Model odczytu analizy dokumentów
Ważne
- Publiczne wersje zapoznawcze analizy dokumentów zapewniają wczesny dostęp do funkcji, które są aktywnie opracowywane. Funkcje, podejścia i procesy mogą ulec zmianie przed ogólną dostępnością na podstawie opinii użytkowników.
- Publiczna wersja zapoznawcza bibliotek klienckich analizy dokumentów jest domyślna dla interfejsu API REST w wersji 2024-07-31-preview.
- Publiczna wersja zapoznawcza 2024-07-31-preview jest obecnie dostępna tylko w następujących regionach świadczenia usługi Azure. Należy pamiętać, że niestandardowy model generowania (wyodrębniania pól dokumentów) w programie AI Studio jest dostępny tylko w regionie Północno-środkowe stany USA:
- Wschodnie stany USA
- Zachodnie stany USA 2
- Europa Zachodnia
- Północno-środkowe stany USA
Ta zawartość dotyczy:![]() wersja 4.0 (wersja zapoznawcza) | Poprzednie wersje:
wersja 4.0 (wersja zapoznawcza) | Poprzednie wersje: ![]() v3.1 (GA) v3.0 (GA)
v3.1 (GA) v3.0 (GA) ![]()
Ta zawartość dotyczy:![]() wersja 4.0 (wersja zapoznawcza) | Poprzednie wersje:
wersja 4.0 (wersja zapoznawcza) | Poprzednie wersje: ![]() v3.1 (GA) v3.0 (GA)
v3.1 (GA) v3.0 (GA) ![]()
Uwaga
W przypadku wyodrębniania tekstu z obrazów zewnętrznych, takich jak etykiety, znaki uliczne i plakaty, użyj funkcji odczytu obrazów usługi Azure AI w wersji 4.0 zoptymalizowanej pod kątem ogólnych obrazów innych niż dokument z ulepszonym synchronicznym interfejsem API, który ułatwia osadzanie OCR w scenariuszach środowiska użytkownika.
Model optycznego rozpoznawania znaków odczytu analizy dokumentów (OCR) działa w wyższej rozdzielczości niż odczyt usługi Azure AI Vision i wyodrębnia tekst drukowany i odręczny z dokumentów PDF i zeskanowanych obrazów. Obejmuje również obsługę wyodrębniania tekstu z dokumentów Microsoft Word, Excel, PowerPoint i HTML. Wykrywa akapity, wiersze tekstu, wyrazy, lokalizacje i języki. Model odczytu jest podstawowym aparatem OCR dla innych wstępnie utworzonych modeli analizy dokumentów, takich jak Układ, Dokument ogólny, Faktura, Paragon, Dokument tożsamości (ID), Karta ubezpieczenia zdrowotnego, W2 oprócz modeli niestandardowych.
Co to jest optyczne rozpoznawanie znaków?
Optyczne rozpoznawanie znaków (OCR) dla dokumentów jest zoptymalizowane pod kątem dużych dokumentów tekstowych w wielu formatach plików i językach globalnych. Obejmuje ona funkcje, takie jak skanowanie obrazów dokumentów o wyższej rozdzielczości w celu lepszego obsługi mniejszego i gęstego tekstu; wykrywanie akapitu; oraz zarządzanie formularzami, które można wypełnić. Funkcje OCR obejmują również zaawansowane scenariusze, takie jak pola pojedynczego znaku i dokładne wyodrębnianie kluczowych pól często występujących na fakturach, paragonach i innych wstępnie utworzonych scenariuszach.
Opcje programowania (wersja 4)
Analiza dokumentów w wersji 4.0 (2024-07-31-preview) obsługuje następujące narzędzia, aplikacje i biblioteki:
| Funkcja | Zasoby | Model ID |
|---|---|---|
| Odczytywanie modelu OCR | • Document Intelligence Studio • REST API • C# SDK • Python SDK• Java SDK • JavaScript SDK |
odczyt wstępnie utworzony |
Wymagania dotyczące danych wejściowych (wersja 4)
Obsługiwane formaty plików:
Model PDF Obraz: JPEG/JPG, ,BMPPNG, ,TIFFHEIFMicrosoft Office:
Word (), Excel (XLSXDOCX), PowerPoint (PPTX), HTMLPrzeczytaj ✔ ✔ ✔ Układ ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview, 2023-10-31-preview) Dokument ogólny ✔ ✔ Wstępnie utworzona ✔ ✔ Niestandardowe wyodrębnianie ✔ ✔ Klasyfikacja niestandardowa ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview) Aby uzyskać najlepsze wyniki, podaj jedno jasne zdjęcie lub wysokiej jakości skanowanie na dokument.
