Cluster service falha ao iniciar com erro "The cluster database could not be loaded due to error '%1' on node '%2'. The file may be missing or corrupt. Automatic repair might be attempted.", porém nem tudo é o que parece...
Por: Rafael Oliveira
Recentemente, trabalhei em um incidente em um ambiente Windows Server 2008 onde o serviço de cluster em dos nodes falhava ao iniciar. No log de sistema do mesmo obtinha-se o seguinte erro:
Log Name: System
Source: Microsoft-Windows-FailoverClustering
Date: 3/3/2016 5:36:26 PM
Event ID: 1057
Task Category: None
Level: Critical
Keywords:
User: SYSTEM
Computer: XXXXXXXXXXXXXXXXX
Description:
The cluster database could not be loaded due to error '%1' on node '%2'. The file may be missing or corrupt. Automatic repair might be attempted.
Event Xml:
<Event xmlns="https://schemas.microsoft.com/win/2004/08/events/event">
<System>
<Provider Name="Microsoft-Windows-FailoverClustering" Guid="{baf908ea-3421-4ca9-9b84-6689b8c6f85f}" />
<EventID>1057</EventID>
<Version>0</Version>
<Level>1</Level>
<Task>0</Task>
<Opcode>0</Opcode>
<Keywords>0x8000000000000000</Keywords>
<TimeCreated SystemTime="2016-03-03T20:36:26.981Z" />
<EventRecordID>1936754</EventRecordID>
<Correlation />
<Execution ProcessID="6112" ThreadID="7024" />
<Channel>System</Channel>
<Computer>XXXXXXXXXXXXXXXXX</Computer>
<Security UserID="S-1-5-18" />
</System>
<ProcessingErrorData>
<ErrorCode>15003</ErrorCode>
<DataItemName>
</DataItemName>
<EventPayload>3100340035003000000042005200530050004F00450056004D003100300032000000</EventPayload>
</ProcessingErrorData>
</Event>
O evento acima, em um primeiro momento, nos levava a crer que se tratava de um problema causado por hive corrompida. Apenas lembrando que a database do cluster (registry hive) está armazenada no arquivo C:\WINDOWS\Cluster\CLUSDB em cada node e, qualquer alteração efetuada é replicada para todos os membros.
Prosseguindo com o troubleshooting coletamos o cluster.log do node com falha e obtivemos as seguintes informações:
000015d8.00001408::2016/03/03-18:28:59.088 INFO [JPM] Node 2: node 1 completed regroup. View is 4302(1 2)
000015d8.00001408::2016/03/03-18:28:59.088 INFO [RGP] Node 2: incoming node 1 is in stage Stable_`0(1) oldView:4302(1 2) proposed:4302(1 2)
000015d8.00001408::2016/03/03-18:28:59.088 INFO [RGP] Node 2: it is good that node 1 finished regroup
000015d8.00001408::2016/03/03-18:28:59.088 INFO [GUM] Node 2: State transfer fast
000015d8.00001408::2016/03/03-18:28:59.088 INFO [CORE] Node 2: Installing state (fast)
000015d8.00001408::2016/03/03-18:28:59.088 INFO [CORE] Node 2: Installing state for Global Update Manager
000015d8.00001408::2016/03/03-18:28:59.088 INFO [GUM] Node 2: Joiner adopted cluster state (locker=1 queue-size=0 seqno=108 targets=(1))
000015d8.00001408::2016/03/03-18:28:59.088 INFO [CORE] NeedStateView is adjusted to (2). SetGumView ((1))
000015d8.00001408::2016/03/03-18:28:59.088 INFO [GUM] Node 2: Gum Targets are set to (1)
000015d8.00001408::2016/03/03-18:28:59.088 INFO [CORE] Node 2: Installing state for Causal Multicast
000015d8.00001408::2016/03/03-18:28:59.088 INFO [Causal] Node 2: adopting timeStamp [0 23]
000015d8.00001408::2016/03/03-18:28:59.088 INFO [CORE] Node 2: Installing state for QuorumManagerFast
000015d8.00001408::2016/03/03-18:28:59.400 INFO [GUM] Node 2: State transfer slow
000015d8.00001a8c::2016/03/03-18:28:59.400 INFO [CORE] Node 2: Installing state (slow)
000015d8.00001a8c::2016/03/03-18:28:59.400 INFO [CORE] Node 2: Installing state for Database Manager
000015d8.00001a8c::2016/03/03-18:28:59.400 INFO [DM] Node 2: Join. Install state <BoxedByteArray len='524288'/>
000015d8.0000157c::2016/03/03-18:28:59.540 INFO [JPM] Node 2: joined successfuly. New view is 4302(1 2)
000015d8.00001a8c::2016/03/03-18:28:59.587 INFO [DM] Key \Registry\Machine\Cluster does not appear to be loaded (status STATUS_OBJECT_NAME_NOT_FOUND(c0000034)
000015d8.00001a8c::2016/03/03-18:28:59.587 INFO [DM] Loading Hive, Key Cluster, FilePath C:\Windows\Cluster\CLUSDB
000015d8.00001a8c::2016/03/03-18:28:59.587 ERR [CORE] Node 2: exception caught STATUS_INSUFFICIENT_RESOURCES(c000009a' because of 'Load(NOTHROW(), securityAttributes, discardError )'
000015d8.00001a8c::2016/03/03-18:28:59.587 ERR Exception in the InstallState is fatal (status = 1450)
000015d8.00001a8c::2016/03/03-18:28:59.587 ERR FatalError is Calling Exit Process.
