpt-4(0613)Możesz też dostosować wcześniej dostosowany model, sformatowany jako model podstawowy.ft-{jobid}.

Aby uzyskać więcej informacji na temat naszych modeli podstawowych, które można dostosować, zobacz Modele.
Wybieranie danych treningowych
Następnym krokiem jest wybranie istniejących przygotowanych danych treningowych lub przekazanie nowych przygotowanych danych treningowych do użycia podczas dostosowywania modelu. W okienku Dane trenowania są wyświetlane wszystkie istniejące, wcześniej przekazane zestawy danych, a także opcje przekazywania nowych danych szkoleniowych.

Jeśli dane szkoleniowe zostały już przekazane do usługi, wybierz pozycję Pliki z poziomu połączenia Azure OpenAI.
- Wybierz plik z wyświetlonej listy rozwijanej.
Aby przekazać nowe dane szkoleniowe, użyj jednej z następujących opcji:
Wybierz pozycję Plik lokalny, aby przekazać dane szkoleniowe z pliku lokalnego.
Wybierz pozycję Azure Blob lub inne udostępnione lokalizacje internetowe, aby zaimportować dane szkoleniowe z usługi Azure Blob lub innej udostępnionej lokalizacji internetowej.
W przypadku dużych plików danych zalecamy importowanie z magazynu obiektów blob platformy Azure. Duże pliki mogą stać się niestabilne podczas przekazywania za pośrednictwem formularzy wieloczęściowych, ponieważ żądania są niepodzielne i nie można ich ponowić ani wznowić. Aby uzyskać więcej informacji na temat usługi Azure Blob Storage, zobacz Co to jest usługa Azure Blob Storage?
Uwaga
Pliki danych treningowych muszą być sformatowane jako pliki JSONL zakodowane w formacie UTF-8 z znacznikiem kolejności bajtów (BOM). Rozmiar pliku musi być mniejszy niż 512 MB.
Przekazywanie danych treningowych z pliku lokalnego
Nowy zestaw danych trenowania można przekazać do usługi z pliku lokalnego przy użyciu jednej z następujących metod:
Przeciągnij i upuść plik w obszarze klienta okienka Dane trenowania, a następnie wybierz pozycję Przekaż plik.
Wybierz pozycję Przeglądaj, aby uzyskać plik z obszaru klienta okienka Dane trenowania, wybierz plik do przekazania w oknie dialogowym Otwieranie , a następnie wybierz pozycję Przekaż plik.
Po wybraniu i przekazaniu zestawu danych trenowania wybierz przycisk Dalej , aby kontynuować.

Importowanie danych szkoleniowych z usługi Azure Blob Store
Zestaw danych szkoleniowych można zaimportować z usługi Azure Blob lub innej udostępnionej lokalizacji internetowej, podając nazwę i lokalizację pliku.
Wprowadź nazwę pliku.
W polu Lokalizacja pliku podaj adres URL obiektu blob platformy Azure, sygnaturę dostępu współdzielonego usługi Azure Storage (SAS) lub inny link do dostępnej udostępnionej lokalizacji internetowej.
Wybierz pozycję Importuj , aby zaimportować zestaw danych trenowania do usługi.
Po wybraniu i przekazaniu zestawu danych trenowania wybierz przycisk Dalej , aby kontynuować.

Wybieranie danych walidacji
W następnym kroku przedstawiono opcje konfigurowania modelu w celu używania danych walidacji w procesie trenowania. Jeśli nie chcesz używać danych walidacji, możesz wybrać pozycję Dalej , aby kontynuować zaawansowane opcje dla modelu. W przeciwnym razie, jeśli masz zestaw danych weryfikacji, możesz wybrać istniejące przygotowane dane weryfikacji lub przekazać nowe przygotowane dane weryfikacji do użycia podczas dostosowywania modelu.
W okienku Dane weryfikacji są wyświetlane wszystkie istniejące, wcześniej przekazane zestawy danych trenowania i walidacji oraz opcje, za pomocą których można przekazać nowe dane weryfikacji.

Jeśli dane weryfikacji zostały już przekazane do usługi, wybierz pozycję Wybierz zestaw danych.
- Wybierz plik z listy pokazanej w okienku Dane weryfikacji.
Aby przekazać nowe dane weryfikacji, użyj jednej z następujących opcji:
Wybierz pozycję Plik lokalny, aby przekazać dane weryfikacji z pliku lokalnego.
Wybierz pozycję Azure Blob lub inne udostępnione lokalizacje internetowe, aby zaimportować dane walidacji z obiektu blob platformy Azure lub innej udostępnionej lokalizacji internetowej.
W przypadku dużych plików danych zalecamy importowanie z magazynu obiektów blob platformy Azure. Duże pliki mogą stać się niestabilne podczas przekazywania za pośrednictwem formularzy wieloczęściowych, ponieważ żądania są niepodzielne i nie można ich ponowić ani wznowić.
Uwaga
Podobnie jak pliki danych szkoleniowych, pliki danych weryfikacji muszą być sformatowane jako pliki JSONL, zakodowane w formacie UTF-8 ze znacznikiem kolejności bajtów (BOM). Rozmiar pliku musi być mniejszy niż 512 MB.
Przekazywanie danych walidacji z pliku lokalnego
Nowy zestaw danych weryfikacji można przekazać do usługi z pliku lokalnego przy użyciu jednej z następujących metod:
Przeciągnij i upuść plik w obszarze klienta okienka Dane walidacji, a następnie wybierz pozycję Przekaż plik.
Wybierz pozycję Przeglądaj, aby uzyskać plik z obszaru klienta okienka Dane walidacji, wybierz plik do przekazania w oknie dialogowym Otwieranie , a następnie wybierz pozycję Przekaż plik.
Po wybraniu i przekazaniu zestawu danych weryfikacji wybierz przycisk Dalej , aby kontynuować.

Importowanie danych walidacji z usługi Azure Blob Store
Zestaw danych weryfikacji można zaimportować z obiektu blob platformy Azure lub innej udostępnionej lokalizacji internetowej, podając nazwę i lokalizację pliku.
Wprowadź nazwę pliku.
W polu Lokalizacja pliku podaj adres URL obiektu blob platformy Azure, sygnaturę dostępu współdzielonego usługi Azure Storage (SAS) lub inny link do dostępnej udostępnionej lokalizacji internetowej.
Wybierz pozycję Importuj , aby zaimportować zestaw danych trenowania do usługi.
Po wybraniu i przekazaniu zestawu danych weryfikacji wybierz przycisk Dalej , aby kontynuować.

Konfigurowanie parametrów zadania
W kreatorze Tworzenie modelu niestandardowego są wyświetlane parametry trenowania dostosowanego modelu w okienku Parametry zadania. Dostępne są następujące parametry:
| Nazwa/nazwisko | Typ | Opis |
|---|---|---|
batch_size |
integer | Rozmiar partii do użycia do trenowania. Rozmiar partii to liczba przykładów trenowania używanych do trenowania pojedynczego przebiegu do przodu i do tyłu. Ogólnie rzecz biorąc, odkryliśmy, że większe rozmiary partii zwykle działają lepiej w przypadku większych zestawów danych. Wartość domyślna, a także maksymalna wartość tej właściwości są specyficzne dla modelu podstawowego. Większy rozmiar partii oznacza, że parametry modelu są aktualizowane rzadziej, ale z niższą wariancją. |
learning_rate_multiplier |
Liczba | Mnożnik szybkości nauki używany do trenowania. Współczynnik dostrajania uczenia to oryginalny współczynnik uczenia używany do wstępnego trenowania pomnożonego przez tę wartość. Większe wskaźniki uczenia się mają tendencję do lepszej pracy z większymi rozmiarami partii. Zalecamy eksperymentowanie z wartościami z zakresu od 0,02 do 0,2, aby zobaczyć, co daje najlepsze wyniki. Mniejsze tempo nauki może być przydatne, aby uniknąć nadmiernego dopasowania. |
n_epochs |
integer | Liczba epok trenowania modelu dla. Epoka odnosi się do jednego pełnego cyklu za pośrednictwem zestawu danych trenowania. |
seed |
integer | Inicjator kontroluje powtarzalność zadania. Przekazywanie tych samych parametrów inicjacji i zadania powinno generować te same wyniki, ale może się różnić w rzadkich przypadkach. Jeśli nasion nie zostanie określony, zostanie wygenerowany dla Ciebie |

Wybierz pozycję Domyślne , aby użyć wartości domyślnych zadania dostrajania lub wybierz pozycję Niestandardowy , aby wyświetlić i edytować wartości hiperparametrów. Po wybraniu wartości domyślnych określamy poprawną wartość algorytmicznie na podstawie danych treningowych.
Po skonfigurowaniu opcji zaawansowanych wybierz przycisk Dalej, aby przejrzeć wybrane opcje i wytrenować dostosowany model.
Przeglądanie wyborów i trenowanie modelu
W okienku Przegląd kreatora są wyświetlane informacje o wybranych konfiguracjach.

Jeśli wszystko będzie gotowe do wytrenowania modelu, wybierz pozycję Rozpocznij zadanie trenowania, aby uruchomić zadanie dostrajania i wrócić do okienka Modele .
Sprawdzanie stanu modelu niestandardowego
W okienku Modele są wyświetlane informacje o modelu niestandardowym na karcie Dostosowane modele . Karta zawiera informacje o stanie i identyfikatorze zadania dostrajania dla modelu niestandardowego. Po zakończeniu zadania na karcie zostanie wyświetlony identyfikator pliku wyników. Może być konieczne wybranie pozycji Odśwież , aby wyświetlić zaktualizowany stan zadania trenowania modelu.

Po uruchomieniu zadania dostrajania może upłynąć trochę czasu. Zadanie można umieścić w kolejce za innymi zadaniami w systemie. Trenowanie modelu może potrwać kilka minut lub godzin w zależności od rozmiaru modelu i zestawu danych.
Poniżej przedstawiono niektóre zadania, które można wykonać w okienku Modele :
Sprawdź stan zadania dostrajania niestandardowego modelu w kolumnie Stan na karcie Dostosowane modele.
W kolumnie Nazwa modelu wybierz nazwę modelu, aby wyświetlić więcej informacji o modelu niestandardowym. Możesz zobaczyć stan zadania dostrajania, wyników trenowania, zdarzeń szkoleniowych i hiperparametrów używanych w zadaniu.
Wybierz pozycję Pobierz plik szkoleniowy, aby pobrać dane szkoleniowe użyte dla modelu.
Wybierz pozycję Pobierz wyniki , aby pobrać plik wyników dołączony do zadania dostrajania dla modelu i przeanalizować niestandardowy model pod kątem wydajności trenowania i walidacji.
Wybierz Odśwież, aby zaktualizować informacje na stronie.
Punkty kontrolne
Po zakończeniu każdego epoki trenowania jest generowany punkt kontrolny. Punkt kontrolny to w pełni funkcjonalna wersja modelu, która może być wdrożona i używana jako model docelowy dla kolejnych zadań dostrajania. Punkty kontrolne mogą być szczególnie przydatne, ponieważ mogą udostępniać migawkę modelu przed nadmiernym dopasowaniem. Po zakończeniu zadania dostrajania będziesz mieć trzy najnowsze wersje modelu dostępne do wdrożenia.
Ocena bezpieczeństwa GPT-4, GPT-4o i GPT-4o-mini fine-tuning - publiczna wersja zapoznawcza
GPT-4o, GPT-4o-mini i GPT-4 to nasze najbardziej zaawansowane modele, które można dostosować do Twoich potrzeb. Podobnie jak w przypadku modeli Azure OpenAI, zaawansowane możliwości dostrojonych modeli zapewniają zwiększone wyzwania związane ze sztuczną inteligencją związaną ze szkodliwą zawartością, manipulacją, zachowaniem przypominającym człowieka, problemami z prywatnością i nie tylko. Dowiedz się więcej o ryzyku, możliwościach i ograniczeniach w temacie Omówienie praktyk dotyczących odpowiedzialnej sztucznej inteligencji i uwagi na temat przejrzystości. Aby pomóc w ograniczeniu ryzyka związanego z zaawansowanymi dostosowanymi modelami, wdrożyliśmy dodatkowe kroki oceny, aby pomóc wykrywać i zapobiegać szkodliwej zawartości w trenowaniu i danych wyjściowych dostosowanych modeli. Te kroki są uziemione w standardzie Microsoft Responsible AI i filtrowaniu zawartości usługi Azure OpenAI Service.
- Oceny są przeprowadzane w dedykowanych, specyficznych dla klienta, prywatnych obszarach roboczych;
- Punkty końcowe oceny znajdują się w tej samej lokalizacji geograficznej co zasób usługi Azure OpenAI;
- Dane szkoleniowe nie są przechowywane w połączeniu z wykonywaniem ocen; utrwalone są tylko ostateczne oceny modelu (możliwe do wdrożenia lub nie można ich wdrożyć); i
Filtry oceny modeli GPT-4o, GPT-4o-mini i GPT-4 zostały ustawione na wstępnie zdefiniowane progi i nie mogą być modyfikowane przez klientów; nie są one powiązane z żadną niestandardową konfiguracją filtrowania zawartości, która mogła zostać utworzona.
Ocena danych
Przed rozpoczęciem szkolenia dane są oceniane pod kątem potencjalnie szkodliwych treści (przemoc, seksualna, nienawiść i sprawiedliwość, samookaleczenia — zobacz definicje kategorii tutaj). Jeśli zostanie wykryta szkodliwa zawartość powyżej określonego poziomu ważności, zadanie trenowania zakończy się niepowodzeniem i zostanie wyświetlony komunikat informujący o kategoriach awarii.
Przykładowy komunikat:
The provided training data failed RAI checks for harm types: [hate_fairness, self_harm, violence]. Please fix the data and try again.
Dane szkoleniowe są oceniane automatycznie w ramach zadania importowania danych w ramach zapewniania możliwości dostrajania.
Jeśli zadanie dostrajania nie powiedzie się z powodu wykrycia szkodliwej zawartości w danych treningowych, nie zostaną naliczone opłaty.
Ocena modelu
Po zakończeniu trenowania, ale zanim dostrojony model będzie dostępny do wdrożenia, wynikowy model zostanie oceniony pod kątem potencjalnie szkodliwych odpowiedzi przy użyciu wbudowanych metryk ryzyka i bezpieczeństwa platformy Azure. Korzystając z tego samego podejścia do testowania, którego używamy dla podstawowych dużych modeli językowych, nasza funkcja oceny symuluje rozmowę z dostosowanym modelem w celu oceny potencjału do generowania szkodliwej zawartości, ponownie przy użyciu określonych szkodliwych kategorii zawartości (przemoc, przemoc, nienawiść i sprawiedliwość, samookaleczenia).
Jeśli model zostanie znaleziony w celu wygenerowania danych wyjściowych zawierających zawartość wykrytą jako szkodliwą powyżej akceptowalnej szybkości, zostanie wyświetlony komunikat, że model nie jest dostępny do wdrożenia z informacjami o określonych kategoriach wykrytych szkód:
Przykładowy komunikat:
This model is unable to be deployed. Model evaluation identified that this fine tuned model scores above acceptable thresholds for [Violence, Self Harm]. Please review your training data set and resubmit the job.