W przypadku plików PDF i TIFF można przetworzyć maksymalnie 2000 stron (w przypadku subskrypcji warstwy Bezpłatna przetwarzane są tylko pierwsze dwie strony).
Rozmiar pliku do analizowania dokumentów wynosi 500 MB dla warstwy płatnej (S0) i
4MB za bezpłatną (F0).Wymiary obrazu muszą mieć od 50 pikseli x 50 pikseli do 10 000 pikseli x 10 000 pikseli.
Jeśli pliki PDF są zablokowane hasłem, przed ich przesłaniem usuń blokadę.
Minimalna wysokość tekstu do wyodrębnienia to 12 pikseli dla obrazu o rozmiarze 1024 x 768 pikseli. Ten wymiar odpowiada tekstowi
8punktowemu na 150 kropek na cal (DPI).W przypadku trenowania modelu niestandardowego maksymalna liczba stron dla danych szkoleniowych wynosi 500 dla niestandardowego modelu szablonu i 50 000 dla niestandardowego modelu neuronowego.
W przypadku trenowania niestandardowego modelu wyodrębniania łączny rozmiar danych treningowych wynosi 50 MB dla modelu szablonu i
1GB dla modelu neuronowego.W przypadku trenowania niestandardowego modelu klasyfikacji całkowity rozmiar danych treningowych wynosi
1GB z maksymalnie 10 000 stron. W przypadku wersji 2024-07-31-preview i nowszych łączny rozmiar danych treningowych wynosi2GB z maksymalnie 10 000 stron.
Wprowadzenie do modelu odczytu (wersja 4)
Spróbuj wyodrębnić tekst z formularzy i dokumentów przy użyciu programu Document Intelligence Studio. Potrzebne są następujące zasoby:
Subskrypcja platformy Azure — możesz utworzyć jedną bezpłatnie.
Wystąpienie analizy dokumentów w witrynie Azure Portal. Aby wypróbować usługę, możesz użyć bezpłatnej warstwy cenowej (
F0). Po wdrożeniu zasobu wybierz pozycję Przejdź do zasobu , aby uzyskać klucz i punkt końcowy.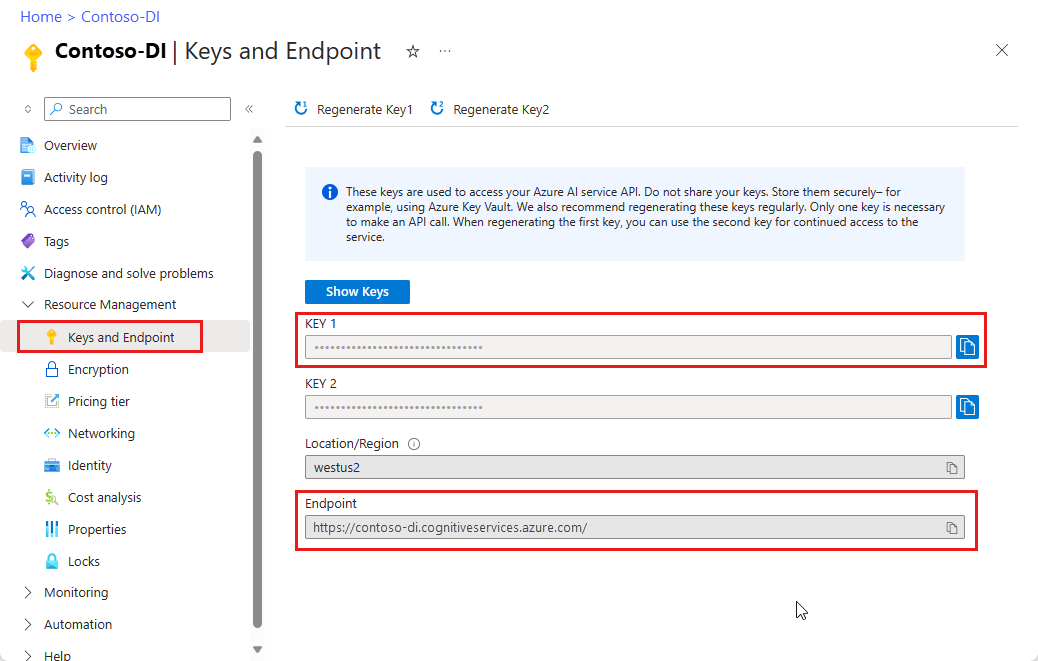
Uwaga
Obecnie program Document Intelligence Studio nie obsługuje formatów plików Microsoft Word, Excel, PowerPoint i HTML.
