Model paragonu analizy dokumentów
Ta zawartość dotyczy:![]() wersja 4.0 (GA) | Poprzednie wersje:
wersja 4.0 (GA) | Poprzednie wersje: ![]() v3.1 (GA) v3.0 (GA)
v3.1 (GA) v3.0 (GA) ![]() v2.1 (GA)
v2.1 (GA) ![]()
::: moniker-end
Ta zawartość dotyczy:![]() wersja 3.1 (GA) | Najnowsza wersja: wersja 4.0 (GA) | Poprzednie wersje:
wersja 3.1 (GA) | Najnowsza wersja: wersja 4.0 (GA) | Poprzednie wersje:![]()
![]() v3.0
v3.0![]() v2.1
v2.1
Ta zawartość dotyczy: ![]() wersja 3.0 (GA) | Najnowsze wersje:
wersja 3.0 (GA) | Najnowsze wersje: ![]() v4.0 (GA)
v4.0 (GA) ![]() v3.1 | Poprzednia wersja:
v3.1 | Poprzednia wersja: ![]() wersja 2.1
wersja 2.1
Ta zawartość dotyczy: ![]() wersja 2.1 | Najnowsza wersja:
wersja 2.1 | Najnowsza wersja: ![]() wersja 4.0 (OGÓLNA)
wersja 4.0 (OGÓLNA)
Model paragonu analizy dokumentów łączy zaawansowane funkcje optycznego rozpoznawania znaków (OCR) z modelami uczenia głębokiego w celu analizowania i wyodrębniania kluczowych informacji z paragonów sprzedaży. Paragony mogą mieć różne formaty i jakość, w tym paragony drukowane i odręczne. Interfejs API wyodrębnia kluczowe informacje, takie jak nazwa sprzedawcy, numer telefonu sprzedawcy, data transakcji, podatek i suma transakcji oraz zwraca ustrukturyzowane dane JSON. Model paragonów w wersji 4.0 (GA) obsługuje również inne pola, w tym ReceiptType, TaxDetails.NetAmount, TaxDetails.DescriptionTaxDetails.Rate i CountryRegion.
Obsługiwane typy paragonów:
- Posiłek
- Materiały
- Hotel
- Paliwo i energia
- Transport
- Komunikacja
- Subskrypcje
- Rozrywka
- Szkolenia
- Opieka zdrowotna
Wyodrębnianie danych paragonu
Cyfryzacja paragonów obejmuje transformację różnych rodzajów paragonów, w tym zeskanowanych, sfotografowanych i drukowanych kopii w formacie cyfrowym w celu usprawnionego przetwarzania podrzędnego. Przykłady obejmują zarządzanie wydatkami, analizę zachowań konsumentów, automatyzację podatków itp. Korzystanie z analizy dokumentów z technologią optycznego rozpoznawania znaków (optycznego rozpoznawania znaków) umożliwia wyodrębnianie i interpretowanie danych z tych zróżnicowanych formatów paragonów. Przetwarzanie analizy dokumentów upraszcza proces konwersji, ale także znacznie skraca czas i nakład pracy, co ułatwia efektywne zarządzanie danymi i pobieranie.
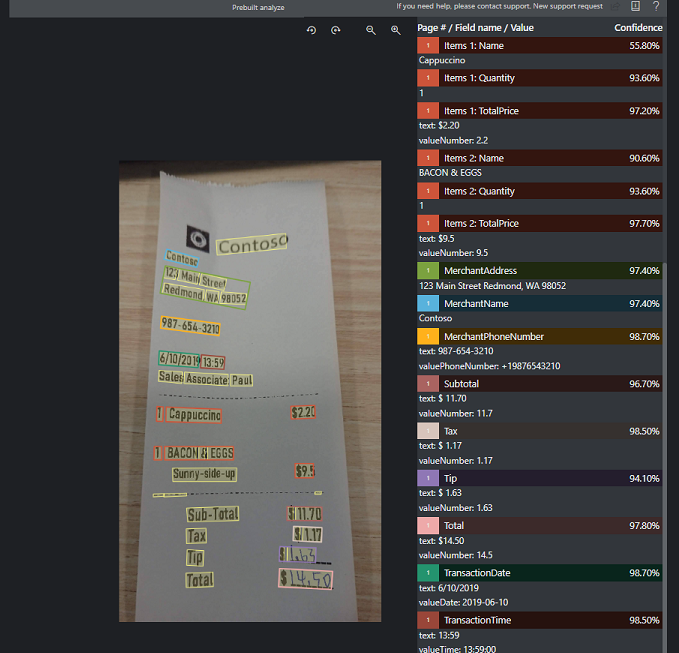
Przykładowe potwierdzenie przetworzone za pomocą programu Document Intelligence Studio:

Przykładowe potwierdzenie przetworzone za pomocą narzędzia do etykietowania przykładowego analizy dokumentów:
Opcje programowania
Analiza dokumentów w wersji 4.0: 2024-11-30 (GA) obsługuje następujące narzędzia, aplikacje i biblioteki:
| Funkcja | Zasoby | Model ID |
|---|---|---|
| Model paragonu | • Document Intelligence Studio • REST API • C# SDK • Python SDK• Java SDK • JavaScript SDK |
