Dostosowywanie modelu (wersja zapoznawcza 4.0)
Ważne
Ta funkcja jest teraz przestarzała. 31 marca 2025 r. zostanie wycofana usługa Azure AI Image Analysis 4.0 Custom Image Classification, Custom Object Detection i Product Recognition (wersja zapoznawcza). Po tej dacie wywołania interfejsu API do tych usług nie powiedzą się.
Aby zapewnić bezproblemową obsługę modeli, przejdź do usługi Azure AI Custom Vision, która jest teraz ogólnie dostępna. Usługa Custom Vision oferuje podobne funkcje do tych funkcji wycofywania.
Dostosowywanie modelu umożliwia trenowanie wyspecjalizowanego modelu analizy obrazów dla własnego przypadku użycia. Modele niestandardowe mogą wykonywać klasyfikację obrazów (tagi mają zastosowanie do całego obrazu) lub wykrywanie obiektów (tagi mają zastosowanie do określonych obszarów obrazu). Po utworzeniu i wytrenowanym modelu niestandardowego należy on do zasobu usługi Vision i można go wywołać przy użyciu interfejsu API analizowania obrazu.
Szybko i łatwo zaimplementuj dostosowywanie modelu, korzystając z przewodnika Szybki start:
Ważne
Model niestandardowy można wytrenować przy użyciu usługi Custom Vision lub usługi Image Analysis 4.0 z dostosowywaniem modelu. W poniższej tabeli porównane są dwie usługi.
| Obszary | Usługa Custom Vision | Usługa Image Analysis 4.0 | ||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zadania | Wykrywanie obiektów klasyfikacji obrazów |
Wykrywanie obiektów klasyfikacji obrazów |
||||||||||||||||||||||||||||||||||||
| Model podstawowy | CNN | Model transformatora | ||||||||||||||||||||||||||||||||||||
| Etykieta | Customvision.ai | AML Studio | ||||||||||||||||||||||||||||||||||||
| Portal sieci Web | Customvision.ai | Vision Studio | ||||||||||||||||||||||||||||||||||||
| Biblioteki | REST, SDK | REST, Przykład języka Python | ||||||||||||||||||||||||||||||||||||
| Wymagane minimalne dane treningowe | 15 obrazów na kategorię | 2–5 obrazów na kategorię | ||||||||||||||||||||||||||||||||||||
| Przechowywanie danych szkoleniowych | Przekazano do usługi | Konto magazynu obiektów blob klienta | ||||||||||||||||||||||||||||||||||||
| Hosting modelu | Chmura i krawędź | Hosting tylko w chmurze, hosting kontenerów brzegowych, które mają być dostępne | ||||||||||||||||||||||||||||||||||||
| Jakość sztucznej inteligencji |
|
|
||||||||||||||||||||||||||||||||||||
| Cennik | Ceny usługi Custom Vision | Cennik analizy obrazów |
Składniki scenariusza
Głównymi składnikami systemu dostosowywania modelu są obrazy treningowe, plik COCO, obiekt zestawu danych i obiekt modelu.
Obrazy szkoleniowe
Zestaw obrazów szkoleniowych powinien zawierać kilka przykładów każdej z etykiet, które chcesz wykryć. Warto również zebrać kilka dodatkowych obrazów, aby przetestować model po wytrenowanym. Obrazy muszą być przechowywane w kontenerze usługi Azure Storage, aby były dostępne dla modelu.
Aby efektywnie trenować model, użyj obrazów z różnymi wizualizacjami. Wybierz obrazy, które różnią się w zależności od:
- kąt kamery
- oświetlenie
- tło
- styl wizualizacji
- osoby/pogrupowane podmioty
- size
- type
Ponadto upewnij się, że wszystkie obrazy szkoleniowe spełniają następujące kryteria:
- Obraz musi być przedstawiony w formacie JPEG, PNG, GIF, BMP, WEBP, ICO, TIFF lub MPO.
- Rozmiar pliku obrazu musi być mniejszy niż 20 megabajtów (MB).
- Wymiary obrazu muszą być większe niż 50 x 50 pikseli i mniejsze niż 16 000 x 16 000 pikseli.
