Etykietowanie wypowiedzi w programie Language Studio
Po utworzeniu schematu dla projektu należy dodać wypowiedzi szkoleniowe do projektu. Wypowiedzi powinny być podobne do używanych przez użytkowników podczas interakcji z projektem. Po dodaniu wypowiedzi musisz przypisać intencję, do której należy. Po dodaniu wypowiedzi oznacz wyrazy w wypowiedzi, które chcesz wyodrębnić jako jednostki.
Etykietowanie danych jest kluczowym krokiem w cyklu projektowania; te dane są używane w następnym kroku podczas trenowania modelu, aby model mógł uczyć się na podstawie oznaczonych danych. Jeśli masz już etykiety wypowiedzi, możesz bezpośrednio zaimportować je do projektu, ale musisz upewnić się, że dane są zgodne z akceptowanym formatem danych. Zobacz tworzenie projektu , aby dowiedzieć się więcej na temat importowania danych oznaczonych etykietami do projektu. Dane oznaczone etykietami informują model, jak interpretować tekst i jest używany do trenowania i oceny.
Wymagania wstępne
Aby można było oznaczyć dane etykietami, potrzebne są następujące elementy:
- Pomyślnie utworzono projekt.
Aby uzyskać więcej informacji, zobacz cykl projektowania projektu.
Wytyczne dotyczące etykietowania danych
Po utworzeniu schematu i utworzeniu projektu należy oznaczyć je etykietami. Etykietowanie danych jest ważne, aby model wiedział, które wyrazy i zdania są skojarzone z intencjami i jednostkami w projekcie. Poświęcaj czas na etykietowanie wypowiedzi — wprowadzanie i udoskonalanie danych używanych w trenowaniu modeli.
Podczas dodawania wypowiedzi i etykietowania ich należy pamiętać:
Modele uczenia maszynowego są uogólniane na podstawie przekazanych przykładów z etykietami; tym więcej przykładów, tym więcej punktów danych, które model musi wprowadzić w lepsze uogólnienia.
Precyzja, spójność i kompletność danych oznaczonych etykietami są kluczowymi czynnikami do określania wydajności modelu.
- Etykieta dokładnie: Etykietuj każdą intencję i jednostkę do odpowiedniego typu zawsze. Uwzględnij tylko dane sklasyfikowane i wyodrębnione, aby uniknąć niepotrzebnych danych w etykietach.
- Spójna etykieta: ta sama jednostka powinna mieć tę samą etykietę we wszystkich wypowiedziach.
- Etykieta całkowicie: podaj różne wypowiedzi dla każdej intencji. Oznacz wszystkie wystąpienia jednostki we wszystkich wypowiedziach.
Jasne etykietowanie wypowiedzi
Upewnij się, że pojęcia, do których odwołują się jednostki, są dobrze zdefiniowane i możliwe do ich separowania. Sprawdź, czy możesz łatwo określić różnice niezawodnie. Jeśli nie możesz, ten brak rozróżnienia może wskazywać, że poznany składnik również będzie miał trudności.
Jeśli istnieje podobieństwo między jednostkami, upewnij się, że istnieją pewne aspekty danych, które zapewniają sygnał różnicy między nimi.
Jeśli na przykład utworzono model do zarezerwowania lotów, użytkownik może użyć wypowiedzi, takiej jak "Chcę lotu z Bostonu do Seattle". Oczekuje się, że miasto pochodzenia i miasto docelowe dla takich wypowiedzi będzie podobne. Sygnałem do odróżnienia miasta pochodzenia może być to, że słowo z często go poprzedza.
Upewnij się, że oznaczysz wszystkie wystąpienia każdej jednostki zarówno w danych szkoleniowych, jak i testowych. Jedną z metod jest użycie funkcji wyszukiwania w celu znalezienia wszystkich wystąpień wyrazu lub frazy w danych w celu sprawdzenia, czy są one poprawnie oznaczone.
Oznacz dane testowe dla jednostek, które nie mają poznanego składnika , a także dla jednostek, które to robią. Ta praktyka pomaga upewnić się, że metryki oceny są dokładne.