wstępnie utworzone potwierdzenie |
Narzędzie Document Intelligence w wersji 3.1 obsługuje następujące narzędzia, aplikacje i biblioteki:
| Funkcja | Zasoby | Model ID |
|---|---|---|
| Model paragonu | • Document Intelligence Studio • REST API • C# SDK • Python SDK• Java SDK • JavaScript SDK |
wstępnie utworzone potwierdzenie |
Narzędzie Document Intelligence w wersji 3.0 obsługuje następujące narzędzia, aplikacje i biblioteki:
| Funkcja | Zasoby | Model ID |
|---|---|---|
| Model paragonu | • Document Intelligence Studio • REST API • C# SDK • Python SDK• Java SDK • JavaScript SDK |
wstępnie utworzone potwierdzenie |
Narzędzie Document Intelligence w wersji 2.1 obsługuje następujące narzędzia, aplikacje i biblioteki:
| Funkcja | Zasoby |
|---|---|
| Model paragonu | • Narzędzie do etykietowania analizy dokumentów• Interfejs API REST• Zestaw SDK biblioteki klienckiej• Kontener docker analizy dokumentów |
Wymagania dotyczące danych wejściowych
Obsługiwane formaty plików:
Model PDF Obraz: JPEG/JPG, ,BMPPNG, ,TIFFHEIFMicrosoft Office:
Word (), Excel (XLSXDOCX), PowerPoint (PPTX), HTMLPrzeczytaj ✔ ✔ ✔ Układ ✔ ✔ ✔ Dokument ogólny ✔ ✔ Wstępnie utworzona ✔ ✔ Niestandardowe wyodrębnianie ✔ ✔ Klasyfikacja niestandardowa ✔ ✔ ✔ Aby uzyskać najlepsze wyniki, podaj jedno jasne zdjęcie lub wysokiej jakości skanowanie na dokument.
W przypadku plików PDF i TIFF można przetworzyć maksymalnie 2000 stron (w przypadku subskrypcji warstwy Bezpłatna przetwarzane są tylko pierwsze dwie strony).
Rozmiar pliku do analizowania dokumentów wynosi 500 MB dla warstwy płatnej (S0) i
4MB za bezpłatną (F0).Wymiary obrazu muszą mieć od 50 pikseli x 50 pikseli do 10 000 pikseli x 10 000 pikseli.
Jeśli pliki PDF są zablokowane hasłem, przed ich przesłaniem usuń blokadę.
Minimalna wysokość tekstu do wyodrębnienia to 12 pikseli dla obrazu o rozmiarze 1024 x 768 pikseli. Ten wymiar odpowiada tekstowi
8punktowemu na 150 kropek na cal (DPI).W przypadku trenowania modelu niestandardowego maksymalna liczba stron dla danych szkoleniowych wynosi 500 dla niestandardowego modelu szablonu i 50 000 dla niestandardowego modelu neuronowego.
W przypadku trenowania niestandardowego modelu wyodrębniania łączny rozmiar danych treningowych wynosi 50 MB dla modelu szablonu i
1GB dla modelu neuronowego.W przypadku trenowania niestandardowego modelu klasyfikacji całkowity rozmiar danych treningowych wynosi
1GB z maksymalnie 10 000 stron. W przypadku wersji 2024-11-30 (GA) całkowity rozmiar danych treningowych wynosi2GB z maksymalnie 10 000 stron.
- Obsługiwane formaty plików: JPEG, PNG, PDF i TIFF.
- Obsługiwany limit stron dla plików PDF i TIFF: Analiza dokumentów może przetwarzać maksymalnie 2000 stron dla subskrybentów warstwy Standardowa lub tylko dwie pierwsze strony dla subskrybentów warstwy bezpłatnie.