Przykładowy dokument przetwarzany za pomocą programu Document Intelligence Studio
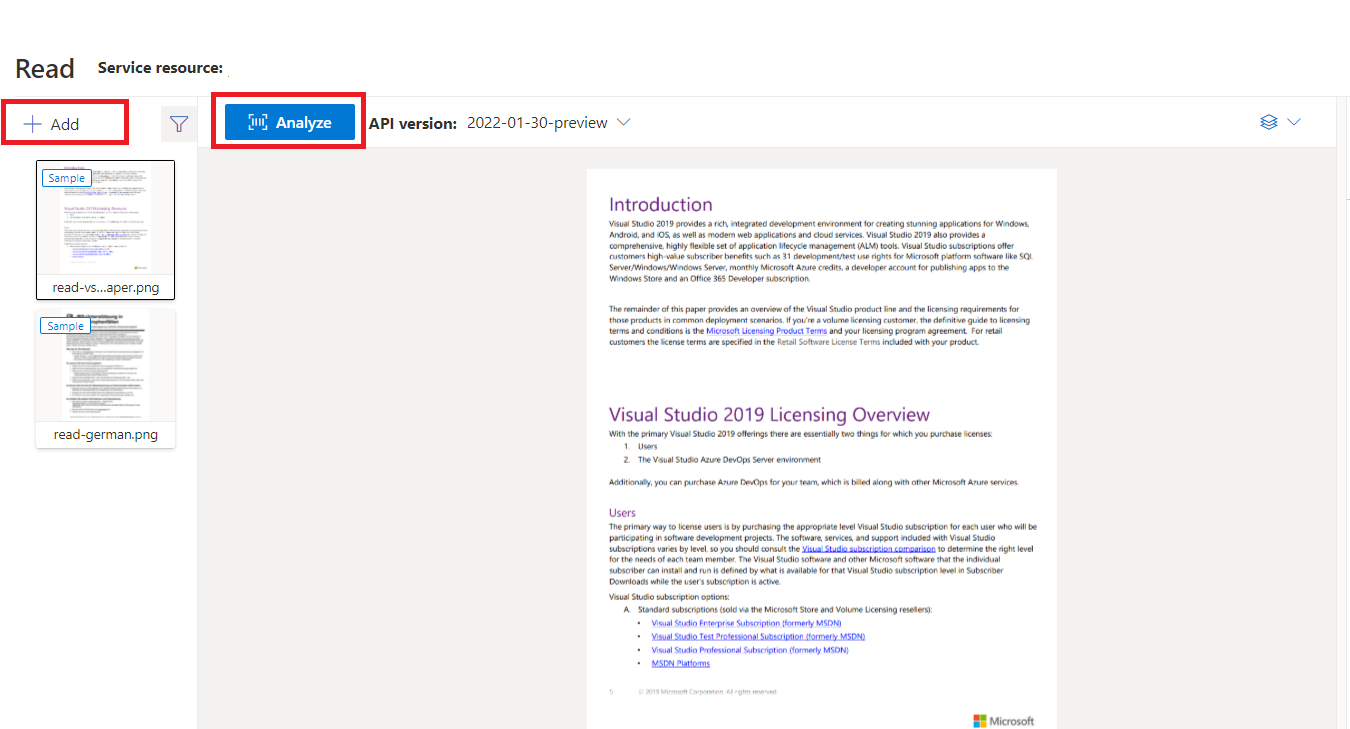
Na stronie głównej Programu Document Intelligence Studio wybierz pozycję Odczyt.
Możesz przeanalizować przykładowy dokument lub przekazać własne pliki.
