Szybki start: rozpoczynanie pracy z generowaniem dźwięku usługi Azure OpenAI
Model gpt-4o-audio-preview wprowadza modalność audio do istniejącego /chat/completions interfejsu API. Model audio rozszerza potencjał aplikacji sztucznej inteligencji w interakcjach tekstowych i głosowych oraz analizie audio. Modalności obsługiwane w gpt-4o-audio-preview modelu obejmują: tekst, dźwięk i tekst + dźwięk.
Oto tabela obsługiwanych modalności z przykładowymi przypadkami użycia:
| Dane wejściowe modalności | Dane wyjściowe modalności | Przykładowy przypadek użycia |
|---|---|---|
| Text | Tekst i dźwięk | Zamiana tekstu na mowę, generowanie książki audio |
| Audio | Tekst i dźwięk | Transkrypcja audio, generowanie książek audio |
| Audio | Text | Transkrypcja audio |
| Tekst i dźwięk | Tekst i dźwięk | Generowanie książek audio |
| Tekst i dźwięk | Text | Transkrypcja audio |
Dzięki możliwościom generowania dźwięku można osiągnąć bardziej dynamiczne i interaktywne aplikacje sztucznej inteligencji. Modele, które obsługują dane wejściowe i wyjściowe audio, umożliwiają generowanie odpowiedzi audio mówionych na monity i używanie danych wejściowych audio w celu wyświetlenia monitu o model.
Obsługiwane modele
Obecnie tylko gpt-4o-audio-preview wersja: 2024-12-17 obsługuje generowanie dźwięku.
Model gpt-4o-audio-preview jest dostępny dla wdrożeń globalnych w regionach Wschodnie stany USA 2 i Szwecja Środkowa.
Obecnie następujące głosy są obsługiwane w przypadku dźwięku wychodzącego: Stop, Echo i Shimmer.
Maksymalny rozmiar pliku audio to 20 MB.
Uwaga
Interfejs API czasu rzeczywistego używa tego samego podstawowego modelu audio GPT-4o co interfejs API uzupełniania, ale jest zoptymalizowany pod kątem interakcji audio w czasie rzeczywistym z małymi opóźnieniami.
Obsługa interfejsu API
Obsługa uzupełniania audio została po raz pierwszy dodana w wersji 2025-01-01-previewinterfejsu API .
Wdrażanie modelu na potrzeby generowania dźwięku
Aby wdrożyć gpt-4o-audio-preview model w portalu azure AI Foundry:
- Przejdź do strony usługi Azure OpenAI Service w portalu usługi Azure AI Foundry. Upewnij się, że zalogowano się przy użyciu subskrypcji platformy Azure, która ma zasób usługi Azure OpenAI Service i wdrożony
gpt-4o-audio-previewmodel. - Wybierz plac zabaw czatu w obszarze Place zabaw w okienku po lewej stronie.
- Wybierz pozycję + Utwórz nowe wdrożenie>z modeli podstawowych, aby otworzyć okno wdrażania.
- Wyszukaj i wybierz
gpt-4o-audio-previewmodel, a następnie wybierz pozycję Wdróż do wybranego zasobu. - W kreatorze wdrażania wybierz
2024-12-17wersję modelu. - Postępuj zgodnie z instrukcjami kreatora, aby zakończyć wdrażanie modelu.
Teraz, gdy masz wdrożenie gpt-4o-audio-preview modelu, możesz wchodzić z nim w interakcje w portalu Usługi Azure AI Foundry — plac zabaw dla czatów lub interfejs API uzupełniania czatów.
Korzystanie z generowania dźwięku GPT-4o
Aby porozmawiać z wdrożonym gpt-4o-audio-preview modelem na placu zabaw czatu w portalu Azure AI Foundry, wykonaj następujące kroki:
Przejdź do strony usługi Azure OpenAI Service w portalu usługi Azure AI Foundry. Upewnij się, że zalogowano się przy użyciu subskrypcji platformy Azure, która ma zasób usługi Azure OpenAI Service i wdrożony
gpt-4o-audio-previewmodel.Wybierz plac zabaw czatu w obszarze Zasób plac zabaw w okienku po lewej stronie.
Wybierz wdrożony
gpt-4o-audio-previewmodel z listy rozwijanej Wdrażanie .Zacznij rozmawiać z modelem i słuchać odpowiedzi audio.
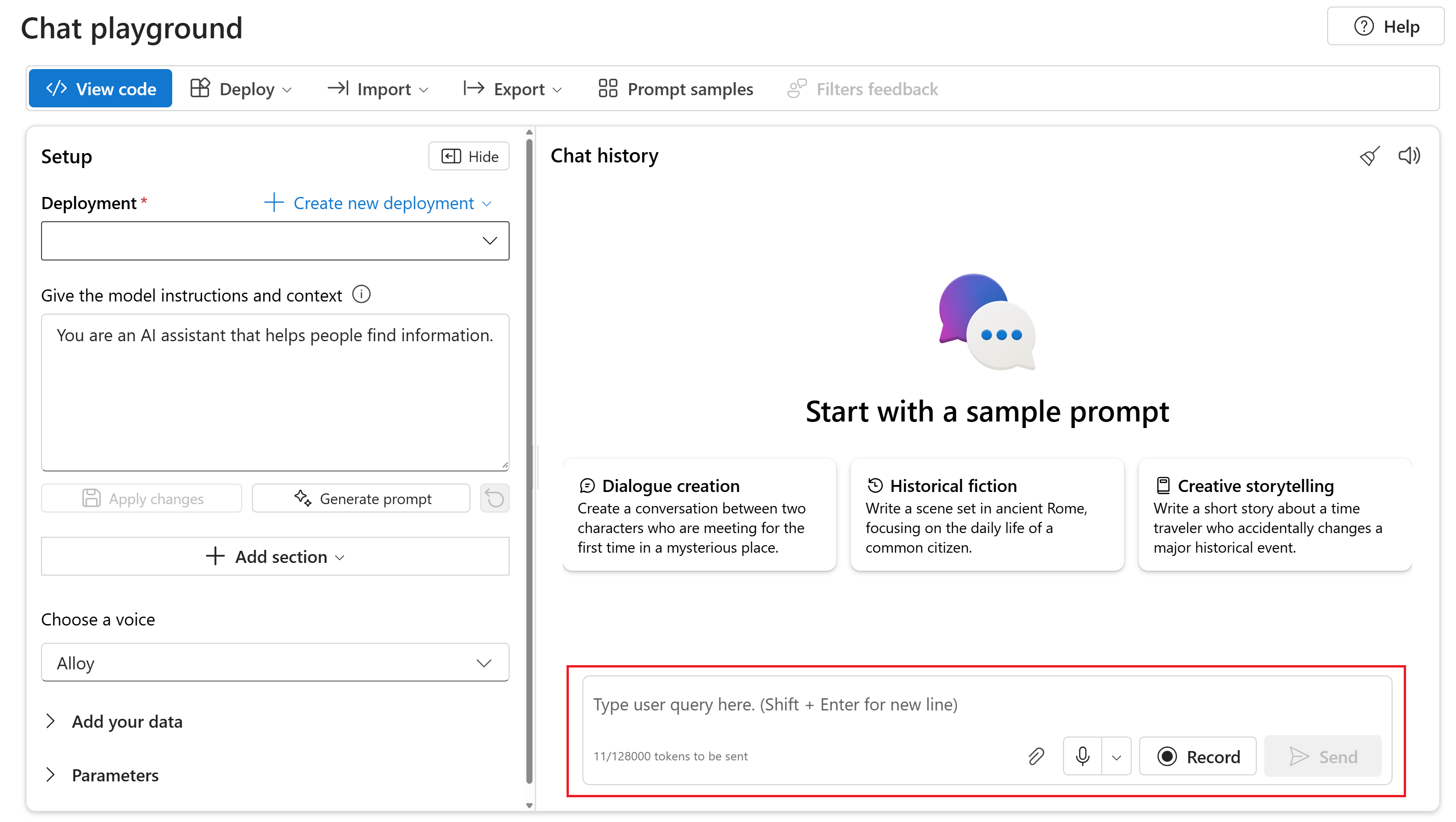
Masz następujące możliwości:
- Nagrywaj monity audio.