Podobnie jak w przypadku oceny danych, model jest oceniany automatycznie w ramach zadania dostrajania w ramach zapewniania możliwości dostrajania. Tylko wynikowa ocena (można wdrożyć lub nie można jej wdrożyć) jest rejestrowana przez usługę. Jeśli wdrożenie dostosowanego modelu zakończy się niepowodzeniem z powodu wykrycia szkodliwej zawartości w danych wyjściowych modelu, nie zostaną naliczone opłaty za przebieg trenowania.
Wdrażanie dostosowanego modelu
Po pomyślnym zakończeniu zadania dostrajania można wdrożyć model niestandardowy w okienku Modele . Musisz wdrożyć model niestandardowy, aby był dostępny do użycia z wywołaniami uzupełniania.
Ważne
Po wdrożeniu dostosowanego modelu, jeśli w dowolnym momencie wdrożenie pozostanie nieaktywne przez ponad piętnaście (15) dni, wdrożenie zostanie usunięte. Wdrożenie dostosowanego modelu jest nieaktywne , jeśli model został wdrożony ponad piętnaście (15) dni temu i nie wykonano do niego żadnych zakończeń ani wywołań ukończenia czatu w ciągu ciągłego 15-dniowego okresu.
Usunięcie nieaktywnego wdrożenia nie powoduje usunięcia lub wpływu na bazowy dostosowany model, a dostosowany model można wdrożyć ponownie w dowolnym momencie. Zgodnie z opisem w cenniku usługi Azure OpenAI, każdy dostosowany (dostosowany) model, który został wdrożony, wiąże się z godzinowym kosztem hostingu, niezależnie od tego, czy do modelu są wykonywane połączenia ukończenia lub ukończenia czatu. Aby dowiedzieć się więcej na temat planowania kosztów i zarządzania nimi za pomocą usługi Azure OpenAI, zapoznaj się ze wskazówkami w temacie Planowanie zarządzania kosztami usługi Azure OpenAI Service.
Uwaga
Tylko jedno wdrożenie jest dozwolone dla modelu niestandardowego. Jeśli wybierzesz już wdrożony model niestandardowy, zostanie wyświetlony komunikat o błędzie.
Aby wdrożyć model niestandardowy, wybierz model niestandardowy do wdrożenia, a następnie wybierz pozycję Wdróż model.

Zostanie otwarte okno dialogowe Wdrażanie modelu . W oknie dialogowym wprowadź nazwę wdrożenia, a następnie wybierz pozycję Utwórz , aby rozpocząć wdrażanie modelu niestandardowego.

Postęp wdrażania można monitorować w okienku Wdrożenia w portalu usługi Azure AI Foundry.
Wdrażanie między regionami
Dostrajanie obsługuje wdrażanie dostosowanego modelu w innym regionie niż w przypadku, gdy model został pierwotnie dostrojony. Można również wdrożyć w innej subskrypcji/regionie.
Jedynymi ograniczeniami jest to, że nowy region musi również obsługiwać dostrajanie, a podczas wdrażania subskrypcji krzyżowej konto generujące token autoryzacji dla wdrożenia musi mieć dostęp zarówno do subskrypcji źródłowych, jak i docelowych.
Wdrożenie między subskrypcjami/regionami można wykonać za pośrednictwem języka Python lub REST.
Korzystanie z wdrożonego modelu niestandardowego
Po wdrożeniu modelu niestandardowego można go użyć jak każdy inny wdrożony model. Za pomocą narzędzi Playgrounds in Azure AI Foundry możesz eksperymentować z nowym wdrożeniem. Możesz nadal używać tych samych parametrów z modelem niestandardowym, takim jak i max_tokens, tak jak temperature w przypadku innych wdrożonych modeli. W przypadku dostrojonych babbage-002 modeli davinci-002 użyjesz placu zabaw uzupełniania i interfejsu API uzupełniania. W przypadku dostosowanych gpt-35-turbo-0613 modeli użyjesz placu zabaw czatu i interfejsu API uzupełniania czatu.

Analizowanie modelu niestandardowego
Usługa Azure OpenAI dołącza plik wynikowy o nazwie results.csv do każdego zadania dostrajania po zakończeniu. Plik wyników umożliwia analizowanie wydajności trenowania i walidacji modelu niestandardowego. Identyfikator pliku wyników jest wyświetlany dla każdego modelu niestandardowego w kolumnie Identyfikator pliku wyników w okienku Modele dla usługi Azure AI Foundry. Możesz użyć identyfikatora pliku, aby zidentyfikować i pobrać plik wynikowy z okienka Pliki danych w narzędziu Azure AI Foundry.
Plik wyników jest plikiem CSV zawierającym wiersz nagłówka i wiersz dla każdego kroku trenowania wykonywanego przez zadanie dostrajania. Plik wyników zawiera następujące kolumny:
| Nazwa kolumny | opis |
|---|---|
step |
Liczba kroków trenowania. Krok trenowania reprezentuje pojedyncze przekazywanie, do przodu i do tyłu na partii danych treningowych. |
train_loss |
Utrata partii szkoleniowej. |
train_mean_token_accuracy |
Procent tokenów w partii szkoleniowej prawidłowo przewidywany przez model. Jeśli na przykład rozmiar partii jest ustawiony na 3, a dane zawierają uzupełnienia [[1, 2], [0, 5], [4, 2]], ta wartość jest ustawiona na 0,83 (5 z 6), jeśli model przewidział [[1, 1], [0, 5], [4, 2]]wartość . |
valid_loss |
Utrata partii weryfikacji. |
validation_mean_token_accuracy |
Procent tokenów w partii weryfikacji prawidłowo przewidywany przez model. Jeśli na przykład rozmiar partii jest ustawiony na 3, a dane zawierają uzupełnienia [[1, 2], [0, 5], [4, 2]], ta wartość jest ustawiona na 0,83 (5 z 6), jeśli model przewidział [[1, 1], [0, 5], [4, 2]]wartość . |
full_valid_loss |
Utrata walidacji obliczona na końcu każdej epoki. Gdy trening idzie dobrze, utrata powinna się zmniejszyć. |
full_valid_mean_token_accuracy |
Prawidłowa dokładność tokenu średniego obliczona na końcu każdej epoki. Gdy trenowanie będzie dobrze, dokładność tokenu powinna wzrosnąć. |
Dane można również wyświetlić w pliku results.csv jako wykresy w portalu usługi Azure AI Foundry. Wybierz link dla wytrenowanego modelu i zobaczysz trzy wykresy: utrata, dokładność tokenu średniej i dokładność tokenu. Jeśli podano dane weryfikacji, oba zestawy danych będą wyświetlane na tym samym wykresie.
Poszukaj utraty, aby zmniejszyć się wraz z upływem czasu, i swoją dokładność, aby zwiększyć. Jeśli wystąpi rozbieżność między danymi treningu i weryfikacji, może to oznaczać, że nadmierne dopasowanie jest nadmierne. Spróbuj trenować z mniejszą liczbą epok lub mniejszym mnożnikiem szybkości nauki.
Czyszczenie wdrożeń, modeli niestandardowych i plików szkoleniowych
Po zakończeniu pracy z modelem niestandardowym możesz usunąć wdrożenie i model. W razie potrzeby możesz również usunąć pliki szkoleniowe i weryfikacyjne przekazane do usługi.
Usuwanie wdrożenia modelu
Ważne
Po wdrożeniu dostosowanego modelu, jeśli w dowolnym momencie wdrożenie pozostanie nieaktywne przez ponad piętnaście (15) dni, wdrożenie zostanie usunięte. Wdrożenie dostosowanego modelu jest nieaktywne , jeśli model został wdrożony ponad piętnaście (15) dni temu i nie wykonano do niego żadnych zakończeń ani wywołań ukończenia czatu w ciągu ciągłego 15-dniowego okresu.
Usunięcie nieaktywnego wdrożenia nie powoduje usunięcia lub wpływu na bazowy dostosowany model, a dostosowany model można wdrożyć ponownie w dowolnym momencie. Zgodnie z opisem w cenniku usługi Azure OpenAI, każdy dostosowany (dostosowany) model, który został wdrożony, wiąże się z godzinowym kosztem hostingu, niezależnie od tego, czy do modelu są wykonywane połączenia ukończenia lub ukończenia czatu. Aby dowiedzieć się więcej na temat planowania kosztów i zarządzania nimi za pomocą usługi Azure OpenAI, zapoznaj się ze wskazówkami w temacie Planowanie zarządzania kosztami usługi Azure OpenAI Service.
Wdrożenie modelu niestandardowego można usunąć w okienku Wdrożenia w portalu usługi Azure AI Foundry. Wybierz wdrożenie do usunięcia, a następnie wybierz pozycję Usuń , aby usunąć wdrożenie.
Usuwanie modelu niestandardowego
Model niestandardowy można usunąć w okienku Modele w portalu usługi Azure AI Foundry. Wybierz model niestandardowy do usunięcia z karty Dostosowane modele , a następnie wybierz pozycję Usuń , aby usunąć model niestandardowy.
Uwaga
Nie można usunąć modelu niestandardowego, jeśli ma istniejące wdrożenie. Przed usunięciem modelu niestandardowego należy najpierw usunąć wdrożenie modelu.
Usuwanie plików szkoleniowych
Opcjonalnie możesz usunąć pliki szkoleniowe i weryfikacyjne przekazane na potrzeby trenowania, a pliki wyników generowane podczas trenowania w okienku Pliki danych zarządzania>w portalu usługi Azure AI Foundry. Wybierz plik do usunięcia, a następnie wybierz pozycję Usuń , aby usunąć plik.
Ciągłe dostrajanie
Po utworzeniu dostosowanego modelu możesz nadal udoskonalić model w czasie przez dalsze dostrajanie. Ciągłe dostrajanie jest procesem iteracyjnym wybierania już dostrojonego modelu jako modelu podstawowego i dostrajania go dalej w nowych zestawach przykładów szkoleniowych.
Aby wykonać precyzyjne dostrajanie modelu, który został wcześniej dostosowany, należy użyć tego samego procesu, jak opisano w artykule tworzenia dostosowanego modelu , ale zamiast określania nazwy ogólnego modelu podstawowego, należy określić już dostosowany model. Niestandardowy dostosowany model wygląda następująco: gpt-35-turbo-0613.ft-5fd1918ee65d4cd38a5dcf6835066ed7

Zalecamy również uwzględnienie parametru suffix , aby ułatwić rozróżnienie różnych iteracji modelu dostosowanego. suffix pobiera ciąg i jest ustawiony, aby zidentyfikować dostrojony model. W interfejsie API języka Python interfejsu OpenAI obsługiwany jest ciąg zawierający maksymalnie 18 znaków, który zostanie dodany do dostosowanej nazwy modelu.