Wybierz przycisk Run analysis (Uruchom analizę), a w razie potrzeby skonfiguruj opcje Analizuj:

Obsługiwane języki i ustawienia regionalne (wersja 4)
Zobacz naszą stronę Obsługa języka — modele analizy dokumentów, aby uzyskać pełną listę obsługiwanych języków.
Wyodrębnianie danych (wersja 4)
Uwaga
Program Microsoft Word i plik HTML są obsługiwane w wersji 4.0. W porównaniu z plikami PDF i obrazami poniższe funkcje nie są obsługiwane:
- Nie ma żadnego kąta, szerokości/wysokości i jednostki dla każdego obiektu strony.
- Dla każdego wykrytego obiektu nie ma ograniczenia wielokąta ani regionu ograniczenia.
- Zakres stron (
pages) nie jest obsługiwany jako parametr. - Brak
linesobiektu.
Pliki PDF z możliwością wyszukiwania
Możliwość przeszukiwania plików PDF umożliwia konwertowanie analogowych plików PDF, takich jak pliki PDF zeskanowanych obrazów, do formatu PDF z osadzonym tekstem. Osadzony tekst umożliwia wyszukiwanie tekstu głębokiego w wyodrębnionej zawartości pliku PDF przez zastąpienie wykrytych jednostek tekstowych na podstawie plików obrazów.
Ważne
- Obecnie możliwość przeszukiwania plików PDF jest obsługiwana tylko przez model
prebuilt-readOCR odczytu. W przypadku korzystania z tej funkcji określmodelIdparametr jakoprebuilt-read, ponieważ inne typy modeli będą zwracać błąd dla tej wersji zapoznawczej. - Plik PDF z możliwością wyszukiwania jest dołączony do modelu 2024-07-31-preview
prebuilt-readbez dodatkowych kosztów generowania danych wyjściowych pdf z możliwością wyszukiwania.
Korzystanie z plików PDF z możliwością wyszukiwania
Aby użyć pliku PDF z możliwością wyszukiwania, utwórz POST żądanie przy użyciu Analyze operacji i określ format danych wyjściowych jako pdf:
POST /documentModels/prebuilt-read:analyze?output=pdf
{...}
202
Sonduj pod kątem ukończenia Analyze operacji. Po zakończeniu operacji wydaj GET żądanie pobrania formatu Analyze PDF wyników operacji.
Po pomyślnym zakończeniu plik PDF można pobrać i pobrać jako application/pdf. Ta operacja umożliwia bezpośrednie pobieranie osadzonej formy tekstu PDF zamiast kodu JSON zakodowanego w formacie Base64.
// Monitor the operation until completion.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}
200
{...}
// Upon successful completion, retrieve the PDF as application/pdf.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}/pdf
200 OK
Content-Type: application/pdf
Parametr pages
Kolekcja stron jest listą stron w dokumencie. Każda strona jest reprezentowana sekwencyjnie w dokumencie i zawiera kąt orientacji wskazujący, czy strona jest obracana, oraz szerokość i wysokość (wymiary w pikselach). Jednostki strony w danych wyjściowych modelu są obliczane, jak pokazano poniżej:
| Format pliku | Obliczona jednostka strony | Łączna liczba stron |
|---|---|---|
| Obrazy (JPEG/JPG, PNG, BMP, HEIF) | Każdy obraz = 1 jednostka strony | Łączna liczba obrazów |
| Każda strona w pliku PDF = 1 jednostka strony | Łączna liczba stron w pliku PDF | |
| TIFF | Każdy obraz w jednostce strony TIFF = 1 | Łączna liczba obrazów w tiff |
| Word (DOCX) | Maksymalnie 3000 znaków = 1 jednostka strony, osadzone lub połączone obrazy nie są obsługiwane | Łączna liczba stron z maksymalnie 3000 znakami |
| Excel (XLSX) | Każdy arkusz = 1 jednostka strony, osadzone lub połączone obrazy nie są obsługiwane | Łączna liczba arkuszy |
| PowerPoint (PPTX) | Każdy slajd = 1 jednostka strony, osadzone lub połączone obrazy nie są obsługiwane | Łączna liczba slajdów |
| HTML | Maksymalnie 3000 znaków = 1 jednostka strony, osadzone lub połączone obrazy nie są obsługiwane | Łączna liczba stron z maksymalnie 3000 znakami |
# Analyze pages.
for page in result.pages:
print(f"----Analyzing document from page #{page.page_number}----")
print(f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}")
Wyodrębnianie tekstu przy użyciu stron
W przypadku dużych wielostronicowych dokumentów PDF użyj parametru pages zapytania, aby wskazać konkretne numery stron lub zakresy stron na potrzeby wyodrębniania tekstu.