- Dołącz pliki audio do czatu.
- Wprowadź monity tekstowe.

Dokumentacja referencyjna — przykłady | pakietu kodu | źródłowego biblioteki źródłowej (npm)Samples |
Model gpt-4o-audio-preview wprowadza modalność audio do istniejącego /chat/completions interfejsu API. Model audio rozszerza potencjał aplikacji sztucznej inteligencji w interakcjach tekstowych i głosowych oraz analizie audio. Modalności obsługiwane w gpt-4o-audio-preview modelu obejmują: tekst, dźwięk i tekst + dźwięk.
Oto tabela obsługiwanych modalności z przykładowymi przypadkami użycia:
| Dane wejściowe modalności | Dane wyjściowe modalności | Przykładowy przypadek użycia |
|---|---|---|
| Text | Tekst i dźwięk | Zamiana tekstu na mowę, generowanie książki audio |
| Audio | Tekst i dźwięk | Transkrypcja audio, generowanie książek audio |
| Audio | Text | Transkrypcja audio |
| Tekst i dźwięk | Tekst i dźwięk | Generowanie książek audio |
| Tekst i dźwięk | Text | Transkrypcja audio |
Dzięki możliwościom generowania dźwięku można osiągnąć bardziej dynamiczne i interaktywne aplikacje sztucznej inteligencji. Modele, które obsługują dane wejściowe i wyjściowe audio, umożliwiają generowanie odpowiedzi audio mówionych na monity i używanie danych wejściowych audio w celu wyświetlenia monitu o model.
Obsługiwane modele
Obecnie tylko gpt-4o-audio-preview wersja: 2024-12-17 obsługuje generowanie dźwięku.
Model gpt-4o-audio-preview jest dostępny dla wdrożeń globalnych w regionach Wschodnie stany USA 2 i Szwecja Środkowa.
Obecnie następujące głosy są obsługiwane w przypadku dźwięku wychodzącego: Stop, Echo i Shimmer.
Maksymalny rozmiar pliku audio to 20 MB.
Uwaga
Interfejs API czasu rzeczywistego używa tego samego podstawowego modelu audio GPT-4o co interfejs API uzupełniania, ale jest zoptymalizowany pod kątem interakcji audio w czasie rzeczywistym z małymi opóźnieniami.
Obsługa interfejsu API
Obsługa uzupełniania audio została po raz pierwszy dodana w wersji 2025-01-01-previewinterfejsu API .
Wymagania wstępne
- Subskrypcja platformy Azure — utwórz bezpłatnie
- obsługa Node.js LTS lub ESM.
- Zasób usługi Azure OpenAI utworzony w regionach Wschodnie stany USA 2 lub Szwecja Środkowa. Zobacz Dostępność regionów.
- Następnie należy wdrożyć
gpt-4o-audio-previewmodel przy użyciu zasobu usługi Azure OpenAI. Aby uzyskać więcej informacji, zobacz Tworzenie zasobu i wdrażanie modelu za pomocą usługi Azure OpenAI.
Wymagania wstępne dotyczące identyfikatora entra firmy Microsoft
W przypadku zalecanego uwierzytelniania bez klucza za pomocą identyfikatora Entra firmy Microsoft należy wykonać następujące czynności:
- Zainstaluj interfejs wiersza polecenia platformy Azure używany do uwierzytelniania bez klucza za pomocą identyfikatora Entra firmy Microsoft.
-
Cognitive Services UserPrzypisz rolę do konta użytkownika. Role można przypisać w witrynie Azure Portal w obszarze Kontrola dostępu (IAM)>Dodawanie przypisania roli.
Konfiguruj
Utwórz nowy folder
audio-completions-quickstartzawierający aplikację i otwórz program Visual Studio Code w tym folderze za pomocą następującego polecenia:mkdir audio-completions-quickstart && code audio-completions-quickstartUtwórz element
package.jsonza pomocą następującego polecenia:npm init -yZaktualizuj element do ecMAScript
package.jsonza pomocą następującego polecenia:npm pkg set type=moduleZainstaluj bibliotekę klienta openAI dla języka JavaScript za pomocą następujących narzędzi:
npm install openaiAby uzyskać zalecane uwierzytelnianie bez klucza za pomocą identyfikatora Entra firmy Microsoft, zainstaluj pakiet za
@azure/identitypomocą polecenia:npm install @azure/identity
Pobieranie informacji o zasobie
Aby uwierzytelnić aplikację przy użyciu zasobu usługi Azure OpenAI, musisz pobrać następujące informacje:
| Nazwa zmiennej | Wartość |
|---|---|
AZURE_OPENAI_ENDPOINT |
Tę wartość można znaleźć w sekcji Klucze i punkt końcowy podczas badania zasobu w witrynie Azure Portal. |
AZURE_OPENAI_DEPLOYMENT_NAME |
Ta wartość będzie odpowiadać nazwie niestandardowej wybranej dla wdrożenia podczas wdrażania modelu. Tę wartość można znaleźć w obszarze Wdrożenia modelu zarządzania>zasobami w witrynie Azure Portal. |
OPENAI_API_VERSION |
Dowiedz się więcej o wersjach interfejsu API. |
Dowiedz się więcej na temat uwierzytelniania bez klucza i ustawiania zmiennych środowiskowych.
Uwaga
Aby użyć zalecanego uwierzytelniania bez klucza z zestawem SDK, upewnij się, że zmienna AZURE_OPENAI_API_KEY środowiskowa nie jest ustawiona.