Wymagania wstępne
- Przeczytaj przewodnik po dostrajaniu interfejsu Azure OpenAI dotyczący używania interfejsu OpenAI.
- Subskrypcja Azure. Utwórz je bezpłatnie.
- Zasób usługi Azure OpenAI. Aby uzyskać więcej informacji, zobacz Tworzenie zasobu i wdrażanie modelu za pomocą usługi Azure OpenAI.
- Następujące biblioteki języka Python:
os, ,jsonrequests,openai. - Biblioteka języka Python OpenAI powinna mieć co najmniej wersję 0.28.1.
- Dostęp do dostrajania wymaga współautora interfejsu OpenAI usług Cognitive Services.
- Jeśli nie masz jeszcze dostępu do wyświetlania limitu przydziału i wdrażania modeli w portalu usługi Azure AI Foundry, będziesz potrzebować dodatkowych uprawnień.
Modele
Następujące modele obsługują dostrajanie:
babbage-002davinci-002gpt-35-turbo(0613)gpt-35-turbo(1106)gpt-35-turbo(0125)gpt-4(0613)*gpt-4o(2024-08-06)gpt-4o-mini(2024-07-18)
* Dostrajanie tego modelu jest obecnie dostępne w publicznej wersji zapoznawczej.
Możesz też dostroić wcześniej dostosowany model, sformatowany jako base-model.ft-{jobid}.
Zapoznaj się ze stroną modeli, aby sprawdzić, które regiony obecnie obsługują dostrajanie.
Zapoznaj się z przepływem pracy dla zestawu PYTHON SDK
Pośmiń chwilę na przejrzenie przepływu pracy dostrajania w celu używania zestawu SDK języka Python z usługą Azure OpenAI:
- Przygotuj dane szkoleniowe i weryfikacyjne.
- Wybierz model podstawowy.
- Przekaż dane szkoleniowe.
- Trenowanie nowego dostosowanego modelu.
- Sprawdź stan dostosowanego modelu.
- Wdróż dostosowany model do użycia.
- Użyj dostosowanego modelu.
- Opcjonalnie przeanalizuj dostosowany model pod kątem wydajności i dopasowania.
Przygotowywanie danych treningowych i weryfikacyjnych
Dane szkoleniowe i zestawy danych do walidacji składają się z przykładów wejściowych i wyjściowych pokazujących, jak ma działać model.
Różne typy modeli wymagają innego formatu danych treningowych.
Używane dane trenowania i walidacji muszą być sformatowane jako dokument JSON Lines (JSONL). W przypadku gpt-35-turbo-0613 zestawu danych dostrajania należy sformatować w formacie konwersacyjnym, który jest używany przez interfejs API uzupełniania czatów .
Jeśli chcesz zapoznać się z przewodnikiem krok po kroku dotyczącym dostrajania, gpt-35-turbo-0613 zapoznaj się z samouczkiem dostrajania usługi Azure OpenAI
Przykładowy format pliku
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "Is Xbox better than PlayStation?"}, {"role": "assistant", "content": "I apologize, but I cannot provide personal opinions. My primary job is to assist you with any issues related to your Xbox device. Do you have any Xbox-related issues that need addressing?"}]}
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "Can I play PC games on my Xbox?"}, {"role": "assistant", "content": "While Xbox consoles don't natively support PC games, they can play an array of Xbox games, many of which are also available on PC. Can I assist you with finding games compatible with your Xbox device?"}]}
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "I'm having trouble connecting my Xbox to the Wi-Fi."}, {"role": "assistant", "content": "No worries, let's go through the network settings on your Xbox. Can you please tell me what happens when you try to connect it to the Wi-Fi?"}]}
Format pliku czatu z wieloma zakrętami
Obsługiwane jest również wiele kolei konwersacji w jednym wierszu pliku szkoleniowego jsonl. Aby pominąć dostosowywanie określonych komunikatów asystenta, dodaj opcjonalną weight parę wartości klucza. Obecnie weight można ustawić wartość 0 lub 1.
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already.", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "William Shakespeare", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "384,400 kilometers", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters.", "weight": 1}]}
Kończenia czatów z wizją
{"messages": [{"role": "user", "content": [{"type": "text", "text": "What's in this image?"}, {"type": "image_url", "image_url": {"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png"}}]}, {"role": "assistant", "content": "The image appears to be a watercolor painting of a city skyline, featuring tall buildings and a recognizable structure often associated with Seattle, like the Space Needle. The artwork uses soft colors and brushstrokes to create a somewhat abstract and artistic representation of the cityscape."}]}
Oprócz formatu JSONL pliki danych trenowania i walidacji muszą być zakodowane w formacie UTF-8 i zawierać znak porządku bajtów (BOM). Rozmiar pliku musi być mniejszy niż 512 MB.
Tworzenie zestawów danych trenowania i walidacji
Tym więcej przykładów treningowych, tym lepiej. Zadania dostrajania nie będą kontynuowane bez co najmniej 10 przykładów treningowych, ale taka mała liczba nie wystarczy, aby zauważalnie wpłynąć na odpowiedzi modelu. Najlepszym rozwiązaniem jest zapewnienie setek, jeśli nie tysięcy, przykładów szkoleniowych, które mają być skuteczne.
Ogólnie rzecz biorąc, podwojenie rozmiaru zestawu danych może prowadzić do liniowego wzrostu jakości modelu. Należy jednak pamiętać, że przykłady niskiej jakości mogą negatywnie wpływać na wydajność. Jeśli wytrenujesz model na dużej ilości danych wewnętrznych, bez uprzedniego przycinania zestawu danych tylko do najlepszych przykładów jakości, można utworzyć model, który działa znacznie gorzej niż oczekiwano.
Przekazywanie danych treningowych
Następnym krokiem jest wybranie istniejących przygotowanych danych treningowych lub przekazanie nowych przygotowanych danych treningowych do użycia podczas dostosowywania modelu. Po przygotowaniu danych treningowych możesz przekazać pliki do usługi. Istnieją dwa sposoby przekazywania danych treningowych:
- Z pliku lokalnego
- Importowanie z magazynu obiektów blob platformy Azure lub innej lokalizacji internetowej
W przypadku dużych plików danych zalecamy importowanie z magazynu obiektów blob platformy Azure. Duże pliki mogą stać się niestabilne podczas przekazywania za pośrednictwem formularzy wieloczęściowych, ponieważ żądania są niepodzielne i nie można ich ponowić ani wznowić. Aby uzyskać więcej informacji na temat usługi Azure Blob Storage, zobacz Co to jest usługa Azure Blob Storage?
Uwaga
Pliki danych treningowych muszą być sformatowane jako pliki JSONL zakodowane w formacie UTF-8 z znacznikiem kolejności bajtów (BOM). Rozmiar pliku musi być mniejszy niż 512 MB.
Poniższy przykład w języku Python przekazuje lokalne pliki szkoleniowe i weryfikacyjne przy użyciu zestawu SDK języka Python i pobiera zwrócone identyfikatory plików.
# Upload fine-tuning files
import os
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-05-01-preview" # This API version or later is required to access seed/events/checkpoint capabilities
)
training_file_name = 'training_set.jsonl'
validation_file_name = 'validation_set.jsonl'
# Upload the training and validation dataset files to Azure OpenAI with the SDK.
training_response = client.files.create(
file=open(training_file_name, "rb"), purpose="fine-tune"
)
training_file_id = training_response.id
validation_response = client.files.create(
file=open(validation_file_name, "rb"), purpose="fine-tune"
)
validation_file_id = validation_response.id
print("Training file ID:", training_file_id)
print("Validation file ID:", validation_file_id)
Tworzenie dostosowanego modelu
Po przekazaniu plików szkoleniowych i weryfikacyjnych możesz rozpocząć zadanie dostrajania.
Poniższy kod języka Python przedstawia przykład tworzenia nowego zadania dostrajania przy użyciu zestawu SDK języka Python:
W tym przykładzie przekazujemy również parametr inicjatora. Inicjator kontroluje powtarzalność zadania. Przekazywanie tych samych parametrów inicjacji i zadania powinno generować te same wyniki, ale może się różnić w rzadkich przypadkach. Jeśli nasion nie zostanie określony, zostanie wygenerowany dla Ciebie.
response = client.fine_tuning.jobs.create(
training_file=training_file_id,
validation_file=validation_file_id,
model="gpt-35-turbo-0613", # Enter base model name. Note that in Azure OpenAI the model name contains dashes and cannot contain dot/period characters.
seed = 105 # seed parameter controls reproducibility of the fine-tuning job. If no seed is specified one will be generated automatically.
)
job_id = response.id
# You can use the job ID to monitor the status of the fine-tuning job.
# The fine-tuning job will take some time to start and complete.
print("Job ID:", response.id)
print("Status:", response.id)
print(response.model_dump_json(indent=2))
Możesz również przekazać dodatkowe parametry opcjonalne, takie jak hiperparametry, aby przejąć większą kontrolę nad procesem dostrajania. W przypadku początkowego trenowania zalecamy użycie automatycznych wartości domyślnych, które są obecne bez określania tych parametrów.
Bieżące obsługiwane hiperparametry do dostrajania są następujące:
| Nazwa/nazwisko | Typ | Opis |
|---|---|---|
batch_size |
integer | Rozmiar partii do użycia do trenowania. Rozmiar partii to liczba przykładów trenowania używanych do trenowania pojedynczego przebiegu do przodu i do tyłu. Ogólnie rzecz biorąc, odkryliśmy, że większe rozmiary partii zwykle działają lepiej w przypadku większych zestawów danych. Wartość domyślna, a także maksymalna wartość tej właściwości są specyficzne dla modelu podstawowego. Większy rozmiar partii oznacza, że parametry modelu są aktualizowane rzadziej, ale z niższą wariancją. |
learning_rate_multiplier |
Liczba | Mnożnik szybkości nauki używany do trenowania. Współczynnik dostrajania uczenia to oryginalny współczynnik uczenia używany do wstępnego trenowania pomnożonego przez tę wartość. Większe wskaźniki uczenia się mają tendencję do lepszej pracy z większymi rozmiarami partii. Zalecamy eksperymentowanie z wartościami z zakresu od 0,02 do 0,2, aby zobaczyć, co daje najlepsze wyniki. Mniejsze tempo nauki może być przydatne, aby uniknąć nadmiernego dopasowania. |
n_epochs |
integer | Liczba epok trenowania modelu dla. Epoka odnosi się do jednego pełnego cyklu za pośrednictwem zestawu danych trenowania. |
seed |
integer | Inicjator kontroluje powtarzalność zadania. Przekazywanie tych samych parametrów inicjacji i zadania powinno generować te same wyniki, ale może się różnić w rzadkich przypadkach. Jeśli nasion nie zostanie określony, zostanie wygenerowany dla Ciebie. |
Aby ustawić niestandardowe hiperparametry w wersji 1.x interfejsu API języka Python openAI:
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-02-01" # This API version or later is required to access fine-tuning for turbo/babbage-002/davinci-002
)
client.fine_tuning.jobs.create(
training_file="file-abc123",
model="gpt-35-turbo-0613", # Enter base model name. Note that in Azure OpenAI the model name contains dashes and cannot contain dot/period characters.
hyperparameters={
"n_epochs":2
}
)
Sprawdzanie stanu zadania dostrajania
response = client.fine_tuning.jobs.retrieve(job_id)
print("Job ID:", response.id)
print("Status:", response.status)
print(response.model_dump_json(indent=2))
Wyświetlanie listy zdarzeń dostrajania
Aby zbadać poszczególne zdarzenia dostrajania, które zostały wygenerowane podczas trenowania:
Aby uruchomić to polecenie, może być konieczne uaktualnienie biblioteki klienta openAI do najnowszej wersji pip install openai --upgrade .
response = client.fine_tuning.jobs.list_events(fine_tuning_job_id=job_id, limit=10)
print(response.model_dump_json(indent=2))
Punkty kontrolne
Po zakończeniu każdego epoki trenowania jest generowany punkt kontrolny. Punkt kontrolny to w pełni funkcjonalna wersja modelu, która może być wdrożona i używana jako model docelowy dla kolejnych zadań dostrajania. Punkty kontrolne mogą być szczególnie przydatne, ponieważ mogą udostępniać migawkę modelu przed nadmiernym dopasowaniem. Po zakończeniu zadania dostrajania będziesz mieć trzy najnowsze wersje modelu dostępne do wdrożenia. Ostateczna epoka będzie reprezentowana przez dostosowany model. Poprzednie dwie epoki będą dostępne jako punkty kontrolne.
Możesz uruchomić polecenie listy punktów kontrolnych, aby pobrać listę punktów kontrolnych skojarzonych z indywidualnym zadaniem dostrajania:
Aby uruchomić to polecenie, może być konieczne uaktualnienie biblioteki klienta openAI do najnowszej wersji pip install openai --upgrade .
response = client.fine_tuning.jobs.list_events(fine_tuning_job_id=job_id, limit=10)
print(response.model_dump_json(indent=2))
Ocena bezpieczeństwa GPT-4, GPT-4o, GPT-4o-mini fine-tuning - publiczna wersja zapoznawcza