- Obsługiwany rozmiar pliku: mniejszy niż 50 MB; minimalna liczba pikseli 50 x 50 pikseli; maksymalna liczba pikseli: 10 000 x 10 000 pikseli.
Wyodrębnianie danych modelu paragonu
Zobacz, w jaki sposób analiza dokumentów wyodrębnia dane, w tym godzinę i datę transakcji, informacje o kupcu i sumy kwot od wpływów. Potrzebne są następujące zasoby:
Subskrypcja platformy Azure — możesz utworzyć jedną bezpłatnie.
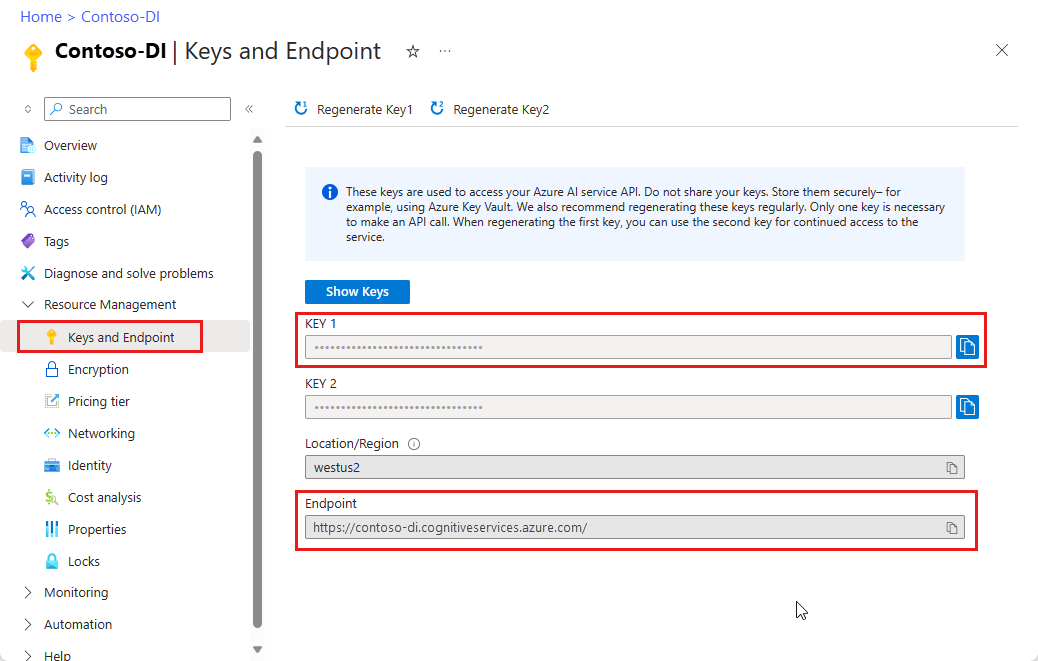
Wystąpienie analizy dokumentów w witrynie Azure Portal. Aby wypróbować usługę, możesz użyć bezpłatnej warstwy cenowej (
F0). Po wdrożeniu zasobu wybierz pozycję Przejdź do zasobu , aby uzyskać klucz i punkt końcowy.
Uwaga
Program Document Intelligence Studio jest dostępny z interfejsami API w wersji 3.1 i 3.0 oraz nowszymi wersjami.

Narzędzie do etykietowania przykładowego analizy dokumentów
Przejdź do narzędzia przykładowego analizy dokumentów.
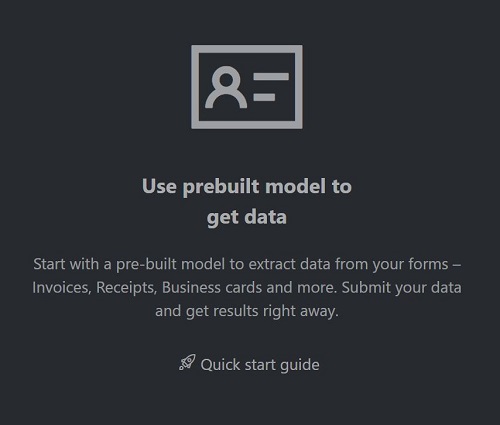
Na stronie głównej przykładowego narzędzia wybierz kafelek Użyj wstępnie utworzonego modelu, aby pobrać dane .
Wybierz typ formularza do przeanalizowania z menu rozwijanego.
Wybierz adres URL pliku, który chcesz przeanalizować z poniższych opcji:
Przykładowy dokument faktury.
Przykładowy obraz potwierdzenia.
Przykładowy obraz wizytówki.