Wyodrębnianie akapitów
Model odczytu OCR w usłudze Document Intelligence wyodrębnia wszystkie zidentyfikowane bloki tekstu w paragraphs kolekcji jako obiekt najwyższego poziomu w obszarze analyzeResults. Każdy wpis w tej kolekcji reprezentuje blok tekstu i zawiera wyodrębniony tekst jakocontent i współrzędne ograniczenia polygon . Informacje span wskazują fragment tekstu we właściwości najwyższego poziomu content zawierającej pełny tekst z dokumentu.
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
Wyodrębnianie tekstu, wierszy i wyrazów
Model odczytu OCR wyodrębnia tekst w stylu drukowania i odręcznego jako lines i words. Model generuje współrzędne ograniczenia i polygon confidence dla wyodrębnionych wyrazów. Kolekcja styles zawiera dowolny styl odręczny wierszy, jeśli zostanie wykryty wraz z zakresami wskazującymi skojarzony tekst. Ta funkcja ma zastosowanie do obsługiwanych języków odręcznych.
W przypadku programów Microsoft Word, Excel, PowerPoint i HTML model odczytu analizy dokumentów w wersji 3.1 lub nowszej wyodrębnia cały osadzony tekst w następujący sposób. Teksty są ekstradowane jako słowa i akapity. Obrazy osadzone nie są obsługiwane.
# Analyze lines.
if page.lines:
for line_idx, line in enumerate(page.lines):
words = get_words(page, line)
print(
f"...Line # {line_idx} has {len(words)} words and text '{line.content}' within bounding polygon '{line.polygon}'"
)
# Analyze words.
for word in words:
print(f"......Word '{word.content}' has a confidence of {word.confidence}")
Wyodrębnianie stylu odręcznego
Odpowiedź zawiera klasyfikację, czy każdy wiersz tekstu ma styl pisma ręcznego, czy nie, wraz z współczynnikiem ufności. Aby uzyskać więcej informacji, zobacz obsługa języka odręcznego. Poniższy przykład przedstawia przykładowy fragment kodu JSON.
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
Jeśli włączono funkcję dodatku czcionki/stylu, otrzymasz również wynik czcionki/stylu jako część styles obiektu.
Następne kroki w wersji 4.0
Ukończ przewodnik Szybki start dotyczący analizy dokumentów:
Zapoznaj się z naszym interfejsem API REST:
Znajdź więcej przykładów w witrynie GitHub:
Ta zawartość dotyczy: ![]() wersja 3.1 (GA)Najnowsza wersja:
wersja 3.1 (GA)Najnowsza wersja: ![]() v4.0 (wersja zapoznawcza) | | Poprzednie wersje:
v4.0 (wersja zapoznawcza) | | Poprzednie wersje: ![]() v3.0
v3.0
Ta zawartość dotyczy:![]() wersja 3.0 (GA) | Najnowsze wersje:
wersja 3.0 (GA) | Najnowsze wersje: ![]() wersja 4.0 (wersja zapoznawcza)
wersja 4.0 (wersja zapoznawcza)![]() 3.1
3.1
Uwaga
W przypadku wyodrębniania tekstu z obrazów zewnętrznych, takich jak etykiety, znaki uliczne i plakaty, użyj funkcji odczytu obrazów usługi Azure AI w wersji 4.0 zoptymalizowanej pod kątem ogólnych obrazów innych niż dokument z ulepszonym synchronicznym interfejsem API, który ułatwia osadzanie OCR w scenariuszach środowiska użytkownika.