Generowanie dźwięku na podstawie wprowadzania tekstu
to-audio.jsUtwórz plik przy użyciu następującego kodu:require("dotenv").config(); const { AzureOpenAI } = require("openai"); const { DefaultAzureCredential, getBearerTokenProvider } = require("@azure/identity"); const { writeFileSync } = require("node:fs"); // Keyless authentication const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); // Set environment variables or edit the corresponding values here. const endpoint = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion = "2025-01-01-preview"; const deployment = "gpt-4o-audio-preview"; const client = new AzureOpenAI({ endpoint, azureADTokenProvider, apiVersion, deployment }); async function main() { // Make the audio chat completions request const response = await client.chat.completions.create({ model: "gpt-4o-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: [ { role: "user", content: "Is a golden retriever a good family dog?" } ] }); // Inspect returned data console.log(response.choices[0]); // Write the output audio data to a file writeFileSync( "dog.wav", Buffer.from(response.choices[0].message.audio.data, 'base64'), { encoding: "utf-8" } ); } main().catch((err) => { console.error("Error occurred:", err); }); module.exports = { main };Zaloguj się do platformy Azure przy użyciu następującego polecenia:
az loginUruchom plik JavaScript.
node to-audio.js
Poczekaj chwilę, aby uzyskać odpowiedź.
Dane wyjściowe generowania dźwięku z wprowadzania tekstu
Skrypt generuje plik audio o nazwie dog.wav w tym samym katalogu co skrypt. Plik dźwiękowy zawiera szczerą odpowiedź na monit: "Czy złoty retriever jest dobrym psem rodzinnym?"
Generowanie dźwięku i tekstu na podstawie danych wejściowych audio
from-audio.jsUtwórz plik przy użyciu następującego kodu:require("dotenv").config(); const { AzureOpenAI } = require("openai"); const { DefaultAzureCredential, getBearerTokenProvider } = require("@azure/identity"); const fs = require('fs').promises; const { writeFileSync } = require("node:fs"); // Keyless authentication const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); // Set environment variables or edit the corresponding values here. const endpoint = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion = "2025-01-01-preview"; const deployment = "gpt-4o-audio-preview"; const client = new AzureOpenAI({ endpoint, azureADTokenProvider, apiVersion, deployment }); async function main() { // Buffer the audio for input to the chat completion const wavBuffer = await fs.readFile("dog.wav"); const base64str = Buffer.from(wavBuffer).toString("base64"); // Make the audio chat completions request const response = await client.chat.completions.create({ model: "gpt-4o-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: [ { role: "user", content: [ { type: "text", text: "Describe in detail the spoken audio input." }, { type: "input_audio", input_audio: { data: base64str, format: "wav" } } ] } ] }); console.log(response.choices[0]); // Write the output audio data to a file writeFileSync( "analysis.wav", Buffer.from(response.choices[0].message.audio.data, 'base64'), { encoding: "utf-8" } ); } main().catch((err) => { console.error("Error occurred:", err); }); module.exports = { main };Zaloguj się do platformy Azure przy użyciu następującego polecenia:
az loginUruchom plik JavaScript.
node from-audio.js
Poczekaj chwilę, aby uzyskać odpowiedź.
Dane wyjściowe generowania dźwięku i tekstu z danych wejściowych audio
Skrypt generuje transkrypcję podsumowania danych wejściowych dźwięku mówionego. Generuje również plik audio o nazwie analysis.wav w tym samym katalogu co skrypt. Plik dźwiękowy zawiera wypowiedzianą odpowiedź na monit.
Generowanie dźwięku i używanie uzupełniania czatu wielowrackowego
multi-turn.jsUtwórz plik przy użyciu następującego kodu:require("dotenv").config(); const { AzureOpenAI } = require("openai"); const { DefaultAzureCredential, getBearerTokenProvider } = require("@azure/identity"); const fs = require('fs').promises; // Keyless authentication const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); // Set environment variables or edit the corresponding values here. const endpoint = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion = "2025-01-01-preview"; const deployment = "gpt-4o-audio-preview"; const client = new AzureOpenAI({ endpoint, azureADTokenProvider, apiVersion, deployment }); async function main() { // Buffer the audio for input to the chat completion const wavBuffer = await fs.readFile("dog.wav"); const base64str = Buffer.from(wavBuffer).toString("base64"); // Initialize messages with the first turn's user input const messages = [ { role: "user", content: [ { type: "text", text: "Describe in detail the spoken audio input." }, { type: "input_audio", input_audio: { data: base64str, format: "wav" } } ] } ]; // Get the first turn's response const response = await client.chat.completions.create({ model: "gpt-4o-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: messages }); console.log(response.choices[0]); // Add a history message referencing the previous turn's audio by ID messages.push({ role: "assistant", audio: { id: response.choices[0].message.audio.id } }); // Add a new user message for the second turn messages.push({ role: "user", content: [ { type: "text", text: "Very concisely summarize the favorability." } ] }); // Send the follow-up request with the accumulated messages const followResponse = await client.chat.completions.create({ model: "gpt-4o-audio-preview", messages: messages }); console.log(followResponse.choices[0].message.content); } main().catch((err) => { console.error("Error occurred:", err); }); module.exports = { main };Zaloguj się do platformy Azure przy użyciu następującego polecenia:
az loginUruchom plik JavaScript.
node multi-turn.js
Poczekaj chwilę, aby uzyskać odpowiedź.
Dane wyjściowe dla uzupełniania czatu wielowrackowego
Skrypt generuje transkrypcję podsumowania danych wejściowych dźwięku mówionego. Następnie sprawia, że ukończenie czatu wielowrotnego w celu krótkiego podsumowania danych wejściowych dźwięku mówionego.
Przykłady pakietów | kodu źródłowego | biblioteki
Model gpt-4o-audio-preview wprowadza modalność audio do istniejącego /chat/completions interfejsu API. Model audio rozszerza potencjał aplikacji sztucznej inteligencji w interakcjach tekstowych i głosowych oraz analizie audio. Modalności obsługiwane w gpt-4o-audio-preview modelu obejmują: tekst, dźwięk i tekst + dźwięk.
Oto tabela obsługiwanych modalności z przykładowymi przypadkami użycia:
| Dane wejściowe modalności | Dane wyjściowe modalności | Przykładowy przypadek użycia |
|---|---|---|
| Text | Tekst i dźwięk | Zamiana tekstu na mowę, generowanie książki audio |
| Audio | Tekst i dźwięk | Transkrypcja audio, generowanie książek audio |
| Audio | Text | Transkrypcja audio |
| Tekst i dźwięk | Tekst i dźwięk | Generowanie książek audio |
| Tekst i dźwięk | Text | Transkrypcja audio |
Dzięki możliwościom generowania dźwięku można osiągnąć bardziej dynamiczne i interaktywne aplikacje sztucznej inteligencji. Modele, które obsługują dane wejściowe i wyjściowe audio, umożliwiają generowanie odpowiedzi audio mówionych na monity i używanie danych wejściowych audio w celu wyświetlenia monitu o model.
Obsługiwane modele
Obecnie tylko gpt-4o-audio-preview wersja: 2024-12-17 obsługuje generowanie dźwięku.