GPT-4o, GPT-4o-mini i GPT-4 to nasze najbardziej zaawansowane modele, które można dostosować do Twoich potrzeb. Podobnie jak w przypadku modeli Azure OpenAI, zaawansowane możliwości dostrojonych modeli zapewniają zwiększone wyzwania związane ze sztuczną inteligencją związaną ze szkodliwą zawartością, manipulacją, zachowaniem przypominającym człowieka, problemami z prywatnością i nie tylko. Dowiedz się więcej o ryzyku, możliwościach i ograniczeniach w temacie Omówienie praktyk dotyczących odpowiedzialnej sztucznej inteligencji i uwagi na temat przejrzystości. Aby pomóc w ograniczeniu ryzyka związanego z zaawansowanymi dostosowanymi modelami, wdrożyliśmy dodatkowe kroki oceny, aby pomóc wykrywać i zapobiegać szkodliwej zawartości w trenowaniu i danych wyjściowych dostosowanych modeli. Te kroki są uziemione w standardzie Microsoft Responsible AI i filtrowaniu zawartości usługi Azure OpenAI Service.
- Oceny są przeprowadzane w dedykowanych, specyficznych dla klienta, prywatnych obszarach roboczych;
- Punkty końcowe oceny znajdują się w tej samej lokalizacji geograficznej co zasób usługi Azure OpenAI;
- Dane szkoleniowe nie są przechowywane w połączeniu z wykonywaniem ocen; utrwalone są tylko ostateczne oceny modelu (możliwe do wdrożenia lub nie można ich wdrożyć); i
Filtry oceny modeli GPT-4o, GPT-4o-mini i GPT-4 zostały ustawione na wstępnie zdefiniowane progi i nie mogą być modyfikowane przez klientów; nie są one powiązane z żadną niestandardową konfiguracją filtrowania zawartości, która mogła zostać utworzona.
Ocena danych
Przed rozpoczęciem szkolenia dane są oceniane pod kątem potencjalnie szkodliwych treści (przemoc, seksualna, nienawiść i sprawiedliwość, samookaleczenia — zobacz definicje kategorii tutaj). Jeśli zostanie wykryta szkodliwa zawartość powyżej określonego poziomu ważności, zadanie trenowania zakończy się niepowodzeniem i zostanie wyświetlony komunikat informujący o kategoriach awarii.
Przykładowy komunikat:
The provided training data failed RAI checks for harm types: [hate_fairness, self_harm, violence]. Please fix the data and try again.
Dane szkoleniowe są oceniane automatycznie w ramach zadania importowania danych w ramach zapewniania możliwości dostrajania.
Jeśli zadanie dostrajania nie powiedzie się z powodu wykrycia szkodliwej zawartości w danych treningowych, nie zostaną naliczone opłaty.
Ocena modelu
Po zakończeniu trenowania, ale zanim dostrojony model będzie dostępny do wdrożenia, wynikowy model zostanie oceniony pod kątem potencjalnie szkodliwych odpowiedzi przy użyciu wbudowanych metryk ryzyka i bezpieczeństwa platformy Azure. Korzystając z tego samego podejścia do testowania, którego używamy dla podstawowych dużych modeli językowych, nasza funkcja oceny symuluje rozmowę z dostosowanym modelem w celu oceny potencjału do generowania szkodliwej zawartości, ponownie przy użyciu określonych szkodliwych kategorii zawartości (przemoc, przemoc, nienawiść i sprawiedliwość, samookaleczenia).
Jeśli model zostanie znaleziony w celu wygenerowania danych wyjściowych zawierających zawartość wykrytą jako szkodliwą powyżej akceptowalnej szybkości, zostanie wyświetlony komunikat, że model nie jest dostępny do wdrożenia z informacjami o określonych kategoriach wykrytych szkód:
Przykładowy komunikat:
This model is unable to be deployed. Model evaluation identified that this fine tuned model scores above acceptable thresholds for [Violence, Self Harm]. Please review your training data set and resubmit the job.
Podobnie jak w przypadku oceny danych, model jest oceniany automatycznie w ramach zadania dostrajania w ramach zapewniania możliwości dostrajania. Tylko wynikowa ocena (można wdrożyć lub nie można jej wdrożyć) jest rejestrowana przez usługę. Jeśli wdrożenie dostosowanego modelu zakończy się niepowodzeniem z powodu wykrycia szkodliwej zawartości w danych wyjściowych modelu, nie zostaną naliczone opłaty za przebieg trenowania.
Wdrażanie dostosowanego modelu
Po pomyślnym zakończeniu zadania dostrajania wartość fine_tuned_model zmiennej w treści odpowiedzi zostanie ustawiona na nazwę dostosowanego modelu. Model jest teraz również dostępny do odnajdywania z poziomu interfejsu API modeli listy. Nie można jednak wydać wywołań uzupełniania do dostosowanego modelu, dopóki dostosowany model nie zostanie wdrożony. Musisz wdrożyć dostosowany model, aby był dostępny do użycia z wywołaniami uzupełniania.
Ważne
Po wdrożeniu dostosowanego modelu, jeśli w dowolnym momencie wdrożenie pozostanie nieaktywne przez ponad piętnaście (15) dni, wdrożenie zostanie usunięte. Wdrożenie dostosowanego modelu jest nieaktywne , jeśli model został wdrożony ponad piętnaście (15) dni temu i nie wykonano do niego żadnych zakończeń ani wywołań ukończenia czatu w ciągu ciągłego 15-dniowego okresu.
Usunięcie nieaktywnego wdrożenia nie powoduje usunięcia lub wpływu na bazowy dostosowany model, a dostosowany model można wdrożyć ponownie w dowolnym momencie. Zgodnie z opisem w cenniku usługi Azure OpenAI, każdy dostosowany (dostosowany) model, który został wdrożony, wiąże się z godzinowym kosztem hostingu, niezależnie od tego, czy do modelu są wykonywane połączenia ukończenia lub ukończenia czatu. Aby dowiedzieć się więcej na temat planowania kosztów i zarządzania nimi za pomocą usługi Azure OpenAI, zapoznaj się ze wskazówkami w temacie Planowanie zarządzania kosztami usługi Azure OpenAI Service.
Możesz również użyć usługi Azure AI Foundry lub interfejsu wiersza polecenia platformy Azure, aby wdrożyć dostosowany model.
Uwaga
Tylko jedno wdrożenie jest dozwolone dla niestandardowego modelu. W przypadku wybrania już wdrożonego niestandardowego modelu wystąpi błąd.
W przeciwieństwie do poprzednich poleceń zestawu SDK wdrożenie musi odbywać się przy użyciu interfejsu API płaszczyzny sterowania, który wymaga oddzielnej autoryzacji, innej ścieżki interfejsu API i innej wersji interfejsu API.
| zmienna | Definicja |
|---|---|
| token | Istnieje wiele sposobów generowania tokenu autoryzacji. Najprostszą metodą testowania początkowego jest uruchomienie usługi Cloud Shell w witrynie Azure Portal. Następnie należy uruchomić polecenie az account get-access-token. Możesz użyć tego tokenu jako tymczasowego tokenu autoryzacji na potrzeby testowania interfejsu API. Zalecamy przechowywanie tej wartości w nowej zmiennej środowiskowej. |
| subskrypcja | Identyfikator subskrypcji skojarzonego zasobu usługi Azure OpenAI. |
| resource_group | Nazwa grupy zasobów dla zasobu usługi Azure OpenAI. |
| resource_name | Nazwa zasobu usługi Azure OpenAI. |
| model_deployment_name | Nazwa niestandardowa nowego, dostosowanego wdrożenia modelu. Jest to nazwa, która zostanie przywołynięta w kodzie podczas wykonywania wywołań ukończenia czatu. |
| fine_tuned_model | Pobierz tę wartość z zadania dostrajania szczegółowego w poprzednim kroku. Będzie ona wyglądać następująco: gpt-35-turbo-0613.ft-b044a9d3cf9c4228b5d393567f693b83. Musisz dodać wartość do pliku json deploy_data. Alternatywnie można wdrożyć punkt kontrolny, przekazując identyfikator punktu kontrolnego, który będzie wyświetlany w formacie ftchkpt-e559c011ecc04fc68eaa339d8227d02d |
import json
import os
import requests
token= os.getenv("<TOKEN>")
subscription = "<YOUR_SUBSCRIPTION_ID>"
resource_group = "<YOUR_RESOURCE_GROUP_NAME>"
resource_name = "<YOUR_AZURE_OPENAI_RESOURCE_NAME>"
model_deployment_name ="gpt-35-turbo-ft" # custom deployment name that you will use to reference the model when making inference calls.
deploy_params = {'api-version': "2023-05-01"}
deploy_headers = {'Authorization': 'Bearer {}'.format(token), 'Content-Type': 'application/json'}
deploy_data = {
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": <"fine_tuned_model">, #retrieve this value from the previous call, it will look like gpt-35-turbo-0613.ft-b044a9d3cf9c4228b5d393567f693b83
"version": "1"
}
}
}
deploy_data = json.dumps(deploy_data)
request_url = f'https://management.azure.com/subscriptions/{subscription}/resourceGroups/{resource_group}/providers/Microsoft.CognitiveServices/accounts/{resource_name}/deployments/{model_deployment_name}'
print('Creating a new deployment...')
r = requests.put(request_url, params=deploy_params, headers=deploy_headers, data=deploy_data)
print(r)
print(r.reason)
print(r.json())
Wdrażanie między regionami
Dostrajanie obsługuje wdrażanie dostosowanego modelu w innym regionie niż w przypadku, gdy model został pierwotnie dostrojony. Można również wdrożyć w innej subskrypcji/regionie.
Jedynymi ograniczeniami jest to, że nowy region musi również obsługiwać dostrajanie, a podczas wdrażania subskrypcji krzyżowej konto generujące token autoryzacji dla wdrożenia musi mieć dostęp zarówno do subskrypcji źródłowych, jak i docelowych.
Poniżej przedstawiono przykład wdrożenia modelu, który został dostosowany do jednej subskrypcji/regionu w innym.
import json
import os
import requests
token= os.getenv("<TOKEN>")
subscription = "<DESTINATION_SUBSCRIPTION_ID>"
resource_group = "<DESTINATION_RESOURCE_GROUP_NAME>"
resource_name = "<DESTINATION_AZURE_OPENAI_RESOURCE_NAME>"
source_subscription = "<SOURCE_SUBSCRIPTION_ID>"
source_resource_group = "<SOURCE_RESOURCE_GROUP>"
source_resource = "<SOURCE_RESOURCE>"
source = f'/subscriptions/{source_subscription}/resourceGroups/{source_resource_group}/providers/Microsoft.CognitiveServices/accounts/{source_resource}'
model_deployment_name ="gpt-35-turbo-ft" # custom deployment name that you will use to reference the model when making inference calls.
deploy_params = {'api-version': "2023-05-01"}
deploy_headers = {'Authorization': 'Bearer {}'.format(token), 'Content-Type': 'application/json'}
deploy_data = {
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": <"FINE_TUNED_MODEL_NAME">, # This value will look like gpt-35-turbo-0613.ft-0ab3f80e4f2242929258fff45b56a9ce
"version": "1",
"source": source
}
}
}
deploy_data = json.dumps(deploy_data)
request_url = f'https://management.azure.com/subscriptions/{subscription}/resourceGroups/{resource_group}/providers/Microsoft.CognitiveServices/accounts/{resource_name}/deployments/{model_deployment_name}'
print('Creating a new deployment...')
r = requests.put(request_url, params=deploy_params, headers=deploy_headers, data=deploy_data)
print(r)
print(r.reason)
print(r.json())
Aby wdrożyć między tą samą subskrypcją, ale w różnych regionach wystarczy, że subskrypcja i grupy zasobów będą identyczne zarówno dla zmiennych źródłowych, jak i docelowych, a tylko nazwy zasobów źródłowych i docelowych muszą być unikatowe.
Wdrażanie modelu za pomocą interfejsu wiersza polecenia platformy Azure
W poniższym przykładzie pokazano, jak za pomocą interfejsu wiersza polecenia platformy Azure wdrożyć dostosowany model. Za pomocą interfejsu wiersza polecenia platformy Azure należy określić nazwę wdrożenia dostosowanego modelu. Aby uzyskać więcej informacji na temat sposobu wdrażania niestandardowych modeli za pomocą interfejsu wiersza polecenia platformy Azure, zobacz az cognitiveservices account deployment.
Aby uruchomić to polecenie interfejsu wiersza polecenia platformy Azure w oknie konsoli, należy zastąpić następujące <symbole> zastępcze odpowiednimi wartościami dostosowanego modelu:
| Symbol zastępczy | Wartość |
|---|---|
| <YOUR_AZURE_SUBSCRIPTION> | Nazwa lub identyfikator subskrypcji platformy Azure. |
| <YOUR_RESOURCE_GROUP> | Nazwa grupy zasobów platformy Azure. |
| <YOUR_RESOURCE_NAME> | Nazwa zasobu usługi Azure OpenAI. |
| <YOUR_DEPLOYMENT_NAME> | Nazwa, której chcesz użyć do wdrożenia modelu. |
| <YOUR_FINE_TUNED_MODEL_ID> | Nazwa dostosowanego modelu. |
az cognitiveservices account deployment create
--resource-group <YOUR_RESOURCE_GROUP>
--name <YOUR_RESOURCE_NAME>
--deployment-name <YOUR_DEPLOYMENT_NAME>
--model-name <YOUR_FINE_TUNED_MODEL_ID>
--model-version "1"
--model-format OpenAI
--sku-capacity "1"
--sku-name "Standard"
Korzystanie z wdrożonego niestandardowego modelu
Po wdrożeniu modelu niestandardowego można go użyć jak każdy inny wdrożony model. Za pomocą narzędzi Playgrounds in Azure AI Foundry możesz eksperymentować z nowym wdrożeniem. Możesz nadal używać tych samych parametrów z modelem niestandardowym, takim jak i max_tokens, tak jak temperature w przypadku innych wdrożonych modeli. W przypadku dostrojonych babbage-002 modeli davinci-002 użyjesz placu zabaw uzupełniania i interfejsu API uzupełniania. W przypadku dostosowanych gpt-35-turbo-0613 modeli użyjesz placu zabaw czatu i interfejsu API uzupełniania czatu.
import os
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-02-01"
)
response = client.chat.completions.create(
model="gpt-35-turbo-ft", # model = "Custom deployment name you chose for your fine-tuning model"
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Does Azure OpenAI support customer managed keys?"},
{"role": "assistant", "content": "Yes, customer managed keys are supported by Azure OpenAI."},
{"role": "user", "content": "Do other Azure AI services support this too?"}
]
)
print(response.choices[0].message.content)
Analizowanie dostosowanego modelu
Usługa Azure OpenAI dołącza plik wynikowy o nazwie results.csv do każdego zadania dostrajania po zakończeniu. Plik wyników umożliwia analizowanie wydajności trenowania i walidacji dostosowanego modelu. Identyfikator pliku wyników znajduje się na liście dla każdego dostosowanego modelu, a zestaw SDK języka Python umożliwia pobranie identyfikatora pliku i pobranie pliku wyników do analizy.