Model optycznego rozpoznawania znaków odczytu analizy dokumentów (OCR) działa w wyższej rozdzielczości niż odczyt usługi Azure AI Vision i wyodrębnia tekst drukowany i odręczny z dokumentów PDF i zeskanowanych obrazów. Obejmuje również obsługę wyodrębniania tekstu z dokumentów Microsoft Word, Excel, PowerPoint i HTML. Wykrywa akapity, wiersze tekstu, wyrazy, lokalizacje i języki. Model odczytu jest podstawowym aparatem OCR dla innych wstępnie utworzonych modeli analizy dokumentów, takich jak Układ, Dokument ogólny, Faktura, Paragon, Dokument tożsamości (ID), Karta ubezpieczenia zdrowotnego, W2 oprócz modeli niestandardowych.
Co to jest OCR dla dokumentów?
Optyczne rozpoznawanie znaków (OCR) dla dokumentów jest zoptymalizowane pod kątem dużych dokumentów tekstowych w wielu formatach plików i językach globalnych. Obejmuje ona funkcje, takie jak skanowanie obrazów dokumentów o wyższej rozdzielczości w celu lepszego obsługi mniejszego i gęstego tekstu; wykrywanie akapitu; oraz zarządzanie formularzami, które można wypełnić. Funkcje OCR obejmują również zaawansowane scenariusze, takie jak pola pojedynczego znaku i dokładne wyodrębnianie kluczowych pól często występujących na fakturach, paragonach i innych wstępnie utworzonych scenariuszach.
Opcje programowania
Narzędzie Document Intelligence w wersji 3.1 obsługuje następujące narzędzia, aplikacje i biblioteki:
| Funkcja | Zasoby | Model ID |
|---|---|---|
| Odczytywanie modelu OCR | • Document Intelligence Studio • REST API • C# SDK • Python SDK• Java SDK • JavaScript SDK |
odczyt wstępnie utworzony |
Narzędzie Document Intelligence w wersji 3.0 obsługuje następujące narzędzia, aplikacje i biblioteki:
| Funkcja | Zasoby | Model ID |
|---|---|---|
| Odczytywanie modelu OCR | • Document Intelligence Studio • REST API • C# SDK • Python SDK• Java SDK • JavaScript SDK |
odczyt wstępnie utworzony |
Wymagania dotyczące danych wejściowych
Obsługiwane formaty plików:
Model PDF Obraz: JPEG/JPG, ,BMPPNG, ,TIFFHEIFMicrosoft Office:
Word (), Excel (XLSXDOCX), PowerPoint (PPTX), HTMLPrzeczytaj ✔ ✔ ✔ Układ ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview, 2023-10-31-preview) Dokument ogólny ✔ ✔ Wstępnie utworzona ✔ ✔ Niestandardowe wyodrębnianie ✔ ✔ Klasyfikacja niestandardowa ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview) Aby uzyskać najlepsze wyniki, podaj jedno jasne zdjęcie lub wysokiej jakości skanowanie na dokument.
W przypadku plików PDF i TIFF można przetworzyć maksymalnie 2000 stron (w przypadku subskrypcji warstwy Bezpłatna przetwarzane są tylko pierwsze dwie strony).
Rozmiar pliku do analizowania dokumentów wynosi 500 MB dla warstwy płatnej (S0) i
4MB za bezpłatną (F0).Wymiary obrazu muszą mieć od 50 pikseli x 50 pikseli do 10 000 pikseli x 10 000 pikseli.
Jeśli pliki PDF są zablokowane hasłem, przed ich przesłaniem usuń blokadę.
Minimalna wysokość tekstu do wyodrębnienia to 12 pikseli dla obrazu o rozmiarze 1024 x 768 pikseli. Ten wymiar odpowiada tekstowi
8punktowemu na 150 kropek na cal (DPI).W przypadku trenowania modelu niestandardowego maksymalna liczba stron dla danych szkoleniowych wynosi 500 dla niestandardowego modelu szablonu i 50 000 dla niestandardowego modelu neuronowego.
W przypadku trenowania niestandardowego modelu wyodrębniania łączny rozmiar danych treningowych wynosi 50 MB dla modelu szablonu i
1GB dla modelu neuronowego.W przypadku trenowania niestandardowego modelu klasyfikacji całkowity rozmiar danych treningowych wynosi
1GB z maksymalnie 10 000 stron. W przypadku wersji 2024-07-31-preview i nowszych łączny rozmiar danych treningowych wynosi2GB z maksymalnie 10 000 stron.