Model gpt-4o-audio-preview jest dostępny dla wdrożeń globalnych w regionach Wschodnie stany USA 2 i Szwecja Środkowa.
Obecnie następujące głosy są obsługiwane w przypadku dźwięku wychodzącego: Stop, Echo i Shimmer.
Maksymalny rozmiar pliku audio to 20 MB.
Uwaga
Interfejs API czasu rzeczywistego używa tego samego podstawowego modelu audio GPT-4o co interfejs API uzupełniania, ale jest zoptymalizowany pod kątem interakcji audio w czasie rzeczywistym z małymi opóźnieniami.
Obsługa interfejsu API
Obsługa uzupełniania audio została po raz pierwszy dodana w wersji 2025-01-01-previewinterfejsu API .
Skorzystaj z tego przewodnika, aby rozpocząć generowanie dźwięku za pomocą zestawu Azure OpenAI SDK dla języka Python.
Wymagania wstępne
- Subskrypcja platformy Azure. Utwórz je bezpłatnie.
- Środowisko Python w wersji 3.8 lub nowszej. Zalecamy używanie języka Python w wersji 3.10 lub nowszej, ale wymagana jest co najmniej wersja python 3.8. Jeśli nie masz zainstalowanej odpowiedniej wersji języka Python, możesz postępować zgodnie z instrukcjami w samouczku języka Python programu VS Code, aby uzyskać najprostszy sposób instalowania języka Python w systemie operacyjnym.
- Zasób usługi Azure OpenAI utworzony w regionach Wschodnie stany USA 2 lub Szwecja Środkowa. Zobacz Dostępność regionów.
- Następnie należy wdrożyć
gpt-4o-audio-previewmodel przy użyciu zasobu usługi Azure OpenAI. Aby uzyskać więcej informacji, zobacz Tworzenie zasobu i wdrażanie modelu za pomocą usługi Azure OpenAI.
Wymagania wstępne dotyczące identyfikatora entra firmy Microsoft
W przypadku zalecanego uwierzytelniania bez klucza za pomocą identyfikatora Entra firmy Microsoft należy wykonać następujące czynności:
- Zainstaluj interfejs wiersza polecenia platformy Azure używany do uwierzytelniania bez klucza za pomocą identyfikatora Entra firmy Microsoft.
-
Cognitive Services UserPrzypisz rolę do konta użytkownika. Role można przypisać w witrynie Azure Portal w obszarze Kontrola dostępu (IAM)>Dodawanie przypisania roli.
Konfiguruj
Utwórz nowy folder
audio-completions-quickstartzawierający aplikację i otwórz program Visual Studio Code w tym folderze za pomocą następującego polecenia:mkdir audio-completions-quickstart && code audio-completions-quickstartTworzenie środowiska wirtualnego. Jeśli masz już zainstalowany język Python w wersji 3.10 lub nowszej, możesz utworzyć środowisko wirtualne przy użyciu następujących poleceń:
Aktywowanie środowiska języka Python oznacza, że po uruchomieniu
pythonlubpipw wierszu polecenia należy użyć interpretera języka Python zawartego.venvw folderze aplikacji. Możesz użyćdeactivatepolecenia , aby zamknąć środowisko wirtualne języka Python i później ponownie aktywować je w razie potrzeby.Napiwek
Zalecamy utworzenie i aktywowanie nowego środowiska języka Python w celu zainstalowania pakietów potrzebnych na potrzeby tego samouczka. Nie instaluj pakietów w globalnej instalacji języka Python. Zawsze należy używać środowiska wirtualnego lub conda podczas instalowania pakietów języka Python. W przeciwnym razie możesz przerwać globalną instalację języka Python.
Zainstaluj bibliotekę klienta OpenAI dla języka Python za pomocą następujących elementów:
pip install openaiAby uzyskać zalecane uwierzytelnianie bez klucza za pomocą identyfikatora Entra firmy Microsoft, zainstaluj pakiet za
azure-identitypomocą polecenia:pip install azure-identity
Pobieranie informacji o zasobie
Aby uwierzytelnić aplikację przy użyciu zasobu usługi Azure OpenAI, musisz pobrać następujące informacje:
| Nazwa zmiennej | Wartość |
|---|---|
AZURE_OPENAI_ENDPOINT |
Tę wartość można znaleźć w sekcji Klucze i punkt końcowy podczas badania zasobu w witrynie Azure Portal. |
AZURE_OPENAI_DEPLOYMENT_NAME |
Ta wartość będzie odpowiadać nazwie niestandardowej wybranej dla wdrożenia podczas wdrażania modelu. Tę wartość można znaleźć w obszarze Wdrożenia modelu zarządzania>zasobami w witrynie Azure Portal. |
OPENAI_API_VERSION |
Dowiedz się więcej o wersjach interfejsu API. |
Dowiedz się więcej na temat uwierzytelniania bez klucza i ustawiania zmiennych środowiskowych.
Generowanie dźwięku na podstawie wprowadzania tekstu
to-audio.pyUtwórz plik przy użyciu następującego kodu:import requests import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential, get_bearer_token_provider token_provider=get_bearer_token_provider(DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default") # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication client=AzureOpenAI( azure_ad_token_provider=token_provider, azure_endpoint=endpoint, api_version="2025-01-01-preview" ) # Make the audio chat completions request completion=client.chat.completions.create( model="gpt-4o-audio-preview", modalities=["text", "audio"], audio={"voice": "alloy", "format": "wav"}, messages=[ { "role": "user", "content": "Is a golden retriever a good family dog?" } ] ) print(completion.choices[0]) # Write the output audio data to a file wav_bytes=base64.b64decode(completion.choices[0].message.audio.data) with open("dog.wav", "wb") as f: f.write(wav_bytes)Uruchom plik języka Python.
python to-audio.py
Poczekaj chwilę, aby uzyskać odpowiedź.
Dane wyjściowe generowania dźwięku z wprowadzania tekstu
Skrypt generuje plik audio o nazwie dog.wav w tym samym katalogu co skrypt. Plik dźwiękowy zawiera szczerą odpowiedź na monit: "Czy złoty retriever jest dobrym psem rodzinnym?"
Generowanie dźwięku i tekstu na podstawie danych wejściowych audio
from-audio.pyUtwórz plik przy użyciu następującego kodu:import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential, get_bearer_token_provider token_provider=get_bearer_token_provider(DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default") # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication client=AzureOpenAI( azure_ad_token_provider=token_provider, azure_endpoint=endpoint api_version="2025-01-01-preview" ) # Read and encode audio file with open('dog.wav', 'rb') as wav_reader: encoded_string = base64.b64encode(wav_reader.read()).decode('utf-8') # Make the audio chat completions request completion = client.chat.completions.create( model="gpt-4o-audio-preview", modalities=["text", "audio"], audio={"voice": "alloy", "format": "wav"}, messages=[ { "role": "user", "content": [ { "type": "text", "text": "Describe in detail the spoken audio input." }, { "type": "input_audio", "input_audio": { "data": encoded_string, "format": "wav" } } ] }, ] ) print(completion.choices[0].message.audio.transcript) # Write the output audio data to a file wav_bytes = base64.b64decode(completion.choices[0].message.audio.data) with open("analysis.wav", "wb") as f: f.write(wav_bytes)Uruchom plik języka Python.
python from-audio.py
Poczekaj chwilę, aby uzyskać odpowiedź.
Dane wyjściowe generowania dźwięku i tekstu z danych wejściowych audio
Skrypt generuje transkrypcję podsumowania danych wejściowych dźwięku mówionego. Generuje również plik audio o nazwie analysis.wav w tym samym katalogu co skrypt. Plik dźwiękowy zawiera wypowiedzianą odpowiedź na monit.
Generowanie dźwięku i używanie uzupełniania czatu wielowrackowego
multi-turn.pyUtwórz plik przy użyciu następującego kodu:import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential, get_bearer_token_provider token_provider=get_bearer_token_provider(DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default") # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication client=AzureOpenAI( azure_ad_token_provider=token_provider, azure_endpoint=endpoint, api_version="2025-01-01-preview" ) # Read and encode audio file with open('dog.wav', 'rb') as wav_reader: encoded_string = base64.b64encode(wav_reader.read()).decode('utf-8') # Initialize messages with the first turn's user input messages = [ { "role": "user", "content": [ { "type": "text", "text": "Describe in detail the spoken audio input." }, { "type": "input_audio", "input_audio": { "data": encoded_string, "format": "wav" } } ] }] # Get the first turn's response completion = client.chat.completions.create( model="gpt-4o-audio-preview", modalities=["text", "audio"], audio={"voice": "alloy", "format": "wav"}, messages=messages ) print("Get the first turn's response:") print(completion.choices[0].message.audio.transcript) print("Add a history message referencing the first turn's audio by ID:") print(completion.choices[0].message.audio.id) # Add a history message referencing the first turn's audio by ID messages.append({ "role": "assistant", "audio": { "id": completion.choices[0].message.audio.id } }) # Add the next turn's user message messages.append({ "role": "user", "content": "Very briefly, summarize the favorability." }) # Send the follow-up request with the accumulated messages completion = client.chat.completions.create( model="gpt-4o-audio-preview", messages=messages ) print("Very briefly, summarize the favorability.") print(completion.choices[0].message.content)Uruchom plik języka Python.
python multi-turn.py
Poczekaj chwilę, aby uzyskać odpowiedź.
Dane wyjściowe dla uzupełniania czatu wielowrackowego
Skrypt generuje transkrypcję podsumowania danych wejściowych dźwięku mówionego. Następnie sprawia, że ukończenie czatu wielowrotnego w celu krótkiego podsumowania danych wejściowych dźwięku mówionego.
Specyfikacje interfejsu API REST |
Model gpt-4o-audio-preview wprowadza modalność audio do istniejącego /chat/completions interfejsu API. Model audio rozszerza potencjał aplikacji sztucznej inteligencji w interakcjach tekstowych i głosowych oraz analizie audio. Modalności obsługiwane w gpt-4o-audio-preview modelu obejmują: tekst, dźwięk i tekst + dźwięk.
Oto tabela obsługiwanych modalności z przykładowymi przypadkami użycia:
| Dane wejściowe modalności | Dane wyjściowe modalności | Przykładowy przypadek użycia |
|---|---|---|
| Text | Tekst i dźwięk | Zamiana tekstu na mowę, generowanie książki audio |
| Audio | Tekst i dźwięk | Transkrypcja audio, generowanie książek audio |
| Audio | Text | Transkrypcja audio |
| Tekst i dźwięk | Tekst i dźwięk | Generowanie książek audio |
| Tekst i dźwięk | Text | Transkrypcja audio |
Dzięki możliwościom generowania dźwięku można osiągnąć bardziej dynamiczne i interaktywne aplikacje sztucznej inteligencji. Modele, które obsługują dane wejściowe i wyjściowe audio, umożliwiają generowanie odpowiedzi audio mówionych na monity i używanie danych wejściowych audio w celu wyświetlenia monitu o model.
Obsługiwane modele
Obecnie tylko gpt-4o-audio-preview wersja: 2024-12-17 obsługuje generowanie dźwięku.
Model gpt-4o-audio-preview jest dostępny dla wdrożeń globalnych w regionach Wschodnie stany USA 2 i Szwecja Środkowa.
Obecnie następujące głosy są obsługiwane w przypadku dźwięku wychodzącego: Stop, Echo i Shimmer.
Maksymalny rozmiar pliku audio to 20 MB.
Uwaga
Interfejs API czasu rzeczywistego używa tego samego podstawowego modelu audio GPT-4o co interfejs API uzupełniania, ale jest zoptymalizowany pod kątem interakcji audio w czasie rzeczywistym z małymi opóźnieniami.
Obsługa interfejsu API
Obsługa uzupełniania audio została po raz pierwszy dodana w wersji 2025-01-01-previewinterfejsu API .
Wymagania wstępne
- Subskrypcja platformy Azure. Utwórz je bezpłatnie.
- Środowisko Python w wersji 3.8 lub nowszej. Zalecamy używanie języka Python w wersji 3.10 lub nowszej, ale wymagana jest co najmniej wersja python 3.8. Jeśli nie masz zainstalowanej odpowiedniej wersji języka Python, możesz postępować zgodnie z instrukcjami w samouczku języka Python programu VS Code, aby uzyskać najprostszy sposób instalowania języka Python w systemie operacyjnym.
- Zasób usługi Azure OpenAI utworzony w regionach Wschodnie stany USA 2 lub Szwecja Środkowa. Zobacz Dostępność regionów.
- Następnie należy wdrożyć
gpt-4o-audio-previewmodel przy użyciu zasobu usługi Azure OpenAI. Aby uzyskać więcej informacji, zobacz Tworzenie zasobu i wdrażanie modelu za pomocą usługi Azure OpenAI.
Wymagania wstępne dotyczące identyfikatora entra firmy Microsoft
W przypadku zalecanego uwierzytelniania bez klucza za pomocą identyfikatora Entra firmy Microsoft należy wykonać następujące czynności:
- Zainstaluj interfejs wiersza polecenia platformy Azure używany do uwierzytelniania bez klucza za pomocą identyfikatora Entra firmy Microsoft.
-
Cognitive Services UserPrzypisz rolę do konta użytkownika. Role można przypisać w witrynie Azure Portal w obszarze Kontrola dostępu (IAM)>Dodawanie przypisania roli.