Poniższy przykład języka Python pobiera identyfikator pliku pierwszego pliku wynikowego dołączonego do zadania dostrajania dostosowanego modelu, a następnie używa zestawu SDK języka Python do pobrania pliku do katalogu roboczego na potrzeby analizy.
# Retrieve the file ID of the first result file from the fine-tuning job
# for the customized model.
response = client.fine_tuning.jobs.retrieve(job_id)
if response.status == 'succeeded':
result_file_id = response.result_files[0]
retrieve = client.files.retrieve(result_file_id)
# Download the result file.
print(f'Downloading result file: {result_file_id}')
with open(retrieve.filename, "wb") as file:
result = client.files.content(result_file_id).read()
file.write(result)
Plik wyników jest plikiem CSV zawierającym wiersz nagłówka i wiersz dla każdego kroku trenowania wykonywanego przez zadanie dostrajania. Plik wyników zawiera następujące kolumny:
| Nazwa kolumny | opis |
|---|---|
step |
Liczba kroków trenowania. Krok trenowania reprezentuje pojedyncze przekazywanie, do przodu i do tyłu na partii danych treningowych. |
train_loss |
Utrata partii szkoleniowej. |
train_mean_token_accuracy |
Procent tokenów w partii szkoleniowej prawidłowo przewidywany przez model. Jeśli na przykład rozmiar partii jest ustawiony na 3, a dane zawierają uzupełnienia [[1, 2], [0, 5], [4, 2]], ta wartość jest ustawiona na 0,83 (5 z 6), jeśli model przewidział [[1, 1], [0, 5], [4, 2]]wartość . |
valid_loss |
Utrata partii weryfikacji. |
validation_mean_token_accuracy |
Procent tokenów w partii weryfikacji prawidłowo przewidywany przez model. Jeśli na przykład rozmiar partii jest ustawiony na 3, a dane zawierają uzupełnienia [[1, 2], [0, 5], [4, 2]], ta wartość jest ustawiona na 0,83 (5 z 6), jeśli model przewidział [[1, 1], [0, 5], [4, 2]]wartość . |
full_valid_loss |
Utrata walidacji obliczona na końcu każdej epoki. Gdy trening idzie dobrze, utrata powinna się zmniejszyć. |
full_valid_mean_token_accuracy |
Prawidłowa dokładność tokenu średniego obliczona na końcu każdej epoki. Gdy trenowanie będzie dobrze, dokładność tokenu powinna wzrosnąć. |
Dane można również wyświetlić w pliku results.csv jako wykresy w portalu usługi Azure AI Foundry. Wybierz link dla wytrenowanego modelu i zobaczysz trzy wykresy: utrata, dokładność tokenu średniej i dokładność tokenu. Jeśli podano dane weryfikacji, oba zestawy danych będą wyświetlane na tym samym wykresie.
Poszukaj utraty, aby zmniejszyć się wraz z upływem czasu, i swoją dokładność, aby zwiększyć. Jeśli widzisz rozbieżność między danymi treningu i weryfikacji, które mogą wskazywać na nadmierne dopasowanie. Spróbuj trenować z mniejszą liczbą epok lub mniejszym mnożnikiem szybkości nauki.
Czyszczenie wdrożeń, dostosowanych modeli i plików szkoleniowych
Po zakończeniu pracy z dostosowanym modelem możesz usunąć wdrożenie i model. W razie potrzeby możesz również usunąć pliki szkoleniowe i weryfikacyjne przekazane do usługi.
Usuwanie wdrożenia modelu
Ważne
Po wdrożeniu dostosowanego modelu, jeśli w dowolnym momencie wdrożenie pozostanie nieaktywne przez ponad piętnaście (15) dni, wdrożenie zostanie usunięte. Wdrożenie dostosowanego modelu jest nieaktywne , jeśli model został wdrożony ponad piętnaście (15) dni temu i nie wykonano do niego żadnych zakończeń ani wywołań ukończenia czatu w ciągu ciągłego 15-dniowego okresu.
Usunięcie nieaktywnego wdrożenia nie powoduje usunięcia lub wpływu na bazowy dostosowany model, a dostosowany model można wdrożyć ponownie w dowolnym momencie. Zgodnie z opisem w cenniku usługi Azure OpenAI, każdy dostosowany (dostosowany) model, który został wdrożony, wiąże się z godzinowym kosztem hostingu, niezależnie od tego, czy do modelu są wykonywane połączenia ukończenia lub ukończenia czatu. Aby dowiedzieć się więcej na temat planowania kosztów i zarządzania nimi za pomocą usługi Azure OpenAI, zapoznaj się ze wskazówkami w temacie Planowanie zarządzania kosztami usługi Azure OpenAI Service.
Aby usunąć wdrożenie dostosowanego modelu, możesz użyć różnych metod:
- Azure AI Foundry
- Interfejs wiersza polecenia platformy Azure
Usuwanie dostosowanego modelu
Podobnie możesz użyć różnych metod do usunięcia dostosowanego modelu:
Uwaga
Nie można usunąć dostosowanego modelu, jeśli ma istniejące wdrożenie. Przed usunięciem dostosowanego modelu należy najpierw usunąć wdrożenie modelu.
Usuwanie plików szkoleniowych
Opcjonalnie możesz usunąć pliki szkoleniowe i weryfikacyjne przekazane na potrzeby trenowania oraz pliki wyników wygenerowane podczas trenowania z subskrypcji usługi Azure OpenAI. Możesz użyć następujących metod, aby usunąć pliki trenowania, walidacji i wyników:
- Azure AI Foundry
- Interfejsy API REST
- Zestaw SDK języka Python
W poniższym przykładzie języka Python użyto zestawu SDK języka Python do usunięcia plików trenowania, walidacji i wyników dla dostosowanego modelu:
print('Checking for existing uploaded files.')
results = []
# Get the complete list of uploaded files in our subscription.
files = openai.File.list().data
print(f'Found {len(files)} total uploaded files in the subscription.')
# Enumerate all uploaded files, extracting the file IDs for the
# files with file names that match your training dataset file and
# validation dataset file names.
for item in files:
if item["filename"] in [training_file_name, validation_file_name, result_file_name]:
results.append(item["id"])
print(f'Found {len(results)} already uploaded files that match our files')
# Enumerate the file IDs for our files and delete each file.
print(f'Deleting already uploaded files.')
for id in results:
openai.File.delete(sid = id)
Ciągłe dostrajanie
Po utworzeniu dostosowanego modelu możesz nadal udoskonalić model w czasie poprzez dalsze dostrajanie. Ciągłe dostrajanie jest procesem iteracyjnym wybierania już dostrojonego modelu jako modelu podstawowego i dostrajania go dalej w nowych zestawach przykładów szkoleniowych.
Aby wykonać precyzyjne dostrajanie modelu, który został wcześniej dostosowany, należy użyć tego samego procesu, jak opisano w artykule tworzenia dostosowanego modelu, ale zamiast określać nazwę ogólnego modelu podstawowego, należy określić identyfikator już dostosowanego modelu. Identyfikator dostosowanego modelu wygląda następująco: gpt-35-turbo-0613.ft-5fd1918ee65d4cd38a5dcf6835066ed7
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-02-01"
)
response = client.fine_tuning.jobs.create(
training_file=training_file_id,
validation_file=validation_file_id,
model="gpt-35-turbo-0613.ft-5fd1918ee65d4cd38a5dcf6835066ed7" # Enter base model name. Note that in Azure OpenAI the model name contains dashes and cannot contain dot/period characters.
)
job_id = response.id
# You can use the job ID to monitor the status of the fine-tuning job.
# The fine-tuning job will take some time to start and complete.
print("Job ID:", response.id)
print("Status:", response.id)
print(response.model_dump_json(indent=2))
Zalecamy również uwzględnienie parametru suffix , aby ułatwić rozróżnienie różnych iteracji modelu dostosowanego. suffix pobiera ciąg i jest ustawiony, aby zidentyfikować dostrojony model. W interfejsie API języka Python interfejsu OpenAI obsługiwany jest ciąg zawierający maksymalnie 18 znaków, który zostanie dodany do dostosowanej nazwy modelu.
Jeśli nie masz pewności co do identyfikatora istniejącego dostosowanego modelu, te informacje można znaleźć na stronie Modele rozwiązania Azure AI Foundry lub wygenerować listę modeli dla danego zasobu usługi Azure OpenAI przy użyciu interfejsu API REST.
Wymagania wstępne
- Przeczytaj przewodnik po dostrajaniu interfejsu Azure OpenAI dotyczący używania interfejsu OpenAI.
- Subskrypcja Azure. Utwórz je bezpłatnie.
- Zasób usługi Azure OpenAI. Aby uzyskać więcej informacji, zobacz Tworzenie zasobu i wdrażanie modelu za pomocą usługi Azure OpenAI.
- Dostęp do dostrajania wymaga współautora interfejsu OpenAI usług Cognitive Services.
- Jeśli nie masz jeszcze dostępu do wyświetlania limitu przydziału i wdrażania modeli w portalu usługi Azure AI Foundry, musisz mieć dodatkowe uprawnienia.
Modele
Następujące modele obsługują dostrajanie:
babbage-002davinci-002gpt-35-turbo(0613)gpt-35-turbo(1106)gpt-35-turbo(0125)gpt-4(0613)*gpt-4o(2024-08-06)gpt-4o-mini(2024-07-18)
* Dostrajanie tego modelu jest obecnie dostępne w publicznej wersji zapoznawczej.
Możesz też dostosować wcześniej dostosowany model, sformatowany jako model podstawowy.ft-{jobid}.
Zapoznaj się ze stroną modeli, aby sprawdzić, które regiony obecnie obsługują dostrajanie.
Przejrzyj przepływ pracy dla interfejsu API REST
Pośmiń chwilę na przejrzenie przepływu pracy dostrajania na potrzeby korzystania z interfejsów API REST i języka Python z usługą Azure OpenAI:
- Przygotuj dane szkoleniowe i weryfikacyjne.
- Wybierz model podstawowy.
- Przekaż dane szkoleniowe.
- Trenowanie nowego dostosowanego modelu.
- Sprawdź stan dostosowanego modelu.
- Wdróż dostosowany model do użycia.
- Użyj dostosowanego modelu.
- Opcjonalnie przeanalizuj dostosowany model pod kątem wydajności i dopasowania.
Przygotowywanie danych treningowych i weryfikacyjnych
Dane szkoleniowe i zestawy danych do walidacji składają się z przykładów wejściowych i wyjściowych pokazujących, jak ma działać model.
Różne typy modeli wymagają innego formatu danych treningowych.
Używane dane trenowania i walidacji muszą być sformatowane jako dokument JSON Lines (JSONL). W przypadku gpt-35-turbo-0613 i innych powiązanych modeli zestaw danych dostrajania musi być sformatowany w formacie konwersacji używanym przez interfejs API uzupełniania czatów .
Jeśli chcesz zapoznać się z przewodnikiem krok po kroku dotyczącym dostrajania, gpt-35-turbo-0613 zapoznaj się z samouczkiem dostrajania usługi Azure OpenAI.
Przykładowy format pliku
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "Is Xbox better than PlayStation?"}, {"role": "assistant", "content": "I apologize, but I cannot provide personal opinions. My primary job is to assist you with any issues related to your Xbox device. Do you have any Xbox-related issues that need addressing?"}]}
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "Can I play PC games on my Xbox?"}, {"role": "assistant", "content": "While Xbox consoles don't natively support PC games, they can play an array of Xbox games, many of which are also available on PC. Can I assist you with finding games compatible with your Xbox device?"}]}
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "I'm having trouble connecting my Xbox to the Wi-Fi."}, {"role": "assistant", "content": "No worries, let's go through the network settings on your Xbox. Can you please tell me what happens when you try to connect it to the Wi-Fi?"}]}
Format pliku czatu z wieloma zakrętami
Obsługiwane jest również wiele kolei konwersacji w jednym wierszu pliku szkoleniowego jsonl. Aby pominąć dostosowywanie określonych komunikatów asystenta, dodaj opcjonalną weight parę wartości klucza. Obecnie weight można ustawić wartość 0 lub 1.
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already.", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "William Shakespeare", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "384,400 kilometers", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters.", "weight": 1}]}
Kończenia czatów z wizją
{"messages": [{"role": "user", "content": [{"type": "text", "text": "What's in this image?"}, {"type": "image_url", "image_url": {"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png"}}]}, {"role": "assistant", "content": "The image appears to be a watercolor painting of a city skyline, featuring tall buildings and a recognizable structure often associated with Seattle, like the Space Needle. The artwork uses soft colors and brushstrokes to create a somewhat abstract and artistic representation of the cityscape."}]}
Oprócz formatu JSONL pliki danych trenowania i walidacji muszą być zakodowane w formacie UTF-8 i zawierać znak porządku bajtów (BOM). Rozmiar pliku musi być mniejszy niż 512 MB.
Tworzenie zestawów danych trenowania i walidacji
Tym więcej przykładów treningowych, tym lepiej. Zadania dostrajania nie będą kontynuowane bez co najmniej 10 przykładów treningowych, ale taka mała liczba nie wystarczy, aby zauważalnie wpłynąć na odpowiedzi modelu. Najlepszym rozwiązaniem jest zapewnienie setek, jeśli nie tysięcy, przykładów szkoleniowych, które mają być skuteczne.
Ogólnie rzecz biorąc, podwojenie rozmiaru zestawu danych może prowadzić do liniowego wzrostu jakości modelu. Należy jednak pamiętać, że przykłady niskiej jakości mogą negatywnie wpływać na wydajność. Jeśli wytrenujesz model na dużej ilości danych wewnętrznych bez uprzedniego przycinania zestawu danych tylko pod kątem najwyższej jakości przykładów, możesz utworzyć model, który działa znacznie gorzej niż oczekiwano.
Wybieranie modelu podstawowego
Pierwszym krokiem tworzenia modelu niestandardowego jest wybranie modelu podstawowego. Okienko Model podstawowy umożliwia wybranie modelu podstawowego do użycia dla modelu niestandardowego. Wybór wpływa zarówno na wydajność, jak i koszt modelu.
Wybierz model podstawowy z listy rozwijanej Typ modelu podstawowego, a następnie wybierz przycisk Dalej, aby kontynuować.
Model niestandardowy można utworzyć na podstawie jednego z następujących dostępnych modeli podstawowych:
babbage-002davinci-002gpt-35-turbo(0613)gpt-35-turbo(1106)gpt-35-turbo(0125)gpt-4(0613)gpt-4o(2024-08-06)gpt-4o-mini(2023-07-18)
Możesz też dostosować wcześniej dostosowany model, sformatowany jako model podstawowy.ft-{jobid}.
Aby uzyskać więcej informacji na temat naszych modeli podstawowych, które można dostosować, zobacz Modele.
Przekazywanie danych treningowych
Następnym krokiem jest wybranie istniejących przygotowanych danych treningowych lub przekazanie nowych przygotowanych danych treningowych do użycia podczas dostosowywania modelu. Po przygotowaniu danych treningowych możesz przekazać pliki do usługi. Istnieją dwa sposoby przekazywania danych treningowych:
W przypadku dużych plików danych zalecamy importowanie z magazynu obiektów blob platformy Azure. Duże pliki mogą stać się niestabilne podczas przekazywania za pośrednictwem formularzy wieloczęściowych, ponieważ żądania są niepodzielne i nie można ich ponowić ani wznowić. Aby uzyskać więcej informacji na temat usługi Azure Blob Storage, zobacz Co to jest usługa Azure Blob Storage?
Uwaga
Pliki danych treningowych muszą być sformatowane jako pliki JSONL zakodowane w formacie UTF-8 z znacznikiem kolejności bajtów (BOM). Rozmiar pliku musi być mniejszy niż 512 MB.
Przekazywanie danych treningowych
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/files?api-version=2023-12-01-preview \
-H "Content-Type: multipart/form-data" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-F "purpose=fine-tune" \
-F "file=@C:\\fine-tuning\\training_set.jsonl;type=application/json"
Przekazywanie danych weryfikacji
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/files?api-version=2023-12-01-preview \
-H "Content-Type: multipart/form-data" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-F "purpose=fine-tune" \
-F "file=@C:\\fine-tuning\\validation_set.jsonl;type=application/json"
Tworzenie dostosowanego modelu
Po przekazaniu plików szkoleniowych i weryfikacyjnych możesz rozpocząć zadanie dostrajania. Poniższy kod przedstawia przykład tworzenia nowego zadania dostrajania za pomocą interfejsu API REST.
W tym przykładzie przekazujemy również parametr inicjatora. Inicjator kontroluje powtarzalność zadania. Przekazywanie tych samych parametrów inicjacji i zadania powinno generować te same wyniki, ale może się różnić w rzadkich przypadkach. Jeśli inicjator nie zostanie określony, zostanie on wygenerowany.
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs?api-version=2024-05-01-preview \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-d '{
"model": "gpt-35-turbo-0613",
"training_file": "<TRAINING_FILE_ID>",
"validation_file": "<VALIDATION_FILE_ID>",
"seed": 105
}'
Możesz również przekazać dodatkowe parametry opcjonalne, takie jak hiperparametry , aby przejąć większą kontrolę nad procesem dostrajania. W przypadku początkowego trenowania zalecamy użycie automatycznych wartości domyślnych, które są obecne bez określania tych parametrów.
Bieżące obsługiwane hiperparametry do dostrajania są następujące:
| Nazwa/nazwisko | Typ | Opis |
|---|---|---|
batch_size |
integer | Rozmiar partii do użycia do trenowania. Rozmiar partii to liczba przykładów trenowania używanych do trenowania pojedynczego przebiegu do przodu i do tyłu. Ogólnie rzecz biorąc, odkryliśmy, że większe rozmiary partii zwykle działają lepiej w przypadku większych zestawów danych. Wartość domyślna, a także maksymalna wartość tej właściwości są specyficzne dla modelu podstawowego. Większy rozmiar partii oznacza, że parametry modelu są aktualizowane rzadziej, ale z niższą wariancją. |
learning_rate_multiplier |
Liczba | Mnożnik szybkości nauki używany do trenowania. Współczynnik dostrajania uczenia to oryginalny współczynnik uczenia używany do wstępnego trenowania pomnożonego przez tę wartość. Większe wskaźniki uczenia się mają tendencję do lepszej pracy z większymi rozmiarami partii. Zalecamy eksperymentowanie z wartościami z zakresu od 0,02 do 0,2, aby zobaczyć, co daje najlepsze wyniki. Mniejsze tempo nauki może być przydatne, aby uniknąć nadmiernego dopasowania. |
n_epochs |
integer | Liczba epok trenowania modelu dla. Epoka odnosi się do jednego pełnego cyklu za pośrednictwem zestawu danych trenowania. |
seed |
integer | Inicjator kontroluje powtarzalność zadania. Przekazywanie tych samych parametrów inicjacji i zadania powinno generować te same wyniki, ale może się różnić w rzadkich przypadkach. Jeśli nasion nie zostanie określony, zostanie wygenerowany dla Ciebie. |
Sprawdzanie stanu dostosowanego modelu
Po rozpoczęciu zadania dostrajania jego ukończenie może zająć trochę czasu. Zadanie może być kolejkowane za innymi zadaniami w systemie. Trenowanie modelu może potrwać kilka minut lub godzin w zależności od rozmiaru modelu i zestawu danych. W poniższym przykładzie użyto interfejsu API REST do sprawdzenia stanu zadania dostrajania. Przykład pobiera informacje o zadaniu przy użyciu identyfikatora zadania zwróconego z poprzedniego przykładu:
curl -X GET $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs/<YOUR-JOB-ID>?api-version=2024-05-01-preview \
-H "api-key: $AZURE_OPENAI_API_KEY"
Wyświetlanie listy zdarzeń dostrajania
Aby zbadać poszczególne zdarzenia dostrajania, które zostały wygenerowane podczas trenowania:
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs/{fine_tuning_job_id}/events?api-version=2024-05-01-preview \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY"
Punkty kontrolne
Po zakończeniu każdego epoki trenowania jest generowany punkt kontrolny. Punkt kontrolny to w pełni funkcjonalna wersja modelu, która może być wdrożona i używana jako model docelowy dla kolejnych zadań dostrajania. Punkty kontrolne mogą być szczególnie przydatne, ponieważ mogą udostępniać migawkę modelu przed nadmiernym dopasowaniem. Po zakończeniu zadania dostrajania będziesz mieć trzy najnowsze wersje modelu dostępne do wdrożenia. Ostateczna epoka będzie reprezentowana przez dostosowany model. Poprzednie dwie epoki będą dostępne jako punkty kontrolne.
Możesz uruchomić polecenie listy punktów kontrolnych, aby pobrać listę punktów kontrolnych skojarzonych z indywidualnym zadaniem dostrajania:
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs/{fine_tuning_job_id}/checkpoints?api-version=2024-05-01-preview \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY"
Ocena bezpieczeństwa GPT-4, GPT-4o, GPT-4o-mini fine-tuning - publiczna wersja zapoznawcza
GPT-4o, GPT-4o-mini i GPT-4 to nasze najbardziej zaawansowane modele, które można dostosować do Twoich potrzeb. Podobnie jak w przypadku modeli Azure OpenAI, zaawansowane możliwości dostrojonych modeli zapewniają zwiększone wyzwania związane ze sztuczną inteligencją związaną ze szkodliwą zawartością, manipulacją, zachowaniem przypominającym człowieka, problemami z prywatnością i nie tylko. Dowiedz się więcej o ryzyku, możliwościach i ograniczeniach w temacie Omówienie praktyk dotyczących odpowiedzialnej sztucznej inteligencji i uwagi na temat przejrzystości. Aby pomóc w ograniczeniu ryzyka związanego z zaawansowanymi dostosowanymi modelami, wdrożyliśmy dodatkowe kroki oceny, aby pomóc wykrywać i zapobiegać szkodliwej zawartości w trenowaniu i danych wyjściowych dostosowanych modeli. Te kroki są uziemione w standardzie Microsoft Responsible AI i filtrowaniu zawartości usługi Azure OpenAI Service.
- Oceny są przeprowadzane w dedykowanych, specyficznych dla klienta, prywatnych obszarach roboczych;
- Punkty końcowe oceny znajdują się w tej samej lokalizacji geograficznej co zasób usługi Azure OpenAI;
- Dane szkoleniowe nie są przechowywane w połączeniu z wykonywaniem ocen; utrwalone są tylko ostateczne oceny modelu (możliwe do wdrożenia lub nie można ich wdrożyć); i
Filtry oceny modeli GPT-4o, GPT-4o-mini i GPT-4 zostały ustawione na wstępnie zdefiniowane progi i nie mogą być modyfikowane przez klientów; nie są one powiązane z żadną niestandardową konfiguracją filtrowania zawartości, która mogła zostać utworzona.
Ocena danych
Przed rozpoczęciem szkolenia dane są oceniane pod kątem potencjalnie szkodliwych treści (przemoc, seksualna, nienawiść i sprawiedliwość, samookaleczenia — zobacz definicje kategorii tutaj). Jeśli zostanie wykryta szkodliwa zawartość powyżej określonego poziomu ważności, zadanie trenowania zakończy się niepowodzeniem i zostanie wyświetlony komunikat informujący o kategoriach awarii.
Przykładowy komunikat:
The provided training data failed RAI checks for harm types: [hate_fairness, self_harm, violence]. Please fix the data and try again.
Dane szkoleniowe są oceniane automatycznie w ramach zadania importowania danych w ramach zapewniania możliwości dostrajania.
Jeśli zadanie dostrajania nie powiedzie się z powodu wykrycia szkodliwej zawartości w danych treningowych, nie zostaną naliczone opłaty.
Ocena modelu
Po zakończeniu trenowania, ale zanim dostrojony model będzie dostępny do wdrożenia, wynikowy model zostanie oceniony pod kątem potencjalnie szkodliwych odpowiedzi przy użyciu wbudowanych metryk ryzyka i bezpieczeństwa platformy Azure. Korzystając z tego samego podejścia do testowania, którego używamy dla podstawowych dużych modeli językowych, nasza funkcja oceny symuluje rozmowę z dostosowanym modelem w celu oceny potencjału do generowania szkodliwej zawartości, ponownie przy użyciu określonych szkodliwych kategorii zawartości (przemoc, przemoc, nienawiść i sprawiedliwość, samookaleczenia).
Jeśli model zostanie znaleziony w celu wygenerowania danych wyjściowych zawierających zawartość wykrytą jako szkodliwą powyżej akceptowalnej szybkości, zostanie wyświetlony komunikat, że model nie jest dostępny do wdrożenia z informacjami o określonych kategoriach wykrytych szkód:
Przykładowy komunikat:
This model is unable to be deployed. Model evaluation identified that this fine tuned model scores above acceptable thresholds for [Violence, Self Harm]. Please review your training data set and resubmit the job.
Podobnie jak w przypadku oceny danych, model jest oceniany automatycznie w ramach zadania dostrajania w ramach zapewniania możliwości dostrajania. Tylko wynikowa ocena (można wdrożyć lub nie można jej wdrożyć) jest rejestrowana przez usługę. Jeśli wdrożenie dostosowanego modelu zakończy się niepowodzeniem z powodu wykrycia szkodliwej zawartości w danych wyjściowych modelu, nie zostaną naliczone opłaty za przebieg trenowania.
Wdrażanie dostosowanego modelu
Ważne
Po wdrożeniu dostosowanego modelu, jeśli w dowolnym momencie wdrożenie pozostanie nieaktywne przez ponad piętnaście (15) dni, wdrożenie zostanie usunięte. Wdrożenie dostosowanego modelu jest nieaktywne , jeśli model został wdrożony ponad piętnaście (15) dni temu i nie wykonano do niego żadnych zakończeń ani wywołań ukończenia czatu w ciągu ciągłego 15-dniowego okresu.
Usunięcie nieaktywnego wdrożenia nie powoduje usunięcia lub wpływu na bazowy dostosowany model, a dostosowany model można wdrożyć ponownie w dowolnym momencie. Zgodnie z opisem w cenniku usługi Azure OpenAI, każdy dostosowany (dostosowany) model, który został wdrożony, wiąże się z godzinowym kosztem hostingu, niezależnie od tego, czy do modelu są wykonywane połączenia ukończenia lub ukończenia czatu. Aby dowiedzieć się więcej na temat planowania kosztów i zarządzania nimi za pomocą usługi Azure OpenAI, zapoznaj się ze wskazówkami w temacie Planowanie zarządzania kosztami usługi Azure OpenAI Service.
W poniższym przykładzie w języku Python pokazano, jak za pomocą interfejsu API REST utworzyć wdrożenie modelu dla dostosowanego modelu. Interfejs API REST generuje nazwę wdrożenia dostosowanego modelu.
| zmienna | Definicja |
|---|---|
| token | Istnieje wiele sposobów generowania tokenu autoryzacji. Najprostszą metodą testowania początkowego jest uruchomienie usługi Cloud Shell w witrynie Azure Portal. Następnie należy uruchomić polecenie az account get-access-token. Możesz użyć tego tokenu jako tymczasowego tokenu autoryzacji na potrzeby testowania interfejsu API. Zalecamy przechowywanie tej wartości w nowej zmiennej środowiskowej. |
| subskrypcja | Identyfikator subskrypcji skojarzonego zasobu usługi Azure OpenAI. |
| resource_group | Nazwa grupy zasobów dla zasobu usługi Azure OpenAI. |
| resource_name | Nazwa zasobu usługi Azure OpenAI. |