000015d8.0000163c::2016/03/03-18:28:59.587 INFO [CS] About to exit process...
A exceção c000009a (STATUS_INSUFFICIENT_RESOURCES) trazia evidências que, possivelmente, não estávamos enfrentando um problema de corrupção da hive do cluster.
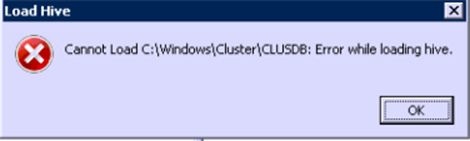
Como um segundo teste para constatar a corrupção da hive, tentamos carregá-la, no próprio node com problemas, através do editor de registro (regedit) usando a opção Load Hive... , porém ao tentar isso, obtivemos o erro:
Através do Task Manager, na aba Performance, vimos em Kernel Memory que a utilização do Paged Pool (Paged) estava com um pouco mais de 2 GB. Esta condição não causava instabilidade no sistema operacional, porém era um ponto de atenção a ser observado naquele momento devido a evidência obtida anteriormente no cluster.log.
Assim utilizando a ferramenta poolmon.exe, que permite obter de forma detalhada o consumo dos pools de memória do Kernel (Paged e NonPaged) obtivemos que a seguinte tag era a ofensora:
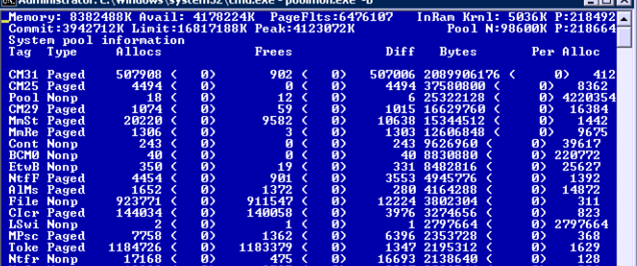
O documento https://blogs.technet.microsoft.com/yongrhee/2009/06/23/pool-tag-list/ contém a lista com a descrição das tags e contém a seguinte descrição refente a tag mostrada acima: "CM?? – nt!cm – Internal Configuration manager allocations". Entrentanto, a tag CM31, precisamente, quase sempre é associada a alocação de memória pelo registro e vendo esta alta utilização de memória da mesma, através do performance monitor verificamos o contador abaixo:
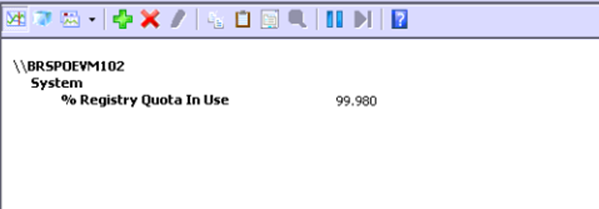
Acima, basicamente vimos que, durante o problema, a utlização da quota de registro disponbilizada pelo sistema operacional estava em quase 100%. Com isso, não era mais possível alocar memória para carregar hives de registro, ou seja, durante o start, o cluster service tentava carregar sua hive (database) na memória, porém com a quota de registro quase toda em uso não havia mais espaço para a mesma, levando a falha durante o processo.
Através da ferramenta Dureg (https://support.microsoft.com/en-us/kb/927229), obtivemos o tamanho das hives executando o comando abaixo:
C:\>DUREG /a
Size of HKEY_CLASSES_ROOT : 14491836
Size of HKEY_USERS : 1845831303
Size of HKEY_LOCAL_MACHINE : 82076221
Total Registry data size: 1942399360
O valor mostrado é expresso em bytes e acima vemos que a causa era alguma hive de registro de usuário uma vez o valor obtido para HKEY_USERS era de aproximadamente 1,8 GB e com o comando abaixo, identificamos que se travava do próprio usuário que estava conectado no servidor:
C:\>dureg /cu:
Size of HKEY_CURRENT_USER : 1844208695
Podería-se prosseguir com a investigação usando a ferramenta para obter os valores de subchaves na hive do usuário a fim de obter onde estava a causa do problema de bloat do registro, porém como, naquele momento, a prioridade era permitir que cluster service iniciasse e node ficasse novamente disponível no cluster, foi dedicido apenas remover o perfil do usuário e criá-lo novamente, pois era uma solução rápida e não trazia impacto para o ambiente uma vez que o mesmo correspondia a conta de administração usada para gerencimento da máquina.