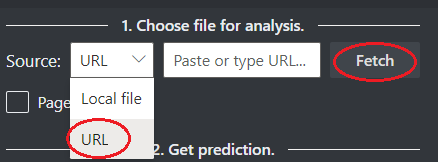
W polu Źródło wybierz pozycję Adres URL z menu rozwijanego, wklej wybrany adres URL i wybierz przycisk Pobierz.
W polu Punkt końcowy usługi Analizy dokumentów wklej punkt końcowy uzyskany w ramach subskrypcji analizy dokumentów.
W polu klucza wklej klucz uzyskany z zasobu analizy dokumentów.

Wybierz pozycję Uruchom analizę. Narzędzie do etykietowania przykładowego analizy dokumentów wywołuje interfejs API analizy wstępnie utworzonej i analizuje dokument.
Wyświetl wyniki — zobacz wyodrębnione pary klucz-wartość, elementy wiersza, wyróżniony tekst wyodrębniony i wykryte tabele.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Uwaga
Przykładowe narzędzie etykietowania nie obsługuje formatu pliku BMP. Jest to ograniczenie narzędzia, a nie usługi analizy dokumentów.
Obsługiwane języki i ustawienia regionalne
Aby uzyskać pełną listę obsługiwanych języków, zobacz naszą wstępnie utworzoną stronę obsługi języka modeli.
Wyodrębnianie pól
W przypadku obsługiwanych pól wyodrębniania dokumentów zapoznaj się ze stroną schematu modelu paragonów w naszym repozytorium przykładowym GitHub
| Nazwisko | Pisz | Opis | Standardowe dane wyjściowe |
|---|---|---|---|
| Typ paragonu | String | Typ paragonu sprzedaży | Wyszczególnione |
| Nazwa handlowca | String | Imię i nazwisko sprzedawcy wystawiającego paragon | |
| Numer MerchantPhone | phoneNumber | Wymieniony numer telefonu sprzedawcy | +1 xxx xxx xxxx |
| Adres handlowca | String | Wymieniony adres sprzedawcy | |
| Data transakcji | Data | Data wystawienia paragonu | rrrr-mm-dd |
| Czas transakcji | Czas | Czas wystawienia paragonu | hh-mm-ss (24-godzinne) |
| Łącznie | Liczba (USD) | Całkowita liczba transakcji odbioru | Liczba zmiennoprzecinkowa dwuprzecinkowa |
| Suma częściowa | Liczba (USD) | Suma częściowa paragonu, często przed zastosowaniem podatków | Liczba zmiennoprzecinkowa dwuprzecinkowa |
| Podatek | Liczba (USD) | Całkowity podatek od paragonu (często podatek od sprzedaży lub odpowiednik). Zmieniono nazwę na "TotalTax" w wersji 2022-06-30. | Liczba zmiennoprzecinkowa dwuprzecinkowa |
| Napiwek | Liczba (USD) | Porada dołączona przez kupującego | Liczba zmiennoprzecinkowa dwuprzecinkowa |
| Elementy | Tablica obiektów | Wyodrębnione elementy wiersza z nazwą, ilością, ceną jednostkową i łączną ceną wyodrębnionej | |
| Nazwisko | String | Opis elementu. Zmieniono nazwę na "Opis" w wersji 2022-06-30. | |
| Ilość | Liczba | Ilość każdego elementu | Liczba zmiennoprzecinkowa dwuprzecinkowa |
| Cena | Liczba | Pojedyncza cena każdej jednostki przedmiotów | Liczba zmiennoprzecinkowa dwuprzecinkowa |
| Cena_łączna | Liczba | Łączna cena elementu wiersza | Liczba zmiennoprzecinkowa dwuprzecinkowa |
Przewodnik migracji i interfejs API REST w wersji 3.1
- Postępuj zgodnie z naszym przewodnikiem migracji do analizy dokumentów w wersji 3.1, aby dowiedzieć się, jak używać wersji 3.1 w aplikacjach i przepływach pracy.
Następne kroki
Spróbuj przetwarzać własne formularze i dokumenty za pomocą programu Document Intelligence Studio.
Ukończ przewodnik Szybki start dotyczący analizy dokumentów i rozpocznij tworzenie aplikacji do przetwarzania dokumentów w wybranym języku programowania.
Spróbuj przetwarzać własne formularze i dokumenty za pomocą narzędzia do etykietowania przykładowego analizy dokumentów.
Ukończ przewodnik Szybki start dotyczący analizy dokumentów i rozpocznij tworzenie aplikacji do przetwarzania dokumentów w wybranym języku programowania.