| model_deployment_name | Nazwa niestandardowa nowego, dostosowanego wdrożenia modelu. Jest to nazwa, która zostanie przywołynięta w kodzie podczas wykonywania wywołań ukończenia czatu. |
| fine_tuned_model | Pobierz tę wartość z zadania dostrajania szczegółowego w poprzednim kroku. Będzie ona wyglądać następująco: gpt-35-turbo-0613.ft-b044a9d3cf9c4228b5d393567f693b83. Musisz dodać wartość do pliku json deploy_data. Alternatywnie można wdrożyć punkt kontrolny, przekazując identyfikator punktu kontrolnego, który będzie wyświetlany w formacie ftchkpt-e559c011ecc04fc68eaa339d8227d02d |
curl -X POST "https://management.azure.com/subscriptions/<SUBSCRIPTION>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.CognitiveServices/accounts/<RESOURCE_NAME>/deployments/<MODEL_DEPLOYMENT_NAME>api-version=2023-05-01" \
-H "Authorization: Bearer <TOKEN>" \
-H "Content-Type: application/json" \
-d '{
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": "<FINE_TUNED_MODEL>",
"version": "1"
}
}
}'
Wdrażanie między regionami
Dostrajanie obsługuje wdrażanie dostosowanego modelu w innym regionie niż w przypadku, gdy model został pierwotnie dostrojony. Można również wdrożyć w innej subskrypcji/regionie.
Jedynymi ograniczeniami jest to, że nowy region musi również obsługiwać dostrajanie, a podczas wdrażania subskrypcji krzyżowej konto generujące token autoryzacji dla wdrożenia musi mieć dostęp zarówno do subskrypcji źródłowych, jak i docelowych.
Poniżej przedstawiono przykład wdrożenia modelu, który został dostosowany do jednej subskrypcji/regionu w innym.
curl -X PUT "https://management.azure.com/subscriptions/<SUBSCRIPTION>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.CognitiveServices/accounts/<RESOURCE_NAME>/deployments/<MODEL_DEPLOYMENT_NAME>api-version=2023-05-01" \
-H "Authorization: Bearer <TOKEN>" \
-H "Content-Type: application/json" \
-d '{
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": "<FINE_TUNED_MODEL>",
"version": "1",
"source": "/subscriptions/{sourceSubscriptionID}/resourceGroups/{sourceResourceGroupName}/providers/Microsoft.CognitiveServices/accounts/{sourceAccount}"
}
}
}'
Aby wdrożyć między tą samą subskrypcją, ale w różnych regionach, wystarczy, że subskrypcja i grupy zasobów będą identyczne zarówno dla zmiennych źródłowych, jak i docelowych, a tylko nazwy zasobów źródłowych i docelowych muszą być unikatowe.
Wdrażanie modelu za pomocą interfejsu wiersza polecenia platformy Azure
W poniższym przykładzie pokazano, jak za pomocą interfejsu wiersza polecenia platformy Azure wdrożyć dostosowany model. Za pomocą interfejsu wiersza polecenia platformy Azure należy określić nazwę wdrożenia dostosowanego modelu. Aby uzyskać więcej informacji na temat sposobu wdrażania niestandardowych modeli za pomocą interfejsu wiersza polecenia platformy Azure, zobacz az cognitiveservices account deployment.
Aby uruchomić to polecenie interfejsu wiersza polecenia platformy Azure w oknie konsoli, należy zastąpić następujące <symbole> zastępcze odpowiednimi wartościami dostosowanego modelu:
| Symbol zastępczy | Wartość |
|---|---|
| <YOUR_AZURE_SUBSCRIPTION> | Nazwa lub identyfikator subskrypcji platformy Azure. |
| <YOUR_RESOURCE_GROUP> | Nazwa grupy zasobów platformy Azure. |
| <YOUR_RESOURCE_NAME> | Nazwa zasobu usługi Azure OpenAI. |
| <YOUR_DEPLOYMENT_NAME> | Nazwa, której chcesz użyć do wdrożenia modelu. |
| <YOUR_FINE_TUNED_MODEL_ID> | Nazwa dostosowanego modelu. |
az cognitiveservices account deployment create
--resource-group <YOUR_RESOURCE_GROUP>
--name <YOUR_RESOURCE_NAME>
--deployment-name <YOUR_DEPLOYMENT_NAME>
--model-name <YOUR_FINE_TUNED_MODEL_ID>
--model-version "1"
--model-format OpenAI
--sku-capacity "1"
--sku-name "Standard"
Korzystanie z wdrożonego niestandardowego modelu
Po wdrożeniu modelu niestandardowego można go użyć jak każdy inny wdrożony model. Za pomocą narzędzi Playgrounds in Azure AI Foundry możesz eksperymentować z nowym wdrożeniem. Możesz nadal używać tych samych parametrów z modelem niestandardowym, takim jak i max_tokens, tak jak temperature w przypadku innych wdrożonych modeli. W przypadku dostrojonych babbage-002 modeli davinci-002 użyjesz placu zabaw uzupełniania i interfejsu API uzupełniania. W przypadku dostosowanych gpt-35-turbo-0613 modeli użyjesz placu zabaw czatu i interfejsu API uzupełniania czatu.
curl $AZURE_OPENAI_ENDPOINT/openai/deployments/<deployment_name>/chat/completions?api-version=2023-05-15 \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-d '{"messages":[{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": "Does Azure OpenAI support customer managed keys?"},{"role": "assistant", "content": "Yes, customer managed keys are supported by Azure OpenAI."},{"role": "user", "content": "Do other Azure AI services support this too?"}]}'
Analizowanie dostosowanego modelu
Usługa Azure OpenAI dołącza plik wynikowy o nazwie results.csv do każdego zadania dostrajania po zakończeniu. Plik wyników umożliwia analizowanie wydajności trenowania i walidacji dostosowanego modelu. Identyfikator pliku dla pliku wyników znajduje się na liście dla każdego dostosowanego modelu i możesz użyć interfejsu API REST, aby pobrać identyfikator pliku i pobrać plik wynikowy do analizy.
Poniższy przykład w języku Python używa interfejsu API REST do pobrania identyfikatora pliku pierwszego pliku wynikowego dołączonego do zadania dostrajania dostosowanego modelu, a następnie pobrania pliku do katalogu roboczego na potrzeby analizy.
curl -X GET "$AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs/<JOB_ID>?api-version=2023-12-01-preview" \
-H "api-key: $AZURE_OPENAI_API_KEY")
curl -X GET "$AZURE_OPENAI_ENDPOINT/openai/files/<RESULT_FILE_ID>/content?api-version=2023-12-01-preview" \
-H "api-key: $AZURE_OPENAI_API_KEY" > <RESULT_FILENAME>
Plik wyników jest plikiem CSV zawierającym wiersz nagłówka i wiersz dla każdego kroku trenowania wykonywanego przez zadanie dostrajania. Plik wyników zawiera następujące kolumny:
| Nazwa kolumny | opis |
|---|---|
step |
Liczba kroków trenowania. Krok trenowania reprezentuje pojedyncze przekazywanie, do przodu i do tyłu na partii danych treningowych. |
train_loss |
Utrata partii szkoleniowej. |
train_mean_token_accuracy |
Procent tokenów w partii szkoleniowej prawidłowo przewidywany przez model. Jeśli na przykład rozmiar partii jest ustawiony na 3, a dane zawierają uzupełnienia [[1, 2], [0, 5], [4, 2]], ta wartość jest ustawiona na 0,83 (5 z 6), jeśli model przewidział [[1, 1], [0, 5], [4, 2]]wartość . |
valid_loss |
Utrata partii weryfikacji. |
validation_mean_token_accuracy |
Procent tokenów w partii weryfikacji prawidłowo przewidywany przez model. Jeśli na przykład rozmiar partii jest ustawiony na 3, a dane zawierają uzupełnienia [[1, 2], [0, 5], [4, 2]], ta wartość jest ustawiona na 0,83 (5 z 6), jeśli model przewidział [[1, 1], [0, 5], [4, 2]]wartość . |
full_valid_loss |
Utrata walidacji obliczona na końcu każdej epoki. Gdy trening idzie dobrze, utrata powinna się zmniejszyć. |
full_valid_mean_token_accuracy |
Prawidłowa dokładność tokenu średniego obliczona na końcu każdej epoki. Gdy trenowanie będzie dobrze, dokładność tokenu powinna wzrosnąć. |
Dane można również wyświetlić w pliku results.csv jako wykresy w portalu usługi Azure AI Foundry. Wybierz link dla wytrenowanego modelu i zobaczysz trzy wykresy: utrata, dokładność tokenu średniej i dokładność tokenu. Jeśli podano dane weryfikacji, oba zestawy danych będą wyświetlane na tym samym wykresie.
Poszukaj utraty, aby zmniejszyć się wraz z upływem czasu, i swoją dokładność, aby zwiększyć. Jeśli widzisz rozbieżność między danymi treningu i weryfikacji, które mogą wskazywać na nadmierne dopasowanie. Spróbuj trenować z mniejszą liczbą epok lub mniejszym mnożnikiem szybkości nauki.
Czyszczenie wdrożeń, dostosowanych modeli i plików szkoleniowych
Po zakończeniu pracy z dostosowanym modelem możesz usunąć wdrożenie i model. W razie potrzeby możesz również usunąć pliki szkoleniowe i weryfikacyjne przekazane do usługi.
Usuwanie wdrożenia modelu
Aby usunąć wdrożenie dostosowanego modelu, możesz użyć różnych metod:
- Azure AI Foundry
- Interfejs wiersza polecenia platformy Azure
Usuwanie dostosowanego modelu
Podobnie możesz użyć różnych metod do usunięcia dostosowanego modelu:
Uwaga
Nie można usunąć dostosowanego modelu, jeśli ma istniejące wdrożenie. Przed usunięciem dostosowanego modelu należy najpierw usunąć wdrożenie modelu.
Usuwanie plików szkoleniowych
Opcjonalnie możesz usunąć pliki szkoleniowe i weryfikacyjne przekazane na potrzeby trenowania oraz pliki wyników wygenerowane podczas trenowania z subskrypcji usługi Azure OpenAI. Możesz użyć następujących metod, aby usunąć pliki trenowania, walidacji i wyników:
Ciągłe dostrajanie
Po utworzeniu dostosowanego modelu możesz nadal udoskonalić model w czasie poprzez dalsze dostrajanie. Ciągłe dostrajanie jest procesem iteracyjnym wybierania już dostrojonego modelu jako modelu podstawowego i dostrajania go dalej w nowych zestawach przykładów szkoleniowych.
Aby wykonać precyzyjne dostrajanie modelu, który został wcześniej dostosowany, należy użyć tego samego procesu, jak opisano w artykule tworzenie dostosowanego modelu, ale zamiast określać nazwę ogólnego modelu podstawowego, należy określić identyfikator już dostosowanego modelu. Identyfikator dostosowanego modelu wygląda następująco: gpt-35-turbo-0613.ft-5fd1918ee65d4cd38a5dcf6835066ed7
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs?api-version=2023-12-01-preview \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-d '{
"model": "gpt-35-turbo-0613.ft-5fd1918ee65d4cd38a5dcf6835066ed7",
"training_file": "<TRAINING_FILE_ID>",
"validation_file": "<VALIDATION_FILE_ID>",
"suffix": "<additional text used to help identify fine-tuned models>"
}'
Zalecamy również uwzględnienie parametru suffix , aby ułatwić rozróżnienie różnych iteracji modelu dostosowanego. suffix pobiera ciąg i jest ustawiony, aby zidentyfikować dostrojony model. Sufiks może zawierać maksymalnie 40 znaków (a-z, A-Z, 0-9 i _), które zostaną dodane do nazwy dostosowanego modelu.
Jeśli nie masz pewności co do identyfikatora dostosowanego modelu, te informacje można znaleźć na stronie Modele rozwiązania Azure AI Foundry lub wygenerować listę modeli dla danego zasobu usługi Azure OpenAI przy użyciu interfejsu API REST.
Dostrajanie obrazów
Dostrajanie jest również możliwe w przypadku obrazów w plikach JSONL. Podobnie jak w przypadku wysyłania jednego lub wielu danych wejściowych obrazów do ukończenia czatu, możesz uwzględnić te same typy komunikatów w danych treningowych. Obrazy mogą być udostępniane jako publicznie dostępne adresy URL lub identyfikatory URI danych zawierające obrazy zakodowane w formacie base64.
Wymagania dotyczące zestawu danych obrazów
- Plik szkoleniowy może zawierać maksymalnie 50 000 przykładów zawierających obrazy (nie w tym przykłady tekstu).
- Każdy przykład może mieć co najwyżej 64 obrazy.
- Każdy obraz może mieć co najwyżej 10 MB.
Formatuj
Obrazy muszą być następujące:
- JPEG
- PNG
- WebP
Obrazy muszą być w trybie obrazu RGB lub RGBA.
Nie można dołączać obrazów jako danych wyjściowych z komunikatów z rolą asystenta.
Zasady kon tryb namiotu ration
Skanujemy obrazy przed rozpoczęciem szkolenia, aby upewnić się, że są one zgodne z naszymi zasadami użytkowania— Uwaga dotycząca przejrzystości. Może to spowodować opóźnienie w walidacji pliku przed rozpoczęciem dostrajania.
Obrazy zawierające następujące elementy zostaną wykluczone z zestawu danych i nie będą używane do trenowania:
- Osoby
- Twarze
- CAPTCHAs
Ważne
W przypadku procesu dostrajania twarzy dostrajania wzroku: wyświetlamy ekran twarzy/osób, aby pominąć te obrazy z trenowania modelu. Możliwość kontroli twarzy wykorzystuje wykrywanie twarzy BEZ identyfikacji twarzy, co oznacza, że nie tworzymy szablonów twarzy ani nie mierzymy określonej geometrii twarzy, a technologia używana do wyświetlania twarzy nie jest w stanie jednoznacznie zidentyfikować osób. Aby dowiedzieć się więcej na temat danych i prywatności na potrzeby rozpoznawania twarzy, zapoznaj się z tematem Dane i prywatność w usługach rozpoznawania twarzy — Azure AI Services | Microsoft Learn.
Rozwiązywanie problemów
Jak mogę włączyć dostrajanie?
Aby pomyślnie uzyskać dostęp do dostrajania, musisz mieć przypisany współautor openAI usług Cognitive Services. Nawet osoba z uprawnieniami administratora usługi wysokiego poziomu będzie nadal potrzebować tego konta jawnie ustawionego w celu uzyskania dostępu do dostrajania. Aby uzyskać więcej informacji, zapoznaj się ze wskazówkami dotyczącymi kontroli dostępu opartej na rolach.
Dlaczego przekazywanie nie powiodło się?
Jeśli przekazywanie pliku nie powiedzie się w programie Azure OpenAI Studio, możesz wyświetlić komunikat o błędzie w obszarze "pliki danych" w usłudze Azure OpenAI Studio. Umieść wskaźnik myszy na miejscu, w którym zostanie wyświetlony komunikat "błąd" (w kolumnie stanu), a wyjaśnienie błędu zostanie wyświetlone.