Plik COCO
Plik COCO odwołuje się do wszystkich obrazów szkoleniowych i kojarzy je z informacjami o etykietowaniu. W przypadku wykrywania obiektów określono współrzędne pola ograniczenia każdego tagu na każdym obrazie. Ten plik musi być w formacie COCO, który jest określonym typem pliku JSON. Plik COCO powinien być przechowywany w tym samym kontenerze usługi Azure Storage co obrazy szkoleniowe.
Napiwek
Informacje o plikach COCO
Pliki COCO to pliki JSON z określonymi wymaganymi polami: "images", "annotations"i "categories". Przykładowy plik COCO będzie wyglądać następująco:
{
"images": [
{
"id": 1,
"width": 500,
"height": 828,
"file_name": "0.jpg",
"absolute_url": "https://blobstorage1.blob.core.windows.net/cpgcontainer/0.jpg"
},
{
"id": 2,
"width": 754,
"height": 832,
"file_name": "1.jpg",
"absolute_url": "https://blobstorage1.blob.core.windows.net/cpgcontainer/1.jpg"
},
...
],
"annotations": [
{
"id": 1,
"category_id": 7,
"image_id": 1,
"area": 0.407,
"bbox": [
0.02663142641129032,
0.40691584277841153,
0.9524163571731749,
0.42766634515266866
]
},
{
"id": 2,
"category_id": 9,
"image_id": 2,
"area": 0.27,
"bbox": [
0.11803319477782331,
0.41586723392402375,
0.7765206955096307,
0.3483334397217212
]
},
...
],
"categories": [
{
"id": 1,
"name": "vegall original mixed vegetables"
},
{
"id": 2,
"name": "Amy's organic soups lentil vegetable"
},
{
"id": 3,
"name": "Arrowhead 8oz"
},
...
]
}
Dokumentacja pola pliku COCO
Jeśli generujesz własny plik COCO od podstaw, upewnij się, że wszystkie wymagane pola są wypełnione prawidłowymi szczegółami. W poniższych tabelach opisano każde pole w pliku COCO:
"obrazy"
| Klucz | Type | Opis | Wymagane? |
|---|---|---|---|
id |
integer | Unikatowy identyfikator obrazu, począwszy od 1 | Tak |
width |
integer | Szerokość obrazu w pikselach | Tak |
height |
integer | Wysokość obrazu w pikselach | Tak |
file_name |
string | Unikatowa nazwa obrazu | Tak |
absolute_url lub coco_url |
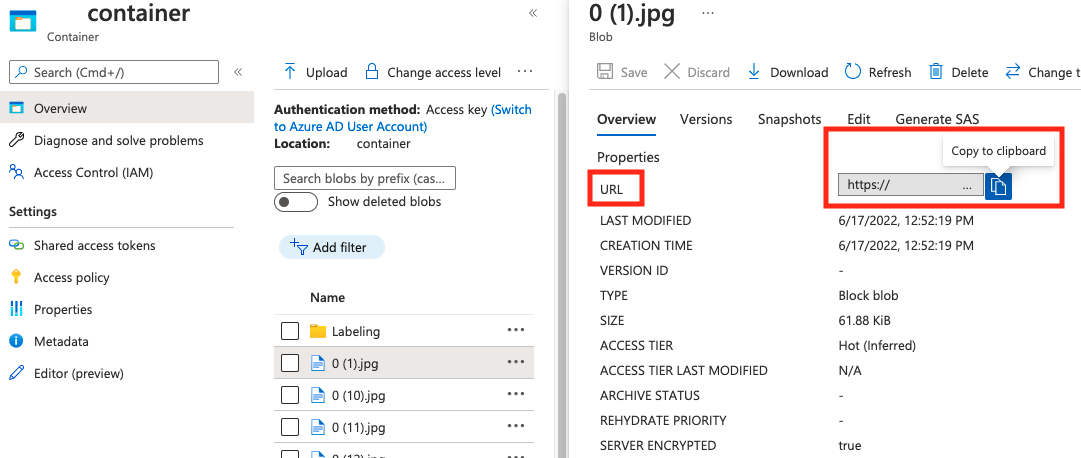
string | Ścieżka obrazu jako bezwzględny identyfikator URI do obiektu blob w kontenerze obiektów blob. Zasób przetwarzania obrazów musi mieć uprawnienia do odczytywania plików adnotacji i wszystkich plików obrazów, do których się odwołujesz. | Tak |
Wartość parametru absolute_url można znaleźć we właściwościach kontenera obiektów blob:
"Adnotacje"
| Klucz | Type | Opis | Wymagane? |
|---|---|---|---|
id |
integer | Identyfikator adnotacji | Tak |
category_id |
integer | Identyfikator kategorii zdefiniowanej categories w sekcji |
Tak |
image_id |
integer | Identyfikator obrazu | Tak |
area |
integer | Wartość wartości "Width" x "Height" (trzecie i czwarte wartości bbox) |
Nie. |
bbox |
