MRS Capability Extension: Importing and Exporting Large In-Memory Data Frames
 Introduction
Introduction
Microsoft R Server is an advanced analytics platform. Enterprise-ready, Microsoft R Server scales and accelerates R. R being an open source, statistical programming language, is a great tool to start building intelligent applications and realizing value in predictive analytics. While powerful, R is single threaded and memory bound. In order to handle Big Data, Microsoft takes your R development and deployment and adds
- Algorithms optimized for parallel execution on Big Data. These algorithms are optimized for distributed execution, eliminate memory limitations and scale from laptops to servers to large clustered systems.
- Adaptable parallel execution framework providing services including communications, storage integration and memory management to enable Parallel algorithms to analyze vast data sets and scale from single-processor workstations to clustered systems with hundreds of servers.
- Versatile access to any data source ranging from simple workstation file systems to complex distributed file systems and MPP databases.
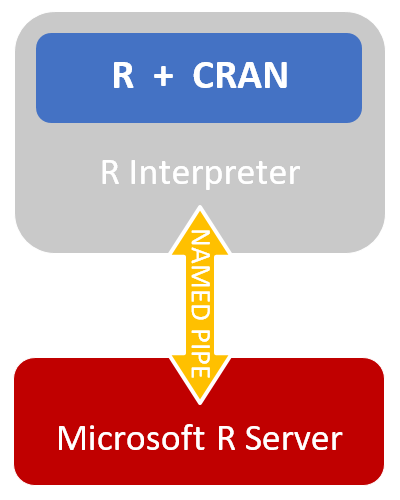
The diagram on the right shows the interface between Open Source R and Microsoft R Server, with all open source code surrounded in gray, and closed source in red.
Memory Limits in R
In standard R, the maximum Data Frame size is limited by the internal 32-bit indexing for vectors, this is true in both 32-bit and 64-bit R, this gives us a ceiling of 2,147,483,647 elements in a vector, with each element being n number of bytes (Source). This means that, as a Data Frame is a vector, the hard limit for Data Frame size is 2,147,483,647 elements. Each element is limited by the maximum bytes size of a single data point which is 2GB, this give us a theoretical maximum In-Memory Data Frame size of… 4,294,967,292 Gigabytes! That’s 4 Exabytes of data! Of course, no client machine would have this much memory available.
Named Pipes, the Interface between Open Source R and Microsoft R Server
To remain compatible with open source R, Microsoft R Server utilizes Named Pipes to pass data between the open source interpreter and Microsoft’s algorithms.
On Linux/Unix based operating systems Named Pipes have a maximum per-read-write size of 2 GB, as they are read from and written into using the system calls read() and write(), which are limited to transfer at most 0x7ffff000 (2,147,479,552) bytes, returning the number of bytes actually transferred.
Documentation: read(), write(), Named Pipe Example
On Windows, Named Pipes have a maximum per-read-write size of 4 GB, as the system API uses DWORD to control the size of a read or write.
Documentation: ReadFile(), WriteFile(), Named Pipe Example
Why is all of this important?
Microsoft R Server imports data into a Data Frames, and also has the capability to archive a Data Frame as an XDF file, via the functions rxImport() and rxDataStep()
rxImport() supports conversions from database data sources (SPSS, SAS, ODBC, or XDF), and writes this data to either a Data Frame or an XDF files. rxDataStep() is primarily used to transform data while importing a Data Frame or exporting data from a Data Frame. rxDataStep() supports, in addition to simple data sources and XDF files, complex data sources, such a directly reading data from Teradata or Hadoop. These two functions are very powerful ways to get data into R for analysis as well as archive the results of analysis.
See also: Transform Data Using Microsoft R Server, Differrence between rxImport and rxDataStep, as well as help(rxDataStep) and help(rxImport).
Because a Data Frame exists wholly in memory, but Microsoft R Server must communicate through the Named Pipe, the original implementation of Microsoft R Server, limited by Named Pipe constraints, had a maximum Data Frame of 2GB in size on Linux/Unix and 4GB in size on Windows. This is significantly smaller than our theoretical maximum of 4 Exabytes.
Solution!
To address this, Microsoft R Server has been improved; Using the Big Data paradigm of divide and conquer, Microsoft R Server segments communication with Open Source R, breaking a Data during transmission into many small parts, recombining the data for the R interpreter.
This improvement allows a user to import any amount of data into a Data Frame, with the limiting factor now being the amount of memory on the system being used to hold the data.
Time to go buy more RAM.