Uruchamianie aplikacji N-warstwowej w wielu regionach usługi Azure Stack Hub w celu zapewnienia wysokiej dostępności
Ta architektura referencyjna pokazuje zestaw sprawdzonych praktyk dotyczących uruchamiania aplikacji N-warstwowej w wielu regionach usługi Azure Stack Hub, w celu osiągnięcia dostępności i solidnej infrastruktury odzyskiwania po awarii. W tym dokumencie usługa Traffic Manager jest używana do zapewnienia wysokiej dostępności, jednak jeśli usługa Traffic Manager nie jest preferowanym wyborem w danym środowisku, można również zamiast niej użyć pary modułów równoważenia obciążenia o wysokiej dostępności.
Notatka
Należy pamiętać, że usługa Traffic Manager używana w poniższej architekturze musi być skonfigurowana na platformie Azure, a punkty końcowe używane do konfigurowania profilu usługi Traffic Manager muszą być publicznie routingowymi adresami IP.
Architektura
Ta architektura opiera się na architekturze pokazanej w aplikacji N-warstwowej z programem SQL Server.
architektura sieci 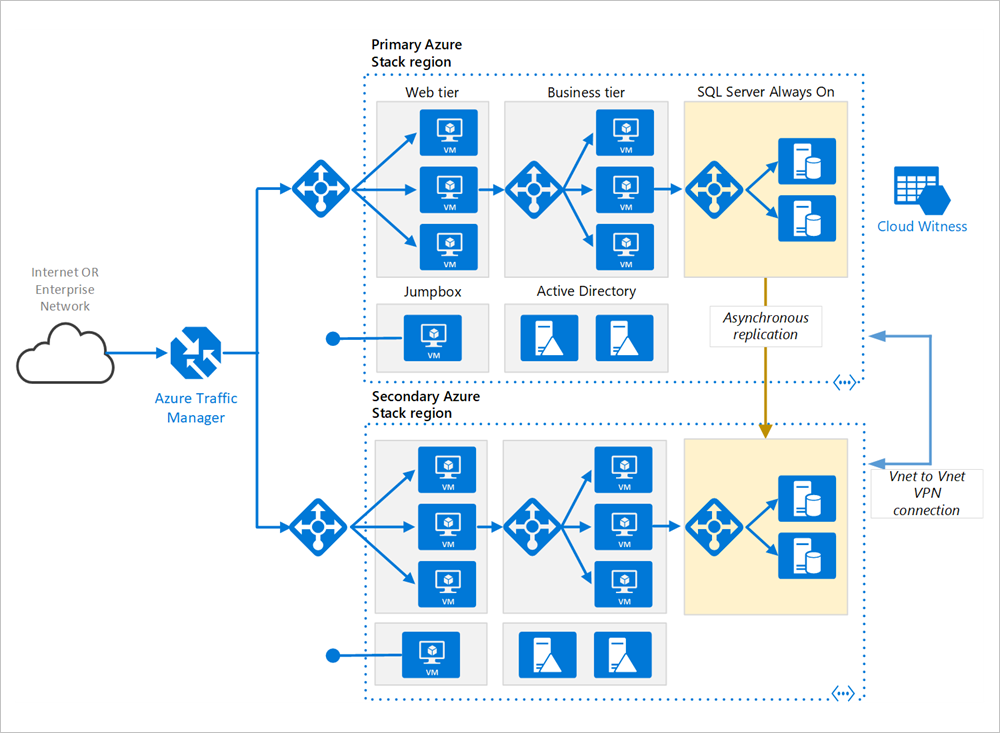
Regiony podstawowe i pomocnicze. Użyj dwóch regionów, aby uzyskać wyższą dostępność. Jednym z nich jest region podstawowy. Drugi region jest przeznaczony do trybu failover.
Azure Traffic Manager. usługa Traffic Manager kieruje żądania przychodzące do jednego z regionów. Podczas normalnych operacji kieruje żądania do regionu podstawowego. Jeśli ten region stanie się niedostępny, usługa Traffic Manager ulegnie awarii w regionie pomocniczym. Aby uzyskać więcej informacji, zobacz sekcję konfiguracji usługi Traffic Manager.
grupy zasobów. Utwórz oddzielne grupy zasobów dla regionu podstawowego, regionu pomocniczego. Zapewnia to elastyczność zarządzania poszczególnymi regionami jako pojedynczą kolekcją zasobów. Na przykład można ponownie wdrożyć jeden region bez wyłączania drugiego. Połącz grupy zasobów, aby można było uruchomić zapytanie, aby wyświetlić listę wszystkich zasobów aplikacji.
sieci wirtualne. Utwórz oddzielną sieć wirtualną dla każdego regionu. Upewnij się, że przestrzenie adresowe nie nakładają się na siebie.
grupa dostępności Always On programu SQL Server. Jeśli używasz programu SQL Server, zalecamy SQL Always On Availability Groups dla wysokiej dostępności. Utwórz pojedynczą grupę dostępności obejmującą wystąpienia programu SQL Server w obu regionach.
Połączenie VPN sieci wirtualnej z inną siecią wirtualną. Ponieważ VNET Peering nie jest jeszcze dostępny w usłudze Azure Stack Hub, użyj połączenia VPN między sieciami VNET, aby połączyć te dwie sieci VNET. Aby uzyskać więcej informacji, zobacz połączenie sieci wirtualnej do sieci wirtualnej w usłudze Azure Stack Hub.
Zalecenia
Architektura z wieloma regionami może zapewnić wyższą dostępność niż wdrażanie w jednym regionie. Jeśli awaria regionalna ma wpływ na region podstawowy, możesz użyć usługi Traffic Manager, aby przejść w tryb failover do regionu pomocniczego. Ta architektura może również pomóc w przypadku awarii poszczególnych podsystemów aplikacji.
Istnieje kilka ogólnych podejść do osiągnięcia wysokiej dostępności w różnych regionach:
aktywne/pasywne z gorącą rezerwą. Ruch przechodzi do jednego regionu, podczas gdy drugi pozostaje w gotowości jako gorąca rezerwa. Rezerwa gorąca oznacza, że maszyny wirtualne w regionie pomocniczym są przydzielane i uruchomione przez cały czas.
aktywny/pasywny z zimną rezerwą. Ruch przechodzi do jednego regionu, podczas gdy drugi czeka w trybie zimnego oczekiwania. Rezerwa zimna oznacza, że maszyny wirtualne w regionie pomocniczym nie są przydzielane do czasu konieczności przejścia w tryb failover. To podejście jest tańsze w eksploatacji, ale zazwyczaj trwa dłużej, aby wejść w tryb online w przypadku awarii.
aktywne/aktywne. Oba regiony są aktywne, a żądania są zrównoważone między nimi. Jeśli jeden region stanie się niedostępny, zostanie wycofany z rotacji.
Ta architektura referencyjna koncentruje się na aktywnym/pasywnym z gorącą rezerwą, wykorzystując Traffic Manager do przełączania awaryjnego. W razie potrzeby można wdrożyć niewielką liczbę maszyn wirtualnych na potrzeby gorącej rezerwy, a następnie rozszerzać ich liczbę.
Konfiguracja usługi Traffic Manager
Podczas konfigurowania usługi Traffic Manager należy wziąć pod uwagę następujące kwestie:
routingu. Usługa Traffic Manager obsługuje kilka algorytmów routingu . W scenariuszu opisanym w tym artykule użyj routingu priorytetowego (wcześniej nazywanego routingiem trybu failover ). Dzięki temu ustawieniu usługa Traffic Manager wysyła wszystkie żądania do regionu podstawowego, chyba że region podstawowy stanie się niedostępny. W tym momencie automatycznie przełącza się do regionu zapasowego. Zobacz Konfigurowanie metody failover routingu.
sonda kondycji. Usługa Traffic Manager używa sondy http (lub HTTPS) do monitorowania dostępności poszczególnych regionów. Sonda sprawdza odpowiedź HTTP 200 dla określonej ścieżki adresu URL. Najlepszym rozwiązaniem jest utworzenie punktu końcowego, który raportuje ogólną kondycję aplikacji i użyj tego punktu końcowego dla sondy kondycji. W przeciwnym razie sonda może zgłosić zdrowy stan punktu końcowego, gdy krytyczne części aplikacji rzeczywiście ulegają awarii. Aby uzyskać więcej informacji, zapoznaj się ze wzorcem monitorowania punktu końcowego kondycji .
W przypadku awarii usługi Traffic Manager występuje okres, w którym klienci nie mogą uzyskać dostępu do aplikacji. Czas trwania ma wpływ na następujące czynniki:
Sonda zdrowia musi wykryć, że region podstawowy stał się już niedostępny.
Serwery DNS muszą zaktualizować buforowane rekordy DNS dla adresu IP, co zależy od czasu życia DNS (TTL). Domyślny czas wygaśnięcia to 300 sekund (5 minut), ale tę wartość można skonfigurować podczas tworzenia profilu usługi Traffic Manager.
Aby uzyskać szczegółowe informacje, zobacz Informacje o monitorowaniu usługi Traffic Manager.
Jeśli usługa Traffic Manager przełączy się w tryb failover, zalecamy wykonanie ręcznego powrotu po awarii zamiast implementowania automatycznego powrotu po awarii. W przeciwnym razie można utworzyć sytuację, w której aplikacja przełącza się tam i z powrotem między regionami. Przed przywróceniem do normalnego stanu sprawdź, czy wszystkie podsystemy aplikacji są sprawne.
Pamiętaj, że usługa Traffic Manager domyślnie automatycznie przywraca oryginalne ustawienia. Aby temu zapobiec, ręcznie obniż priorytet regionu podstawowego po zdarzeniu failover. Załóżmy na przykład, że region podstawowy ma priorytet 1, a pomocniczy ma priorytet 2. Po przejściu w tryb failover ustaw region podstawowy na priorytet 3, aby zapobiec automatycznemu powrotowi po awarii. Gdy wszystko będzie gotowe do przełączenia, z powrotem zaktualizuj priorytet na 1.
Następujące polecenie Azure CLI aktualizuje priorytet:
az network traffic-manager endpoint update --resource-group <resource-group> --profile-name <profile>
--name <endpoint-name> --type externalEndpoints --priority 3
Innym podejściem jest tymczasowe wyłączenie punktu końcowego, aż będziesz gotowy do przywrócenia.
az network traffic-manager endpoint update --resource-group <resource-group> --profile-name <profile>
--name <endpoint-name> --type externalEndpoints --endpoint-status Disabled
W zależności od przyczyny przejścia w tryb failover może być konieczne ponowne wdrożenie zasobów w regionie. Przed wdrożeniem procedury powrotu do poprzedniego stanu, wykonaj test gotowości operacyjnej. Test powinien zweryfikować następujące elementy:
Maszyny wirtualne są poprawnie skonfigurowane. (Wszystkie wymagane oprogramowanie jest zainstalowane, usługi IIS są uruchomione itd.)
Podsystemy aplikacji są w dobrej kondycji.
Testowanie funkcjonalne. (Na przykład warstwa bazy danych jest osiągalna z warstwy internetowej).
Konfigurowanie zawsze włączonych grup dostępności programu SQL Server
Przed systemem Windows Server 2016 zawsze włączone grupy dostępności programu SQL Server wymagają kontrolera domeny, a wszystkie węzły w grupie dostępności muszą znajdować się w tej samej domenie usługi Active Directory (AD).
Aby skonfigurować grupę dostępności:
Umieść co najmniej dwa kontrolery domeny w każdym regionie.
Nadaj każdemu kontrolerowi domeny statyczny adres IP.
Utwórz sieci VPN, aby umożliwić komunikację między dwiema sieciami wirtualnymi.
Dla każdej sieci wirtualnej dodaj adresy IP kontrolerów domeny (z obu regionów) do listy serwerów DNS. Możesz użyć następującego polecenia interfejsu wiersza polecenia. Aby uzyskać więcej informacji, zobacz Zmienianie serwerów DNS.
az network vnet update --resource-group <resource-group> --name <vnet-name> --dns-servers "10.0.0.4,10.0.0.6,172.16.0.4,172.16.0.6"Utwórz klaster klastra trybu failover systemu Windows Server (WSFC), który obejmuje wystąpienia programu SQL Server w obu regionach.
Utwórz zawsze włączoną grupę dostępności programu SQL Server, która zawiera wystąpienia programu SQL Server w regionach podstawowych i pomocniczych. Zobacz Rozszerzanie zawsze włączonej grupy dostępności na zdalne centrum danych platformy Azure (PowerShell), aby uzyskać instrukcje.
Umieść replikę podstawową w regionie podstawowym.
Umieść co najmniej jedną replikę pomocniczą w regionie podstawowym. Skonfiguruj je tak, aby korzystały z zatwierdzania synchronicznego z automatycznym trybem failover.