list[float] | Współrzędne względne pola ograniczenia (od 0 do 1) w kolejności od "Lewa", "Góra", "Szerokość", "Wysokość" | Tak |
"kategorie"
| Klucz | Type | Opis | Wymagane? |
|---|---|---|---|
id |
integer | Unikatowy identyfikator dla każdej kategorii (klasa etykiety). Powinny one znajdować się w annotations sekcji . |
Tak |
name |
string | Nazwa kategorii (klasa etykiety) | Tak |
Weryfikacja pliku COCO
Możesz użyć naszego przykładowego kodu w języku Python, aby sprawdzić format pliku COCO.
Obiekt zestawu danych
Obiekt Dataset to struktura danych przechowywana przez usługę Analizy obrazów, która odwołuje się do pliku skojarzenia. Przed utworzeniem i wytreniem modelu należy utworzyć obiekt Zestawu danych .
Obiekt modelu
Obiekt Model to struktura danych przechowywana przez usługę Image Analysis, która reprezentuje model niestandardowy. Aby można było przeprowadzić wstępne szkolenie, należy go skojarzyć z zestawem danych . Po zakończeniu trenowania możesz wykonać zapytanie względem modelu, wprowadzając jego nazwę w parametrze model-name zapytania wywołania interfejsu API analizowania obrazów.
Limity przydziału
W poniższej tabeli opisano limity skali niestandardowych projektów modelu.
| Kategoria | Klasyfikator obrazu ogólnego | Ogólny detektor obiektów |
|---|---|---|
| Maksymalna liczba godzin trenowania | 288 (12 dni) | 288 (12 dni) |
| Maksymalna liczba obrazów szkoleniowych | 1 000 000 | 200,000 |
| Maksymalna liczba obrazów oceny | 100 000 | 100 000 |
| Minimalna liczba obrazów treningowych na kategorię | 2 | 2 |
| Maksymalna liczba tagów na obraz | 1 | Nie dotyczy |
| Maksymalna liczba regionów na obraz | Nie dotyczy | 1000 |
| Maksymalna liczba kategorii | 2500 | 1000 |
| Minimalna liczba kategorii | 2 | 1 |
| Maksymalny rozmiar obrazu (trenowanie) | 20 MB | 20 MB |
| Maksymalny rozmiar obrazu (przewidywanie) | Synchronizacja: 6 MB, Partia: 20 MB | Synchronizacja: 6 MB, Partia: 20 MB |
| Maksymalna szerokość/wysokość obrazu (trenowanie) | 10,240 | 10,240 |
| Minimalna szerokość/wysokość obrazu (przewidywanie) | 50 | 50 |
| Dostępne regiony | Zachodnie stany USA 2, Wschodnie stany USA, Europa Zachodnia | Zachodnie stany USA 2, Wschodnie stany USA, Europa Zachodnia |
| Zaakceptowane typy obrazów | jpg, png, bmp, gif, jpeg | jpg, png, bmp, gif, jpeg |
Często zadawane pytania
Dlaczego importowanie pliku COCO kończy się niepowodzeniem podczas importowania z magazynu obiektów blob?
Obecnie firma Microsoft rozwiązała problem powodujący niepowodzenie importowania plików COCO z dużymi zestawami danych podczas inicjowania w programie Vision Studio. Aby wytrenować przy użyciu dużego zestawu danych, zaleca się użycie interfejsu API REST.
Dlaczego szkolenie trwa dłużej/krócej niż określony budżet?
Określony budżet trenowania to skalibrowany czas obliczeniowy, a nie czas zegara ściany. Poniżej wymieniono niektóre typowe przyczyny różnicy:
Dłuższy niż określony budżet:
- Analiza obrazów ma duży ruch szkoleniowy, a zasoby procesora GPU mogą być napięte. Zadanie może czekać w kolejce lub zostać wstrzymane podczas trenowania.
- Proces trenowania zaplecza napotkał nieoczekiwane błędy, co spowodowało ponowienie próby logiki. Przebiegi, które zakończyły się niepowodzeniem, nie zużywają budżetu, ale może to prowadzić do dłuższego czasu trenowania ogólnie.
- Dane są przechowywane w innym regionie niż zasób usługi Vision, co doprowadzi do dłuższego czasu transmisji danych.
Krótszy niż określony budżet: Następujące czynniki przyspieszają szkolenie kosztem korzystania z większego budżetu w określonym czasie zegara.
- Analiza obrazów czasami trenuje z wieloma procesorami GPU w zależności od danych.
- Analiza obrazów czasami trenuje wiele prób eksploracji na wielu procesorach GPU w tym samym czasie.
- Analiza obrazów czasami używa jednostek SKU procesora GPU premier (szybciej) do trenowania.
Dlaczego moje szkolenie kończy się niepowodzeniem i co należy zrobić?
Poniżej przedstawiono niektóre typowe przyczyny niepowodzenia trenowania:
-
diverged: Szkolenie nie może nauczyć się znaczących rzeczy z danych. Oto niektóre typowe przyczyny:- Dane nie są wystarczające: zapewnienie większej ilości danych powinno pomóc.
- Dane są niskiej jakości: sprawdź, czy obrazy mają niską rozdzielczość, skrajne współczynniki proporcji lub czy adnotacje są nieprawidłowe.
-
notEnoughBudget: Określony budżet nie jest wystarczający dla rozmiaru zestawu danych i typu modelu, który trenujesz. Określ większy budżet. -
datasetCorrupt: Zazwyczaj oznacza to, że podane obrazy nie są dostępne lub plik adnotacji jest w niewłaściwym formacie. -
datasetNotFound: nie można odnaleźć zestawu danych -
unknown: Może to być problem z zapleczem. Skontaktuj się z pomocą techniczną dotyczącą badania.
Jakie metryki są używane do oceny modeli?
Używane są następujące metryki:
- Klasyfikacja obrazów: średnia precyzja, dokładność top 1, dokładność top 5
- Wykrywanie obiektów: średnia precyzja @ 30, średnia precyzja @ 50, średnia precyzja @ 75
Dlaczego rejestracja zestawu danych kończy się niepowodzeniem?
Odpowiedzi interfejsu API powinny być wystarczająco informacyjne. Są to:
-
DatasetAlreadyExists: istnieje zestaw danych o tej samej nazwie -
DatasetInvalidAnnotationUri: "Podano nieprawidłowy identyfikator URI wśród identyfikatorów URI adnotacji w czasie rejestracji zestawu danych.
Ile obrazów jest wymaganych do rozsądnej/dobrej/najlepszej jakości modelu?
Chociaż modele Florencji mają doskonałe możliwości tworzenia kilku zdjęć (osiągnięcie wysokiej wydajności modelu w ramach ograniczonej dostępności danych), ogólnie więcej danych sprawia, że wytrenowany model jest lepszy i bardziej niezawodny. Niektóre scenariusze wymagają niewielkiej ilości danych (takich jak klasyfikowanie jabłek przeciwko bananowi), ale inne wymagają więcej (takich jak wykrywanie 200 rodzajów owadów w lesie deszczowym). Utrudnia to nadanie pojedynczej rekomendacji.
Jeśli budżet etykietowania danych jest ograniczony, zalecanym przepływem pracy jest powtórzenie następujących kroków:
Zbieranie
Nobrazów na klasę, gdzieNobrazy są łatwe do zbierania (na przykładN=3)Wytrenuj model i przetestuj go na zestawie oceny.