Wprowadzenie do modelu odczytu
Spróbuj wyodrębnić tekst z formularzy i dokumentów przy użyciu programu Document Intelligence Studio. Potrzebne są następujące zasoby:
Subskrypcja platformy Azure — możesz utworzyć jedną bezpłatnie.
Wystąpienie analizy dokumentów w witrynie Azure Portal. Aby wypróbować usługę, możesz użyć bezpłatnej warstwy cenowej (
F0). Po wdrożeniu zasobu wybierz pozycję Przejdź do zasobu , aby uzyskać klucz i punkt końcowy.
Uwaga
Obecnie program Document Intelligence Studio nie obsługuje formatów plików Microsoft Word, Excel, PowerPoint i HTML.
Przykładowy dokument przetwarzany za pomocą programu Document Intelligence Studio
Na stronie głównej Programu Document Intelligence Studio wybierz pozycję Odczyt.
Możesz przeanalizować przykładowy dokument lub przekazać własne pliki.
Wybierz przycisk Run analysis (Uruchom analizę), a w razie potrzeby skonfiguruj opcje Analizuj:
Obsługiwane języki i ustawienia regionalne
Zobacz naszą stronę Obsługa języka — modele analizy dokumentów, aby uzyskać pełną listę obsługiwanych języków.
Wyodrębnianie danych
Uwaga
Program Microsoft Word i plik HTML są obsługiwane w wersjach 3.1 i nowszych. W porównaniu z plikami PDF i obrazami poniższe funkcje nie są obsługiwane:
- Nie ma żadnego kąta, szerokości/wysokości i jednostki dla każdego obiektu strony.
- Dla każdego wykrytego obiektu nie ma ograniczenia wielokąta ani regionu ograniczenia.
- Zakres stron (
pages) nie jest obsługiwany jako parametr. - Brak
linesobiektu.
Plik PDF z możliwością wyszukiwania
Możliwość przeszukiwania plików PDF umożliwia konwertowanie analogowych plików PDF, takich jak pliki PDF zeskanowanych obrazów, do formatu PDF z osadzonym tekstem. Osadzony tekst umożliwia wyszukiwanie tekstu głębokiego w wyodrębnionej zawartości pliku PDF przez zastąpienie wykrytych jednostek tekstowych na podstawie plików obrazów.
Ważne
- Obecnie możliwość przeszukiwania plików PDF jest obsługiwana tylko przez model
prebuilt-readOCR odczytu. W przypadku korzystania z tej funkcji określmodelIdparametr jakoprebuilt-read, ponieważ inne typy modeli będą zwracać błąd dla tej wersji zapoznawczej. - Plik PDF z możliwością wyszukiwania jest dołączony do modelu 2024-07-31-preview
prebuilt-readbez dodatkowych kosztów generowania danych wyjściowych pdf z możliwością wyszukiwania.- Plik PDF z możliwością wyszukiwania obecnie obsługuje tylko pliki PDF jako dane wejściowe. Obsługa innych typów plików, takich jak pliki obrazów, będzie dostępna później.
Korzystanie z pliku PDF z możliwością wyszukiwania
Aby użyć pliku PDF z możliwością wyszukiwania, utwórz POST żądanie przy użyciu Analyze operacji i określ format danych wyjściowych jako pdf:
POST /documentModels/prebuilt-read:analyze?output=pdf
{...}
202
Sonduj pod kątem ukończenia Analyze operacji. Po zakończeniu operacji wydaj GET żądanie pobrania formatu Analyze PDF wyników operacji.
Po pomyślnym zakończeniu plik PDF można pobrać i pobrać jako application/pdf. Ta operacja umożliwia bezpośrednie pobieranie osadzonej formy tekstu PDF zamiast kodu JSON zakodowanego w formacie Base64.