W przypadku projektów wielojęzycznych dodawanie wypowiedzi w innych językach zwiększa wydajność modelu w tych językach, ale unikaj duplikowania danych we wszystkich językach, które chcesz obsługiwać. Na przykład, aby poprawić wydajność bota kalendera dla użytkowników, deweloper może dodać przykłady głównie w języku angielskim i kilka w języku hiszpańskim lub francuskim, jak również. Mogą one dodawać wypowiedzi, takie jak:
- "Ustaw spotkanie z Mattem i Kevinemjutro o 12:00." (angielski)
- "Odpowiedz jako wstępna na cotygodniowe spotkanie aktualizacji "." (angielski)
- "Anuluj mi próxima reunión." (hiszpański)
Jak oznaczyć wypowiedzi
Aby oznaczyć wypowiedzi, wykonaj następujące kroki:
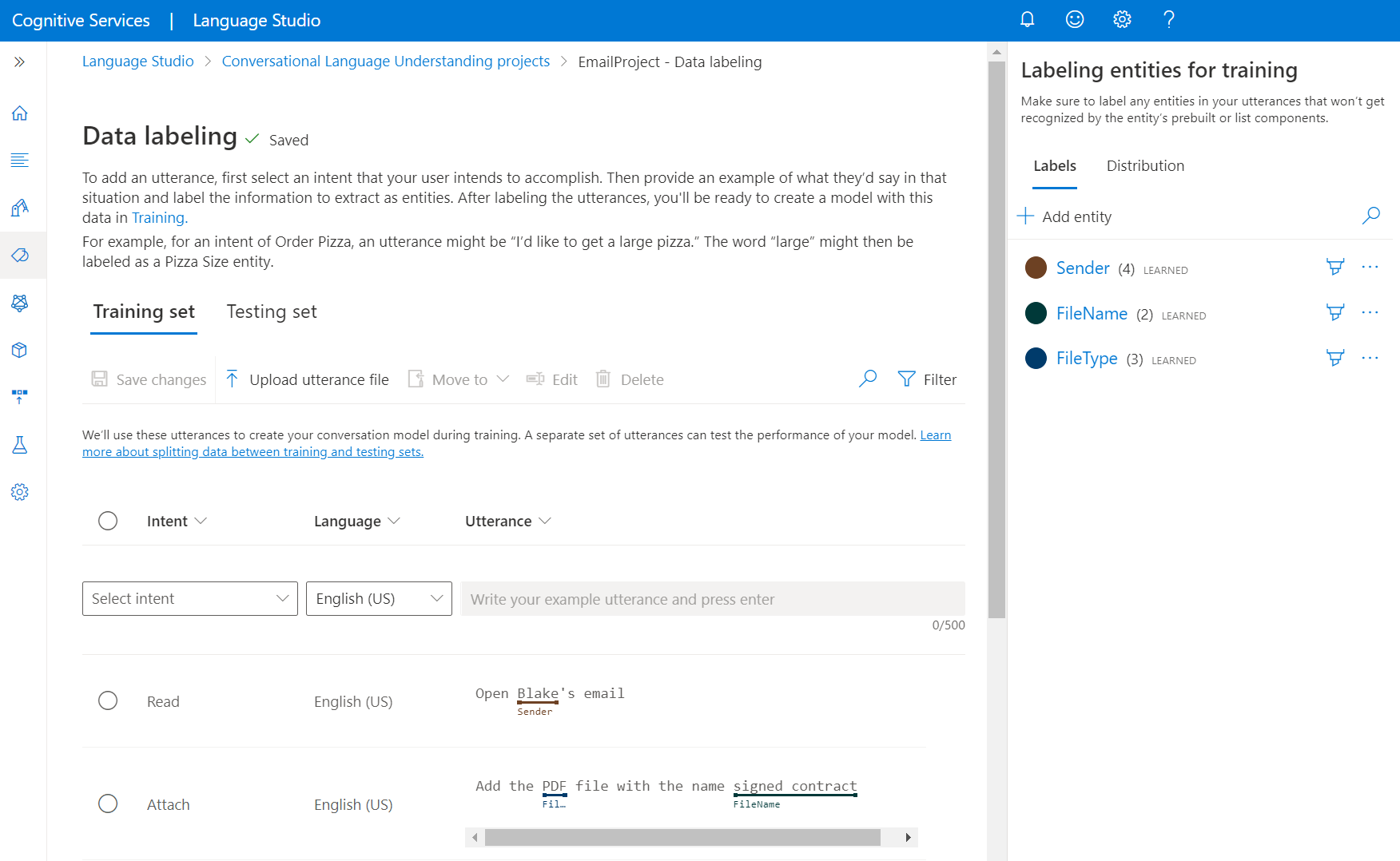
Przejdź do strony projektu w programie Language Studio.
W menu po lewej stronie wybierz pozycję Etykietowanie danych. Na tej stronie możesz zacząć dodawać wypowiedzi i oznaczać je etykietami. Możesz również przekazać swoją wypowiedź bezpośrednio, klikając pozycję Przekaż plik wypowiedzi z górnego menu, upewnij się, że jest on zgodny z akceptowanym formatem.
Z górnych elementów przestawnych można zmienić widok na zestaw trenowania lub zestaw testów. Dowiedz się więcej na temat zestawów trenowania i testowania oraz sposobu ich użycia na potrzeby trenowania i oceny modelu.
Napiwek
Jeśli planujesz użycie opcji Automatycznie podziel zestaw testów na podstawie podziału danych treningowych, dodaj wszystkie wypowiedzi do zestawu treningowego.
Z menu rozwijanego Wybierz intencję wybierz jedną z intencji, język wypowiedzi (dla projektów wielojęzycznych) i samą wypowiedź. Naciśnij Enter w polu tekstowym wypowiedzi, aby dodać wypowiedź.
Istnieją dwie opcje etykietowania jednostek w wypowiedzi:
Opcja Opis Etykieta przy użyciu pędzla Wybierz ikonę pędzla obok jednostki w okienku po prawej stronie, a następnie wyróżnij tekst w wypowiedzi, którą chcesz oznaczyć. Etykieta przy użyciu menu wbudowanego Wyróżnij wyraz, który chcesz oznaczyć jako jednostkę, a zostanie wyświetlone menu. Wybierz jednostkę, z którą chcesz oznaczyć te wyrazy. W okienku po prawej stronie w obszarze przestawnym Etykiety można znaleźć wszystkie typy jednostek w projekcie i liczbę wystąpień oznaczonych etykietami dla każdego z nich.
W obszarze przestawnym Dystrybucja można wyświetlić rozkład między zestawami trenowania i testowania. Dostępne są dwie opcje wyświetlania:
- Łączna liczba wystąpień dla jednostki oznaczonej etykietą, w której można wyświetlić liczbę wszystkich oznaczonych etykietami wystąpień określonej jednostki.
- Unikatowe wypowiedzi dla jednostki oznaczonej etykietą, w których każda wypowiedź jest liczone, jeśli zawiera co najmniej jedno wystąpienie oznaczone etykietą tej jednostki.
- Wypowiedzi na intencję , w których można wyświetlić liczbę wypowiedzi na intencję.


Uwaga
Składniki list i wstępnie utworzone nie są wyświetlane na stronie etykietowania danych, a wszystkie etykiety mają zastosowanie tylko do poznanego składnika.
Aby usunąć etykietę:
- W wypowiedzi wybierz jednostkę, z której chcesz usunąć etykietę.
- Przewiń wyświetlone menu i wybierz pozycję Usuń etykietę.
Aby usunąć jednostkę:
- Wybierz jednostkę, którą chcesz edytować w okienku po prawej stronie.
- Wybierz trzy kropki obok jednostki i wybierz odpowiednią opcję z menu rozwijanego.
Sugerowanie wypowiedzi za pomocą usługi Azure OpenAI
W usłudze CLU użyj usługi Azure OpenAI, aby zasugerować wypowiedzi do dodania do projektu przy użyciu modeli GPT. Najpierw musisz uzyskać dostęp i utworzyć zasób w usłudze Azure OpenAI. Następnie należy utworzyć wdrożenie dla modeli GPT. Wykonaj tutaj kroki wymagań wstępnych.
Przed rozpoczęciem funkcja sugerowanych wypowiedzi jest dostępna tylko wtedy, gdy zasób języka znajduje się w następujących regionach:
- Wschodnie stany USA
- South Central US
- West Europe
Na stronie Etykietowanie danych:
- Wybierz przycisk Sugeruj wypowiedzi . Po prawej stronie zostanie otwarte okienko z monitem o wybranie zasobu i wdrożenia usługi Azure OpenAI.
- Po wybraniu zasobu azure OpenAI wybierz pozycję Połącz, co umożliwia zasobowi języka bezpośredni dostęp do zasobu usługi Azure OpenAI. Przypisuje ona zasób Language rolę
Cognitive Services Userzasobu azure OpenAI, który umożliwia bieżącemu zasobowi języka dostęp do usługi Azure OpenAI. Jeśli połączenie nie powiedzie się, wykonaj poniższe kroki , aby ręcznie dodać odpowiednią rolę do zasobu usługi Azure OpenAI. - Po nawiązaniu połączenia z zasobem wybierz wdrożenie. Zalecanym modelem wdrożenia usługi Azure OpenAI jest
gpt-35-turbo-instruct. - Wybierz intencję, dla której chcesz uzyskać sugestie. Upewnij się, że wybrana intencja zawiera co najmniej 5 zapisanych wypowiedzi, które mają być włączone dla sugestii wypowiedzi. Sugestie udostępniane przez usługę Azure OpenAI są oparte na najnowszych wypowiedziach dodanych do tej intencji.
- Wybierz pozycję Generuj wypowiedzi. Po zakończeniu sugerowane wypowiedzi są wyświetlane z kropkowaną linią wokół niej z notą Wygenerowaną przez sztuczną inteligencję. Te sugestie muszą zostać zaakceptowane lub odrzucone. Zaakceptowanie sugestii powoduje po prostu dodanie jej do projektu, tak jakby zostało ono dodane samodzielnie. Odrzucenie tej propozycji powoduje całkowite usunięcie sugestii. Tylko zaakceptowane wypowiedzi są częścią projektu i są używane do trenowania lub testowania. Możesz zaakceptować lub odrzucić, klikając zielone znaczniki wyboru lub czerwone przyciski anulowania obok każdej wypowiedzi. Możesz również użyć
Accept allprzycisków iReject allna pasku narzędzi.

Użycie tej funkcji wiąże się z opłatą za zasób usługi Azure OpenAI dla podobnej liczby tokenów do wygenerowanych sugerowanych wypowiedzi. Szczegóły cennika usługi Azure OpenAI można znaleźć tutaj.
Dodawanie wymaganych konfiguracji do zasobu usługi Azure OpenAI
Jeśli łączenie zasobu language z zasobem usługi Azure OpenAI zakończy się niepowodzeniem, wykonaj następujące kroki:
Włącz zarządzanie tożsamościami dla zasobu language przy użyciu następujących opcji:
Aby umożliwić korzystanie z witryny Azure Portal, zasób języka musi mieć zarządzanie tożsamościami:
- Przejdź do zasobu Language
- W menu po lewej stronie w sekcji Zarządzanie zasobami wybierz pozycję Tożsamość
- Na karcie Przypisane przez system upewnij się, że ustawiono opcję Stan na Włączone
Po włączeniu tożsamości zarządzanej przypisz rolę Cognitive Services User do zasobu usługi Azure OpenAI przy użyciu tożsamości zarządzanej zasobu Language.
- Zaloguj się do witryny Azure Portal i przejdź do zasobu azure OpenAI.
- Wybierz kartę Kontrola dostępu (IAM) po lewej stronie.
- Wybierz pozycję Dodaj > przypisanie roli.
- Wybierz pozycję "Role funkcji zadania" i kliknij przycisk Dalej.
- Wybierz
Cognitive Services Userz listy ról i kliknij przycisk Dalej. - Wybierz pozycję Przypisz dostęp do pozycji "Tożsamość zarządzana" i wybierz pozycję "Wybierz członków".
- W obszarze "Tożsamość zarządzana" wybierz pozycję "Język".
- Wyszukaj zasób i wybierz go. Następnie wybierz przycisk Wybierz poniżej i obok, aby ukończyć proces.
- Przejrzyj szczegóły i wybierz pozycję Przejrzyj i przypisz.

Po kilku minutach odśwież program Language Studio i możesz pomyślnie nawiązać połączenie z usługą Azure OpenAI.