Jeśli wydajność modelu jest:
- Wystarczająco dobra (wydajność jest lepsza niż oczekiwano lub wydajność zbliżona do poprzedniego eksperymentu z mniej zebranymi danymi): zatrzymaj się tutaj i użyj tego modelu.
- Nie jest dobra (wydajność jest nadal niższa od oczekiwań lub lepszej niż poprzedni eksperyment z mniejszymi danymi zebranymi na rozsądnym marginesie):
- Zbierz więcej obrazów dla każdej klasy — liczbę, która jest łatwa do zebrania — i wróć do kroku 2.
- Jeśli zauważysz, że wydajność nie poprawia się jeszcze po kilku iteracji, może to być spowodowane:
- ten problem nie jest dobrze zdefiniowany lub jest zbyt twardy. Skontaktuj się z nami, aby przeanalizować wielkość liter.
- dane treningowe mogą być niskiej jakości: sprawdź, czy istnieją nieprawidłowe adnotacje lub bardzo małe obrazy pikseli.
Ile budżetu szkoleniowego należy określić?
Należy określić górny limit budżetu, który chcesz zużyć. Analiza obrazów używa systemu AutoML w zapleczu, aby wypróbować różne modele i przepisy szkoleniowe, aby znaleźć najlepszy model dla danego przypadku użycia. Im więcej budżetu, tym większa szansa na znalezienie lepszego modelu.
System automatycznego uczenia maszynowego również zatrzymuje się automatycznie, jeśli stwierdza, że nie ma potrzeby próbować więcej, nawet jeśli nadal istnieje pozostały budżet. W związku z tym nie zawsze wyczerpuje określony budżet. Nie masz gwarancji, że nie będą naliczane opłaty za określony budżet.
Czy mogę kontrolować parametry hyper-parameters lub używać własnych modeli podczas trenowania?
Nie, usługa dostosowywania modelu analizy obrazów używa systemu trenowania automatycznego uczenia maszynowego o niskim kodzie, który obsługuje wyszukiwanie hiperparam i wybór modelu podstawowego w zapleczu.
Czy mogę wyeksportować model po trenowaniu?
Interfejs API przewidywania jest obsługiwany tylko za pośrednictwem usługi w chmurze.
Dlaczego ocena kończy się niepowodzeniem dla mojego modelu wykrywania obiektów?
Poniżej przedstawiono możliwe przyczyny:
-
internalServerError: wystąpił nieznany błąd. Spróbuj ponownie później. -
modelNotFound: Nie można odnaleźć określonego modelu. -
datasetNotFound: Nie można odnaleźć określonego zestawu danych. -
datasetAnnotationsInvalid: Wystąpił błąd podczas próby pobrania lub przeanalizowanie adnotacji podstawy prawdy skojarzonych z testowym zestawem danych. -
datasetEmpty: Zestaw danych testowych nie zawierał żadnych adnotacji "prawda naziemna".
Jakie jest oczekiwane opóźnienie przewidywania z modelami niestandardowymi?
Nie zalecamy używania modeli niestandardowych w środowiskach krytycznych dla działania firmy ze względu na potencjalne duże opóźnienie. Gdy klienci szkolą modele niestandardowe w usłudze Vision Studio, te modele niestandardowe należą do zasobu usługi Azure AI Vision, w ramach którego zostali przeszkoleni, a klient może wykonywać wywołania tych modeli przy użyciu interfejsu API analizowania obrazów . Podczas wykonywania tych wywołań model niestandardowy jest ładowany w pamięci, a infrastruktura przewidywania jest inicjowana. W takim przypadku klienci mogą doświadczać dłuższych niż oczekiwano opóźnień, aby otrzymywać wyniki przewidywania.
Prywatność i zabezpieczenia danych
Podobnie jak w przypadku wszystkich usług azure AI, deweloperzy korzystający z dostosowywania modelu analizy obrazów powinni pamiętać o zasadach firmy Microsoft dotyczących danych klientów. Aby dowiedzieć się więcej, zobacz stronę usługi Azure AI w Centrum zaufania firmy Microsoft.