// Monitor the operation until completion.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}
200
{...}
// Upon successful completion, retrieve the PDF as application/pdf.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}/pdf
200 OK
Content-Type: application/pdf
Strony
Kolekcja stron jest listą stron w dokumencie. Każda strona jest reprezentowana sekwencyjnie w dokumencie i zawiera kąt orientacji wskazujący, czy strona jest obracana, oraz szerokość i wysokość (wymiary w pikselach). Jednostki strony w danych wyjściowych modelu są obliczane, jak pokazano poniżej:
| Format pliku | Obliczona jednostka strony | Łączna liczba stron |
|---|---|---|
| Obrazy (JPEG/JPG, PNG, BMP, HEIF) | Każdy obraz = 1 jednostka strony | Łączna liczba obrazów |
| Każda strona w pliku PDF = 1 jednostka strony | Łączna liczba stron w pliku PDF | |
| TIFF | Każdy obraz w jednostce strony TIFF = 1 | Łączna liczba obrazów w tiff |
| Word (DOCX) | Maksymalnie 3000 znaków = 1 jednostka strony, osadzone lub połączone obrazy nie są obsługiwane | Łączna liczba stron z maksymalnie 3000 znakami |
| Excel (XLSX) | Każdy arkusz = 1 jednostka strony, osadzone lub połączone obrazy nie są obsługiwane | Łączna liczba arkuszy |
| PowerPoint (PPTX) | Każdy slajd = 1 jednostka strony, osadzone lub połączone obrazy nie są obsługiwane | Łączna liczba slajdów |
| HTML | Maksymalnie 3000 znaków = 1 jednostka strony, osadzone lub połączone obrazy nie są obsługiwane | Łączna liczba stron z maksymalnie 3000 znakami |
"pages": [
{
"pageNumber": 1,
"angle": 0,
"width": 915,
"height": 1190,
"unit": "pixel",
"words": [],
"lines": [],
"spans": []
}
]
# Analyze pages.
for page in result.pages:
print(f"----Analyzing document from page #{page.page_number}----")
print(
f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}"
)
Wybieranie stron na potrzeby wyodrębniania tekstu
W przypadku dużych wielostronicowych dokumentów PDF użyj parametru pages zapytania, aby wskazać konkretne numery stron lub zakresy stron na potrzeby wyodrębniania tekstu.
Ustępów
Model odczytu OCR w usłudze Document Intelligence wyodrębnia wszystkie zidentyfikowane bloki tekstu w paragraphs kolekcji jako obiekt najwyższego poziomu w obszarze analyzeResults. Każdy wpis w tej kolekcji reprezentuje blok tekstu i zawiera wyodrębniony tekst jakocontent i współrzędne ograniczenia polygon . Informacje span wskazują fragment tekstu we właściwości najwyższego poziomu content zawierającej pełny tekst z dokumentu.
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
Tekst, wiersze i wyrazy
Model odczytu OCR wyodrębnia tekst w stylu drukowania i odręcznego jako lines i words. Model generuje współrzędne ograniczenia i polygon confidence dla wyodrębnionych wyrazów. Kolekcja styles zawiera dowolny styl odręczny wierszy, jeśli zostanie wykryty wraz z zakresami wskazującymi skojarzony tekst. Ta funkcja ma zastosowanie do obsługiwanych języków odręcznych.
W przypadku programów Microsoft Word, Excel, PowerPoint i HTML model odczytu analizy dokumentów w wersji 3.1 lub nowszej wyodrębnia cały osadzony tekst w następujący sposób. Teksty są ekstradowane jako słowa i akapity. Obrazy osadzone nie są obsługiwane.
"words": [
{
"content": "While",
"polygon": [],
"confidence": 0.997,
"span": {}
},
],
"lines": [
{
"content": "While healthcare is still in the early stages of its Al journey, we",
"polygon": [],
"spans": [],
}
]
# Analyze lines.
for line_idx, line in enumerate(page.lines):
words = line.get_words()
print(
f"...Line # {line_idx} has {len(words)} words and text '{line.content}' within bounding polygon '{format_polygon(line.polygon)}'"
)
# Analyze words.
for word in words:
print(
f"......Word '{word.content}' has a confidence of {word.confidence}"
)
Styl odręczny dla wierszy tekstu
Odpowiedź zawiera klasyfikację, czy każdy wiersz tekstu ma styl pisma ręcznego, czy nie, wraz z współczynnikiem ufności. Aby uzyskać więcej informacji, zobacz obsługa języka odręcznego. Poniższy przykład przedstawia przykładowy fragment kodu JSON.
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
Jeśli włączono funkcję dodatku czcionki/stylu, otrzymasz również wynik czcionki/stylu jako część styles obiektu.
Następne kroki
Ukończ przewodnik Szybki start dotyczący analizy dokumentów:
Zapoznaj się z naszym interfejsem API REST:
Znajdź więcej przykładów w witrynie GitHub: