SQL Server 2005 UNICODE considerations.
ISV applications today often require international support. Migrating an existing non-Unicode database to Unicode is a commonly discussed topic in the ISV application space. This BLOG entry discusses the general considerations and approaches to migrate a database to Unicode with SQL Server.
SQL Server Unicode Support
SQL Server Unicode data types support UCS-2 encoding. Unicode data types store character data using two bytes for each character rather than one byte. There are 65,536 different bit patterns in two bytes, so Unicode can use one standard set of bit patterns to encode each character in all languages, including languages such as Chinese that have large numbers of characters.
In SQL Server, data types that support Unicode data are:
- nchar
- nvarchar
- nvarchar(max) – new in SQL Server 2005
- ntext
Use of nchar, nvarchar, nvarchar(max), and ntext is the same as char, varchar, varchar(max), and text, respectively, except:
- Unicode supports a wider range of characters.
- More space is needed to store Unicode characters.
- The maximum size of nchar and nvarchar columns is 4,000 characters, not 8,000 characters like char and varchar.
- Unicode constants are specified with a leading N, for example, N'A Unicode string'
Migration Considerations
Migrating a database to Unicode involves considerations beyond simply changing columns to use Unicode data types. It requires careful planning on the database and application to avoid the possibility of losing and corrupting data. The discussion on application planning is outside the scope of this BLOG. On the database side, the things to consider before migration are
1) Column size
2) Page size
3) Variable
4) Disk Space
Column Size
Unicode data types store each character with two bytes instead of one byte. SQL Server column limit is 8000 bytes for both Non-Unicode and Unicode column. The maximum size of a Unicode column is 4000 characters. When migrate to Unicode, all column data beyond 4000 characters will be truncated. Column data should be scanned to prevent data loss. If a Unicode column needs to hold more than 4000 characters, the column should be converted to nvarchar(max).
Page Size
SQL Server page size is 8K. The size of a character column doubles when migrate to Unicode. Existing data that used to fit in an 8K page might not fit any more. In SQL Server 2000, the way to extend a record beyond 8060 bytes of data is through a BLOB (text, image) column. With SQL Server 2005, the 8K page size is still there, but SQL Server 2005 supports large rows by allowing data in variable size columns to over-flow automatically in the case of a record length is greater than 8060 bytes. SQL Sever 2005 has a mechanism to dynamically over-flow data off page or pull data in page as a record size increases beyond 8k or decreases to fit within an 8k page. The flexibility provided by SQL Server 2005 could mean one less consideration for Unicode migration. However, be aware that flexibility comes with a price. Constant data move off/on page could affect performance. If you know a column will most likely contain a large block of data, use the nvarchar(max) data type. And use the sp_tableoption “large value types out of row” option to store the max data type out of page.
Variables
Nchar, nvarchar, nvarchar(max), ntext should be used when declaring a variable for use with the Unicode schema. With Unicode data type declaration, the column size specifier is in character instead of in bytes. Unicode literals are specified with a leading uppercase N, for example N’A Unicode string’. The N stands for National Language in the SQL-92 standard. If a query contains Non-Unicode variable, literal is being executed against a Unicode schema, the variable/literal will need to be converted to Unicode during execution, and cause additional execution overheads. Existing T-SQL code (store procedures, user defined functions, check constraints, computed columns) hould be reviewed to ensure 1) valid variable declaration. 2) use of N identifier. 3) any byte operations are still valid.
Disk Space
SQL Server uses a single byte for storing character in a non-Unicode code page that’s non-DBCS, and two bytes for Asian languages that use DBCS. For Unicode data SQL Server uses two bytes for each character. Depending on the amount of character data and character based indexes in the database, the size of the database could increase significantly after migrating a non-Asian database to Unicode. Sufficient disk space should be planned for the migration.
Migrating to a Unicode Database
There are two general approaches to migrate data from non-Unicode to Unicode: 1) Full Export and Import 2) In-place Conversion.
Full Export and Import
In most case a full export and import data is needed to convert data to Unicode without data loss. The steps to migrate to Unicode using a full export and import are:
- Backup the database
- Scan the database for possible data truncation, column size, page size issues
- Create a new database with Unicode schema (without indexes)
- Export non-Unicode data
- Import data into Unicode database
- Create indexes on Unicode database
- Review existing T-SQL code to ensure variable declaration, byte operations are still valid
To simplify the process of exporting and importing data into SQL Server, you can use SQL Server Integration Service or the SQL server BCP utility. Both provide the ability for automatic Unicode conversion.
Using BCP
To prevent data loss when copying code page data into Unicode database, you can specify the data to be exported and imported in Unicode format with the –N or the –w flag. The following table is a comparison of the two options.
Flag |
Description |
-N |
Use Unicode character format for all character data, and use native (database) data types for all non-character data. This option offers higher performance than the –w option. This option limits BCP data between SQL Server with same character sets and sort order. |
-w |
Use Unicode character data format for all columns. |
For example, to export data to from table “strTbl” using trusted connection.
bcp myDb.dbo.strTbl out C:\strTbl.Dat -N -T
When importing the data, use the BCP fast mode when possible. The fast mode can save substantial time for data loading. To take advantage of the BCP fast mode, the following criteria must be met.
- The “select into/bulkcopy” database option must be set
- The target table should not have any indexes
- The target table must not be part of the replication
- Use TABLOCK to lock the target table
For example, to import data into Unicode table “wstrTbl” using the data file exported above.
bcp myUnicodeDb.dbo.wstrTbl in C:\strTbl.Dat -N -T
Using SQL Server Integration Services
If there are requirements to pre-process data before migrating data to Unicode, SQL Server Integration Services (SSIS) would be a better tool than BCP. The advantages of using SSIS over BCP are 1) better manageability and control 2) no need for intermediate disk storage for bcp files 3) user friendly GUI interface.
Using SSIS Data Flow Task to pump data between a non-Unicode to a Unicode database is straightforward. What should be aware of is that SSIS is now more restricted on data mapping in data Flow. For example, with the old SQL2K DTS, you can do Copy Column Transformation from a varchar column to an nvarchar column. In cases when the source data does not have the same code page as the source server, data could be corrupted during the data pump. DTS does not prevent that. SSIS is more proactive in preventing data corruption. With SSIS, if you attempt to do Copy Column Transformation between a varchar column and an nvarchar column, you will receive a compile time error “cannot convert between Unicode and no-Unicode string data type”. No implicit data conversion is allowed in SSIS. All data types need to match or be explicitly converted. To load non-Unicode data to a Unicode table, all character data would need to be explicated converted to Unicode data types upstream using the Data Conversion or Derived Column Transformation task. The following picture shows the Data Flow Task that uses a Data Conversion Transformation to explicitly convert non-Unicode character data to Unicode and fast loads data into a Unicode table.
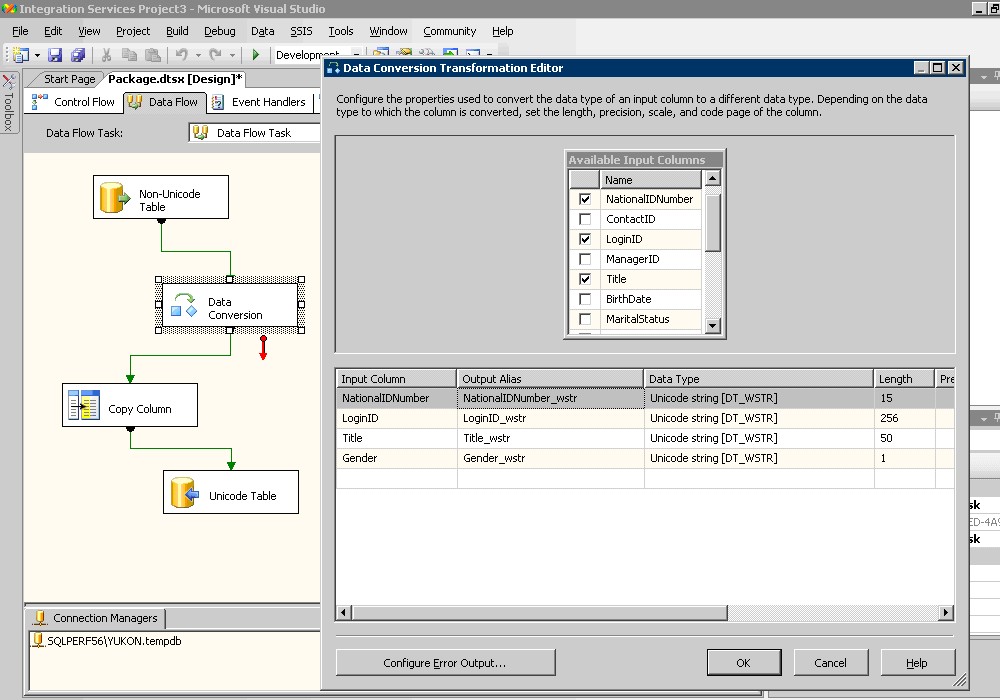
In-Place Conversion
If the non-Unicode database character set ASCII, and is in the 7-bit range such as US-English, it’s possible to convert the data in-place since UCS-2 is a superset of ASCII. You can use the Alter Table Alter Column statement to change columns from non-Unicode data types, char, varchar, varchar(max), text to Unicode data types, nchar, nvarchar, nvarchar(max), ntext. For example,
With the following table schema:
CREATE TABLE employee (
EmployeeID int NOT NULL,
NationalIDNumber varchar(15) NULL,
LoginID] varchar(256) NULL,
ManagerID int NULL,
Title varchar(50) NULL,
BirthDate datetime NOT NULL,
Gender char(1) NULL
)
You could convert the table to Unicode with the following Alter Table Alter Column statements:
Alter Table employee Alter Column NationalIDNumber nvarchar(15)
Alter Table employee Alter Column LoginID nvarchar(256)
Alter Table employee Alter Column Title nvarchar(50)
Alter Table employee Alter Column Gender nchar(1)
Before you run the Alter Table Alter Column statement, ensure all constraints, indexes on the column are remove.
Another method of in-place conversion, or rather a pseudo in-place conversion is to use the SELECT INTO statement to create a new table with Unicode scheme, and bulk load the data over to the new table. For example with the above schema, you could create a new Unicode table.
SELECT
EmployeeID,
CAST(NationalIDNumber as nvarchar(15)) as NationalIDNumber,
CAST(LoginID as nvarachar(256)) as LoginID,
ManagerID,
CAST(Title as nvarchar(50)) as Title,
BirthDate,
CAST(Gender as nchar(1)) as Gender
INTO
employee_wstr
FROM
employee
Depending on how many constraints, indexes you have defined on the character columns, the SELECT INTO method may perform better than the Alter Table Alter Column method.
In-place conversion is less time-consuming than full export and import, but it should only be used with extreme discretion. To prevent data loss, the data should be fully scanned to ensure that no data are outside the ASCII 7-bit range.
Comments
Anonymous
July 09, 2006
PingBack from http://www.idoel.smilejogja.com/2006/07/09/sql-server-2005-unicode-considerations/Anonymous
March 07, 2007
PingBack from http://chaespot.com/mssql/2007/03/07/price-495-excerpt-boise-idaho-3/Anonymous
August 21, 2011
Plz Help me . I am using google transliteration to display the text in Hindi/Tamil etc. I tried to store the text appear as Hindi from textarea in an nvarchar field of database (SQL Server 2005) , the text saved as "???????". After retireving text from the same it display the text as "???????". Can anyone help me how to store and retrieve the actual data from SQL Server 2005? I am using ASP.net, C# and SQL Server 2005 plz send details on nafadekiran11@yahoo.com urgentyAnonymous
August 22, 2012
Use the following url may help you... msdn.microsoft.com/.../bb330962(v=sql.90).aspx