Mój dobrze dostrojony model nie wydaje się być ulepszony
Brak komunikatu systemowego: po dostrojeniu należy podać komunikat systemowy. Podczas korzystania z modelu dostrajania należy podać ten sam komunikat systemowy. Jeśli podasz inny komunikat systemowy, mogą pojawić się inne wyniki niż te, dla których się dostroisz.
Za mało danych: chociaż 10 jest minimum do uruchomienia potoku, potrzebujesz setek do tysięcy punktów danych, aby nauczyć model nowej umiejętności. Zbyt mało punktów danych wiąże się z nadmiernym dopasowaniem i słabą uogólnioną. Twój dostosowany model może dobrze działać na danych treningowych, ale źle na innych danych, ponieważ zapamiętał przykłady trenowania zamiast wzorców uczenia. Aby uzyskać najlepsze wyniki, zaplanuj przygotowanie zestawu danych z setkami lub tysiącami punktów danych.
Nieprawidłowe dane: słabo wyselekcjonowane lub nierepresacyjne zestawy danych spowodują wygenerowanie modelu o niskiej jakości. Model może uczyć się niedokładnych lub stronniczych wzorców z zestawu danych. Jeśli na przykład trenujesz czatbota na potrzeby obsługi klienta, ale dostarczasz tylko dane szkoleniowe dla jednego scenariusza (np. zwracanego elementu), nie będzie wiedział, jak reagować na inne scenariusze. Jeśli jednak dane szkoleniowe są nieprawidłowe (zawierają niepoprawne odpowiedzi), model nauczy się dostarczać nieprawidłowe wyniki.
Dostrajanie z wizją
Co zrobić, jeśli obrazy zostaną pominięte
Obrazy mogą być pomijane z następujących powodów:
- zawiera CAPTCHAs
- zawiera osoby
- zawiera twarze
Usuń obraz. Na razie nie możemy dostroić modeli z obrazami zawierającymi te jednostki.
Typowe problemy
| Problem | Przyczyna/rozwiązanie |
|---|---|
| Pominięte obrazy | Obrazy mogą być pomijane z następujących powodów: zawiera elementy CAPTCHA, osoby lub twarze. Usuń obraz. Na razie nie możemy dostroić modeli z obrazami zawierającymi te jednostki. |
| Niedostępny adres URL | Sprawdź, czy adres URL obrazu jest publicznie dostępny. |
| Obraz jest za duży | Sprawdź, czy obrazy mieszczą się w naszych limitach rozmiaru zestawu danych. |
| Nieprawidłowy format obrazu | Sprawdź, czy obrazy mieszczą się w naszym formacie zestawu danych. |
Jak przekazać duże pliki
Pliki szkoleniowe mogą być dość duże. Pliki można przekazywać maksymalnie 8 GB w wielu częściach przy użyciu interfejsu API przekazywania, a nie interfejsu API plików, co umożliwia przekazywanie plików do 512 MB.
Obniżanie kosztów trenowania
Jeśli ustawisz parametr szczegółów obrazu na niski, rozmiar obrazu zostanie zmieniony na 512 o 512 pikseli i jest reprezentowany tylko przez 85 tokenów niezależnie od jego rozmiaru. Spowoduje to zmniejszenie kosztów trenowania.
{
"type": "image_url",
"image_url": {
"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png",
"detail": "low"
}
}
Inne zagadnienia dotyczące dostrajania obrazów
Aby kontrolować wierność zrozumienia obrazu, ustaw parametr szczegółów parametru image_url na low, highlub auto dla każdego obrazu. Wpłynie to również na liczbę tokenów na obraz, które model widzi w czasie trenowania i wpłynie na koszt trenowania.
Następne kroki
- Zapoznaj się z możliwościami dostosowywania w samouczku dostrajania usługi Azure OpenAI.
- Przegląd dostępności regionalnej modelu dostosowywania szczegółowego
- Dowiedz się więcej o limitach przydziałów usługi Azure OpenAI