Rozmieść co najmniej jedną replikę pomocniczą w regionie pomocniczym. Skonfiguruj je tak, aby używać asynchronicznego zatwierdzania ze względów wydajności. (W przeciwnym razie wszystkie transakcje T-SQL muszą czekać w obie strony przez sieć do regionu pomocniczego).
Notatka
Repliki zatwierdzeń asynchronicznych nie obsługują automatycznego trybu failover.
Zagadnienia dotyczące dostępności
W przypadku złożonej aplikacji N-warstwowej może nie być konieczne replikowanie całej aplikacji w regionie pomocniczym. Zamiast tego można po prostu replikować podsystem krytyczny, który jest potrzebny do obsługi ciągłości działania.
Usługa Traffic Manager jest możliwym punktem awarii w systemie. Jeśli usługa Traffic Manager zakończy się niepowodzeniem, klienci nie będą mogli uzyskać dostępu do aplikacji podczas przestoju. Przejrzyj umowę SLA dotycząca usługi Traffic Manager i ustal, czy samo korzystanie z usługi Traffic Manager spełnia wymagania biznesowe dotyczące wysokiej dostępności. Jeśli nie, rozważ dodanie innego rozwiązania do zarządzania ruchem jako opcję awaryjną. Jeśli usługa Azure Traffic Manager zakończy się niepowodzeniem, zmień rekordy CNAME w systemie DNS, aby wskazywały inną usługę zarządzania ruchem. (Ten krok należy wykonać ręcznie, a aplikacja będzie niedostępna do momentu propagowania zmian DNS).
W przypadku klastra programu SQL Server należy wziąć pod uwagę dwa scenariusze trybu failover:
Wszystkie repliki bazy danych programu SQL Server w regionie podstawowym kończą się niepowodzeniem. Na przykład może się to zdarzyć podczas awarii regionalnej. W takim przypadku należy ręcznie przełączyć grupę dostępności, mimo że usługa Traffic Manager automatycznie przełącza się na poziomie frontendu. Wykonaj kroki opisane w Wykonywanie wymuszonego ręcznego przejścia w tryb failover grupy dostępności programu SQL Server, w którym opisano sposób przeprowadzania wymuszonego przejścia w tryb failover przy użyciu programu SQL Server Management Studio, języka Transact-SQL lub programu PowerShell w programie SQL Server 2016.
Ostrzeżenie
W przypadku wymuszonego przejścia w tryb failover istnieje ryzyko utraty danych. Gdy region podstawowy wróci do trybu online, utwórz migawkę bazy danych i użyj tablediff, aby znaleźć różnice.
Usługa Traffic Manager przełącza się w tryb failover do regionu zapasowego, ale podstawowa replika bazy danych SQL Server jest nadal dostępna. Na przykład warstwa front-end może ulec awarii, nie wpływając na maszyny wirtualne SQL Server. W takim przypadku ruch internetowy jest kierowany do regionu pomocniczego, a ten region nadal może łączyć się z repliką podstawową. Jednak wystąpi większe opóźnienie, ponieważ połączenia programu SQL Server będą działać w różnych regionach. W takiej sytuacji należy wykonać ręczne przejście w tryb failover w następujący sposób:
Tymczasowo przełącz replikę bazy danych SQL Server w regionie zapasowym na synchroniczne zatwierdzanie. Dzięki temu nie nastąpi utrata danych podczas pracy w trybie failover.
Przełącz na tę replikę.
Po powrocie po awarii do regionu podstawowego przywróć ustawienie zatwierdzenia asynchronicznego.
Zagadnienia dotyczące możliwości zarządzania
Podczas aktualizowania wdrożenia zaktualizuj jeden region naraz, aby zmniejszyć prawdopodobieństwo awarii globalnej z nieprawidłowej konfiguracji lub błędu w aplikacji.
Przetestuj odporność systemu na błędy. Oto kilka typowych scenariuszy niepowodzenia do przetestowania:
Wyłącz instancje maszyn wirtualnych.
Obciążenie zasobów, takie jak procesor CPU i pamięć.
Rozłącz/opóźnij sieć.
Procesy awarii.
Wygasanie certyfikatów.
Symulowanie błędów sprzętowych.
Zamknij usługę DNS na kontrolerach domeny.
Zmierz czas odzyskiwania i sprawdź, czy spełniają twoje wymagania biznesowe. Przetestuj również kombinacje trybów awarii.
Następne kroki
- Aby dowiedzieć się więcej na temat wzorców chmury platformy Azure, zobacz Wzorce projektowania chmury.