Konfiguruj
Utwórz nowy folder
audio-completions-quickstartzawierający aplikację i otwórz program Visual Studio Code w tym folderze za pomocą następującego polecenia:mkdir audio-completions-quickstart && code audio-completions-quickstartTworzenie środowiska wirtualnego. Jeśli masz już zainstalowany język Python w wersji 3.10 lub nowszej, możesz utworzyć środowisko wirtualne przy użyciu następujących poleceń:
Aktywowanie środowiska języka Python oznacza, że po uruchomieniu
pythonlubpipw wierszu polecenia należy użyć interpretera języka Python zawartego.venvw folderze aplikacji. Możesz użyćdeactivatepolecenia , aby zamknąć środowisko wirtualne języka Python i później ponownie aktywować je w razie potrzeby.Napiwek
Zalecamy utworzenie i aktywowanie nowego środowiska języka Python w celu zainstalowania pakietów potrzebnych na potrzeby tego samouczka. Nie instaluj pakietów w globalnej instalacji języka Python. Zawsze należy używać środowiska wirtualnego lub conda podczas instalowania pakietów języka Python. W przeciwnym razie możesz przerwać globalną instalację języka Python.
Zainstaluj bibliotekę klienta OpenAI dla języka Python za pomocą następujących elementów:
pip install openaiAby uzyskać zalecane uwierzytelnianie bez klucza za pomocą identyfikatora Entra firmy Microsoft, zainstaluj pakiet za
azure-identitypomocą polecenia:pip install azure-identity
Pobieranie informacji o zasobie
Aby uwierzytelnić aplikację przy użyciu zasobu usługi Azure OpenAI, musisz pobrać następujące informacje:
| Nazwa zmiennej | Wartość |
|---|---|
AZURE_OPENAI_ENDPOINT |
Tę wartość można znaleźć w sekcji Klucze i punkt końcowy podczas badania zasobu w witrynie Azure Portal. |
AZURE_OPENAI_DEPLOYMENT_NAME |
Ta wartość będzie odpowiadać nazwie niestandardowej wybranej dla wdrożenia podczas wdrażania modelu. Tę wartość można znaleźć w obszarze Wdrożenia modelu zarządzania>zasobami w witrynie Azure Portal. |
OPENAI_API_VERSION |
Dowiedz się więcej o wersjach interfejsu API. |
Dowiedz się więcej na temat uwierzytelniania bez klucza i ustawiania zmiennych środowiskowych.
Generowanie dźwięku na podstawie wprowadzania tekstu
to-audio.pyUtwórz plik przy użyciu następującego kodu:import requests import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication credential = DefaultAzureCredential() token = credential.get_token("https://cognitiveservices.azure.com/.default") api_version = '2025-01-01-preview' url = f"{endpoint}/openai/deployments/gpt-4o-audio-preview/chat/completions?api-version={api_version}" headers= { "Authorization": f"Bearer {token.token}", "Content-Type": "application/json" } body = { "modalities": ["audio", "text"], "model": "gpt-4o-audio-preview", "audio": { "format": "wav", "voice": "alloy" }, "messages": [ { "role": "user", "content": [ { "type": "text", "text": "Is a golden retriever a good family dog?" } ] } ] } # Make the audio chat completions request completion = requests.post(url, headers=headers, json=body) audio_data = completion.json()['choices'][0]['message']['audio']['data'] # Write the output audio data to a file wav_bytes = base64.b64decode(audio_data) with open("dog.wav", "wb") as f: f.write(wav_bytes)Uruchom plik języka Python.
python to-audio.py
Poczekaj chwilę, aby uzyskać odpowiedź.
Dane wyjściowe generowania dźwięku z wprowadzania tekstu
Skrypt generuje plik audio o nazwie dog.wav w tym samym katalogu co skrypt. Plik dźwiękowy zawiera szczerą odpowiedź na monit: "Czy złoty retriever jest dobrym psem rodzinnym?"
Generowanie dźwięku i tekstu na podstawie danych wejściowych audio
from-audio.pyUtwórz plik przy użyciu następującego kodu:import requests import base64 import os from azure.identity import DefaultAzureCredential # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication credential = DefaultAzureCredential() token = credential.get_token("https://cognitiveservices.azure.com/.default") # Read and encode audio file with open('dog.wav', 'rb') as wav_reader: encoded_string = base64.b64encode(wav_reader.read()).decode('utf-8') api_version = '2025-01-01-preview' url = f"{endpoint}/openai/deployments/gpt-4o-audio-preview/chat/completions?api-version={api_version}" headers= { "Authorization": f"Bearer {token.token}", "Content-Type": "application/json" } body = { "modalities": ["audio", "text"], "model": "gpt-4o-audio-preview", "audio": { "format": "wav", "voice": "alloy" }, "messages": [ { "role": "user", "content": [ { "type": "text", "text": "Describe in detail the spoken audio input." }, { "type": "input_audio", "input_audio": { "data": encoded_string, "format": "wav" } } ] }, ] } completion = requests.post(url, headers=headers, json=body) print(completion.json()['choices'][0]['message']['audio']['transcript']) # Write the output audio data to a file audio_data = completion.json()['choices'][0]['message']['audio']['data'] wav_bytes = base64.b64decode(audio_data) with open("analysis.wav", "wb") as f: f.write(wav_bytes)Uruchom plik języka Python.
python from-audio.py
Poczekaj chwilę, aby uzyskać odpowiedź.
Dane wyjściowe generowania dźwięku i tekstu z danych wejściowych audio
Skrypt generuje transkrypcję podsumowania danych wejściowych dźwięku mówionego. Generuje również plik audio o nazwie analysis.wav w tym samym katalogu co skrypt. Plik dźwiękowy zawiera wypowiedzianą odpowiedź na monit.
Generowanie dźwięku i używanie uzupełniania czatu wielowrackowego
multi-turn.pyUtwórz plik przy użyciu następującego kodu:import requests import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication credential = DefaultAzureCredential() token = credential.get_token("https://cognitiveservices.azure.com/.default") api_version = '2025-01-01-preview' url = f"{endpoint}/openai/deployments/gpt-4o-audio-preview/chat/completions?api-version={api_version}" headers= { "Authorization": f"Bearer {token.token}", "Content-Type": "application/json" } # Read and encode audio file with open('dog.wav', 'rb') as wav_reader: encoded_string = base64.b64encode(wav_reader.read()).decode('utf-8') # Initialize messages with the first turn's user input messages = [ { "role": "user", "content": [ { "type": "text", "text": "Describe in detail the spoken audio input." }, { "type": "input_audio", "input_audio": { "data": encoded_string, "format": "wav" } } ] }] body = { "modalities": ["audio", "text"], "model": "gpt-4o-audio-preview", "audio": { "format": "wav", "voice": "alloy" }, "messages": messages } # Get the first turn's response, including generated audio completion = requests.post(url, headers=headers, json=body) print("Get the first turn's response:") print(completion.json()['choices'][0]['message']['audio']['transcript']) print("Add a history message referencing the first turn's audio by ID:") print(completion.json()['choices'][0]['message']['audio']['id']) # Add a history message referencing the first turn's audio by ID messages.append({ "role": "assistant", "audio": { "id": completion.json()['choices'][0]['message']['audio']['id'] } }) # Add the next turn's user message messages.append({ "role": "user", "content": "Very briefly, summarize the favorability." }) body = { "model": "gpt-4o-audio-preview", "messages": messages } # Send the follow-up request with the accumulated messages completion = requests.post(url, headers=headers, json=body) print("Very briefly, summarize the favorability.") print(completion.json()['choices'][0]['message']['content'])Uruchom plik języka Python.
python multi-turn.py
Poczekaj chwilę, aby uzyskać odpowiedź.
Dane wyjściowe dla uzupełniania czatu wielowrackowego
Skrypt generuje transkrypcję podsumowania danych wejściowych dźwięku mówionego. Następnie sprawia, że ukończenie czatu wielowrotnego w celu krótkiego podsumowania danych wejściowych dźwięku mówionego.
Dokumentacja referencyjna — przykłady | pakietu kodu | źródłowego biblioteki źródłowej (npm)Samples |
Model gpt-4o-audio-preview wprowadza modalność audio do istniejącego /chat/completions interfejsu API. Model audio rozszerza potencjał aplikacji sztucznej inteligencji w interakcjach tekstowych i głosowych oraz analizie audio. Modalności obsługiwane w gpt-4o-audio-preview modelu obejmują: tekst, dźwięk i tekst + dźwięk.
Oto tabela obsługiwanych modalności z przykładowymi przypadkami użycia:
| Dane wejściowe modalności | Dane wyjściowe modalności | Przykładowy przypadek użycia |
|---|---|---|
| Text | Tekst i dźwięk | Zamiana tekstu na mowę, generowanie książki audio |
| Audio | Tekst i dźwięk | Transkrypcja audio, generowanie książek audio |
| Audio | Text | Transkrypcja audio |
| Tekst i dźwięk | Tekst i dźwięk | Generowanie książek audio |
| Tekst i dźwięk | Text | Transkrypcja audio |
Dzięki możliwościom generowania dźwięku można osiągnąć bardziej dynamiczne i interaktywne aplikacje sztucznej inteligencji. Modele, które obsługują dane wejściowe i wyjściowe audio, umożliwiają generowanie odpowiedzi audio mówionych na monity i używanie danych wejściowych audio w celu wyświetlenia monitu o model.
Obsługiwane modele
Obecnie tylko gpt-4o-audio-preview wersja: 2024-12-17 obsługuje generowanie dźwięku.
Model gpt-4o-audio-preview jest dostępny dla wdrożeń globalnych w regionach Wschodnie stany USA 2 i Szwecja Środkowa.
Obecnie następujące głosy są obsługiwane w przypadku dźwięku wychodzącego: Stop, Echo i Shimmer.
Maksymalny rozmiar pliku audio to 20 MB.
Uwaga
Interfejs API czasu rzeczywistego używa tego samego podstawowego modelu audio GPT-4o co interfejs API uzupełniania, ale jest zoptymalizowany pod kątem interakcji audio w czasie rzeczywistym z małymi opóźnieniami.
Obsługa interfejsu API
Obsługa uzupełniania audio została po raz pierwszy dodana w wersji 2025-01-01-previewinterfejsu API .
Wymagania wstępne
- Subskrypcja platformy Azure — utwórz bezpłatnie
- obsługa Node.js LTS lub ESM.
- Język TypeScript zainstalowany globalnie.
- Zasób usługi Azure OpenAI utworzony w regionach Wschodnie stany USA 2 lub Szwecja Środkowa. Zobacz Dostępność regionów.
- Następnie należy wdrożyć
gpt-4o-audio-previewmodel przy użyciu zasobu usługi Azure OpenAI. Aby uzyskać więcej informacji, zobacz Tworzenie zasobu i wdrażanie modelu za pomocą usługi Azure OpenAI.
Wymagania wstępne dotyczące identyfikatora entra firmy Microsoft
W przypadku zalecanego uwierzytelniania bez klucza za pomocą identyfikatora Entra firmy Microsoft należy wykonać następujące czynności:
- Zainstaluj interfejs wiersza polecenia platformy Azure używany do uwierzytelniania bez klucza za pomocą identyfikatora Entra firmy Microsoft.
-
Cognitive Services UserPrzypisz rolę do konta użytkownika. Role można przypisać w witrynie Azure Portal w obszarze Kontrola dostępu (IAM)>Dodawanie przypisania roli.
Konfiguruj
Utwórz nowy folder
audio-completions-quickstartzawierający aplikację i otwórz program Visual Studio Code w tym folderze za pomocą następującego polecenia:mkdir audio-completions-quickstart && code audio-completions-quickstartUtwórz element
package.jsonza pomocą następującego polecenia:npm init -yZaktualizuj element do ecMAScript
package.jsonza pomocą następującego polecenia:npm pkg set type=moduleZainstaluj bibliotekę klienta openAI dla języka JavaScript za pomocą następujących narzędzi:
npm install openaiAby uzyskać zalecane uwierzytelnianie bez klucza za pomocą identyfikatora Entra firmy Microsoft, zainstaluj pakiet za
@azure/identitypomocą polecenia:npm install @azure/identity
Pobieranie informacji o zasobie
Aby uwierzytelnić aplikację przy użyciu zasobu usługi Azure OpenAI, musisz pobrać następujące informacje:
| Nazwa zmiennej | Wartość |
|---|---|
AZURE_OPENAI_ENDPOINT |
Tę wartość można znaleźć w sekcji Klucze i punkt końcowy podczas badania zasobu w witrynie Azure Portal. |
AZURE_OPENAI_DEPLOYMENT_NAME |
Ta wartość będzie odpowiadać nazwie niestandardowej wybranej dla wdrożenia podczas wdrażania modelu. Tę wartość można znaleźć w obszarze Wdrożenia modelu zarządzania>zasobami w witrynie Azure Portal. |
OPENAI_API_VERSION |
Dowiedz się więcej o wersjach interfejsu API. |
Dowiedz się więcej na temat uwierzytelniania bez klucza i ustawiania zmiennych środowiskowych.
Uwaga
Aby użyć zalecanego uwierzytelniania bez klucza z zestawem SDK, upewnij się, że zmienna AZURE_OPENAI_API_KEY środowiskowa nie jest ustawiona.
Generowanie dźwięku na podstawie wprowadzania tekstu
to-audio.tsUtwórz plik przy użyciu następującego kodu:import { writeFileSync } from "node:fs"; import { AzureOpenAI } from "openai/index.mjs"; import { DefaultAzureCredential, getBearerTokenProvider, } from "@azure/identity"; // Set environment variables or edit the corresponding values here. const endpoint: string = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion: string = "2025-01-01-preview"; const deployment: string = "gpt-4o-audio-preview"; // Keyless authentication const getClient = (): AzureOpenAI => { const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); const client = new AzureOpenAI({ endpoint: endpoint, apiVersion: apiVersion, azureADTokenProvider, }); return client; }; const client = getClient(); async function main(): Promise<void> { // Make the audio chat completions request const response = await client.chat.completions.create({ model: "gpt-4o-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: [ { role: "user", content: "Is a golden retriever a good family dog?" } ] }); // Inspect returned data console.log(response.choices[0]); // Write the output audio data to a file if (response.choices[0].message.audio) { writeFileSync( "dog.wav", Buffer.from(response.choices[0].message.audio.data, 'base64'), { encoding: "utf-8" } ); } else { console.error("Audio data is null or undefined."); } } main().catch((err: Error) => { console.error("Error occurred:", err); }); export { main };Utwórz plik do
tsconfig.jsontranspilowania kodu TypeScript i skopiuj następujący kod dla języka ECMAScript.{ "compilerOptions": { "module": "NodeNext", "target": "ES2022", // Supports top-level await "moduleResolution": "NodeNext", "skipLibCheck": true, // Avoid type errors from node_modules "strict": true // Enable strict type-checking options }, "include": ["*.ts"] }Transpiluj z języka TypeScript do języka JavaScript.
tscZaloguj się do platformy Azure przy użyciu następującego polecenia:
az loginUruchom kod za pomocą następującego polecenia:
node to-audio.js
Poczekaj chwilę, aby uzyskać odpowiedź.
Dane wyjściowe generowania dźwięku z wprowadzania tekstu
Skrypt generuje plik audio o nazwie dog.wav w tym samym katalogu co skrypt. Plik dźwiękowy zawiera szczerą odpowiedź na monit: "Czy złoty retriever jest dobrym psem rodzinnym?"
Generowanie dźwięku i tekstu na podstawie danych wejściowych audio
from-audio.tsUtwórz plik przy użyciu następującego kodu:import { AzureOpenAI } from "openai"; import { writeFileSync } from "node:fs"; import { promises as fs } from 'fs'; import { DefaultAzureCredential, getBearerTokenProvider, } from "@azure/identity"; // Set environment variables or edit the corresponding values here. const endpoint: string = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion: string = "2025-01-01-preview"; const deployment: string = "gpt-4o-audio-preview"; // Keyless authentication const getClient = (): AzureOpenAI => { const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); const client = new AzureOpenAI({ endpoint: endpoint, apiVersion: apiVersion, azureADTokenProvider, }); return client; }; const client = getClient(); async function main(): Promise<void> { // Buffer the audio for input to the chat completion const wavBuffer = await fs.readFile("dog.wav"); const base64str = Buffer.from(wavBuffer).toString("base64"); // Make the audio chat completions request const response = await client.chat.completions.create({ model: "gpt-4o-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: [ { role: "user", content: [ { type: "text", text: "Describe in detail the spoken audio input." }, { type: "input_audio", input_audio: { data: base64str, format: "wav" } } ] } ] }); console.log(response.choices[0]); // Write the output audio data to a file if (response.choices[0].message.audio) { writeFileSync("analysis.wav", Buffer.from(response.choices[0].message.audio.data, 'base64'), { encoding: "utf-8" }); } else { console.error("Audio data is null or undefined."); } } main().catch((err: Error) => { console.error("Error occurred:", err); }); export { main };Utwórz plik do
tsconfig.jsontranspilowania kodu TypeScript i skopiuj następujący kod dla języka ECMAScript.{ "compilerOptions": { "module": "NodeNext", "target": "ES2022", // Supports top-level await "moduleResolution": "NodeNext", "skipLibCheck": true, // Avoid type errors from node_modules "strict": true // Enable strict type-checking options }, "include": ["*.ts"] }Transpiluj z języka TypeScript do języka JavaScript.
tscZaloguj się do platformy Azure przy użyciu następującego polecenia:
az loginUruchom kod za pomocą następującego polecenia:
node from-audio.js
Poczekaj chwilę, aby uzyskać odpowiedź.
Dane wyjściowe generowania dźwięku i tekstu z danych wejściowych audio
Skrypt generuje transkrypcję podsumowania danych wejściowych dźwięku mówionego. Generuje również plik audio o nazwie analysis.wav w tym samym katalogu co skrypt. Plik dźwiękowy zawiera wypowiedzianą odpowiedź na monit.
Generowanie dźwięku i używanie uzupełniania czatu wielowrackowego
multi-turn.tsUtwórz plik przy użyciu następującego kodu:import { AzureOpenAI } from "openai/index.mjs"; import { promises as fs } from 'fs'; import { ChatCompletionMessageParam } from "openai/resources/index.mjs"; import { DefaultAzureCredential, getBearerTokenProvider, } from "@azure/identity"; // Set environment variables or edit the corresponding values here. const endpoint: string = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion: string = "2025-01-01-preview"; const deployment: string = "gpt-4o-audio-preview"; // Keyless authentication const getClient = (): AzureOpenAI => { const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); const client = new AzureOpenAI({ endpoint: endpoint, apiVersion: apiVersion, azureADTokenProvider, }); return client; }; const client = getClient(); async function main(): Promise<void> { // Buffer the audio for input to the chat completion const wavBuffer = await fs.readFile("dog.wav"); const base64str = Buffer.from(wavBuffer).toString("base64"); // Initialize messages with the first turn's user input const messages: ChatCompletionMessageParam[] = [ { role: "user", content: [ { type: "text", text: "Describe in detail the spoken audio input." }, { type: "input_audio", input_audio: { data: base64str, format: "wav" } } ] } ]; // Get the first turn's response const response = await client.chat.completions.create({ model: "gpt-4o-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: messages }); console.log(response.choices[0]); // Add a history message referencing the previous turn's audio by ID messages.push({ role: "assistant", audio: response.choices[0].message.audio ? { id: response.choices[0].message.audio.id } : undefined }); // Add a new user message for the second turn messages.push({ role: "user", content: [ { type: "text", text: "Very concisely summarize the favorability." } ] }); // Send the follow-up request with the accumulated messages const followResponse = await client.chat.completions.create({ model: "gpt-4o-audio-preview", messages: messages }); console.log(followResponse.choices[0].message.content); } main().catch((err: Error) => { console.error("Error occurred:", err); }); export { main };Utwórz plik do
tsconfig.jsontranspilowania kodu TypeScript i skopiuj następujący kod dla języka ECMAScript.{ "compilerOptions": { "module": "NodeNext", "target": "ES2022", // Supports top-level await "moduleResolution": "NodeNext", "skipLibCheck": true, // Avoid type errors from node_modules "strict": true // Enable strict type-checking options }, "include": ["*.ts"] }Transpiluj z języka TypeScript do języka JavaScript.
tscZaloguj się do platformy Azure przy użyciu następującego polecenia:
az loginUruchom kod za pomocą następującego polecenia:
node multi-turn.js
Poczekaj chwilę, aby uzyskać odpowiedź.
Dane wyjściowe dla uzupełniania czatu wielowrackowego
Skrypt generuje transkrypcję podsumowania danych wejściowych dźwięku mówionego. Następnie sprawia, że ukończenie czatu wielowrotnego w celu krótkiego podsumowania danych wejściowych dźwięku mówionego.
Czyszczenie zasobów
Jeśli chcesz wyczyścić i usunąć zasób usługi Azure OpenAI, możesz usunąć zasób. Przed usunięciem zasobu należy najpierw usunąć wszystkie wdrożone modele.